
ブロックチェーンのパフォーマンスのテストと最適化 - パート 1
最初のレベルのタイトル
概要
この記事の目的は、特定の例 (cosmos-sdk SimApp) を通じて完全なパフォーマンス プロジェクト プロセスを紹介することです。具体的な内容では、使用されるブロックチェーン パフォーマンス テストが紹介されています。
1. 基本的な考え方
2. 共通ツール
最初のレベルのタイトル
基本的な考え方
ブロックチェーンのパフォーマンス テストは、方法論的には従来のパフォーマンス テストと何ら変わりません。パフォーマンス テストには混乱を招く概念が多数ありますが、ここでは、この記事で説明されている概念をリストして定義を示します。
副題
パフォーマンステストの定義
パフォーマンステストとは、システムまたはサービスのパフォーマンス指標の監視戦略を確立し、特定のシナリオでテストを実行し、パフォーマンスのボトルネックを分析および判断して最適化し、最終的にパフォーマンス結果を取得してシステムまたはサービスのパフォーマンス指標が所定の値を満たしているかどうかを評価することです。ここではcosmos-sdkのsimappブロックチェーンと合わせて説明します。
1. 指標とは、一般にテクニカル指標とビジネス指標の 2 種類を指します。テクニカル指標とは一般的にTPS、応答時間、リソース使用率などで、ブロックチェーンに相当するものとしては1秒間に何件のトランザクションを処理できるかを指すのが一般的です。これらのトランザクションの応答時間や統計はどのようなものですか?この場合、システムによって使用されるリソースの状態はどうなるのでしょうか?満たされることが期待されるビジネス指標は、本番環境の統計から取得する必要があります。cosmos-sdk の本番アプリケーション cosmos-hub を例に取ると、現在のブロック生成時間は約 6 秒であり、各ブロックのトランザクション数はほとんどが10未満です。期待される景気指数を TPS として 100 に設定する方が合理的です。 (このような低い TPS は、実際には、cosmos-hub の主な焦点がチェーンの相互運用性にあるため、その目標に関連しています)。
2. テスト モデル: 実際のシーンを抽象化し、ビジネス モデルがどのようなものであるかを説明します。 cosmos-hub を例にとると、世界中に分散されたブロックチェーン ノードは、約 500 個のバリデーター ノードと約 200 個のアクティブなバリデーター ノードが存在するときにトランザクションを処理します。実際の状況は、テスト時にスケールに応じて抽象化できます。
3. テスト計画: テスト環境、テストデータ、テストモデル、パフォーマンス指標などを含みます。ブロックチェーンシステムを比較するテストは、テスト構成を決定し、1000人のユーザーと各ユーザーの残高1000ステークなどのコンテンツを準備します。
4. 監視が必要です: 監視オブジェクトには、印刷機、ブロックチェーン ノード、および負荷分散サーバーなどのその他のものが含まれます。クラウドネイティブ時代の監視は一般的に Kubernetes+Prometheus+Grafana です。
5. 必要なテスト条件: ハードウェア環境、テスト実行戦略など。例: 4 C 8 G、最初の 60 秒間は、1 秒あたり 10 スレッドを追加します。
7. 結果レポートを作成する: レポートの内容は、もちろん実際の指標データです。
副題
パフォーマンスシナリオの分類
1. ベースライン パフォーマンス シナリオ: インターフェイスの単一トランザクション/容量 (トラフィック量) を作成し、混合容量を準備します。
2. (混合) キャパシティ パフォーマンス シナリオ: 混合キャパシティ テストは、実際のオンライン シーンがさまざまなサービスで構成されているため、さまざまな同時実行率に従ってこれらのサービスによって開始される勾配圧力テストが混合キャパシティ テスト シナリオです。
4. 異常なパフォーマンスのシナリオ: 強い圧力下で、異常をシミュレートします。
副題
重要なパフォーマンス指標
1. RT, Response Time
2. HPS, Hits Per Second
3. TPS, Transactions Per Second,パフォーマンス テストには次のような多くの指標があります。
4. QPS, Queries Per Second
5. PV, Page View
6. Throughput
7. IOPS, Input/Output Operations Per Second
ここでのトランザクションは、一般的に従来のアプリケーションでは「トランザクション」と呼ばれ、ブロックチェーン分野では「トランザクション」と呼ばれます。
より重要な指標はリソース使用率、スループット、および応答時間であり、サービス プロバイダーは前者 2 つを重視し、ユーザーは後者を更新します。これらの指標の一般的な状況は、パフォーマンス テスト方法論 (http://hosteddocs.ittoolbox.com/questnolg 22106 java.pdf) の古典的な図を参照して説明されており、実際の状況は異なる場合があります。図には 3 つのライン、3 つのエリア、3 つの状態が定義されていますが、この図はさらに見る価値があり、指標間の関係が大まかに理解できます。
1. 3 ワイヤ: 使用率、スループット、応答時間
副題
他の
他の
1. 一般的に、パフォーマンス テストはどのような場合に実行する必要がありますか。
a. プロジェクトがオンラインになる前に、システムの収容能力を見積もる
b. プロジェクト再構築後の効果評価
2. パフォーマンス報告書を受け取った場合はプロジェクトを終了します。これは単なるパフォーマンス検証です。包括的なパフォーマンス テストを実行し、同時にシステムを最適な状態に調整することは、完全なパフォーマンス プロジェクトです。パフォーマンスのチューニングには長い時間がかかり、場合によっては開発への参加が必要となり、費用がかかります。
ブロックチェーンのパフォーマンステストWhy blockchain performance is hard to measure副題
遅れ
遅れ
この遅れた期間の開始と終了はどのように定義されますか?
