
Polymarket ตั้งราคาผิดหรือไม่? 200 ตัวแทน AI จำลองวิกฤตให้คำตอบที่ไม่คาดคิด
- มุมมองหลัก: การทดลองที่ใช้ MiroFish เพื่อจำลองการอภิปรายกลุ่มของตัวแทน AI 200 ตัวในวิกฤตช่องแคบฮอร์มุซ พบว่าการคาดการณ์ที่เกิดขึ้นเองในการอภิปรายอย่างอิสระของตัวแทน (เฉลี่ย 47.9%) แตกต่างอย่างมีนัยสำคัญจากการคาดการณ์ของตลาด Polymarket (31%) และการคาดการณ์ของตัวแทนผู้เชี่ยวชาญส่วนน้อยที่แสดงทัศนคติในแง่ร้ายในการอภิปรายอย่างอิสระ (เฉลี่ย 22%) ใกล้เคียงกับการกำหนดราคาของตลาดมากที่สุด ซึ่งเผยให้เห็นความคลาดเคลื่อนอย่างเป็นระบบระหว่างการแสดงออกต่อสาธารณะกับการประเมินความเสี่ยงที่แท้จริง
- องค์ประกอบสำคัญ:
- การทดลองสร้างเครือข่ายสังคมจำลองที่มีบทบาท 200 บทบาท รวมถึงรัฐบาล สื่อ และสถาบันการเงิน โดยอ้างอิงจากกราฟความรู้สรุป 5800 ตัวอักษร ซึ่งสร้างโพสต์ 1888 รายการและพฤติกรรมปฏิสัมพันธ์จำนวนมากในช่วงการจำลอง 7 วัน
- การอภิปรายกลุ่มอย่างอิสระ (ผลลัพธ์แบบออร์แกนิก) โดยรวมมีแนวโน้มมองในแง่ดี โดยมีความน่าจะเป็นในการคาดการณ์เฉลี่ย 47.9% ในขณะที่ความน่าจะเป็นที่สอดคล้องกับการกำหนดราคาตลาด Polymarket คือ 31% ซึ่งแตกต่างกัน 16.9 จุดเปอร์เซ็นต์
- ในการอภิปรายอย่างอิสระ ตัวแทนผู้เชี่ยวชาญ 7 ตัวที่ให้การคาดการณ์ในแง่ร้ายโดยธรรมชาติ (≤30%) ค่าการคาดการณ์เฉลี่ยของพวกเขา (22%) ใกล้เคียงกับผลลัพธ์ของตลาดมากที่สุด โดยมีข้อผิดพลาดภายใน 10 จุดเปอร์เซ็นต์
- เมื่อสอบถามตัวแทนโดยตรงในรูปแบบการสัมภาษณ์ ตัวแทนเกือบทั้งหมดให้การคาดการณ์ที่มองในแง่ดีและร่วมมือกันมากขึ้น (ค่าเฉลี่ยของแต่ละประเภทสูงกว่า 60%) ซึ่งตัดกันอย่างชัดเจนกับประสิทธิภาพในการอภิปรายอย่างอิสระ
- การทดลองเผยให้เห็นความแตกแยกที่คล้ายกันในโลกแห่งความเป็นจริง: คำพูดในที่สาธารณะมักมีแนวโน้มที่จะมั่นคงและมองในแง่ดี ในขณะที่การประเมินความเสี่ยงที่แท้จริงซ่อนอยู่ในการกระทำจริง การแสดงออกอย่างไม่เป็นทางการ หรือการเดิมพันในตลาด
ชื่อต้นฉบับ: how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
ผู้เขียนต้นฉบับ: The Smart Ape
ผู้แปลต้นฉบับ: Peggy, BlockBeats
หมายเหตุบรรณาธิการ: เมื่อ AI เริ่มสามารถจำลองสนามความคิดเห็นได้ การคาดการณ์เองก็กำลังเปลี่ยนแปลงไปอย่างเงียบๆ
บทความนี้บันทึกการทดลองเกี่ยวกับสถานการณ์ในช่องแคบฮอร์มุซ: ผู้เขียนใช้ MiroFish สร้างระบบจำลองที่ประกอบด้วยเอเจนต์ 200 ตัว โดยให้รัฐบาล สื่อ บริษัทพลังงาน นักเทรด และประชาชนทั่วไปอาศัยอยู่ในเครือข่ายสังคมออนไลน์จำลองร่วมกัน ก่อตัวเป็นข้อสรุปผ่านการโต้ตอบอย่างต่อเนื่อง การโต้แย้ง และการเผยแพร่ข้อมูล จากนั้นเปรียบเทียบผลลัพธ์ของกลุ่มนี้กับราคาตลาดของ Polymarket
