
Thách thức cốt lõi của lý luận AI phi tập trung: Làm thế nào để chứng minh với toàn bộ mạng lưới rằng bạn không "gian lận"?
- 核心观点:去中心化LLM需验证节点模型真实性。
- 关键要素:
- GPU非确定性导致输出比较困难。
- 经济机制惩罚作弊,声誉归零。
- 三种验证方案防范模型替换攻击。
- 市场影响:提升去中心化AI网络可信度。
- 时效性标注:中期影响。
Bài viết gốc của Anastasia Matveeva, Đồng sáng lập Gonka Protocol
Trong bài viết trước , chúng ta đã khám phá mối quan hệ căng thẳng cơ bản giữa bảo mật và hiệu suất trong lập luận phi tập trung bằng LLM. Hôm nay, chúng ta sẽ thực hiện lời hứa và đi sâu vào một câu hỏi cốt lõi: Trong một mạng lưới mở, làm thế nào để xác minh một nút thực sự đang chạy đúng mô hình mà nó tuyên bố?
01. Tại sao việc xác minh lại khó khăn như vậy?
Để hiểu cơ chế xác thực, hãy cùng xem lại quy trình nội bộ của Transformer khi thực hiện suy luận. Khi các token đầu vào được xử lý, lớp cuối cùng của mô hình sẽ tạo ra các logit—điểm số thô, chưa chuẩn hóa cho mỗi token trong từ vựng. Các logit này sau đó được chuyển đổi thành xác suất bằng hàm softmax, tạo thành một phân phối xác suất trên tất cả các token tiếp theo có thể có. Ở mỗi bước tạo, một token được lấy mẫu từ phân phối này để tiếp tục tạo chuỗi.
Trước khi tìm hiểu sâu hơn về các phương thức tấn công tiềm ẩn và cách triển khai xác minh cụ thể, trước tiên chúng ta cần hiểu tại sao việc xác minh lại khó khăn.
Nguyên nhân gốc rễ của vấn đề nằm ở tính không xác định của GPU. Ngay cả cùng một mô hình và đầu vào cũng có thể tạo ra kết quả đầu ra hơi khác nhau trên các phần cứng khác nhau, hoặc thậm chí trên cùng một thiết bị, do các vấn đề như độ chính xác của dấu phẩy động.
Tính không xác định của GPU khiến việc so sánh trực tiếp các chuỗi token đầu ra trở nên vô nghĩa. Do đó, chúng ta cần kiểm tra quy trình tính toán nội bộ của Transformer. Một lựa chọn tự nhiên là so sánh các phân phối xác suất trên lớp đầu ra, tức là từ vựng mô hình. Để đảm bảo rằng chúng ta đang so sánh các phân phối xác suất của cùng một chuỗi, quy trình xác minh của chúng tôi yêu cầu trình xác minh phải tái tạo hoàn toàn chính xác cùng một chuỗi token do trình thực thi tạo ra và sau đó so sánh các phân phối xác suất này từng bước một. Quy trình này tạo ra một chứng chỉ xác minh chứng minh tính xác thực của mô hình.
Tuy nhiên, hành vi xác suất cũng đặt ra một sự cân bằng tinh tế: chúng ta cần trừng phạt những kẻ gian lận dai dẳng đồng thời tránh vô tình gây hại cho các nút trung thực vốn chỉ đơn giản là kém may mắn và tạo ra kết quả có xác suất thấp. Đặt ngưỡng quá cao có thể vô tình giết chết những người chơi giỏi; đặt ngưỡng quá thấp có thể giúp những người chơi kém thoát tội.
02. Kinh tế học về gian lận: Lợi ích và rủi ro
Lợi ích tiềm năng: Sự cám dỗ lớn
Cuộc tấn công trực tiếp nhất là "thay thế mô hình". Giả sử việc triển khai mạng đòi hỏi một lượng lớn sức mạnh tính toán cho mô hình Qwen3-32B, một nút lý trí có thể nghĩ: "Điều gì sẽ xảy ra nếu tôi bí mật chạy mô hình Qwen2.5-3B nhỏ hơn nhiều và bỏ túi phần chênh lệch về sức mạnh tính toán tiết kiệm được?"
