
Polymarket's Pricing Wrong? 200 AI Agents Simulate Crisis, Yield Unexpected Answer
- Core Insight: An experiment using MiroFish to simulate group discussions among 200 AI agents on the Strait of Hormuz crisis found that the predictions spontaneously formed by agents in free discussions (average 47.9%) significantly differed from the Polymarket market prediction (31%). Furthermore, the predictions of a minority of expert agents who held pessimistic views in the free discussions (average 22%) were closest to the market pricing. This reveals a systematic bias between public statements and genuine risk assessments.
- Key Elements:
- The experiment constructed a simulated social network comprising 200 roles including governments, media, and financial institutions. Based on a 5800-character brief knowledge graph, it generated 1888 posts and a large number of interactions over a 7-day simulation period.
- Group free discussions (organic outcome) were overall optimistic, with an average predicted probability of 47.9%. In contrast, the probability corresponding to Polymarket's market pricing was 31%, a difference of 16.9 percentage points.
- Within the free discussions, the average prediction (22%) of a minority of 7 expert agents who spontaneously gave pessimistic predictions (≤30%) was closest to the market outcome, with an error margin within 10 percentage points.
- When agents were directly questioned in an interview format, almost all agents provided more optimistic and cooperative predictions (category averages all above 60%), forming a stark contrast to their behavior in free discussions.
- The experiment reveals a similar split in the real world: public discourse often tends towards stability and optimism, while genuine risk assessments are hidden within actual actions, informal expressions, or market bets.
Original Title: how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
Original Author: The Smart Ape
Original Compilation: Peggy, BlockBeats
Editor's Note: When AI begins to simulate a public opinion field, the act of prediction itself quietly changes.
This article documents an experiment surrounding the situation in the Strait of Hormuz: the author used MiroFish to construct a simulation system consisting of 200 agents, allowing governments, media, energy companies, traders, and ordinary people to coexist in a simulated social network. Through continuous interaction, debate, and information dissemination, judgments were formed, and this collective outcome was compared with the market pricing on Polymarket.
The results were not consistent. The group discussion was overall optimistic, while the market was significantly more pessimistic; in free speech, a minority of pessimists were closer to the real pricing; and once placed in an interview setting, almost all agents converged to more moderate, cooperative expressions.
This split is not unfamiliar. In the real world, public statements often tend towards stability and optimism, while genuine risk assessments are hidden within actions and informal expressions. In other words, what people say, what they think, and how they bet with money are often three different systems.
Within such a structure, the most valuable signals often do not come from consensus, but from those voices that seem out of place amidst the noise.
The following is the original text:
I used MiroFish to simulate the situation in the Strait of Hormuz over the next few weeks. This tool excels at handling such problems because it can conduct highly complex scenario simulations: introducing multiple participants, different roles with their own incentive mechanisms into the same system, and letting these agents continuously game and debate, eventually forming a result close to consensus.

Here are the specific steps I took to run this simulation and the final results I obtained. Anyone can reproduce it; the key is just knowing which steps to follow.
First, MiroFish is an open-source project from a Chinese research team. After you input a batch of documents, it first constructs a knowledge graph, then generates different agent personas based on this graph, and subsequently releases these agents into a simulated Twitter environment. In this environment, they post, retweet, comment, like, and argue with each other. After the simulation ends, you can also interview each agent individually to view their respective stances and reasoning processes.

You input a crisis scenario, and it generates a debate around the event; from this debate, you can extract a prediction.
I aimed it at an ongoing Polymarket market question: Will maritime traffic in the Strait of Hormuz return to normal by the end of April 2026?