ผลลัพธ์ไม่สอดคล้องกัน การอภิปรายของกลุ่มโดยรวมมีแนวโน้มมองโลกในแง่ดี ในขณะที่ตลาดมองโลกในแง่ร้ายอย่างมีนัยสำคัญ; ในการแสดงความคิดเห็นอย่างอิสระ เสียงของผู้มองโลกในแง่ร้ายเพียงไม่กี่คนกลับใกล้เคียงกับราคาจริงมากกว่า; และเมื่อเข้าสู่สถานการณ์การสัมภาษณ์ เอเจนต์เกือบทั้งหมดจะมาบรรจบกันที่การแสดงออกที่อ่อนโยนและให้ความร่วมมือมากขึ้น
ความแตกแยกนี้ไม่ใช่เรื่องแปลก ในโลกแห่งความเป็นจริง การแสดงจุดยืนในที่สาธารณะมักมีแนวโน้มที่จะมีเสถียรภาพและมองโลกในแง่ดี ในขณะที่การประเมินความเสี่ยงที่แท้จริงกลับซ่อนอยู่ในพฤติกรรมและการแสดงออกที่ไม่เป็นทางการ กล่าวอีกนัยหนึ่ง วิธีที่ผู้คนพูด วิธีที่พวกเขาคิด และวิธีที่พวกเขาเดิมพันด้วยเงิน มักเป็นระบบที่แตกต่างกันสามระบบ
ในโครงสร้างดังกล่าว สัญญาณที่มีค่าที่สุดมักไม่ได้มาจากฉันทามติ แต่มาจากเสียงที่ดูเหมือนไม่เข้ากับคนอื่นท่ามกลางเสียงรบกวน
ต่อไปนี้เป็นเนื้อหาต้นฉบับ:
ฉันใช้ MiroFish จำลองสถานการณ์ในช่องแคบฮอร์มุซในอีกไม่กี่สัปดาห์ข้างหน้า เครื่องมือนี้ทำงานได้ดีเยี่ยมในการจัดการปัญหาประเภทนี้ เนื่องจากสามารถดำเนินการจำลองสถานการณ์ที่ซับซ้อนสูงได้: นำผู้มีส่วนร่วมหลายฝ่าย บทบาทที่แตกต่างกัน และกลไกจูงใจของแต่ละฝ่ายเข้ามาในระบบเดียวกัน และปล่อยให้เอเจนต์เหล่านี้แข่งขันและโต้แย้งกันอย่างต่อเนื่อง ในที่สุดก็ค่อยๆ ก่อตัวเป็นผลลัพธ์ที่ใกล้เคียงกับฉันทามติ

ต่อไปนี้เป็นขั้นตอนเฉพาะที่ฉันใช้ในการรันการจำลองนี้ และผลลัพธ์สุดท้ายที่ฉันได้รับ ใครๆ ก็สามารถทำซ้ำได้ สิ่งสำคัญคือเพียงแค่รู้ว่าควรดำเนินการตามขั้นตอนใดบ้าง
ประการแรก MiroFish เป็นโครงการโอเพ่นซอร์สจากทีมวิจัยชาวจีน หลังจากคุณป้อนเอกสารชุดหนึ่งให้กับมัน มันจะสร้างกราฟความรู้ก่อน จากนั้นสร้างบุคลิกภาพเอเจนต์ที่แตกต่างกันตามกราฟนี้ จากนั้นจึงปล่อยเอเจนต์เหล่านี้เข้าสู่สภาพแวดล้อม Twitter จำลอง ในสภาพแวดล้อมนี้ พวกมันจะโพสต์ ทวีตตอบกลับ กดไลค์ โต้แย้งกัน หลังจากเสร็จสิ้นการจำลองแล้ว คุณยังสามารถสัมภาษณ์เอเจนต์แต่ละตัวแยกกัน เพื่อดูจุดยืนและกระบวนการให้เหตุผลของแต่ละตัวได้

คุณป้อนสถานการณ์วิกฤตให้กับมัน มันจะสร้างการโต้วาทีรอบๆ เหตุการณ์นั้นขึ้นมา; จากนั้นจากวาทกรรมนี้ คุณสามารถสกัดผลการคาดการณ์ออกมาได้
ฉันเล็งมันไปที่ปัญหาตลาด Polymarket ที่กำลังดำเนินอยู่: ภายในสิ้นเดือนเมษายน 2026 การขนส่งทางทะเลในช่องแคบฮอร์มุซจะกลับสู่ภาวะปกติหรือไม่?
