
Lobster Key 11 Questions: The Most Easy-to-Understand Breakdown of OpenClaw Principles
- Core Viewpoint: Using OpenClaw as an example, this article provides an in-depth yet accessible analysis of the core working principles of AI Agents. It reveals how they grant large language models capabilities such as memory, tool calling, and proactive execution through a "shell" framework, while also emphasizing the significant security risks that accompany these powerful functionalities.
- Key Elements:
- Large language models are essentially probabilistic predictors; they lack memory and perception. OpenClaw simulates "memory" by concatenating an ultra-long Prompt containing settings, history, and tool results during each interaction.
- Tool calling is a "double act" between the framework and the model: the model outputs text instructions in a pre-agreed format, which are then identified and executed as specific operations by the locally running OpenClaw program, with the results fed back to the model.
- To address context window limitations, OpenClaw introduces a sub-agent mechanism, splitting complex tasks for execution and returning only summarized results to the main agent, thereby saving Tokens and improving efficiency.
- The heartbeat mechanism enables the Agent to periodically and proactively check and execute tasks. Combined with "setting an alarm"-style waiting, this facilitates a shift from passive response to active work.
- OpenClaw possesses high permissions locally, posing security risks such as loss of control (e.g., ignoring instructions to delete emails) and prompt injection (inability to distinguish between user and malicious input). Physical isolation deployment is recommended.
- OpenClaw consumed 8.69 trillion Tokens on OpenRouter in the past 30 days. Heavy users' monthly costs can reach approximately seven thousand yuan. The high cost stems from the need to process massive context Prompts during every interaction.
ต้นฉบับวิดีโอจาก | Youtuber:Hung-yi Lee
เรียบเรียงโดย | Odaily Suzz

OpenClaw กำลังเป็นที่นิยมอย่างมาก
ในกระแสการเรียนรู้ที่ครอบคลุมทุกคน ผู้ใช้มือใหม่ส่วนใหญ่ที่ไม่เคยสัมผัสกับ AI (หรือแม้แต่อินเทอร์เน็ต) ต่างก็กำลังเรียนรู้ ติดตั้ง และทดลองใช้ด้วยความรู้สึก FOMO