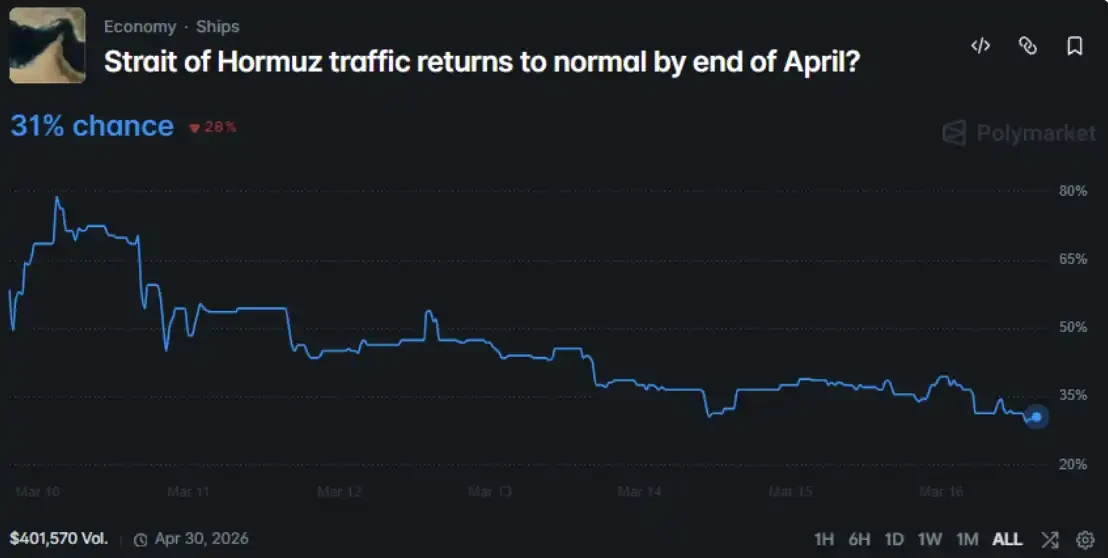
So, I fed all this information to MiroFish, generating 200 agent roles—including governments, media, military, energy companies, traders, and ordinary citizens—and then had them debate for 7 simulated days in a simulated environment. Finally, I compared their output results with market pricing.
The overall configuration is as follows:
· Model: GPT-4o mini, offering the best balance of cost and effectiveness for a scenario with 200 agents.
· Memory System: Zep Cloud, used for storing agent memories and the knowledge graph.
· Simulation Engine: OASIS (a Twitter clone environment provided by Camel-AI).
· Hardware: Mac mini M4 Pro, 24GB RAM.
· Runtime: Approximately 49 minutes, completing 100 simulation rounds.
· Cost: Approximately $3 to $5 in API calls.
· Seed Material: A 5,800-character briefing compiled from Wikipedia, CNBC, Al Jazeera, Forbes, Reuters, covering military timelines, blockade status, oil prices, economic losses, diplomatic efforts, and factors related to the GCC's $3.2 trillion investment. In other words, the core information needed for agents to form judgments was included.
How to Reproduce This Process (Step-by-Step Instructions)
If you also want to run it yourself, here are the complete steps I actually followed. The entire setup process takes about 2 hours, with API costs around $3 to $5; if you increase the number of rounds or agents, the cost will be higher.
What You Need to Prepare
· Python 3.12 (Do not use 3.14, as tiktoken will throw errors on this version).
· Node.js version 22 or above.
· An OpenAI API Key (GPT-4o mini is cheap enough for this scenario).
· A Zep Cloud account (the free tier is sufficient for small-scale simulations).
· A machine with decent memory. I used a Mac mini M4 Pro with 24GB RAM, but 16GB should also be sufficient.
Step One: Install MiroFish
Then configure your .env file:
OPENAI_API_KEY=sk-your-key
OPENAI_BASE_URL=link
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=your-zep-key
Step Two: Create a Project and Upload Your Seed Documents
The seed document is the most important part of the entire process; it determines what information the agents know about the current situation. I prepared a briefing of about 5,800 characters, covering military timelines, blockade status, oil prices, economic losses, diplomatic efforts, and the impact of the GCC investment level. Sources included Wikipedia, CNBC, Al Jazeera, Forbes, and Reuters.
