
[Consensus Column] Quorum Mechanism and PBFT
text
Practical Byzantine Fault Tolerance (PBFT) is a practical method to solve the Byzantine generals problem when the channel is reliable. The Byzantine Generals Problem was first proposed by Leslie Lamport et al. in a paper [1] published in 1982. In the paper, it was proved that when the total number of generals n is greater than 3f and the number of defectors is f or less, loyal generals can reach a consensus on orders, namely 3f+1<=n, the algorithm complexity is O(n^(f+1)). Subsequently, Miguel Castro and Barbara Liskov first proposed the PBFT algorithm in the paper [2] published in 1999. The number of fault tolerance of the algorithm also satisfies 3f+1<=n, and the algorithm complexity is reduced to O(n^2).
If you have an understanding of the PBFT consensus algorithm, you may be familiar with the relationship between the total number of nodes n and the upper limit of fault tolerance f: under the premise that there are at most f faulty nodes in the system, the total number of nodes n in the system should satisfy n>3f. In the process of advancing the consensus, a certain number of votes need to be collected to complete the certification process. In this section, we will first discuss how the relationship between these values can be derived.
--Quorum Mechanism--
In a distributed storage system with redundant data, redundant data objects will store multiple copies between different machines. But at the same time, multiple copies of a data object can only be used for reading or writing. In order to maintain data redundancy and consistency, a corresponding voting mechanism is required to maintain it, which is the Quorum mechanism. As a distributed system, blockchain also needs this mechanism for cluster maintenance.
In order to better understand the Quorum mechanism, let's first understand a similar but more extreme voting mechanism - WARO mechanism (Write All Read One). When using the WARO mechanism to maintain a cluster with a total number of nodes of n, the "votes" for nodes to perform write operations should be n, while the "votes" for read operations can be set to 1. That is to say, when performing a write operation, it is necessary to ensure that all nodes complete the write operation before the operation can be regarded as complete, otherwise the write operation will fail; correspondingly, when performing a read operation, only the state of one node needs to be read, You can check the system status. It can be seen that in the cluster using the WARO mechanism, the execution of the write operation is very fragile: as long as one node fails to perform the write, the operation cannot be completed. However, although the robustness of write operations is sacrificed, under the WARO mechanism, it is very easy to perform read operations on the cluster.
The Quorum mechanism [3] is a compromise consideration for read and write operations. For each copy of the same data object, no more than two access objects will be read and written, and the set size requirements for reading and writing are weighed. In a distributed cluster, each data copy object is given a vote. Assumptions:
There are V tickets in the system, which means that a data object has V redundant copies;
For each read operation, the number of votes obtained must not be less than the minimum number of read votes R (read quorum) to be successfully read;
For each write operation, the number of votes obtained must not be less than the minimum number of write votes W (write quorum) to be successfully written.
For the consensus nodes in the cluster, when advancing the consensus algorithm, the nodes participating in the consensus will simultaneously perform read and write operations on the cluster. In order to balance the requirements of read and write operations on the size of the collection, R and W of each node take the same size, denoted as Q. When there are a total of n nodes in the cluster, and there are at most f error nodes, how do we calculate the relationship between n, f, and Q? Next, we will start from the simplest CFT scenario and gradually explore how to obtain the relationship between these numerical values in the BFT scenario.
▲CFT
text
CFT (Crash Fault Tolerance), means that the nodes in the system will only experience the error behavior of crash (Crash), and no node will actively send out error messages. When we discuss the reliability of consensus algorithms, we usually focus on two basic properties of algorithms: liveness and safety. When calculating the size of Q, it can also be considered from these two angles.
For activity and security, there is a more intuitive way to describe:
something eventually happens[4], an event will eventually happen
something good eventually happens[4], this event that will eventually happen is reasonable
From the perspective of activity, our cluster needs to be able to continue to run, and the consensus cannot be continued due to errors of some nodes. From the perspective of security, our cluster can continue to obtain a reasonable result in the process of consensus promotion. For distributed systems, the most basic requirement for this "reasonable" result is the overall state of the cluster. consistency.
Therefore, in the CFT scenario, the determination of the Q value becomes simple and clear:<=n-f。
Activity: Since we need to ensure that the cluster can continue to run, we must ensure the possibility of obtaining Q tickets in any scenario, so as to read and write data for the collection. Since at most f nodes in the cluster will be down, in order to ensure that Q tickets can be obtained, the size of this value needs to satisfy: Q
▲BFT
Security: Since we need to ensure that the cluster does not diverge, according to the basic requirements of the Quorum mechanism, the two inequalities mentioned in the previous section need to be met, and Q is brought into this set of inequalities as the minimum read set and the minimum write set , at this time, Q satisfies the inequality relationship, Q+Q>n and Q>n/2, therefore, the size of this value needs to satisfy: Q>n/2.