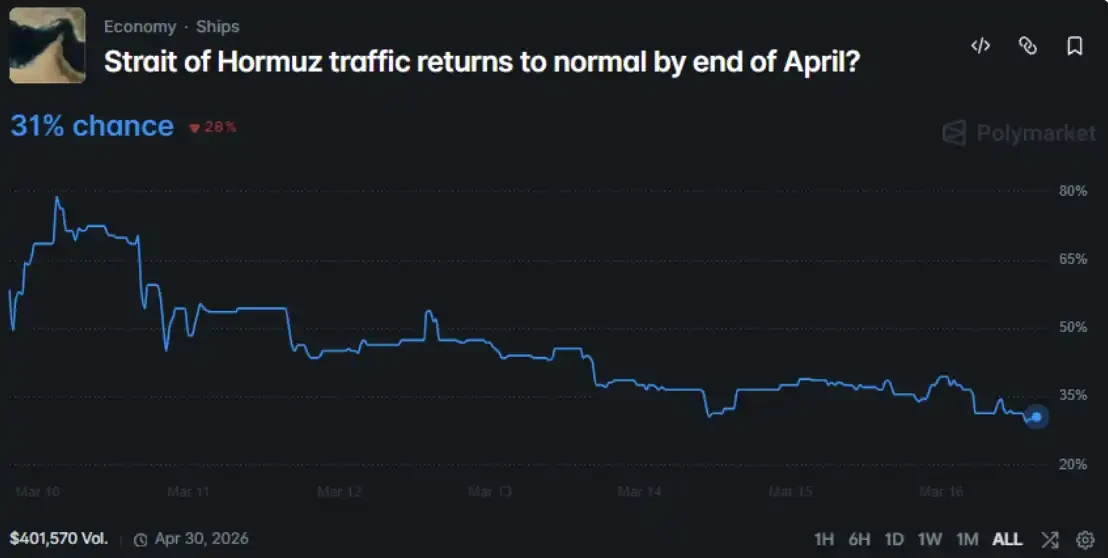
ดังนั้น ฉันจึงป้อนข้อมูลทั้งหมดนี้ให้กับ MiroFish สร้างบทบาทเอเจนต์ 200 ตัว - รวมถึงรัฐบาล สื่อ กองทัพ บริษัทพลังงาน นักเทรด และประชาชนทั่วไป - จากนั้นให้พวกเขาโต้แย้งกันในสภาพแวดล้อมจำลองเป็นเวลา 7 วันจำลอง สุดท้าย เปรียบเทียบผลลัพธ์ที่พวกเขาส่งออกกับราคาตลาด
การกำหนดค่าทั้งหมดมีดังนี้:
· โมเดล: GPT-4o mini ในสถานการณ์ที่มีเอเจนต์ 200 ตัว ให้ความสมดุลระหว่างต้นทุนและประสิทธิภาพที่ดีที่สุด
· ระบบความจำ: Zep Cloud ใช้สำหรับจัดเก็บความจำและกราฟความรู้ของเอเจนต์
· เครื่องยนต์จำลอง: OASIS (สภาพแวดล้อมโคลน Twitter ที่ให้โดย Camel-AI)
· ฮาร์ดแวร์: Mac mini M4 Pro, หน่วยความจำ 24GB
· ระยะเวลาการรัน: ประมาณ 49 นาที เสร็จสิ้น 100 รอบการจำลอง
· ต้นทุน: การเรียกใช้ API ประมาณ 3 ถึง 5 ดอลลาร์
· วัสดุตั้งต้น: บรีฟฟิงขนาด 5800 ตัวอักษร รวบรวมจาก Wikipedia, CNBC, Al Jazeera, Forbes, Reuters เนื้อหาประกอบด้วยไทม์ไลน์ทางทหาร สถานะการปิดล้อม ราคาน้ำมัน ความเสียหายทางเศรษฐกิจ ความพยายามทางการทูต และปัจจัยที่เกี่ยวข้องกับการลงทุน 3.2 ล้านล้านดอลลาร์ของ GCC นั่นคือ ข้อมูลหลักที่เอเจนต์ต้องการเพื่อสร้างการตัดสินใจถูกรวมไว้ทั้งหมด
วิธีทำซ้ำขั้นตอนนี้ (คำแนะนำทีละขั้นตอน)
หากคุณต้องการรันด้วยตัวเอง นี่คือขั้นตอนที่สมบูรณ์ที่ฉันดำเนินการจริง กระบวนการทั้งหมดใช้เวลาประมาณ 2 ชั่วโมงในการกำหนดค่า ต้นทุน API ประมาณ 3 ถึง 5 ดอลลาร์; หากคุณเพิ่มจำนวนรอบหรือจำนวนเอเจนต์ ต้นทุนจะสูงขึ้น
สิ่งที่คุณต้องเตรียม
