
DeepSeek V4 sau khi triển khai: Zhipu, MiniMax lao dốc, NVIDIA lo lắng
- Quan điểm chính: Việc phát hành mô hình DeepSeek V4 đã làm đảo lộn logic định giá thị trường vốn AI, thúc đẩy dòng vốn chuyển từ các công ty mô hình đóng mã nguồn lớn sang cơ sở hạ tầng tính toán nội địa, đánh dấu sự xuất hiện của cả hai bước ngoặt: mã nguồn mở và hệ sinh thái chip nội địa.
- Các yếu tố chính:
- Tham số mô hình: Mô hình MoE cơ bản 1T tham số, phiên bản Flash 285B, phiên bản Pro 1,6T, theo giao thức nguồn mở Apache 2.0.
- Phân hóa thị trường: Chuỗi tính toán cổ phiếu A (Hanguang, Haiguang, v.v.) tăng mạnh, các công ty mô hình đóng mã nguồn niêm yết tại Hồng Kông (Zhipu, MiniMax) bị bán khống, NVIDIA điều chỉnh nhẹ.
- Lợi thế nguồn mở: Trong số 11 mô hình mới trong 30 ngày qua, V4 là mô hình nguồn mở hàng đầu đầu tiên gây áp lực toàn diện lên các mô hình đóng mã nguồn về ba mặt: hiệu suất, giá cả và độ mở.
- Hệ sinh thái tính toán nội địa: V4 đạt được khả năng thích ứng toàn diện Day 0 với chip Hanguang Siyuan 590 và Huawei Ascend 950PR, mã nguồn triển khai được mở, phá vỡ sự phụ thuộc vào CUDA.
- Dữ liệu hiệu suất: Độ trễ suy luận của V4 trên siêu nút Ascend thấp hơn 35% so với cụm H100, sức mạnh tính toán FP8 của chip Hanguang tương đương H100 với giá thấp hơn.
- Bước ngoặt hệ sinh thái: vLLM hợp nhất backend GPU nội địa không phải của NVIDIA, nhu cầu suy luận AI của Trung Quốc bắt đầu tách rời khỏi Bắc Mỹ, thay thế nội địa bước vào giai đoạn sản xuất có thể định giá.
