
YBB Capital: Preview of Potential Track - Decentralized Computing Power Market (Part 1)
Original author: Zeke, YBB Capital

Preface
Since the birth of GPT-3, generative AI has ushered in an explosive turning point in the field of artificial intelligence with its amazing performance and broad application scenarios, and technology giants have begun to gather together to jump into the AI track. But problems also arise. The training and inference of large language models (LLM) require a large amount of computing power. With the iterative upgrade of the model, the computing power requirements and costs increase exponentially. Taking GPT-2 and GPT-3 as an example, the difference in parameter amounts between GPT-2 and GPT-3 is 1166 times (GPT-2 is 150 million parameters and GPT-3 is 175 billion parameters). A training session of GPT-3 The cost was calculated based on the price model of the public GPU cloud at the time, which was up to 12 million US dollars, which was 200 times that of GPT-2. In actual use, every user question requires inference calculations. Based on the 13 million unique user visits at the beginning of this year, the corresponding chip demand is more than 30,000 A 100 GPUs. The initial investment cost would then be a staggering $800 million, with an estimated daily model inference cost of $700,000.
Insufficient computing power and high costs have become problems faced by the entire AI industry, but the same problems seem to be plaguing the blockchain industry as well. On the one hand, Bitcoin’s fourth halving and ETF adoption are imminent. As prices rise in the future, miners’ demand for computing hardware will inevitably increase significantly. Zero-knowledge proofs on the other hand ("Zero-Knowledge Proof", ZKP for short) technology is booming, and Vitalik has repeatedly emphasized that ZK’s impact on the blockchain field in the next ten years will be as important as the blockchain itself. Although the blockchain industry has high hopes for the future of this technology, ZK also consumes a lot of computing power and time in generating proofs due to its complex calculation process, just like AI.
In the foreseeable future, the shortage of computing power will become inevitable, so will the decentralized computing power market be a good business?
Decentralized computing power market definition
The decentralized computing power market is actually basically equivalent to the decentralized cloud computing track, but compared to decentralized cloud computing, I personally think this term is more appropriate to describe the new projects discussed later. The decentralized computing power market should belong to a subset of DePIN (Decentralized Physical Infrastructure Network). Its goal is to create an open computing power market that enables anyone with idle computing power resources to use token incentives. Their resources are provided on this market, mainly serving B-end users and developer groups. From the perspective of more familiar projects, such as Render Network, a decentralized GPU-based rendering solution network, and Akash Network, a distributed peer-to-peer market for cloud computing, both belong to this track.
The following will start with the basic concepts and then discuss the three emerging markets under this track: the AGI computing power market, the Bitcoin computing power market, and the AGI computing power market in the ZK hardware acceleration market. The latter two will be discussed in Potential Track Preview: Decentralized Computing Power Market (Part 2) will be discussed.
Overview of computing power
The origin of the concept of computing power can be traced back to the beginning of the invention of the computer. The original computer used a mechanical device to complete computing tasks, and computing power refers to the computing power of the mechanical device. With the development of computer technology, the concept of computing power has also evolved. Todays computing power usually refers to the collaborative work of computer hardware (CPU, GPU, FPGA, etc.) and software (operating system, compiler, application program, etc.) ability.
definition
Computing power refers to the amount of data that a computer or other computing device can process or the number of computing tasks completed within a certain period of time. Computing power is usually used to describe the performance of a computer or other computing device. It is an important indicator of the processing power of a computing device.
Metrics
Computing power can be measured in various ways, such as computing speed, computing energy consumption, computing accuracy, and parallelism. In the computer field, commonly used computing power metrics include FLOPS (floating point operations per second), IPS (instructions per second), TPS (transactions per second), etc.
FLOPS (floating-point operations per second) refers to the computers ability to process floating-point operations (mathematical operations on numbers with decimal points that require consideration of precision issues and rounding errors). It measures how much the computer can complete per second. Floating point operations. FLOPS is a measure of a computers high-performance computing capabilities and is commonly used to measure the computing capabilities of supercomputers, high-performance computing servers, graphics processing units (GPUs), etc. For example, a computer system has an FLOPS of 1 TFLOPS (one trillion floating-point operations per second), meaning it can complete 1 trillion floating-point operations per second.
IPS (Instructions Per Second) refers to the speed at which a computer processes instructions. It is a measure of how many instructions a computer can execute per second. IPS is a measure of a computers single instruction performance and is usually used to measure the performance of a central processing unit (CPU), etc. For example, a CPU with an IPS of 3 GHz (300 million instructions per second) means it can execute 300 million instructions per second.
TPS (transactions per second) refers to a computers ability to process transactions. It measures how many transactions a computer can complete per second. Typically used to measure database server performance. For example, a database server has a TPS of 1000, meaning it can handle 1000 database transactions per second.
In addition, there are some computing power indicators for specific application scenarios, such as inference speed, image processing speed, and speech recognition accuracy.
Type of computing power
GPU computing power refers to the computing power of the graphics processor (Graphics Processing Unit). Unlike the CPU (Central Processing Unit), the GPU is hardware specifically designed to process graphics data such as images and videos. It has a large number of processing units and efficient parallel computing capabilities, and can perform a large number of floating point operations simultaneously. Since GPUs were originally designed for gaming graphics processing, they typically have higher clock frequencies and greater memory bandwidth than CPUs to support complex graphics operations.
