
หลังจากการเปิดตัว DeepSeek V4: Zhipu และ MiniMax ร่วงลง Nvidia เริ่มหวั่น
- มุมมองหลัก: การเปิดตัวโมเดล DeepSeek V4 ได้พลิกโฉมตรรกะการประเมินมูลค่าในตลาดทุน AI ผลักดันเงินทุนจากบริษัทโมเดลปิดสู่โครงสร้างพื้นฐานด้านคอมพิวเตอร์ในประเทศจีน ส่งสัญญาณถึงจุดเปลี่ยนครั้งสำคัญทั้งในระบบเปิดและระบบนิเวศชิปในประเทศ
- ปัจจัยสำคัญ:
- พารามิเตอร์โมเดล: โมเดล MoE พื้นฐาน 1T พารามิเตอร์, เวอร์ชัน Flash 285B, เวอร์ชัน Pro 1.6T, ใช้สัญญาอนุญาตเปิด Apache 2.0
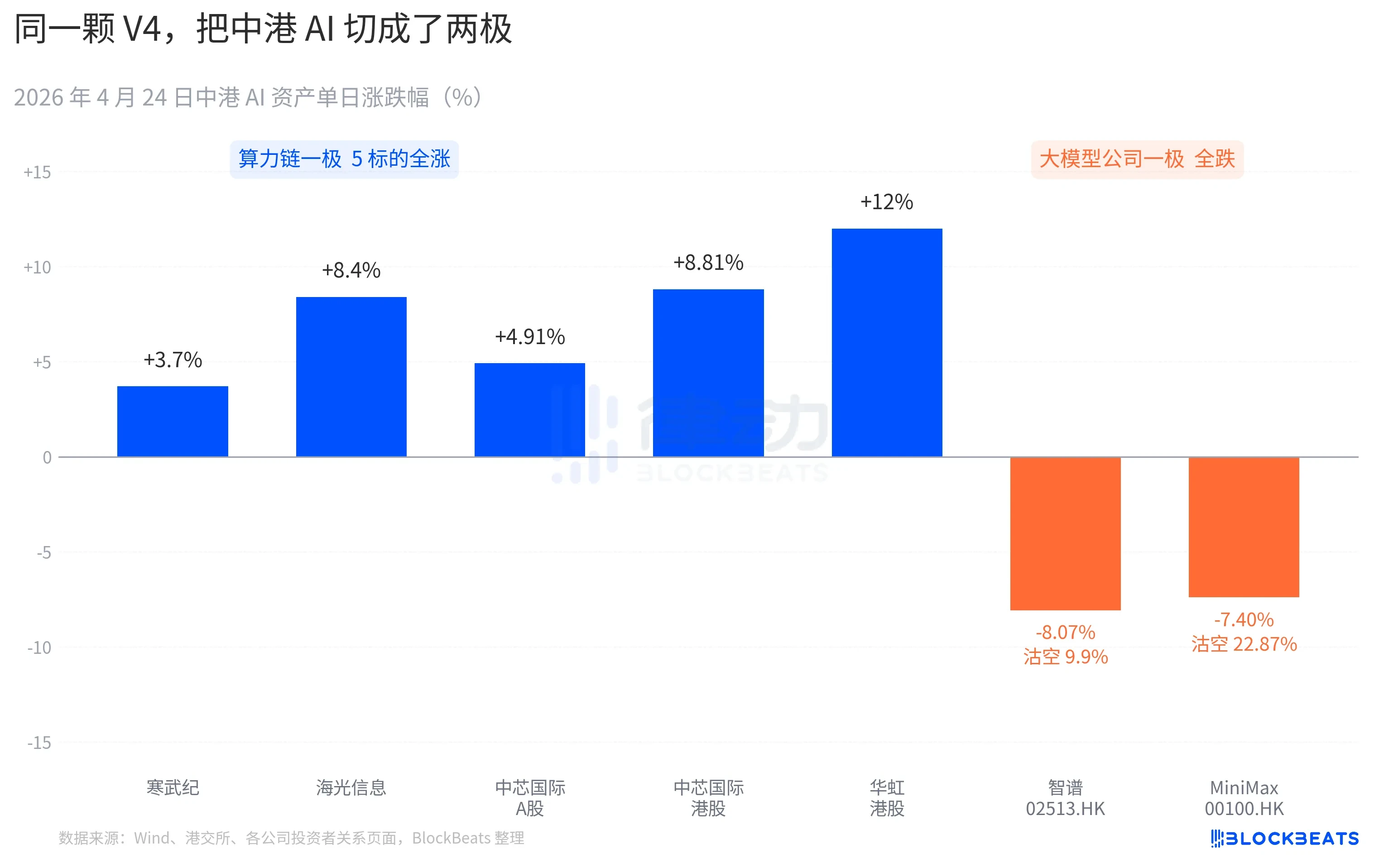
- ความแตกต่างของตลาด: หุ้นในตลาด A ที่เกี่ยวข้องกับห่วงโซ่การประมวลผล (เช่น Cambricon, Haiguang) พุ่งสูงขึ้น ขณะที่บริษัทโมเดลปิดในตลาดฮ่องกง (Zhipu, MiniMax) ถูกชอร์ต Nvidia ปรับตัวในกรอบแคบ
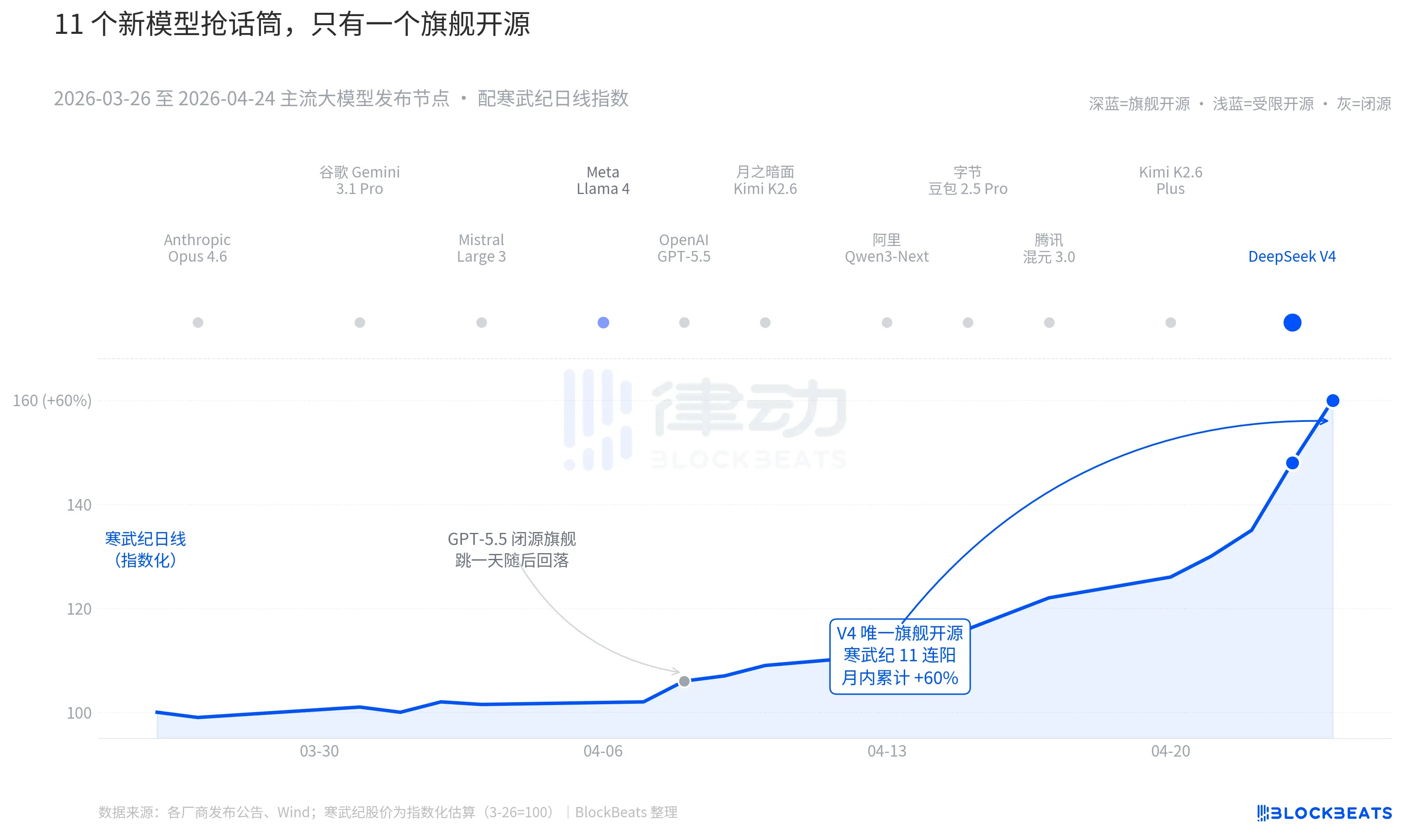
- ข้อได้เปรียบของโอเพนซอร์ส: จากโมเดลใหม่ 11 รายการใน 30 วันที่ผ่านมา V4 เป็นโมเดลโอเพนซอร์สเรือธงรุ่นแรกที่กดดันโมเดลปิดอย่างเต็มรูปแบบในด้านประสิทธิภาพ ราคา และความเปิดกว้าง
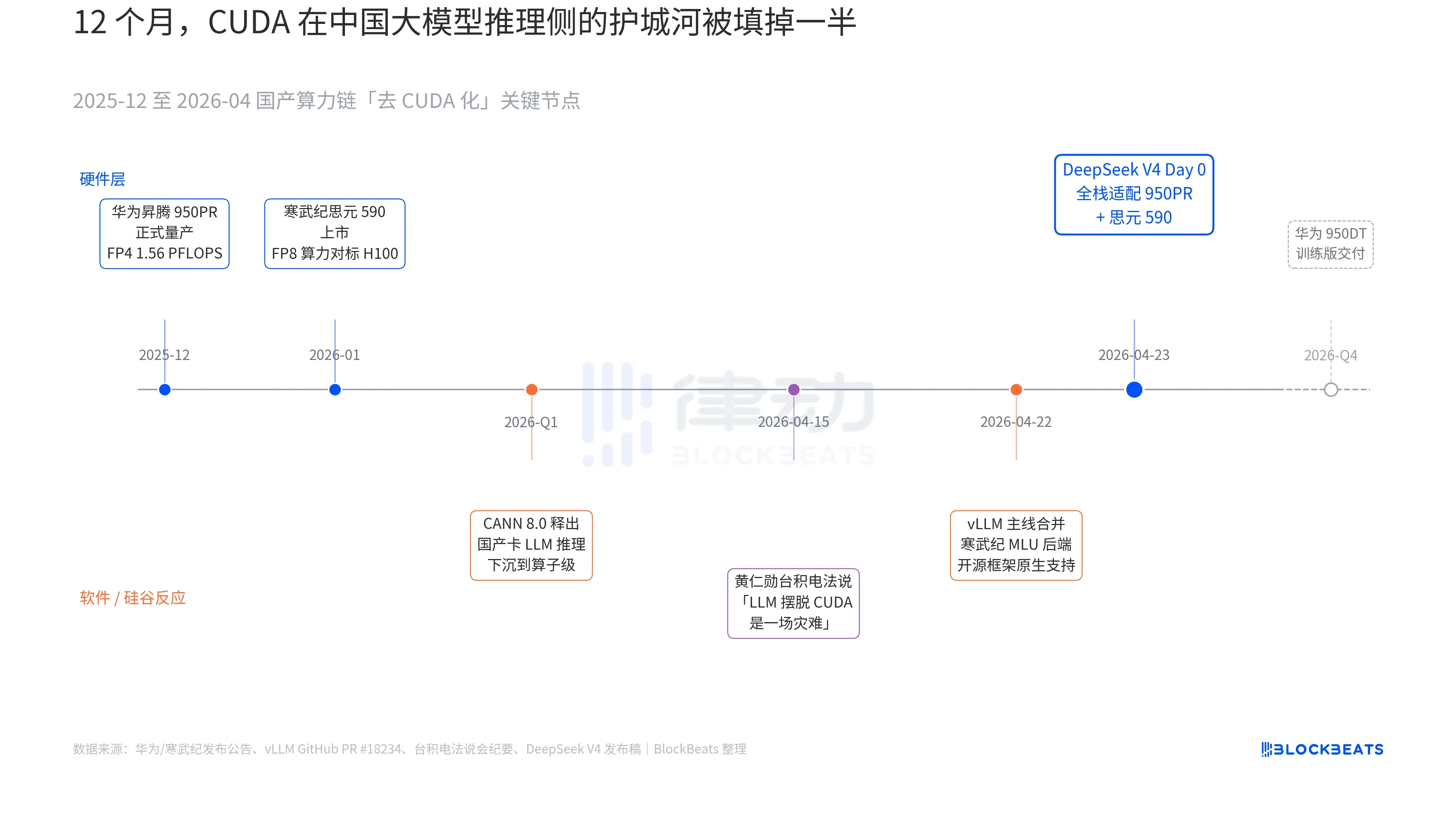
- ระบบนิเวศชิปในประเทศ: V4 รองรับการปรับแต่งทั้งระบบ (Day 0) สำหรับชิป思元590 ของ Cambricon และ 昇腾950PR ของ Huawei โค้ดการปรับใช้เป็นโอเพนซอร์ส ทำลายการพึ่งพา CUDA
- ข้อมูลประสิทธิภาพ: เวลาแฝงในการอนุมานของ V4 บนโหนดซูเปอร์ของ昇腾 ต่ำกว่าคลัสเตอร์ H100 ถึง 35% ความสามารถในการคำนวณ FP8 ของชิป Cambricon เทียบเท่ากับ H100 แต่มีราคาถูกกว่า
