
กลไกการพิสูจน์ระดับเคอร์เนลสำหรับโมเดลการเรียนรู้ของเครื่อง
ผู้เขียนต้นฉบับ: Zhiyong Fang
“กินช้างยังไง ครั้งละคำ”
ในช่วงไม่กี่ปีที่ผ่านมา โมเดลการเรียนรู้ของเครื่องจักรได้พัฒนาก้าวหน้าอย่างก้าวกระโดดด้วยอัตราที่น่าทึ่ง เมื่อความสามารถของโมเดลเพิ่มขึ้น ความซับซ้อนของโมเดลก็เพิ่มขึ้นพร้อมๆ กันด้วย โมเดลขั้นสูงในปัจจุบันมักมีพารามิเตอร์เป็นล้านหรือพันล้านตัว เพื่อรับมือกับความท้าทายในระดับนี้ จึงได้เกิดระบบพิสูจน์ความรู้เป็นศูนย์ขึ้น ซึ่งมุ่งมั่นที่จะสร้างสมดุลแบบไดนามิกระหว่างเวลาพิสูจน์ เวลายืนยัน และขนาดการพิสูจน์อยู่เสมอ
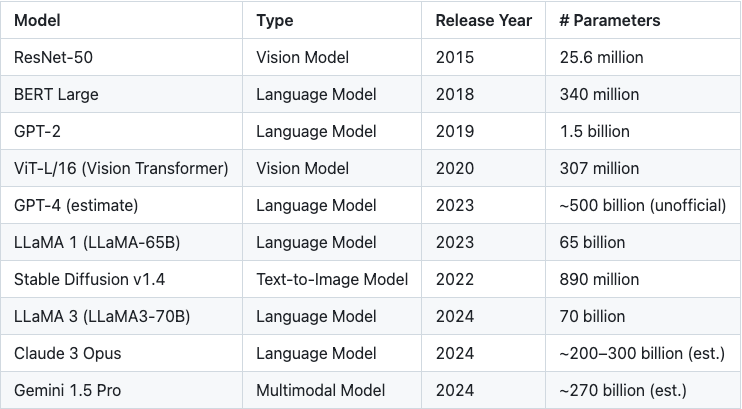
ตารางที่ 1: การเติบโตแบบเอ็กซ์โพเนนเชียลในขนาดพารามิเตอร์ของโมเดล
แม้ว่างานปัจจุบันส่วนใหญ่ในสาขาการพิสูจน์ความรู้เป็นศูนย์จะเน้นที่การปรับปรุงระบบการพิสูจน์เอง แต่มิติสำคัญที่มักถูกมองข้ามไป นั่นก็คือ วิธีแบ่งโมเดลขนาดใหญ่ให้เป็นโมดูลย่อยที่เล็กกว่าและจัดการได้ง่ายกว่าสำหรับการพิสูจน์ คุณอาจถามว่า เหตุใดสิ่งนี้จึงสำคัญมาก?