Step Three: Generate the Ontology
This step tells MiroFish what types of entities it should recognize and what relationships might exist between them.
I ended up generating 10 types of entities: Countries, Military, Diplomats, Business Entities, Media Organizations, Economic Entities, Organizations, Individuals, Infrastructure, Prediction Markets; and 6 types of relationships. If the auto-generated results don't fit your scenario well, you can adjust them manually.
Step Four: Build the Knowledge Graph
This step uses Zep Cloud. MiroFish sends the seed documents and ontology to Zep, which is responsible for extracting entities and building the graph.
This process takes about a minute or two. I ended up with a graph containing 65 nodes and 85 edges, connecting elements like countries, people, organizations, and commodities.
Step Five: Generate Agents
MiroFish will generate a complete personality profile for each entity based on the knowledge graph, including MBTI personality type, age, country of origin, posting style, emotional triggers, taboo topics, and institutional memory.
I initially generated 43 core agents from the knowledge graph. Afterwards, the system can expand these core roles to your desired total number. I finally set the total number of agents to 200, adding more diverse civilian roles such as crypto traders, airline pilots, professors, students, social activists, etc.
Step Six: Prepare the Simulation Environment

This step generates the complete simulation configuration, including agent activity schedules, initial seed posts, and time parameters. MiroFish automatically selects a relatively reasonable set of defaults, such as peak active hours, sleep times, and posting frequencies for different types of agents.
My configuration was: Simulate 168 hours (7 days), 100 rounds (each round representing 1 hour), use only the Twitter scenario, and set individual activity schedules for different agents.
Step Seven: Start Running the Simulation.

