
【Consensus Column】HotStuff Consensus
—— Preface——
We have learned that distributed systems generally achieve consistency through the principle of state replicator [1]. The core idea is that all replicas in the system run the same state machine, as long as all replicas start with the same initial state and perform a set of operations in the same sequence based on the same initial state, then all states will eventually converge. , that is, the entire system exhibits consistency externally. Determining this group of operations in the same order requires the system to reach a consensus. Further, all honest nodes reach a consensus on the execution order. This is the famous Byzantine Generals [2] problem.
The theoretical security guarantee of the Byzantine consensus algorithm, that is, n>3f, n is the total number of nodes, and f is the number of malicious nodes. A Byzantine consensus algorithm needs to guarantee two properties:
Security: All honest nodes believe that the system state is s at a certain moment
Activity: All honest nodes can finally determine s as the system state
Among them, s is an abstract concept. It can be understood that there is a variable S in the system. The value of this variable S is the system state. The nodes in the system receive a series of operation instructions about S. At a certain moment (assuming that there is no error in the clock of each node ) Consensus on the value of S, all honest nodes determine the variable S=s to meet security, all honest nodes must make a decision on the value of variable S and terminate to meet liveness.
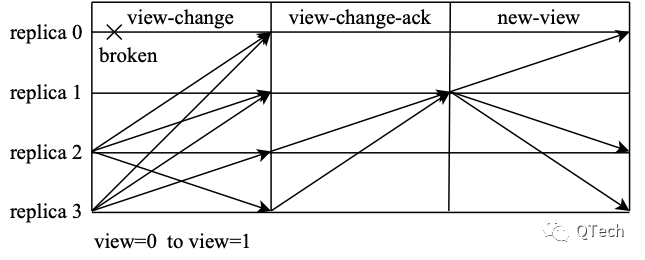
In the past, in the research of distributed systems, Byzantine consensus was often accompanied by high communication complexity, which caused great consumption of the network, and the scale of the system was not easy to expand. For example, in the classic PBFT algorithm, it needs to go through three stages to reach a consensus. In the PRE-PREPARE stage, the master node sends the request message to other nodes. After the other nodes verify the message, they send prepare messages to other nodes. This stage generates n ^2 messages. In order to ensure consistency across views, a node sends a commit message to other nodes after receiving at least quorum prepare messages. When the node finally receives a commit message of at least quorum, it finally submits the request. However, when a network abnormal node times out and triggers view switching, a communication complexity of o(n^3) is required
Understanding the work of each stage in PBFT is the basis of HotStuff, and the goal of each stage in PBFT is to ensure safety and liveness.
Assuming that the system receives the command S'=S+1 at a certain moment, the master node sends this command S'=S+1 to the non-master node (this is a pre-prepare message), because it is a Byzantine problem, the honest node is not sure about itself Whether the received message is consistent with other honest nodes (the master node sends an inconsistent message), and the nodes need to communicate with each other once to ensure that the message received by themselves and other honest nodes is consistent (determine that the master node has not sent an inconsistent message), each node Send the prepare message to all other nodes, and if you receive quorum prepare messages and pass the verification (verify that the instructions pointed to in prepare are consistent with yourself), the first round of consensus is reached (this is the PREPARE stage). At this point, it seems that the messages received by the honest nodes are consistent. But the implicit condition here is that the nodes that have reached consensus only see it from their own perspective: I have received and verified quorum consistent messages. However, other nodes may not necessarily receive quorum prepare messages to reach a consensus. If the submission is made at this time and a network failure occurs, the submitted node knows that a consensus has been reached. As long as the network recovers, this instruction will definitely be accepted by the entire system. submit. However, other nodes may not have reached a consensus due to network failure, and they cannot be sure whether they can submit after waiting. In order to keep the system alive, view switching is performed, and at this time the new master node needs to determine whether to execute new instructions on the basis of S' or S. If it is not found that some nodes have submitted the instruction, and another instruction S''=S+2 has been agreed and submitted, the system will have an inconsistency in the value of the variable S. Therefore, there are security issues to submit at this time.
If another stage of consensus is carried out, after the PREPARE consensus is reached, each will send another commit message, and each node will wait to accept and verify quorum commit messages before submitting. They will encounter the same problem. The nodes that have reached the COMMIT consensus have submitted. They know that if the network is normal, the system will submit sooner or later, but other nodes that have not reached the COMMIT consensus are not sure whether they can submit in the end. After a network failure occurs, if the master node in the new view does not find the submitted nodes, it will still cause inconsistencies. The contradiction here is that we need to switch views to continue the consensus for activity; for security, we also need to ensure that the value of S is consistent before the new view starts consensus, and the submitted instructions must also be submitted in the new view. In PBFT, the method of sending a message to other nodes to prove the state of its own S when the view is switched is used, that is, sending a pre-prepare message of its latest S and corresponding quorum prepare messages. When the view is switched, the new master node can judge whether S'=S+1 needs to be submitted before the consensus.
