
Cơ chế chứng minh cấp độ hạt nhân cho các mô hình học máy
Tác giả gốc: Zhiyong Fang
"Làm sao để ăn một con voi? Mỗi lần chỉ ăn một miếng."
Trong những năm gần đây, các mô hình học máy đã đạt được những bước tiến vượt bậc với tốc độ đáng kinh ngạc. Khi khả năng của các mô hình tăng lên, độ phức tạp của chúng cũng tăng theo - các mô hình tiên tiến ngày nay thường chứa hàng triệu hoặc thậm chí hàng tỷ tham số. Để đối phó với thách thức về quy mô này, nhiều hệ thống chứng minh không kiến thức đã xuất hiện, luôn cố gắng đạt được sự cân bằng động giữa thời gian chứng minh, thời gian xác minh và quy mô chứng minh.
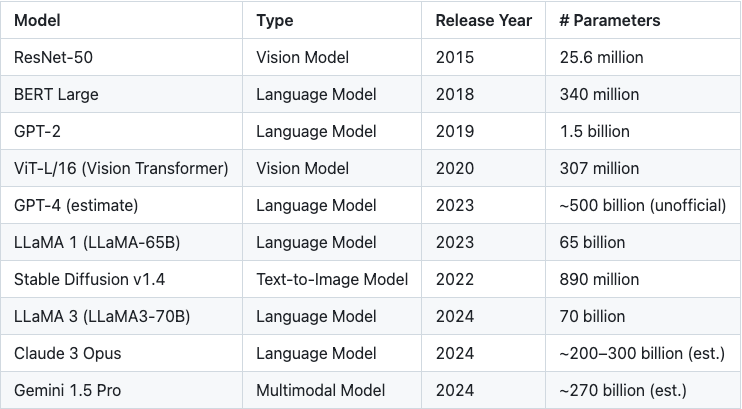
Bảng 1: Tăng trưởng theo cấp số nhân trong kích thước tham số mô hình
Mặc dù hầu hết các công trình hiện tại trong lĩnh vực bằng chứng không kiến thức tập trung vào việc tối ưu hóa hệ thống bằng chứng, một khía cạnh quan trọng thường bị bỏ qua: cách phân chia đúng các mô hình quy mô lớn thành các mô-đun con nhỏ hơn, dễ quản lý hơn để chứng minh. Bạn có thể hỏi, tại sao điều này lại quan trọng như vậy?
Chúng ta hãy giải thích chi tiết:
Số lượng tham số trong các mô hình học máy hiện đại thường lên tới hàng tỷ, vốn đã chiếm một lượng tài nguyên bộ nhớ rất lớn ngay cả khi không có bất kỳ quá trình xử lý mật mã nào. Trong bối cảnh bằng chứng không kiến thức (ZKP), thách thức này còn lớn hơn nữa.
Mỗi tham số dấu phẩy động phải được chuyển đổi thành một phần tử trong trường đại số và quá trình chuyển đổi này tự nó sẽ làm tăng mức sử dụng bộ nhớ lên khoảng 5 đến 10 lần. Ngoài ra, để mô phỏng chính xác các phép toán dấu phẩy động trong trường đại số, phải đưa thêm chi phí hoạt động, thường là khoảng 5 lần.
Nhìn chung, yêu cầu bộ nhớ chung của mô hình có thể tăng lên gấp 25 đến 50 lần so với kích thước ban đầu. Ví dụ, một mô hình có 1 tỷ tham số dấu phẩy động 32 bit có thể cần 100 đến 200 GB bộ nhớ chỉ để lưu trữ các tham số đã chuyển đổi. Xem xét chi phí chung của các giá trị tính toán trung gian và bản thân hệ thống chứng minh, mức sử dụng bộ nhớ chung dễ dàng vượt quá mức TB.