· Python 3.12 (อย่าใช้ 3.14, tiktoken จะรายงานข้อผิดพลาดในเวอร์ชันนี้)
· Node.js เวอร์ชัน 22 ขึ้นไป
· คีย์ OpenAI API หนึ่งอัน (GPT-4o mini ราคาถูกพอเหมาะสำหรับสถานการณ์นี้)
· บัญชี Zep Cloud หนึ่งบัญชี (รุ่นฟรีเพียงพอสำหรับการจำลองขนาดเล็ก)
· เครื่องที่มีหน่วยความจำค่อนข้างดี ฉันใช้ Mac mini M4 Pro, หน่วยความจำ 24GB, แต่ 16GB น่าจะเพียงพอ
ขั้นตอนที่หนึ่ง: ติดตั้ง MiroFish
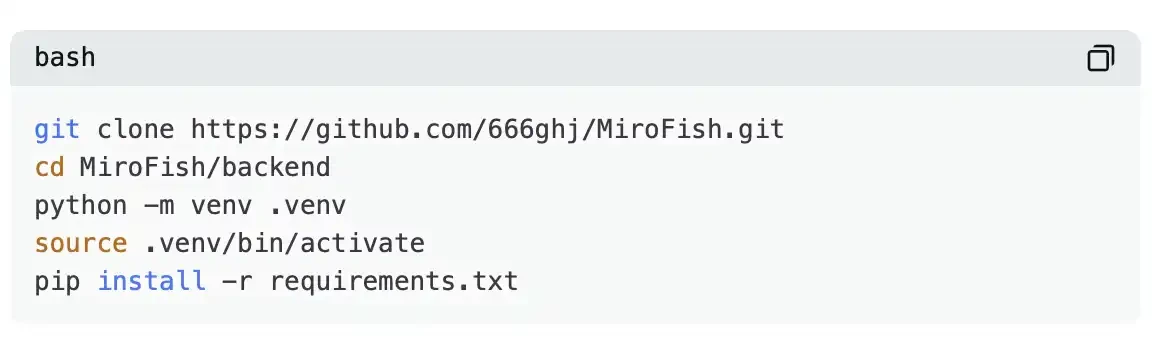
จากนั้นกำหนดค่าไฟล์ .env ของคุณ
OPENAI_API_KEY=sk-your-key
OPENAI_BASE_URL=link
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=your-zep-key
ขั้นตอนที่สอง: สร้างโปรเจกต์และอัปโหลดเอกสารตั้งต้นของคุณ
เอกสารตั้งต้นเป็นส่วนที่สำคัญที่สุดในกระบวนการทั้งหมด มันกำหนดว่าเอเจนต์จะรู้ข้อมูลใดบ้างเกี่ยวกับสถานการณ์ปัจจุบัน ฉันเตรียมบรีฟฟิงขนาดประมาณ 5800 ตัวอักษร ครอบคลุมไทม์ไลน์ทางทหาร สถานะการปิดล้อม ราคาน้ำมัน ความเสียหายทางเศรษฐกิจ ความพยายามทางการทูต และผลกระทายในระดับการลงทุนของ GCC แหล่งข้อมูลรวมถึง Wikipedia, CNBC, Al Jazeera, Forbes และ Reuters
ขั้นตอนที่สาม: สร้างออนโทโลยี (ontology)
ขั้นตอนนี้คือการบอก MiroFish ว่าควรระบุเอนทิตีประเภทใด และอาจมีความสัมพันธ์ใดระหว่างเอนทิตีเหล่านี้
ในส่วนของฉัน สร้างเอนทิตี 10 ประเภทในที่สุด: ประเทศ กองทัพ เจ้าหน้าที่ทางการทูต องค์กรธุรกิจ สถาบันสื่อ เอนทิตีทางเศรษฐกิจ องค์กร บุคคล โครงสร้างพื้นฐาน ตลาดทำนาย; และความสัมพันธ์ 6 ประเภท หากผลลัพธ์ที่สร้างขึ้นอัตโนมัติไม่ค่อยเหมาะกับสถานการณ์ของคุณ คุณสามารถปรับเปลี่ยนด้วยตนเองได้
