
フェデレーテッド ラーニング フレームワークの分析
【序文】
▲ フェデレーテッド ラーニングの問題の見直し 前述したように、Google は 2016 年に「フェデレーテッド ラーニング」と呼ばれる入力方式モデルの新しい学習方法を提案しました。時間が経つにつれて、フェデレーション ラーニングは Google 入力メソッド モデルに対する単純なソリューションではなくなり、新しい学習モデルが形成されました。フェデレーテッド ラーニングによって解決される問題は通常、TMMPP (プライバシーを備えた複数のデータ ソースにわたる機械学習モデルのトレーニング) と呼ばれます。つまり、複数の参加者のデータが漏洩しないようにしながら、所定のモデルのトレーニングを共同で完了することです。フェデレーテッド ラーニングで解く TMMPP 問題には、n 個のデータ キューブ (Data Controller) {D1, D2,...Dn} が含まれており、各データ キューブは n 個のデータ {P1, P2,...Pn} に対応します。フェデレーテッド ラーニングのトレーニング モードの観点から見ると、トレーニングする必要があるフェデレーテッド ラーニング アルゴリズムを選択した後、フェデレーテッド ラーニングに対応する入力を提供し、トレーニング後に最終的に出力を取得する必要があります。
連合学習の入力(Input):各データ当事者は、Pi が所有するオリジナルデータ Di を共同モデリングの入力として使用し、連合学習のプロセスに入力します。
フェデレーテッド ラーニングの出力 (出力): すべての参加者のデータを結合し、グローバル モデル M をフェデレーテッド トレーニングします (トレーニング プロセス中、データ パーティの元のデータに関する情報は他のエンティティに公開されません)。
▲ フェデレーテッド ラーニングで直面する課題
フェデレーション ラーニング テクノロジは、現在も継続的に改善されています。開発の過程で、フェデレーテッド ラーニングは、統計上の課題、効率の課題、セキュリティの課題という 3 つの大きな課題に直面します。
【統計的課題】 統計的課題とは、フェデレーテッドラーニングの実行時に、各ユーザーのデータの分布や量の違いによって引き起こされる課題です。
a) 非独立かつ同一に分散されたデータ (Non-IID データ)、つまり、異なるユーザーのデータの分布が独立しておらず、明らかな分布の違いがあります。乙は中国南部の田植えデータを持っているが、緯度、気候、人文科学などの影響により、両当事者のデータは同じ分布に従わない。
b) 不均衡なデータ(不均衡データ)、つまり利用者のデータ量に明らかな差があり、例えば大企業では数千万件近いデータを保有しているのに対し、中小企業では数万件しか保有していない。巨大企業に対するデータの影響は最小限であり、モデルのトレーニングに貢献することは困難です。
[効率の課題] 効率の課題とは、フェデレーション ラーニングにおける各ノードのローカル コンピューティングと通信の消費によって引き起こされる課題を指します。
a) 通信オーバーヘッド、つまりユーザー(参加者)ノード間の通信は、通常、限られた帯域幅を前提として各ユーザー間で送信されるデータ量を指し、データ量が大きくなるほど通信損失も大きくなります。