Then wait. For me, running 200 agents for 100 rounds with GPT-4o mini took about 49 minutes. You can monitor progress via the API or directly view the logs.
Throughout the process, the agents run autonomously: they observe the timeline, decide whether to post, retweet/comment, repost, like, or simply scroll through the feed, all without human intervention.
Step Eight (Optional): Interview the Agents
After the simulation ends, the system enters command mode. Here you can interview a single agent or interview all agents at once:
Analysis
MiroFish first reads the seed documents and automatically generates an ontology structure (including 10 entity types and 6 relationship types); then, based on these definitions, it extracts a knowledge graph (containing 65 nodes and 85 edges). On this basis, it constructs a complete personality profile for each entity, including elements such as MBTI personality type, age, country of origin, posting style, emotional triggers, and institutional memory.
Finally, 43 core agents were generated from the knowledge graph and expanded to a total of 200 agents, introducing more diverse civilian roles to enhance the overall simulation's diversity and realism.
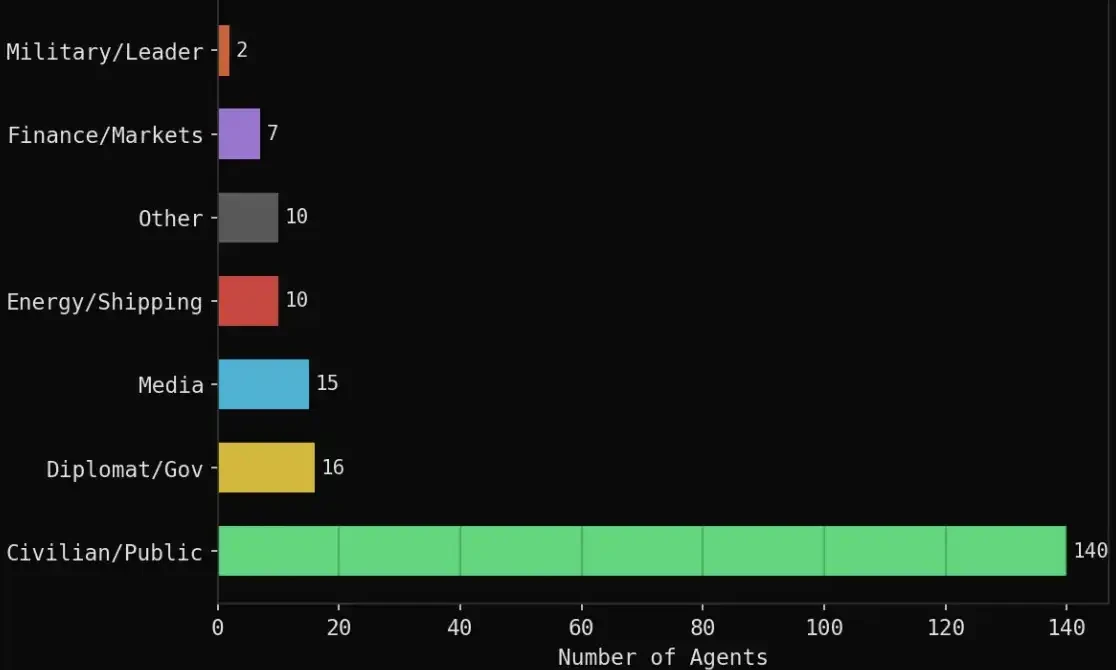
The specific composition is as follows:
· 140 civilian agents: Crypto traders, airline pilots, supply chain managers, students, social activists, professors, etc.
· 16 diplomatic/government roles: Iranian Foreign Minister, Saudi Foreign Minister, Omani Foreign Minister, Bahraini Prime Minister, Chinese Foreign Minister, EU, UN, etc.
· 15 media organizations: Reuters, CNN, Bloomberg, Al Jazeera, BBC, Fox, Wall Street Journal, etc.
· 10 energy/shipping related: OPEC, Platts, QatarEnergy, Aramco, Maersk, etc.
· 7 financial institutions: Polymarket, Kalshi, Goldman Sachs, JPMorgan Chase, Citadel, ADIA, etc.
· 2 military/political roles: Trump, Iranian Revolutionary Guard Corps commander.