เชื่อว่าหลายคนคงเคยเห็นบทช่วยสอนที่เป็นประโยชน์มากมายแล้ว แต่วิดีโอนี้ที่กำลังเป็นที่นิยมบน Youtube เมื่อไม่กี่วันที่ผ่านมา เป็นคำอธิบายหลักการทำงานของ AI Agent ที่เข้าใจง่ายที่สุดที่ฉันเคยเห็น เขาใช้มนุษย์เป็นอุปมาอุปไมย "ใช้ภาษาที่แม้แต่คุณยายก็เข้าใจ" อธิบายรายละเอียดเกี่ยวกับปัญหาที่เราทุกคนสงสัยตามธรรมชาติ: การก่อตัวของความจำของ AI, สาเหตุที่ใช้เงินเยอะ, การใช้งานและการไหลของกระบวนการเรียกใช้เครื่องมือ, ความจำเป็นและขอบเขตของการสร้างตัวแทนย่อย, การออกแบบให้ทำงานเชิงรุก, และที่สำคัญที่สุดคือการใช้อย่างปลอดภัย
บางคนอาจมีกระเป๋าเงินที่เลือดออกพรูอยู่แล้ว และกำลังอวดความฉลาดของ OpenClaw ของคุณกับเพื่อนๆ แต่ถ้าถูกถามว่าเจ้านี่ทำงานยังไงกันแน่ เชื่อว่าหลังจากอ่านคำถามสำคัญ 11 ข้อที่ฉันสรุปจากวิดีโอของHung-yi Leeนี้ คุณก็จะสามารถตอบ (และอวด) ได้อย่างคล่องแคล่ว
1. ความจริงของสมอง: "นักต่อคำ"ที่อาศัยอยู่ในกล่องดำ
เพื่อให้เข้าใจว่า OpenClaw (小龙虾) กำลังทำอะไรอยู่ สิ่งแรกที่ต้องทำคือทำลายภาพลวงตาของคนส่วนใหญ่เกี่ยวกับ AI
หลายคนเมื่อได้คุยกับ AI เป็นครั้งแรก มักจะเกิดภาพลวงตาอย่างแรงว่า มีคนที่เข้าใจเราจริงๆ นั่งอยู่ตรงหน้า มันจำได้ว่าเราคุยอะไรไปเมื่อครั้งก่อน สามารถคุยต่อได้ และดูเหมือนจะมีแนวโน้มและทัศนคติของตัวเอง แต่ความจริงไม่ได้โรแมนติกขนาดนั้น
โมเดลใหญ่ที่อยู่เบื้องหลัง OpenClaw ไม่ว่าจะเป็น Claude, GPT หรือ DeepSeek โดยพื้นฐานแล้วคือตัวทำนายความน่าจะเป็น ความสามารถทั้งหมดของพวกมันสามารถสรุปได้เป็นสิ่งง่ายๆ อย่างหนึ่ง: เมื่อได้รับข้อความหนึ่งชุด ให้ทำนายคำถัดไปที่น่าจะปรากฏขึ้นมากที่สุด เหมือนกับ "นักต่อคำ" ที่เก่งมาก คุณให้จุดเริ่มต้นกับมัน มันสามารถต่อได้อย่างเป็นธรรมชาติมาก และต่อได้ลื่นไหลจนคุณรู้สึกว่ามัน "เข้าใจคุณ"
แต่จริงๆ แล้วมันไม่เข้าใจอะไรเลย มันไม่มีตา มองไม่เห็นว่าคุณเปิดซอฟต์แวร์อะไรอยู่บนหน้าจอ มันไม่มีหู ได้ยินเสียงรอบตัวคุณไม่ได้ มันไม่มีปฏิทิน ไม่รู้ว่าวันนี้วันอะไร และที่สำคัญที่สุดคือมันไม่มีหน่วยความจำ — ทุกคำขอใหม่สำหรับมันคือ "ครั้งแรกของชีวิต" มันจำไม่ได้เลยว่าเพิ่งคุยกับคุณไปเมื่อสามวินาทีก่อน มันอาศัยอยู่ในกล่องดำที่ปิดสนิทโดยสมบูรณ์ อินพุตเดียวคือข้อความ เอาต์พุตเดียวก็คือข้อความ

ดังนั้นคุณค่าของ OpenClaw จึงอยู่ที่นี่: มันไม่ใช่โมเดลใหญ่เอง แต่เป็น "เปลือก" ที่ห่อหุ้มโมเดลใหญ่นั้นไว้ มันมีหน้าที่เปลี่ยนตัวทำนายที่เล่นได้แค่การต่อคำ ให้กลายเป็น "พนักงานดิจิทัล" ที่จำคุณได้ ทำงานได้ และแม้กระทั่งหางานทำเอง Peter Steinberger ผู้ก่อตั้ง OpenClaw เองก็เคยกล่าวว่า OpenClaw เป็นแค่เปลือก โมเดลใหญ่ที่คุณเชื่อมต่อต่างหากที่ทำงานจริงๆ แต่เปลือกนี้แหละที่กำหนดว่าประสบการณ์ AI ของคุณจะเป็น "การคุยกับแชทบอทอย่างอึดอัด" หรือ "การมีผู้ช่วยส่วนตัวตัวจริง"
Q1: โมเดลเองเป็น "โรคความจำเสื่อมรุนแรง" การประมวลผลแต่ละคำขอเริ่มจากศูนย์ทุกครั้ง แล้วมันทำยังไงถึง "จำ" ได้ว่าคุณคุยอะไรไปเมื่อครั้งก่อน "รู้" ว่าตัวเองควรเล่นบทบาทอะไร?