If no node reaches a consensus on PREPARE for S'=S+1, it will not continue to submit S'=S+1.
If there is a node pair that reached a consensus on the PREPARE phase of S'=S+1, it is impossible to reach a consensus on a conflicting instruction S''=S+2 and submit it.
According to this rule, the security and activity are guaranteed, but the complexity brought by this method is o(n^3). Therefore, the algorithm still cannot be used in large-scale networks. The HotStuff consensus algorithm [4] proposed by Yin Maofan et al. has the characteristics of linear view change, which solves the bottleneck of classic PBFT or even BFT consensus. The switch of the master node does not need to increase other protocols and costs, and the system can still perform consistent external work. It reduces the communication complexity of the consensus process to o(n).
——HotStuff basic concept——
Understanding the hotstuff algorithm requires introducing several concepts related to the consensus process:
1) Threshold signatures [5] (Threshold signatures): A (k, n) threshold signature scheme refers to a signature group composed of n members, all members share a common key, and each member has its own private key. As long as the signatures of k members are collected and a complete signature is generated, the signature can be verified by the public key.
2) Certificate (Quorum Certificate, QC): After the master node receives at least quorum node pairs voting messages (with signatures) for a proposal, it uses the threshold signature to synthesize a QC. This QC can be understood as the complete threshold signature generated Signature means that a consensus has been reached on the proposal.
3) View: View is the basic unit of consensus. A view can reach a consensus at most once, and it increases monotonically. Each view gradually rotates to advance the consensus.
4) Consensus state tree: each consensus block can be regarded as a tree node, each tree node contains the corresponding proposal content (the previous operation instructions) and the corresponding QC, and each tree node contains a parent tree node hash to form a tree structure, and the master node generates new tree nodes based on the longest local branch. A lagging node synchronizes intermediate missing tree nodes against the latest tree nodes on the longest branches of other nodes.
—— HotStuff Consensus Process ——
text
▲ Basic Hotstuff
Basic HotStuff is the basic process of consensus. Among them, the view is continuously switched in a monotonically increasing manner. Each view has a unique master node responsible for proposals, collecting and forwarding messages and generating QC. The whole process includes 4 stages: preparation stage (PREPARE), pre-submission stage (PRE-COMMIT), submission stage (COMMIT), In the decision stage (DECIDE), the master node submits (reaches a consensus) a certain branch, collects voting messages with signatures from quorum consensus nodes in the three stages of PREPARE, PRE-COMMIT, and COMMIT, uses the threshold signature to synthesize a QC, and then broadcasts it to other node.
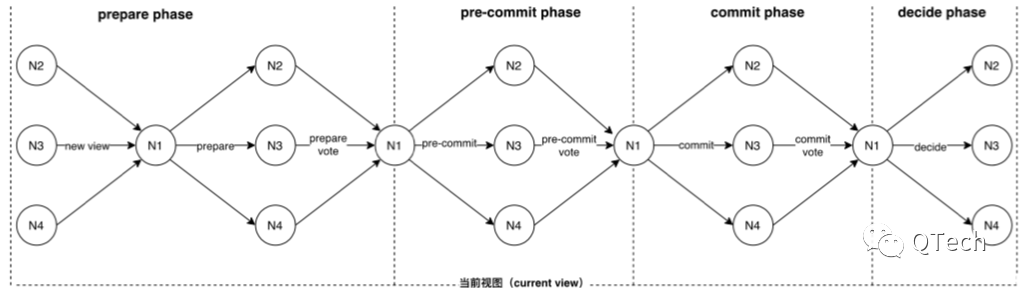
Combined with threshold signatures, HotStuff can convert the previous method of broadcasting consensus messages to the master node for processing, merging and forwarding, and the communication complexity can be reduced to o(n). In short, HotStuff uses threshold signatures + two rounds of communication to achieve The consensus effect of a round of PBFT communication.
Compared with the PBFT algorithm, the consensus starts when the master node sends the request to other nodes in the pre-prepare. The master node has fulfilled the responsibility of this round of consensus, and then it is the same as other nodes. The whole consensus process includes a broadcast proposal phase (PRE-PREPARE phase) and two consensus phases (PREPARE phase, COMMIT phase).
