
深度解析$VVV:被低估的隐私AI基础设施与增长曲线
- 核心观点:Venice作为隐私优先的AI推理平台,通过独特的匿名代理、TEE和E2EE多层隐私架构及无审查模型访问,正在经历高速增长。市场严重低估了其隐私AI推理赛道的规模,当前代币VVV的市值仅为未来12个月预期收入的2.5倍,存在显著的价值重估空间。
- 关键要素:
- 技术独特性:Venice是唯一将Anonymous、Private、TEE和E2EE四种隐私模式整合于单一消费者产品中的平台,用户可按需选择,竞争对手无法提供完整组合。
- 用户驱动力:核心用户群体并非主动搜索隐私工具,而是被主流AI平台的内容政策、合规要求或隐私威胁“推”向Venice,包括受监管行业从业者、开发者及高风险个人。
- 增长加速度:最新三周数据(4月26日至5月16日)显示新增订阅ARR增速高达34%,周化新增速度从约200万美元跃升至260万美元。API收入增长同步,预计未来12个月总收入增量约2亿美元。
- 市场规模:2027年全球推理市场预计达1400-1600亿美元,其中隐私细分市场占比5-15%(约70-230亿美元)。Venice当前市占率不足0.3%,增长空间巨大。
- 估值对比:当前市值约6.6亿美元,对应11倍当前ARR(6000万美元)。按未来12个月2.6亿美元预期ARR计算,市销率压缩至2.5倍,远低于同行OpenRouter的26倍。
- 代币设计优势:双代币模型(VVV与DIEM)通过质押、回购销毁及永久性API额度捕获平台增长。通胀率正快速下降,净供给即将转负,增强代币价值捕获能力。
Original Author: Yan Liberman
Original Translation: Deep Tide TechFlow
Deep Tide Commentary: Venice's subscription data over the last three weeks shows new ARR growth accelerating at 34%, with the current market capitalization trading at just 2.5 times expected revenue over the next 12 months. This former crypto investor deconstructs the full chain of Venice, from its privacy architecture to its business model, arguing that the market significantly underestimates the true scale of the "private AI inference" track, as well as Venice's irreplaceable combined advantage on this track, and is bullish on $VVV.

Venice is a privacy-first AI inference platform that allows users to use frontier and open-source models without exposing their identity to the underlying model providers. I believe it is the most complete privacy solution on the AI market today: anonymous proxy, open-source model routing, hardware-attested TEE inference, and end-to-end encrypted inference—all four functions integrated into a single consumer product where privacy mode can be selected on a per-request basis. No other player offers all four simultaneously.
This business is growing significantly. Discussions about Venice on Crypto Twitter generally underestimate current revenue, near-term growth, and future trajectory. Venice recently began publishing daily subscription data, and three weeks of granular data show a clear acceleration in new subscription ARR:
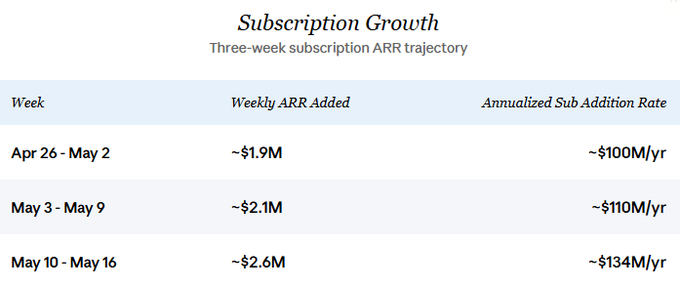
Sustained growth rate is the core assumption of this analysis. I also assume API revenue has recently been growing in tandem with subscriptions, an assumption detailed in the "Current State and Growth" section below. Anchoring conservatively to $100 million in annual new subscription additions (in line with late April's pace) and assuming an equal amount for API additions, total revenue increments over the next 12 months would be approximately $200 million.
The recent acceleration trend suggests that if this pace holds, actual numbers will have significant upside.
This article will break down Venice's uniqueness point by point:
- Privacy Tiers: A set of privacy architectures far deeper than the standard "private AI chat" narrative.
- User Categories: Venice's user base is driven out of mainstream paths (content policies, compliance, threat models, principles) rather than attracted by marketing.
- Market Size: A growing private inference market segment typically underestimated by consumer chat frameworks.
- Competitive Landscape: Venice bundles privacy depth, uncensored model access, and crypto-native distribution—a combination currently unique among competitors.