The difference between CPU and GPU
Architecture: CPU and GPU have different computing architectures. CPUs typically employ one or more cores, each of which is a general-purpose processor capable of performing a variety of different operations. The GPU has a large number of Stream Processors and Shaders, which are specially used to perform operations related to image processing;
Parallel Computing: GPUs generally have higher parallel computing capabilities. A CPU has a limited number of cores, and each core can only execute one instruction, but a GPU can have thousands of stream processors that can execute multiple instructions and operations simultaneously. Therefore, GPUs are generally better suited than CPUs to perform parallel computing tasks, such as machine learning and deep learning, which require large amounts of parallel computing;
Programming: GPU programming is more complex than CPU, requiring the use of specific programming languages (such as CUDA or OpenCL) and the use of specific programming techniques to utilize the parallel computing capabilities of the GPU. In contrast, CPU programming is simpler and general-purpose programming languages and programming tools can be used.
The importance of computing power
In the era of the Industrial Revolution, oil was the blood of the world and penetrated into every industry. Computing power is in the blockchain, and in the coming AI era, computing power will be the “digital oil” of the world. From major companies frantic grabs for AI chips and Nvidias stock exceeding one trillion, to the United States recent blockade of high-end chips from China, the details include computing power, chip area, and even plans to ban the GPU cloud. Its importance is self-evident. , computing power will be a commodity in the next era.

An overview of artificial general intelligence
Artificial Intelligence (Artificial Intelligence) is a new technical science that studies and develops theories, methods, technologies and application systems for simulating, extending and expanding human intelligence. It originated in the 1950s and 1960s. After more than half a century of evolution, it has experienced the intertwined development of three waves of symbolism, connectionism and behavioral subjects. Now, as an emerging general technology, it is promoting society. Great changes in life and all walks of life. A more specific definition of common generative AI at this stage is: Artificial General Intelligence (AGI), an artificial intelligence system with a wide range of understanding capabilities that can perform well in a variety of different tasks and fields. Human-like or superior intelligence. AGI basically requires three elements, deep learning (DL), big data, and large-scale computing power.
deep learning
Deep learning is a subfield of machine learning (ML), and deep learning algorithms are neural networks modeled after the human brain. For example, the human brain contains millions of interconnected neurons that work together to learn and process information. Likewise, deep learning neural networks (or artificial neural networks) are composed of multiple layers of artificial neurons working together inside a computer. Artificial neurons are software modules called nodes that use mathematical calculations to process data. Artificial neural networks are deep learning algorithms that use these nodes to solve complex problems.
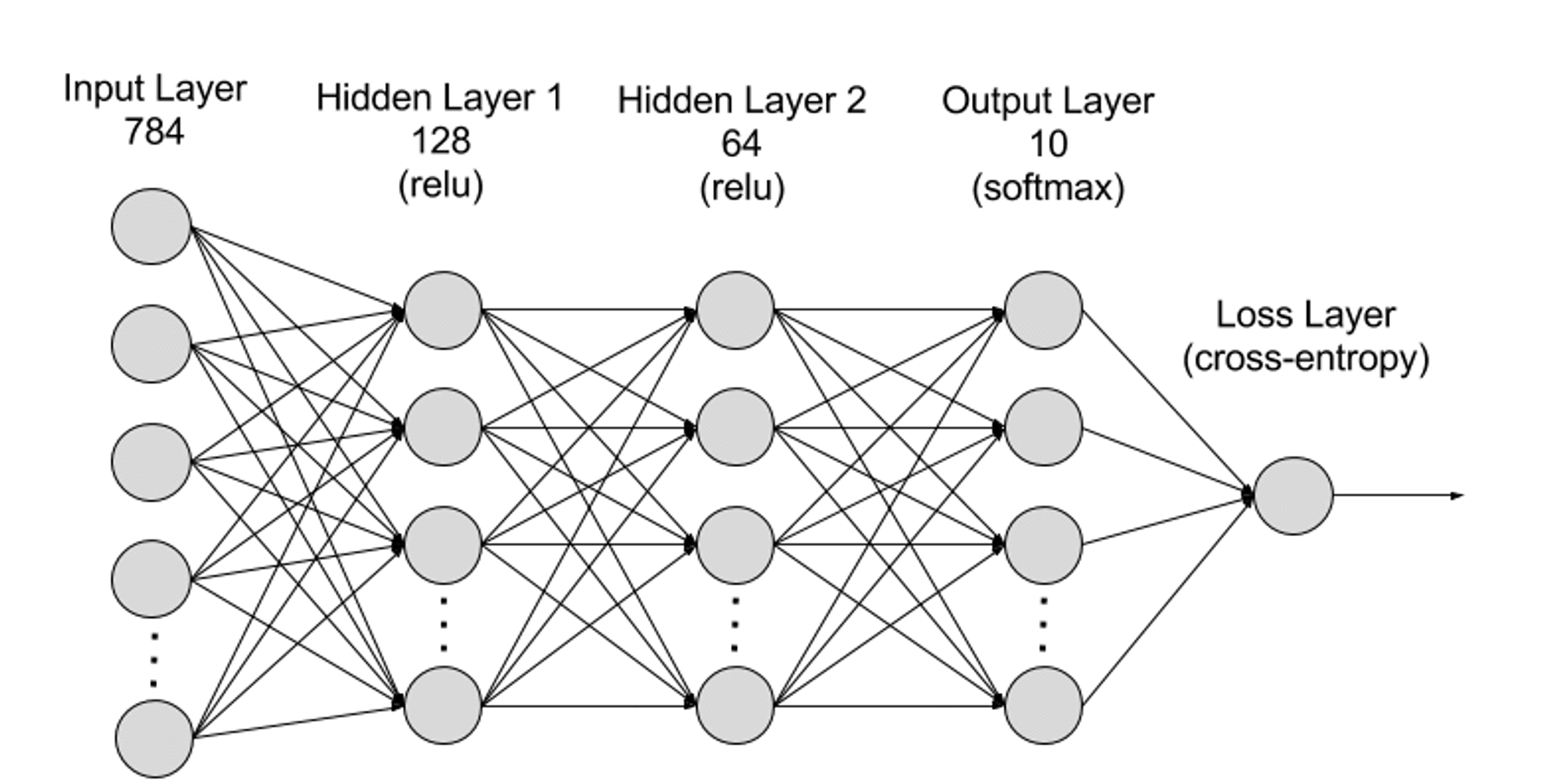
Neural networks can be divided into input layer, hidden layer and output layer from a hierarchical level, and the parameters are connected between different layers.