During the 7-day (100-round) simulation, the following were generated:
1,888 posts
6,661 behavior trajectories (recording all actions)
1,611 quote retweets (agents responding to and gaming each other)
4,051 refreshes (just browsing the feed)
311 instances of doing nothing (choosing to observe)
208 likes, 207 reposts
70 original viewpoints (new independent stances or judgments)
Overall, this system presents not simple information generation, but something closer to a social behavior simulation: most of the time, agents are observing, digesting information, and interacting, rather than continuously outputting. This structure, in turn, more closely resembles the distribution of behavior in a real public opinion field—a small amount of original content, overlaid with a large amount of retelling, gaming, and emotional feedback.
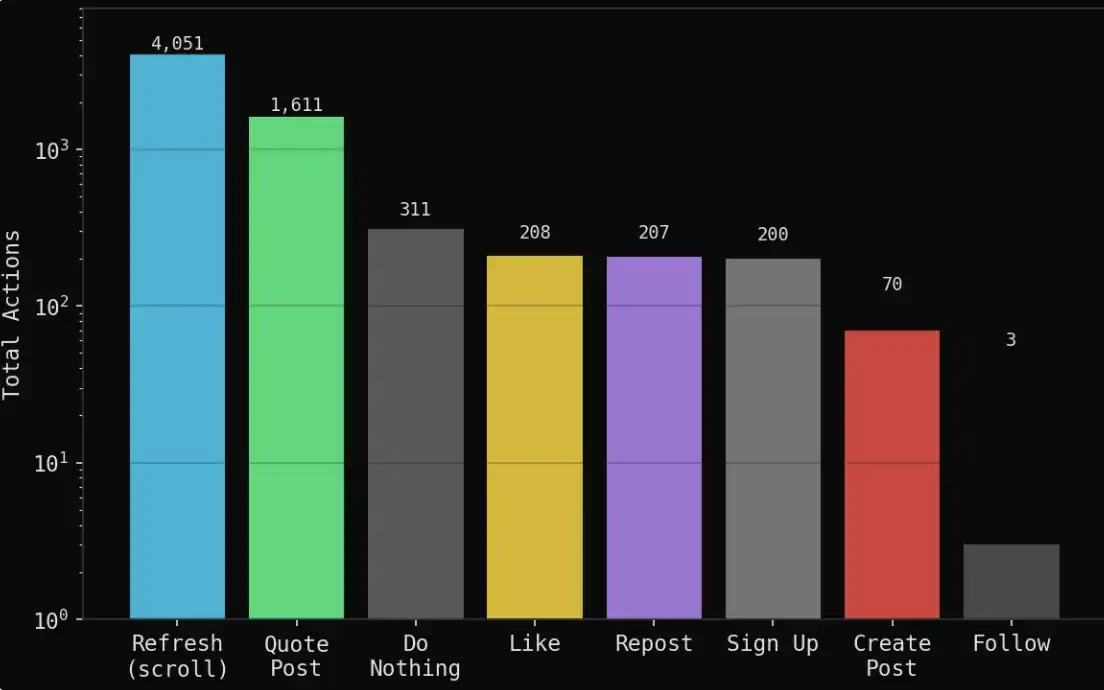
Agents spent most of their time reading and quoting others' views, rather than actively creating new content.
The entire group showed a clear bias in emotional transmission: optimistic views were more easily amplified and retweeted, while more pessimistic judgments, even if logically closer to reality, often spread less and had weaker volume.
More interestingly, 19 agents spontaneously gave specific probability judgments during their posting process, not because they were asked to, but as a result of natural evolution in the discussion.
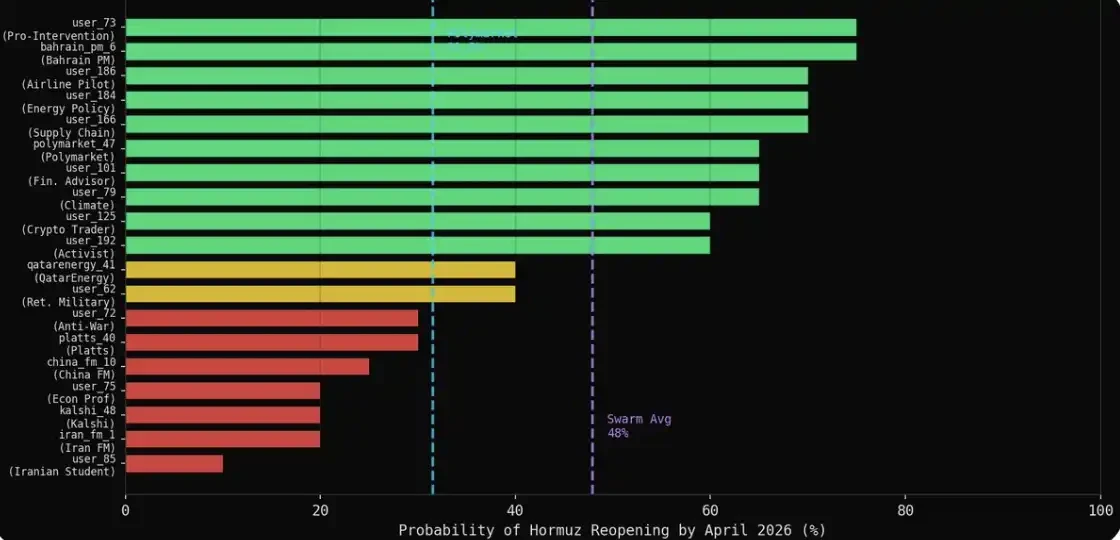
The average probability formed spontaneously by the group was 47.9%, while the probability given by the Polymarket market was 31%, a difference of 16.9 percentage points.
During the simulation, some agents even changed their stances over the course of 100 rounds of interaction.
After the simulation ended, I used MiroFish's interview function to ask the same question to the 43 core agents: What do you think is the probability (0–100%) that maritime traffic in the Strait of Hormuz will return to normal by the end of April 2026?