b) 計算の複雑さ、つまり、基礎となる暗号化プロトコルに基づく計算の複雑さは、通常、基礎となる暗号化プロトコルの計算の時間計算量を指し、アルゴリズムの計算ロジックが複雑になればなるほど、時間がかかります。
[セキュリティ課題] セキュリティ課題とは、フェデレーテッド ラーニング プロセス中にさまざまなユーザーがさまざまな攻撃方法を使用することによって引き起こされる情報クラッキングやポイズニングなどの課題を指します。
a) 半正直モデル。つまり、各ユーザーはフェデレーテッド ラーニングのすべてのプロトコルを誠実に実装しますが、取得した情報を使用して他のユーザーのデータを分析し、プッシュバックしようとします。
b) 悪意のあるモデル。つまり、ノード間の合意を厳密に遵守せず、元のデータまたは中間データをポイズニングしてフェデレーテッド ラーニング プロセスを破壊する可能性のあるクライアントが存在します。
【Federated Learningの共通フレームワーク】
上記の 3 つの課題に直面して、学術コミュニティは対象を絞った研究を実施し、フェデレーテッド ラーニング トレーニング プロセスを最適化するために多くの効果的で専用のフェデレーテッド ラーニング フレームワークを提案してきました。以下にこれらのフレームワークを簡単に紹介します。
Federated Learning 1.0 – 従来の Federated Learning
まず第一に、フェデレーテッド ラーニングの概念と原理を再説明しましょう。フェデレーテッド ラーニング タスクを共同で実行する複数の参加者と共同作業者がいます。参加者 (つまり、データ所有者) は、事前に設定されたフェデレーテッド ラーニング アルゴリズムを通じて勾配に似た中間データを生成します。 、さらなる処理のためにコーディネーターに引き渡され、その後、次のトレーニングラウンドの準備のために各参加者に戻されます。
繰り返して、フェデレーテッド ラーニング タスクが完了します。タスク全体を通じて、参加者のローカル データは各 FL フレームワークで交換されませんが、コーディネーターと参加者の間で送信されるパラメーター (勾配など) によって機密情報が漏洩する可能性があります。
データ所有者のローカル データを漏洩から保護し、トレーニング中に中間データのプライバシーを保護するために、参加者がコーディネーターと対話するときにパラメーターをプライベートに交換するために、いくつかのプライバシー技術が FL のフレームワークに適用されます。さらに、FL フレームワークで使用されるプライバシー保護メカニズムの観点から、FL フレームワークは次のように分割されます。
1) 暗号化されていないフェデレーション ラーニング フレームワーク (つまり、情報は暗号化されません)。
2) 差分プライバシーに基づく連合学習フレームワーク (差分プライバシーを使用して情報を混乱させ、暗号化する)。
3) セキュアなマルチパーティ コンピューティングに基づくフェデレーテッド ラーニング フレームワーク (セキュアなマルチパーティ コンピューティングを使用して情報を暗号化します)。
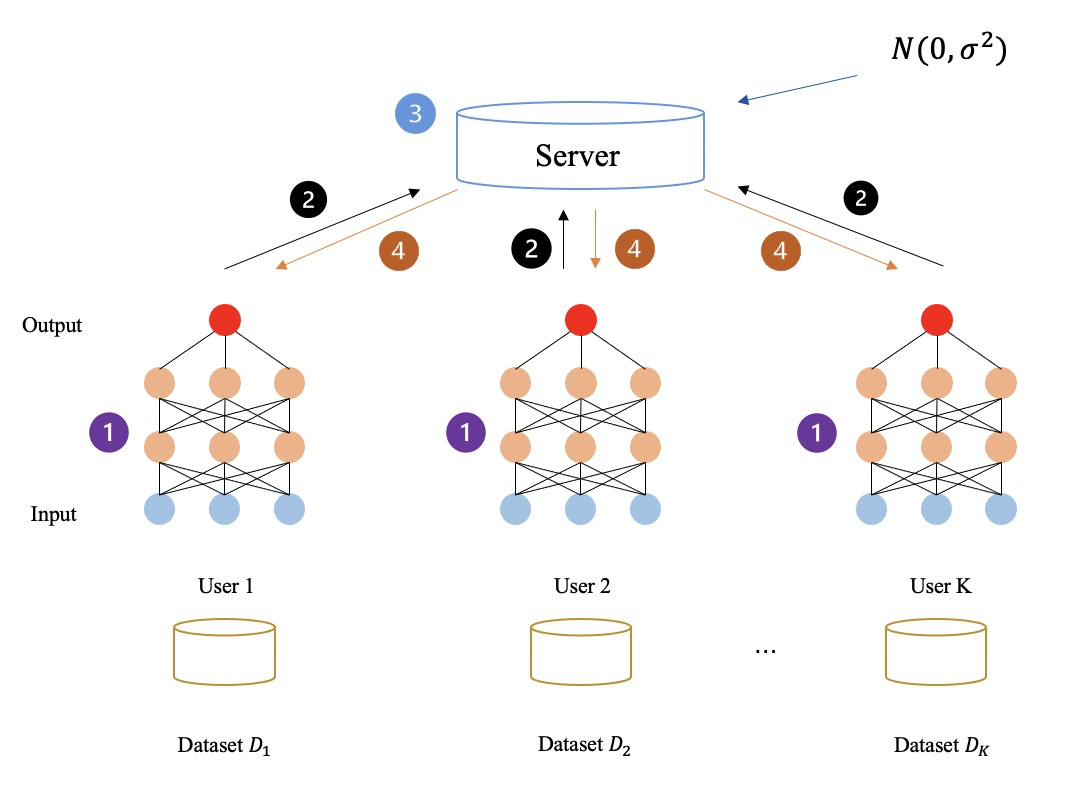
▲ 非暗号化フェデレーテッド ラーニング フレームワーク
多くの FL フレームワークは、平文パラメータの交換によってもたらされる潜在的なリスクを無視しながら、効率の向上や統計的異質性の課題に対処することに重点を置いています。