Input Layer: The input layer is the first layer of the neural network and is responsible for receiving external input data. Each neuron in the input layer corresponds to a feature of the input data. For example, when processing image data, each neuron may correspond to a pixel value in the image;
Hidden Layers: The input layer processes data and passes it to further layers in the neural network. These hidden layers process information at different levels, adjusting their behavior as they receive new information. Deep learning networks have hundreds of hidden layers and can be used to analyze problems from many different perspectives. For example, if you are given an image of an unknown animal that you must classify, you can compare it to animals you already know. For example, you can tell what kind of animal it is by the shape of its ears, the number of legs, and the size of its pupils. Hidden layers in deep neural networks work in the same way. If a deep learning algorithm is trying to classify an image of an animal, each of its hidden layers will process a different feature of the animal and try to classify it accurately;
Output Layer: The output layer is the last layer of the neural network and is responsible for generating the output of the network. Each neuron in the output layer represents a possible output category or value. For example, in a classification problem, each output layer neuron may correspond to a category, while in a regression problem, the output layer may have only one neuron whose value represents the prediction result;
Parameters: In neural networks, the connections between different layers are represented by weights and biases parameters, which are optimized during the training process to enable the network to accurately identify patterns in the data and make predictions. The increase in parameters can improve the model capacity of the neural network, that is, the models ability to learn and represent complex patterns in the data. But correspondingly, the increase in parameters will increase the demand for computing power.
Big Data
In order to be effectively trained, neural networks usually require large amounts of diverse and high-quality data from multiple sources. It is the basis for machine learning model training and validation. By analyzing big data, machine learning models can learn patterns and relationships in the data to make predictions or classifications.
Large scale computing power
The multi-layer complex structure of the neural network, a large number of parameters, big data processing requirements, and iterative training methods (in the training phase, the model needs to be iterated repeatedly, and the forward propagation and back propagation need to be calculated for each layer during the training process, including the activation function calculation, loss function calculation, gradient calculation and weight update), high-precision computing requirements, parallel computing capabilities, optimization and regularization techniques, and model evaluation and verification processes have collectively led to the need for high computing power. With deep learning With the advancement of AGI, the requirements for large-scale computing power are increasing by about 10 times every year. The latest model so far, GPT-4, contains 1.8 trillion parameters, a single training cost of more than 60 million US dollars, and required computing power of 2.15 e 25 FLOPS (21500 trillion floating point calculations). The demand for computing power for subsequent model training is still expanding, and new models are also being added.
AI Computational Economics
future market size
According to the most authoritative calculations, the 2022-2023 Global Computing Power Index Assessment Report jointly compiled by IDC (International Data Corporation), Inspur Information and Tsinghua University Global Industry Research Institute, the global AI computing market size will increase from 2022 to 2022. From US$19.50 billion to US$34.66 billion in 2026, the generative AI computing market will grow from US$820 million in 2022 to US$10.99 billion in 2026. Generative AI computing will grow from 4.2% to 31.7% of the overall AI computing market.
Computing power economic monopoly
The production of AI GPUs has been exclusively monopolized by NVIDA and is extremely expensive (the latest H 100 has been sold for US$40,000 per chip), and the GPUs were snapped up by Silicon Valley giants as soon as they were released, and some of these devices are used in their own products. Training of new models. The other part is rented to AI developers through cloud platforms. Cloud computing platforms such as Google, Amazon and Microsoft have a large number of computing resources such as servers, GPUs and TPUs. Computing power has become a new resource monopolized by giants. A large number of AI-related developers cannot even purchase a dedicated GPU without a price increase. In order to use the latest equipment, developers have to rent AWS or Microsoft cloud servers. Judging from the financial report, this business has extremely high profits. AWSs cloud service has a gross profit margin of 61%, while Microsofts gross profit margin is even higher at 72%.

So do we have to accept this centralized authority and control and pay a 72% profit fee for computing resources? Will the giants who monopolize Web2 still monopolize the next era?
