
Gate Ventures Research Insights: Cuộc chiến trình duyệt lần thứ ba, Trận chiến gia nhập trong Kỷ nguyên tác nhân AI
Tóm lại
Cuộc chiến trình duyệt thứ ba đang âm thầm diễn ra. Nhìn lại lịch sử, từ Netscape và IE của Microsoft vào những năm 1990 đến Firefox nguồn mở và Chrome của Google, cuộc chiến trình duyệt luôn là sự phản ánh tập trung của việc kiểm soát nền tảng và sự thay đổi mô hình công nghệ. Chrome đã giành được vị trí thống lĩnh nhờ tốc độ cập nhật và liên kết sinh thái, trong khi Google đã hình thành một vòng khép kín của việc nhập thông tin thông qua cấu trúc "song quyền" của tìm kiếm và trình duyệt.
Nhưng ngày nay, mô hình này đang bị lung lay. Sự trỗi dậy của các mô hình ngôn ngữ lớn (LLM) đã cho phép ngày càng nhiều người dùng hoàn thành các tác vụ trên các trang kết quả tìm kiếm với "không nhấp chuột", và các nhấp chuột vào trang web truyền thống đang giảm dần. Đồng thời, tin đồn rằng Apple có ý định thay thế công cụ tìm kiếm mặc định trong Safari tiếp tục đe dọa nền tảng lợi nhuận của Alphabet (công ty mẹ của Google) và thị trường đã bắt đầu cho thấy sự lo lắng về "chính thống tìm kiếm".
Bản thân trình duyệt cũng đang phải đối mặt với việc định hình lại vai trò. Nó không chỉ là một công cụ để hiển thị các trang web mà còn là một tập hợp nhiều khả năng như nhập dữ liệu, hành vi của người dùng và danh tính riêng tư. Mặc dù AI Agent rất mạnh mẽ, nhưng nó vẫn cần phải dựa vào ranh giới tin cậy và hộp cát chức năng của trình duyệt để hoàn thành các tương tác trang phức tạp, gọi dữ liệu danh tính cục bộ và kiểm soát các thành phần trang web. Trình duyệt đang thay đổi từ giao diện người dùng sang nền tảng gọi hệ thống của tác nhân.
Trong bài viết này, chúng tôi sẽ khám phá xem liệu trình duyệt có còn cần thiết hay không. Đồng thời, chúng tôi tin rằng thứ có khả năng phá vỡ thị trường trình duyệt hiện tại không phải là một "Chrome tốt hơn" khác, mà là một cấu trúc tương tác mới: không phải là hiển thị thông tin, mà là gọi các tác vụ. Trong tương lai, trình duyệt nên được thiết kế cho các tác nhân AI - không chỉ đọc mà còn viết và thực thi. Các dự án như Browser Use đang cố gắng ngữ nghĩa hóa cấu trúc trang, biến giao diện trực quan thành văn bản có cấu trúc có thể được LLM gọi, hiện thực hóa việc ánh xạ các trang thành hướng dẫn và giảm đáng kể chi phí tương tác.
Các dự án chính thống trên thị trường đã bắt đầu thử nghiệm: Perplexity đã xây dựng một trình duyệt gốc Comet, sử dụng AI để thay thế kết quả tìm kiếm truyền thống; Brave kết hợp bảo vệ quyền riêng tư với lý luận cục bộ, sử dụng LLM để tăng cường chức năng tìm kiếm và chặn; và các dự án gốc Crypto như Donut đang nhắm mục tiêu vào các điểm vào mới để AI tương tác với các tài sản trên chuỗi. Điểm chung của các dự án này là chúng cố gắng tái tạo đầu vào của trình duyệt thay vì làm đẹp lớp đầu ra của nó.
Đối với các doanh nhân, cơ hội ẩn chứa trong mối quan hệ tam giác giữa đầu vào, cấu trúc và tác nhân. Là giao diện để các tác nhân gọi thế giới trong tương lai, trình duyệt có nghĩa là bất kỳ ai có thể cung cấp "khối khả năng" có cấu trúc, có thể gọi và đáng tin cậy đều có thể trở thành một phần của thế hệ nền tảng mới. Từ SEO đến AEO (Tối ưu hóa công cụ tác nhân), từ lưu lượng truy cập trang đến các cuộc gọi chuỗi tác vụ, biểu mẫu sản phẩm và tư duy thiết kế đang được tái cấu trúc. Cuộc chiến trình duyệt thứ ba diễn ra ở "đầu vào" thay vì "hiển thị"; người chiến thắng không còn được xác định bởi ai thu hút sự chú ý của người dùng, mà là ai giành được sự tin tưởng của tác nhân và có được điểm vào để gọi.
Lịch sử tóm tắt về sự phát triển của trình duyệt
Vào đầu những năm 1990, khi Internet vẫn chưa trở thành một phần của cuộc sống hàng ngày, Netscape Navigator đã ra đời, giống như một con tàu buồm mở ra một lục địa mới, mở ra cánh cửa đến với thế giới số cho hàng triệu người dùng. Trình duyệt này không phải là trình duyệt đầu tiên, nhưng nó là sản phẩm đầu tiên thực sự đến với đại chúng và định hình trải nghiệm Internet. Vào thời điểm đó, lần đầu tiên, mọi người có thể duyệt web dễ dàng như vậy thông qua giao diện đồ họa, như thể toàn bộ thế giới đột nhiên trở nên trong tầm tay.
Tuy nhiên, vinh quang thường ngắn ngủi. Microsoft sớm nhận ra tầm quan trọng của trình duyệt và quyết định đưa Internet Explorer vào hệ điều hành Windows, biến nó thành trình duyệt mặc định. Chiến lược này có thể được gọi là "kẻ giết chết nền tảng" và trực tiếp làm suy yếu sự thống trị thị trường của Netscape. Nhiều người dùng không chủ động chọn IE, nhưng chấp nhận nó vì hệ thống chấp nhận nó theo mặc định. Với sự trợ giúp của khả năng phân phối của Windows, IE nhanh chóng trở thành người dẫn đầu ngành và Netscape rơi vào con đường suy thoái.

Sự tiến hóa của logo Firefox
Trong tình hình khó khăn, các kỹ sư Netscape đã chọn một con đường cấp tiến và lý tưởng - họ công khai mã nguồn trình duyệt và kêu gọi cộng đồng nguồn mở. Quyết định này dường như là một "sự nhượng bộ của Macedonia" trong thế giới công nghệ, báo hiệu sự kết thúc của kỷ nguyên cũ và sự trỗi dậy của các thế lực mới. Mã này sau đó đã trở thành cơ sở của dự án trình duyệt Mozilla, ban đầu được đặt tên là Phoenix (có nghĩa là niết bàn phượng hoàng), nhưng đã được đổi tên nhiều lần do các vấn đề về nhãn hiệu và cuối cùng được đặt tên là Firefox.
Firefox không phải là bản sao đơn giản của Netscape. Nó đã đạt được nhiều đột phá về trải nghiệm người dùng, hệ sinh thái plug-in, bảo mật, v.v. Sự ra đời của nó đánh dấu chiến thắng của tinh thần nguồn mở và truyền sức sống mới vào toàn bộ ngành công nghiệp. Một số người mô tả Firefox là "người kế thừa tinh thần" của Netscape, giống như Đế chế Ottoman thừa hưởng ánh hào quang của Byzantium. Mặc dù phép ẩn dụ này có phần cường điệu, nhưng nó khá có ý nghĩa.
Nhưng vài năm trước khi Firefox chính thức được phát hành, Microsoft đã phát hành sáu phiên bản IE. Dựa vào lợi thế về thời gian và chiến lược đóng gói hệ thống, Firefox đã ở vị thế bắt kịp ngay từ đầu, điều đó có nghĩa là cuộc cạnh tranh này không phải là cuộc cạnh tranh công bằng với điểm xuất phát ngang nhau.
Cùng lúc đó, một trình duyệt khác cũng âm thầm ra mắt. Năm 1994, trình duyệt Opera ra đời tại Na Uy và ban đầu chỉ là một dự án thử nghiệm. Nhưng bắt đầu từ phiên bản 7.0 năm 2003, trình duyệt này đã giới thiệu công cụ Presto của riêng mình và là trình duyệt đầu tiên hỗ trợ các công nghệ tiên tiến như CSS, bố cục thích ứng, điều khiển bằng giọng nói và mã hóa Unicode. Mặc dù số lượng người dùng có hạn, nhưng trình duyệt này luôn đi đầu trong ngành về mặt công nghệ, trở thành "trình duyệt được yêu thích của dân mê công nghệ".
