
DeepSeek V4落地後:智譜、MiniMax暴跌,輝達慌了
- 核心觀點:DeepSeek V4模型的發布顛覆了AI資本市場估值邏輯,推動資金從閉源大模型公司轉向國產算力基礎設施,標誌著開源與國產晶片生態雙重拐點的到來。
- 關鍵要素:
- 模型參數:基礎MoE模型1T參數,Flash版本285B,Pro版本1.6T,Apache 2.0開源協議。
- 市場分化:A股算力鏈(寒武紀、海光等)大漲,港股閉源模型公司(智譜、MiniMax)遭做空,輝達溫和盤整。
- 開源優勢:過去30天11個新模型中,V4是首個在性能、價格、開放度三方面全面施壓閉源的旗艦開源模型。
- 國產算力生態:V4實現Day 0全棧適配寒武紀思元590及華為昇騰950PR,部署代碼開源,打破CUDA依賴。
- 性能數據:V4在昇騰超節點上的推理延遲比H100集群低35%,寒武紀晶片FP8算力對標H100且價格更低。
- 生態拐點:vLLM合併非輝達國產GPU後端,中國AI推理需求開始與北美脫鉤,國產替代進入可定價的production階段。
DeepSeek V4 終於上線了。這是一個被等了將近五個月的時刻。1T 參數的 MoE 主模型 + 285B 參數的 Flash 版本,全套 1.6T 的 Pro 版本緊隨其後,完整開源到 GitHub,Apache 2.0 協議,權重和部署程式碼同步釋出。
模型一出來,資本市場就用三種相互獨立又彼此咬合的方式,給出了它們的回答。
資本市場的不同反應
