
Ethereum's road to expansion: which solution is the future?
Research Institution: Seer Labs
foreword

foreword
Whether you are an expert in blockchain technology or not, as long as you stay in the Crypto world long enough. The words Ethereum expansion, layer2, and Rollup are familiar to you. Many people are familiar with one or more of these concepts, but how are they related? Why do we need these technologies? What kind of problem are they trying to solve?
If you want to know the answers to the above questions, I hope this article will help you:
text
text
sinceCryotoKittySince the day when the congestion on the Ethereum chain was caused, Ethereum developers have been constantly exploring solutions to improve the throughput of Ethereum.
In principle, it can be divided into two categories:
(1) It is to transform the Ethereum block itself. Let us call it the Layer1 solution. The main solution here is sharding.
(2) It is to change the way we use Ethereum, and place the execution and processing of transactions off-chain. Ethereum itself is only used to verify the validity of its transactions and provide security. This is what we often hear about Layer2.
The core idea of Layer2 is to execute and calculate a large number of actual transactions off-chain, and then verify the final validity of the transaction through a very small number of transactions on Ethereum. Whether it is State Channel, Plasma or Rollup, they all follow this principle.
secondary title
1. Status channel
The following is the most primitive structure of a state channel:
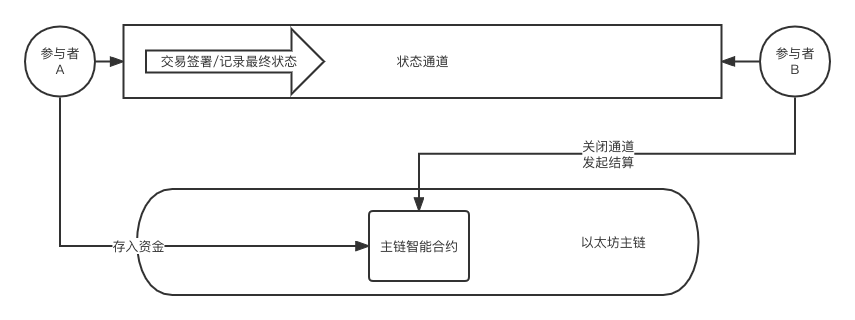
State channels are a blockchain scaling solution that has existed for a long time, and its most famous application is Bitcoin's Lightning Network.
Compared to describing his principle,An example can better explain what a state channel is:
You like the barber shop downstairs very much. Every time you go to the barber shop, Mr. Tony will always ask you to apply for a card in your ear.
One day you finally decide, just apply for the card, anyway, I will come in the future. So you transfer 1,000 yuan to the barber shop to get a card.
Every time you go for a haircut in the future, you don't need to transfer money to the barber shop. Instead, the balance in your card will be deducted. At the same time, you have completed an actual transaction with the barber shop every time you get a haircut.
After a month, you are going to move, but the money in your card has not been used up. So you apply to the barber shop to return the card, and Mr. Tony in the barber shop refunds you 200 yuan.
During this month, you spent more than a dozen times at the barber shop, but you and the barber shop actually only transferred money to each other twice.
Putting this process on the blockchain, the process of buying a card is actually depositing money into a smart contract, and at the same time opening a state channel between you and the barber shop. The process of returning your card closes the "status channel" between you and the barber. The mutual transfer between you and the barber shop is equivalent to two transactions on the Ethereum main chain.
Imagine that you don't have a card, and you need to transfer the account to the barber shop every time you finish your haircut.
Application Scenario
Application Scenario
(1) The state channel can play a very important role in some simple scenarios such as streaming payment. It records transaction data by signing messages off the chain, and simplifies a large number of transactions that have occurred logically into the main Two transactions on the chain.
(2) Because of its low cost, the state channel is very suitable for some micropayment scenarios, such as buying breakfast coffee with ETH or BTC.
limitation
secondary title
2. Plasma
1: PrincipleNow we all know the limitations of the state channel, and in order to solve this problem-Plasma came into being. It solves the problem of sending assets to any target person, and can also ensure the improvement of TPS. In fact, for a long time when developers began to study Layer2 solutions, Plasma was once considered to be the "one".
To understand Plasma, you must first understand that it is not an actual technology, it is more like a design idea or technical architecture.
Plasma is usually a chain, which can have a different consensus mechanism than the main chain, or it can have its own miners. But the most important thing is that there will be a Plasma chain called "OperatorMerkle treeMerkle tree, and submit the root hash value of this Merkle tree to the main chain for verification and recording. Why Merkle trees and their root hashes can be used as verification of state transitions will be discussed in Rollup, which also uses this application.
In this way, no matter how many transactions occurred on the sub-chain during the two submissions, the sub-chain only needs to submit the state information caused by the transaction execution to the main chain.
The following is a simple diagram of using the Plasma mechanism:
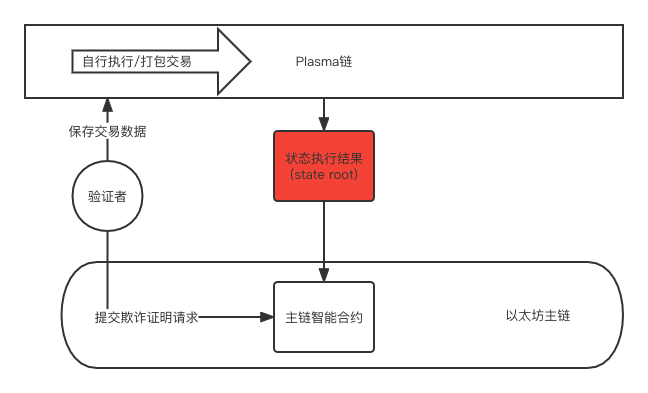
Users who want to enter the Plasma chain need to map assets on the Ethereum main chain, and when they need to transfer assets on the Plasma chain or the main chain, they need to go through a period of challenge for others to use "fraud proof" Mechanisms to confirm the validity of asset transfers.