2015 年に西尾らによって提案された機械学習のためのモバイル エッジ コンピューティング フレームワークである FedCS[3] は、異種データ所有者の設定に基づいて FL を迅速かつ効率的に実行できます。
2017 年に Smith らは、FL とマルチタスク学習を組み合わせた MOCHA[2] と呼ばれるシステム認識型の最適化フレームワークを提案し、マルチタスク学習を使用して統計的課題に対処します。データ量の違いによるものです。
同年、Liang らは、ローカル表現学習と組み合わせた LG-FEDAVG [4] を提案しました。彼らは、ローカル モデルが異種データをより適切に処理し、公平な表現を効率的に学習して、保護されたプロパティを難読化できることを示しています。
以下の図に示すように、フェデレーテッド ラーニング プロセスでは中間データはまったく暗号化されず、すべての中間データ (勾配など) はプレーン テキストで送信および計算されます。上記の方法を通じて、最終的に参加者は一緒に学習し、連合学習モデルを取得します。
▲ 差分プライバシーに基づくフェデレーションラーニングフレームワーク
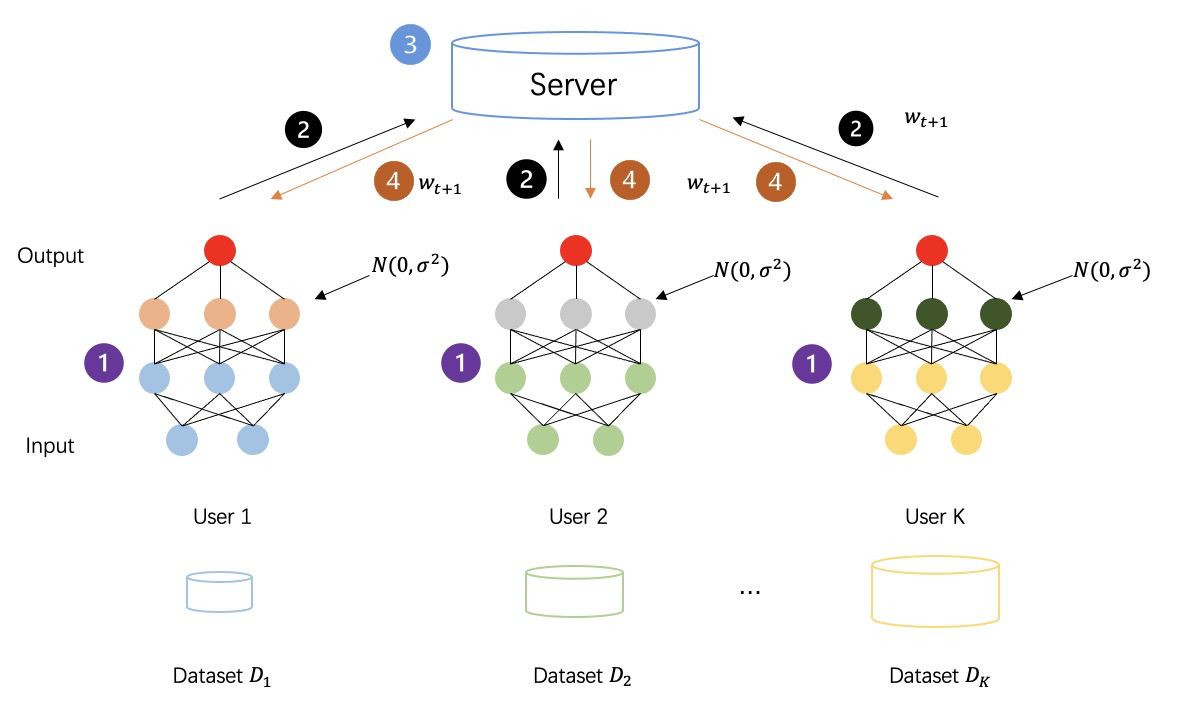
差分プライバシー (DP) は、データにノイズを追加するための強力な情報理論的保証を備えたプライバシー技術 [5-7] です [8-10]。 DP を満たすデータセットは、プライベート データのいかなる分析にも耐性があります。言い換えれば、取得されたデータ攻撃者は、同じデータセット内の他のデータを推論するのにほとんど役に立ちません。 DP は、生データまたはモデル パラメーターにランダム ノイズを追加することにより、個々の記録に統計的なプライバシー保証を提供し、データを取得不能にしてデータ所有者のプライバシーを保護します。
以下の図に示すように、差分プライバシーを採用して中間データを暗号化した後のフェデレーテッド ラーニング プロセスでは、すべての当事者によって生成された中間データは平文の送信計算ではなくなり、セキュリティがさらに強化されるようにノイズが追加されたプライバシー データになります。トレーニングプロセスのセックス。
▲安全なマルチパーティコンピューティングに基づくフェデレーションラーニングフレームワーク
FLの枠組みでは、準同型暗号(HE)や秘密マルチパーティ計算(MPC)などの手法が広く利用されていますが、これらは計算結果を参加者や調整者に公開するだけで、計算以外の情報は公開されていません。プロセス中の結果、追加情報。
実際、HE は、安全なマルチパーティ学習 (MPL) フレームワーク (FL から派生したフレームワーク。MPL フレームワークについては以下で詳しく説明します) と同様の方法で FL フレームワークに適用されますが、詳細は若干異なります。 FL フレームワークでは、HE は、MPL フレームワークで適用される HE のように参加者間でやり取りされるデータを直接保護するのではなく、参加者とコーディネーターの間でやり取りされるモデル パラメーター (勾配など) のプライバシーを保護するために使用されます。 [1] FL モデルに加法準同型性 (AHE) を適用して勾配のプライバシーを保護し、半完全性集中型コーディネーターに対するセキュリティを提供します。