Các hệ thống chứng minh chính thống hiện tại, chẳng hạn như Groth 16 và Plonk, thường cho rằng tất cả dữ liệu có liên quan có thể được tải vào bộ nhớ cùng lúc trong các triển khai chưa được tối ưu hóa. Mặc dù giả định này khả thi về mặt kỹ thuật, nhưng nó cực kỳ khó khăn trong điều kiện phần cứng thực tế và hạn chế rất nhiều tài nguyên tính toán chứng minh có sẵn.
Giải pháp của khối đa diện: zkCuda
ZkCuda là gì?
Như chúng tôi đã mô tả trong Tài liệu kỹ thuật zkCUDA :
ZkCUDA của Polyhedra là môi trường điện toán không kiến thức để phát triển mạch hiệu suất cao, được thiết kế để cải thiện hiệu quả tạo bằng chứng. Không làm mất đi tính biểu cảm của mạch, zkCUDA có thể tận dụng đầy đủ khả năng song song của phần cứng và trình chứng minh cơ bản để đạt được khả năng tạo bằng chứng ZK nhanh chóng.
Ngôn ngữ zkCUDA rất giống với CUDA về cú pháp và ngữ nghĩa, và rất thân thiện với các nhà phát triển đã có kinh nghiệm về CUDA. Việc triển khai cơ bản của nó là trong Rust, đảm bảo cả tính bảo mật và hiệu suất.
Với zkCUDA, các nhà phát triển có thể:
Nhanh chóng xây dựng mạch ZK hiệu suất cao;
Lên lịch và sử dụng hiệu quả các tài nguyên phần cứng phân tán, chẳng hạn như GPU hoặc môi trường cụm hỗ trợ MPI, để đạt được khả năng tính toán song song quy mô lớn.
Tại sao lại là zkCUDA?
zkCuda là một khuôn khổ điện toán không kiến thức hiệu suất cao lấy cảm hứng từ điện toán GPU. Nó có thể chia các mô hình học máy quy mô lớn thành các đơn vị điện toán nhỏ hơn và dễ quản lý hơn (kernel) và đạt được khả năng kiểm soát hiệu quả thông qua ngôn ngữ front-end tương tự như CUDA. Thiết kế này mang lại những lợi thế chính sau:
1. Lựa chọn hệ thống chứng minh để khớp chính xác
zkCUDA hỗ trợ phân tích chi tiết từng hạt nhân máy tính và kết hợp nó với hệ thống chứng minh không kiến thức phù hợp nhất. Ví dụ:
Đối với các tác vụ tính toán song song cao, có thể sử dụng các giao thức như GKR có khả năng xử lý song song có cấu trúc tốt;
Đối với các tác vụ nhỏ hơn hoặc có cấu trúc không đều, việc sử dụng hệ thống chứng minh như Groth 16 có chi phí thấp trong các tình huống tính toán nhỏ gọn sẽ phù hợp hơn.
Bằng cách tùy chỉnh lựa chọn phần phụ trợ, zkCUDA có thể tối đa hóa lợi thế về hiệu suất của nhiều giao thức ZK khác nhau.
2. Lập lịch tài nguyên thông minh hơn và tối ưu hóa song song
Các hạt nhân chứng minh khác nhau có yêu cầu tài nguyên khác nhau đáng kể đối với CPU, bộ nhớ và I/O. zkCUDA có thể đánh giá chính xác mức tiêu thụ tài nguyên của từng tác vụ và lên lịch thông minh để tối đa hóa thông lượng tổng thể.
Quan trọng hơn, zkCUDA hỗ trợ phân bổ tác vụ giữa các nền tảng điện toán không đồng nhất—bao gồm CPU, GPU và FPGA—để đạt được mục đích sử dụng tối ưu tài nguyên phần cứng và cải thiện đáng kể hiệu suất cấp hệ thống.
zkCuda là sự phù hợp tự nhiên cho giao thức GKR
Mặc dù zkCuda được thiết kế như một khuôn khổ điện toán chung tương thích với nhiều hệ thống chứng minh không kiến thức, nhưng nó có mức độ tương thích kiến trúc cao tự nhiên với giao thức GKR (Goldwasser-Kalai-Rothblum).