DeepSeek V4 cuối cùng đã ra mắt. Đây là khoảnh khắc được chờ đợi gần năm tháng. Mô hình chính MoE với 1T tham số + phiên bản Flash với 285B tham số, cùng bộ Pro hoàn chỉnh 1.6T theo sau, mã nguồn mở hoàn toàn trên GitHub, giấy phép Apache 2.0, trọng số và mã triển khai được phát hành đồng thời.
Khi mô hình vừa ra mắt, thị trường vốn đã phản ứng theo ba cách riêng biệt nhưng lại đan xen lẫn nhau.
Phản ứng khác nhau của thị trường vốn
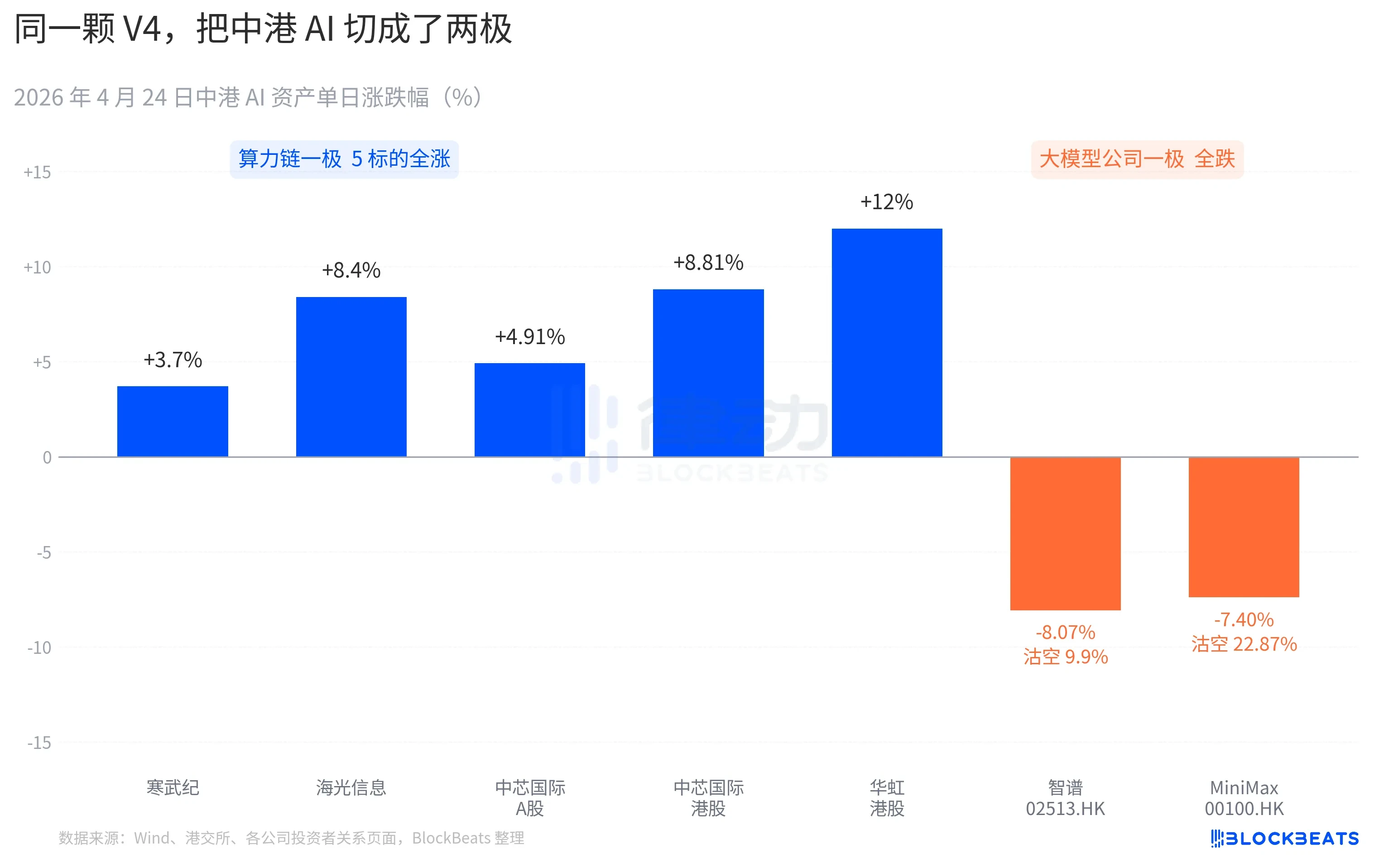
Chuỗi sức mạnh tính toán trên thị trường chứng khoán A-Share gần như tăng điểm đồng loạt. Hàn Vũ Kỷ (Cambricon) đã có chuỗi 11 phiên tăng, tăng 3,7% trong một ngày, tổng mức tăng trong tháng vượt quá 60%. Cổ phiếu Hải Quang Tín Tức (Haiguang Information) đã chạm mức tăng trần 10% trong phiên, đóng cửa ở mức +8,4%. Trung Tâm Quốc Tế (SMIC) A-Share tăng 4,91%, cổ phiếu H-Share tăng 8,81%. Cổ phiếu Hoa Hồng (Hua Hong) H-Share đạt mức cao nhất +18%, đóng cửa ở mức +12%. Quỹ ETF Khoa học Kỹ thuật Chip Quốc Thái (ChinaTech Chip Guotai ETF) đã thu hút 2,4 tỷ nhân dân tệ trong một ngày, quy mô đạt mức cao nhất lịch sử.
Phía các công ty mô hình lớn trên thị trường chứng khoán H-Share lại mang một màu sắc khác. Trí Phổ (Zhipu AI) (02513.HK) giảm 8,07%, tỷ lệ bán khống là 9,9%. MiniMax (00100.HK) giảm 7,40%, tỷ lệ bán khống tăng vọt lên 22,87%. Đây là dữ liệu bán khống một ngày cao nhất trong ba tháng qua của mảng AI trên thị trường chứng khoán H-Share. Cả hai công ty này đều là đại diện cho làn sóng IPO AI trên thị trường chứng khoán H-Share nửa cuối năm 2025, và bản cáo bạch IPO đều ghi cùng một câu nói về năng lực cốt lõi: "Mô hình nền tảng tự nghiên cứu".