ขั้นตอนที่สี่: สร้างกราฟความรู้
ขั้นตอนนี้จะใช้ Zep Cloud MiroFish จะส่งเอกสารตั้งต้นและออนโทโลยีไปยัง Zep โดยให้ Zep รับผิดชอบในการดึงเอนทิตีและสร้างกราฟ
กระบวนการนี้ใช้เวลาประมาณหนึ่งหรือสองนาที ฉันได้กราฟที่มีโหนด 65 โหนด ขอบ 85 เส้น ซึ่งเชื่อมโยงองค์ประกอบต่างๆ เช่น ประเทศ บุคคล องค์กร สินค้าโภคภัณฑ์ ฯลฯ เข้าด้วยกัน
ขั้นตอนที่ห้า: สร้างเอเจนต์
MiroFish จะสร้างชุดการตั้งค่าบุคลิกภาพที่สมบูรณ์สำหรับแต่ละเอนทิตีตามกราฟความรู้ รวมถึงประเภทบุคลิกภาพ MBTI อายุ ประเทศต้นทาง สไตล์การโพสต์ จุดกระตุ้นอารมณ์ หัวข้อต้องห้าม และความจำเชิงสถาบัน เป็นต้น
ฉันสร้างเอเจนต์หลัก 43 ตัวจากกราฟความรู้ในตอนแรก หลังจากนั้น ระบบยังสามารถขยายบทบาทหลักเหล่านี้เป็นจำนวนทั้งหมดที่คุณต้องการ ฉันตั้งจำนวนเอเจนต์ทั้งหมดเป็น 200 ในที่สุด และเพิ่มบทบาทพลเมืองที่หลากหลายมากขึ้น เช่น นักเทรดคริปโต นักบินสายการบิน ศาสตราจารย์ นักเรียน นักกิจกรรมสังคม เป็นต้น
ขั้นตอนที่หก: เตรียมสภาพแวดล้อมจำลอง

ขั้นตอนนี้จะสร้างการกำหนดค่าการจำลองที่สมบูรณ์ รวมถึงตารางการดำเนินการของเอเจนต์ โพสต์ตั้งต้นเริ่มต้น และพารามิเตอร์เวลา MiroFish จะเลือกชุดการตั้งค่าเริ่มต้นที่ค่อนข้างสมเหตุสมผลโดยอัตโนมัติ เช่น ชั่วโมงเร่งด่วน ชั่วโมงนอน และความถี่ในการโพสต์ของเอเจนต์ประเภทต่างๆ
การกำหนดค่าของฉันคือ: จำลองทั้งหมด 168 ชั่วโมง (7 วัน), 100 รอบ (แต่ละรอบแทน 1 ชั่วโมง), ใช้เฉพาะฉาก Twitter และตั้งตารางเวลาที่ใช้งานสำหรับเอเจนต์ที่แตกต่างกัน