OpenClaw ทำหน้าที่ "ส่งกระดาษโน๊ต" จำนวนมากเบื้องหลัง
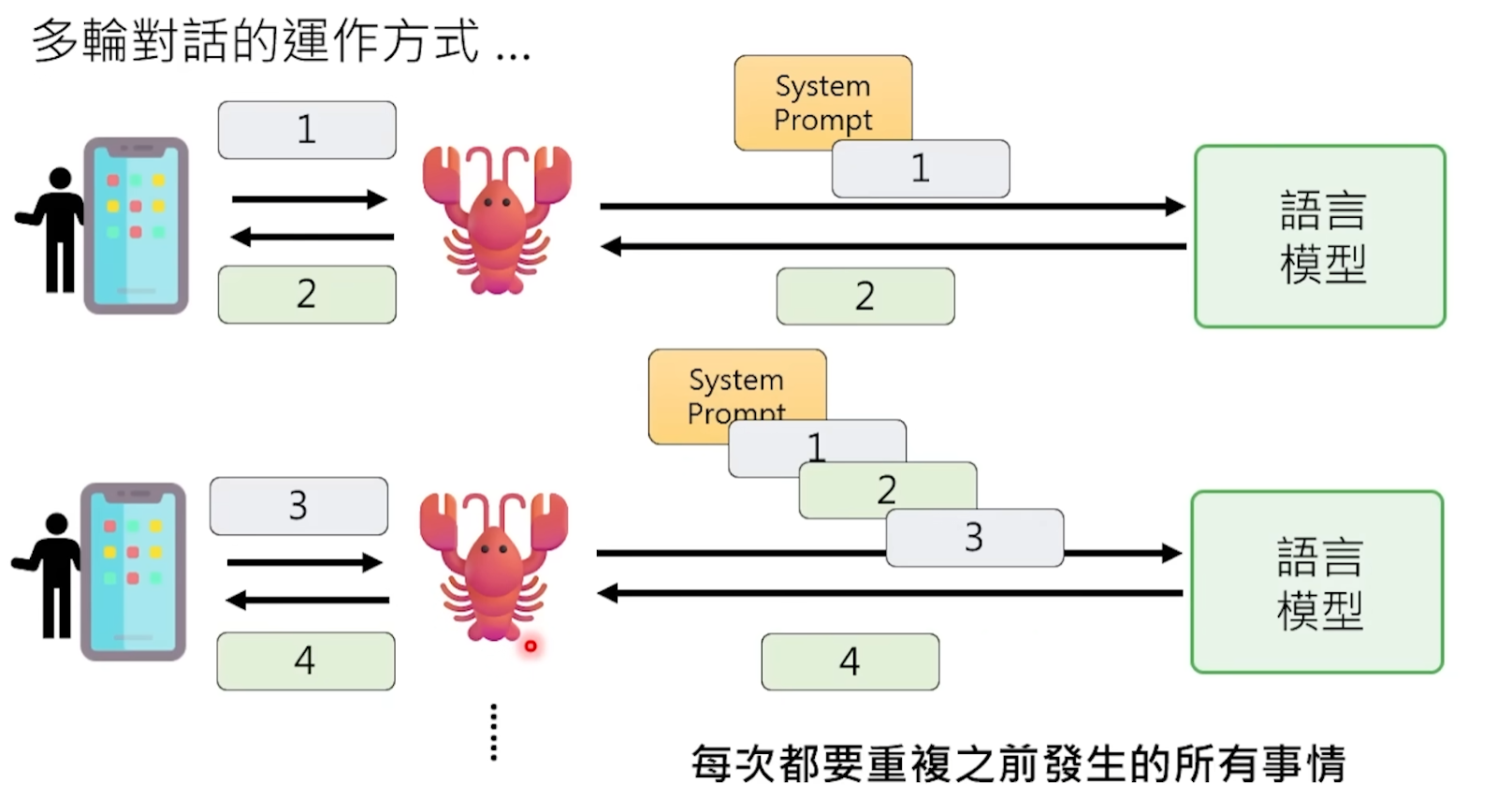
ทุกครั้งก่อนส่งข้อความของคุณไปยังโมเดล OpenClaw จะทำงานใหญ่เบื้องหลังอย่างเงียบๆ ก่อน — นั่นคือการต่อข้อมูลทั้งหมดที่โมเดลจำเป็นต้อง "รู้" เข้าด้วยกันเป็น Prompt ขนาดใหญ่ แล้วยัดให้โมเดลทีเดียว
Prompt นี้มีอะไรบ้าง? อย่างแรกคือ "ชุดวิญญาณสามชิ้น" ในพื้นที่ทำงานของ OpenClaw — ไฟล์สามไฟล์คือ AGENTS.md, SOUL.md, USER.md ซึ่งเขียนว่า OpenClaw ตัวนี้คือใคร บุคลิกภาพเป็นอย่างไร เจ้าของคือใคร เจ้าของมีนิสัยและความชอบในการทำงานอย่างไร จากนั้นคือบันทึกการสนทนาทั้งหมดระหว่างคุณกับมันก่อนหน้านี้ ติดตามมาทุกคำทุกตัวอักษร รวมถึงผลลัพธ์ที่ได้จากการเรียกใช้เครื่องมือก่อนหน้านี้ ข้อมูลสภาพแวดล้อมเช่นวันที่และเวลาปัจจุบัน
หลังจากโมเดลอ่านข้อความยาวนับหมื่นคำนี้แล้ว มันจึง "นึกได้" ว่าตัวเองคือใคร และคุยอะไรกับคุณไปก่อนหน้านี้ จากนั้นมันจึงทำนายการตอบกลับครั้งถัดไปตามบริบททั้งหมดนี้
