
Analysis and Optimization of Storage Explosion Problem in Ethereum
background
background
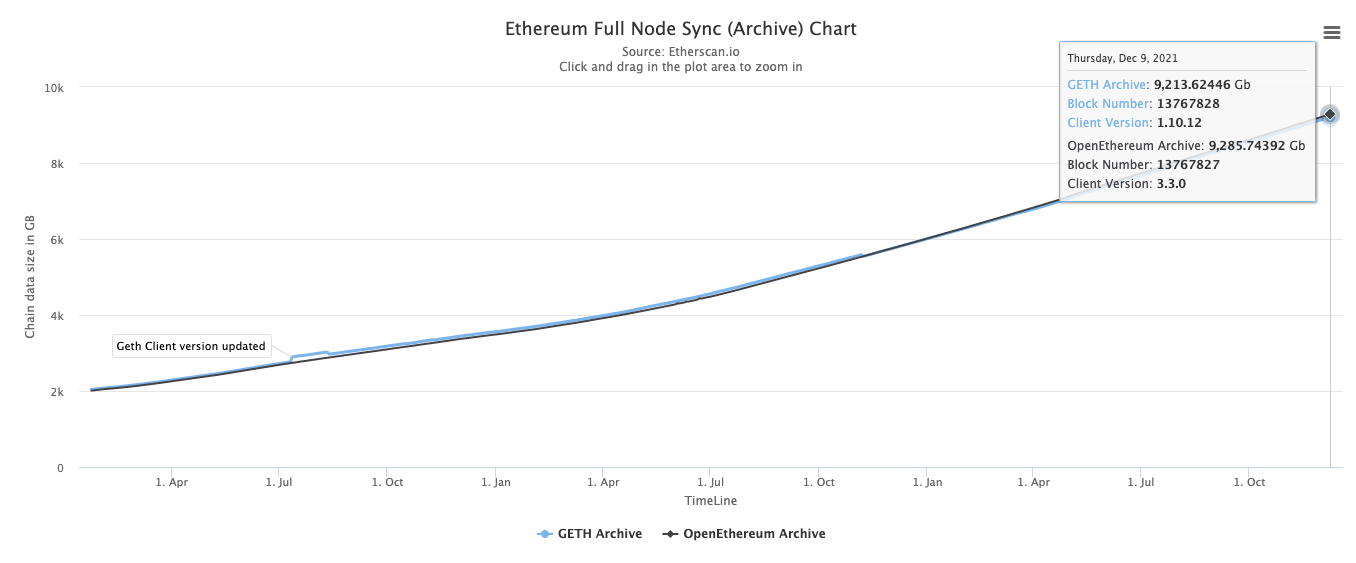
The vigorous development of decentralized applications such as DeFi and GameFi has greatly increased the demand for high-performance blockchains with low transaction fees. However, a key challenge in building high-performance blockchains is storage explosion. The image below is a graph taken from Etherscan illustrating the blockchain data size of an Ethereum full node (archive).
secondary title
Break down storage overhead
If we further analyze the storage usage, we can find that the block data only accounts for about 300GB of data (from block height 0 to 13.6M), which is much less than 9TB. So where did the remaining 8.7TB of data come from?
block
block
state
transaction receipt
Among them, the state is the main component of the 8.7TB. So sometimes, we refer to storage explosion as "state explosion". But why is the state so large?
What is Ethereum state?
The Ethereum state is a Merkle Patrica tree (MPT) where
A leaf node is a mapping of addresses (0x...) => accounts, where accounts store balances, nonces, etc. associated with addresses
Internal nodes maintain a tree structure so that the hash root of the entire tree can be computed quickly
secondary title
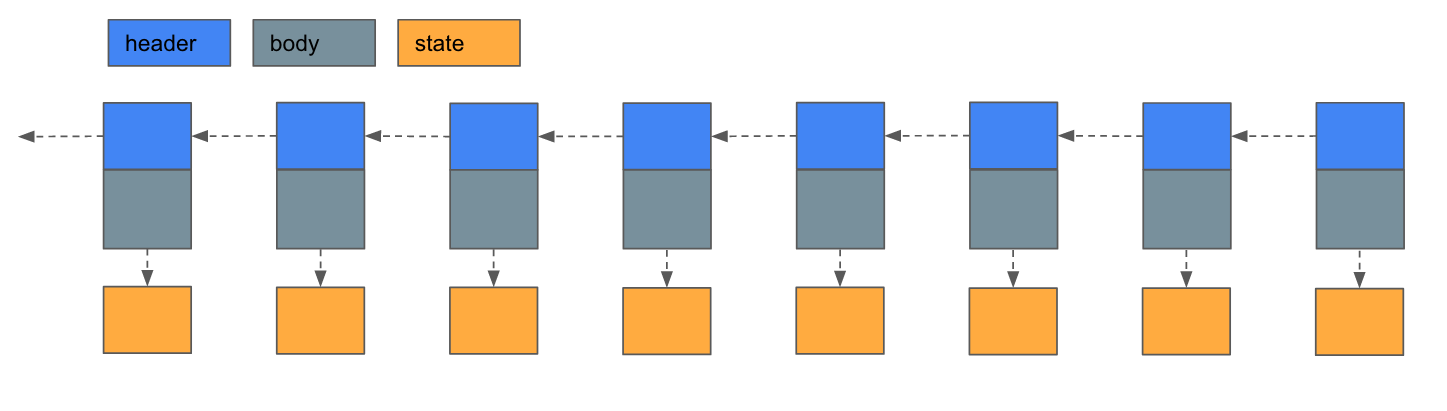
Geth full node
To solve the problem of archive node state explosion, the genius engineers at Geth created a new mode called "prune" mode, which only periodically stores MPT. Here we give a simplified example where the nodes only save the MPT for every 3 blocks. (Note that in order to obtain a state that does not contain any state blocks, a node must obtain the most recent state before that block and replay the subsequent transactions).