"Fraud Proof"It means that within this challenge period (usually 7 days or longer), anyone can submit proof that the withdrawal of user assets is illegal through Merkle tree verification.
But this creates two problems:(1) If you want to verify the correctness of this withdrawal, you need a node to save the transaction and state information on Layer 2, because Plasma will only submit the result of its state transfer, and you must have the information on Layer 2 to submit a fraud proof, which will Greatly increase the cost of the role of the verifier.
(2) is called"Data not available"secondary title
3. Rollup
We can see that a very important problem with Plasma is that its "data is not available". The main chain will only receive the state transfer results submitted by the Operator, and it can only expect that someone has stored the transaction and state information under the chain. The proof mechanism is used to ensure the authenticity of the submission of the subchain. It only assumes the role of the confirmer in this process, and its security level is poor.
1. A specific understanding of "data not available"
Ethereum makes all the data that happens on its chain public, and everyone can query it. However, Plasma does not submit these transaction data to the main chain, but only submits the execution results, so its efficiency is greatly improved, but the price of doing so is that Plasma cannot establish the same level of trust as the Ethereum main chain.
Rollup can actually be regarded as a compromise between the original main chain processing method and the Plasma method. It will submit data to the main chain, but it will maximize the compression of these data through clever coding methods, and at the same time delete and reduce appropriately based on the characteristics of Rollup itself Part of the data, as long as the final submission can be verified by anyone.
After the transaction data is uploaded to the chain, anyone can verify whether the results submitted by Rollup are correct based on this data. Therefore, Rollup is more secure than Plasma.
data availabilitydata availability”, it will submit the data to the main chain, which greatly strengthens the security.
So how exactly is Rollup implemented?
2. Principle
(1) State Root: First, Rollup has one (or a series of interrelated) contracts on the main chain:
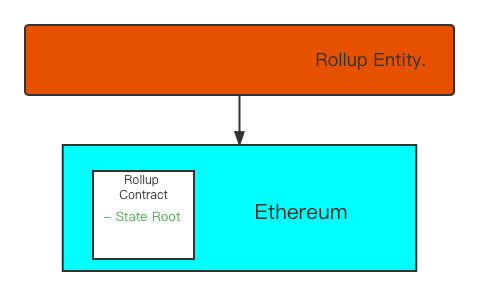
This contract is used to maintain the state record in the Rollup layer. This state record is actually a hash value stored at the root node of a Merkle tree. This hash value is calledstate root。
And the leaf node of this Merkle tree is the account status information in Rollup. If you don't know what a Merkle tree is, here is a simple example:
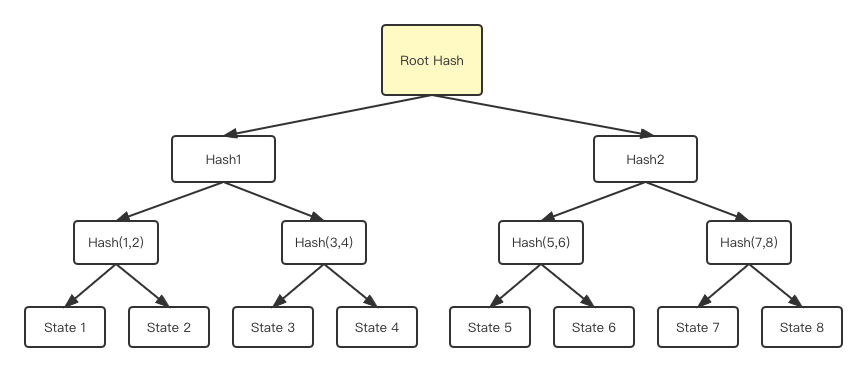
It can be seen that this is a binary tree, and the status information of the current rollup layer account is recorded on the leaf nodes of the binary tree.
For every two state information (such as State 1/State 2), we can calculate a unique hash value (eg: Hash(1,2) ) according to a certain hash formula as the father of these two leaf nodes Nodes, one by one, and so on, and finally get a hash value stored in the root node:
You don't need to know how to calculate a hash, you just need to remember a few things.
1 The change of any leaf node will cause the value of the root node to change (Any state change will cause the Root hash to change)
2 If the root hash values of the two trees are the same, it means that the information stored in their leaf nodes is exactly the same(Therefore, it is only necessary to compare the hash values of two root nodes to confirm the consistency of the underlying state information)
text
text
The key is the account address, and the value contains status information such as balance/Nonce/contract code/storage (for contract accounts)
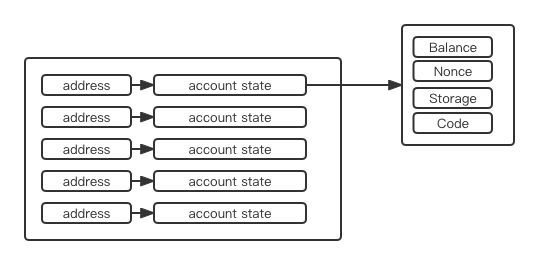
When a transaction occurs on the rollup, obviously, the status of these accounts will change, resulting in a new state root.
Although this can provide very accurate and timely feedback of the latest state changes on Rollup, if the state root is updated on the main chain every time a transaction occurs, the cost incurred will be higher than that of executing these transactions on Layer1.
Therefore, in order to solve this problem, the transactions generated in the rollup will be packaged and aggregated in batches, and a new state root will be generated according to the state after all the transactions in this batch are executed. No matter who submits the transaction package to the smart contract on the main chain, he needs to calculate this new state root and submit it together with the previous state root and transaction data.
