
万字深研:AI x Crypto入门指南(上)
ผู้เขียนต้นฉบับ: Mohamed Baioumy และ Alex Cheema
การรวบรวมต้นฉบับ: BeWater

เนื่องจากรายงานฉบับเต็มมีความยาว เราจึงได้แบ่งออกเป็นสองส่วนเพื่อเผยแพร่ บทความนี้เป็นบทความแรก โดยส่วนใหญ่จะอธิบายกรอบงานหลักของ AI x Crypto ตัวอย่างเฉพาะ โอกาสสำหรับผู้สร้าง ฯลฯ หากต้องการดูฉบับแปลฉบับเต็ม โปรดคลิกที่นี่ลิงค์。
1. บทนำ
ปัญญาประดิษฐ์ (AI) จะก่อให้เกิดการเปลี่ยนแปลงทางสังคมอย่างที่ไม่เคยเกิดขึ้นมาก่อน
เมื่อ AI ก้าวหน้าอย่างรวดเร็วและสร้างความเป็นไปได้ใหม่ๆ ในทุกสาขาอาชีพ ก็จะทำให้เกิดการหยุดชะงักทางเศรษฐกิจในวงกว้างอย่างหลีกเลี่ยงไม่ได้ อุตสาหกรรม crypto ก็ไม่มีข้อยกเว้น เราสังเกตเห็นการโจมตี DeFi ครั้งใหญ่สามครั้งในสัปดาห์แรกของปี 2024 โดยมีมูลค่า 76 พันล้านดอลลาร์ในโปรโตคอล DeFi ที่ตกอยู่ในความเสี่ยง ด้วยการใช้ประโยชน์จาก AI เราสามารถตรวจสอบสัญญาอัจฉริยะเพื่อหาช่องโหว่ด้านความปลอดภัย และรวมชั้นความปลอดภัยที่ใช้ AI เข้ากับบล็อกเชน
ข้อจำกัดของ AI ก็คือผู้ไม่ประสงค์ดีสามารถใช้โมเดลที่ทรงพลังในทางที่ผิด ซึ่งเห็นได้จากการแพร่กระจายของดีพเฟคที่เป็นอันตราย โชคดีที่ความก้าวหน้าต่างๆ ในการเข้ารหัสจะนำเสนอความสามารถใหม่ๆ ให้กับโมเดล AI ซึ่งช่วยเพิ่มคุณค่าให้กับอุตสาหกรรม AI อย่างมาก ในขณะเดียวกันก็แก้ไขข้อบกพร่องร้ายแรงบางประการ
การบรรจบกันของ AI และ crypto (Crypto) จะสร้างโครงการที่น่าสังเกตนับไม่ถ้วน โปรเจ็กต์เหล่านี้บางโปรเจ็กต์จะให้แนวทางแก้ไขปัญหาข้างต้น ในขณะที่โปรเจ็กต์อื่นๆ จะรวม AI และ Crypto เข้าด้วยกันในลักษณะผิวเผิน แต่ไม่มีผลประโยชน์ที่แท้จริง
ในรายงานนี้ เราจะแนะนำกรอบแนวคิด ตัวอย่างที่เป็นรูปธรรม และข้อมูลเชิงลึกเพื่อช่วยให้คุณเข้าใจอดีต ปัจจุบัน และอนาคตของสาขานี้

2. กรอบงานหลักของ AI x Crypto
ในส่วนนี้ เราจะแนะนำเครื่องมือที่ใช้งานได้จริงเพื่อช่วยคุณวิเคราะห์โปรเจ็กต์ AI x Crypto ได้ละเอียดยิ่งขึ้น
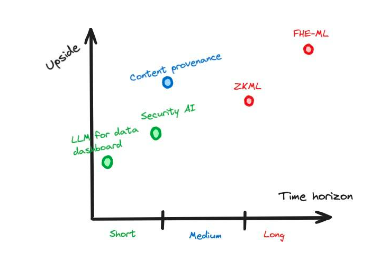
2.1 โครงการ AI (เทคโนโลยีปัญญาประดิษฐ์) x Crypto (เทคโนโลยีการเข้ารหัส) คืออะไร?
เรามาตรวจสอบตัวอย่างบางส่วนของโครงการที่ใช้ทั้ง crypto และ AI แล้วอภิปรายว่าเป็นโครงการ AI x Crypto อย่างแท้จริงหรือไม่

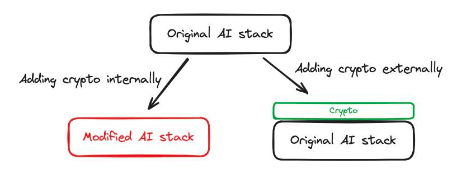
กรณีนี้แสดงให้เห็นว่าการเข้ารหัสสามารถช่วยและปรับปรุงผลิตภัณฑ์ AI ได้อย่างไร โดยใช้วิธีการเข้ารหัสเพื่อเปลี่ยนวิธีการฝึกอบรม AI ส่งผลให้เกิดผลิตภัณฑ์ที่ไม่สามารถทำได้โดยใช้เทคโนโลยี AI เพียงอย่างเดียว: โมเดลที่ยอมรับคำสั่งการเข้ารหัสได้
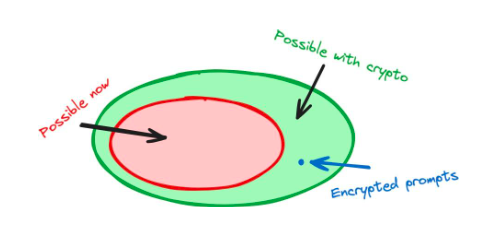
รูปที่ 1: การใช้การเข้ารหัสเพื่อทำการเปลี่ยนแปลงภายในกับ AI Stack สามารถนำไปสู่ความสามารถใหม่ๆ ตัวอย่างเช่น FHE อนุญาตให้เราใช้คำสั่งการเข้ารหัส