Cùng năm đó, Apple đã ra mắt trình duyệt Safari. Đây là một bước ngoặt quan trọng. Vào thời điểm đó, Microsoft đã đầu tư 150 triệu đô la vào Apple, công ty đang trên bờ vực phá sản, để duy trì vẻ ngoài cạnh tranh và tránh sự giám sát của luật chống độc quyền. Mặc dù công cụ tìm kiếm mặc định của Safari là Google kể từ khi ra đời, nhưng sự vướng mắc mang tính lịch sử này với Microsoft tượng trưng cho mối quan hệ phức tạp và tinh tế giữa những gã khổng lồ Internet: hợp tác và cạnh tranh luôn song hành.
Năm 2007, IE 7 được ra mắt cùng với Windows Vista, nhưng phản ứng của thị trường lại khá tầm thường. Mặt khác, Firefox, với nhịp độ cập nhật nhanh hơn, cơ chế mở rộng thân thiện hơn và sức hấp dẫn tự nhiên đối với các nhà phát triển, đã liên tục tăng thị phần lên khoảng 20%. Sự thống trị của IE đang dần mất đi và hướng gió đang thay đổi.
Google có cách tiếp cận khác. Mặc dù đã có kế hoạch xây dựng trình duyệt riêng từ năm 2001, nhưng phải mất sáu năm để thuyết phục CEO Eric Schmidt chấp thuận dự án. Chrome được ra mắt vào năm 2008, dựa trên dự án mã nguồn mở Chromium và công cụ WebKit được Safari sử dụng. Nó được mệnh danh là trình duyệt "phồng rộp", nhưng nhanh chóng trở nên nổi tiếng nhờ chuyên môn sâu sắc của Google về quảng cáo và xây dựng thương hiệu.
Vũ khí chính của Chrome không phải là các tính năng, mà là các bản cập nhật phiên bản thường xuyên (sáu tuần một lần) và trải nghiệm thống nhất trên mọi nền tảng. Vào tháng 11 năm 2011, Chrome đã vượt qua Firefox lần đầu tiên, đạt thị phần 27%; sáu tháng sau, nó đã vượt qua IE, hoàn thành quá trình chuyển đổi từ một đối thủ cạnh tranh thành một đối thủ thống trị.
Cùng lúc đó, Internet di động của Trung Quốc cũng đang hình thành hệ sinh thái riêng. UC Browser của Alibaba nhanh chóng trở nên phổ biến vào đầu những năm 2010, đặc biệt là ở các thị trường mới nổi như Ấn Độ, Indonesia và Trung Quốc. Nó đã giành được sự ủng hộ của người dùng thiết bị cấp thấp với thiết kế nhẹ, tính năng nén dữ liệu và tiết kiệm lưu lượng. Năm 2015, thị phần trình duyệt di động toàn cầu của nó đã vượt quá 17% và từng đạt 46% tại Ấn Độ. Nhưng chiến thắng này không kéo dài. Khi chính phủ Ấn Độ tăng cường đánh giá bảo mật các ứng dụng của Trung Quốc, UC Browser đã buộc phải rút lui khỏi các thị trường quan trọng và dần mất đi vinh quang trước đây.

Thị phần trình duyệt, nguồn: statcounter
Bước vào những năm 2020, sự thống trị của Chrome đã được thiết lập, với thị phần toàn cầu khoảng 65%. Điều đáng chú ý là mặc dù công cụ tìm kiếm Google và trình duyệt Chrome thuộc về Alphabet, nhưng chúng là hai hệ thống bá quyền độc lập theo quan điểm thị trường - công cụ trước kiểm soát khoảng 90% các cổng thông tin tìm kiếm trên thế giới, trong khi công cụ sau kiểm soát "cửa sổ đầu tiên" để hầu hết người dùng truy cập Internet.
Để duy trì cấu trúc độc quyền kép này, Google đã đầu tư rất nhiều. Năm 2022, Alphabet đã trả cho Apple khoảng 20 tỷ đô la chỉ để giữ Google làm công cụ tìm kiếm mặc định trong Safari. Một số nhà phân tích chỉ ra rằng khoản chi này tương đương với 36% doanh thu quảng cáo tìm kiếm của Google từ lưu lượng truy cập Safari. Nói cách khác, Google đang trả "phí bảo vệ" cho hào nước của mình.
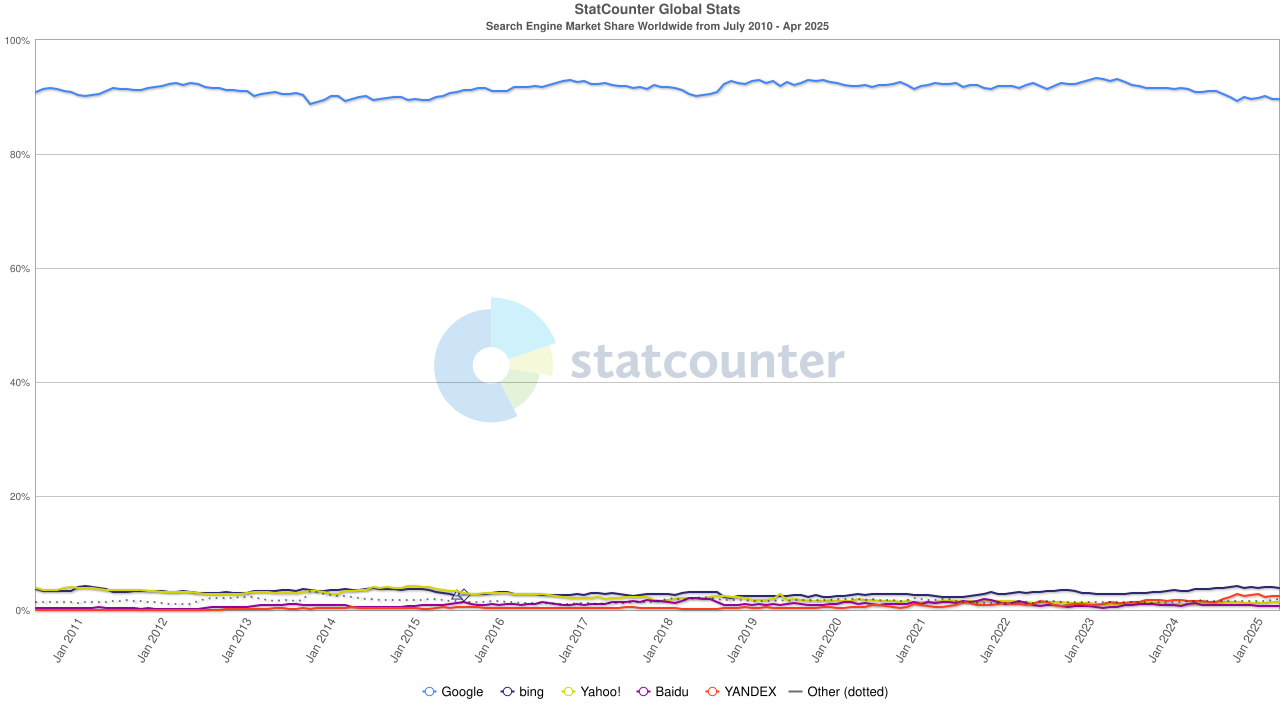
Thị phần công cụ tìm kiếm, nguồn: statcounter
Nhưng hướng gió lại thay đổi một lần nữa. Với sự trỗi dậy của các mô hình ngôn ngữ lớn (LLM), tìm kiếm truyền thống đã bắt đầu bị ảnh hưởng. Vào năm 2024, thị phần tìm kiếm của Google đã giảm từ 93% xuống còn 89%. Mặc dù vẫn thống trị, nhưng các vết nứt đang bắt đầu xuất hiện. Thậm chí còn mang tính lật đổ hơn là tin đồn rằng Apple có thể ra mắt công cụ tìm kiếm AI của riêng mình. Nếu tìm kiếm mặc định của Safari chuyển sang phe của riêng mình, điều này không chỉ viết lại bối cảnh sinh thái mà còn có thể làm rung chuyển trụ cột lợi nhuận của Alphabet. Thị trường đã phản ứng nhanh chóng và giá cổ phiếu của Alphabet đã giảm từ 170 đô la xuống còn 140 đô la, không chỉ phản ánh sự hoảng loạn của các nhà đầu tư mà còn phản ánh sự lo lắng sâu sắc về hướng đi trong tương lai của kỷ nguyên tìm kiếm.