secondary title
A fast-syncable full node for Geth
One problem with running a node by replaying all transactions from the genesis block is that replaying all transactions can take a long time. Generally, it takes weeks for establishing such a node to catch up to the latest state of the network from the genesis block. In order to speed up the startup process of the node, Geth further provides a fast synchronization mode, which can download the MPT of the latest stable block without replaying and maintaining the historical MPT before the block. After downloading the MPT, it replays new blocks (with periodic state storage) like a full node.
question
question
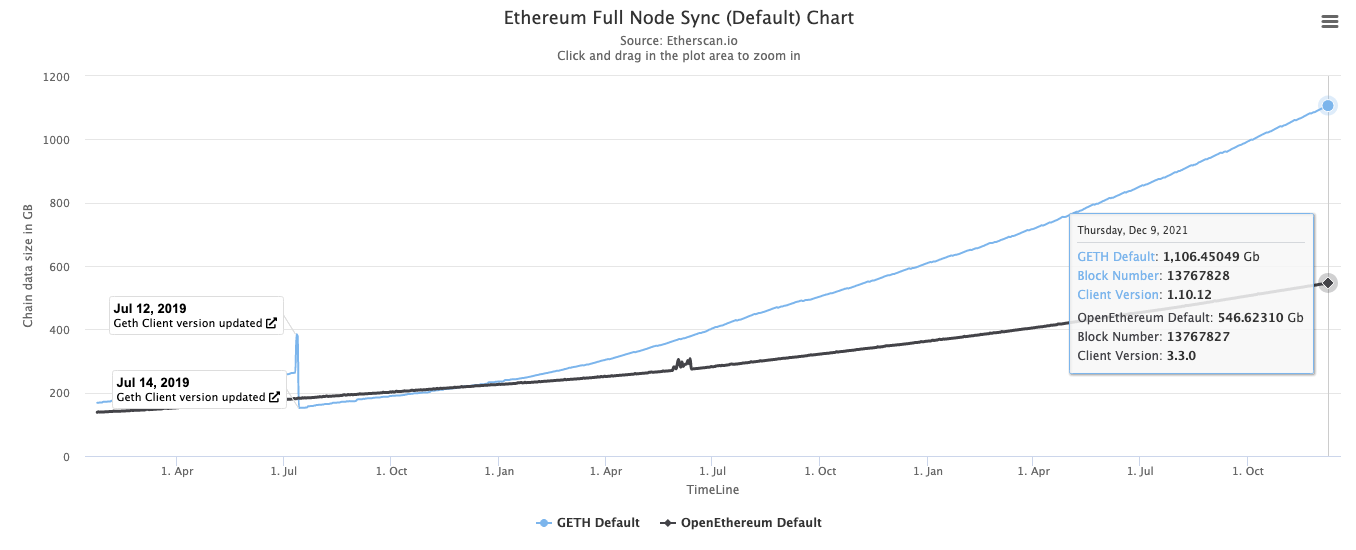
With the current Ethereum storage size of 447GB and 15 TPS, we expect that a common configuration computer with a 1TB SSD should be able to run an Ethereum node for a considerable period of time (say years). So is there really a storage explosion or a state explosion? Maybe Ethereum will not in the next few years, but what if we can scale Ethereum's virtual machine (EVM) to hundreds or thousands of TPS?