MPC には多くの要素が含まれており、元の精度が維持され、高いセキュリティが保証されます。 MPC は、各当事者が結果しか知らないことを保証します。したがって、MPC を FL モデルに適用して、安全な集約とローカル モデルの保護を行うことができます。 MPC ベースの FL フレームワークでは、集中コーディネーターはローカル情報やローカル更新情報を取得できませんが、コラボレーションの各ラウンドで集計された結果を取得します。しかしながら、MPC技術がFLフレームワークに適用される場合、多額の追加の通信および計算コストが発生することになる。
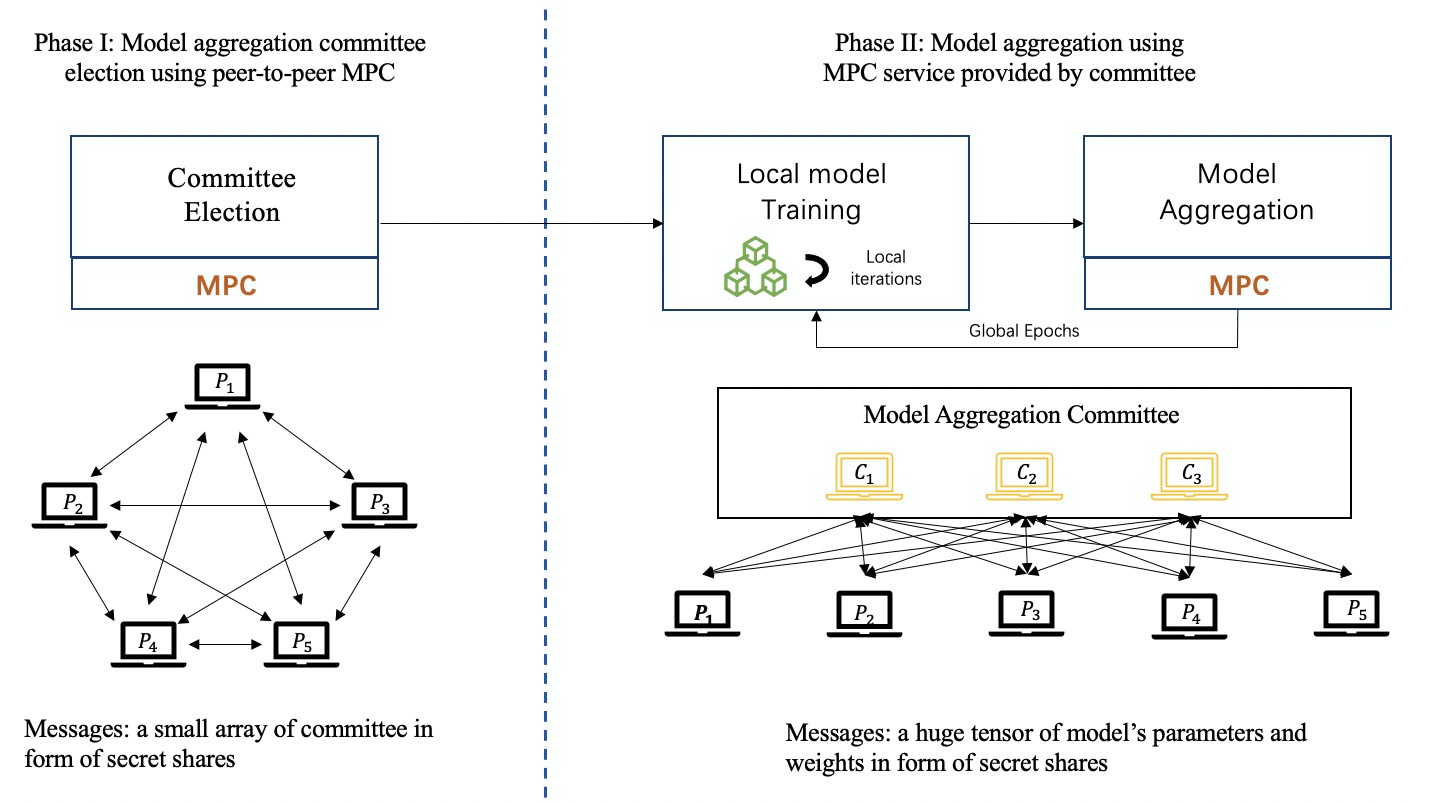
これまでのところ、秘密共有 (SS) は FL フレームワークで最も広く使用されている MPC ベースのプロトコルであり、特に Shamir の SS [24] です。
以下の図に示すように、MPC ベースの連合学習トレーニング プロセスでは、委員会メンバーのグループがコーディネーターとして参加者によって公平に選出され、MPC テクノロジーが実装されて協力してモデル集約のタスクを完了します。
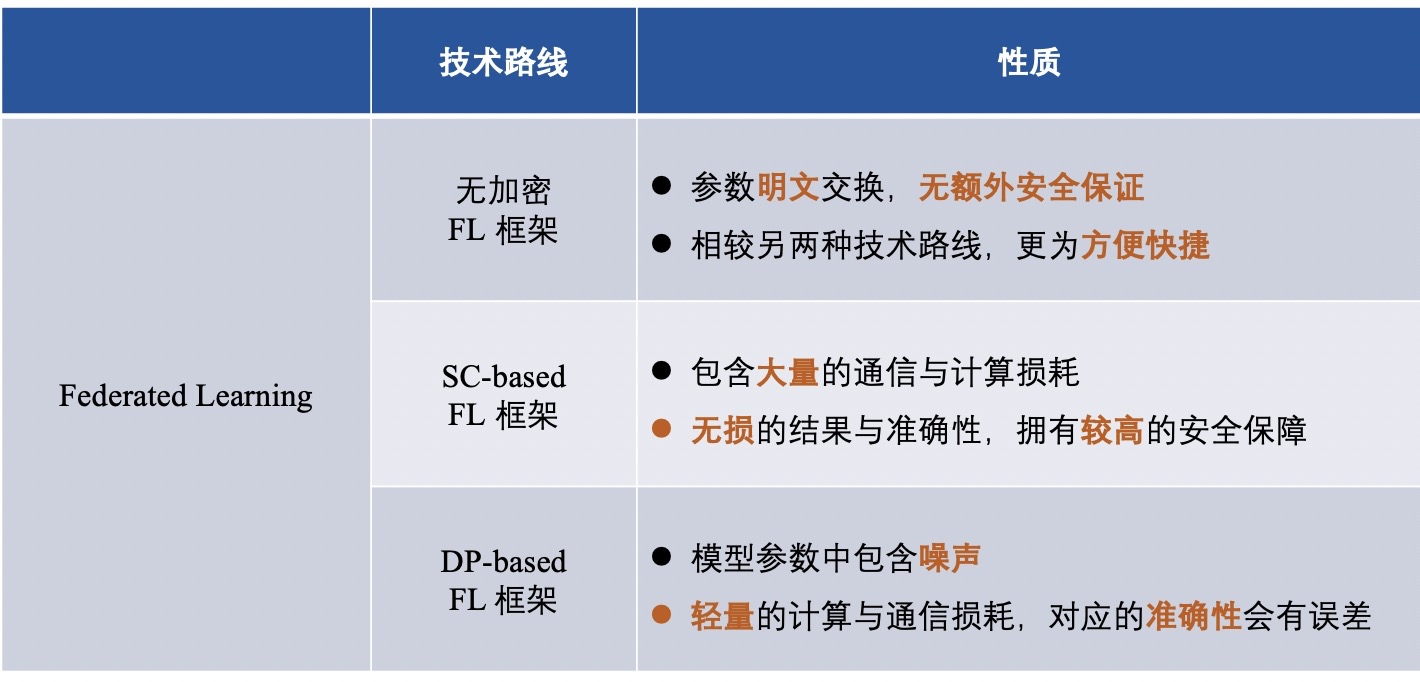
3 つの FL フレームワークを紹介した後、さまざまな技術ルートのフレームワークの違いを次のように要約します。
Federated Learning 2.0 -- 安全なマルチパーティ学習
上で「安全なマルチパーティ ラーニング」について説明しましたが、これはフェデレーション ラーニングから派生した用語です。簡単に言うと、サードパーティの協力者のいないフェデレーション ラーニングは、セキュアなマルチパーティ ラーニング (MPL) と呼ばれます。FL の区別が導入されました。言い換えれば、安全なマルチパーティ学習は、フェデレーテッド ラーニングに基づいて、従来のフェデレーテッド ラーニング モデルのコーディネーターを排除し、コーディネーターの能力を弱め、元のスター ネットワークをピアツーピア ネットワークに置き換え、すべての参加者を構成します。同じステータスを持っています。
MPL のフレームワークは、次の 4 つのカテゴリに大別できます。
1) 準同型暗号化 (HE) に基づく MPL フレームワーク。
2) Confused Circuit (GC) に基づく MPL フレームワーク。
3) 秘密共有 (SS) に基づく MPL フレームワーク。
4)ハイブリッドプロトコルに基づくMPLフレームワーク。
簡単に言うと、さまざまな MPL フレームワークは次のとおりです。中間データのセキュリティを確保するためにさまざまな暗号化プロトコルを使用するフレームワークです。 MPL のプロセスは FL のプロセスとほぼ似ています。使用される 4 つの暗号化プロトコルを見てみましょう。
▲準同型暗号(HE)
準同型暗号化 (HE) は、復号したりキーを知らなくても、暗号文に対して特定の代数演算を直接実行できる暗号化形式です。次に、暗号化された結果が生成されますが、その復号結果は、平文に対して実行された同じ操作の結果とまったく同じです。