- จุดเปลี่ยนระบบนิเวศ: vLLM รวมแบ็กเอนด์ GPU ที่ไม่ใช่ของ Nvidia จากจีน ความต้องการการอนุมาน AI ของจีนเริ่มแยกตัวจากอเมริกาเหนือ การทดแทนด้วยชิปในประเทศเข้าสู่ขั้นตอนการผลิตที่สามารถกำหนดราคาได้
DeepSeek V4 has finally launched. This is a moment that has been awaited for nearly five months. The main MoE model with 1T parameters, plus a Flash version with 285B parameters, and a full Pro version with 1.6T parameters closely follow. It is fully open-sourced on GitHub under the Apache 2.0 license, with weights and deployment code released simultaneously.
As soon as the model was released, the capital markets responded in three independent yet interconnected ways.
Different Reactions from Capital Markets
On the A-share computing power chain, almost all stocks surged. Cambricon recorded 11 consecutive bullish days, rising 3.7% in a single day, with a cumulative monthly gain exceeding 60%. Haiguang Information hit the 10% daily limit during trading, closing at +8.4%. SMIC A-shares rose by 4.91%, while its H-shares rose by 8.81%. Hua Hong H-shares peaked at +18% before closing at +12%. The China Securities Science and Technology Chip National ETF attracted 2.4 billion yuan in a single day, reaching a historical high in scale.