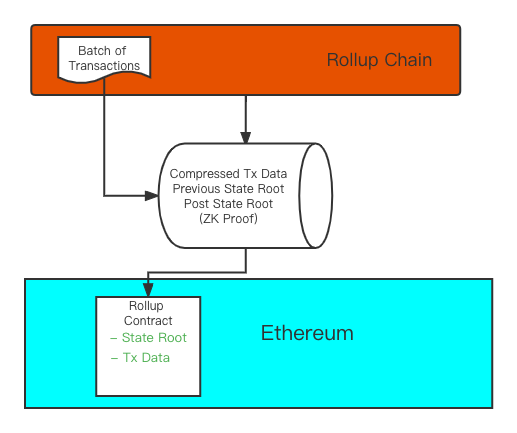
This part of the packaging is called a "batch". After the submitter submits the batch to the Rollup contract, the main chain will verify whether the new state root is correct. If the verification is passed, the state root will be updated to the latest submitted state root. And finally complete the state transfer confirmation in a rollup.
text
Therefore, the essence of Rollup is to aggregate a large amount of actually generated transactions into a transaction on the main chain. These transactions are executed and calculated by the Rollup chain, but the data will be submitted to the main chain, and the main chain will act as a "highest The role of a "court judge" ultimately confirms these transactions. Therefore, we take advantage of the consensus and security of the main chain, while improving the actual transaction efficiency and reducing transaction costs.
3: Doubt
After reading the above description, you may have some questions, don’t worry, we will deduce and explain step by step.
(1) If the full amount of transaction data is submitted, it is still difficult to expand, right? Does the data compression mentioned above solve this problem? How do you do it?
These two technical solutions can achieve expansion, and the core is the compression and packaging of transactions. This is because the block gas limit of Ethereum has an upper limit. The smaller the compressed transaction, the more transactions can be submitted to the main chain at one time. So how to do this?
The following is a compression mode described by Vitalik in his article, as an example to help us understand
A simple transaction on the Ethereum main chain (such as sending ETH) typically consumes about 110 bytes. However, sending ETH on Rollup can be reduced to about 12 bytes.
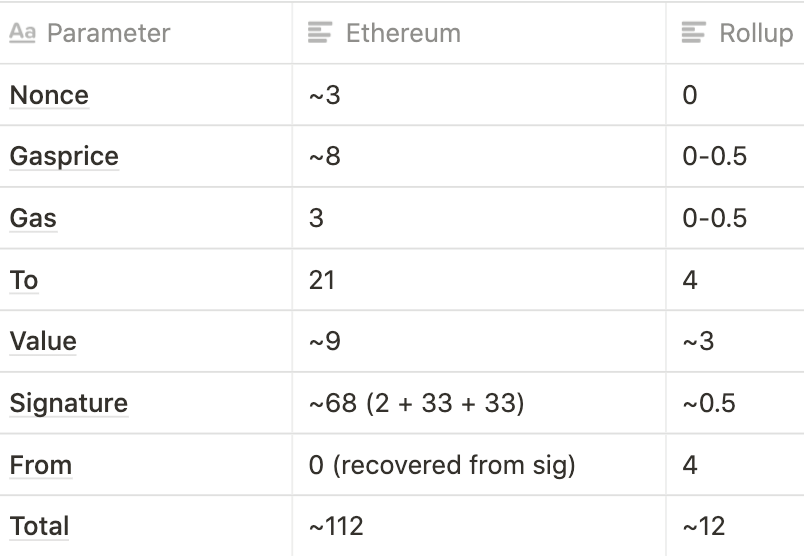
To achieve such a compression effect, on the one hand, a simpler and advanced encoding is adopted, and the current RLP of Ethereum wastes 1 byte in the length of each value. On the other hand, there are some neat compression tricks:
Nonce: The nonce can be completely omitted in rollup
Gasprice: We can allow users to pay with a fixed range of gasprices, such as 2 to the 16th power
Gas: We can also set gas to multiple powers of 2. In addition, we can also set the gas limit at the batch level.
To: The address can be identified by the index on the Merkle tree
Value: We can store value in scientific notation. In most cases, only 1 to 3 significant digits are required for transfers.
Signature: We can use BLS aggregate signature to combine multiple signatures into one
These compression techniques are the key to rollup expansion. If we don’t compress transaction data, rollup may only be able to improve efficiency by about 10 times on the basis of the main chain, but with these compression techniques, we can achieve 50 times 100 times times or even higher compression efficiency.
At the same time, in order to save gas, these compressed transaction data will be stored in the calldata parameter. The famous EIP-4488 proposed to reduce the gas consumption of each byte of data in calldata, in order to further optimize the amount of transaction data in the roll layer that can be carried by a main chain transaction. For the specific compression effect, we will show simple data when comparing two different ZK-Rollups below.
(2) How to verify that the submitted verifiable information is correct?
Since the final state transition confirmation (which also represents the confirmation of the transaction) is determined by the update of the state root, but it seems that the submitter on Rollup can submit the transaction data and state root he wants at will, so how to verify his submitted Is this information correct?
For this problem, there are generally two solutions, and according to different solutions, rollup is also divided into two categories:
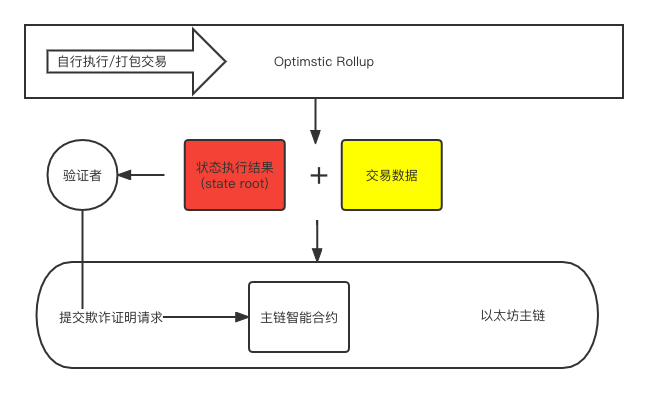
4:Optimistic Rollup
True to its name, this solution chooses to optimistically believe that the batch submitted by the submitter is correct, unless someone proves through a fraud proof that the submitter is actually a bad guy who submitted a wrong batch.