The problem of decentralized AGI computing power
When it comes to antitrust, decentralization is usually the optimal solution. Judging from existing projects, can we achieve the large-scale computing power required for AI through storage projects in DePIN plus idle GPU utilization protocols such as RDNR? The answer is no. The road to slaying the dragon is not that simple. Early projects were not specifically designed for AGI computing power and were not feasible. At least the following five challenges need to be faced to add computing power to the chain:
1. Work verification: To build a truly trustless computing network and provide economic incentives for participants, the network must have a way to verify whether the deep learning computing work is actually performed. The core of this problem is the state dependence of deep learning models; in deep learning models, the input of each layer depends on the output of the previous layer. This means that you cannot just validate a certain layer in a model without taking into account all the layers before it. The calculation of each layer is based on the results of all previous layers. Therefore, in order to verify the work done at a specific point (such as a specific layer), all work from the beginning of the model to that specific point must be performed;
2. Market: As an emerging market, the AI computing power market is subject to supply and demand dilemmas, such as the cold start problem. Supply and demand liquidity need to be roughly matched from the beginning so that the market can grow successfully. In order to capture the potential supply of computing power, participants must be provided with clear incentives in exchange for their computing power resources. The market needs a mechanism to track completed computing work and pay providers accordingly in a timely manner. In traditional marketplaces, intermediaries handle tasks such as management and onboarding, while reducing operating costs by setting minimum payment amounts. However, this approach is more costly when expanding the market size. Only a small portion of the supply can be economically efficiently captured, leading to a threshold equilibrium state in which the market can only capture and maintain a limited supply without being able to grow further;
3. Halting problem: The halting problem is a fundamental problem in computing theory, which involves determining whether a given computing task will be completed within a limited time or never stop. This problem is unsolvable, meaning that there is no universal algorithm that can predict for all computing tasks whether they will stop within a finite time. For example, smart contract execution on Ethereum also faces similar downtime issues. That is, it is impossible to determine in advance how much computing resources the execution of a smart contract will require, or whether it will be completed within a reasonable time;
(In the context of deep learning, this problem will be more complex, as models and frameworks will switch from static graph construction to dynamic construction and execution.)
4. Privacy: Privacy-aware design and development is a must for project parties. Although a large amount of machine learning research can be conducted on public datasets, in order to improve the performance of the model and adapt to specific applications, the model usually needs to be fine-tuned on proprietary user data. This fine-tuning process may involve the processing of personal data, so privacy protection requirements need to be considered;
5. Parallelization: This is a key factor that makes the current project unfeasible. Deep learning models are usually trained in parallel on large hardware clusters with proprietary architecture and extremely low latency, and GPUs in distributed computing networks need to be Frequent data exchange will introduce latency and will be limited by the lowest performance GPU. When the computing power source is untrustworthy and unreliable, how to achieve heterogeneous parallelization is a problem that must be solved. The current feasible method is to achieve parallelization through the Transformer Model, such as Switch Transformers, which are now highly parallel. characteristics.
Solution: Although the current attempts to decentralize the AGI computing power market are still in the early stages, there are exactly two projects that have initially solved the consensus design of the decentralized network and the implementation of the decentralized computing power network in model training and inference. process. The following will use Gensyn and Together as examples to analyze the design methods and problems of the decentralized AGI computing power market.
Gensyn

Gensyn is an AGI computing power market that is still in the construction stage and aims to solve the various challenges of decentralized deep learning computing and reduce the current cost of deep learning. Gensyn is essentially a first-layer proof-of-stake protocol based on the Polkadot network, which directly rewards solvers (Solver) through smart contracts in exchange for their idle GPU devices for computing and performing machine learning tasks.
So back to the above question, the core of building a truly trustless computing network lies in verifying the completed machine learning work. This is a highly complex problem that requires finding a balance between the intersection of complexity theory, game theory, cryptography, and optimization.
Gensyn proposes a simple solution for solvers to submit the results of machine learning tasks they have completed. To verify that these results are accurate, another independent verifier attempts to re-perform the same work. This approach can be called single replication because only one validator performs the re-execution. This means there is only one additional effort to verify the accuracy of the original work. However, if the person validating the work is not the requester of the original work, then trust issues remain. Because the verifiers themselves may not be honest, and their work needs to be verified. This leads to a potential problem where if the person validating the work is not the requester of the original work, then another validator will be needed to validate their work. But it’s also possible that this new validator isn’t trusted, so another validator is needed to verify their work, which could go on forever, creating an infinite replication chain. Here we need to introduce three key concepts and interweave them to build a participant system with four roles to solve the infinite chain problem.
Probabilistic learning proofs: Use metadata of gradient-based optimization processes to build certificates of work done. By replicating certain stages, these certificates can be quickly verified to ensure that the work has been completed as expected.
Graph-based precise localization protocol: Using multi-granularity, graph-based precise localization protocols, and consistent execution of cross-evaluators. This allows validation efforts to be rerun and compared to ensure consistency and ultimately confirmed by the blockchain itself.
Truebit style incentive game: Use staking and slashing to build an incentive game that ensures every financially reasonable participant will act honestly and perform their intended tasks.
The participant system consists of submitters, solvers, verifiers, and reporters.
Submitters:
Submitters are end users of the system who provide tasks to be computed and pay for units of work completed;
Solvers:
The solver is the main worker of the system, performing model training and generating proofs that are checked by the verifier;
Verifiers:
The verifier is key to linking the non-deterministic training process with deterministic linear computation, replicating part of the solvers proof and comparing distances to expected thresholds;
Whistleblowers:
Whistleblowers are the last line of defense, checking the work of validators and issuing challenges in hopes of receiving generous bounty payments.