On the Hong Kong stock market, large model companies told a different story. Zhipu (02513.HK) fell 8.07%, with a short-selling ratio of 9.9%. MiniMax (00100.HK) fell 7.40%, with its short-selling ratio soaring to 22.87%. The latter represents the highest single-day short-selling data for the Hong Kong-listed AI sector in the past three months. Both companies are representatives of the wave of AI IPOs in the second half of 2025, with their IPO prospectuses citing the same core competitiveness: "self-developed foundational large model".
The reaction on the other side of the Pacific was equally specific. Nvidia opened down 1.8% last night, briefly falling to -2.6% during the session, before closing flat. Bloomberg's market commentary compared this consolidation to the V3 "DeepSeek moment" on January 27. The difference is that the January event was a panic sell-off, evaporating $600 billion in market cap in a single day. This time, it felt more like a repricing, moderate in magnitude but clear in direction. A new phrase appeared in research notes from buy-side institutions: "China's AI inference demand is beginning to decouple from North America's AI inference demand."
Overlaying these three market movements forms the first verdict written by the market within 24 hours of V4's launch. With the victory of open-source, capital is beginning to pick sides anew. What can be priced is no longer the model itself, but which card the model runs on and which industrial chain it is embedded in.
30 Days, 11 New Models: V4 Fuels the Open-Source Camp
The timing of V4's release is part of the reason this reaction was amplified.
Zooming out to the past 30 days. Between March 26 and April 24, there were at least 11 globally influential large model releases or major updates, covering almost all key players. This includes Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot AI Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, and finally, DeepSeek V4 released early on April 23.
On average, a new model was released every 2.7 days. This is a pace so fast that even fund managers can't keep up with reading the release notes. However, looking at the K-line charts for Chinese and Hong Kong AI assets over these 30 days, only one name left a lasting trace on the market. GPT-5.5 on April 8 drove Nvidia up 4.2% in a single day, peaking and then falling. Then came DeepSeek V4 on April 23-24, driving the computing power chains in China and Hong Kong to surge continuously.