เรามาอธิบายกันอย่างละเอียด:
จำนวนพารามิเตอร์ในโมเดลการเรียนรู้ของเครื่องจักรสมัยใหม่มักมีจำนวนเป็นพันล้านตัว ซึ่งใช้ทรัพยากรหน่วยความจำจำนวนมากอยู่แล้วแม้จะไม่มีการประมวลผลการเข้ารหัสใดๆ ก็ตาม ในบริบทของการพิสูจน์ความรู้เป็นศูนย์ (ZKP) ความท้าทายนี้จะยิ่งทวีความรุนแรงมากขึ้น
พารามิเตอร์จุดลอยตัวแต่ละตัวจะต้องถูกแปลงเป็นองค์ประกอบในฟิลด์พีชคณิต และกระบวนการแปลงนี้จะเพิ่มการใช้หน่วยความจำประมาณ 5 ถึง 10 เท่า นอกจากนี้ เพื่อจำลองการดำเนินการจุดลอยตัวในฟิลด์พีชคณิตได้อย่างแม่นยำ จะต้องมีการเพิ่มค่าใช้จ่ายการดำเนินการเพิ่มเติม ซึ่งโดยปกติแล้วจะอยู่ที่ประมาณ 5 เท่า
โดยทั่วไป ความต้องการหน่วยความจำโดยรวมของแบบจำลองอาจเพิ่มขึ้นเป็น 25 ถึง 50 เท่าของขนาดเดิม ตัวอย่างเช่น แบบจำลองที่มีพารามิเตอร์จุดลอยตัว 32 บิต 1 พันล้านตัวอาจต้องใช้หน่วยความจำ 100 ถึง 200 GB เพื่อจัดเก็บพารามิเตอร์ที่แปลงแล้วเท่านั้น เมื่อพิจารณาถึงค่าใช้จ่ายด้านการคำนวณระดับกลางและระบบพิสูจน์เองแล้ว การใช้หน่วยความจำโดยรวมจะเกินระดับ TB ได้อย่างง่ายดาย
ระบบพิสูจน์กระแสหลักในปัจจุบัน เช่น Groth 16 และ Plonk มักจะถือว่าข้อมูลที่เกี่ยวข้องทั้งหมดสามารถโหลดลงในหน่วยความจำได้ในเวลาเดียวกันในการใช้งานที่ไม่ได้รับการปรับให้เหมาะสม แม้ว่าสมมติฐานนี้จะเป็นไปได้ในทางเทคนิค แต่ก็ท้าทายอย่างยิ่งภายใต้เงื่อนไขฮาร์ดแวร์จริง และจำกัดทรัพยากรคอมพิวเตอร์พิสูจน์ที่มีอยู่อย่างมาก
โซลูชันของรูปหลายเหลี่ยม: zkCuda
zkCuda คืออะไร?
ตามที่เราได้ระบุไว้ใน เอกสารทางเทคนิคของ zkCUDA :
zkCUDA ของ Polyhedra เป็นสภาพแวดล้อมการคำนวณแบบไร้ความรู้สำหรับการพัฒนาวงจรประสิทธิภาพสูง ออกแบบมาเพื่อปรับปรุงประสิทธิภาพในการสร้างหลักฐาน zkCUDA สามารถใช้ความสามารถของตัวพิสูจน์และฮาร์ดแวร์คู่ขนานพื้นฐานได้อย่างเต็มที่เพื่อสร้างหลักฐาน ZK ได้อย่างรวดเร็ว โดยไม่ต้องเสียสละการแสดงออกของวงจร
ภาษา zkCUDA มีความคล้ายคลึงกับภาษา CUDA มากทั้งในด้านไวยากรณ์และความหมาย และเป็นมิตรต่อนักพัฒนาที่มีประสบการณ์ด้าน CUDA อยู่แล้ว การใช้งานพื้นฐานอยู่ใน Rust ซึ่งรับประกันทั้งความปลอดภัยและประสิทธิภาพ
ด้วย zkCUDA นักพัฒนาสามารถ:
สร้างวงจร ZK ประสิทธิภาพสูงได้อย่างรวดเร็ว
กำหนดเวลาและใช้ทรัพยากรฮาร์ดแวร์แบบกระจายอย่างมีประสิทธิภาพ เช่น GPU หรือสภาพแวดล้อมคลัสเตอร์ที่รองรับ MPI เพื่อให้บรรลุการประมวลผลแบบขนานขนาดใหญ่
ทำไมต้อง zkCUDA?