- Token Design & VVV Valuation: How the mechanisms of VVV and DIEM translate platform growth into token value, and how VVV's valuation multiples compare to privacy inference peers like OpenRouter, Fireworks, and Together AI.
After the recent rally and pullback to $14, VVV's market cap is approximately $660 million, with a fully diluted valuation (FDV) of about $1.12 billion. Current ARR is roughly $60 million (estimated in the "Current State and Growth" section below), increasing at a rate of about $200 million per year and accelerating. At the current ARR, VVV's price-to-sales ratio is about 11x (19x on FDV), lower than privacy inference peer OpenRouter's 26x. Based on the next 12 months' ARR of approximately $260 million ($60 million current base plus $200 million annualized additions), VVV's price-to-sales ratio is about 2.5x (4.3x on FDV).
Current State and Growth
Venice recently began publishing daily new subscription data. Combined with periodic public milestones for total registered users, these two data streams allow me to construct current ARR estimates and future trajectories.
To estimate current ARR, I start with total registrations. Based on the cadence of public announcements over time, total registrations have been growing at roughly 300,000 per month. The most recently confirmed milestone was approximately 3 million registered users as of May 16, 2026, up from ~2 million on February 1st, consistent with the 300k/month pace. Assuming a ~5% lifetime paid conversion rate (likely conservative given daily data shows faster conversion for new registrations), this implies roughly 150,000 active paid subscribers by mid-May. Until mid-to-late April, only the basic $18/month Pro plan existed; the introduction of Pro+ ($68/month) and Max ($200/month) plans has started to change the mix, but the vast majority of paid users remain on the $18 plan. The weighted ARPPU is roughly $18-19 per month, implying a current subscription MRR of about $2.8 million, or roughly $33 million subscription ARR. This is just the subscription portion; API revenue is layered on in this section below to arrive at the complete current ARR estimate.
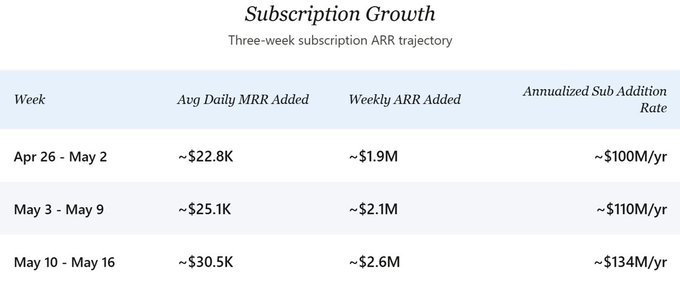
Looking at the future trajectory, the growth rate of new subscription ARR has been accelerating. At late April's pace, the company was adding roughly $2 million in subscription ARR per week. By the most recent week (May 10-16), this pace has jumped to approximately $2.6 million per week, annualized to $134 million in new subscription additions. In the central scenario of this analysis, I anchor conservatively to a $100 million annualized figure to avoid overstating the recent acceleration. Net growth after churn would be slightly lower, but at the current scale, this difference is directionally insignificant; gross growth velocity is the core of this article's forward-looking analysis.
Three weeks of granular data (April 26 - May 16) show a clear ramp-up:
From Week 1 to Week 3, daily MRR additions increased by approximately 34%. Assuming API revenue tracks new subscription MRR 1:1 (explained below), the implied total annualized new additions pace has jumped from roughly $200 million to approximately $268 million. Two factors seem to be driving this inflection: the launch of Pro+ and Max plans gave high-WTP users options they didn't have before, boosting weighted ARPPU; and paid conversion appears to have accelerated after the plan expansion.
API revenue is harder to measure due to lack of direct disclosure. My base case is that the ratio of recent incremental API operating revenue to new subscription MRR is approximately 1:1, with historical incremental ratios being lower. The result is a current API ARR base that is substantial but slightly lower than subscription ARR, trending towards parity over time.
The rationale for roughly a 50/50 split starts with peer benchmarks. Among large closed-source model platforms, ChatGPT's API accounts for ~25% and subscriptions ~75%, due to its massive consumer subscription base making API share smaller. Anthropic's API accounts for ~80% and subscriptions ~20%, as its user base leans heavily toward developers and enterprises. Venice falls structurally in between: its privacy positioning doesn't attract average consumers like ChatGPT, but its paid user base is broader than Anthropic's enterprise-heavy mix. The 50/50 split falls in the middle of this range.
This range is reinforced by two pieces of Venice-specific evidence.