Phản ứng từ phía bên kia Thái Bình Dương cũng cụ thể không kém. Cổ phiếu Nvidia đã giảm 1,8% khi mở cửa phiên tối qua, có lúc giảm xuống -2,6% trong phiên, và đóng cửa gần như đi ngang. Bản phân tích nhanh của Bloomberg đã so sánh đợt điều chỉnh này với "Khoảnh khắc DeepSeek" V3 ngày 27 tháng 1. Sự khác biệt nằm ở chỗ, lần hồi tháng 1 là một đợt bán tháo hoảng loạn, làm bốc hơi 600 tỷ đô la Mỹ vốn hóa thị trường trong một ngày. Lần này giống như một đợt định giá lại, quy mô nhẹ nhàng hơn nhưng hướng đi rõ ràng. Một câu nói mới xuất hiện trong các ghi chú nghiên cứu của các tổ chức mua: "Nhu cầu suy luận AI của Trung Quốc bắt đầu tách rời khỏi nhu cầu suy luận AI của Bắc Mỹ".
Kết hợp ba mảng thị trường này lại với nhau, đó chính là bản án đầu tiên mà thị trường viết ra trong vòng 24 giờ sau khi V4 ra mắt. Sau khi mã nguồn mở chiến thắng, tiền bắt đầu chọn phe lại, và thứ có thể định giá không còn là bản thân mô hình nữa, mà là mô hình chạy trên loại card nào, được gắn trong chuỗi công nghiệp nào.
30 ngày với 11 mô hình mới, V4 tiếp thêm lửa cho phe mã nguồn mở
Khung thời gian phát hành V4 tự nó là một phần lý do khiến phản ứng lần này bị khuếch đại.
Hãy nhìn lại 30 ngày qua. Từ ngày 26 tháng 3 đến ngày 24 tháng 4, đã có ít nhất 11 mô hình lớn có ảnh hưởng đáng kể được ra mắt hoặc cập nhật lớn trên toàn cầu, danh sách bao gồm hầu hết các bên chơi chính. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moon Face Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, và cuối cùng là DeepSeek V4 được phát hành vào rạng sáng ngày 23 tháng 4.
Trung bình, cứ 2,7 ngày lại có một mô hình mới ra đời. Đây là tốc độ mà ngay cả các nhà quản lý quỹ cũng không kịp đọc hết các thông cáo phát hành. Nhưng hãy nhìn qua các đường K-line của tài sản AI Trung Quốc và Hồng Kông trong 30 ngày này, chỉ có một cái tên để lại dấu ấn liên tục trên bảng điện. GPT-5.5 vào ngày 8 tháng 4 đã đẩy Nvidia tăng 4,2% trong một ngày, nhưng một ngày sau đã đạt đỉnh. Sau đó là DeepSeek V4 vào các ngày 23-24 tháng 4, đẩy chuỗi sức mạnh tính toán Trung Quốc và Hồng Kông đi lên liên tục.