Việc sử dụng mô hình 3 tỷ tham số để giả mạo thành mô hình 32 tỷ tham số có thể giảm chi phí năng lực tính toán xuống một bậc. Nếu bạn có thể đánh lừa hệ thống xác minh, thì cũng giống như được trả tiền cho năng lực tính toán chất lượng cao trong khi vẫn mang lại kết quả bằng năng lực tính toán giá rẻ.
Một kẻ tấn công tinh vi hơn có thể sử dụng các kỹ thuật lượng tử hóa, tuyên bố chạy ở độ chính xác FP8, nhưng thực chất lại sử dụng lượng tử hóa INT4. Sự khác biệt về hiệu suất có thể không đáng kể, nhưng chi phí tiết kiệm vẫn đáng kể, và kết quả đầu ra có thể đủ tương tự để vượt qua bước xác minh đơn giản.
Ở cấp độ phức tạp hơn, còn có các cuộc tấn công điền trước. Kiểu tấn công này cho phép kẻ tấn công tạo ra bằng chứng cho đầu ra của một mô hình giá rẻ như thể đầu ra đó được tạo ra bởi mô hình đầy đủ mà mạng mong đợi. Nó hoạt động như sau:
Ví dụ, đạt được sự đồng thuận về chuỗi triển khai Qwen3-235B với một tập hợp các tham số cụ thể.
1. Bộ thực thi sử dụng Qwen2.5-3B để tạo chuỗi: `[Xin chào, thế giới, bạn khỏe không?]`.
2. Người thực thi tính toán bằng chứng Qwen3-235B cho chính xác các mã thông báo này thông qua một lần chuyển tiếp duy nhất: `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`.
3. Người thực hiện đưa ra xác suất của Qwen3-235B làm bằng chứng, khẳng định rằng lý luận xuất phát từ Qwen3-235B.
Trong trường hợp này, các xác suất đến từ mô hình chính xác, khiến chúng có vẻ hợp lệ, nhưng quy trình tạo chuỗi thực tế lại rẻ hơn nhiều. Vì về mặt lý thuyết, mô hình đầy đủ cũng có thể tạo ra cùng một đầu ra như mô hình nhỏ hơn, nên kết quả có thể hoàn toàn hợp lệ từ góc độ xác minh.
Tổn thất tiềm ẩn: Đắt hơn
Mặc dù việc gian lận hệ thống có thể mang lại lợi ích đáng kể, nhưng tổn thất tiềm ẩn cũng đáng kể không kém. Thách thức thực sự đối với những kẻ gian lận không phải là vượt qua một lần xác minh duy nhất, mà là phải liên tục tránh bị phát hiện trong một thời gian dài, sao cho "mức giảm giá" mà chúng nhận được khi tính toán vượt quá mức phạt mà mạng lưới có thể áp đặt.
Trong mạng lưới Gonka , chúng tôi đã thiết kế một cơ chế đàn áp kinh tế tinh vi:
- Mọi người đều là người xác thực: Mỗi nút xác minh một phần lý luận của mạng theo trọng số của nó
- Hệ thống danh tiếng: Giá trị danh tiếng của một nút mới là 0 và tất cả các suy luận đều được xác minh. Với sự tham gia trung thực liên tục, danh tiếng sẽ tăng lên và tần suất xác minh có thể giảm xuống còn 1%.
- Cơ chế phạt: Nếu bị phát hiện gian lận, danh tiếng của bạn sẽ bị xóa về 0 và mất khoảng 30 ngày để xây dựng lại.
- Thanh toán theo thời gian: Trong vòng khoảng 24 giờ, nếu bạn bị phát hiện gian lận với số lần đáng kể về mặt thống kê, tất cả phần thưởng cho toàn bộ thời gian đó sẽ bị tịch thu.
Điều này có nghĩa là một kẻ gian lận cố gắng tiết kiệm 50% sức mạnh tính toán có thể sẽ mất 100% lợi nhuận. Rủi ro "lỗ trên lãi" này khiến việc gian lận trở nên không có lợi về mặt kinh tế. Vấn đề chúng tôi muốn giải quyết với cơ chế xác minh này không phải là nắm bắt mọi suy luận đáng ngờ, mà là vạch ra một ranh giới đảm bảo chúng tôi có thể liên tục phát hiện ra những kẻ gian lận với xác suất đủ cao mà không làm tổn hại đến danh tiếng của những người tham gia trung thực.