HE は「3 つのタイプ」に分類できます: 1) 部分準同型暗号化 (PHE)、PHE では無制限の数の演算 (加算または乗算) のみが許可されます; 2)-3) 制限付き準同型暗号化 (SWHE) および同一ステートフル暗号化 (FHE) )、暗号文での SWHE と FHE の同時加算と乗算用。 SWHE は特定の種類の操作を限られた回数だけ実行できますが、FHE はすべての操作を回数無制限に処理できます。 FHE の計算の複雑さは、SWHE や PHE よりもはるかに高価です。
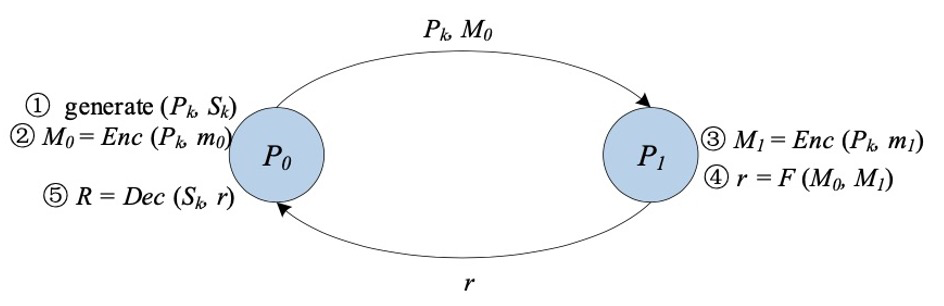
▲混乱回路(GC)
混乱回路[11][12] (GC) は、Yao の混乱回路としても知られ、学者 Yao Qizhi によって提案された安全な 2 者間コンピューティングの基盤技術です。 GC は、2 者 (ガーブラーと評価者) が任意の関数 (通常はブール回路として表される) の無思慮な評価を実行するための対話型プロトコルを提供します。
クラシック GC の構築には主に、暗号化、送信、評価の 3 つの段階が含まれます。
まず、難読化ツールは、回路内の各ワイヤに対して、そのワイヤの 2 つの可能なビット値「0」と「1」をそれぞれ表すラベルとして 2 つのランダムな文字列を生成します。回路内のゲートごとに、難読化プログラムは真理値表を作成します。真理値表の各出力は、その入力に対応する 2 つのラベルを使用して暗号化されます。これら 2 つのラベルを使用して対称キーを生成するキー導出関数を選択するのは、難読化プログラムの責任です。
次に、難読化ツールは真理値表の行をラップします。難読化フェーズが終了すると、難読化プログラムは難読化されたテーブルとその入力に対応する入力行ラベルを評価プログラムに渡します。
さらに、評価者は、oblivious transfer (Oblivious Transfer [13、14、15]) を介して入力に対応するラベルを安全に取得します。難読化テーブルと入力行のラベルを使用して、評価者は関数の最終結果が得られるまで難読化テーブルを繰り返し復号化する責任があります。
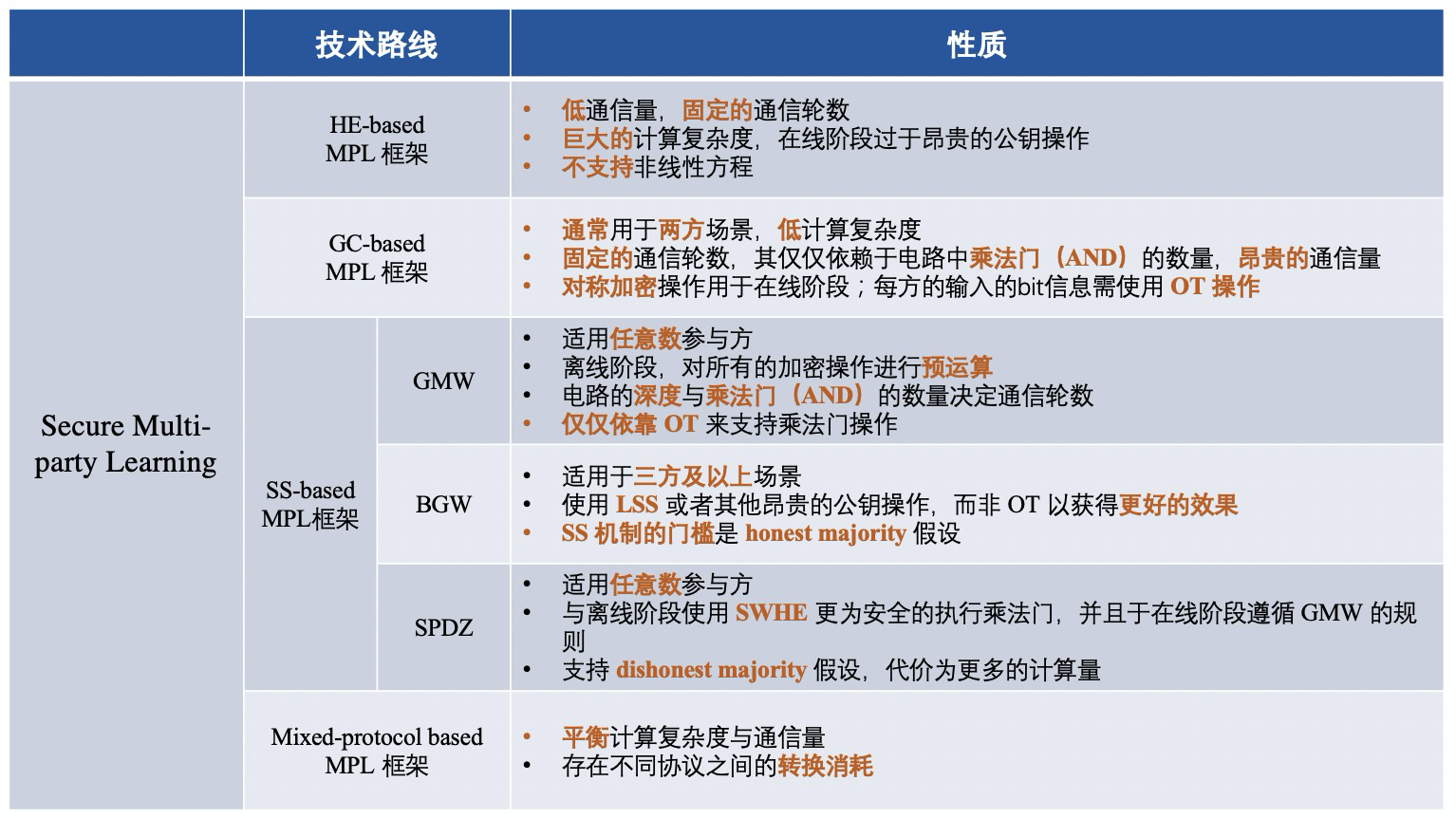
▲秘密分散(SS)
GMW プロトコルは、ブール回路または算術回路として表現できる関数を任意の数の関係者が安全に計算できるようにする最初の安全なマルチパーティ計算プロトコルです。ブール回路を例にとると、すべての関係者が XOR ベースの SS スキームを使用して入力を共有し、関係者が対話してゲートごとに結果を計算します。 GMW に基づくプロトコルは真理値表を混乱させる必要がなく、計算に XOR および AND 演算を実行するだけでよいため、対称暗号化および復号化演算を実行する必要がありません。さらに、GMW ベースのプロトコルでは、すべての暗号化操作の事前計算が可能ですが、オンライン段階で複数の当事者間で複数回の対話が必要になります。したがって、GMW は低遅延ネットワークで優れたパフォーマンスを実現します。
BGW プロトコルは、3 者以上のパーティによる演算回路のための安全なマルチパーティ コンピューティング プロトコルです。契約の全体的な構造は GMW と同様です。一般に、BGW はあらゆる算術回路の計算に使用できます。 GMW プロトコルと同様に、回路内の加算ゲートの計算はローカルで実行できますが、乗算ゲートの場合はすべての関係者が対話する必要があります。ただし、GMW と BGW はインタラクションの形式が異なります。 BGW は、パーティ間の通信に OT を使用する代わりに、線形 SS (Shamir の SS など) に依存して乗算をサポートします。しかし、BGW は正直多数派に依存しています。 BGW プロトコルは、t の削除に対抗できます。