(1) Here is a simple example of fraud proof construction (thanks again Vitalik):
To submit a fraud proof to prove that a submitted batch is wrong, the information included in the green part of the figure below is required:
1. The batch submitted by the submitter
2. A part of the Merkle tree (actually representing the real account status information) represented by the previous state root, and a complete Merkle tree can be constructed based on this part
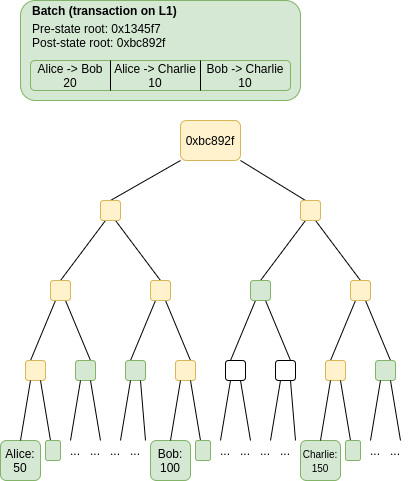
Based on the Merkle tree constructed in the second part, we simulated the execution of the transactions submitted in the batch, thereby obtaining a new account state, a new Merkle tree, and a new state root.
Compare the state root obtained in the previous step with the state root in the batch to verify that the batch is correct
(2) Verification process
We logically sorted out the process of Optimstic to ensure the authenticity of the state root. In fact, in order to ensure that the submitter can be deterred from doing evil, the submitter often needs to pledge funds. When his submission is verified as wrong, part of the pledged funds will be Deduction as punishment. At the same time, verifiers who submit corresponding fraud proofs will get deducted funds in some solutions, so as to incentivize the behavior of monitoring and submitting fraud proofs.
If we compare OR and Plasma, we will find some similarities, for example, they both use a fraud proof mechanism and need a validator role to monitor the submission of OR to the main chain. However, since OR submits transaction data to the main chain at the same time, verifiers on OR do not need to save and record transactions on OR themselves. For comparison, the simple architecture diagram above is placed here for readers to compare:
5:ZK-Rollup
(1) The core of Zk-rollup
Another type of solution is ZK Rollup. Unlike OR (Optimistic Rollup), ZK Rollup makes such fundamental assumptions:
I don't believe that the submitter can actively submit the correct batch, or it is similar to the "presumption of guilt" in jurisprudence. In addition to the transaction data and post/previous state root, the submitter also needs to carry a ZK-SNARK certificate when submitting the batch.
Validity certificateValidity certificate", he can be directly used to verify that the submitted batch is correct. After this proof is submitted to the Rollup contract, anyone can use it to verify a specific batch of transactions in the Rollup layer, and this means that rollup does not Then you need to wait 7-14 days after submitting for verification.
(2) The difference between validity proof and fraud proof
So how to popularly understand the difference between "validity proof" like ZK-Rollup and "fraudulent proof" used by Plasma/Optimsitic Rollup?
First of all, all three solutions require someone to sort, execute, and package transactions on Layer 2. Let us call this role the "executor".
The executors of Plasma will only submit the execution results. Adhering to the principle of whether others believe it or not, if you don’t trust me, you need to initiate a challenge, and initiating a challenge requires you to save the underlying transaction data yourself.
The same is true for OR, but the executor will also put up the transaction data when submitting it. It is also a matter of believing it or not. If you don’t believe it, you can verify it yourself based on the transaction data.
But ZK is different, ZK said that I don't want to wait for you for several days for you to challenge me, what a waste of time, I was in a hurry to confirm my transaction. So ZK directly generates a certificate when submitting, puts this certificate on it, and completes the verification while submitting.
At the same time, Plasma/OR both need to pledge to ensure that the executor will lose money if he does evil, but ZK does not, because it does not require others to believe it, and he will prove his innocence every time he commits.
In addition to this difference, another meaningful point is that ZK-SNARK allows us to prove the validity of this batch of transactions without submitting all transaction data, which is very important for Rollup, as follows We will explain this.
(3) Implementation logic of ZK-Rollup
First of all, ZK-Rollup is essentially a Rollup solution, so it still needs to do the following two things:
Pack and compress a batch of transaction data
Generate a new state root
The only difference is the verification method, ZK-Rollup will not wait for the verifier to initiate the fraud proof process, but directly generate a ZK-SNARK proof and add it to the Batch and submit it to the main chain rollup contract.
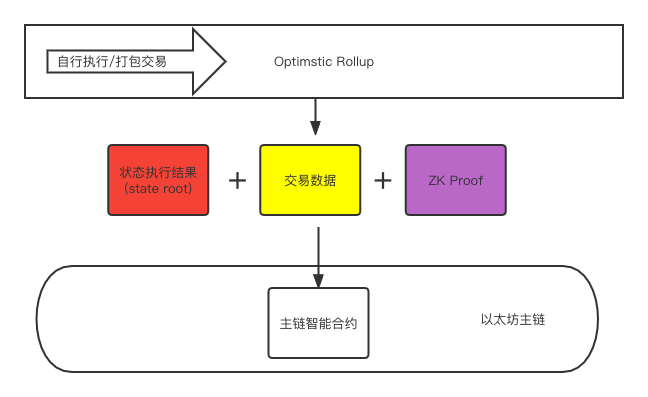
As shown in the figure, the submitted content adds a ZK-Proof compared to OR, and the role of the verifier is hidden.
After submitting to the rollup contract, anyone can verify it. After the verification is successful, the main chain rollup contract will update the State root to the latest submitted data.
(4) How to generate a ZK-SNARK validity proof?
A What are ZK-SNARKs?
The full name of ZK-SNARK is "Zero-Knowledge Succinct Non-Interactive Argument of Knowledge."
Succinct non-interactive zero-knowledge proofs. I'll try to explain what each part of it means:
Succint (concise): Compared to the amount of data actually proved, this method generates proofs that are much smaller.
For example, if we want to prove that a series of transactions do exist and occur, the amount of proof data generated must be smaller than the amount of data of these transactions themselves.
Non-interactive (no interaction): After the proof is built, the prover only needs to send a simple message to the verifier once, and usually allows anyone to verify without permission.