Từ Navigator đến Chrome, từ lý tưởng nguồn mở đến thương mại hóa quảng cáo, từ trình duyệt nhẹ đến trợ lý tìm kiếm AI, cuộc chiến trình duyệt luôn là cuộc chiến về công nghệ, nền tảng, nội dung và kiểm soát. Chiến trường liên tục thay đổi, nhưng bản chất không bao giờ thay đổi: bất kỳ ai kiểm soát lối vào sẽ định nghĩa tương lai.
Trong mắt các VC, dựa vào nhu cầu mới của mọi người về công cụ tìm kiếm trong kỷ nguyên LLM và AI, cuộc chiến trình duyệt thứ ba đang dần diễn ra. Sau đây là tình hình tài trợ của một số dự án trình duyệt AI nổi tiếng.

Kiến trúc cũ của trình duyệt hiện đại
Khi nói đến kiến trúc của trình duyệt, kiến trúc truyền thống cổ điển được thể hiện trong hình bên dưới:

Kiến trúc tổng thể, nguồn: Damien Benveniste
1. Mục nhập frontend của khách hàng
Truy vấn được gửi đến Google Front End gần nhất qua HTTPS, hoàn tất giải mã TLS, lấy mẫu QoS và định tuyến địa lý. Nếu phát hiện lưu lượng bất thường (DDoS, thu thập dữ liệu tự động), có thể giới hạn hoặc thách thức lưu lượng này ở lớp này.
2. Hiểu truy vấn
Phần giao diện cần hiểu được ý nghĩa của các từ do người dùng nhập, bao gồm ba bước: sửa lỗi chính tả thần kinh, sửa "recpie" thành "recipe"; mở rộng từ đồng nghĩa, mở rộng "how to fix bike" thành "repair bicycle"; và phân tích ý định, xác định xem truy vấn là để tìm thông tin, điều hướng hay mục đích giao dịch, rồi chỉ định các yêu cầu theo chiều dọc.
3. Thu hồi ứng cử viên
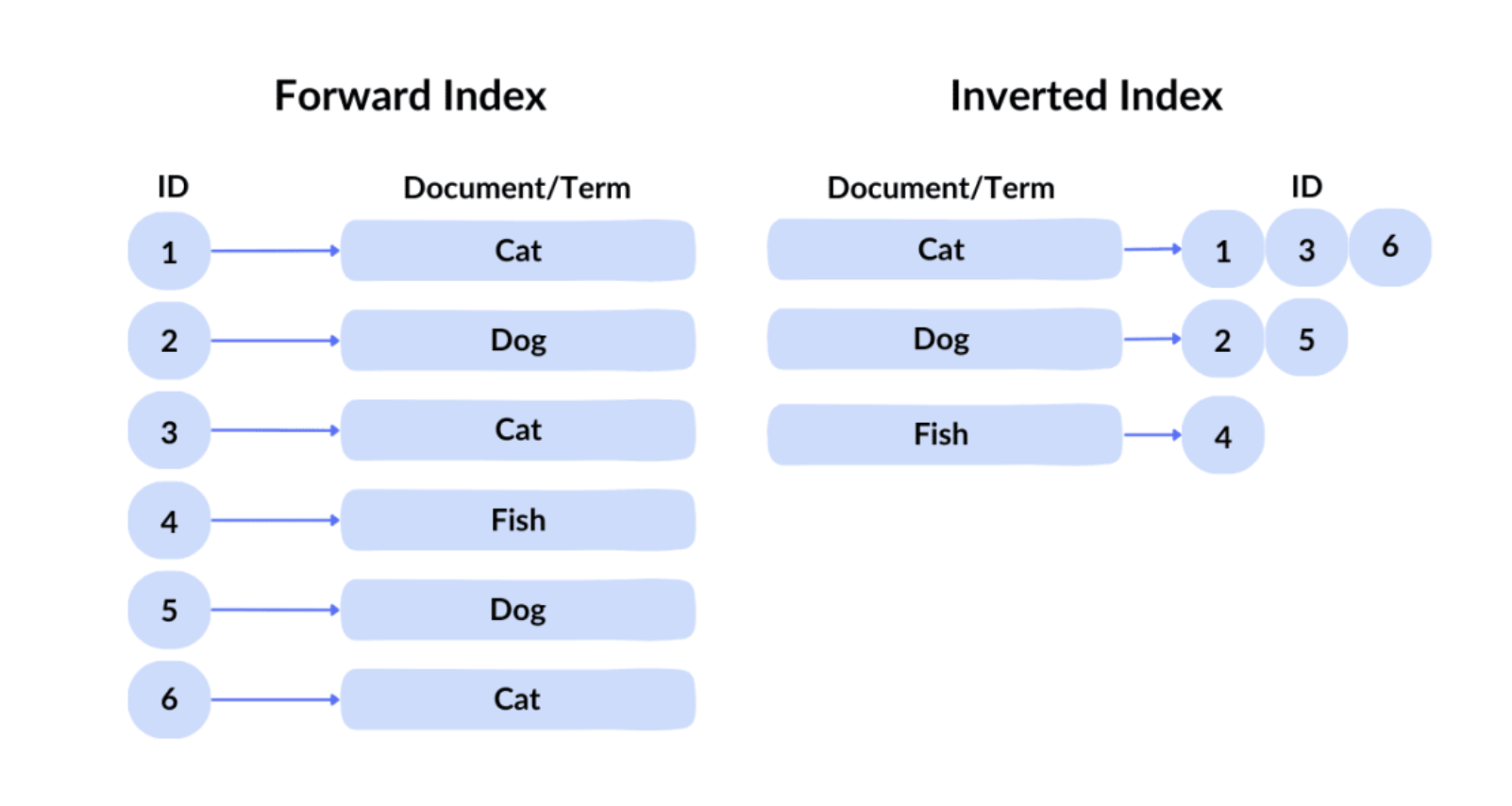
Chỉ số đảo ngược, nguồn: spot intelligence
Công nghệ truy vấn được Google sử dụng được gọi là: inverted index. Trong forward index, chúng ta có thể lập chỉ mục tệp được cung cấp ID. Tuy nhiên, người dùng không thể biết số lượng nội dung mong muốn trong hàng trăm tỷ tệp, vì vậy nó sử dụng inverted index rất truyền thống để truy vấn tệp nào có từ khóa tương ứng thông qua nội dung. Tiếp theo, Google sử dụng vector indexing để xử lý tìm kiếm ngữ nghĩa, tức là tìm nội dung có ý nghĩa tương tự với truy vấn. Nó chuyển đổi văn bản, hình ảnh và nội dung khác thành các vector đa chiều (nhúng) và tìm kiếm dựa trên sự tương đồng giữa các vector này. Ví dụ, ngay cả khi người dùng tìm kiếm "cách làm bột bánh pizza", công cụ tìm kiếm có thể trả về kết quả liên quan đến "hướng dẫn làm bột bánh pizza" vì chúng tương tự về mặt ngữ nghĩa. Sau inverted index và vector index, khoảng 100.000 trang web sẽ được sàng lọc ban đầu.
4. Phân loại nhiều cấp
Hệ thống thường sử dụng hàng nghìn tính năng nhẹ như BM2 5, TF-IDF và điểm chất lượng trang để lọc các trang ứng viên từ hàng trăm nghìn đến khoảng 1.000 trang để tạo thành một tập hợp ứng viên sơ bộ. Các hệ thống như vậy được gọi chung là công cụ đề xuất. Chúng dựa vào các tính năng lớn được tạo ra bởi nhiều thực thể, bao gồm hành vi của người dùng, thuộc tính trang, ý định truy vấn và tín hiệu theo ngữ cảnh. Ví dụ: Google sẽ tích hợp thông tin như lịch sử người dùng, phản hồi về hành vi từ những người dùng khác, ngữ nghĩa trang, ý nghĩa truy vấn, v.v., đồng thời cũng xem xét các yếu tố theo ngữ cảnh như thời gian (thời gian trong ngày, ngày cụ thể trong tuần) và các sự kiện bên ngoài như tin tức thời gian thực.