พูดอีกอย่างคือ "ความจำ" ของโมเดลเป็นเพียงภาพลวงตา — มัน "แกล้ง" ว่ามีความจำได้โดยการอ่านบันทึกการสนทนาทั้งหมดใหม่ตั้งแต่ต้นทุกครั้ง เหมือนผู้ป่วยความจำเสื่อมที่อ่านสมุดบันทึกตั้งแต่หน้าแรกถึงหน้าสุดท้ายทุกครั้งก่อนพบคุณ ดังนั้นเมื่อคุยกับคุณจึงดูเหมือนจำทุกอย่างได้ แต่จริงๆ แล้วเขากำลังทำความรู้จักคุณใหม่ทุกครั้ง
OpenClaw ก้าวไปไกลกว่านั้น: มันมีระบบ "ความจำระยะยาว" ที่คงอยู่ ซึ่งจะเขียนข้อมูลสำคัญลงในไฟล์ในพื้นที่ทำงาน ดังนั้นแม้ว่าประวัติการสนทนาจะถูกล้าง ข้อมูลสำคัญเหล่านั้นจะไม่สูญหาย คุณเคยบอกว่าอยู่หางโจว ครั้งหน้าอาจจะแนะนำกิจกรรม AI ในท้องถิ่นให้คุณเอง — ไม่ใช่เพราะมัน "จำได้" แต่เพราะข้อมูลนี้ถูกเขียนลงในไฟล์แล้ว และจะถูกนำมาต่อใน Prompt ครั้งหน้า
Q2: ทำไมการเลี้ยง OpenClaw ถึงใช้เงินเยอะจัง?
