
世界模型從預測走向規劃,HWM與長時程控制難題
- 核心觀點:世界模型的研究重點正從提升內部預測能力,轉向構建集預測、規劃與驗證於一體的可執行系統能力,以解決長時程、多階段任務中的誤差累積和規劃複雜度難題。
- 關鍵要素:
- V-JEPA 2通過超百萬小時影片預訓練,展示了世界模型在表徵學習與基礎預測上的潛力,為後續規劃提供了基礎。
- HWM通過引入分層規劃結構,將長任務分解為高層階段路徑與底層局部動作,在真實抓取任務中將成功率從0%提升至70%。
- 分層規劃不僅提高了任務成功率,還將部分場景的規劃計算成本降低至原來的四分之一左右。
- WAV模型聚焦於模型對自身預測失真的識別與修正,代表了系統驗證能力的發展方向。
- 研究趨勢表明,世界模型正從單純預測未來,向整合預測、規劃、驗證的系統能力演進,以應對長鏈路、多階段任務的挑戰。
導語
世界模型近一年的研究焦點最初集中在表徵學習和未來預測。模型先理解世界,再在內部推演未來狀態。這條路線已經產出一批有代表性的成果。V-JEPA 2(Video Joint Embedding Predictive Architecture 2——Meta 在 2025 年發佈的一套影片世界模型)用超過 100 萬小時網際網路影片做預訓練,再結合少量機器人互動資料,展示了世界模型在理解、預測和零樣本機器人規劃上的潛力。
但模型會預測,不等於模型會處理長任務。面對多階段控制,系統通常會遇到兩個壓力。一個是預測誤差會在長rollout(連續多步推演)中持續積累,導致整條路徑越來越容易偏離目標。另一個是動作搜尋空間會隨horizon(規劃視距)增長而迅速擴大,導致規劃成本持續上升。HWM 沒有改寫世界模型的底層學習路線,而是在已有帶動作條件的世界模型之上加入分層規劃結構,讓系統先組織階段路徑,再處理局部動作。
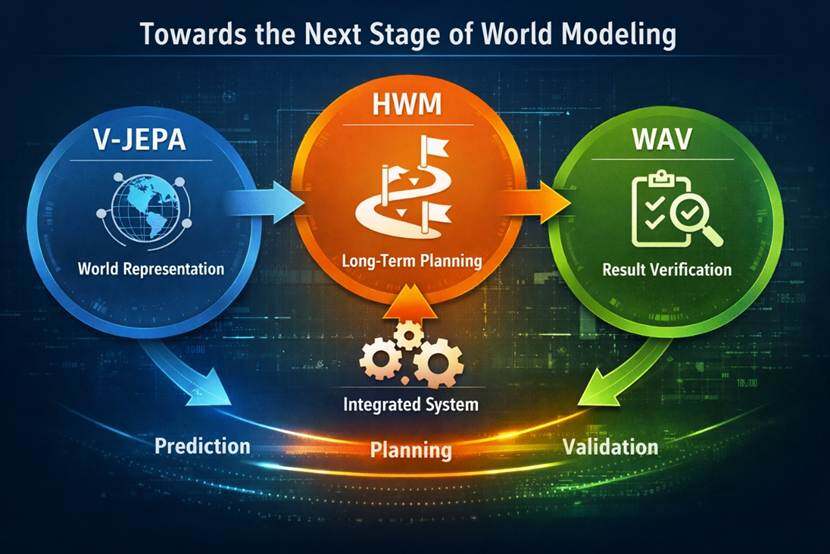
從技術上看,V-JEPA 2(https://ai.meta.com/research/vjepa/) 更偏向世界表徵與基礎預測,HWM 更偏向長時程規劃,WAV (World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry,https://arxiv.org/abs/2604.01985)更偏向模型對自身預測失真的識別與修正。三條線正在逐步收斂。世界模型研究的重點,已經從單純預測未來,轉向如何把預測能力轉成可執行、可修正、可驗證的系統能力。
一、長時程控制為何仍是世界模型的瓶頸
長時程控制的難點,放到機器人任務裡會更容易看清。以機械臂操作為例,抓起一個杯子再把它放進抽屜,這不是單一動作,而是一串連續步驟。系統要靠近物體,調整姿態,完成抓取,移動到目標位置,再處理抽屜和放置。鏈條一長,兩個問題就會同時出現。一是預測誤差會沿著rollout持續積累,另一個是動作搜尋空間會迅速擴大。
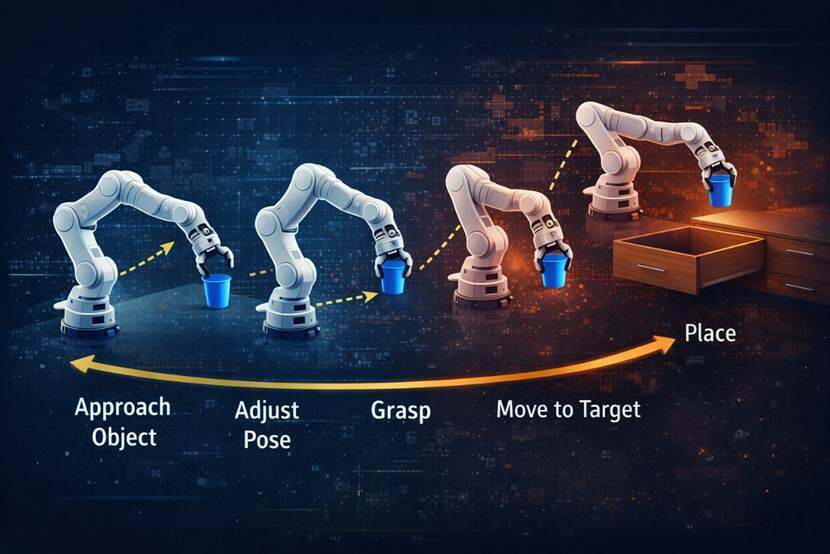
系統缺少的,通常不是局部預測能力,而是把遠目標組織成階段路徑的能力。許多動作從局部看像是在偏離目標,實際卻是完成目標所需的中間步驟。比如抓取前先抬高手臂,開抽屜前先後退一點再調整角度。
在展示型任務中,世界模型已經能夠給出連貫預測。但進入真實控制場景後,效能開始下滑,問題也隨之浮現。壓力不只來自表徵本身,也來自規劃層還不夠成熟。
二、HWM 如何重構規劃過程
HWM把原本一層完成的規劃過程拆成兩層。上層負責較長時間尺度上的階段方向,下層負責較短時間尺度上的局部執行。模型不是只按一個節奏規劃,而是按兩個不同的時間節奏同時規劃。