SPDZ は、Damgard らによって提案された不正多数決計算プロトコルであり、2 者以上による算術回路の計算をサポートできます。オフラインフェーズとオンラインフェーズに分かれています。 SPDZ の利点は、オフライン段階では高価な公開鍵暗号計算を実行できるのに対し、オンライン段階では安価で情報理論的に安全なプリミティブのみを使用できることです。 SWHE は、オフライン段階で定数ラウンドの安全な乗算を実行するために使用されます。 SPDZ のオンライン フェーズは線形ラウンドであり、GMW パラダイムに従い、有限フィールド上の秘密共有を使用してセキュリティを確保します。 SPDZ は、最大で t <=n の悪意のある敵対者の腐敗したパーティと戦うことができます。ここで、t は対戦相手の数、n はコンピューティング パーティの数です。
集中暗号化プロトコルは段階的にまとめられ、技術的なルートごとにフレームワークの違いは次のようになります。
Federated Learning 3.0 -- 集団学習
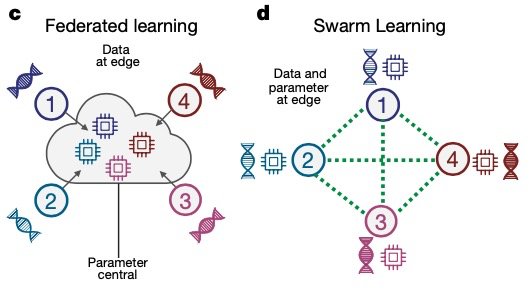
2021 年、ボン大学のヨアヒム シュルツェ氏とそのパートナーは、Swarm Learning (グループ学習) と呼ばれる「分散型機械学習システム」を提案しました。これは、MPL に基づいたさらなる進化とアップグレードであり、現在の機関間の学習方法に代わるものです。医学研究におけるデータ共有を一元化します。 Swarm Learning は、Swarm ネットワークを通じてパラメータを共有し、各参加者のローカル データに基づいて独立してモデルを構築し、ブロックチェーン技術を使用して Swarm ネットワークを破壊しようとする不正な参加者に対して強力な対策を講じます。
FL や MPL と比較して、Swarm Learning はフェデレーテッド ラーニングのトレーニング プロセスにブロックチェーン テクノロジーを導入し、信頼できるサードパーティをブロックチェーンに置き換えてトレーニングの相乗効果の役割を果たします。
【概要と展望】▲ Federated Learning Technologyルートの比較
フェデレーション ラーニングの過去と現在を通して、問題を解決するためのさまざまな技術的ルートがすでに存在します。要約すると、分散機械学習 (DML)、フェデレーテッド ラーニング (FL)、安全なマルチパーティ学習 (MPL)、グループ学習 (SL) になります。 ) 違いは大まかに次のとおりです。
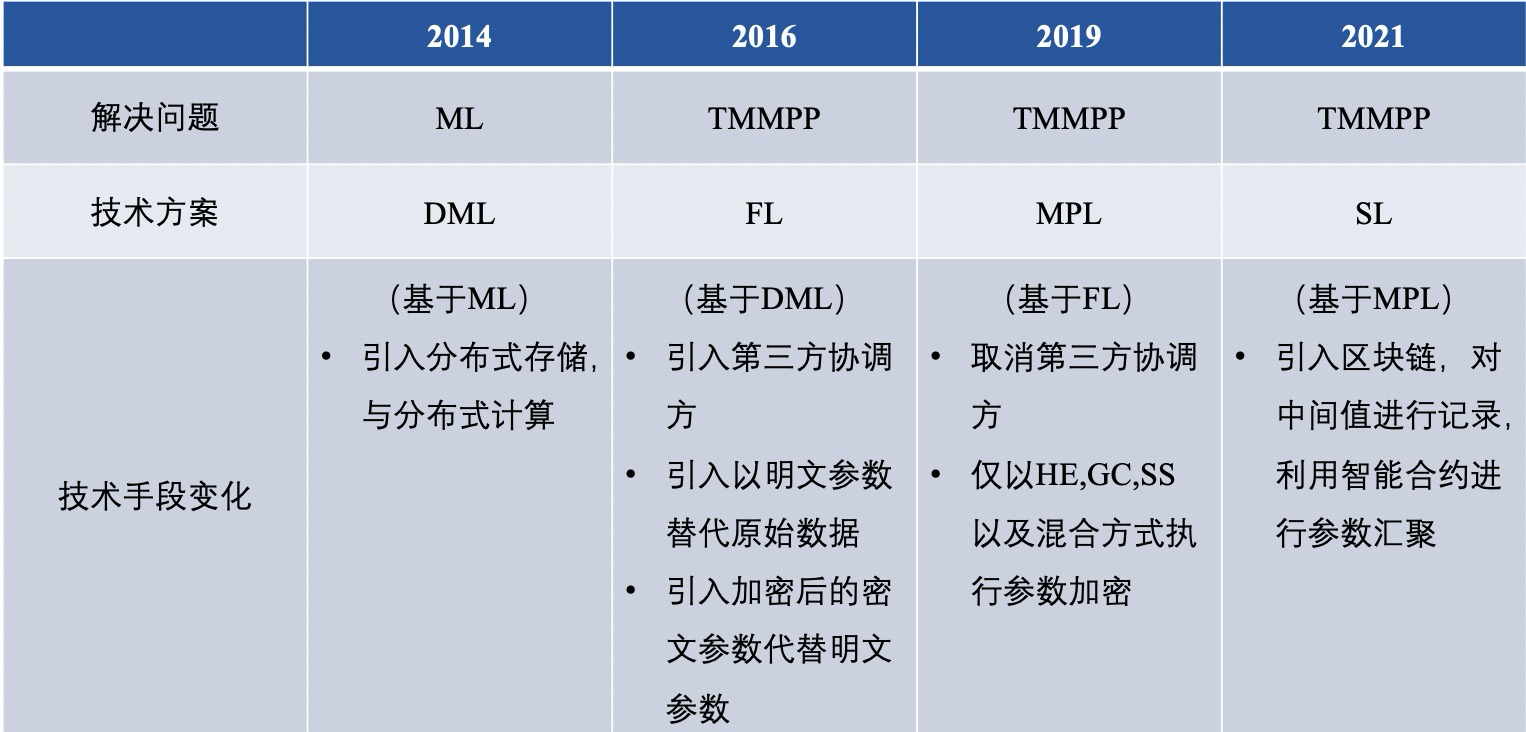
その中で、従来の FL と MPL をさらに詳しく比較し、それは次の 6 つの点に反映されます。
1) プライバシー保護
MPC フレームワークで使用される MPC プロトコルは、双方に高いセキュリティを保証します。ただし、暗号化されていない FL フレームワークでは、データ所有者とサーバーの間でモデル パラメーターが平文で交換されるため、機密情報が漏洩する可能性もあります。