5. Học sâu để phân loại sơ cấp
Trong giai đoạn truy xuất ban đầu, Google sử dụng các công nghệ như RankBrain và Neural Matching để hiểu ngữ nghĩa của truy vấn và lọc ra các kết quả có liên quan sơ bộ từ một số lượng lớn tài liệu. RankBrain là một hệ thống máy học được Google giới thiệu vào năm 2015, được thiết kế để hiểu rõ hơn ý nghĩa của các truy vấn của người dùng, đặc biệt là những truy vấn xuất hiện lần đầu tiên. Hệ thống này tìm ra các kết quả có liên quan nhất bằng cách chuyển đổi các truy vấn và tài liệu thành các biểu diễn vectơ và tính toán mức độ tương đồng giữa chúng. Ví dụ, đối với truy vấn "cách làm bột bánh pizza", RankBrain có thể xác định nội dung liên quan đến "kiến thức cơ bản về pizza" hoặc "làm bột" ngay cả khi không có từ khóa khớp chính xác nào trong tài liệu.
Neural Matching là một công nghệ khác mà Google ra mắt vào năm 2018 để hiểu sâu hơn về mối quan hệ ngữ nghĩa giữa các truy vấn và tài liệu. Công nghệ này sử dụng mô hình mạng nơ-ron để nắm bắt mối quan hệ mờ nhạt giữa các từ, giúp Google khớp tốt hơn các truy vấn và nội dung trang web. Ví dụ, đối với truy vấn "Tại sao quạt máy tính xách tay của tôi lại ồn như vậy?", Neural Matching có thể hiểu rằng người dùng có thể đang tìm kiếm thông tin khắc phục sự cố về tình trạng quá nhiệt, tích tụ bụi hoặc sử dụng CPU cao, ngay cả khi những từ này không xuất hiện trực tiếp trong truy vấn.
6. Xếp hạng lại sâu: Ứng dụng của mô hình BERT
Sau khi sàng lọc ban đầu các tài liệu có liên quan, Google sử dụng mô hình BERT (Bidirectional Encoder Representations from Transformers) để sắp xếp các tài liệu này tinh tế hơn nhằm đảm bảo rằng các kết quả có liên quan nhất được xếp hạng đầu tiên. BERT là mô hình ngôn ngữ được đào tạo trước dựa trên Transformer có thể hiểu được mối quan hệ theo ngữ cảnh giữa các từ trong một câu. Trong tìm kiếm, BERT được sử dụng để xếp hạng lại các tài liệu được truy xuất ban đầu. Nó xếp hạng lại các tài liệu bằng cách mã hóa chung truy vấn và tài liệu và tính toán điểm liên quan giữa chúng. Ví dụ: đối với truy vấn "đỗ xe trên đường dốc không có lề đường", BERT có thể hiểu nghĩa của "không có lề đường" và trả về một trang khuyến nghị tài xế quay vô lăng về phía lề đường, thay vì hiểu sai thành tình huống có lề đường. Đối với các kỹ sư SEO, cần phải tìm hiểu chính xác các thuật toán đề xuất của xếp hạng Google và máy học để tối ưu hóa nội dung của các trang web theo cách có mục tiêu để có được thứ hạng hiển thị cao hơn.
Trên đây là quy trình làm việc điển hình của công cụ tìm kiếm Google. Tuy nhiên, trong thời đại bùng nổ AI và dữ liệu lớn hiện nay, người dùng có nhu cầu mới về tương tác trên trình duyệt.
Tại sao AI sẽ định hình lại trình duyệt
Trước hết, chúng ta cần làm rõ lý do tại sao biểu mẫu trình duyệt vẫn tồn tại? Có một biểu mẫu thứ ba, một tùy chọn khác ngoài các tác nhân trí tuệ nhân tạo và trình duyệt không?
Chúng tôi tin rằng sự tồn tại là không thể thay thế. Tại sao trí tuệ nhân tạo có thể sử dụng trình duyệt nhưng không thể thay thế hoàn toàn chúng? Bởi vì trình duyệt là nền tảng phổ quát, không chỉ là điểm vào để đọc dữ liệu mà còn là điểm vào phổ quát để nhập dữ liệu. Thế giới này không chỉ có thể nhập thông tin mà còn phải tạo dữ liệu và tương tác với các trang web, vì vậy các trình duyệt tích hợp thông tin người dùng được cá nhân hóa vẫn sẽ tồn tại rộng rãi.
Chúng tôi nắm bắt được điểm này: trình duyệt là điểm vào chung, không chỉ để đọc dữ liệu mà người dùng thường cần tương tác với dữ liệu. Bản thân trình duyệt là nơi tuyệt vời để lưu trữ dấu vân tay người dùng. Các hành vi người dùng phức tạp hơn và các hành vi tự động phải được thực hiện thông qua trình duyệt. Trình duyệt có thể lưu trữ tất cả dấu vân tay hành vi người dùng, thông qua và thông tin riêng tư khác, và triển khai các cuộc gọi không cần tin cậy trong quá trình tự động hóa. Các hành động tương tác với dữ liệu có thể phát triển thành:
Người dùng → Gọi tác nhân AI → Trình duyệt.
Nói cách khác, phần duy nhất có thể thay thế là phần phù hợp với xu hướng tiến hóa của thế giới - thông minh hơn, cá nhân hóa hơn và tự động hóa hơn. Phải thừa nhận rằng, phần này có thể được xử lý bởi AI Agent, nhưng bản thân AI Agent không phải là nơi phù hợp để mang nội dung được cá nhân hóa của người dùng, vì nó phải đối mặt với nhiều thách thức về bảo mật dữ liệu và sự tiện lợi. Cụ thể:
Trình duyệt là nơi lưu trữ nội dung được cá nhân hóa:
1. Hầu hết các mô hình lớn đều được lưu trữ trên đám mây và bối cảnh phiên được lưu trên máy chủ, khiến việc gọi trực tiếp dữ liệu nhạy cảm như mật khẩu cục bộ, ví và cookie trở nên khó khăn.
2. Việc gửi tất cả dữ liệu duyệt web và thanh toán đến mô hình của bên thứ ba yêu cầu phải được người dùng ủy quyền lại; cả luật bảo mật của EU DMA và luật riêng tư của tiểu bang Hoa Kỳ đều yêu cầu giảm thiểu việc truyền dữ liệu ra ngoài.
3. Tự động điền mã xác minh hai yếu tố, gọi camera hoặc sử dụng GPU để suy luận WebGPU đều phải được thực hiện trong hộp cát của trình duyệt.
4. Bối cảnh dữ liệu phụ thuộc rất nhiều vào trình duyệt, bao gồm các tab, cookie, IndexedDB, Service Worker Cache, thông tin xác thực Passkey và dữ liệu mở rộng, tất cả đều được lưu trữ trong trình duyệt.
Một sự thay đổi sâu sắc về hình thức tương tác
Quay lại chủ đề ban đầu, hành vi sử dụng trình duyệt của chúng ta có thể được chia thành ba dạng: đọc dữ liệu, nhập dữ liệu và tương tác với dữ liệu. Mô hình lớn trí tuệ nhân tạo (LLM) đã thay đổi sâu sắc hiệu quả và cách đọc dữ liệu. Trước đây, hành vi tìm kiếm trang web dựa trên từ khóa của người dùng có vẻ rất cũ và kém hiệu quả.
Đã có nhiều nghiên cứu phân tích sự phát triển của hành vi tìm kiếm của người dùng - để có được câu trả lời tóm tắt hay nhấp vào trang web.
Về mặt hành vi của người dùng, một nghiên cứu năm 2024 cho thấy trong mỗi 1.000 truy vấn Google tại Hoa Kỳ, chỉ có 374 truy vấn nhấp vào trang web đang mở. Nói cách khác, gần 63% là hành vi "không nhấp". Người dùng đã quen với việc lấy thông tin như thời tiết, tỷ giá hối đoái và thẻ kiến thức trực tiếp từ trang kết quả tìm kiếm.
Về mặt tâm lý người dùng, một cuộc khảo sát năm 2023 chỉ ra rằng 44% số người được hỏi tin rằng kết quả tự nhiên thông thường đáng tin cậy hơn các đoạn trích nổi bật. Nghiên cứu học thuật cũng phát hiện ra rằng trong các chủ đề gây tranh cãi hoặc không có sự thật thống nhất, người dùng thích các trang kết quả có chứa nhiều liên kết nguồn.