03. Làm thế nào để bắt kẻ gian lận? Ba phương thức xác minh
Vậy, làm thế nào để phát hiện những cuộc tấn công này? Vấn đề có thể được chia thành hai phần: 1) xác minh rằng phân phối trong bằng chứng gần với phân phối do mô hình được yêu cầu tạo ra; và 2) xác nhận rằng văn bản đầu ra thực sự được tạo ra dựa trên bằng chứng đã nộp.
Lựa chọn 1: So sánh phân phối xác suất (Nền tảng cốt lõi)
Khi trình thực thi tạo ra đầu ra suy luận (ví dụ: `[Hello, world, how, are, you]`), chúng sẽ ghi lại chứng chỉ xác minh chứa đầu ra cuối cùng và K xác suất cao nhất cho mỗi vị trí trong chuỗi đầu ra (ví dụ: `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]` cho vị trí đầu tiên, v.v.). Sau đó, trình xác minh buộc mô hình của mình tuân theo chính xác cùng một chuỗi mã thông báo và tính toán khoảng cách chuẩn hóa \(d_i \) giữa các xác suất tại mỗi vị trí:
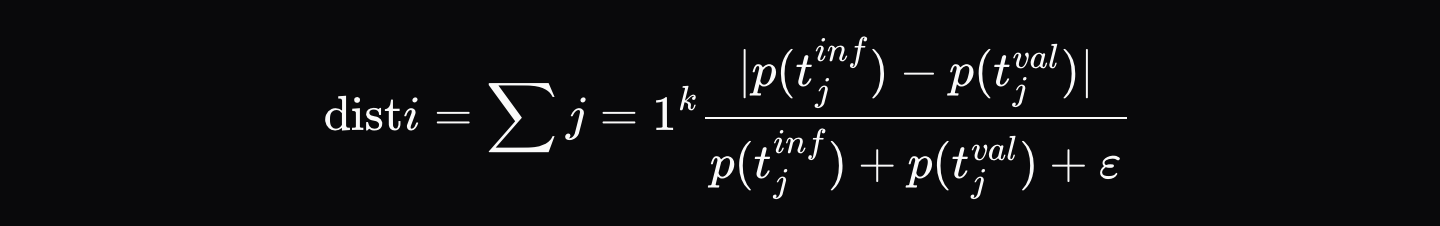
trong đó \( p_{\text{artifact},ij} \) là xác suất của mã thông báo có khả năng xảy ra thứ j tại vị trí đó trong kho lưu trữ suy luận và \( p_{\text{validator},ij} \) là xác suất của cùng một mã thông báo trong phân phối trình xác thực.
Chỉ số khoảng cách cuối cùng là tổng khoảng cách trung bình của mỗi mã thông báo:
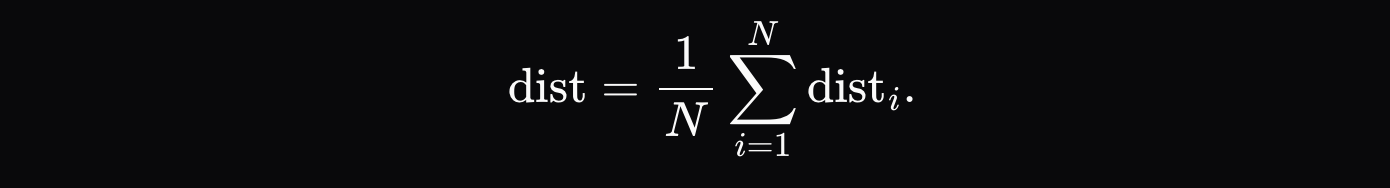
Việc so sánh các xác suất K hàng đầu đã chứng minh là đủ để phát hiện các mô hình hoàn toàn khác nhau, hoặc thậm chí các phiên bản lượng tử hóa khác nhau của cùng một mô hình. Như thể hiện trong biểu đồ bên dưới, khi thử nghiệm giữa các phiên bản lượng tử hóa Qwen3-32B FP8 và INT4, chúng tôi đã đạt được tỷ lệ phát hiện gian lận 99% với không có kết quả dương tính giả nào. Phân phối xác suất của các mô hình khác cũng đủ khác biệt để có thể dễ dàng phát hiện gian lận trong một kỷ nguyên duy nhất, trong khi những người tham gia trung thực vẫn an toàn.