System operation
The operation of the gaming system designed by the protocol will include eight stages, covering four main participant roles, to complete the complete process from task submission to final verification.
1. Task Submission: A task consists of three specific pieces of information:
Metadata describing the task and hyperparameters;
a model binary (or base schema);
Publicly accessible, pre-processed training data.
2. To submit a task, the submitter specifies the details of the task in a machine-readable format and submits them to the chain along with the model binary (or machine-readable schema) and a publicly accessible location of the preprocessed training data. Public data can be stored in simple object storage such as AWS S3, or in a decentralized storage such as IPFS, Arweave or Subspace.
3. Profiling: The profiling process determines a baseline distance threshold for proof of learning verification. Validators will periodically crawl analysis tasks and generate mutation thresholds for proof-of-learning comparisons. To generate the threshold, the verifier will deterministically run and rerun part of the training, using different random seeds, and generate and check its own proofs. During this process, the verifier will establish an overall expected distance threshold for non-deterministic work that can be used as a verification solution.
4. Training: After analysis, tasks enter a public task pool (similar to Ethereum’s Mempool). Select a solver to perform the task and remove the task from the task pool. The solver performs tasks based on the metadata submitted by the submitter and the model and training data provided. When performing training tasks, the solver also generates proofs of learning by periodically checkpointing and storing metadata from the training process, including parameters, so that the verifier replicates the following optimization steps as accurately as possible.
5. Proof generation: The solver periodically stores model weights or updates and the corresponding index to the training data set to identify the samples used to generate the weight updates. Checkpoint frequency can be adjusted to provide stronger guarantees or to save storage space. Proofs can be stacked, meaning that the proofs can start from a random distribution used to initialize the weights, or from pretrained weights generated using their own proofs. This enables the protocol to build a set of proven, pre-trained base models (i.e., base models) that can be fine-tuned for more specific tasks.
6. Verification of proof: After the task is completed, the solver registers the task completion with the chain and displays its learning proof in a publicly accessible location for verifiers to access. The verifier draws verification tasks from a public task pool and performs computational work to rerun parts of the proof and perform distance calculations. The resulting distance is then used by the chain (along with the threshold calculated during the analysis phase) to determine whether the verification matches the proof.
7. Graph-based pinpoint challenge: After verifying the learning proof, the whistleblower can copy the verifier’s work to check whether the verification work itself was performed correctly. If a whistleblower believes that validation has been performed incorrectly (maliciously or not), they can challenge it to contract arbitration to receive a reward. This reward can come from solver and validator deposits (in the case of a true positive), or from the lottery prize pool (in the case of a false positive), with arbitration performed using the chain itself. Whistleblowers (in their case, verifiers) will verify and subsequently challenge work only if they expect to receive appropriate compensation. In practice, this means that whistleblowers are expected to join and leave the network based on the number of other active whistleblowers (i.e., with live deposits and challenges). Therefore, the expected default strategy for any whistleblower is to join the network when the number of other whistleblowers is low, post a deposit, randomly select an active task, and begin their verification process. After the first task ends, they will grab another random active task and repeat until the number of whistleblowers exceeds their determined payout threshold, and then they will leave the network (or, more likely, switch to the network depending on their hardware capabilities perform another role - verifier or solver) until the situation is reversed again.
8. Contract arbitration: When a validator is challenged by a whistleblower, they will enter a process with the chain to find out the location of the disputed operation or input, and ultimately the chain will perform the final basic operation and determine whether the challenge is rational. To keep whistleblowers honest and to overcome the validator dilemma, periodic forced errors and jackpot payouts are introduced here.
9. Settlement: During the settlement process, participants are paid based on the conclusions of probability and certainty checks. Different scenarios will have different payments based on the results of previous verifications and challenges. If the work is deemed to have been performed correctly and all checks passed, solution providers and verifiers are rewarded based on the actions performed.
Project brief review
Gensyn has designed a wonderful game system on the verification layer and incentive layer. By finding the divergence points in the network, it can quickly locate the error, but there are still many details missing in the current system. For example, how to set parameters to ensure that rewards and punishments are reasonable without setting the threshold too high? Have you considered the extreme situations and the different computing power of the solvers in the game? There is no detailed description of heterogeneous parallel operation in the current version of the white paper. At present, Gensyn still has a long way to go.
Together.ai
Together is an open source company that focuses on large models and is committed to decentralized AI computing power solutions. We hope that anyone, anywhere can access and use AI. Strictly speaking, Together is not a blockchain project, but the project has initially solved the delay problem in the decentralized AGI computing network. Therefore, the following article only analyzes Together’s solutions and does not evaluate the project.
How to achieve training and inference of large models when decentralized networks are 100 times slower than data centers?
Let us imagine what the distribution of GPU devices participating in the network would look like in a decentralized situation? These devices will be distributed in different continents and cities, and the devices will need to be connected, and the latency and bandwidth of the connections will vary. As shown in the figure below, a distributed situation is simulated. The devices are distributed in North America, Europe and Asia, and the bandwidth and delay between the devices are different. So what needs to be done to connect it in series?