ขั้นตอนที่เจ็ด: เริ่มรันการจำลอง

จากนั้นก็รอ เอเจนต์ 200 ตัวของฉันใช้ GPT-4o mini รัน 100 รอบการจำลอง ใช้เวลาประมาณ 49 นาที คุณสามารถตรวจสอบความคืบหน้าผ่าน API หรือดูบันทึกโดยตรงได้
ในระหว่างกระบวนการทั้งหมด เอเจนต์จะทำงานโดยอัตโนมัติ: พวกมันจะสังเกตไทม์ไลน์ ตัดสินใจว่าจะโพสต์ ทวีตตอบกลับ แชร์ กดไลค์ หรือเพียงแค่เลื่อนดูฟีด ไม่ต้องการการแทรกแซงจากมนุษย์
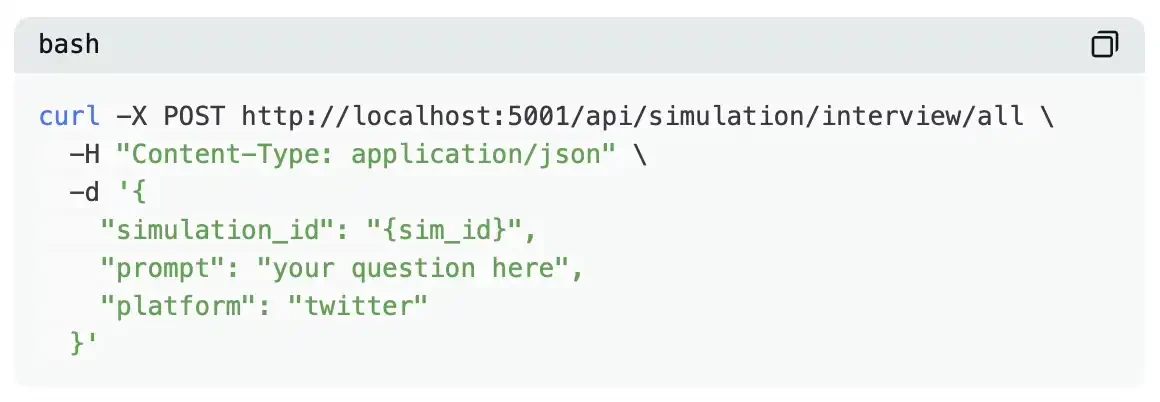
ขั้นตอนที่แปด (ไม่บังคับ): สัมภาษณ์เอเจนต์
หลังจากเสร็จสิ้นการจำลอง ระบบจะเข้าสู่โหมดคำสั่ง ตอนนี้คุณสามารถสัมภาษณ์เอเจนต์เฉพาะรายหรือสัมภาษณ์เอเจนต์ทั้งหมดในครั้งเดียว:
การวิเคราะห์
MiroFish จะอ่านเอกสารตั้งต้นก่อน และสร้างโครงสร้างออนโทโลยีโดยอัตโนมัติ (รวมถึงเอนทิตี 10 ประเภทและความสัมพันธ์ 6 ประเภท); จากนั้นจะดึงกราฟความรู้ (ประกอบด้วยโหนด 65 โหนดและขอบ 85 เส้น) ตามคำจำกัดความเหล่านี้ บนพื้นฐานนี้ มันจะสร้างการตั้งค่าบุคลิกภาพที่สมบูรณ์สำหรับแต่ละเอนทิตี รวมถึงองค์ประกอบต่างๆ เช่น ประเภทบุคลิกภาพ MBTI อายุ ประเทศต้นทาง สไตล์การโพสต์ จุดกระตุ้นอารมณ์ และความจำเชิงสถาบัน เป็นต้น
ในที่สุด สร้างเอเจนต์หลัก 43 ตัวจากกราฟความรู้ และขยายเป็นเอเจนต์ทั้งหมด 200 ตัวบนพื้นฐานนี้ นำเข้าบทบาทพลเมืองที่หลากหลายมากขึ้น เพื่อเพิ่มความหลากหลายและความสมจริงโดยรวมของการจำลอง
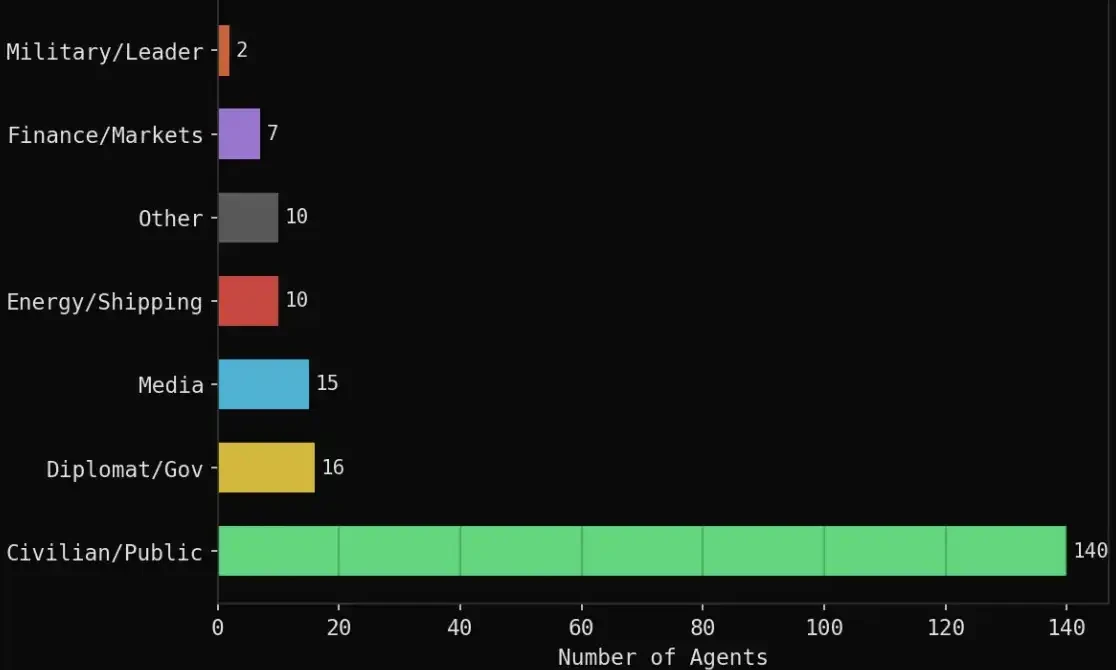
องค์ประกอบเฉพาะมีดังนี้:
· เอเจนต์พลเมือง 140 ตัว: นักเทรดคริปโต นักบินสายการบิน ผู้จัดการซัพพลายเชน นักเรียน นักกิจกรรมสังคม ศาสตราจารย์ เป็นต้น