BFT (Byzantine Fault Tolerance), which means that the wrong nodes in the cluster may not only go down, but also have malicious behaviors, that is, Byzantine behaviors, such as active state forks. In this case, for the cluster as a whole, only nf nodes are in a reliable state, and when we collect Q votes, only Qf votes come from reliable nodes. Therefore, in terms of security, in the BFT scenario, it is necessary to ensure that there will be no divergence between nodes with reliable states, so the following two relationships are obtained:<=n-f。
Activity: It is still only necessary to ensure that there is a possibility of obtaining Q tickets at all times, therefore, Q
▲The total number of nodes and the upper limit of fault tolerance
text
For the total number of nodes n and the upper limit of fault tolerance f, the explanation given in the PBFT paper [1]: Since there are f nodes that may be down, we need to respond when we receive nf messages at least, and for us to receive The messages from nf nodes, since there may be at most f messages from unreliable Byzantine nodes, it needs to satisfy nff>f, so, n>3f.To put it simply, the author of PBFT obtained the relationship between the total number of nodes and the upper limit of fault tolerance from the perspective of cluster activity and security. In the previous section, we also obtained the relationship between n, f and Q from the perspective of activity and security, which can also be used to derive the relationship between n and f here: in order to meet the requirements of activity and security at the same time, Q needs to satisfy Inequality relationship, Q<=nf and Q>(n+f)/2, therefore, the inequality relationship between n and f can be obtained, (n+f)/2
(In a similar way, the relationship between n and f in the CFT scene can also be obtained, n>2f.)
--PBFT and RBFT--
After understanding the relationship between n, f, and Q in the BFT scenario, let's move on to the introduction of PBFT. Before that, briefly mention the SMR (State Machine Replication) replication state machine [5]. In this model, for different state machines, if they start from the same initial state and input the same instruction set in the same order, then they will always get the same final result. For the consensus algorithm, it only needs to ensure that "the same instructions are entered in the same order" to obtain the same state on each state machine. PBFT is the consensus on the order of instruction execution.
▲ Two-stage consensus
text
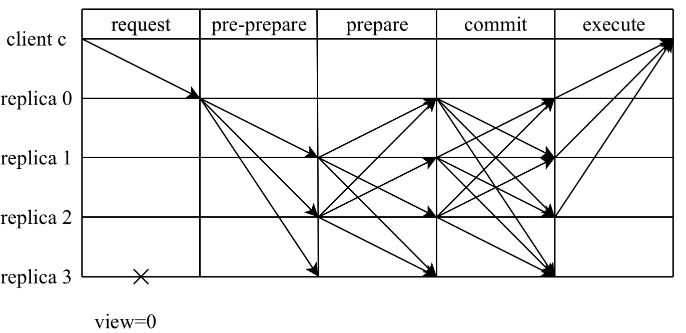
Compared with the more common "three-stage" concept (pre-preapre, prepare, commit), viewing PBFT as a two-stage consensus protocol may better reflect the purpose of each stage: proposal stage (pre-prepare and prepare) and commit stage (commit). In each stage, each node needs to collect unanimous votes from Q nodes before entering the next stage. For easier discussion, here we will discuss the scenario when the total number of nodes is 3f+1. At this time, the number of read and write tickets Q is 2f+1.
1) Proposal stage
In this phase, the master node sends pre-prepare to initiate consensus, and the slave node sends prepare to confirm the proposal of the master node. After receiving the request from the client, the master node will actively broadcast the pre-prepare message to other nodes
v is the current view
n The request sequence number assigned by the master node
D(m) is the message digest
m is the message itself
After receiving the pre-prepare message, the slave node will verify the validity of the message. If the verification is passed, the node will enter the pre-prepared state, indicating that the request has passed the legality verification at the slave node. Otherwise, the slave node will reject the request and trigger the view switching process. When the slave node enters the pre-prepared state, it will broadcast the prepare message to other nodes
i is the current node identification number
After other nodes receive the message, if the request has entered the pre-prepared state at the current node, and receives 2f corresponding prepare messages (including itself) from different nodes, it enters the prepared state, and the proposal phase is completed. At this time, 2f+1 nodes agree to assign sequence number n to message m, which means that the consensus cluster has assigned sequence number n to message m.