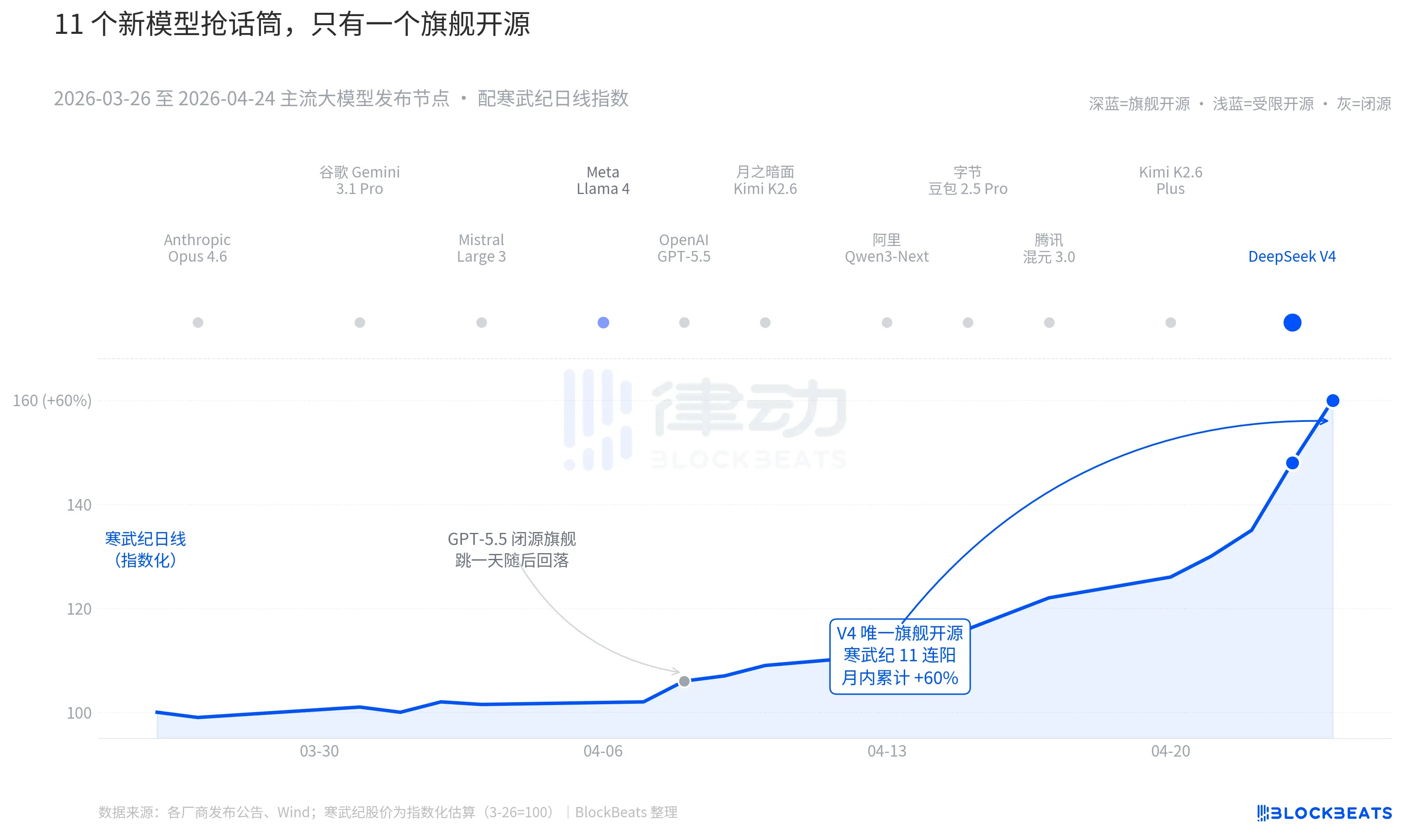
Sự khác biệt không nằm ở bản thân năng lực mô hình. Khoảng cách giữa 11 mô hình này trên bảng xếp hạng LMArena, trong hầu hết các trường hợp, không vượt quá 50 điểm, nằm trong một dải hẹp "cùng một đẳng cấp". Sự khác biệt nằm ở sự kết hợp của hai điều.
Điều thứ nhất là mã nguồn mở. Trong 10 mô hình đầu tiên, chỉ có Llama 4 là mã nguồn mở, nhưng thỏa thuận trọng số của Llama 4 kèm theo một loạt các điều khoản hạn chế thương mại. Cộng đồng nhà phát triển ở châu u và Mỹ đánh giá lạnh nhạt, và OpenRouter đã rơi khỏi top 10 ngay ngày thứ ba. Thỏa thuận của V4 là Apache 2.0, trọng số không có rào cản, thương mại không hạn chế, mã suy luận được phát hành đồng thời. Đây là mô hình mã nguồn mở hàng đầu trong sáu tháng qua, lần đầu tiên gây áp lực lên phe mã nguồn đóng trên cả ba khía cạnh: hiệu suất, giá cả và độ mở.
Điều thứ hai là thời điểm. Trong bối cảnh phe mã nguồn đóng liên tục tung ra những "chiêu lớn", câu chuyện về mã nguồn mở đang bị bóp nghẹt nhiều lần. Opus 4.6 đã đẩy SWE-Bench cho các tác vụ mã lên một tầm cao mới, GPT-5.5 đặt giá mỗi triệu token ở mức neo thấp 1,25 USD. Cuộc tranh luận về việc liệu mã nguồn mở có thể bắt kịp mã nguồn đóng hay không đã kéo dài hai năm ở Thung lũng Silicon. V4, với tư cách là một mô hình mã nguồn mở hàng đầu có ước tính 90 triệu người dùng hoạt động hàng tháng, đã tạm thời nhấn nút tạm dừng cho cuộc tranh luận này.
Theo một nhà quản lý quỹ lớn trong nước trong buổi lộ trình, "Trước V4, chúng tôi đã để lại một khoản chiết khấu trong định giá các mô hình lớn mã nguồn mở, sau V4, khoản chiết khấu này bắt đầu được thu hồi theo hướng ngược lại."