Hình sau đây so sánh số lượng xác minh thành công và thất bại đối với lượng tử hóa Qwen3-32B FP8 (trung thực) so với INT4 (gian lận):
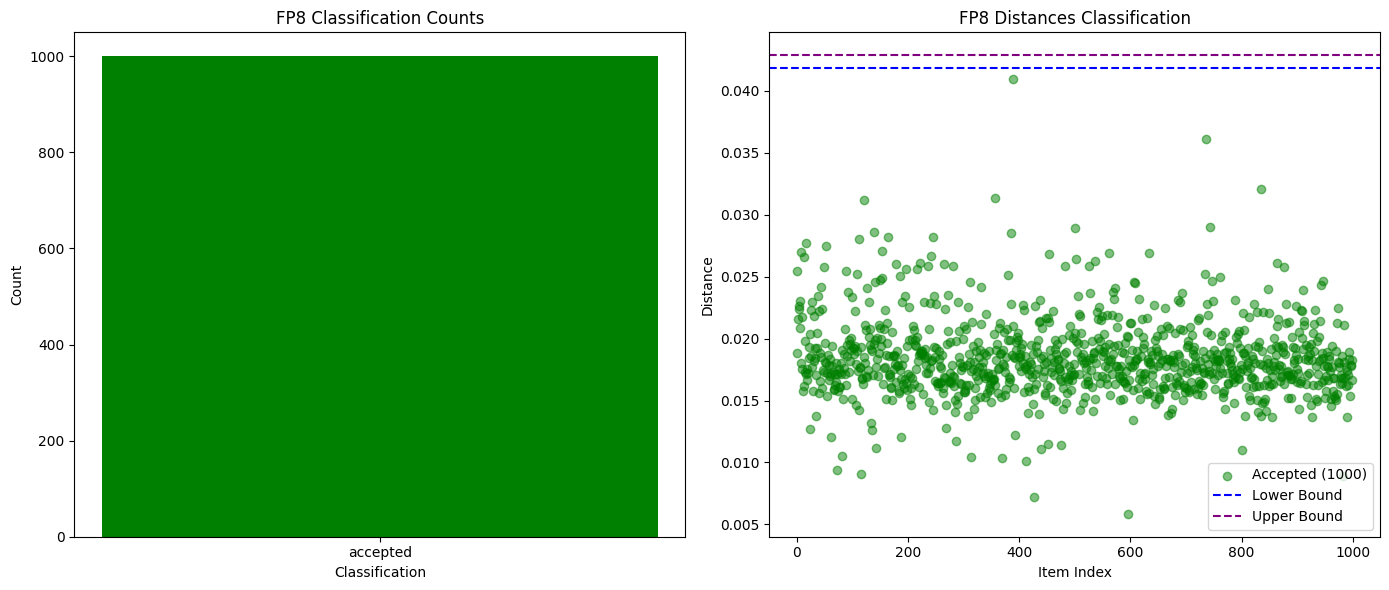
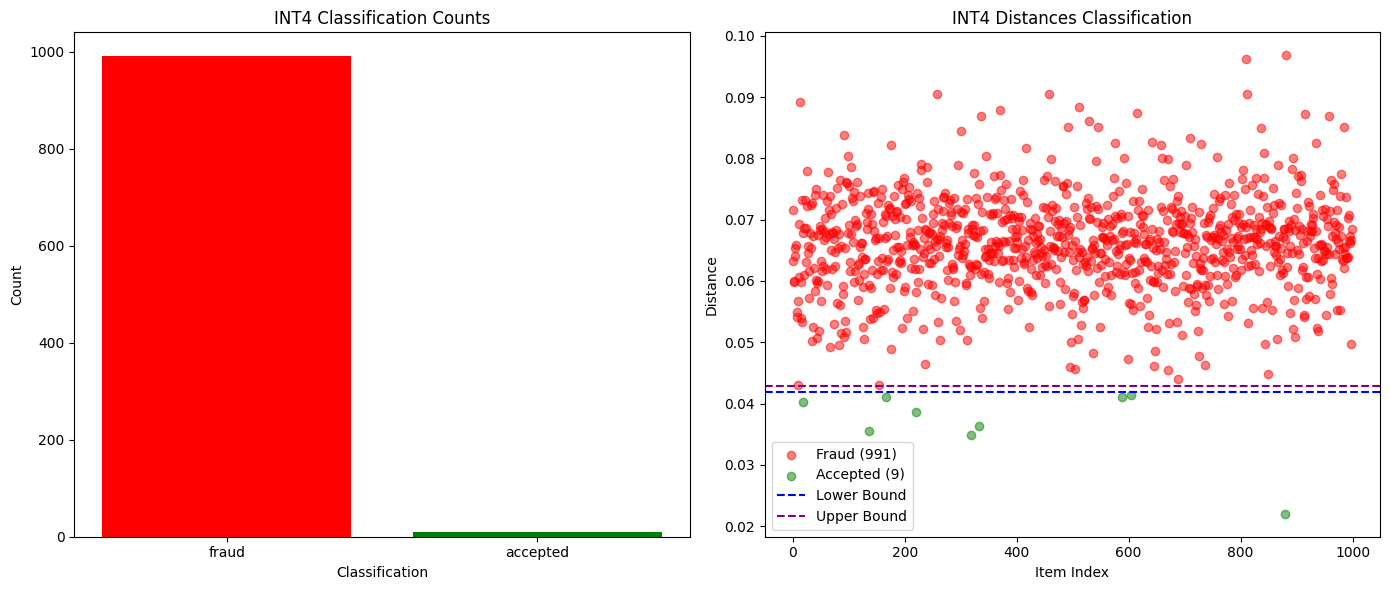
Hình sau đây cho thấy sự thay đổi trong khoảng cách phân phối xác suất của lượng tử hóa Qwen3-32B FP8 (trung thực) so với INT4 (gian lận) theo hàm số của độ dài chuỗi:
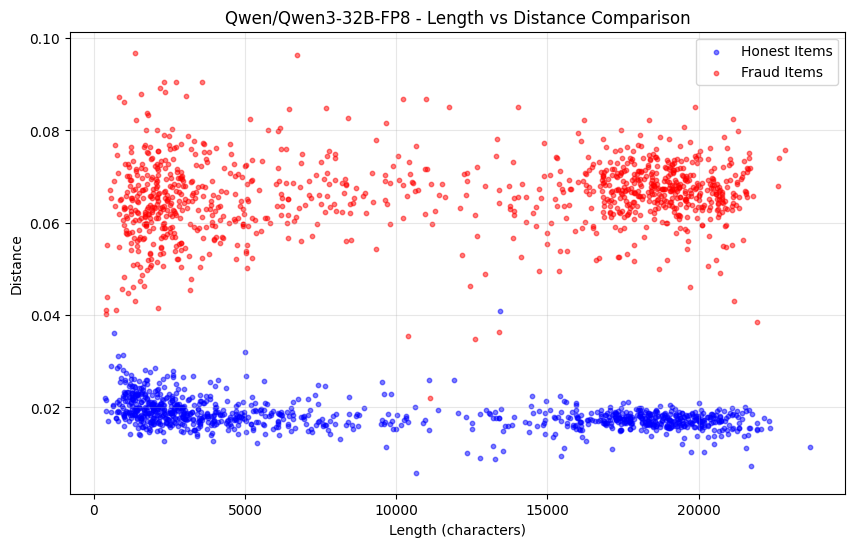
Tuy nhiên, nhược điểm của phương pháp này là nó không bảo vệ chống lại các cuộc tấn công điền trước. Nếu xác suất khớp với phân phối của mô hình đầy đủ, nhưng các chuỗi được tạo ra thông qua một mô hình nhỏ hơn, chúng ta có một số phương pháp bổ sung để phát hiện tình huống này.