This is very important for ZK-Rollup or ZK applications on the blockchain, because some ZK proofs require multiple interactions between the prover and the verifier (guessing the color problem is a typical example), and putting it on the chain will It means to initiate multiple transactions, which is intolerable in terms of cost.
Arguments: can resist the attack of the prover with limited computing power
This part means that the complexity of the encryption algorithm used to generate the proof cannot be violently cracked at an acceptable time and economic cost under the existing computing power conditions.
of Knowledge: It is impossible to construct a proof without knowing what is being proved
This is also very important for ZK-Rollup, because we cannot allow someone to create a ZK Proof based on non-transaction data and submit it to the main chain contract.
Last but not least"Zero-Knowledge”:
Zero-knowledge means that when the prover proves a statement (Statement) to the verifier, he does not disclose any useful information or any information related to the proven entity itself.
B One of the simplest zero-knowledge proof examples is this
Alice wants to prove to Bob that she knows the password of a certain safe. The password is the only way to open the safe, but she doesn't want to tell Bob the password of the safe. What should I do?
It happened that Bob knew that there was a love letter written by Bob's ex-girlfriend in the safe, with the fingerprints of both Bob and his ex-girlfriend on it.
So Alice opened the safe behind Bob's back, took out the love letter and gave it to Bob.
This proves that Alice knows the password of the safe, and Alice did not tell Bob what the password is, success!
C How to generate a ZK-SNARK proof for ZK-Rollup?
Briefly, generating a ZK-SNARK proof is divided into the following steps:
Determine the logical verification rules of the problem (such as checking whether the balance and nonce meet the requirements, etc.)
Transform logical verification rules into gate circuit Circle problems
Transform the Gate Circuit Circle problem into R1CS (rank-1 constraint system, first-order constraint system) form
Convert R1CS to QAP (Quadratic Arithmetic Program)
This articleThis article。
If you think this part is more complicated than every previous part, you are right. What is also complicated is the current ZK-Rollup solution provider, which is one of the reasons why the current ZK-Rollup research and development progress and actual application are slower than Optimstic Rollup. If you are not a math/cryptography expert, or a Matter Labs developer, here are just a few things you need to know:
Generating a ZK-SNARK proof is much more computationally and time-consuming than verifying a Merkle tree
Not just any language, compilation environment, virtual machine, and instruction set can seamlessly support the completion of the above-mentioned process, and additional adaptation is required.
For the first point, this is the direction that major ZK solution providers are currently working on. The first is the time cost. If it takes an hour to generate a usable ZK-Proof, the indirect user withdrawal time will also be longer. The calculation cost includes two parts, one is the data volume of the generated ZK-Proof, and the other is the computing power required to verify the Proof. The larger these two parts are, the more Gas needs to be consumed on Ethereum, which in turn affects the optimization performance of ZK-Rollup.
For the second point, this is a major reason that currently limits the development of ZK-Rollup. At the beginning of EVM design, developers had no idea that ZK technology would be used later. It is therefore nearly impossible to generate usable zero-knowledge proofs for EVM operations, thus giving rise to the need for ZK-EVM.
D Why is it so difficult for ZK to be compatible with EVM?
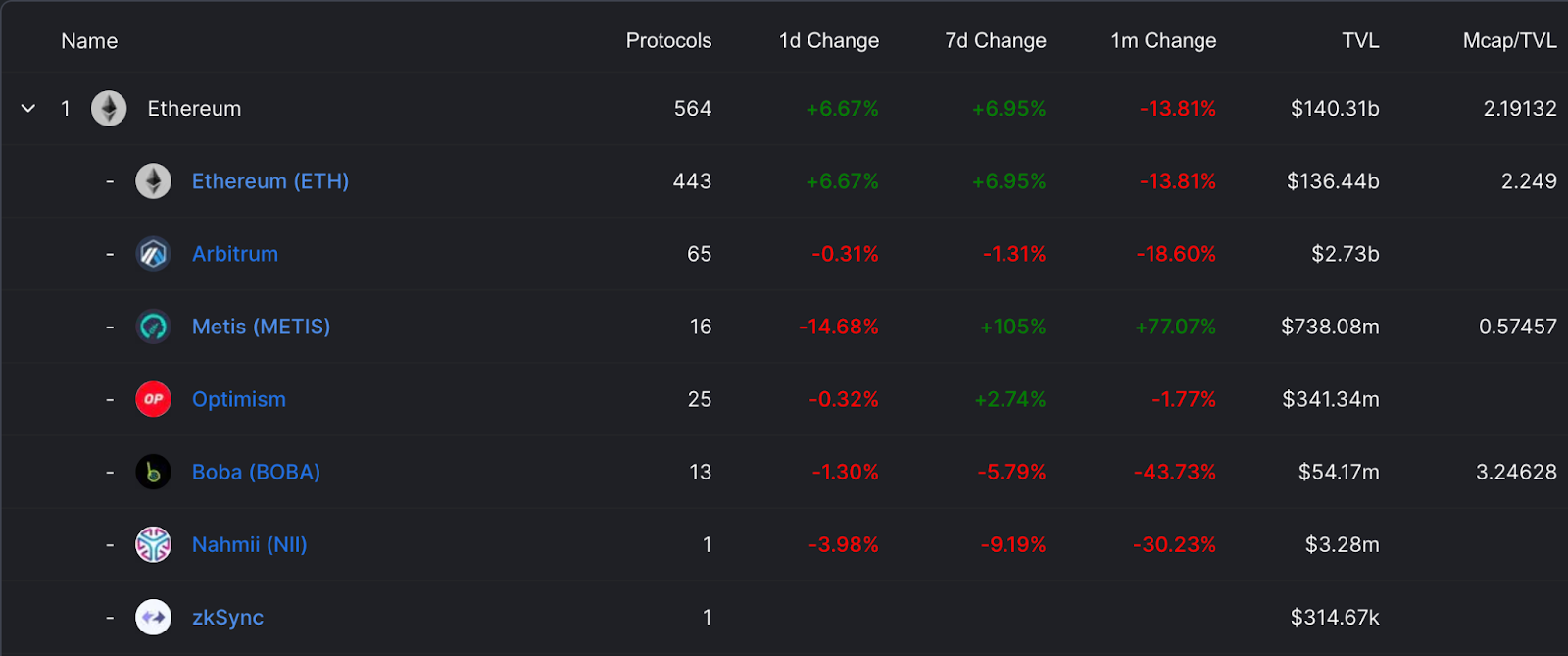
Open DeFillama, and you will find that the top Layer 2 solutions in TVL are all ORs. This is because these OR solutions already have their own networks, and these networks are EVM compatible. Developers can seamlessly integrate The smart contracts on Ethereum are transplanted to their network, and users can also perform operations such as swap, mortgage, and liquidity provision on their network.
