
黃仁勳GTC演講全文:推理時代到來,龍蝦就是新操作系統
- 核心觀點:輝達在GTC 2026大會上闡述了其從晶片公司向「AI基礎設施和工廠公司」的轉型,並基於「Token工廠經濟學」的商業邏輯,給出了到2027年至少1兆美元的強勁需求預期。
- 關鍵要素:
- 業績指引:黃仁勳表示,輝達對到2027年的需求預期至少為1兆美元,並認為實際需求會更高,此預期一度推動股價上漲超4.3%。
- Token工廠經濟學:未來的資料中心是生產AI Token的「工廠」,在固定電力限制下,每瓦Token吞吐量最高的系統生產成本最低,直接決定收入。
- 技術突破:新一代AI計算系統Vera Rubin透過端到端協同設計,在兩年內將Token生成速率提升350倍,遠超摩爾定律的1.5倍提升。
- 生態與軟體革命:開源專案OpenClaw被視為智能體時代的「操作系統」,黃仁勳斷言所有SaaS公司都將轉變為AaaS(智能體即服務)公司。
- 市場結構:輝達60%業務來自前五大雲端服務商,40%廣泛分佈於主權雲、企業、工業、機器人和邊緣運算等領域,展現了廣泛的行業覆蓋。
原文作者:鮑奕龍
原文來源:華爾街見聞

2026 年 3 月 16 日,輝達 GTC 2026 大會正式開幕,輝達創始人兼 CEO 黃仁勳發表了主題演講。
在這場被視為「AI 行業年度朝聖」的大會上,黃仁勳闡述了輝達從一家「晶片公司」向「AI 基礎設施和工廠公司」的蛻變。面對市場最關心的業績持續性與增長空間問題,黃仁勳詳細拆解了驅動未來增長的底層商業邏輯——「Token 工廠經濟學」。
業績指引極度樂觀,「2027 年至少 1 兆美元的需求」
過去兩年,全球 AI 計算需求呈指數級爆炸。隨著大模型從「感知」、「生成」進化到「推理」與「行動(執行任務)」,算力的消耗量急劇攀升。針對市場高度關注的訂單與營收天花板,黃仁勳給出了極為強勁的預期。
黃仁勳在演講中直言:
去年這個時候,我說過,我們看到了 5000 億美元的高確信度需求,涵蓋 Blackwell 和 Rubin 直到 2026 年。現在,就在此時此地,我看到到 2027 年至少有 1 兆美元的需求(at least $1 trillion)。

黃仁勳的兆元預期一度推動輝達股價漲超 4.3%。
不僅如此,他更是對這一數字做出了補充:
這合理嗎?這就是我接下來要講的。事實上,我們甚至會供不應求。我確定,實際的計算需求會比這高得多。
黃仁勳指出,如今的輝達系統已經證明了自己是全球「成本最低的基礎設施」。由於輝達能執行幾乎所有領域的 AI 模型,這種通用性使得客戶投入的這 1 兆美元能夠被充分利用並保持長久的生命週期。
目前,輝達 60% 的業務來自排名前五的超大型雲端服務商,而另外 40% 的業務則廣泛分佈於主權雲、企業、工業、機器人和邊緣計算等各個領域。
Token 工廠經濟學,每瓦性能決定商業命脈
為了解釋這 1 兆需求的合理性,黃仁勳向全球企業 CEO 展示了一套全新的商業思維。他指出,未來的資料中心不再是儲存檔案的倉庫,而是生產 Token(AI 生成的基本單位)的「工廠」。

黃仁勳強調:
每一座資料中心、每一座工廠,從定義上來說都是受電力限制的。一座 1GW(吉瓦)的工廠永遠不會變成 2GW,這是物理和原子的定律。在固定的功率下,誰的每瓦 Token 吞吐量最高,誰的生產成本就最低。
黃仁勳將未來的 AI 服務分為五個商業層級:
- 免費層(高吞吐、低速度)
- 中級層(~每百萬 token 3 美元)
- 高級層(~每百萬 token 6 美元)
- 高速層(~每百萬 token 45 美元)