A 股算力鏈這一頭幾乎全線跳漲。寒武紀走出了 11 連陽,單日漲 3.7%,月內累計漲幅突破 60%。海光資訊盤中觸及 10% 漲停,收盤 +8.4%。中芯國際 A 股 +4.91%,港股 +8.81%。華虹港股最高拉到 +18%,收盤 +12%。科創晶片國泰 ETF 單日吸金 24 億元,規模站上歷史高點。
港股大模型公司這一頭是另一種顏色。智譜(02513.HK)跌 8.07%,沽空比例 9.9%。MiniMax(00100.HK)跌 7.40%,沽空比例飆到 22.87%。後者是港股 AI 板塊過去三個月最高的單日做空數據。這兩家公司都是 2025 年下半年港股 AI 上市潮的代表,IPO 招股書裡寫的核心競爭力是同一句話,「自研基座大模型」。
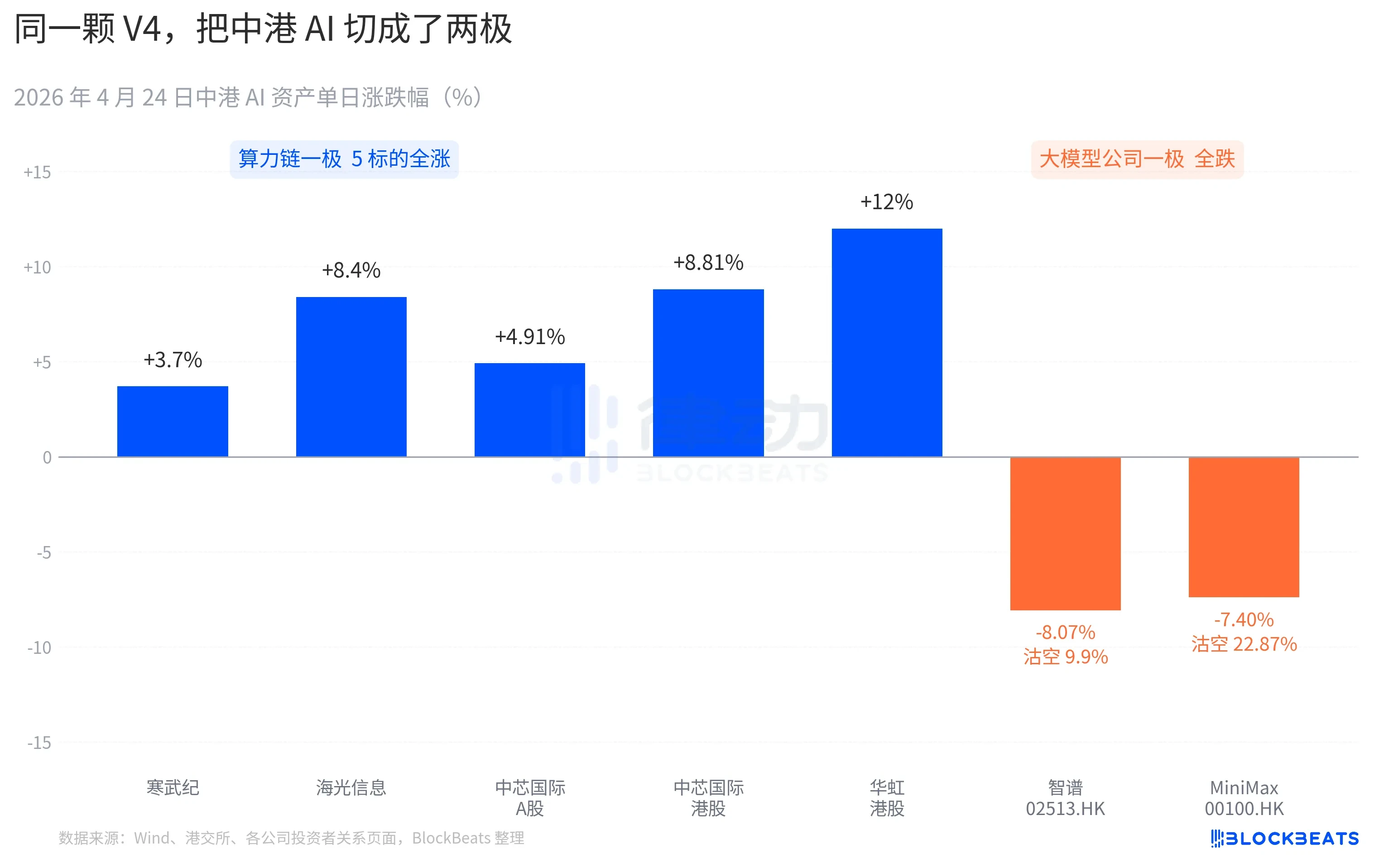
太平洋另一頭的反應同樣具體。輝達昨晚開盤下跌 1.8%,盤中一度跌至 -2.6%,全天收平。彭博的市場速評把這次盤整與 1 月 27 日的 V3「DeepSeek 時刻」做了對比。區別在於,1 月那一次是恐慌式拋售,單日蒸發 6000 億美元市值。這一次更像一次重新計價,量級溫和但方向明確。買方機構的研究紀要裡出現了一句新表述,「中國 AI 推理需求開始與北美 AI 推理需求脫鉤」。
把這三塊盤面疊在一起,就是 V4 落地之後 24 小時之內被市場寫下的第一份判決書。開源勝出之後,錢開始重新選邊,能定價的不再是模型本身,是模型跑在哪塊卡上、裝在哪條產業鏈裡。
30 天 11 個新模型,V4 給開源陣營添一把火
V4 發布的時間視窗本身就是這次反應被放大的部分原因。