2) 通信方法
MPL では、データ所有者間の通信は通常、信頼できる第三者を介さないピアツーピアの形式ですが、FL は通常、集中サーバーを使用したクライアントサーバーの形式です。言い換えれば、MPL の各データ所有者は状態において同等ですが、FL のデータ所有者と集中サーバーは同等ではありません。
3) 通信オーバーヘッド
FL の場合、データ所有者間の通信は集中サーバーによって調整できるため、特にデータ所有者の数が非常に多い場合、通信のオーバーヘッドはポイントツーポイント形式の MPL よりも小さくなります。
4) データ形式
現在、MPL のソリューションでは非 IID 設定は考慮されていません。ただし、FL のソリューションでは、各データ所有者がモデルをローカルでトレーニングするため、非 IID 設定に適応するのが簡単です。
5) 学習モデルの精度
MPL では、通常、グローバル モデルの精度が失われることはありません。しかし、FL がプライバシーを保護するために DP を利用する場合、通常、グローバル モデルはある程度の精度の低下を被ります。
6) 応用シナリオ
上記の分析と組み合わせると、MPL はより高いセキュリティと精度が必要なシナリオに適しており、FL はより高いパフォーマンス要件が必要なシナリオに適しており、より多くのデータ所有者に使用されていることがわかります。
▲ フェデレーテッド ラーニング フレームワークのマルチパーティ比較
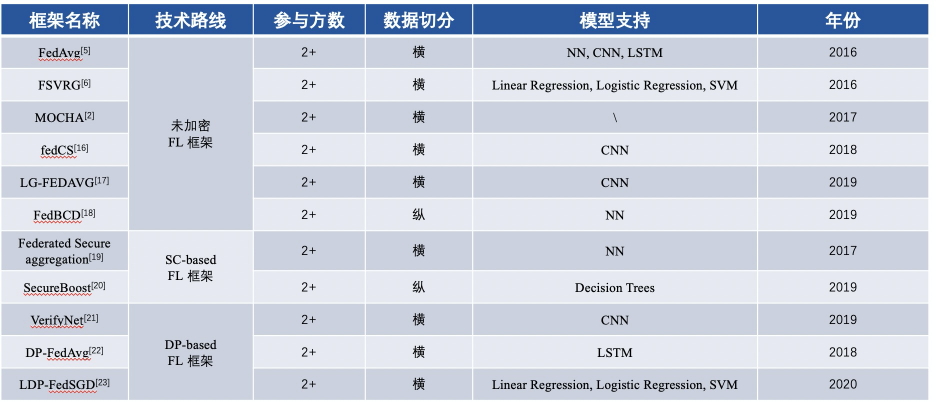
2016年以降のFL基本枠組みの内容比較
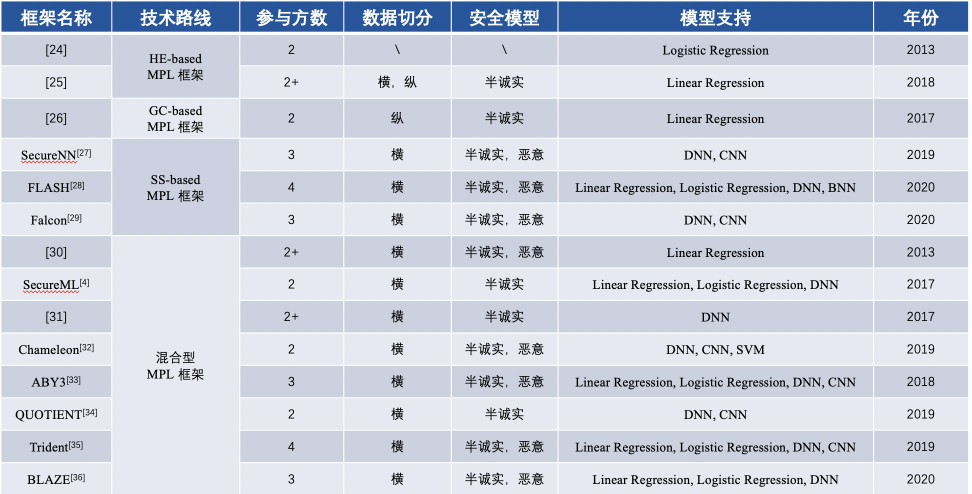
FLベースのMPL基本フレームワークの内容比較
フェデレーテッド ラーニング テクノロジーの継続的な開発により、さまざまな課題に対応するフェデレーテッド ラーニング プラットフォームが登場していますが、まだ成熟段階には達していません。現在、学界では、フェデレーテッド ラーニング プラットフォームは主に不均衡で不均一に分散されたデータの問題を解決していますが、業界ではフェデレーテッド ラーニングのセキュリティ問題を解決するための暗号プロトコルに重点が置かれています。
両者は密接に関係しており、既存の機械学習アルゴリズムの多くは連邦化されていますが、それらはまだ未熟で、運用できる段階にはまだ達していません。近年、フェデレーション ラーニング フレームワークの研究と実装はまだ初期段階にあり、継続的な努力と進歩が必要です。
著者について
ヤンヤン連邦学習の先駆者
参考文献
参考文献
[1] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[2] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[3] D. Demmler, T. Schneider, and M. Zohner, “Aby-a framework for efficient mixed-protocol secure two-party computation.” in Proceedings of The Network and Distributed System Security Symposium, 2015.