- 超高速層(~每百萬 token 150 美元)
他指出,隨著模型越來越大、上下文越來越長,AI 會變得更聰明,但 Token 的生成速率會降低。黃仁勳表示:
在這個 Token 工廠裡,你的吞吐量和 Token 生成速度,將直接轉化為你明年的精確收入。
黃仁勳強調輝達的架構能夠讓客戶在免費層實現極高的吞吐量,同時在最高價值的推理層級上,將性能提升驚人的 35 倍。
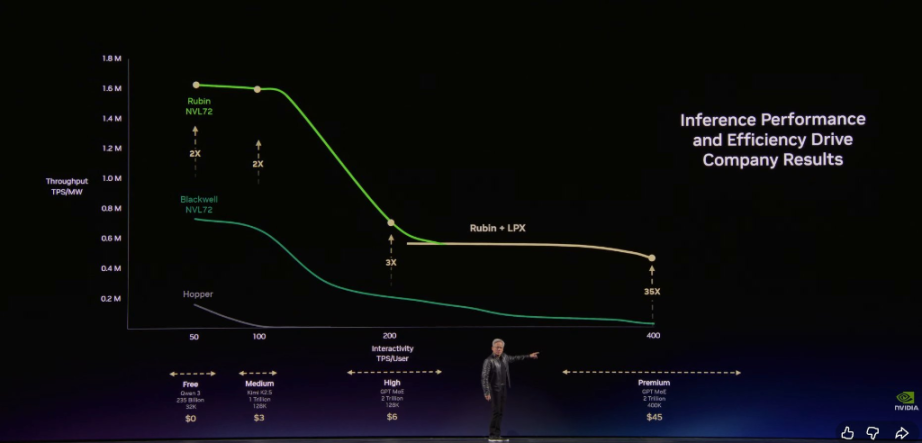
Vera Rubin 兩年實現 350 倍加速,Groq 填補極速推理
在這個物理極限的約束下,輝達介紹其有史以來最複雜的 AI 計算系統,Vera Rubin。黃仁勳表示:
過去提到 Hopper,我會舉起一塊晶片,那很可愛。但提到 Vera Rubin,大家想到的是整個系統。在這個 100% 液冷、完全消滅了傳統線纜的系統中,過去需要兩天安裝的機架,現在只需兩小時。
黃仁勳指出,透過極致的端到端軟硬體協同設計,Vera Rubin 在同一座 1GW 資料中心裡創造了驚人的數據跨越:
在短短兩年時間內,我們將 Token 的生成速率從 2200 萬提升到了 7 億,實現了 350 倍的增長。摩爾定律在同時期僅能帶來約 1.5 倍的提升。
為了解決極速推理(如 1000 Tokens/ 秒)條件下的頻寬瓶頸,輝達給出了整合被收購公司 Groq 的最終方案:非對稱式的分離推理。黃仁勳解釋:
這兩款處理器的特點截然不同。Groq 晶片擁有 500MB 的 SRAM,而一顆 Rubin 晶片擁有 288GB 的記憶體。

黃仁勳指出,輝達透過 Dynamo 軟體系統,將需要海量計算和顯存的「預填充(Pre-fill)」階段交給 Vera Rubin,將對延遲極度敏感的「解碼」階段交給 Groq。黃仁勳還對企業算力配置給出了建議:
如果你的工作主要是高吞吐,100% 使用 Vera Rubin;如果你有大量高價值的程式設計級別的 Token 生成需求,拿出 25% 的資料中心規模給 Groq。
據透露,由三星代工的 Groq LP30 晶片已在量產,預計第三季度出貨,而首個 Vera Rubin 機架已在微軟 Azure 雲上執行。
此外,針對光互聯技術,黃仁勳展示了全球首款量產的共封裝光學(CPO)交換器 Spectrum X,並平息了市場對於「銅退光進」的路線之爭:
我們需要更多的銅纜產能,更多的光晶片產能,更多的 CPO 產能。
Agent 終結傳統 SaaS,「年薪 +Token」成矽谷標配
除了硬體壁壘,黃仁勳把大量篇幅留給了 AI 軟體和生態的革命,特別是 Agent(智慧體)的爆發。
他將開源專案 OpenClaw 形容為「人類歷史上最受歡迎的開源專案」,稱其僅用幾周時間就超越了 Linux 在過去 30 年取得的成就。黃仁勳直言,OpenClaw 本質上就是 Agent 電腦的「作業系統」。
黃仁勳斷言:
每一個 SaaS(軟體即服務)公司都將變成 AaaS(Agent-as-a-Service,智慧體即服務)公司。毫無疑問,為了讓這種具備存取敏感資料和執行程式碼能力的智慧體安全落地,輝達推出了企業級的 NeMo Claw 參考設計,增加了策略引擎和隱私路由器。
對於普通職場人,這場變革同樣近在咫尺。黃仁勳描繪了未來的職場新形態:
在未來,我們公司的每一位工程師都需要一個年度 Token 預算。他們的基礎年薪可能是幾十萬美元,我會在此基礎上再拿出大約一半的金額作為 Token 額度給他們,讓他們實現 10x 的效率提升。這已經是矽谷的新招聘籌碼了:你的 offer 裡帶多少 Token?