把鏡頭拉到過去 30 天。3 月 26 日到 4 月 24 日之間,全球至少有 11 個有顯著影響力的大模型發布或重大更新,名單覆蓋幾乎所有主要玩家。Anthropic Opus 4.6、谷歌 Gemini 3.1 Pro、OpenAI GPT-5.5、Mistral Large 3、Meta Llama 4、月之暗面 Kimi K2.6、阿里 Qwen3-Next、字節豆包 2.5 Pro、騰訊混元 3.0、Kimi K2.6 Plus,最後是 4 月 23 日凌晨發布的 DeepSeek V4。
平均下來,每 2.7 天就有一個新模型出爐。這是連基金經理都來不及讀完發布稿的速度。但翻一遍這 30 天的中港 AI 資產 K 線,能在盤面上留下持續痕跡的只有一個名字。4 月 8 日的 GPT-5.5 帶動輝達單日漲 4.2%,一日見頂。然後是 4 月 23-24 日的 DeepSeek V4,帶動中港算力鏈走出連續跳漲。
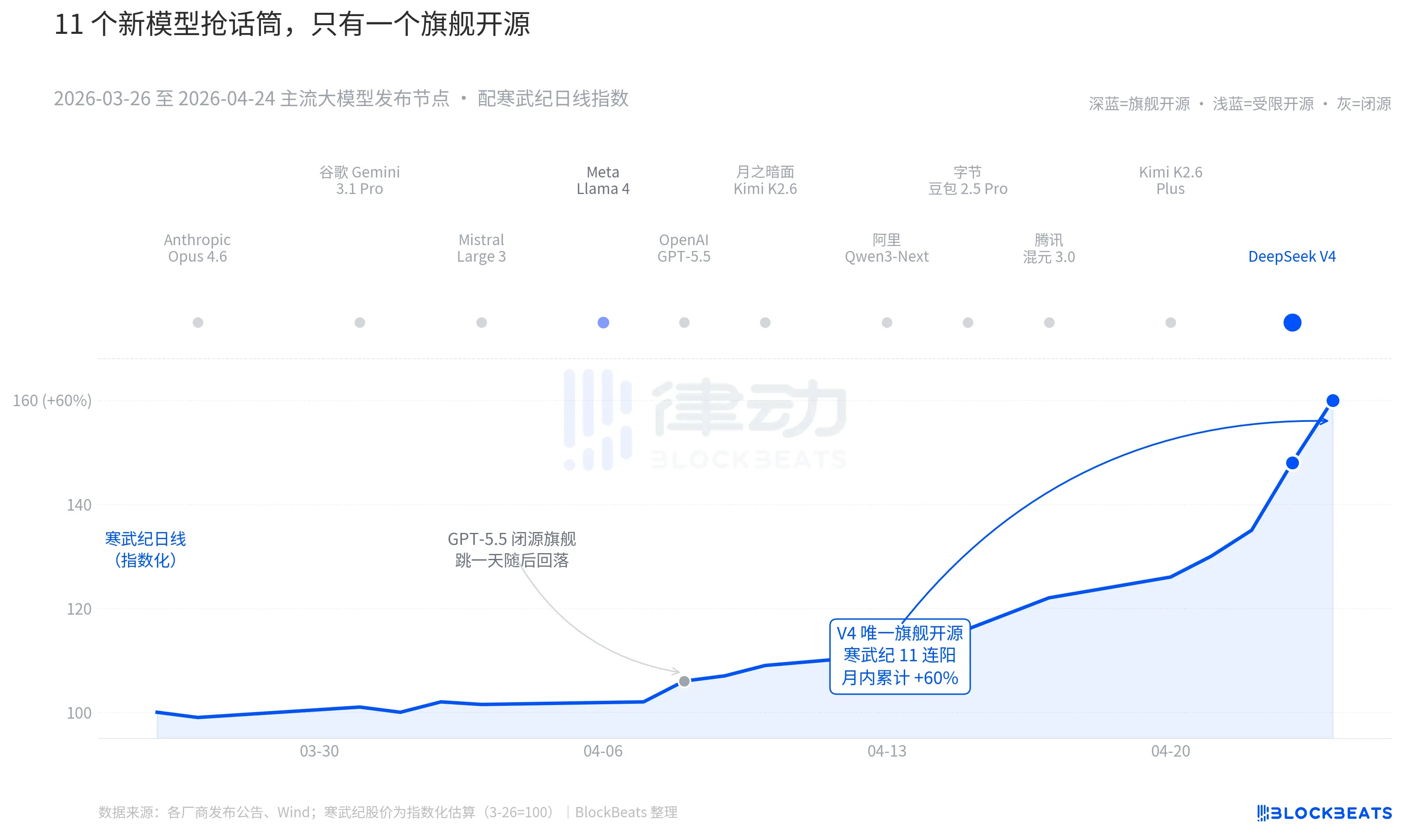
差別不在模型能力本身。這 11 個模型在 LMArena 排行榜上的差距,多數情況下不超過 50 分,處在「同一段位」的窄帶裡。差別在兩件事的疊加。
第一件是開源。前 10 個模型裡只有 Llama 4 開源,但 Llama 4 的權重協議附了一長串商用限制條款,歐美開發者社群評價冷淡,OpenRouter 上線第三天就掉出前十。V4 的協議是 Apache 2.0,權重無門檻、商用無限制、推理程式碼同步釋出。這是過去半年裡第一個讓閉源陣營在性能、價格、開放度三個維度同時承壓的旗艦開源模型。