zkCuda คือกรอบงานการคำนวณแบบไร้ความรู้ประสิทธิภาพสูงที่ได้รับแรงบันดาลใจจากการคำนวณด้วย GPU กรอบงานนี้สามารถแบ่งโมเดลการเรียนรู้ของเครื่องขนาดใหญ่ออกเป็นหน่วยการคำนวณ (เคอร์เนล) ที่เล็กกว่าและจัดการได้ง่ายกว่า และสามารถควบคุมได้อย่างมีประสิทธิภาพผ่านภาษาฟรอนต์เอนด์ที่คล้ายกับ CUDA การออกแบบนี้ให้ข้อได้เปรียบหลักดังต่อไปนี้:
1. การเลือกระบบพิสูจน์สำหรับการจับคู่ที่แน่นอน
zkCUDA รองรับการวิเคราะห์แบบละเอียดของเคอร์เนลคอมพิวเตอร์แต่ละตัวและจับคู่กับระบบพิสูจน์ความรู้เป็นศูนย์ที่เหมาะสมที่สุด ตัวอย่างเช่น:
สำหรับงานประมวลผลแบบขนานสูง อาจใช้โปรโตคอลเช่น GKR ที่เหมาะสำหรับการจัดการการประมวลผลแบบขนานที่มีโครงสร้างได้
สำหรับงานขนาดเล็กหรือมีโครงสร้างไม่สม่ำเสมอ จะเหมาะสมกว่าที่จะใช้ระบบพิสูจน์ เช่น Groth 16 ที่มีค่าใช้จ่ายเบื้องต้นต่ำในสถานการณ์การประมวลผลแบบกะทัดรัด
ด้วยการปรับแต่งการเลือกแบ็กเอนด์ zkCUDA สามารถเพิ่มข้อได้เปรียบด้านประสิทธิภาพของโปรโตคอล ZK ต่างๆ ให้สูงสุดได้
2. การกำหนดตารางทรัพยากรที่ชาญฉลาดและการเพิ่มประสิทธิภาพแบบคู่ขนาน
เคอร์เนลพิสูจน์ที่แตกต่างกันจะมีความต้องการทรัพยากรที่แตกต่างกันอย่างมากสำหรับ CPU หน่วยความจำ และ I/O zkCUDA สามารถประเมินการใช้ทรัพยากรของแต่ละงานได้อย่างแม่นยำและกำหนดเวลาอย่างชาญฉลาดเพื่อเพิ่มปริมาณงานโดยรวมให้สูงสุด
ที่สำคัญกว่านั้น zkCUDA รองรับการกระจายงานระหว่างแพลตฟอร์มคอมพิวเตอร์ที่ไม่เป็นเนื้อเดียวกัน รวมถึง CPU, GPU และ FPGA เพื่อให้บรรลุการใช้ทรัพยากรฮาร์ดแวร์อย่างเหมาะสมที่สุดและปรับปรุงประสิทธิภาพระดับระบบอย่างมีนัยสำคัญ
zkCuda เหมาะกับโปรโตคอล GKR
แม้ว่า zkCuda ได้รับการออกแบบมาให้เป็นกรอบงานการคำนวณทั่วไปที่เข้ากันได้กับระบบพิสูจน์ความรู้เป็นศูนย์หลากหลาย แต่ก็มีความเข้ากันได้ทางสถาปัตยกรรมในระดับสูงกับโปรโตคอล GKR (Goldwasser-Kalai-Rothblum)
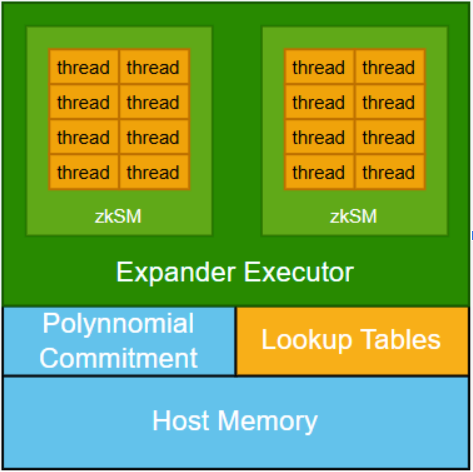