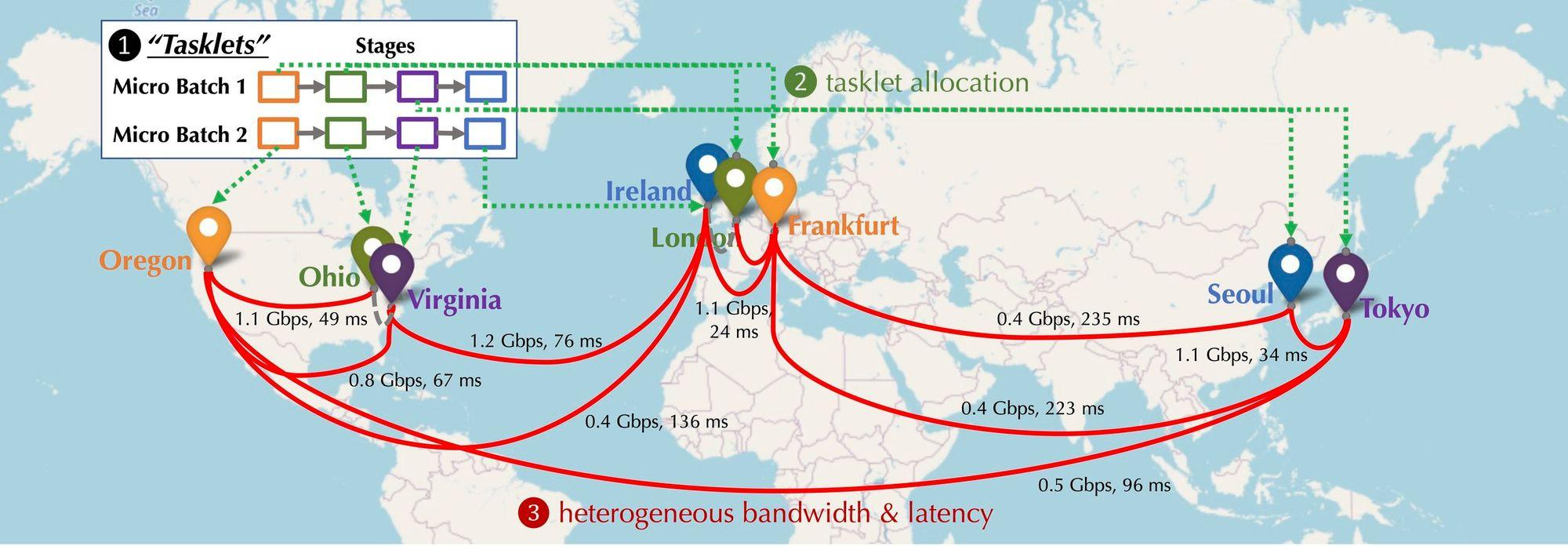
Distributed training computing modeling:The figure below shows the basic model training on multiple devices. From the communication type, there are three communication types: forward activation (Forward Activation), reverse gradient (Backward Gradient), and horizontal communication.
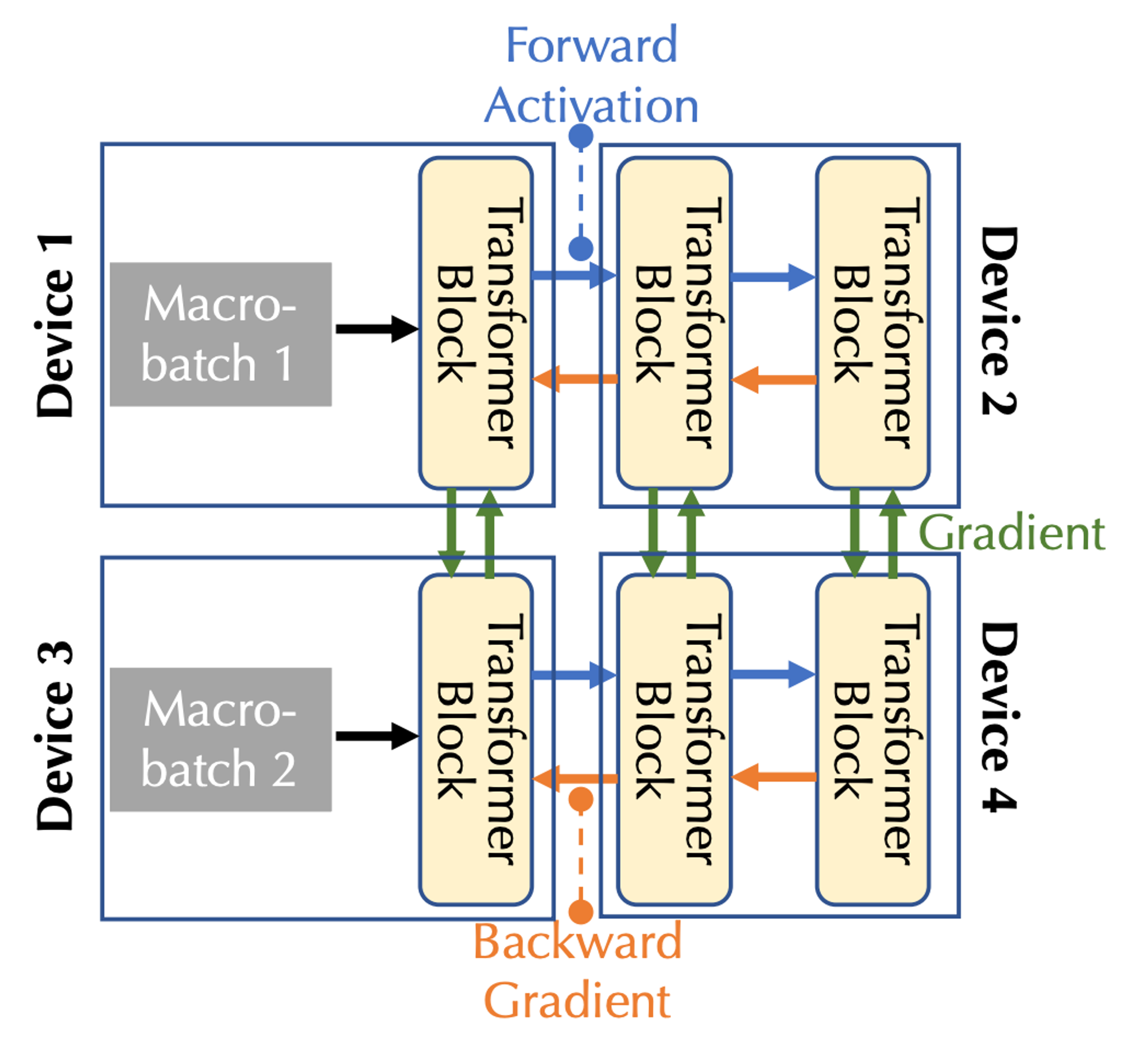
Combining communication bandwidth and latency, two forms of parallelism need to be considered: pipeline parallelism and data parallelism, corresponding to the three types of communication in the multi-device case:
In pipeline parallelism, all layers of the model are divided into stages, where each device processes one stage, which is a continuous sequence of layers, such as multiple Transformer blocks; in forward pass, activations are passed to the next stage, whereas in backward pass, the activation gradient is passed to the previous stage.
In data parallelism, devices independently compute gradients for different micro-batches but require communication to synchronize these gradients.
Scheduling optimization:
In a decentralized environment, the training process is often communication-constrained. Scheduling algorithms generally assign tasks that require a large amount of communication to devices with faster connections. Considering the dependencies between tasks and the heterogeneity of the network, the cost of a specific scheduling strategy needs to be modeled first. In order to capture the complex communication cost of training the base model, Together proposed a novel formula and decomposed the cost model into two levels through graph theory:
Graph theory is a branch of mathematics that mainly studies the properties and structure of graphs (networks). A graph consists of vertices (nodes) and edges (lines connecting nodes). The main purpose of graph theory is to study various properties of graphs, such as the connectivity of graphs, the color of graphs, and the properties of paths and cycles in graphs.
The first level is a balanced graph partitioning (partitioning the set of vertices of the graph into several equally or approximately equal-sized subsets while minimizing the number of edges between subsets. In this partitioning, each subset represents a partition, and reduce the communication cost by minimizing the edges between partitions) problem, corresponding to the communication cost of data parallelism.
The second level is a joint graph matching and traveling salesman problem (joint graph matching and traveling salesman problem is a combinatorial optimization problem that combines elements of graph matching and traveling salesman problem. The graph matching problem is to find a matching in the graph such that Some kind of cost minimization or maximization. And the traveling salesman problem is to find a shortest path that visits all nodes in the graph), corresponding to the communication cost of pipeline parallelism.
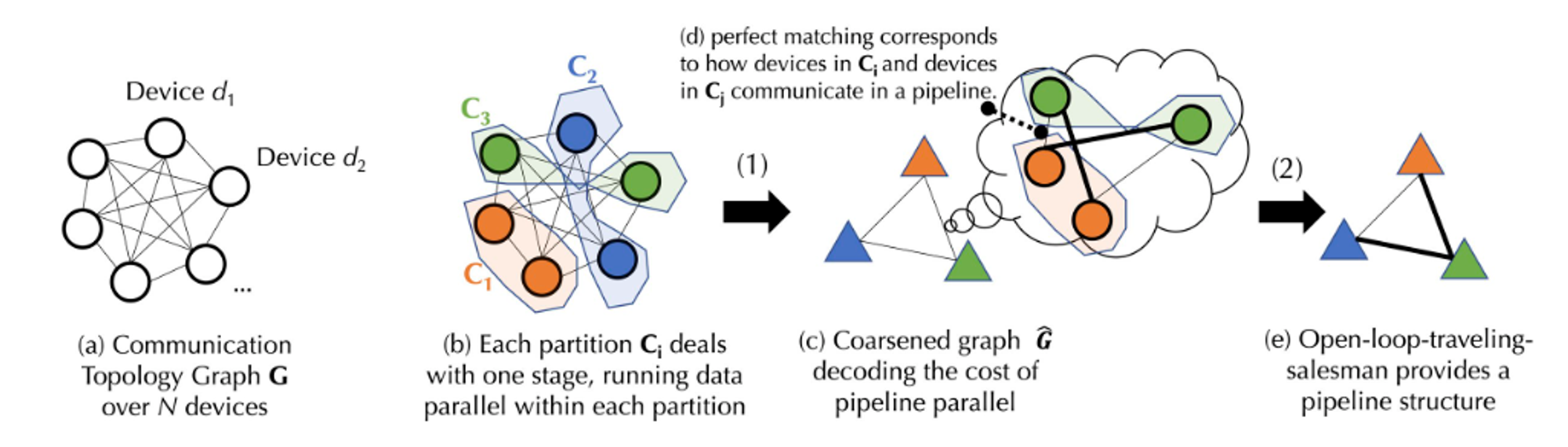 The above picture is a schematic process diagram, because the actual implementation process involves some complex calculation formulas. In order to facilitate understanding, the process in the figure will be explained in a simpler way below. For the detailed implementation process, you can consult the documents on the Together official website.