單層方法處理長任務時,通常需要在底層動作空間裡直接搜尋整條動作鏈。任務越長,搜尋成本越高,預測誤差也越容易沿著多步 rollout 持續擴散。HWM拆開過程後,高層只處理較長時間尺度上的路線選擇,低層只處理當前這一段動作的完成,整條長任務被拆成多段較短任務,規劃複雜度隨之下降
這裡還有個關鍵設計,高層動作並不是簡單記錄兩個狀態之間的差值,而是用一個編碼器,把一段低層動作壓縮成更高層的動作表示。對長任務來說,關鍵不只在起點和終點之間差了多少,更在於中間步驟是如何組織的。高層如果只看位移差,容易丟掉這段動作鏈裡的路徑資訊。
HWM體現的是一種分層任務組織方式。面對一項多階段工作,系統不再一次性展開所有動作,而是先形成較粗的階段路徑,再逐段執行與修正。這種層級關係進入世界模型之後,預測能力會開始更穩定地轉化成規劃能力。
三、從0%到70%,實驗結果說明了什麼
在論文設定的真實世界抓取並放置任務中,系統只拿到最終目標條件,不提供人工拆好的中間目標。在這種條件下,HWM的成功率達到 70%,而單層 world model 成功率為 0%。原本幾乎無法完成的長任務,在引入分層規劃後,變成了大概率可實現的結果。

論文還測試了推物體操作和迷宮導航等模擬任務。結果顯示,分層規劃不只提高了成功率,也降低了規劃階段的計算成本。在一些環境中規劃階段的計算成本最多可以減少到原來的四分之一左右,同時保持更高或相當的成功率。
四、從 V-JEPA 到 HWM 再到 WAV
V-JEPA 2代表的是世界表徵這條路線。V-JEPA 2 用超過 100 萬小時網際網路影片進行預訓練,再結合不到 62 小時的機器人影片做 post-training(預訓練後的針對性訓練),得到可用於理解、預測和規劃物理世界的 latent action-conditioned world model(在抽象表示空間中、結合動作資訊進行預測的世界模型)。它所展示的是模型可以透過大規模觀察獲得世界表徵,並把這種表徵遷移到機器人規劃中。
HWM 處在下一步。模型已經擁有世界表徵和基礎預測能力,但一進入多階段控制,誤差累積和搜尋空間擴張的問題就會爆發。HWM沒有改變底層表示學習路線,而是在已有帶動作條件的世界模型之上加入多時間尺度的規劃結構。它所處理的問題是模型怎樣把遠目標組織成一組中間步驟,再逐段推進。
WAV則進一步把焦點放在驗證能力上。世界模型想進入策略最佳化和部署場景,不能只會預測,還要能發現自己在哪些區域容易失真,並據此進行校正。它關注的是模型怎樣檢查自己。
V-JEPA偏向世界表徵,HWM偏向任務規劃,WAV偏向結果驗證。三者雖關注點不同,但大方向是一致的。世界模型的下一階段,已經不只是內部預測,而是預測、規劃、驗證逐漸連成一套系統能力。
五、從內部預測走向可執行系統
過去不少世界模型工作,更接近於提升未來狀態預測的連續性,或者提升內部世界表徵的穩定性。但當前研究重點已經開始變化,系統既要形成對環境的判斷,也要把判斷轉成動作,並在結果出來後繼續修正下一步。想要更接近真實部署,就需要在長時程任務裡控制誤差傳播、壓縮搜尋範圍、降低推理成本。
這類變化也會影響 AI agent。很多agent系統已經能完成短鏈路任務,比如呼叫工具、讀取檔案、執行若干步驟指令。但任務一旦變成長鏈路、多階段、需要中途重規劃,效能就會下滑。這與機器人控制中的難點並沒有本質差別,都是高層路徑組織能力不足,導致局部執行和整體目標之間脫節。
HWM提供的分層思路,高層負責路徑與階段目標,低層負責局部動作與回饋處理,再疊加結果驗證,這類分層結構未來會在更多系統中持續出現。世界模型的下一階段,重點也不再只是預測未來,而是把預測、執行和修正組織成一條可以執行的路徑。