However, ZK-Rollup is still difficult to achieve this, and many existing solutions can only support simple payment and swap scenarios.
Why is this so? First of all, we need to make it clear that on Layer 1, the bytecodes of deployed smart contracts are all stored in Ethereum storage (storage items). Then the transaction will be propagated in the peer-to-peer network. For each transaction, each full node needs to load the corresponding bytecode and execute it on the EVM to obtain the same state (the transaction will be used as input data).
On Layer 2, although the bytecode of the smart contract is also stored in the storage item, the user's operation method is also the same. But its transaction will be sent to a centralized zkEVM node under the chain. At the same time, zkEVM not only needs to execute the bytecode, but also must generate a Proof to indicate that the state has been correctly updated after the transaction is completed. Finally, the Layer 1 contract can verify the proof and update the state, and at this time there is no need to re-execute the transaction on layer 2.
That is to say, executing transactions on zk-Rollup is a completely different logic and path. At the same time, zkEVM also adapts to generate zk circuit proofs while executing transactions. The existing EVM generates ZK-SNARK proofs as follows: question:
Some elliptic curve operations required by ZK-SNARK are not supported
Compared with traditional virtual machines, EVM has many unique opcodes, which are difficult for circuit design
EVM runs on 256-bit integers (just like most common virtual machines run on 32-64-bit integers), and zero-knowledge proofs "naturally" run on prime fields.
These are only some of the problems of generating ZK Proof in EVM. Although OR also needs to build a virtual machine to perform EVM operations, since it only needs to complete transaction packaging and other functions on the basis of executing transactions, it needs to be constructed. Much simpler. For ZK-Rollup, in addition to the difficulty of generating ZK-Proof while being compatible with EVM, it is not easy to verify this proof on Layer1.
If you want to know more about the difficulty of ZK-EVM, you can read this article: https://hackmd.io/@yezhang/S1_KMMbGt
After reading the above content, it is undeniable that the implementation of zk-Rollup has high technical difficulty, so why don't we directly use the more "simple" Optimistic Rollup technology?
Now let's make a simple comparison of these two Rollup techniques.
6:Optimstic VS ZK
(1) Efficiency optimization (TPS/transaction fees)
source
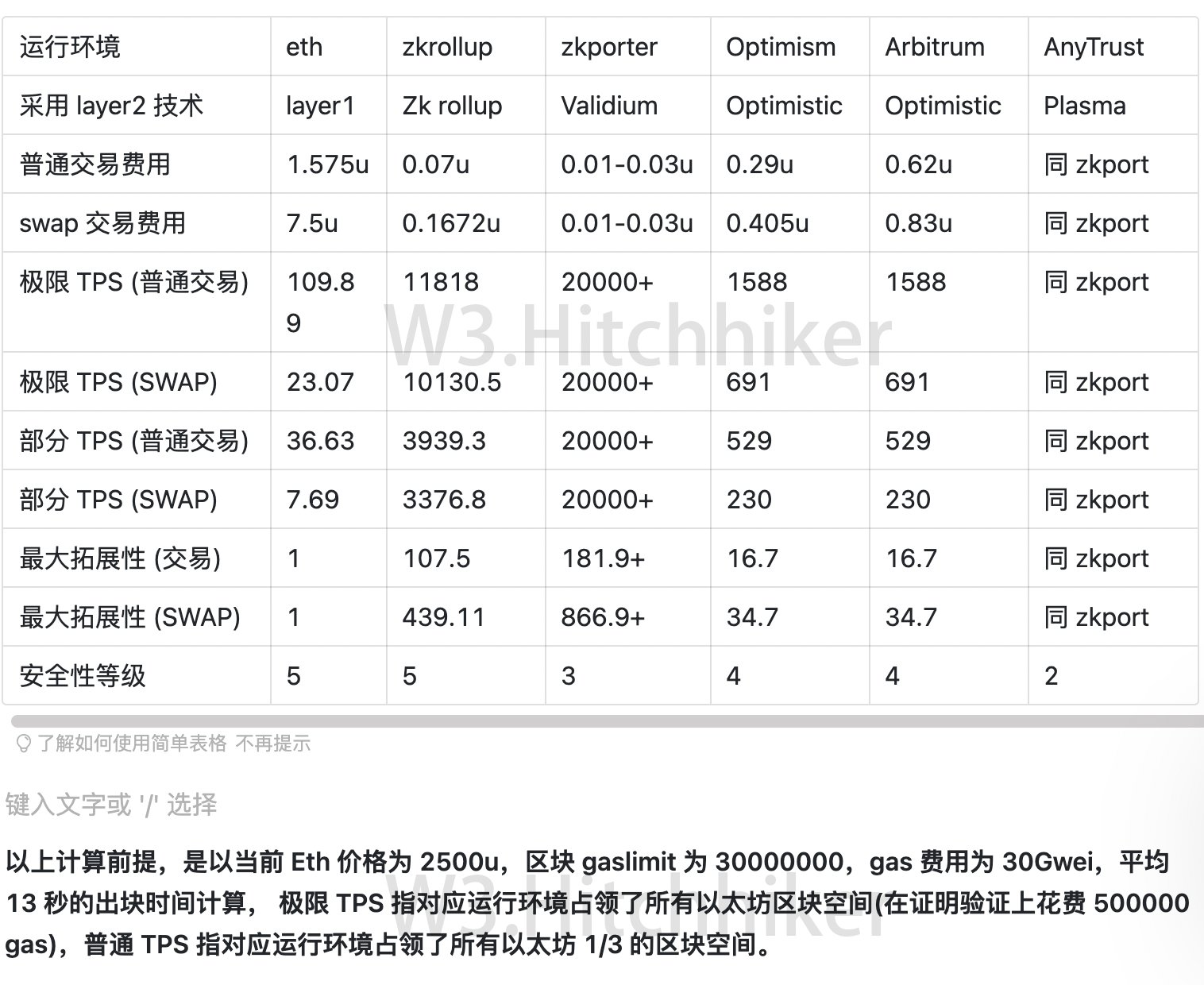
Thanks to the @W3.Hitchhiker team for their contributions!