Nói cách khác, một số người dùng không tin tưởng nhiều vào bản tóm tắt AI, nhưng một tỷ lệ đáng kể hành vi của người dùng đã chuyển sang "không nhấp chuột". Do đó, trình duyệt AI vẫn cần khám phá một hình thức tương tác phù hợp - đặc biệt là trong phần đọc dữ liệu, vì "vấn đề ảo giác" của mô hình lớn hiện tại vẫn chưa được xóa bỏ và nhiều người dùng vẫn thấy khó tin tưởng hoàn toàn vào bản tóm tắt nội dung được tạo tự động. Về vấn đề này, nếu mô hình lớn được nhúng vào trình duyệt, thực tế không cần phải thực hiện thay đổi đột ngột đối với trình duyệt, mà chỉ cần giải quyết dần độ chính xác và khả năng kiểm soát của mô hình. Sự cải thiện này cũng đang được thúc đẩy liên tục.
Điều thực sự có thể gây ra sự thay đổi lớn trong trình duyệt là lớp tương tác dữ liệu. Trước đây, mọi người hoàn thành tương tác bằng cách nhập từ khóa - đây là giới hạn mà trình duyệt có thể hiểu được. Bây giờ, người dùng ngày càng có xu hướng sử dụng toàn bộ một đoạn văn ngôn ngữ tự nhiên để mô tả các tác vụ phức tạp, chẳng hạn như:
● “Tìm chuyến bay thẳng từ New York đến Los Angeles trong một khoảng thời gian nhất định”
● “Đang tìm chuyến bay từ New York đến Thượng Hải và sau đó đến Los Angeles”
Những hành vi này, ngay cả đối với con người, cũng đòi hỏi rất nhiều thời gian để truy cập nhiều trang web, thu thập và so sánh dữ liệu. Tuy nhiên, các tác vụ đại lý này đang dần được các tác nhân AI tiếp quản.
Điều này cũng phù hợp với hướng tiến hóa lịch sử: tự động hóa và trí thông minh. Mọi người háo hức giải phóng đôi tay của mình và các tác nhân AI sẽ được nhúng sâu vào trình duyệt. Các trình duyệt trong tương lai phải được thiết kế để tự động hóa hoàn toàn, đặc biệt là khi xem xét:
● Làm thế nào để cân bằng giữa trải nghiệm đọc của con người và khả năng phân tích cú pháp của AI Agent,
● Cách phục vụ cả người dùng và mô hình tác nhân trên cùng một trang.
Chỉ khi thiết kế đáp ứng được hai yêu cầu này thì trình duyệt mới thực sự trở thành nền tảng ổn định để AI Agent thực hiện nhiệm vụ.
Tiếp theo, chúng tôi sẽ tập trung vào năm dự án rất được mong đợi, bao gồm Browser Use, Arc (The Browser Company), Perplexity, Brave và Donut. Các dự án này đại diện cho sự phát triển trong tương lai của trình duyệt AI và tiềm năng tích hợp gốc của chúng trong các kịch bản Web3 và Crypto.
Sử dụng trình duyệt
Đây là logic cốt lõi đằng sau khoản tài trợ khổng lồ cho Perplexity và Browser Use. Đặc biệt, Browser Use là cơ hội đổi mới có tiềm năng tăng trưởng và chắc chắn thứ hai xuất hiện trong nửa đầu năm 2025.

Sử dụng trình duyệt, nguồn: Sử dụng trình duyệt
Trình duyệt đã xây dựng một lớp ngữ nghĩa thực sự, cốt lõi của lớp này là xây dựng kiến trúc nhận dạng ngữ nghĩa cho thế hệ trình duyệt tiếp theo.
Browser Use giải mã "DOM = cây nút cho con người" theo cách truyền thống thành "DOM ngữ nghĩa = cây hướng dẫn cho LLM", cho phép các tác nhân nhấp, điền và tải lên chính xác mà không cần "xem tọa độ của các điểm phim"; tuyến đường này thay thế OCR trực quan hoặc phối hợp Selenium bằng "văn bản có cấu trúc → lệnh gọi hàm", do đó việc thực hiện nhanh hơn, các mã thông báo được lưu và ít lỗi hơn. TechCrunch gọi nó là "lớp keo cho phép AI thực sự hiểu các trang web" và vòng hạt giống trị giá 17 triệu đô la hoàn thành vào tháng 3 là một khoản cược vào sự đổi mới cơ bản này.
Sau khi kết xuất HTML, một cây DOM chuẩn sẽ được hình thành; sau đó trình duyệt sẽ xây dựng một cây trợ năng để cung cấp cho trình đọc màn hình các nhãn "vai trò" và "trạng thái" phong phú hơn.
1. Tóm tắt từng phần tử tương tác (<button>, <input>, v.v.) thành một đoạn JSON có siêu dữ liệu như vai trò, khả năng hiển thị, tọa độ, hành động có thể thực thi, v.v.;
2. Dịch toàn bộ trang thành "danh sách nút ngữ nghĩa" phẳng để LLM đọc ngay tại dấu nhắc hệ thống;
3. Nhận hướng dẫn cấp cao (như click(node_id="btn-Checkout")) do LLM đưa ra và phát lại chúng trên trình duyệt thực. Blog chính thức gọi quá trình này là "chuyển đổi giao diện trang web thành văn bản có cấu trúc có thể được phân tích cú pháp bởi LLM".
Đồng thời, một khi bộ tiêu chuẩn này được đưa vào W3C, nó có thể giải quyết phần lớn vấn đề nhập liệu của trình duyệt. Chúng tôi sử dụng thư ngỏ và trường hợp của The Browser Company để giải thích thêm tại sao ý tưởng của The Browser Company là sai.
Cung
Công ty Browser (công ty mẹ của Arc) đã tuyên bố trong thư ngỏ rằng trình duyệt ARC sẽ bước vào giai đoạn bảo trì thường xuyên và nhóm sẽ tập trung vào DIA, một trình duyệt hoàn toàn hướng đến AI. Bức thư cũng thừa nhận rằng con đường triển khai cụ thể của DIA vẫn chưa được xác định. Đồng thời, nhóm đã đưa ra một số dự đoán về thị trường trình duyệt trong tương lai trong bức thư. Dựa trên những dự đoán này, chúng tôi tin rằng nếu chúng tôi thực sự muốn lật đổ bối cảnh trình duyệt hiện tại, chìa khóa nằm ở việc thay đổi đầu ra ở phía tương tác.
Sau đây là ba dự đoán mà chúng tôi thu thập được từ nhóm ARC về tương lai của thị trường trình duyệt.
Các trang web sẽ không còn là giao diện chính nữa. Các trình duyệt truyền thống được xây dựng để tải các trang web. Nhưng ngày càng nhiều, các trang web — ứng dụng, bài viết và tệp — sẽ trở thành các cuộc gọi công cụ với giao diện trò chuyện AI. Theo nhiều cách, các giao diện trò chuyện đã hoạt động giống như các trình duyệt: chúng tìm kiếm, đọc, tạo, phản hồi. Chúng tương tác với API, LLM, cơ sở dữ liệu. Và mọi người dành hàng giờ mỗi ngày trong đó. Nếu bạn còn nghi ngờ, hãy gọi cho một người anh em họ ở trường trung học hoặc đại học — các giao diện ngôn ngữ tự nhiên, trừu tượng hóa sự nhàm chán của các mô hình điện toán cũ, sẽ tồn tại lâu dài.
Nhưng Web sẽ không biến mất — ít nhất là không phải trong thời gian tới. Figma và The New York Times sẽ không trở nên kém quan trọng hơn. Sếp của bạn sẽ không từ bỏ các công cụ SaaS của nhóm bạn. Hoàn toàn ngược lại. Chúng ta vẫn cần phải chỉnh sửa tài liệu, xem video, đọc các bài viết cuối tuần từ các nhà xuất bản yêu thích của mình. Nói trực tiếp hơn: các trang web sẽ không bị thay thế — chúng vẫn là thiết yếu. Các tab của chúng ta không thể thay thế được, chúng là ngữ cảnh cốt lõi của chúng ta. Đó là lý do tại sao chúng ta nghĩ rằng giao diện mạnh mẽ nhất đối với AI trên máy tính để bàn sẽ không phải là trình duyệt web hoặc giao diện trò chuyện AI — mà sẽ là cả hai. Giống như bơ đậu phộng và thạch. Cũng giống như iPhone kết hợp các danh mục cũ thành một thứ hoàn toàn mới, trình duyệt AI cũng vậy. Ngay cả khi nó không phải của chúng ta chiến thắng.