1. 開始点はユーザーが送信をクリックしたときですか、それともトランザクションがメモリプールに到着したときですか?
2. エンドポイントは、トランザクションが最初のブロックによって確認されることですか?それとも6番目のブロックで確認されているのでしょうか(POWブロックチェーンはそう考えています)?それとも、エンドユーザーがインターフェースから応答を受け取ったときですか?
3. 一部のブロックチェーン システムは、処理を開始する前に、一定の遅延と一定量のトランザクションを待機します。このようにして、最も幸運なトランザクションが最後に参加し、その処理遅延が最も短くなります。
5. 一部のブロックチェーンシステムではトランザクション処理が優先されており、手数料の高いトランザクションはすぐに確認されますが、手数料の低いトランザクションは比較的遅くなります。手数料の違いは、トランザクション遅延と TPS 統計に影響を与えます。
副題
スループット
もう 1 つの実際的な問題は、ユーザーがブロックチェーンの TPS をあまり気にしておらず、手数料を削減してトランザクションをできるだけ早く完了する方法だけを気にしていることです。この観点から見ると、TPS はシステム サービス プロバイダーにとってのみ意味があります。
基本的なツール
副題
圧力ツールJmeter一般用加圧工具
4. …
または、次のような特定のアプリケーション固有のテスト ツール:
Jmeter の使用は、使用シナリオに近く、より一般的である必要があります。一般に、ブロックチェーン ノードと対話する方法があります (一般的なコマンド ライン対話は、最終的には次のインターフェイスのいずれかを呼び出します)。
1. gRPCプロトコル
Jmeter によってサポートされるサンプラーは HTTP をサポートし、gRPC プロトコルのサポートにはプラグインの助けが必要です。jmeter-grpc-request
副題
監視ツールPrometheus一般的な監視ツールhttps://prometheus.io/assets/architecture.pngこのツールは多くのコンテンツを監視できます。その生態は図に示されています (
)。ブロックチェーン アプリケーションをテストする実践では、正式なテスト環境は一般に高度なハードウェア構成を備えているため、複数のブロックチェーン ノードをデプロイして正式なテスト環境をシミュレートするために docker-compose が一般的に使用されます。クラウド サービス メーカーのマシンは高価なので、コストを節約できます。cadvisor。