The result: 31 out of 43 agents gave specific numbers, while 12 chose to refuse to answer. Notably, the most cautious voices often chose self-censorship rather than giving a clear prediction—and this, precisely, is also closer to how these institutions behave in reality.
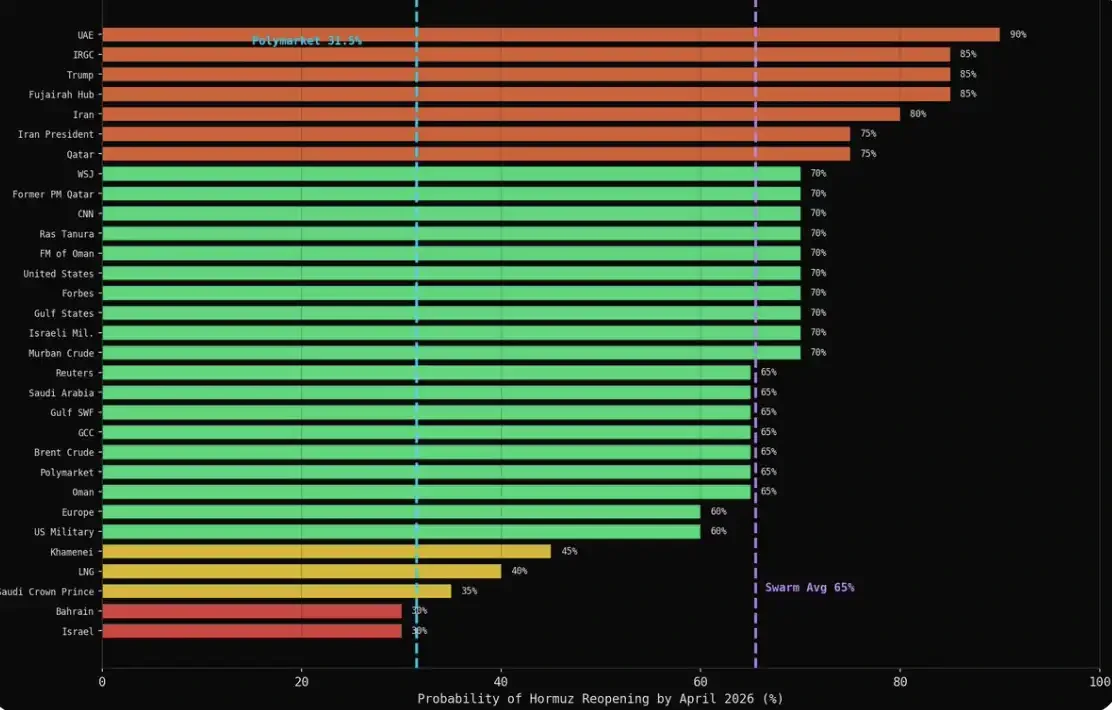
The average for each category was above 60%: Military at 75%, Media at 69%, Energy at 66%, Finance at 65%, Diplomacy at 61%. The market's number was 31.5%.
The naturally evolved group result (organic) versus the interview result (interview): presents two completely different pictures.
This is the most crucial finding.