Giao diện mới bắt đầu từ những giao diện quen thuộc. Trong thế giới mới này, hai lực đối lập đồng thời đúng. Cách chúng ta sử dụng máy tính đang thay đổi nhanh hơn nhiều (do AI) so với hầu hết mọi người thừa nhận. Nhưng đồng thời, chúng ta còn lâu mới từ bỏ hoàn toàn những cách cũ của mình hơn những gì những người trong ngành AI công nhận. Cursor đã chứng minh luận điểm này trong không gian mã hóa: ứng dụng AI đột phá của năm ngoái là một IDE (cũ) — được thiết kế để trở thành AI gốc. OpenAI đã xác nhận lý thuyết này khi họ mua Windsurf (một IDE AI khác), mặc dù Codex vẫn hoạt động âm thầm ở chế độ nền. Chúng tôi tin rằng trình duyệt AI sẽ là mục tiêu tiếp theo.
Đầu tiên, nó tin rằng các trang web không còn là giao diện tương tác chính nữa. Phải thừa nhận rằng, đây là một phán đoán đầy thách thức, và cũng là lý do chính khiến chúng ta có những nghi ngờ về kết quả phản ánh của người sáng lập. Theo chúng tôi, quan điểm này đánh giá thấp đáng kể vai trò của trình duyệt, đây cũng là vấn đề chính mà nó bỏ qua khi khám phá con đường của trình duyệt AI.
Các mô hình lớn rất giỏi trong việc nắm bắt ý định, chẳng hạn như hiểu các lệnh như "đặt cho tôi một chuyến bay". Tuy nhiên, chúng vẫn còn thiếu về mật độ thông tin. Khi người dùng cần bảng điều khiển, sổ ghi chép kiểu Bloomberg Terminal hoặc khung vẽ trực quan như Figma, không gì tuyệt hơn một trang web chuyên dụng được sắp xếp với độ chính xác hoàn hảo đến từng pixel. Thiết kế công thái học được thiết kế riêng cho từng sản phẩm—biểu đồ, chức năng kéo và thả, phím nóng—không phải là thứ trang trí rườm rà, mà là khả năng nhận thức được nén lại. Những khả năng này không thể thực hiện được bằng các tương tác đàm thoại đơn giản. Lấy Gate.com làm ví dụ, nếu người dùng muốn thực hiện các hoạt động đầu tư, chỉ dựa vào đối thoại AI là không đủ vì người dùng phụ thuộc rất nhiều vào thông tin đầu vào, độ chính xác và cách trình bày có cấu trúc.
Nhóm RC có một sai lệch cơ bản trong giả định về đường đi của mình, tức là họ không phân biệt rõ ràng rằng "tương tác" bao gồm hai chiều: đầu vào và đầu ra. Về phía đầu vào, quan điểm của họ là hợp lý trong một số trường hợp và AI thực sự có thể cải thiện hiệu quả của tương tác dựa trên lệnh; nhưng về phía đầu ra, phán đoán này rõ ràng là không cân bằng, bỏ qua vai trò cốt lõi của trình duyệt trong việc trình bày thông tin và trải nghiệm được cá nhân hóa. Ví dụ, Reddit có bố cục và kiến trúc thông tin độc đáo, trong khi AAVE có giao diện và cấu trúc hoàn toàn khác. Là một nền tảng có thể chứa dữ liệu cực kỳ riêng tư và hiển thị nhiều giao diện sản phẩm, khả năng thay thế của trình duyệt ở lớp đầu vào bị hạn chế và về phía đầu ra, tính phức tạp và không chuẩn hóa của nó khiến nó khó bị phá hoại. Ngược lại, các trình duyệt AI hiện tại trên thị trường tập trung nhiều hơn vào cấp độ "tóm tắt đầu ra": tóm tắt các trang web, tinh chỉnh thông tin và đưa ra kết luận, không đủ để tạo thành thách thức cơ bản đối với các trình duyệt chính thống hoặc hệ thống tìm kiếm như Google và chỉ chia sẻ thị phần tóm tắt tìm kiếm.
Do đó, người thực sự có thể làm rung chuyển Chrome, vốn có thị phần lên tới 66%, thì không được định sẵn là "Chrome tiếp theo". Để đạt được sự gián đoạn này, chế độ hiển thị của trình duyệt phải được định hình lại cơ bản để có thể thích ứng với các nhu cầu tương tác do các tác nhân AI thống trị trong kỷ nguyên thông minh, đặc biệt là trong thiết kế kiến trúc của phía đầu vào. Vì lý do này, chúng tôi ủng hộ con đường kỹ thuật mà Browser Use thực hiện - trọng tâm của nó là những thay đổi về mặt cấu trúc trong các cơ chế cơ bản của trình duyệt. Khi bất kỳ hệ thống nào được "nguyên tử hóa" hoặc "mô-đun hóa", khả năng lập trình và khả năng kết hợp kết quả sẽ mang lại tiềm năng phá hoại cực kỳ tàn khốc và đây chính xác là hướng mà Browser Use đang tiến tới hiện nay.
Tóm lại, hoạt động của AI Agent vẫn phụ thuộc rất nhiều vào sự tồn tại của trình duyệt. Trình duyệt không chỉ là nơi lưu trữ chính cho dữ liệu cá nhân phức tạp mà còn là giao diện kết xuất chung cho các ứng dụng đa dạng, do đó, nó sẽ tiếp tục đóng vai trò là lối vào tương tác cốt lõi trong tương lai. Vì AI Agent được nhúng sâu vào trình duyệt để hoàn thành các tác vụ cố định, nên nó sẽ tương tác với các ứng dụng cụ thể bằng cách gọi dữ liệu người dùng, tức là nó chủ yếu hoạt động ở phía đầu vào. Để đạt được mục đích này, chế độ kết xuất hiện tại của trình duyệt cần được cải tiến để đạt được khả năng tương thích và thích ứng tối đa với AI Agent, để nắm bắt các ứng dụng hiệu quả hơn.
Sự bối rối
Perplexity là một công cụ tìm kiếm AI nổi tiếng với hệ thống đề xuất của mình. Định giá mới nhất của công ty lên tới 14 tỷ đô la, gần gấp năm lần so với 3 tỷ đô la vào tháng 6 năm 2024. Công ty xử lý hơn 400 triệu truy vấn tìm kiếm mỗi tháng và xử lý khoảng 250 triệu truy vấn vào tháng 9 năm 2024. Số lượng truy vấn của người dùng tăng gấp tám lần so với cùng kỳ năm trước và số lượng người dùng hoạt động hàng tháng vượt quá 30 triệu.
Tính năng chính của nó là có thể tóm tắt các trang theo thời gian thực, mang lại cho nó lợi thế trong việc thu thập thông tin tức thời. Đầu năm nay, nó đã bắt đầu xây dựng trình duyệt gốc của riêng mình, Comet. Perplexity mô tả Comet sắp ra mắt là một trình duyệt không chỉ "hiển thị" các trang web mà còn "suy nghĩ" về chúng. Các quan chức cho biết nó sẽ nhúng sâu công cụ trả lời của Perplexity vào bên trong trình duyệt, đây là ý tưởng "toàn bộ máy" theo phong cách Steve Jobs: chôn các tác vụ AI sâu vào lớp dưới cùng của trình duyệt, thay vì tạo các plug-in thanh bên. Thay thế "mười liên kết màu xanh lam" truyền thống bằng các câu trả lời ngắn gọn có trích dẫn, cạnh tranh trực tiếp với Chrome.