[4] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy- preserving machine learning,” in Proceedings of 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017, pp. 19–38.
[5] H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas, “Feder- ated learning of deep networks using model averaging,” CoRR, vol. abs/1602.05629, 2016.
[6] J. Konecˇny`, H. B. McMahan, D. Ramage, and P. Richta ́rik, “Federated optimization: Distributed machine learning for on-device intelligence,” arXiv preprint arXiv:1610.02527, 2016.
[7] J. Konecˇny`, H. B. McMahan, F. X. Yu, P. Richta ́rik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communica- tion efficiency,” arXiv preprint arXiv:1610.05492, 2016.
[8] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentral- ized data,” in Proceedings of Artificial Intelligence and Statistics, 2017, pp. 1273–1282.
[9] A. C.-C. Yao, “How to generate and exchange secrets,” in Proceedings of the 27th Annual Symposium on Foundations of Computer Science (sfcs 1986). IEEE, 1986, pp. 162–167.
[10] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Proceedings of Advances in Neural Information Processing Systems, 2017, pp. 4424–4434.
[11] R. Fakoor, F. Ladhak, A. Nazi, and M. Huber, “Using deep learning to enhance cancer diagnosis and classification,” in Proceedings of the international conference on machine learning, vol. 28. ACM New York, USA, 2013.
[12] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary convolutional neural networks,” in Proceedings of European conference on computer vision. Springer, 2016, pp. 525–542.
[13] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823.
[14] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[15] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[16] T.NishioandR.Yonetani,“Clientselectionforfederatedlearningwith heterogeneous resources in mobile edge,” in Proceedings of 2019 IEEE International Conference on Communications (ICC). IEEE, 2019, pp. 1–7.
[17] P. P. Liang, T. Liu, L. Ziyin, R. Salakhutdinov, and L.-P. Morency, “Think locally, act globally: Federated learning with local and global representations,” arXiv preprint arXiv:2001.01523, 2020.
[18] Y. Liu, Y. Kang, X. Zhang, L. Li, Y. Cheng, T. Chen, M. Hong, and Q. Yang, “A communication efficient vertical federated learning framework,” arXiv preprint arXiv:1912.11187, 2019.
[19] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggre- gation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191.
[20] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, and Q. Yang, “Se- cureboost: A lossless federated learning framework,” arXiv preprint arXiv:1901.08755, 2019.
[21] G. Xu, H. Li, S. Liu, K. Yang, and X. Lin, “Verifynet: Secure and verifiable federated learning,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 911–926, 2019.
[22] H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang, “Learn- ing differentially private recurrent language models,” arXiv preprint arXiv:1710.06963, 2017.
[23] Y. Zhao, J. Zhao, M. Yang, T. Wang, N. Wang, L. Lyu, D. Niyato, and K. Y. Lam, “Local differential privacy based federated learning for internet of things,” arXiv preprint arXiv:2004.08856, 2020.
[24] M. Hastings, B. Hemenway, D. Noble, and S. Zdancewic, “Sok: General purpose compilers for secure multi-party computation,” in Proceedings of 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 1220–1237.
[25] I. Giacomelli, S. Jha, M. Joye, C. D. Page, and K. Yoon, “Privacy-
preserving ridge regression with only linearly-homomorphic encryp- tion,” in Proceedings of 2018 International Conference on Applied Cryptography and Network Security. Springer, 2018, pp. 243–261.
[26] A. Gasco ́n, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, and D. Evans, “Privacy-preserving distributed linear regression on high- dimensional data,” Proceedings on Privacy Enhancing Technologies, vol. 2017, no. 4, pp. 345–364, 2017.
[27] S. Wagh, D. Gupta, and N. Chandran, “Securenn: 3-party secure computation for neural network training,” Proceedings on Privacy Enhancing Technologies, vol. 2019, no. 3, pp. 26–49, 2019.
[28] M. Byali, H. Chaudhari, A. Patra, and A. Suresh, “Flash: fast and robust framework for privacy-preserving machine learning,” Proceedings on Privacy Enhancing Technologies, vol. 2020, no. 2, pp. 459–480, 2020.
[29] S. Wagh, S. Tople, F. Benhamouda, E. Kushilevitz, P. Mittal, and T. Rabin, “Falcon: Honest-majority maliciously secure framework for private deep learning,” arXiv preprint arXiv:2004.02229, 2020.
[30] V. Nikolaenko, U. Weinsberg, S. Ioannidis, M. Joye, D. Boneh, and N. Taft, “Privacy-preserving ridge regression on hundreds of millions of records,” pp. 334–348, 2013.
[31] M. Chase, R. Gilad-Bachrach, K. Laine, K. E. Lauter, and P. Rindal, “Private collaborative neural network learning.” IACR Cryptol. ePrint Arch., vol. 2017, p. 762, 2017.
[32] M. S. Riazi, C. Weinert, O. Tkachenko, E. M. Songhori, T. Schneider, and F. Koushanfar, “Chameleon: A hybrid secure computation frame- work for machine learning applications,” in Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 2018, pp. 707–721.
[33] P. Mohassel and P. Rindal, “Aby3: A mixed protocol framework for machine learning,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018, pp. 35– 52.
[34] N. Agrawal, A. Shahin Shamsabadi, M. J. Kusner, and A. Gasco ́n, “Quotient: two-party secure neural network training and prediction,” in Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019, pp. 1231–1247.
[35] R. Rachuri and A. Suresh, “Trident: Efficient 4pc framework for pri- vacy preserving machine learning,” arXiv preprint arXiv:1912.02631, 2019.
[36] A. Patra and A. Suresh, “Blaze: Blazing fast privacy-preserving ma- chine learning,” arXiv preprint arXiv:2005.09042, 2020.
[37] Song L, Wu H, Ruan W, et al. SoK: Training machine learning models over multiple sources with privacy preservation[J]. arXiv preprint arXiv:2012.03386, 2020.