เข้าใจกลไก Prompt ข้างต้นแล้ว คุณก็จะเข้าใจปัญหาที่ทำให้ผู้ใช้หลายคนปวดหัวนี้ได้
ทุกครั้งที่มีการโต้ตอบ โมเดลไม่ได้ประมวลผลแค่ประโยคเดียวที่คุณเพิ่งส่งไป มันต้องประมวลผล Prompt ทั้งหมด ซึ่งรวมถึงการตั้งค่าวิญญาณหลายพันคำ ประวัติการสนทนาทั้งหมด ผลลัพธ์จากเครื่องมือทั้งหมด เนื้อหาเหล่านี้คิดค่าใช้จ่ายเป็นหน่วย Token โดย Token หนึ่งหน่วยประมาณเท่ากับอักษรจีนหนึ่งตัวหรือครึ่งคำภาษาอังกฤษ
แม้ว่าคุณจะส่งแค่ "สวัสดี" OpenClaw อาจประกอบ Prompt ขนาด 5000 Token ไว้เบื้องหลังแล้ว เพราะมันต้องนำไฟล์การตั้งค่าพื้นหลังทั้งหมดมาด้วย เงินที่คุณจ่ายสำหรับ "สวัสดี" นี้จริงๆ แล้วคือค่าประมวลผล Token 5000 ตัว ไม่ใช่ 2 ตัว
และอย่าลืมว่า OpenClaw ยังมีกลไก Heartbeat ซึ่งจะกระตุ้นโมเดลโดยอัตโนมัติทุกๆ สิบนาที แม้ว่าคุณจะไม่พูดอะไรเลย Token ก็ยังคงถูกใช้ไปอย่างต่อเนื่อง ตามสถิติ OpenClaw ถูกเรียกใช้บน OpenRouter มากเป็นอันดับหนึ่งของโลกใน 30 วันที่ผ่านมา โดยใช้ Token ทั้งหมด 8.69 ล้านล้าน Token ผู้ใช้หนักประมาณหนึ่งเดือนต้องการ Token 100 ล้านตัว ค่าใช้จ่ายประมาณเจ็ดพันหยวน แม้กระทั่งมีกรณีที่ OpenClaw ทำงานผิดพลาดและใช้ Token หลายร้อยล้านตัวในคราวเดียว สร้างบิลหลายหมื่นหยวน
ทุกการโต้ตอบเทียบเท่ากับการให้โมเดล "อ่านนวนิยายทั้งเล่มใหม่ทุกครั้ง" นี่คือสาเหตุพื้นฐานที่การเลี้ยง OpenClaw ใช้เงินเยอะ
2. ร่างกายและเครื่องมือ: จะให้โมเดลที่ "แค่พูดได้" "ลงมือทำ" ได้อย่างไร?
แชทบอททั่วไป เช่น ChatGPT เวอร์ชันเว็บ โดยพื้นฐานแล้วคือ "ตัวแทนพูด" คุณถามมันว่า "ช่วยส่งไฟล์ PDF นี้ไปที่อีเมลของฉันหน่อย" มันสามารถบอกขั้นตอนการดำเนินการได้เท่านั้น แต่ทำเองไม่ได้ คุณให้มันช่วยลบไฟล์บนเดสก์ท็อป มันสามารถให้คำแนะนำคุณได้เท่านั้น มันแค่พูด ไม่ลงมือทำ
ความแตกต่างพื้นฐานระหว่าง OpenClaw กับพวกมันอยู่ที่นี่ ตามคำพูดที่แพร่หลายที่สุดในชุมชน: ChatGPT คือที่ปรึกษาทางทหาร แค่ให้แผน; OpenClaw คือทหารช่าง ดำเนินการโดยตรง คุณพูดว่า "ช่วยดาวน์โหลดคอร์ส Python ของ MIT ให้หน่อย" AI ทั่วไปจะให้ลิงก์คุณ ส่วน OpenClaw จะเปิดเบราว์เซอร์อัตโนมัติ หาแหล่งข้อมูล ดาวน์โหลด และวางไว้บนเดสก์ท็อปของคุณ
แต่มีข้อเท็จจริงสำคัญที่ต้องแก้ไข: โมเดลเองไม่ได้มีความสามารถในการควบคุมคอมพิวเตอร์จริงๆ มันยังคงแค่ส่งออกข้อความเท่านั้น เวทมนตร์ที่แท้จริงเกิดขึ้นบน "เปลือก" OpenClaw นี้
Q3: โมเดลภาษาขนาดใหญ่แค่ส่งออกข้อความเท่านั้น แล้ว "การเรียกใช้เครื่องมือ" เกิดขึ้นได้อย่างไรกันแน่?