DeepSeek đã thay đổi bảng định giá của chuỗi cung ứng sức mạnh tính toán
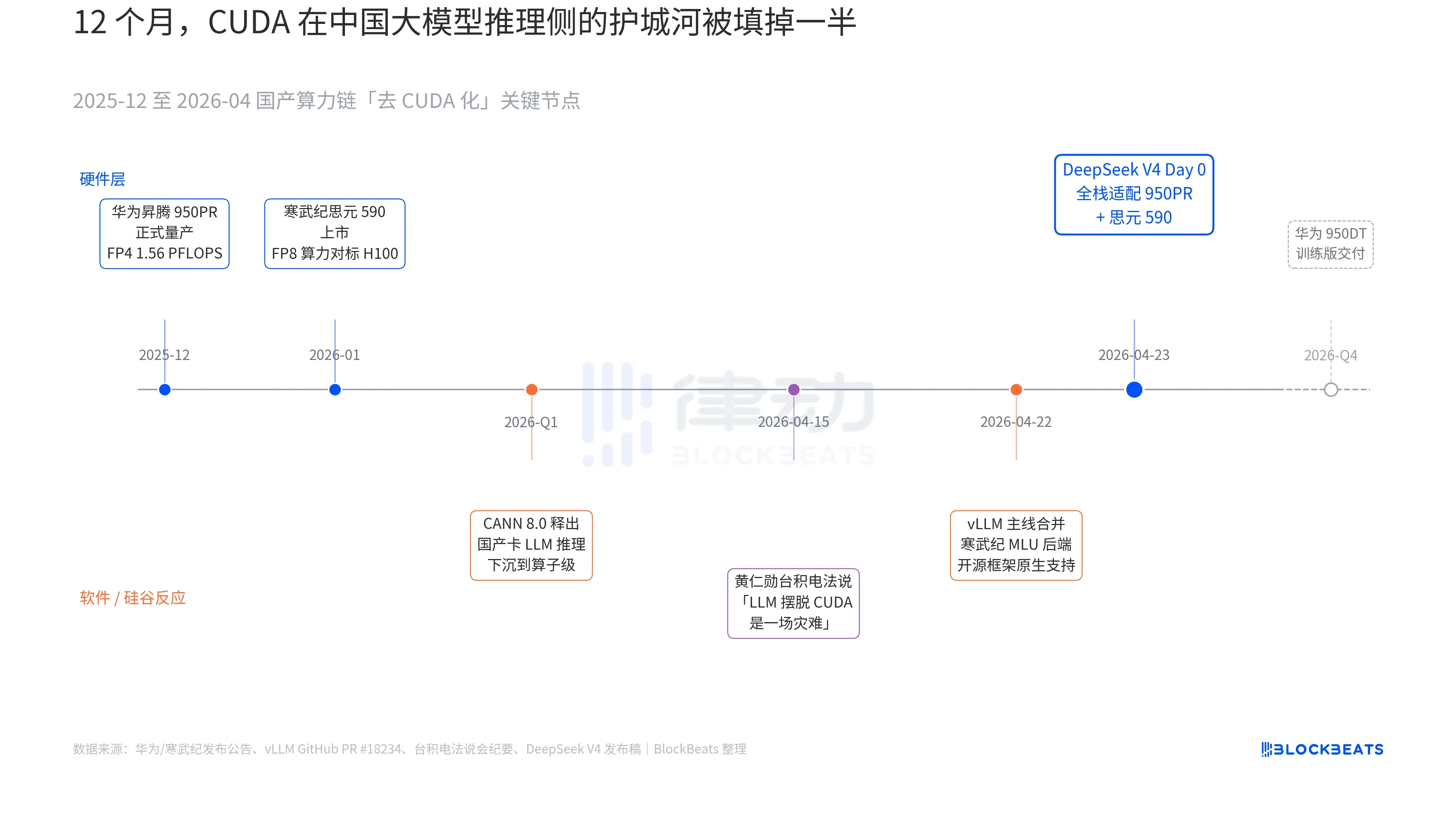
Trong thông cáo phát hành V4 có một dòng chữ chưa từng xuất hiện trong tài liệu chính thức của bất kỳ mô hình lớn Trung Quốc nào trước đây: "Ngày 0 tích hợp toàn diện với Hàn Vũ Kỷ (Cambricon) Siyuan 590 và Huawei Ascend 950PR, mã triển khai được công bố đồng thời." Tầm quan trọng của dòng chữ này chỉ có thể được hiểu khi kết nối ba mạch ngầm song song đã triển khai trong 12 tháng qua. Ba mạch ngầm này lần lượt thuộc về phần cứng, phần mềm và phản ứng từ Thung lũng Silicon.