演講最後,黃仁勳還「劇透」了下一代計算架構 Feynman,它將首次實現銅線與 CPO 的共同水平擴充套件。更引人遐想的是,輝達正在研發部署在太空的資料中心電腦「Vera Rubin Space-1」,徹底打開了 AI 算力向地球之外延伸的想象空間。
黃仁勳 GTC 2026 演講全文,全文翻譯如下(AI 工具輔助):
主持人: 歡迎輝達創始人兼執行長黃仁勳上台。
黃仁勳,創始人兼執行長:
歡迎來到 GTC。我想提醒大家,這是一場技術大會。能看到這麼多人一大早排隊入場,能看到在座的各位,我感到非常高興。
在 GTC,我們將聚焦三大主題:技術、平臺和生態系統。輝達目前擁有三大平臺:CUDA-X 平臺、系統平臺,以及我們最新推出的 AI 工廠平臺。
在正式開始之前,我要感謝我們的預熱環節主持人——Conviction 的 Sarah Guo、紅杉資本的 Alfred Lin(輝達的第一位風險投資人),以及輝達的第一位主要機構投資人 Gavin Baker。這三位對技術有深刻的洞見,在整個技術生態系統中擁有極廣的影響力。當然,我還要感謝今天所有我親自邀請出席的貴賓們。感謝這支全明星團隊。
我同樣要感謝今天到場的所有企業。輝達是一家平臺公司,我們擁有技術、平臺和豐富的生態系統。今天到場的企業代表了價值 100 兆美元行業中幾乎全部的參與者,共有 450 家公司贊助了本次活動,在此深表感謝。
本次大會共設有 1,000 場技術論壇、2,000 位演講嘉賓,將涵蓋人工智慧「五層蛋糕」架構的每一個層級——從土地、電力與機房等基礎設施,到晶片、平臺、模型,以及最終推動整個行業騰飛的各類應用。
CUDA:二十年的技術積澱
一切的起點,就在這裡。今年是 CUDA 誕生二十週年。
二十年來,我們始終致力於這一架構的研發。CUDA 是一項革命性的發明——SIMT(單指令多執行緒)技術允許開發者以標量程式碼編寫程式,並將其擴充套件為多執行緒應用,其程式設計難度遠低於此前的 SIMD 架構。我們最近還新增了 Tiles 功能,幫助開發者更便捷地程式設計張量核心(Tensor Core),以及當今人工智慧所依賴的各類數學運算結構。目前,CUDA 已擁有數千種工具、編譯器、框架和庫,在開源社群中存在數十萬個公開專案,並已深度整合到每一個技術生態系統之中。
這張圖表揭示了輝達 100% 的策略邏輯,我從最初就一直在講這張幻燈片。其中最難實現、也是最核心的要素,是圖表底部的「裝機量」。歷經二十年,我們已在全球範圍內積累了數億塊執行 CUDA 的 GPU 和計算系統。
我們的 GPU 覆蓋所有雲平臺,服務於幾乎所有計算機廠商和行業。CUDA 龐大的裝機量,正是這個飛輪不斷加速的根本原因。裝機量吸引開發者,開發者創造新演算法並取得突破,突破催生全新市場,新市場形成新生態並吸引更多企業加入,進而擴大裝機量——這個飛輪正在持續加速。
輝達庫的下載量正以驚人的速度增長,規模龐大且增速不斷提升。這個飛輪使我們的計算平臺能夠支撐海量應用和層出不窮的新突破。
更重要的是,它還賦予了這些基礎設施極長的使用壽命。原因顯而易見:NVIDIA CUDA 上可執行的應用極為豐富,涵蓋 AI 生命週期的每個階段、各類資料處理平臺,以及各種科學原理求解器。因此,一旦安裝了輝達 GPU,其實際使用價值極高。這也是為何我們六年前釋出的 Ampere 架構 GPU,其雲端價格反而在上漲。