First, Venice's API has already established significant developer distribution channels. OpenRouter routes Venice models, Fleek defaults all hosted agents to Venice inference, and Cursor, Brave Leo (via BYOM), and VSCode community extensions all support Venice. These integrations have accumulated over the past year, supporting the thesis that API is a real and significant business with production-scale traffic.
Second, the recent token throughput ramp far exceeds what subscription growth alone can explain. Daily token throughput grew from 20 billion in early February to over 60 billion by early May, roughly 3x in three months. Over the same window, the paid subscriber base grew by about 50% (from ~100k paid subs to ~150k). The mid-April Pro+/Max expansion only shifted a small fraction of new registrations to higher ARPPU plans, and even generous assumptions about token consumption per user for these plans cannot fill the gap. The bulk of the token ramp appears to come from usage-based API workloads: agent deployments, integrated partners scaling production traffic, and similar high-volume use cases.
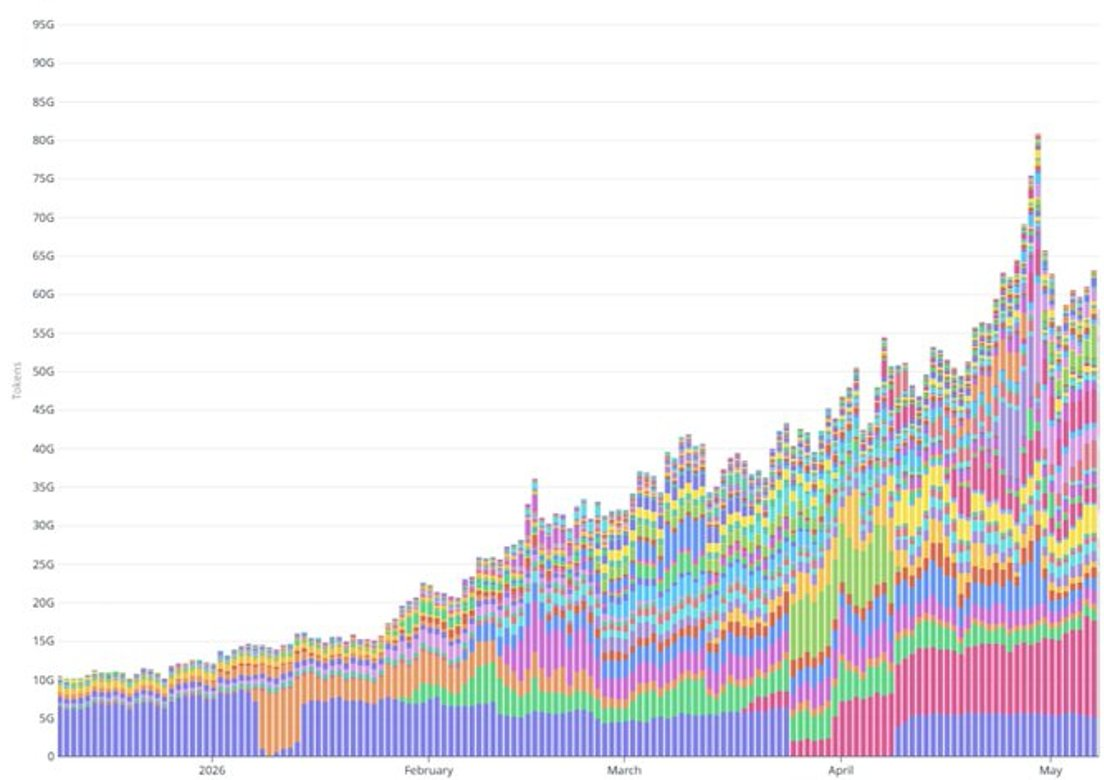
Estimating current API ARR is harder than subscription ARR, as the 1:1 ratio appears to be a recent phenomenon; before mid-April, the API share was likely smaller. Using a midpoint assumption that API revenue historically averaged ~70-80% of subscription revenue and only recently reached parity, current API ARR is approximately $25-30 million. Total current ARR estimate: ~$55-65 million, with a midpoint of ~$60 million.
The API portion warrants a brief caveat: it's based on annualizing current usage-based operating revenue, not recurring subscription commitments, and therefore carries higher inherent volatility than the subscription portion. A heavy API client reducing usage could lead to a significant drop in API operating revenue without a similar churn in the subscription base.