Mạch ngầm thứ nhất nằm ở phía chip. Huawei Ascend 950PR chính thức được sản xuất hàng loạt vào tháng 12 năm 2025, với sức mạnh tính toán FP4 1,56 PFLOPS, dung lượng HBM 112GB, đây là lần đầu tiên chip AI nội địa Trung Quốc đạt chuẩn so sánh với dòng B của Nvidia về các chỉ số cứng. Trong các tác vụ suy luận MoE với 1T tham số như V4, thông lượng một card cao hơn 2,87 lần so với H20. Ngăn xếp phần mềm CANN 8.0 đi kèm đã tối ưu hóa khung suy luận LLM xuống cấp độ toán tử. Benchmark công khai của DeepSeek cho thấy, độ trễ suy luận đầu cuối của V4 trên siêu nút Ascend (8 card 950PR) thấp hơn 35% so với cụm H100 có quy mô tương đương. Dữ liệu của Hàn Vũ Kỷ (Cambricon) Siyuan 590 còn mạnh mẽ hơn, sức mạnh tính toán FP8 một chip ngang bằng H100, nhưng giá bán chưa bằng một nửa.
Mạch ngầm thứ hai nằm ở phía phần mềm. Vào ngày 22 tháng 4, nhánh chính của vLLM đã hợp nhất PR backend MLU của Hàn Vũ Kỷ (Cambricon), lần đầu tiên khung suy luận mã nguồn mở hỗ trợ nguyên bản GPU nội địa không phải của Nvidia. DCU của Hải Quang Tín Tức (Haiguang Information) đi theo một con đường khác thông qua hệ sinh thái ROCm, nhưng có thể chạy hoàn chỉnh lớp định tuyến MoE của V4. Điều này có nghĩa là việc triển khai V4 không còn là "chỉ có thể chạy trên một loại card nội địa nhất định" nữa, mà là "có thể lựa chọn giữa nhiều loại card nội địa". Sự phụ thuộc của hệ sinh thái vào một nhà cung cấp duy nhất đã bị phá vỡ, đây là bước ngoặt quan trọng cho sản xuất (production).
Mạch ngầm thứ ba đến từ Thung lũng Silicon. Vào ngày 15 tháng 4, Jensen Huang đã bị các nhà phân tích chất vấn về tiến độ của sức mạnh tính toán nội địa Trung Quốc tại buổi họp với TSMC. Câu trả lời lạnh lùng và cụ thể: "Nếu họ thực sự có thể giải phóng LLM khỏi CUDA, đó sẽ là một thảm họa (a disaster) đối với chúng tôi." Chín ngày sau, DeepSeek đã đưa ra câu trả lời bằng một dòng thông báo Ngày 0.
Bốn chữ "Thay thế nội địa" đã bị nhắc đến nhiều đến mức mất đi ý nghĩa trong ba năm qua. Nhưng sau sáng ngày 24 tháng 4, điều này lần đầu tiên có được dữ liệu cụ thể có thể định giá bởi thị trường vốn. Thông lượng một card, độ trễ suy luận đầu cuối, chi phí suy luận, mã triển khai có thể thương mại hóa, tất cả đã âm thầm đưa cuộc chiến truyền thông kéo dài này đến ngưỡng cửa của sản xuất (production).
Logic đằng sau chuỗi 11 phiên tăng của cổ phiếu Hàn Vũ Kỷ (Cambricon) nằm ở đây. Nó không còn là một "cổ phiếu khái niệm GPU nội địa" nữa, mà là "nhà cung cấp cơ sở hạ tầng suy luận cho DeepSeek V4". Logic tương tự cũng có thể giải thích mức tăng 12% của cổ phiếu Hoa Hồng (Hua Hong) H-Share, vì nó sản xuất gia công quy trình tương đương 7nm cho 950PR. Mỗi token V4 chạy trên Ascend nội địa, đều có nghĩa là công suất vốn dĩ sẽ chảy đến Nvidia và TSMC, đã bị giữ lại một phần ở đồng bằng Châu Giang.
Và bước tiếp theo đã được chuẩn bị sẵn. Trong lộ trình của Huawei, 950DT (phiên bản huấn luyện) được lên kế hoạch giao hàng vào quý 4 năm 2026, mục tiêu tương ứng là "huấn luyện toàn diện mô hình cấp độ V5 hoặc tương đương trên cụm 10.000 card". Nếu con đường này có thể thành công, hào CUDA trong mảng huấn luyện mô hình lớn của Trung Quố