· บทบาททางการทูต/รัฐบาล 16 บทบาท: รัฐมนตรีต่างประเทศอิหร่าน รัฐมนตรีต่างประเทศซาอุดีอาระเบีย รัฐมนตรีต่างประเทศโอมาน นายกรัฐมนตรีบาห์เรน รัฐมนตรีต่างประเทศจีน สหภาพยุโรป สหประชาชาติ เป็นต้น
· สถาบันสื่อ 15 แห่ง: Reuters, CNN, Bloomberg, Al Jazeera, BBC, Fox, Wall Street Journal เป็นต้น
· เกี่ยวข้องกับพลังงาน/การเดินเรือ 10 แห่ง: OPEC, Platts, QatarEnergy, Aramco, Maersk เป็นต้น
· สถาบันการเงิน 7 แห่ง: Polymarket, Kalshi, Goldman Sachs, JPMorgan Chase, Citadel, ADIA เป็นต้น
· บทบาททางทหาร/การเมือง 2 บทบาท: ทรัมป์, ผู้บัญชาการกองกำลังพิทักษ์ปฏิวัติอิหร่าน
ในระหว่างกระบวนการจำลอง 7 วัน (100 รอบ) สร้าง:
โพสต์ 1,888 รายการ
เส้นทางการดำเนินการ 6,661 รายการ (บันทึกการกระทำทั้งหมด)
การอ้างอิงและรีทวีต 1,611 รายการ (เอเจนต์ตอบโต้และแข่งขันกัน)
การรีเฟรช 4,051 ครั้ง (เพียงแค่เลื่อนดูฟีด)
ไม่ทำอะไรเลย 311 ครั้ง (เลือกรอดูสถานการณ์)
กดไลค์ 208 ครั้ง, แชร์ 207 ครั้ง
มุมมองดั้งเดิม 70 รายการ (จุดยืนหรือการตัดสินใจอิสระใหม่)
โดยรวมแล้ว ระบบนี้ไม่ได้แสดงให้เห็นเพียงการสร้างข้อมูลอย่างง่าย แต่ใกล้เคียงกับการจำลองพฤติกรรมทางสังคมมากขึ้น: เวลาส่วนใหญ่ เอเจนต์สังเกต ดูดซับข้อมูล และโต้ตอบ แทนที่จะส่งออกอย่างต่อเนื่อง โครงสร้างนี้ กลับใกล้เคียงกับการกระจายพฤติกรรมในสนามความคิดเห็นจริงมากกว่า - เนื้อหาดั้งเดิมจำนวนเล็กน้อย ซ้อนทับด้วยการเล่าเรื่องซ้ำ การแข่งขัน และการตอบสนองทางอารมณ์จำนวนมาก
![]()
![]()
![]()
![]()
![]()
![]()