2) Submission phase
▲Checkpoint mechanism
text
During the operation of the PBFT consensus algorithm, a large amount of consensus data will be generated, so it is necessary to implement a reasonable garbage collection mechanism to clean up redundant consensus data in a timely manner. In order to achieve this goal, the PBFT algorithm designs a checkpoint process for garbage collection.
Checkpoint is a checkpoint, which is the process of checking whether the cluster has entered a stable state. When checking, nodes broadcast checkpoint messages
n is the current request sequence number
d is the digest obtained after message execution
i represents the current node
After the checkpoint message, it can be considered that the current cluster has entered a stable checkpoint (stable checkpoint) for sequence number n. At this point, the consensus data before the stable checkpoint will no longer be needed and can be cleaned up. However, if checkpoints are frequently executed for garbage collection, it will bring a significant burden to the system operation. Therefore, PBFT designs an execution interval for the checkpoint process, and after every k requests are executed, the node will actively initiate a checkpoint to obtain the latest stable checkpoint.
In addition, PBFT introduces the concept of high/low watermarks to assist in garbage collection. During the consensus process, due to the performance gap between nodes, there may be a situation where the operating speed difference between nodes is too large. The sequence numbers executed by some nodes may be ahead of other nodes, resulting in the consensus data of the leading nodes not being cleared for a long time, resulting in the problem of excessive memory usage, and the function of high and low water levels is to limit the overall running speed of the cluster, thus The consensus data size of the nodes is limited.
▲View change
text
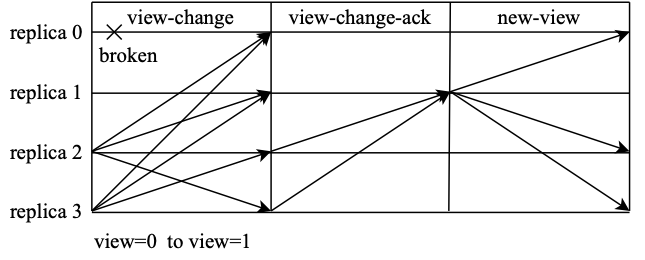
A view-change is triggered when the master node times out and does not respond or when the slave nodes collectively believe that the master node is a problem node. After the view change is completed, the view number will increase by 1, and then the master node will switch to the next node. As shown in the figure, an exception occurs on node 0 to trigger the view change process. After the change is completed, node 1 becomes the new primary node.
When a view change occurs, the node will actively enter the new view v+1, and broadcast a view-change message, requesting to switch the master node. At this point, the consensus cluster needs to ensure that requests that have completed consensus in the old view can be retained in the new view. Therefore, in the view change request, it is generally necessary to add part of the consensus log in the old view, and the request broadcast by the node is
i is the identity of the sender node
v+1 indicates the new view that the request enters
h is the height of the latest stable checkpoint of the current node
Stored in the same way, it means that the current node has executed the checkpoint check with sequence number n and digest d, and sent the corresponding consensus message.
Stored in the same way, it means that in the view v, the request whose summary is d and whose sequence number is n has entered the prepared state. Since the request has reached the prepared state, it means that at least 2f+1 nodes own and approve the request, and the consistency confirmation can be completed only in the commit stage. Therefore, in the new view, this part of the message can directly use the original sequence number , without assigning a new sequence number.
way to store. Since the request has entered the pre-prepared state, it means that the request has been approved by the current node.
However, after receiving the view-change message sent by other nodes, the new primary node P corresponding to view v+1 cannot confirm whether the view-change message is sent by the Byzantine node, and cannot guarantee that it must use the correct message for decision-making. PBFT allows all nodes to check and confirm all the view-change messages it receives through the view-change-ack message, and then sends the confirmed result to P. Master node P counts view-change-ack messages, and can identify which view-changes are correct and which are sent by Byzantine nodes.
When the node confirms the view-change message, it will check the P and Q sets in it, and the request message in the set is required to be less than or equal to view v. If the requirements are met, the view-change-ack message will be sent
i is the node ID that sent the ack message
j is the sender ID of the view-change message to be confirmed
d is the digest of the view-change message to acknowledge
Different from the broadcast of general messages, the digital signature is no longer used to identify the sender of the message, but the session key is used to ensure the credibility of the communication between the current node and the master node, thereby helping the master node to judge the credibility of the view-change message.
The new primary node P maintains a set S to store the verified correct view-change message. When P obtains a view-change message and a total of 2f-1 corresponding view-change-ack messages, it will add this view-change message to the set S. When the size of the set S reaches 2f+1, it proves that there are enough non-Byzantine nodes to initiate view changes. The master node P will generate a new-view message and broadcast it according to the received view-change message.