The above picture is a schematic process diagram, because the actual implementation process involves some complex calculation formulas. In order to facilitate understanding, the process in the figure will be explained in a simpler way below. For the detailed implementation process, you can consult the documents on the Together official website.
Suppose there is a device set D containing N devices, communication between which has uncertain latency (A matrix) and bandwidth (B matrix). Based on the device set D, we first generate a balanced graph partition. The number of devices in each partition or device group is approximately equal, and they all handle the same pipeline stages. This ensures that when data is parallelized, each device group performs a similar amount of work. (Data parallelism refers to multiple devices performing the same task, while pipeline stages refer to devices executing different task steps in a specific order). Based on the latency and bandwidth of the communication, a formula can be used to calculate the cost of transmitting data between groups of devices. Each balanced device group is merged, producing a fully connected rough graph, where each node represents a stage of the pipeline and the edges represent the communication cost between two stages. To minimize communication costs, a matching algorithm is used to determine which groups of devices should work together.
For further optimization, this problem can also be modeled as an open-loop traveling salesman problem (open-loop means that there is no need to return to the starting point of the path) to find an optimal path to transmit data between all devices. Finally, Together uses their innovative scheduling algorithm to find the optimal allocation strategy for a given cost model, thereby minimizing communication costs and maximizing training throughput. According to actual measurements, even if the network is 100 times slower under this scheduling optimization, the end-to-end training throughput is only about 1.7 to 2.3 times slower.
Communication compression optimization:
For the optimization of communication compression, Together introduced the AQ-SGD algorithm (for detailed calculation process, please refer to the paper Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees). The AQ-SGD algorithm is to solve the problem of pipeline parallelism on low-speed networks. A novel active compression technology designed to solve the communication efficiency problem of training. Different from previous methods that directly compress activity values, AQ-SGD focuses on compressing the changes in activity values of the same training sample in different periods. This unique method introduces an interesting self-executing dynamic. As the training stabilizes, The algorithms performance is expected to gradually improve. The AQ-SGD algorithm has undergone rigorous theoretical analysis and proved to have a good convergence rate under certain technical conditions and a quantized function with bounded errors. Not only can this algorithm be implemented efficiently, but it also adds no additional end-to-end runtime overhead, although it requires utilizing more memory and SSD to store liveness values. Validated through extensive experiments on sequence classification and language modeling datasets, AQ-SGD can compress activity values to 2-4 bits without sacrificing convergence performance. In addition, AQ-SGD can also be integrated with state-of-the-art gradient compression algorithms to achieve end-to-end communication compression, that is, all data exchanges between machines, including model gradients, forward activity values, and reverse gradients, are compressed into low accuracy, thus greatly improving the communication efficiency of distributed training. Compared with the end-to-end training performance without compression on a centralized computing network (such as 10 Gbps), it is currently only 31% slower. Combined with the data on scheduling optimization, although there is still a certain gap between the centralized computing power network and the centralized computing power network, the hope of catching up in the future is relatively high.
Conclusion
In the dividend period brought by the AI wave, the AGI computing power market is undoubtedly the market with the greatest potential and the most demand among many computing power markets. However, development difficulty, hardware requirements, and financial requirements are also the highest. Judging from the situation of the above two projects, there is still a certain distance before the AGI computing power market can be implemented. A truly decentralized network is much more complicated than the ideal situation. It is obviously not enough to compete with the cloud giants at present. While writing this article, I also observed that some small-scale projects in their infancy (PPT stage) have begun to explore some new entry points, such as focusing on the less difficult inference stage or small models. In terms of training, these are more practical attempts.
It is still unclear how the AGI computing power market will eventually be realized. Although it faces many challenges, in the long run, the decentralization and permissionless significance of AGI computing power is important, and the rights of reasoning and training should not be concentrated. to a few centralized giants. Because mankind does not need a new religion or a new pope, let alone paying expensive dues.
references
1.Gensyn Litepaper:https://docs.gensyn.ai/litepaper/
2.NeurIPS 2022: Overcoming Communication Bottlenecks for Decentralized Training :https://together.ai/blog/neurips-2022-overcoming-communication-bottlenecks-for-decentralized-training-12
3.Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees:https://arxiv.org/abs/2206.01299
4.The Machine Learning Compute Protocol and our future:https://mirror.xyz/gensyn.eth/_K2v2uuFZdNnsHxVL3Bjrs4GORu3COCMJZJi7_MxByo
5.Microsoft:Earnings Release FY 23 Q2:https://www.microsoft.com/en-us/Investor/earnings/FY-2023-Q2/performance
6. Competing for AI admission tickets: BAT, Byte and Meituan compete for GPU:https://m.huxiu.com/article/1676290.html
7.IDC: 2022-2023 Global Computing Power Index Assessment Report:https://www.tsinghua.edu.cn/info/1175/105480.htm
8. Guosheng Securities large model training estimation:https://www.fxbaogao.com/detail/3565665
9. Wings of Information: What is the relationship between computing power and AI? :https://zhuanlan.zhihu.com/p/627645270