Cross-validation with YTD revenue: Based on token throughput ramping from 20B/day in early February to over 60B/day in early May, Venice has generated at least $30 million in cumulative revenue in 2026. This figure is consistent with current ARR landing in the $55-65 million range, a base rapidly growing towards a $200 million annualized addition pace.
Importantly, the annualized addition pace is not the same as revenue earned over the next 12 months. New ARR adds linearly over the year, so a $200 million annualized addition pace, if sustained through 2026, translates to approximately $100 million in new revenue earned over the year, plus another ~$60 million contributed by the current ARR base. Total revenue earned over the next 12 months should fall in the $150-200 million range, with ARR at the end of that 12-month window being approximately $260 million (before churn) ($60 million current + $200 million new ARR added).
Looking back is mainly a footnote. Venice's current annualized ARR addition pace is about $200 million; the real question is whether today's pace is a floor or a starting point. Key variables: whether subscription growth holds, whether API usage continues to expand faster than subscriptions, how much churn materializes as cohorts mature, and whether the addressable market can support sustained growth at this pace.
The market size question becomes easier to answer once you understand what Venice actually does. The clearest framing is a privacy ladder for LLM interactions, with each rung representing a different set of privacy assumptions, and Venice's model embedding specific rungs.
Privacy Tiers
The ladder below ranks cloud-based AI usage along a narrow but important axis: who can associate plaintext prompts with user identity. It doesn't solve all privacy problems. Device compromise, payment trails, account metadata, subpoena risk, and endpoint security remain separate issues. But it clarifies what actually changes when a user moves from a default chatbot to Venice's higher privacy modes. The level numbers (0-7) are mine, used to position Venice within the broader landscape. Venice's own taxonomy only uses four named modes: Anonymous, Private, TEE, and E2EE, mapping to Levels 3, 4, 6, and 7 below.
The strongest privacy option isn't on the ladder at all. Running open-source models on hardware you own, with no cloud involvement, beats everything downstream. Running GLM 5.1 or Qwen 3.6 on a beefy Mac or workstation, with no network calls, no third parties involved. Nothing beats "prompts never leave my machine," provided the machine itself is reasonably hardened. But this isn't the path most people will take. Hardware is expensive. Open-source models that can run locally still lag behind the frontier levels of closed-source labs on the hardest tasks. You lose integrations and 24/7 cloud uptime, and you take on the responsibility of maintaining the entire stack. Setting local deployment aside, the ladder below covers the realistic options for cloud-based inference.
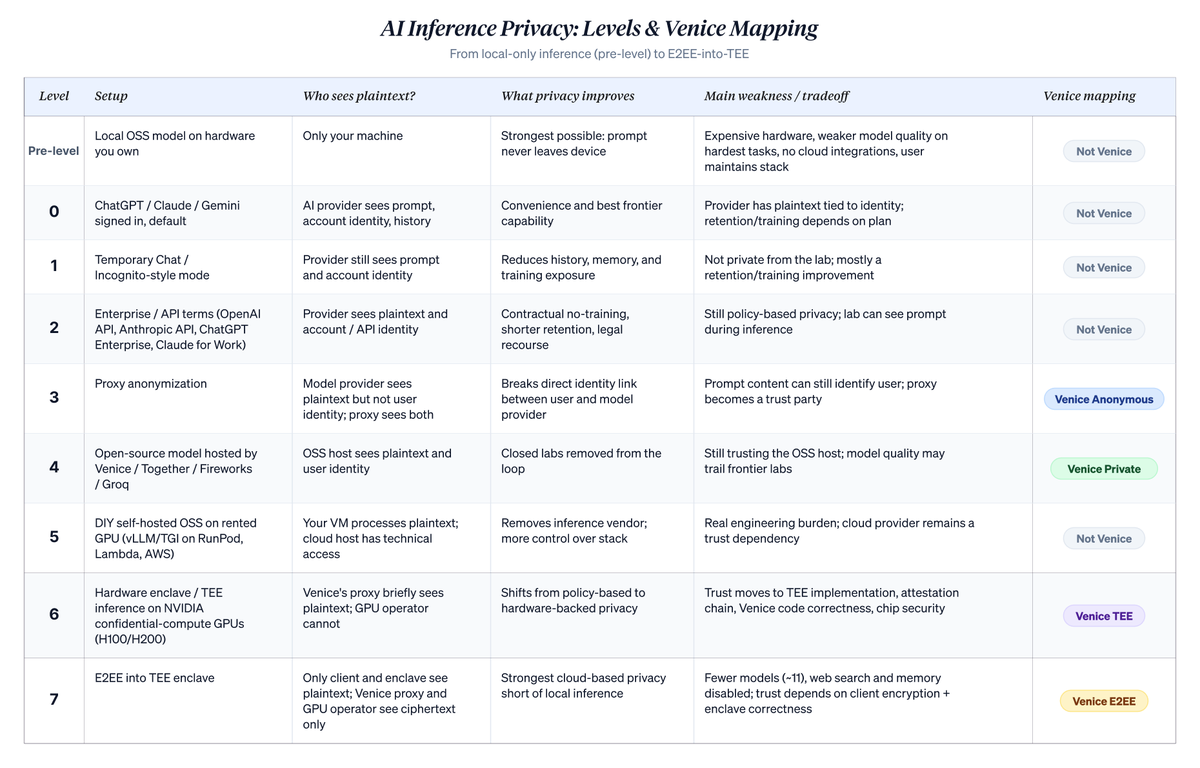
A detailed breakdown of each level follows, including the analogy underpinning each:
Level 0: "ChatGPT, Claude, or Gemini, logged in, default state." Your prompts are sent to the lab associated with your account. They know who you are and what you asked. On consumer plans, unless you opt out, conversations may be used to improve future models and are stored in your server-side chat history. There are real commitments here (no data selling, retention periods, deletion controls), but you are identified, retained, and potentially in the training pipeline on consumer plans. Most people are on this level. Architecturally, any hosted API consumer service applies the same posture regardless of provider location. Hosted plans from Chinese providers (DeepSeek hosted edition, GLM/Zhipu, MiniMax, Qwen direct) operate at the same architectural level: the provider sees plaintext, identity is linked to account, retention and training policies vary. Users often choose these services for price, as they tend to be significantly cheaper than Anthropic or OpenAI. Your data's ultimate jurisdiction depends on the specific provider, the endpoint you access, your region, and the contract. Don't assume you get US or EU-style data handling just because the model is cheap.
Analogy: You go directly to a large firm (AI provider) to see a consultant (model). They read your memo, answer your question, and file a copy under your name. They might use anonymized versions of past memos to train other consultants or improve service.
Level 1: "ChatGPT Temporary Chat / Claude Incognito Chat." Same provider, same identity, same plaintext on their servers. The conversation doesn't appear in your history, the model doesn't persist it, and by policy it's excluded from training. Useful for sensitive one-off conversations you don't want tied to your account. The provider still knows it's you and sees the full prompt; they just can't retain it long-term or use it for training. Hidden from your own history, but not from the lab.
Analogy: Same direct interaction with the consultant (model), but you ask them to keep this specific memo out of your main file. They read it, answer, and put it in a temporary drawer (incognito chat) that gets cleared after a while. They still know it's you and saw what you sent.
Level 2: "Anthropic API, Claude for Work, ChatGPT Enterprise, OpenAI API." Moving from consumer chat to commercial terms. Contractually, your data is excluded from training. Retention is short, typically ~30 days for security review, sometimes zero at the enterprise level. You have legal recourse if policies are violated. The lab still sees plaintext during inference and ties traffic to your API key, but protections are stronger and contractually enforceable. This is the privacy posture most companies actually use and a real upgrade over consumer chat. But it's still policy-based, not architecture-based. The reasons to climb higher are real: future policy changes, compelled disclosure, data breaches, or the lab itself turning bad.
Analogy: You sign a contract with a consulting firm (enterprise/API terms) that stipulates no copying, no cross-client mixing, short retention, and legal recourse if breached. Same direct interaction with the consultant (model) who reads your memo and knows it's from you, just stricter rules about what happens to the memo afterward.
Level 3: "Venice Anonymous Mode." A proxy sits between you and the lab, stripping your identity before forwarding. The lab sees the prompt content in plaintext but doesn't know it's you. They see "a request from Venice." For prompts that don't identify you within the content, this breaks the link between your queries and your name, making long-term profiling by the lab much harder. For prompts that do identify you within the content (your company, your trades, your name), this is largely cosmetic. The content reveals you anyway. You also add Venice as a trusted party. DIYing this is unrealistic. You would be the only user of your own proxy, and single-user anonymity isn't anonymity.
Analogy: A courier service (Venice) handles delivery. The courier strips your name from the memo before handing it to the consultant (model). The consultant reads the content but doesn't know who sent it; the courier service knows both parties.
<