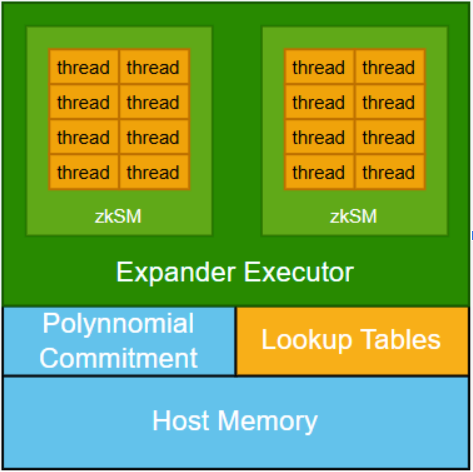
Về mặt thiết kế kiến trúc, zkCUDA giới thiệu một cơ chế cam kết đa thức để kết nối các hạt nhân tính toán phụ khác nhau để đảm bảo rằng tất cả các tính toán phụ đều chạy dựa trên dữ liệu được chia sẻ nhất quán. Cơ chế này rất quan trọng để duy trì tính toàn vẹn của hệ thống, nhưng nó cũng mang lại chi phí tính toán đáng kể.
Ngược lại, giao thức GKR cung cấp một đường dẫn thay thế hiệu quả hơn. Không giống như các hệ thống không kiến thức truyền thống yêu cầu mỗi hạt nhân phải chứng minh đầy đủ các ràng buộc nội bộ của nó, GKR cho phép xác minh tính chính xác tính toán được truy ngược lại một cách đệ quy từ đầu ra của hạt nhân đến đầu vào. Cơ chế này cho phép tính chính xác được chuyển qua các hạt nhân thay vì mở rộng hoàn toàn xác minh trong mỗi mô-đun. Ý tưởng cốt lõi của nó tương tự như truyền ngược gradient trong học máy, theo dõi và truyền các yêu cầu về tính chính xác thông qua đồ thị tính toán.
Mặc dù việc hợp nhất các "gradient bằng chứng" như vậy theo nhiều đường dẫn mang lại một số phức tạp, nhưng chính cơ chế này tạo thành cơ sở cho sự hợp tác sâu sắc giữa zkCUDA và GKR. Bằng cách sắp xếp các đặc điểm cấu trúc của quy trình đào tạo máy học, zkCUDA dự kiến sẽ đạt được sự tích hợp hệ thống chặt chẽ hơn và tạo ra bằng chứng không kiến thức hiệu quả hơn trong các kịch bản mô hình lớn.
Kết quả sơ bộ và hướng đi trong tương lai
Chúng tôi đã hoàn tất quá trình phát triển ban đầu của nền tảng zkCuda và đã thử nghiệm thành công trong nhiều tình huống, bao gồm các hàm băm mật mã như Keccak và SHA-256, cũng như các mô hình học máy quy mô nhỏ.
Nhìn về phía trước, chúng tôi hy vọng sẽ tiếp tục giới thiệu một loạt các công nghệ kỹ thuật trưởng thành trong đào tạo máy học hiện đại, chẳng hạn như lập lịch hiệu quả về bộ nhớ và tối ưu hóa cấp độ đồ thị. Chúng tôi tin rằng việc tích hợp các chiến lược này vào quy trình tạo bằng chứng không kiến thức sẽ cải thiện đáng kể ranh giới hiệu suất và tính linh hoạt thích ứng của hệ thống.
Đây chỉ là điểm khởi đầu. zkCuda sẽ tiếp tục hướng tới một khuôn khổ chứng minh phổ quát có hiệu quả, khả năng mở rộng cao và khả năng thích ứng cao.