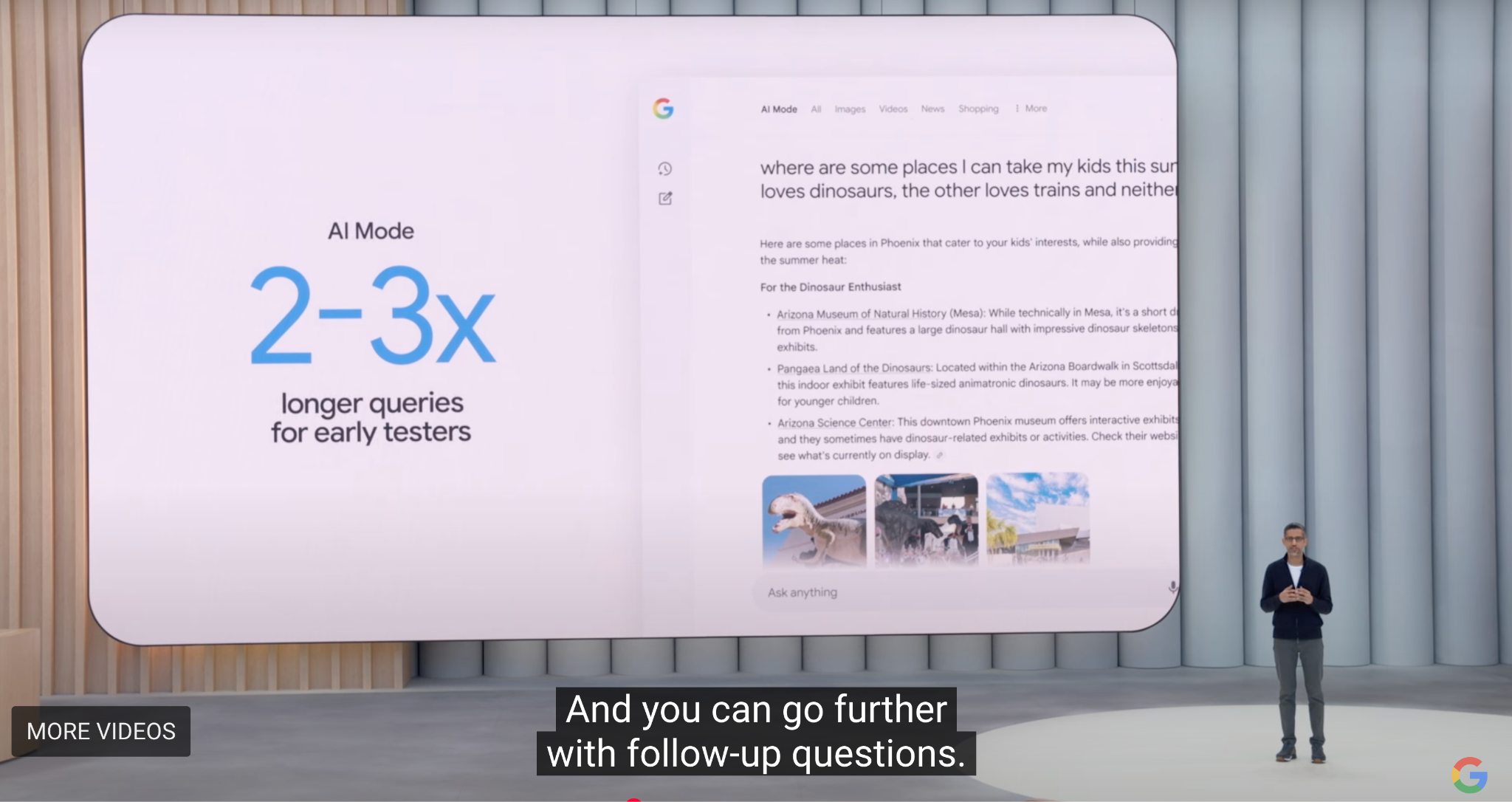
Google I/O 2025
Nhưng vẫn cần giải quyết hai vấn đề cốt lõi: chi phí tìm kiếm cao và biên lợi nhuận thấp từ người dùng biên. Mặc dù Perplexity đã ở vị trí dẫn đầu trong lĩnh vực tìm kiếm AI, Google cũng đã công bố việc định hình lại thông minh trên quy mô lớn các sản phẩm cốt lõi của mình tại hội nghị I/O năm 2025. Để đáp lại việc định hình lại trình duyệt, Google đã ra mắt trải nghiệm tab trình duyệt mới có tên là AI Model, tích hợp Tổng quan, Nghiên cứu sâu và các tính năng Agentic trong tương lai. Dự án tổng thể có tên là "Project Mariner".
Google đang tích cực định hình lại AI, vì vậy rất khó để tạo ra mối đe dọa thực sự đối với AI chỉ bằng cách bắt chước các chức năng của nó trên bề mặt, chẳng hạn như Tổng quan, Nghiên cứu sâu hoặc Agentics. Điều thực sự có khả năng thiết lập một trật tự mới trong hỗn loạn là tái cấu trúc kiến trúc trình duyệt từ dưới lên, nhúng sâu mô hình ngôn ngữ lớn (LLM) vào hạt nhân trình duyệt và đạt được sự thay đổi cơ bản trong cách tương tác.
Can đảm
Brave là trình duyệt sớm nhất và thành công nhất trong ngành công nghiệp tiền điện tử. Nó dựa trên kiến trúc Chromium và do đó tương thích với các plug-in trên Google Store. Nó dựa vào quyền riêng tư và mô hình kiếm token thông qua việc duyệt web để thu hút người dùng. Con đường phát triển của Brave đã chứng minh tiềm năng tăng trưởng của nó ở một mức độ nhất định. Tuy nhiên, xét về góc độ sản phẩm, quyền riêng tư rất quan trọng, nhưng nhu cầu của nó vẫn chủ yếu tập trung vào các nhóm người dùng cụ thể và nhận thức về quyền riêng tư vẫn chưa trở thành yếu tố ra quyết định chính thống đối với công chúng nói chung. Do đó, khả năng cố gắng lật đổ những gã khổng lồ hiện tại bằng cách dựa vào tính năng này là thấp.
Tính đến thời điểm hiện tại, Brave có 82,7 triệu người dùng hoạt động hàng tháng và 35,6 triệu người dùng hoạt động hàng ngày, với thị phần khoảng 1% - 1,5%. Quy mô người dùng tiếp tục tăng: từ 6 triệu vào tháng 7 năm 2019 lên 25 triệu vào tháng 1 năm 2021, 57 triệu vào tháng 1 năm 2023 và hơn 82 triệu vào tháng 2 năm 2025, với tốc độ tăng trưởng kép hàng năm trung bình là hai chữ số. Khối lượng truy vấn tìm kiếm trung bình hàng tháng của nó là khoảng 1,34 tỷ lần, chiếm khoảng 0,3% của Google.
Dưới đây là lộ trình lặp đi lặp lại của Brave.

Brave đang có kế hoạch nâng cấp lên trình duyệt AI ưu tiên quyền riêng tư. Tuy nhiên, do hạn chế về quyền truy cập vào dữ liệu người dùng nên mô hình lớn ít tùy chỉnh hơn, điều này không có lợi cho việc lặp lại sản phẩm nhanh chóng và chính xác. Trong kỷ nguyên Agentic Browser sắp tới, Brave có thể duy trì thị phần ổn định trong một số nhóm người dùng có ý thức về quyền riêng tư, nhưng khó có thể trở thành một đối thủ lớn. Trợ lý AI Leo của Brave giống như một plug-in hơn, chỉ nâng cao chức năng của các sản phẩm hiện có và có khả năng tóm tắt nội dung nhất định, nhưng không có chiến lược rõ ràng nào để chuyển hoàn toàn sang AI Agent và sự đổi mới ở cấp độ tương tác vẫn chưa đủ.
bánh rán
Gần đây, ngành công nghiệp tiền điện tử cũng đã có những tiến triển trong lĩnh vực Agentic Browser. Dự án khởi nghiệp Donut đã nhận được 7 triệu đô la tài trợ trong vòng Pre-seed, do Sequoia China (Hongshan), HackVC và Bitkraft Ventures dẫn đầu. Dự án vẫn đang trong giai đoạn khái niệm ban đầu và tầm nhìn là đạt được các khả năng tích hợp của "khám phá, ra quyết định và thực hiện tiền điện tử gốc".
Cốt lõi của hướng đi này là kết hợp đường dẫn thực thi tự động mã hóa gốc. Như a16z đã dự đoán, trong tương lai, Agent dự kiến sẽ thay thế các công cụ tìm kiếm làm lối vào lưu lượng truy cập chính. Các doanh nhân sẽ không còn cạnh tranh xung quanh thuật toán xếp hạng của Google nữa, mà cạnh tranh để giành được lưu lượng truy cập và chuyển đổi do thực thi Agent mang lại. Ngành công nghiệp này gọi xu hướng này là "AEO" (Answer/Agent Engine Optimization), hay còn gọi là "ATF" (Agentic Task Fulfillment), tức là không còn tối ưu hóa thứ hạng tìm kiếm nữa, mà trực tiếp phục vụ các mô hình thông minh có thể hoàn thành các tác vụ như đặt hàng, đặt vé và viết thư cho người dùng.