這一切的根本原因在於:裝機量龐大,飛輪強勁,開發者生態廣泛。當這些因素共同發揮作用,加之我們持續更新軟體,計算成本便會不斷下降。加速計算在大幅提升應用效能的同時,隨著我們長期維護和迭代軟體,使用者不僅能在初期獲得效能躍升,還能持續享受計算成本的下降。我們願意為全球每一塊 GPU 提供長期支援,因為它們在架構上完全相容。
我們之所以願意這樣做,是因為裝機量如此龐大——每釋出一次新的最佳化,便能惠及數百萬使用者。這種動態組合,使得輝達架構在持續擴大覆蓋範圍、加速自身成長的同時,不斷壓低計算成本,最終刺激新的增長。CUDA 是這一切的核心。
從 GeForce 到 CUDA:二十五年的演進之路
而我們與 CUDA 的旅程,實際上早在二十五年前就已開始。
GeForce——相信在座有很多人是伴隨著 GeForce 長大的。GeForce 是輝達最成功的市場推廣專案。我們從你們還買不起產品的時候就開始培養未來的客戶——是你們的父母代替你們成為了輝達最早的使用者,年復一年地購買我們的產品,直到有一天,你們成長為優秀的計算機科學家,成為真正意義上的客戶和開發者。
這是二十五年前 GeForce 奠定的基業。二十五年前,我們發明了可程式設計著色器——這是讓加速器實現可程式設計化的一項顯而易見卻意義深遠的發明,也是世界上第一款可程式設計加速器,即畫素著色器。這五年後,我們創造了 CUDA——這是我們有史以來最重要的投資之一。當時公司財力有限,但我們將絕大部分利潤押注於此,致力於將 CUDA 從 GeForce 延伸到每一臺計算機。我們之所以如此堅定,是因為我們深信其潛力。儘管初期歷經艱辛,公司堅守這一信念長達 13 代、整整二十年,如今 CUDA 已無處不在。
正是畫素著色器推動了 GeForce 的革命。而大約八年前,我們推出了 RTX——為現代計算機圖形時代對架構進行了全面革新。GeForce 將 CUDA 帶給了全世界,也正因如此,讓 Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton、Andrew Ng 等眾多學者發現,GPU 可以成為加速深度學習的利器,由此點燃了十年前人工智慧的大爆炸。
十年前,我們決定將可程式設計著色與兩個全新理念相融合:一是硬體光線追蹤(Ray Tracing),這在技術上極具挑戰;二是一個當時頗具前瞻性的想法——大約十年前,我們就預見到 AI 將徹底變革計算機圖形。正如 GeForce 將 AI 帶給了全世界,AI 如今也將反過來重塑整個計算機圖形的實現方式。
今天,我要向大家展示未來。這是我們的下一代圖形技術,我們稱之為神經渲染(Neural Rendering)——3D 圖形與人工智慧的深度融合。這就是 DLSS 5,請看。
神經渲染:結構化資料與生成式 AI 的融合
這是不是令人歎為觀止?計算機圖形就此煥發生機。
我們做了什麼?我們將可控的 3D 圖形(虛擬世界的真實基礎)與其結構化資料相結合,再融入生成式 AI 和概率計算。一個完全確定性,另一個概率性卻高度逼真——我們將這兩種理念融為一體,透過結構化資料實現精準可控,同時進行實時生成。
最終,內容既美觀驚豔,又完全可控。
結構化資訊與生成式 AI 融合這一理念,將在一個又一個行業中不斷覆現。結構化資料是可信 AI 的基石。
結構化資料與非結構化資料的加速平臺
現在我要帶大家看一張技術架構圖。
結構化資料——大家熟悉的