From the figure, we can see that the ZK scheme is more efficient than the OR scheme. Why?
For a Rollup scheme, the most important thing is how much Layer 2 transaction data can be carried in an Ethereum transaction, and this is related to two parameters:
Gas consumption of a transaction compressed by Rollup
The max gas limit of the Ethereum block
Among them, Rollup can solve the first point, although the storage and verification of ZK-Rollup proofs need to consume a certain amount of storage space and gas (a credible data is about 500K). However, due to better transaction compression, and transaction data storage consumption is the vast majority of Gas consumption, ZK-Rollup performs better than OR efficiency optimization.
In addition, you may notice that ZKPort has the best TPS and transaction cost optimization in the table. This is mainly because the Validium it uses is essentially a Plasma solution that replaces fraud proofs with ZK Proofs. It does not submit transaction data. Its efficiency is entirely determined by the processing efficiency of the Plasma chain, but it also faces the problem of data unavailability in terms of security.
The calculation above assumes a gas price of 30 Gwei, and we all know what gas prices go to when Ethereum activity spikes. At that time, the cost optimization effect of Rollup, especially the ZK scheme, will be more obvious.
(2) Time cost
We mentioned earlier that withdrawals on Optimtisc Rollup require a 7-14 day submission period due to the fraud proof mechanism for others to disprove potential misconduct.
Of course, we can reduce the withdrawal period through some behaviors independent of the Rollup mechanism itself, similar to the liquidity pool mechanism proposed by Optimstic Rollup solutions such as Boba Network.
Let us assume such a scenario:
Alice is an OR user with 5ETH assets on L2.
Another liquidity pool B on L1 is turned to provide liquidity for OR users like ALice.
Now Alice wants to get back all assets from OR, and now he makes a transaction with B:
Alice can take 5ETH directly from Bob and pay a certain handling fee at the same time
After 7 days, Alice's assets are unlocked, and the 5ETH that Alice took is returned to the pool.
This has a certain risk for the liquidity pool, so he can monitor the OR contract and get a penalty for dishonest submission to hedge the risk. At the same time, the handling fee charged is also a reserve for reducing risks.
But this method is not suitable for NFT, because NFT is indivisible, and the liquidity pool cannot simply copy an NFT to the user.
However, ZK-Rollup does not have this problem. The submitter must prove his innocence when submitting and provide a verifiable ZK-SNARK certificate. The current ZK-SNARK certificate generation time can reach a few minutes. Users only need to wait for the next batch to be submitted and verified.
Time cost is the shortcoming of OR, and it is also one of the significant advantages of ZK-Rollup.
(3) Adaptability
Both Optimsitic and ZK are faced with the problem of compatibility and adaptation to complex EVM contract call operations, but obviously Optimsitic is easier to implement.
OR solutions including Arbiturm and Optimsim have EVM-compatible virtual machines that allow them to process all transactions that occur on the Ethereum main chain. Some OG-level DeFi protocols such as Uniswap/Synthetix/Curve have also been deployed on the OR network.
Constructing an EVM-compatible ZK-SNARK proves to be very difficult, so far there is no publicly available ZK-Rollup solution. However, we have some good news recently. The zkSync 2.0 public testnet was officially launched at the end of February. This is also the first EVM-compatible ZK Rollup on the Ethereum testnet. Perhaps the official large-scale actual use of ZK Rollup will be faster than we thought.
(4) Security
The answer to this question is obvious, the security of OR comes from economics. In order to work well, OR must design a reasonable incentive mechanism to drive a group of validators on the main chain to monitor the submitter at any time and prepare to submit fraud proofs. As for the submitter, it also needs to ensure that the node will pay the corresponding price for doing evil through pledge and other methods.
The security of ZK comes from mathematics or cryptography, just like the foundation of trust in the blockchain: the code will not do evil. The guarantees provided by mathematics and cryptography are far more stable than the optimistic belief that human nature will not do evil.
Of course, the current Rollup mechanism itself has certain security issues, although rollup submits data to the main chain to solve the problem of data availability. But we haven't discussed who is responsible for transaction processing, ordering, compression, packaging and submission. Some current mainstream solutions, such as Arbitrum, Optimism, and StarkNet, use a role called sequencer, which is a single node that they run on their own.The result of this approach is a high degree of centralization.
We know that decentralization is the premise of all security. The advantage of this sequencer model is its high efficiency. It can be quickly iterated when the rollup is still in the exploratory stage. These solutions also declare that the decentralization process of the sequencer will be gradually carried out in the future. . For example, using PoS or dPoS to elect sequencer nodes, new solutions like Metis have been explored.