Giải pháp 2: Phát hiện sự bối rối (Phòng thủ chống lại các cuộc tấn công điền trước)
Ngoài việc xác minh rằng bằng chứng đến từ mô hình chính xác, chúng tôi còn kiểm tra xem văn bản đầu ra có "có khả năng" đến từ phân phối xác suất của bằng chứng hay không.
Nếu chuỗi được tạo ra bởi một mô hình khác, độ phức tạp của nó so với phân phối xác suất của mô hình được yêu cầu sẽ cao bất thường. Trong thử nghiệm, sự khác biệt về độ phức tạp giữa các cuộc tấn công được điền sẵn Qwen2.5-7B và Qwen2.5-3B là đáng kể.
Cách trực quan nhất để phát hiện các cuộc tấn công điền trước là kiểm tra sự bối rối: ngoài việc xác minh rằng chứng thực được tạo ra bởi mô hình được yêu cầu, chúng ta cũng có thể kiểm tra xem văn bản đầu ra có khả năng được tạo ra từ bản phân phối đã gửi hay không:
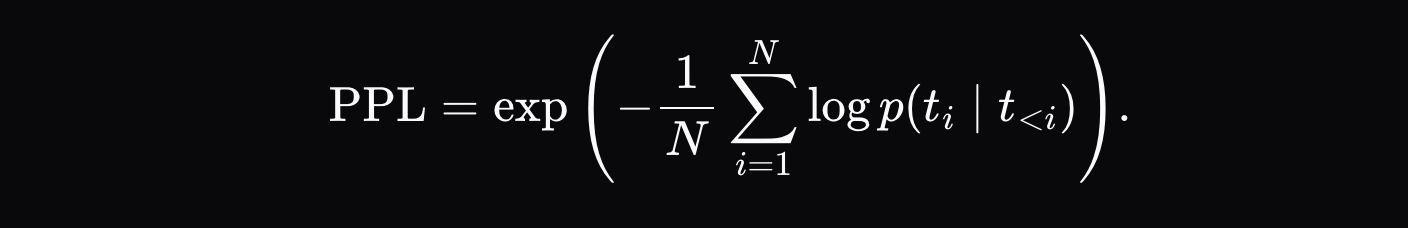
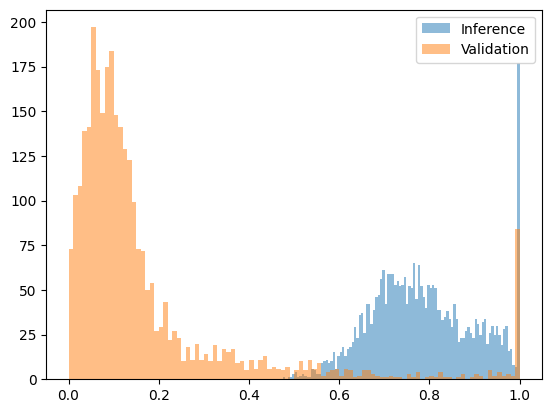
Nếu độ phức tạp quá cao, điều đó cho thấy chuỗi có khả năng được tạo ra bởi một mô hình khác. Cách tiếp cận này hiệu quả trong việc phòng thủ chống lại các cuộc tấn công sử dụng các mô hình khác biệt đáng kể. Khi chúng tôi kiểm tra các chuỗi được tạo ra bởi Qwen2.5-3B nhưng được cho là từ Qwen2.5-7B, sự khác biệt về độ phức tạp đủ đáng kể để thiết lập một ngưỡng rõ ràng. Hình bên dưới cho thấy một hàm độ phức tạp đã được biến đổi, được điều chỉnh theo khoảng [0, 1], trong đó đầu ra của mô hình 7B chủ yếu nằm dưới 0,2, trong khi đầu ra của cuộc tấn công được điền sẵn (đầu ra của mô hình 3B với xác suất của mô hình 7B) đều nằm trên 0,4.