Dành cho doanh nhân
Trước hết, chúng ta phải thừa nhận rằng bản thân trình duyệt vẫn là "điểm vào" lớn nhất trong thế giới Internet chưa được tái thiết. Có khoảng 2,1 tỷ người dùng máy tính để bàn và hơn 4,3 tỷ người dùng thiết bị di động trên toàn thế giới. Đây là phương tiện truyền tải chung cho dữ liệu nhập, hành vi tương tác và lưu trữ dấu vân tay được cá nhân hóa. Lý do tại sao hình thức này vẫn tồn tại không phải vì quán tính, mà là vì trình duyệt tự nhiên có thuộc tính hai chiều: nó vừa là "mục nhập đọc" cho dữ liệu vừa là "lối ra viết" cho hành vi.
Do đó, đối với các doanh nhân, tiềm năng phá vỡ thực sự không phải là tối ưu hóa ở cấp độ "đầu ra trang". Ngay cả khi bạn có thể triển khai chức năng tổng quan AI tương tự như Google trong một tab mới, thì về cơ bản, đó là một lần lặp lại của lớp plug-in trình duyệt và vẫn chưa tạo thành một sự thay đổi mô hình cơ bản. Bước đột phá thực sự nằm ở "phía đầu vào" - tức là làm thế nào để AI Agent chủ động gọi sản phẩm của doanh nhân để hoàn thành các nhiệm vụ cụ thể. Điều này sẽ trở thành chìa khóa để các sản phẩm trong tương lai có thể được nhúng vào hệ sinh thái Agent và có được lưu lượng truy cập và phân phối giá trị hay không.
Trong thời đại tìm kiếm, nó được gọi là "nhấp chuột"; trong thời đại đại lý, nó được gọi là "gọi".
Nếu bạn là một doanh nhân, bạn cũng có thể tưởng tượng lại sản phẩm của mình như một thành phần API—để tác nhân thông minh không chỉ có thể "đọc" mà còn có thể "gọi" nó. Điều này đòi hỏi bạn phải xem xét ba chiều khi bắt đầu thiết kế sản phẩm:
1. Chuẩn hóa cấu trúc giao diện: Sản phẩm của bạn có thể “gọi được” không?
Việc một sản phẩm có khả năng được gọi bởi một tác nhân thông minh hay không phụ thuộc vào việc cấu trúc thông tin của nó có thể được chuẩn hóa và trừu tượng hóa thành một lược đồ rõ ràng hay không. Ví dụ, các hoạt động chính như đăng ký người dùng, nút đặt hàng và gửi bình luận có thể được mô tả thông qua các cấu trúc DOM ngữ nghĩa hoặc ánh xạ JSON không? Hệ thống có cung cấp máy trạng thái để tác nhân có thể tái tạo ổn định quy trình hành vi của người dùng không? Tương tác của người dùng trên trang có hỗ trợ khôi phục theo tập lệnh không? Có WebHook truy cập ổn định hoặc Điểm cuối API không?
Đây là lý do thiết yếu cho việc tài trợ thành công cho Browser Use - nó chuyển đổi trình duyệt từ HTML được kết xuất phẳng thành cây ngữ nghĩa có thể được gọi bằng LLM. Đối với các doanh nhân, việc giới thiệu các khái niệm thiết kế tương tự trong các sản phẩm web là để thực hiện các điều chỉnh về mặt cấu trúc cho kỷ nguyên AI Agent.
2. Danh tính và quyền truy cập: Bạn có thể giúp Đại lý “vượt qua rào cản tin cậy” không?
Để các tác nhân AI hoàn tất giao dịch, gọi thanh toán hoặc tài sản, chúng cần một số loại lớp trung gian đáng tin cậy - bạn có thể là lớp đó không? Trình duyệt có thể tự nhiên đọc bộ nhớ cục bộ, gọi ví, xác định mã xác minh và truy cập xác thực hai yếu tố, đó là lý do tại sao chúng phù hợp hơn để thực hiện so với các mô hình đám mây lớn. Điều này đặc biệt đúng trong các tình huống Web3: các tiêu chuẩn giao diện để gọi tài sản trên chuỗi không được thống nhất và các tác nhân sẽ không thể tiến lên nếu không có "khả năng nhận dạng" hoặc "chữ ký".
Do đó, đối với các doanh nhân tiền điện tử, có một vùng trống đầy trí tưởng tượng: "MCP (Nền tảng đa năng) trong thế giới blockchain". Đây có thể là một lớp hướng dẫn chung (cho phép Agent gọi Dapp), một bộ giao diện hợp đồng chuẩn hóa hoặc thậm chí là một ví nhẹ + nền tảng trung gian danh tính chạy cục bộ.
3. Hiểu lại cơ chế lưu lượng truy cập: Tương lai không phải là SEO mà là AEO/ATF
Trước đây, bạn phải giành được sự ưu ái của thuật toán Google; giờ đây bạn phải được nhúng vào chuỗi tác vụ của AI Agent. Điều này có nghĩa là sản phẩm phải có mức độ chi tiết tác vụ rõ ràng: không phải là một "trang", mà là một chuỗi "đơn vị khả năng có thể gọi"; điều này có nghĩa là bạn phải bắt đầu thực hiện Tối ưu hóa tác nhân (AEO) hoặc Thích ứng lập lịch tác vụ (ATF): ví dụ, liệu quy trình đăng ký có thể được đơn giản hóa thành các bước có cấu trúc hay không, liệu giá có thể được kéo qua giao diện hay không và liệu hàng tồn kho có thể được kiểm tra theo thời gian thực hay không;
Bạn thậm chí cần phải bắt đầu điều chỉnh cú pháp gọi theo các khuôn khổ LLM khác nhau - OpenAI và Claude có sở thích khác nhau về các lệnh gọi hàm và cách sử dụng công cụ. Chrome là thiết bị đầu cuối của thế giới cũ, không phải là lối vào thế giới mới. Dự án kinh doanh thực sự có tương lai không phải là tạo ra một trình duyệt mới, mà là làm cho trình duyệt hiện tại phục vụ cho Agent và xây dựng một cây cầu cho thế hệ "luồng hướng dẫn" mới.
Những gì bạn cần xây dựng là "cú pháp giao diện" để Agent gọi đến thế giới của bạn;
Điều bạn đang phấn đấu là trở thành một mắt xích trong chuỗi tin cậy của thực thể thông minh;
Những gì bạn cần xây dựng là "Lâu đài API" ở chế độ tìm kiếm tiếp theo.
Nếu Web2 dựa vào UI để thu hút sự chú ý của người dùng thì trong kỷ nguyên Web3 + AI Agent, nó dựa vào chuỗi cuộc gọi để nắm bắt ý định thực hiện của tác nhân.
Tuyên bố miễn trừ trách nhiệm:
Nội dung này không cấu thành bất kỳ lời đề nghị, chào mời hoặc khuyến nghị nào. Bạn nên luôn tìm kiếm lời khuyên chuyên nghiệp độc lập trước khi đưa ra bất kỳ quyết định đầu tư nào. Xin lưu ý rằng Gate và/hoặc Gate Ventures có thể hạn chế hoặc cấm toàn bộ hoặc một phần Dịch vụ khỏi các khu vực bị hạn chế. Vui lòng đọc Thỏa thuận người dùng hiện hành của họ để biết thêm thông tin.
Giới thiệu về Gate Ventures
Gate Ventures là nhánh đầu tư mạo hiểm của Gate, tập trung vào các khoản đầu tư vào cơ sở hạ tầng phi tập trung, hệ sinh thái và ứng dụng sẽ định hình lại thế giới trong kỷ nguyên Web 3.0. Gate Ventures hợp tác với các nhà lãnh đạo ngành toàn cầu để trao quyền cho các nhóm và công ty khởi nghiệp với tư duy và khả năng sáng tạo để xác định lại các mô hình tương tác xã hội và tài chính.
Trang web chính thức: https://ventures.gate.io/
Twitter: https://x.com/gate_ventures
Phương tiện: https://medium.com/gate_ventures