(5) Summary
Let's visualize the above discussion in terms of a table:
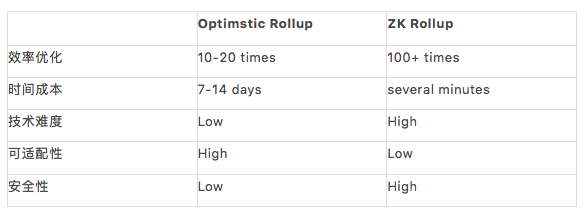
Overall, OR is the more mature solution at this stage, and indeed it is, with products from Optimstic and Arbiturm already available to Ethereum developers. However, due to the use of a fraud proof mechanism, its withdrawal time and security are currently questionable, and its cost optimization is also slightly inferior to that of ZK.
The weaknesses of ZK Rollup are basically technical issues. With a large number of excellent developers investing in related research, most people, including Vitalik, agree that ZK Rollup will be a better expansion solution in the future.
7: Is Rollup perfect?
After the above explanation of the three types of Layer 2 solutions, I believe you already have a certain understanding of them. In fact, the order in which the articles are written is also the order in which developers research Layer 2 expansion solutions. Often after discovering problems with a certain solution, another better solution is proposed to solve related problems. Not only in the field of encryption research, this process can be extended to all engineering problems:
Ideas are developed, tested, iterated, optimized until the most viable solution is found.
Now it seems that Rollup is the answer we are looking for. It solves the problem of universality and data availability. At the same time, it looks good in terms of security and efficiency. So, is it the flawless one?
The answer is no. No solution can be perfect. Rollup also has many problems. Even ZK-rollup, which looks better, cannot avoid them.
(1) There is a ceiling in efficiency optimization:
When we talked about the main difference between rollup and plasma, we talked about ensuring data availability. Rollup needs to submit transaction data to the main chain, which is the main reason why the rollup scheme beats plasma.
But we have to see on the other hand, the on-chain transaction means that rollup will still be limited by the capacity of the Ethereum main chain:
Simple calculation:
Current Ethereum block max gas limit: 12.5M gas
Data cost per byte stored on-chain: 16 gas
Maximum bytes per block: ~781,000 bytes (12500000/16)
The amount of data required for Rollup to perform an ETH transfer: 12 bytes (see the gas cost in the previous section)
Transactions per block: ~65,000 (781,000 bytes/ 12 bytes)
Average block time on Ethereum: 13 seconds
TPS:~5000(65,000 tx/13 s)
Here we make a lot of assumptions, for example, we assume that all transactions are simple ETH transfers. The actual transaction will contain a lot of complex contract calls, and the gas consumption will be higher. And for ZK-Rollup we also need to count the cost of verifying ZK-Proof (half of which is around 500K gas).
Even so, the TPS that Rollup can achieve is only about 5000. We also saw that the direct efficiency optimization brought by the use of the Plasma mechanism is much higher than that of Rollup.
The Ethereum Foundation is also very aware of this problem. At present, their main solution is sharding + rollup, which will increase the TPS brought by rollup by another order of magnitude.
(2) Fragmentation of liquidity:
Under the influence of the current multi-chain structure, its own liquidity fragmentation has become increasingly serious.
However, due to the existence of multiple technical solutions and multiple solutions, the number of rollup networks in the future will only continue to grow, which will bring about more serious liquidity fragmentation.
A look at the current TVL of Ethereum and its layer2 network
The good news is that cross-chain communication can solve this problem. The representative event is that Synthetix is already working on merging its debt pools on the Ethereum main chain and Optimism. If this process is completed smoothly and smoothly, it is believed that the trend of liquidity merging on the main chain and sub-chains will be promoted to a certain extent.
After all, the debt pool model of synthetic asset projects is far more complicated than the current more common liquidity pool model, and it is foreseeable that mainstream DeFi projects such as Uniswap will continue this process.
(3) Reduced composability caused by communication difficulties and technical obstacles:
In the previous question, we talked about the communication problem that split the liquidity. This phenomenon also applies to the interaction between the main chain dapp and the sub-chain dapp. Every new protocol built on Ethereum is like Lego blocks. Others Protocols can be easily built on top of it, which is one of the reasons why DeFi is growing rapidly.
If the communication problem cannot be solved, then the dapps on the sub-chain need to re-establish their own ecology, which causes a greater waste of resources. Not only between the sub-chain and the main chain, but also between the sub-chain and the sub-chain need to build a communication mechanism.
Again, some good developers are working on this as well, let's hope they simplify these operations and processes. After all, the operation of Layer1 itself is cumbersome enough. If the complexity of layer2 is added, this will make the threshold of the Web3 world even higher.
(4) Centralization risk
epilogue
epilogue
The full text has exceeded 10,000 words, far exceeding my expectations. The expansion of Ethereum itself is a very grand and complex topic. In this article, only part of the Layer2 solution is involved. Layer1 expansion solutions (sharding), and other Layer2 solutions such as Side Chain, Validium, etc. are not mentioned. In fact, the expansion of Ethereum is not a single solution that can be solved once and for all. Many solution providers are also exploring multiple paths, and companies like Polygon have invested in a large number of different types of Layer 2 solutions.
At the same time, many things in the article are limited by the length of the article and still need to be explored, such as what kind of communication support is required for the submission between Layer2 and Layer1. How the fraud proof/validity proof is implemented on Layer 1, the specific differences between various ZK/OR implementation schemes, etc. Understanding these things is very important for researchers who want to understand Layer2, especially Rollup expansion. In order to facilitate understanding and sorting out some concepts in the article, we have made a more general overview. For example, OR/ZK has very different solutions in terms of transaction data compression, etc. The example of vitalik used in the article is more biased towards the ZK solution . In the process of writing, we also referred to some excellent Layer2 content, and we marked it in the text and at the end of the text. We also hope that more and better content will appear to help everyone further establish relevant cognition.
Finally, from the perspective of the two Rollup solutions we introduced,Optimstic Rollup has taken the lead in the market, while launching available products, it gradually attracts mainstream Dapps to integrate into the ecology. It is undeniable that the great contributions of relevant developers have been made. butreferences:
references:
1.An Incomplete Guide to Rollups (Vitalik)
2.W3hitchhiker team's cost comparison of four Layer2 solutions