Hình sau đây cho thấy hàm phức tạp sau khi chuyển đổi Qwen2.5-7B (trung thực) so với Qwen2.5-3B tấn công được điền sẵn (gian lận):
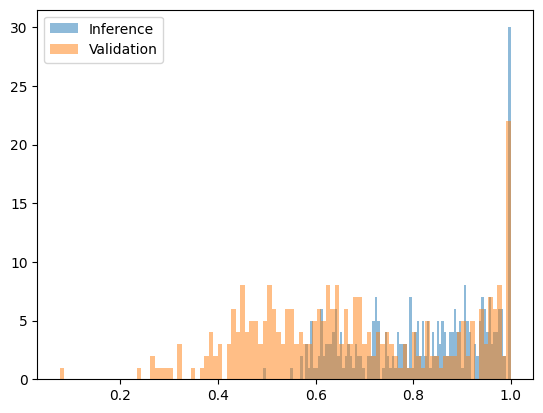
Tuy nhiên, việc phát hiện độ phức tạp có những hạn chế khi so sánh các mô hình tương tự và các phiên bản lượng tử hóa khác nhau của cùng một mô hình. Ví dụ, khi so sánh phiên bản lượng tử hóa w8a16 và w8a8 của Qwen2.5-7B Base, không có sự khác biệt đáng kể nào được thể hiện.
Hình sau đây cho thấy hàm phức tạp sau phép biến đổi lượng tử hóa Qwen2.5-7B w8a16 (trung thực) so với w8a8 (gian lận):
May mắn thay, việc sử dụng một mô hình tương tự cho một cuộc tấn công thường không mang lại hiệu quả kinh tế. Nếu họ chạy một mô hình có chi phí bằng 70-90% mô hình được công bố, cộng với việc tính toán điểm số so với mô hình thực tế, họ có thể thực sự tốn nhiều tài nguyên tính toán hơn so với việc chỉ chạy mô hình thực tế.
Điều quan trọng cần lưu ý là một kết quả đầu ra có xác suất thấp duy nhất do một người tham gia trung thực tạo ra sẽ không làm giảm đáng kể danh tiếng của họ. Nếu kết quả đầu ra có xác suất thấp này không tồn tại lâu dài đối với người tham gia đó, tức là nó chỉ là một giá trị ngoại lệ thống kê ngẫu nhiên, thì họ vẫn sẽ nhận được toàn bộ phần thưởng vào cuối kỷ nguyên.
Giải pháp 3: Liên kết hạt giống RNG (giải pháp xác định)
Đây là giải pháp triệt để nhất: liên kết chuỗi đầu ra với hạt giống của máy phát số ngẫu nhiên.
Bộ thực thi khởi tạo RNG bằng cách sử dụng hạt giống xác định được lấy từ yêu cầu (ví dụ: `run_seed = SHA256(user_seed || inference_id_from_chain)`). Bằng chứng xác minh chứa hạt giống này và phân phối xác suất.
Trình xác minh sử dụng cùng một hạt giống để xác minh rằng nếu chuỗi thực sự xuất phát từ phân phối xác suất của mô hình được yêu cầu, kết quả đầu ra tương tự sẽ được tái tạo. Điều này cung cấp câu trả lời "có/không" mang tính xác định, loại bỏ hoàn toàn các cuộc tấn công điền trước, và chi phí xác minh thấp hơn nhiều so với suy luận đầy đủ.
04. Triển vọng: Hướng tới tương lai AI phi tập trung
Chúng tôi chia sẻ những thực hành và suy ngẫm này xuất phát từ niềm tin vững chắc vào tương lai của AI phi tập trung. Khi các mô hình AI ngày càng thâm nhập vào cuộc sống, nhu cầu gắn kết đầu ra của mô hình với các tham số cụ thể sẽ ngày càng mạnh mẽ hơn.
Sơ đồ xác minh do mạng Gonka lựa chọn đã được chứng minh là khả thi trong thực tế và các thành phần của nó cũng có thể được tái sử dụng trong các tình huống khác khi cần xác minh tính xác thực của lý luận AI.
Trí tuệ nhân tạo phi tập trung không chỉ là một bước tiến công nghệ; nó là sự chuyển đổi của quan hệ sản xuất. Nó cố gắng giải quyết các vấn đề cơ bản về lòng tin thông qua các thuật toán và cơ chế kinh tế trong một môi trường mở. Mặc dù chặng đường phía trước còn dài, nhưng chúng ta đã có những bước tiến vững chắc.