Let’s turn our attention to another EVM-based chain, Binance Smart Chain (BSC). As of December 8, 2021, BSC has:
About 984 GB of on-chain data, of which blocks account for about 550 GB and states account for about 400 GB.
2.06623 billion transactions, 100 TPS
If we further predict the data size by the number of transactions, we get:
If TPS is 100, that is ~3,153 M TPY
1 year later, total TX ~5,219M, block ~1.375 TB, state ~1.085TB
3 years later, total TX ~11,525M, block ~3.025TB, state ~2.387 TB
If TPS is 150 (observed peak TPS), that's ~4,730 M TPY
1 year later, total TX ~6,796M, block ~1.809 TB, state ~1.427 TB
3 years later, total TX ~16,256M, block ~4.327 TB, state ~3.414TB
To sum up, for BSC, if the current speed is maintained or even higher, it will soon reach the same storage size of the Ethereum archive node, which is almost impossible for ordinary computers to run.
Storage Explosion Problem for Blockchains with Extremely High TPS
If we make a bolder assumption about a blockchain with a very high TPS (such as QuarkChain is able to do), what will this number become? Let's consider a blockchain with 1000 TPS and analyze its block and state sizes, would be:
Assuming that the tx size is about 100 bytes, the storage required for each block is 1000 (TPS) * 100 (bytes per tx) * 365 * 24 * 3600 = 2.86 TB
Assuming MPT has 10 billion accounts (more than the world's population!), we expect the state size to be 150G (Ethereum state size) / 0.18B (Ethereum unique addresses) * 10B = 8.3 TB
optimization
optimization
secondary title
state storage optimization
The first optimization we propose is to use plain KV instead of MPT. When the MPT is large, all internal nodes in the MPT can be very expensive. And our optimization will remove all internal nodes in MPT. Assuming that the data of each account is about 50 bytes (20 addresses + 2 nonces + 12 accounts + others), we can save the data of the next 10 billion accounts as:
~ 10B * 50 + 100GB (code) = 600 GB, about 1/10 of the MPT version!
While there are huge benefits to using plain KV, a major problem is that we cannot calculate the state post-hash of each block in such a short block interval, which means we lose the following benefits of Ethereum:
Fast Sync: Download the state of any block and quickly sync the network by replaying the remaining blocks
Fork detection (or Byzantine detection): Whether a newly created block from a peer will result in a different state than a locally executed block.
To enable fast syncing, we have a periodic snapshot block (snapshot interval = epoch = eg, 14 weeks). A snapshot block contains the additional information of the pre-state hash, which is the post-state hash of the previous snapshot block (the state hash after executing the transaction):
A non-snapshot block does not maintain a state hash, but instead has an incremental hash, which contains the hash of the original database operations (delete, update) of all transactions for that block. This makes fork detection possible!
We use pre-transaction state hashes instead of post-transaction state hashes for blocks in Ethereum. The reason is that nodes cannot immediately calculate the state hash after the transaction, but by using the pre-transaction state hash, the node can use the entire epoch interval to calculate the hash. For example, assuming the state hash calculation processes 10M state data per second, then computing the entire state of 600 GB will take 600 GB / 10 M ~ 16.67 hours (vs. epoch = 14 weeks)
The process of calculating the pre-state hash is as follows:
1. When a snapshot block is received and finalized, its KV state is snapshotted and a background thread is created to iterate over all KV entries (addresses => accounts) and calculate the hash.
2. When the next snapshot block is created, the calculated pre-state hash value will be stored in that block. Likewise, the node will create another snapshot of the KV and calculate its hash in the background.
3. When the next snapshot block is created, in addition to storing the pre-state hash, the node can now release the KV snapshot of the snapshot block, which means that all deleted/updated data from the snapshot block will be automatically Garbage collection (eg compaction in levelDB)
secondary title
Block storage optimization
Using snapshot blocks, we can further reduce the required block data in the node by only storing:
The state snapshot before transaction execution of the latest snapshot block, that is, (latest — 1) state after transaction execution of the snapshot block
(latest — 1) the full block after the snapshot block
We can do simple math on the storage cost: assuming an epoch duration of 2 weeks, the block resize is
2 * 14 (days) * 24 (hours) * 3600 (seconds) * 100 * 1000 (TPS) = 224 GB!
Summarize
Summarize
We analyzed Ethereum's current storage usage:
Not only blocks, state storage consumes a lot of space
When TPS > 1000, storage usage is prohibitively high
We propose to optimize blocks and state:
Block size reduced from 2.86 TB to 224 GB per year
State size (~10B accounts) reduced from 8.3 TB to 600 GB
A 2TB normal config computer should suffice for long running nodes
thank you
thank you
Thanks to dapp-learning for hosting this event.