โมเดลภาษาขนาดใหญ่ไม่มีความสามารถในการเรียกใช้เครื่องมือโดยตรง มันอ่านไฟล์ไม่ได้ ส่งคำขอไม่ได้ ควบคุมเบราว์เซอร์ไม่ได้ — สิ่งเดียวที่มันทำได้คือส่งออกชุดอักขระหนึ่งชุด สิ่งที่เรียกว่า "การเรียกใช้เครื่องมือ" โดยพื้นฐานแล้วคือละครสองคนที่โมเดลและเฟรมเวิร์กร่วมกันแสดง
กล่าวโดยเจาะจง OpenClaw บอกโมเดลไว้ล่วงหน้าใน Prompt ว่า: "เมื่อคุณต้องการดำเนินการบางอย่าง โปรดส่งออกข้อความพิเศษในรูปแบบต่อไปนี้" รูปแบบนี้มักจะเป็นสตริงที่มีโครงสร้าง เช่น JSON ที่มีเครื่องหมาย Tool Call ซึ่งระบุว่าคุณต้องการเรียกใช้เครื่องมือใด และส่งพารามิเตอร์อะไร
โมเดลทำตาม — เมื่อมันตัดสินว่า "ตอนนี้ต้องอ่านไฟล์" มันไม่ได้ไปอ่านจริงๆ แต่เขียนประโยคประมาณนี้ในผลลัพธ์:
[Tool Call] Read("/Users/คุณ/Desktop/report.txt")
นี่เป็นแค่ข้อความธรรมดา ไม่มีเวทมนตร์ใดๆ

จากนั้น OpenClaw ที่อยู่ด้านนอกจะคอยดูผลลัพธ์ทุกชิ้นของโมเดล เมื่อตรวจพบว่าผลลัพธ์มีสตริงรูปแบบพิเศษนี้ มันก็จะรู้ว่า: "อ้อ โมเดลอยากใช้เครื่องมือ Read แล้ว" ดังนั้น OpenClaw จึงไปดำเนินการนี้เอง — เรียกใช้อินเทอร์เฟซของระบบปฏิบัติการ อ่านเนื้อหาไฟล์ — แล้วนำผลลัพธ์กลับมาเป็นข้อความใหม่ใส่กลับเข้าไปใน Prompt เพื่อให้โมเดลประมวลผลต่อ
ตลอดกระบวนการ โมเดลเองไม่รู้เลยว่าเครื่องมือถูกดำเนินการจริงหรือไม่ ผลลัพธ์เป็นอย่างไร มันแค่ "พูดประโยคที่ตรงกับรูปแบบ" แล้วรอดูผลลัพธ์ในการสนทนารอบถัดไป งานหนักทั้งหมดเป็นหน้าที่ของโปรแกรม OpenClaw ที่ทำงานบนคอมพิวเตอร์ของคุณอยู่เบื้องหลัง
นี่คือเหตุผลที่บอกว่า OpenClaw เป็น "เปลือก" — โมเดลคือสมอง OpenClaw คือมือและเท้า สมองบอกว่า "ฉันจะหยิบแก้วนั้น" มือยื่นออกไปหยิบ แล้วส่งความรู้สึกสัมผัสกลับไปให้สมอง สมองเองไม่เคยสัมผัสแก้วเลย

Q4: เมื่อพูดถึง OpenClaw โดยเฉพาะ กระบวนการเรียกใช้เครื่องมือที่สมบูรณ์หนึ่งครั้งเป็นอย่างไร?