docker-compose では、コンテナーが使用するメモリや CPU の計算能力などのリソースを制限したり、CPU コアをバインドしたりすることができます。stress-ng写真
最初のレベルのタイトル
性能調整
一般に、パフォーマンスのボトルネックの一般的なメタ原因 (通常はハードウェア レベルでの理由を「理由の背後にある理由」と呼んでいます) は、ネットワーク、CPU、およびディスク IO です。ディスク IO ボトルネックの原因となる操作には、頻繁なログの書き込み、不要なログの印刷、ネットワークを介したディスク アクセスなどがあります。これらのリソースはシステム コールを通じて完了します。システム コールを追跡するには、strace を使用して、どのシステム コールが実行されたか、およびこれらのコールに費やされた時間を確認できます。
発生する可能性のあるもう 1 つの問題は、システムの不安定性です。これは、CPU 使用率や TPS の不安定性として現れることがあります。
CPU 使用率が不安定 (傾向は安定しているが変動が大きい) の場合、CPU 命令の実行の観点から見ると、CPU がさまざまな時間にわたってアイドル状態にあることを意味します。この場合の理由は、アイドル状態の CPU があることではなく、アイドル状態の時間が長いか短いことが原因です。原因を観察して見つけるには、Linux システム ツールやプログラムに対応するプロファイリング ツールを使用する必要があります。
副題
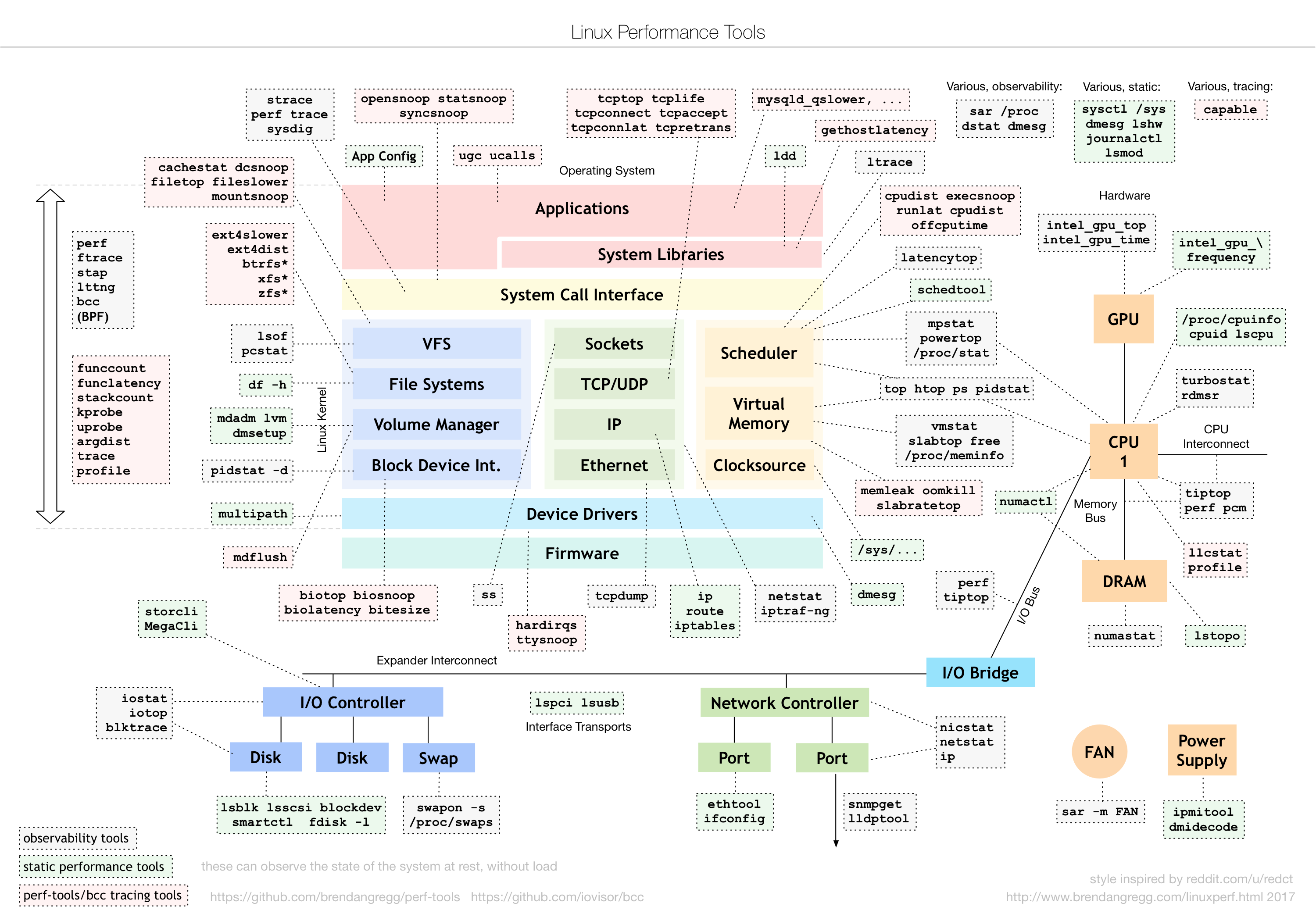
分析ツールhttps://www.brendangregg.com/Perf/linux_perf_tools_full.png写真
副題
一般にディスク IO はシステムのボトルネックを引き起こし、ディスク IO スタックは比較的長いため、分析が困難になります。 IO スタックに精通していると、問題を見つけるのに役立ちます (https://www.thomas-krenn.com/en/wikiEN/images/c/c 2/Linux-storage-stack-diagram_v 6.2.pdf)
写真
原因がわかったら、オペレーティング システムのパラメータやアプリケーション システムのパラメータを調整してパフォーマンスを最適化する方が早いですが、コードを変更する必要がある場合は、システム アーキテクチャの最適化やコーディング作業が必要になり、チューニング サイクルが非常に長くなります。 。



{kind=link}
{kind=link}