It means that the digest of the view-change message sent by node i is d, which corresponds to the messages in the set S, and other nodes can use the digest and node ID in the set to confirm the legitimacy of the view change.
X: Contains stable checkpoints and requests to opt into new views. The new primary node P will calculate according to the view-change message of S in the set, determine the maximum stable checkpoint and the request that needs to be kept in the new view according to the set of C, P, and Q, and write it into the set X Among them, the specific selection process is relatively cumbersome. If you are interested, readers can refer to the original paper [6].
▲Improvement space and RBFT
RBFT (Robust Byzantine Fault Tolerance) is a highly robust consensus algorithm developed by Qulian Technology based on PBFT for the enterprise-level alliance chain platform. Compared with PBFT, we have optimized and improved consensus message processing, node state recovery, cluster dynamic maintenance and other aspects, so that the RBFT consensus algorithm can cope with more complex and diverse actual scenarios.
1) Trading pool
In the industrial implementation of many consensus algorithms, including RBFT, an independent transaction pool module is designed. After receiving the transaction, the transaction itself is stored in the transaction pool, and the transaction is shared through the transaction pool, so that each consensus node can obtain the shared transaction. In the consensus process, only the transaction hash needs to be consensused.
When dealing with large transactions, the transaction pool has a good improvement in the stability of the consensus. Decoupling the transaction pool from the consensus algorithm itself makes it easier to implement more functional features through the transaction pool, such as transaction deduplication.
2) Active Recovery
In PBFT, when a node finds that its own low water level is behind through checkpoint or view-change, that is, when the stable checkpoint is behind, the lagging node will trigger the corresponding recovery process to pull the data before the stable checkpoint. Such a backward recovery mechanism has some disadvantages: on the one hand, the triggering of the recovery process is passive, and the backward recovery can only be triggered when the checkpoint process or triggered view-change is completed; on the other hand, for the backward node, if the checkpoint When it is found that its own stable checkpoint is behind, the backward node can only restore to the latest stable checkpoint, but cannot obtain the consensus message behind the checkpoint, and may not be able to truly participate in the consensus.
In RBFT, we have designed an active node recovery mechanism: on the one hand, the recovery mechanism can be triggered actively to help the lagging nodes to recover faster; on the other hand, on the basis of recovering to the latest stable checkpoint, we design The recovery mechanism between water levels is established, so that lagging nodes can obtain the latest consensus news and participate in the normal consensus process faster.
3) Cluster dynamic maintenance
As a consensus algorithm widely used in engineering, one of the important advantages of Raft is that it can dynamically complete cluster member changes. However, PBFT does not provide a dynamic change scheme for cluster members, which is insufficient in practical applications. In RBFT, we designed a scheme to dynamically change cluster members, so that cluster members can be added or deleted without stopping the cluster as a whole.
When adding or deleting a node, the administrator sends a transaction to the cluster to create a proposal to operate the node, and waits for other administrators to vote. After the vote is passed, the administrator who created the proposal sends the execution proposal configuration transaction to the cluster again, and the cluster will be changed during execution configuration.
For the consensus part, when processing and executing the proposal configuration transaction, the nodes in the cluster will enter the configuration change state and no other transactions will be packaged. The master node packages the transaction separately to generate a configuration package, and agrees on the configuration package. When the configuration package completes consensus, it will be executed and a configuration block will be generated. In order to ensure that the modified configuration block cannot be rolled back, the consensus layer will wait for the execution result of the modified configuration package, and confirm that a stable checkpoint has been formed for the height of the configuration package in the cluster before releasing the configuration status of the node and continuing to package other transactions .
This method of dynamically changing cluster members makes cluster configuration maintenance more reliable and convenient, and provides the possibility to dynamically modify more configuration information.
About the Author
About the Author
Consensus Algorithm Research Group of the Basic Platform Department of FunChain Technology
references
[1] Lamport L, Shostak R, Pease M. The Byzantine generals problem[M]//Concurrency: the Works of Leslie Lamport. 2019: 203-226.
[2] Castro M, Liskov B. Practical Byzantine fault tolerance[C]//OSDI.1999, 99(1999): 173-186.
[3] https://en.wikipedia.org/wiki/Quorum _ (distributed_computing)
[4] Owicki S, Lamport L. Proving liveness properties of concurrent programs[J]. ACM Transactions on Programming Languages and Systems (TOPLAS), 1982, 4(3): 455-495.
[5] Fred B. Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv., 22(4):299–319, 1990.
[6] Castro M, Liskov B. Practical Byzantine fault tolerance andproactive recovery[J]. ACM Transactions on Computer Systems (TOCS), 2002,20(4): 398-461.