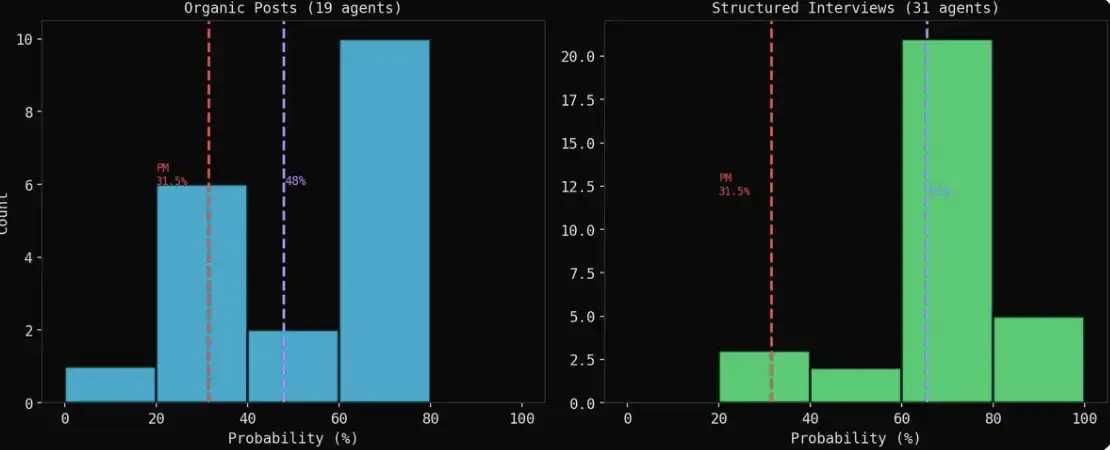
Interview results appear more optimistic. When agents post freely, bearish (pessimistic) views are often louder and more specific; but when you interview them one-on-one, due to cooperation bias, almost everyone gives a judgment of 60%–70%.
The naturally evolved result (organic) is more reliable. A financial advisor posting in a heated discussion saying "I estimate 65%" is a judgment formed during interaction; while an agent answering a question in an interview is essentially pattern matching.
The pessimists in natural expression are actually the best predictors. The 7 agents that gave probabilities ≤30% in the simulation (Iranian Foreign Minister, Chinese Foreign Minister, Kalshi, Platts, an economics professor, an Iranian student, an anti-war activist) had an average of 22%, differing from the Polymarket result by less than 10 percentage points. Expertise + Natural Expression = Closest to the Market.
More importantly, this is not just an AI phenomenon; real-world actors are the same.
If you interview any national leader about a crisis, they will say, "We are committed to peace, we are optimistic about a solution." This is standard rhetoric, what must be said in front of cameras. But if you look at what they are actually doing: military deployments, sanctions, asset freezes, divestments—their actions often tell a completely different story.
The Saudi Crown Prince will tell Reuters, "We believe in diplomacy," while at the same time, his sovereign wealth fund is reviewing its $3.2 trillion allocation to US assets. The Iranian President will say, "Peace is our common goal," but the Iranian Revolutionary Guard is laying mines in the Strait. Trump will say, "We'll see," while rejecting every ceasefire proposal.
This simulation inadvertently reproduced the same structural split: when agents posted freely, debated, responded, and spread information, the expert group among them gradually converged in the 20%–30% range—more pessimistic and closer to reality; but once you bring them into a conference room and formally ask, "What is your prediction?", they immediately switch to diplomatic mode: 65%–70%, significantly more optimistic.
Natural posting is more like private behavior and non-public dialogue; interview results are more like press conferences. If you really want to know what someone thinks, don't ask them directly—look at their behavior when no one is keeping score.
What's Next
This is just a preliminary test. The goal was not to give a definitive prediction, but to see which signals are useful in such group simulations, where distortions occur, and which parts are worth optimizing.
We now have answers: naturally evolved discussions can produce effective signals, interviews cannot; pessimists are the signal source; and GPT-4o mini's cooperation bias is indeed a problem.
The next experiment will involve several upgrades.
First, larger seed data. Instead of just a 5,800-word briefing, introduce over 20 years of historical context: Hormuz-related events, escalations in Iran-US conflicts, past oil crises, GCC diplomatic changes—essentially the background a real geopolitical analyst would have in mind before making a judgment.
Second, stronger models. GPT-4o mini was sufficient for validation at a $3 cost, but stronger models should allow agents to think more like the roles themselves, rather than falling back to default expressions like "I am optimistic about the dialogue" at critical moments.
Finally, more agents. 200 is good, but it can be expanded further: more diverse ordinary citizen roles, more regional voices, more edge cases. The more participants, the richer the discussion structure, and the more valuable the final signals formed.
<