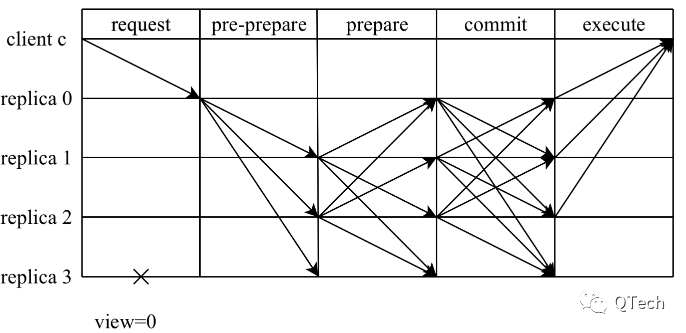
PREPARE stage:
Master node: 1) According to the received quorum New-View message, which contains the prepareQC with the highest height in the sender's state tree, the master node calculates the highest height QC from the received prepareQC, which is recorded as highQC ;
2) According to the branch pointed to by the highQC node, pack the block to create a new tree node, and its parent node is the node pointed to by highQC;
3) Send the generated proposal to other slave nodes in the prepare message, and the current proposal contains highQC.
Slave node: 1) After receiving the prepare message, verify the information in the prepare, including the validity of the signature in qc; whether it is the proposal of the current view;
2) Whether the node in the prepare message is extended from the branch of lockedQC (that is, the child node) or the view number of highQC in the prepare message is greater than that of lockedQC (the former is a security condition, and the latter is an active condition to ensure timely synchronization when the node lags behind);
3) Generate a prepare-vote message and send it to the master node with a signature.
PRE-COMMIT stage:
When the master node receives quorum prepare-vote messages for the current proposal, prepareQC is obtained by aggregating quorum partial signatures; then the master node broadcasts the pre-commit message with the aggregated prepareQC.
Slave node: other nodes receive the pre-commit message, and after verification, send a pre-commit vote message to the master node.
⚠️Note that at this time, the prepareQC in the pre-commit sent by the master node indicates the proposal message in the prepare message, and all nodes voted to successfully reach a consensus. This moment is similar to the consensus reached in the PREPARE stage in PBFT.
Commit stage:
Master node: Similar to the pre-commit stage. 1) The master node first collects quorum pre-commit vote messages, then aggregates the pre-commitQC of this stage, and sends it to other nodes in the commit message. 2) Set the local lockedQC to pre-commitQC.
Slave node: When the commit message is received, the message verification is passed and the local lockedQC is also updated as the pre-commitQC in the commit message, and it is signed and a commit vote is generated and sent to the master node
⚠️Note that at this time, the pre-commitQC attached to the commit message sent by the master node is similar to the second round of COMMIT phase consensus in PBFT, where the consensus of this phase in PBFT indicates the consensus of the first phase of the node pair to reach a consensus , that is to ensure that at least quorum nodes have completed the PREPARE phase, and when a view switch occurs, enough nodes can prove that the PREPARE consensus has been reached on the proposal, and the proposal content needs to be submitted in the new view.
DECIDE stage:
Master node: 1) When quorum commit vote messages are collected, commitQC is aggregated and sent to other nodes in the decide message;
2) When other nodes receive the decide message, the transaction in the proposal pointed to by commitQC will be executed;
3) Then increase the view number viewnumber, start the next round of consensus, and construct the New-View message according to prepareQC.
Slave node: After verifying the message, execute the transaction of the tree node pointed to by commitQC in the decide message.
nextView interrupt stage: If a timeout event occurs in any other stage of the consensus, sending a new-view message for a new view will directly start the next round of new consensus.
text
▲ Chained HotStuff
It can be found that the processes of each stage in Basic HotStuff are highly similar. The author of HotStuff proposed Chained HotStuff to simplify the message type of Basic HotStuff and allow each stage of Basic HotStuff to process transactions in a pipelined manner.