第二件是時機。在閉源陣營連續放大招的背景下,開源敘事正在被反覆擠壓。Opus 4.6 把程式碼任務的 SWE-Bench 推到新高,GPT-5.5 把每百萬 token 價格定在了 1.25 美元的下沉錨點。開源能不能追上閉源,這場爭論在矽谷已經持續兩年。V4 用一個月活預估衝到 9000 萬的開源旗艦,把這場爭論按下了暫停鍵。
按一位國內大型基金經理在路演裡的說法,「V4 之前我們對開源大模型估值留了一個折扣,V4 之後這個折扣開始反著收。」
DeepSeek 把算力供應鏈的定價表換了一張
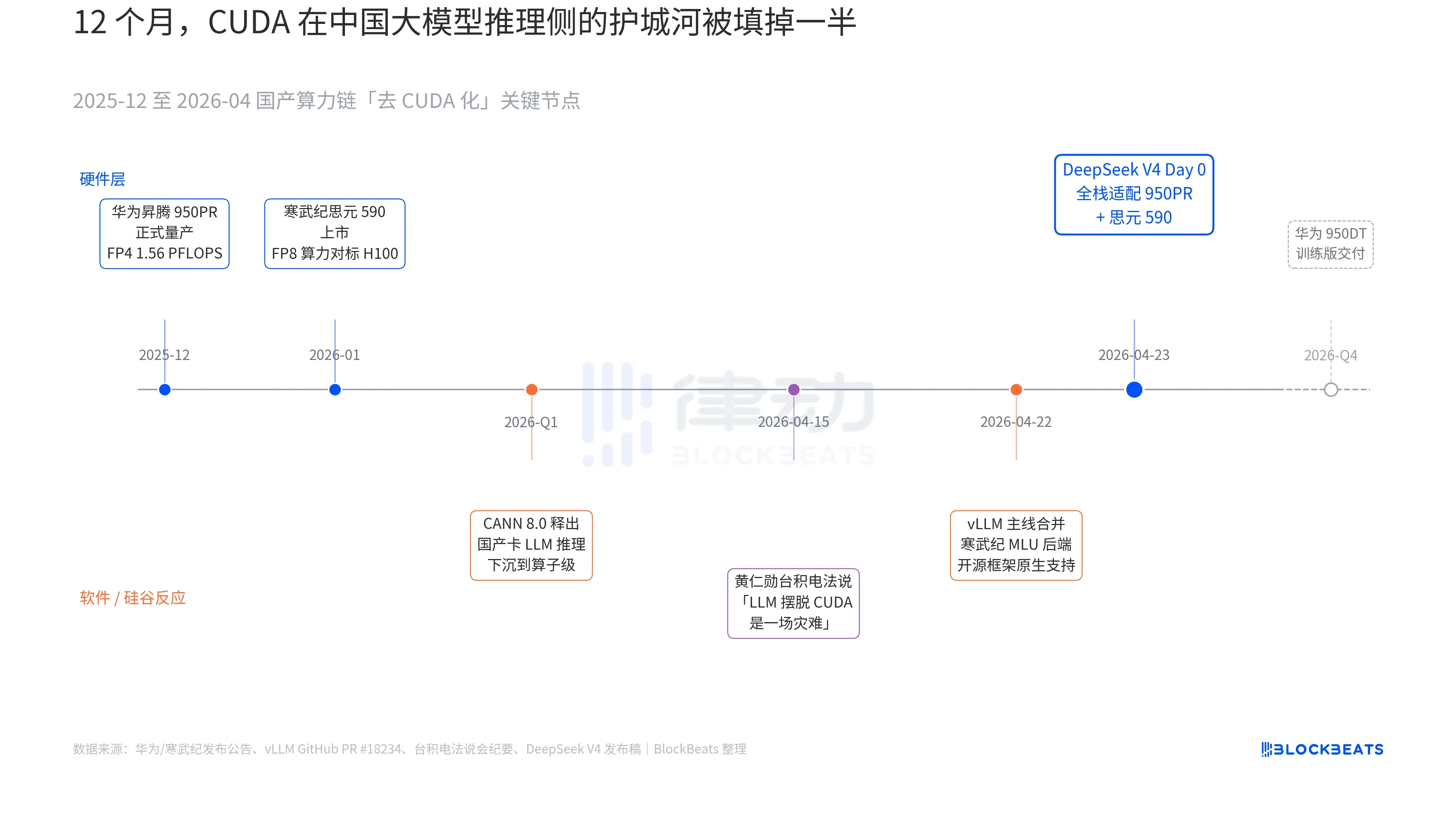
V4 發布稿裡有一行字之前從未出現在任何中國大模型的官方文檔裡:「Day 0 全棧適配寒武紀思元 590 與華為昇騰 950PR,部署程式碼同步開源。」這一行字的分量,要把過去 12 個月裡三條平行展開的暗線接到一起才看得明白。這三條暗線分別屬於硬體、軟體和矽谷的反應。
第一條暗線在晶片側。華為昇騰 950PR 在 2025 年 12 月正式量產,FP4 算力 1.56 PFLOPS,HBM 容量 112GB,是國產 AI 晶片第一次在硬指標上對標輝達 B 系列。在 V4 這種 1T 參數的 MoE 推理任務裡,單卡吞吐較 H20 提升 2.87 倍。配套的 CANN 8.0 軟體棧,把 LLM 推理框架的最佳化下沉到算子級別,DeepSeek 公開的 Benchmark 顯示,V4 在昇騰超節點(8 卡 950PR)上的端到端推理延遲比同等規模的 H100 叢集低 35%。寒武紀思元 590 的數據更激進,單晶片 FP8 算力對標 H100,售價不到一半。