ลองใช้สถานการณ์จริงเพื่อเดินตามกระบวนการทั้งหมด สมมติว่าคุณพูดกับ OpenClaw ของคุณบน Feishu ว่า: "ช่วยอ่านไฟล์ report.txt บนเดสก์ท็อปและสรุปให้หน่อย"
ขั้นตอนแรก ก่อนที่ OpenClaw จะส่งข้อความของคุณไปยังโมเดล มันได้ใส่ "คู่มือการใช้เครื่องมือ" ลงใน Prompt แล้ว คู่มือนี้บอกโมเดลในรูปแบบที่มีโครงสร้างว่า: คุณมีเครื่องมือต่อไปนี้ให้ใช้ เครื่องมือแต่ละตัวต้องการพารามิเตอร์อะไร จะส่งคืนผลลัพธ์อะไร เช่น เครื่องมือ Read สามารถอ่านไฟล์ได้ เครื่องมือ Shell สามารถรันคำสั่ง command line ได้ เครื่องมือ Browser สามารถควบคุมเบราว์เซอร์ได้
ขั้นตอนที่สอง โมเดลเห็นคำขอของคุณ จากคู่มือเครื่องมือตัดสินว่าต้องใช้เครื่องมือ Read ดังนั้นในผลลัพธ์จึงเขียนสตริง Tool Call ตามรูปแบบที่ตกลงกัน ประกอบด้วยชื่อเครื่องมือและพาธไฟล์
ขั้นตอนที่สาม OpenClaw ระบุสตริงรูปแบบพิเศษนี้ และดำเนินการอ่านไฟล์จริงๆ บนคอมพิวเตอร์ของคุณ ได้รับเนื้อหาจริงของ report.txt ต้องเน้นตรงนี้: OpenClaw ทำงานบนคอมพิวเตอร์ท้องถิ่นของคุณ นี่เป็นหนึ่งในความแตกต่างที่ใหญ่ที่สุดระหว่างมันกับ ChatGPT มันสามารถเข้าถึงระบบไฟล์บนคอมพิวเตอร์ของคุณโดยตรง
ขั้นตอนที่สี่ OpenClaw นำเนื้อหาไฟล์ที่อ่านได้มาใส่กลับเข้าไปใน Prompt เป็นข้อความใหม่ จากนั้นส่ง Prompt ฉบับสมบูรณ์ที่อัปเดตแล้วกลับไปให้โมเดลอีกครั้ง โมเดลอ่านเนื้อหาไฟล์แล้ว จึงสามารถจัดเรียงภาษาเพื่อสรุปให้คุณได้ เนื่องจาก OpenClaw เชื่อมต่อกับ Feishu สรุปนี้จะถูกส่งไปยังโทรศัพท์ของคุณเป็นข้อความ Feishu โดยตรง — คุณอาจกำลังอยู่บนรถไฟฟ้าใต้ดิน หยิบโทรศัพท์มาดู งานก็เสร็จแล้ว
Peter Steinberger กล่าวถึงข้อได้เปรียบใหญ่มากที่หลายคนมองข้าม: เนื่องจาก OpenClaw ทำงานบนคอมพิวเตอร์ของคุณ ปัญหาเรื่องการรับรองความถูกต้องจึงถูกแก้ไขโดยตรง มันใช้เบราว์เซอร์ของคุณ บัญชีที่คุณล็อกอินแล้ว การอนุญาตทั้งหมดที่มีอยู่ของคุณ ไม่จำเป็นต้องขอ OAuth ใดๆ ไม่ต้องเจรจากับแพลตฟอร์มใดๆ มีผู้ใช้แชร์ว่า OpenClaw ของเขาพบว่าการทำงานบางอย่างต้องการ API Key มันจึงเปิดเบราว