ในแง่ของการออกแบบสถาปัตยกรรม zkCUDA แนะนำกลไกการยืนยันพหุนามเพื่อเชื่อมต่อเคอร์เนลย่อยการประมวลผลต่างๆ เพื่อให้แน่ใจว่าการประมวลผลย่อยทั้งหมดทำงานโดยอาศัยข้อมูลที่ใช้ร่วมกันอย่างสอดคล้องกัน กลไกนี้มีความสำคัญต่อการรักษาความสมบูรณ์ของระบบ แต่ยังก่อให้เกิดต้นทุนการประมวลผลจำนวนมากอีกด้วย
ในทางกลับกัน โปรโตคอล GKR มอบทางเลือกที่มีประสิทธิภาพมากกว่า ซึ่งแตกต่างจากระบบ zero-knowledge แบบดั้งเดิมที่ต้องใช้เคอร์เนลแต่ละตัวในการพิสูจน์ข้อจำกัดภายในทั้งหมด GKR ช่วยให้สามารถติดตามการตรวจสอบความถูกต้องของการคำนวณได้แบบย้อนกลับจากเอาต์พุตของเคอร์เนลไปยังอินพุต กลไกนี้ช่วยให้สามารถถ่ายโอนความถูกต้องข้ามเคอร์เนลแทนที่จะขยายการตรวจสอบในแต่ละโมดูลอย่างสมบูรณ์ แนวคิดหลักของโปรโตคอลนี้คล้ายกับการแพร่กระจายย้อนกลับแบบไล่ระดับในการเรียนรู้ของเครื่อง โดยติดตามและส่งการอ้างความถูกต้องผ่านกราฟการคำนวณ
แม้ว่าการรวม "การไล่ระดับการพิสูจน์" ดังกล่าวในเส้นทางต่างๆ จะมีความซับซ้อนบ้าง แต่กลไกนี้เองที่เป็นพื้นฐานสำหรับการทำงานร่วมกันอย่างลึกซึ้งระหว่าง zkCUDA และ GKR การจัดแนวลักษณะโครงสร้างของกระบวนการฝึกอบรมการเรียนรู้ของเครื่องจักร คาดว่า zkCUDA จะบรรลุการบูรณาการระบบที่แน่นแฟ้นยิ่งขึ้นและการสร้างการพิสูจน์ความรู้เป็นศูนย์ที่มีประสิทธิภาพมากขึ้นในสถานการณ์จำลองขนาดใหญ่
ผลเบื้องต้นและทิศทางในอนาคต
เราได้เสร็จสิ้นการพัฒนาขั้นต้นของกรอบงาน zkCuda และได้ทดสอบสำเร็จแล้วในสถานการณ์ต่างๆ มากมาย รวมถึงฟังก์ชันแฮชการเข้ารหัสเช่น Keccak และ SHA-256 ตลอดจนโมเดลการเรียนรู้ของเครื่องขนาดเล็ก
เมื่อมองไปข้างหน้า เราหวังว่าจะสามารถนำเสนอเทคโนโลยีทางวิศวกรรมที่ครบถ้วนสมบูรณ์เพิ่มเติมในหลักสูตรการเรียนรู้ของเครื่องจักรสมัยใหม่ เช่น การจัดตารางเวลาที่มีประสิทธิภาพในการใช้หน่วยความจำและการเพิ่มประสิทธิภาพในระดับกราฟ เราเชื่อว่าการบูรณาการกลยุทธ์เหล่านี้เข้ากับกระบวนการสร้างหลักฐานความรู้เป็นศูนย์จะช่วยปรับปรุงขอบเขตประสิทธิภาพและความยืดหยุ่นในการปรับตัวของระบบได้อย่างมาก
นี่เป็นเพียงจุดเริ่มต้น zkCuda จะเดินหน้าไปสู่กรอบการทำงานพิสูจน์สากลที่มีประสิทธิภาพ ปรับขนาดได้สูง และปรับเปลี่ยนได้สูง