第二條暗線在軟體側。vLLM 主線在 4 月 22 日合併了寒武紀 MLU 後端 PR,開源推理框架第一次原生支援非輝達的國產 GPU。海光資訊的 DCU 透過 ROCm 生態走另一條路,但能把 V4 的 MoE 路由層完整跑通。這意味著 V4 的部署不再是「只能在某家國產卡上跑」,而是「可以在多家國產卡之間選」。生態對單點供應商的依賴被打破,這是 production 的關鍵拐點。
第三條暗線來自矽谷。4 月 15 日,黃仁勳在台積電的法說會上被分析師追問中國國產算力的進展,原話冷峻而具體,「如果他們真的能讓 LLM 擺脫 CUDA,對我們來說會是一場災難(a disaster)」。九天之後,DeepSeek 用一行 Day 0 公告給出了答案。
「國產替代」這四個字在過去三年裡被說濫到失去意義。但 4 月 24 日上午之後,這件事第一次有了可以被資本市場定價的具體數據。單卡吞吐、端到端推理延遲、推理成本、可商用的部署程式碼,悄無聲息地把這場漫長的話術戰推到了 production 的門檻之內。
寒武紀股價 11 連陽的邏輯就藏在這裡。它不再是一隻「國產 GPU 概念股」,而是「DeepSeek V4 推理基礎設施供應商」。同樣的邏輯也可以解釋華虹港股 12% 的漲幅,它代工的是 950PR 的 7nm 等效工藝。每一顆在國產昇騰上跑的 V4 token,都意味著原本要流向輝達和台積電的產能,被部分截留在珠江三角洲。
而下一步早已鋪好。華為路線圖裡,950DT(訓練版)規劃在 2026 年第四季度交付,對應的目標是「V5 或同等量級模型在 1 萬卡叢集上的全棧訓練」。如果這條路能跑通,CUDA 在中國大模型訓練側的護城河,會從「必要」降級為「可選」。