The process of Chained HotStuff is as follows:
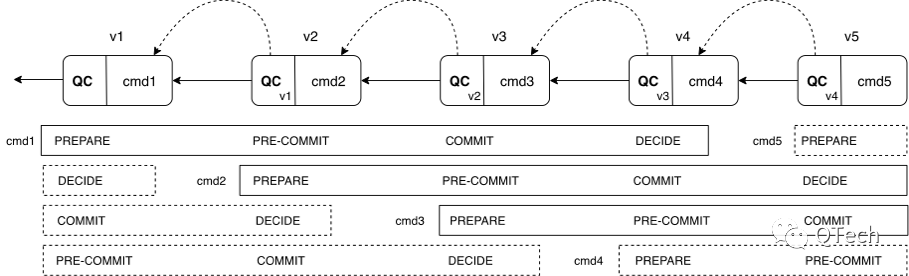
As can be seen from the figure, each stage switches views, so each proposal has its own view. Nodes are in different views for different proposals. The votes in the PREPARE stage are synthesized into QC by the master node of the current view and forwarded to the master node of the next view. Proceed to the PRE-COMMIT phase of the previous view. Each phase has a similar structure, and the PREPARE phase of view v+1 can be regarded as the PRE-COMMIT phase of view v. The PREPARE phase of view v+2 is regarded as the PRE-COMMIT phase of view v+1 and the COMMIT phase of view v. cmd1 in v1 will perform PREPARE, PRE-COMMIT, and COMMIT phases in views v1, v2, and v3 respectively, and commit in v4. cmd2 and so on. The generation of cmd proposals in each stage will be accompanied by the QC voted in the previous stage. The working process of the streamlined version of HotStuff is as follows:
Master node: 1) Wait for the NEW-VIEW message and send out its own proposal;
2) Waiting for other nodes to vote;
3) Send a NEW-VIEW message to the next master node.
Slave node: 1) Wait for the proposal message from the master node;
2) Check the QC in the proposal, update the local highQC, lockedQC, and send votes;
3) Send a NEW-VIEW message to the next master node.
▲ Event-driven HotStuff
From Chained HotStuff to Event-driven HotStuff, the original paper decouples the safety (safety) and liveness (liveness) of the entire protocol, and the liveness becomes a separate pacemaker module. The pacemaker module guarantees liveness after the Global Stability Time (GST). Provides two functions:
Select and verify the primary node for each view.
Help masternodes generate proposals.
In other words, with such a low view switching cost, any suitable node rotation mechanism and any proposal generation strategy can be adopted in pacemaker.
The principle of Event-driven Hotstuff and other versions is still the core three-stage consensus. The difference is only the convenience of engineering implementation. For details, see the pseudocode of the paper [4]
secondary title
Activity Mechanism Optimization
The active mechanism is the key to the continuous advancement of the consensus. In the original HotStuff paper, the liveness mechanism used a globally consistent timeout to determine the view timeout. In NoxBFT, we have designed a more flexible mechanism to cope with the instability of the network environment.
secondary title
transaction buffer pool
In the application of blockchain, in order to avoid transaction loss, we have designed a transaction cache pool to cache client transactions. The consensus module actively pulls transactions for packaging. The transaction pool can also reduce the consensus workload and deduplicate transactions. We identify transactions through the transaction content hash, and write the executed transactions into the Bloom filter to prevent double-spending attacks and improve the stability of the consensus algorithm.
fast recovery mechanism
An unstable network environment may cause consensus nodes to lose consensus messages, causing nodes to fall behind. In the original HotStuff paper, the author left the specific implementation of this part to developers. We have implemented the synchronization algorithm available in the project to restore the ordering function of the lagging consensus nodes, which is divided into two steps:
1) The node lags far behind, and directly pulls blocks from other nodes to restore to the latest checkpoint.
2) The consensus progress after the checkpoint falls behind, and the latest CommitQC is pulled from other nodes to quickly restore the consensus progress.
In order to improve efficiency, we adopt a mechanism to pull blocks from different nodes in parallel, and the degree of parallelism can be flexibly configured. The blocks pulled in parallel are first persisted and then executed in an orderly manner. At the same time, the scores of each node's pulling efficiency are recorded, so that the target node can be efficiently selected for synchronization next time. The whole process can pull all lost transactions at the fastest speed, reducing the waiting time of the whole process.
aggregate signature
Summarize
Summarize
About the Author
About the Author
Cheng Taining
references
references
[1] Schneider F B . The state machine approach: A tutorial[J]. Springer New York, 1990.
[2] Lamport L , Shostak R , Pease M . The Byzantine Generals Problem[J]. ACM Transactions on Programming Languages and Systems, 1982, 4(3).
[3] Castro M, Liskov B. Practical Byzantine fault tolerance[C]. OSDI.1999, 99(1999): 173-186.
[4] Yin M , Malkhi D , Reiter M K , et al. HotStuff: BFT Consensus in the Lens of Blockchain[J]. 2018.
[5] Shoup V . Practical Threshold Signatures[C]// International Conference on Theory & Application of Cryptographic Techniques. Springer-Verlag, 2000.