The difference wasn't in the model capabilities themselves. The gap between these 11 models on the LMArena leaderboard, in most cases, was no more than 50 points, placing them within a narrow "same tier" band. The difference lies in the combination of two factors.
First is open-source. Among the first 10 models, only Llama 4 was open-source. However, Llama 4's weight license came with a long list of commercial usage restrictions. The developer community in Europe and America reacted coldly, and it dropped out of the top ten on OpenRouter by the third day. V4's license is Apache 2.0, with unrestricted weights, no commercial limitations, and inference code released simultaneously. This is the first flagship open-source model in the past six months to put simultaneous pressure on the closed-source camp across three dimensions: performance, price, and openness.
Second is timing. Against the backdrop of successive major releases from the closed-source camp, the open-source narrative has been under repeated pressure. Opus 4.6 pushed the SWE-Bench for coding tasks to new highs. GPT-5.5 set the price anchor at $1.25 per million tokens. The debate on whether open-source can catch up to closed-source has been ongoing in Silicon Valley for two years. V4, an open-source flagship with an estimated 90 million monthly active users, has pressed the pause button on this debate.
As one major domestic fund manager put it during a roadshow: "Before V4, we applied a discount to the valuation of open-source large models. After V4, this discount is starting to reverse."
DeepSeek Rewrites the Pricing Table for the Computing Power Supply Chain
V4's release notes contained a line never before seen in any official Chinese large model document: "Day 0 full-stack adaptation for Cambricon Siyuan 590 and Huawei Ascend 950PR, with deployment code open-sourced simultaneously." To understand the weight of this sentence, one must connect the three parallel undercurrents that have unfolded over the past 12 months. These three undercurrents belong to hardware, software, and Silicon Valley's reaction.
The first undercurrent is on the chip side. The Huawei Ascend 950PR entered mass production in December 2025, boasting 1.56 PFLOPS of FP4 computing power and 112GB of HBM memory. This is the first time a domestic AI chip has rivaled Nvidia's B-series on hard specs. In inference tasks for a 1T-parameter MoE model like V4, single-card throughput improved 2.87 times compared to the H20. The accompanying CANN 8.0 software stack pushed the optimization of LLM inference frameworks down to the operator level. DeepSeek's published benchmarks show that V4's end-to-end inference latency on an Ascend supernode (8x 950PR) is 35% lower than on a comparable H100 cluster. Data for the Cambricon Siyuan 590 is even more aggressive, with single-chip FP8 computing power comparable to the H100 at less than half the price.
The second undercurrent is on the software side. The main branch of vLLM merged the PR for the Cambricon MLU backend on April 22. For the first time, an open-source inference framework natively supports a non-Nvidia domestic GPU. Haiguang Information's DCU takes a different path through the ROCm ecosystem, but it can fully run V4's MoE routing layer. This means V4's deployment is no longer "only runnable on a specific domestic card" but "selectable among multiple domestic cards". The ecosystem's dependence on a single point supplier is broken, which is a key inflection point for production.
The third undercurrent comes from Silicon Valley. On April 15, during TSMC's earnings call, Jensen Huang was questioned by analysts about the progress of domestic Chinese computing power. His cold and specific response was: "If they can really decouple LLMs from CUDA, it would be a disaster for us." Nine days later, DeepSeek gave its answer with a one-line Day 0 announcement.
The term "domestic substitution" has been so overused in the past three years that it lost its meaning. But after the morning of April 24, this concept finally had concrete data that could be priced by the capital market: single-card throughput, end-to-end inference latency, inference cost, and commercially deployable code. These factors quietly brought this long-standing war of words to the threshold of production.
The logic behind Cambricon's 11 consecutive bullish days lies here. It is no longer just a "domestic GPU concept stock", but a "DeepSeek V4 inference infrastructure supplier". The same logic can explain Hua Hong's 12% H-share gain; it manufactures the equivalent 7nm process for the 950PR. Every V4 token running on a domestic Ascend chip represents production capacity that would have flowed to Nvidia and TSMC, partially retained in the Pearl River Delta.
And the next step is already laid out. On Huawei's roadmap, the 950DT (training version) is planned for delivery in Q4 2026, with the corresponding goal being "full-stack training of a V5 or equivalent model on a 10,000-card cluster". If this path proves successful, CUDA's moat in the training of large models in China will be downgraded from "necessary" to "optional".