ในกรณีนี้ เทคโนโลยี AI ถูกนำมาใช้เพื่อปรับปรุงผลิตภัณฑ์ crypto ซึ่งตรงกันข้ามกับสิ่งที่เราพูดคุยกันก่อนหน้านี้ Dorsa นำเสนอโมเดล AI ที่ทำให้กระบวนการสร้างสัญญาอัจฉริยะที่ปลอดภัยรวดเร็วและถูกกว่า แม้ว่าจะเป็นแบบออฟไลน์ แต่การใช้โมเดล AI ยังคงช่วยโครงการ crypto ได้: สัญญาอัจฉริยะมักจะเป็นแกนหลักของโซลูชันโครงการ crypto
ความสามารถด้าน AI ของ Dorsa สามารถป้องกันการแฮ็กในอนาคตโดยการค้นพบช่องโหว่ที่มนุษย์ลืมตรวจสอบ อย่างไรก็ตาม ตัวอย่างเฉพาะนี้ไม่ได้ใช้ประโยชน์จาก AI เพื่อให้ผลิตภัณฑ์ crypto สามารถทำสิ่งที่พวกเขาไม่เคยทำมาก่อน นั่นคือการเขียนสัญญาอัจฉริยะที่ปลอดภัย AI ของ Dorsa ทำให้กระบวนการดีขึ้นและเร็วขึ้น อย่างไรก็ตาม นี่คือตัวอย่างของเทคโนโลยี AI (แบบจำลอง) ที่ปรับปรุงผลิตภัณฑ์ crypto (สัญญาอัจฉริยะ)

LoverGPT ไม่ใช่ตัวอย่างของ Crypto x AI เราได้กำหนดไว้ว่า AI สามารถช่วยปรับปรุงสแต็คการเข้ารหัสลับและในทางกลับกัน ซึ่งแสดงให้เห็นโดยตัวอย่างของ Privasea และ Dorsa อย่างไรก็ตาม ในกรณีของ LoverGPT ส่วนการเข้ารหัสและส่วน AI จะไม่โต้ตอบกัน เพียงแต่อยู่ร่วมกันในผลิตภัณฑ์ สำหรับโปรเจ็กต์ที่จะได้รับการพิจารณาว่าเป็นโปรเจ็กต์ AI x Crypto นั้น AI และ Crypto นั้นไม่เพียงพอที่จะสนับสนุนผลิตภัณฑ์หรือโซลูชันเดียวกัน เทคโนโลยีเหล่านี้จะต้องเชื่อมโยงกันเพื่อสร้างโซลูชัน

Crypto และ AI เป็นเทคโนโลยีที่สามารถนำมารวมกันได้โดยตรงเพื่อสร้างโซลูชันที่ดีกว่า การใช้ร่วมกันสามารถทำให้กันและกันทำงานได้ดีขึ้นในโครงการโดยรวม เฉพาะโครงการที่เกี่ยวข้องกับการทำงานร่วมกันระหว่างเทคโนโลยีเหล่านี้เท่านั้นที่จัดเป็นโครงการ AI X Crypto
2.2 AI และ Crypto ส่งเสริมซึ่งกันและกันอย่างไร

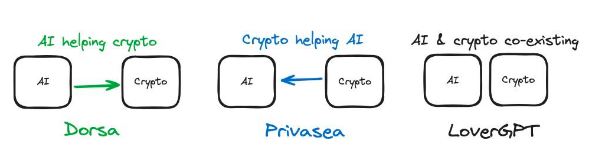
รูปที่ 2: AI และ crypto รวมกันใน 3 ผลิตภัณฑ์ที่แตกต่างกันอย่างไร
เรามาทบทวนกรณีศึกษาก่อนหน้านี้กันดีกว่า ใน Privasea, FHE หรือการเข้ารหัสใช้เพื่อสร้างโมเดล AI ที่สามารถรับอินพุตที่เข้ารหัสได้ ดังนั้นเราจึงใช้โซลูชัน Crypto เพื่อปรับปรุงกระบวนการฝึกอบรมของ AI ดังนั้น Crypto จึงช่วย AI ใน Dorsa มีการใช้แบบจำลอง AI เพื่อตรวจสอบความปลอดภัยของสัญญาอัจฉริยะ โซลูชัน AI ถูกนำมาใช้เพื่อปรับปรุงผลิตภัณฑ์ crypto ดังนั้น AI จึงช่วย Crypto สิ่งนี้นำเราไปสู่มิติที่สำคัญในการประเมินโครงการที่ AI
คำถามง่ายๆ นี้สามารถช่วยให้เราค้นพบแง่มุมที่สำคัญของกรณีการใช้งานในปัจจุบันของเราได้ เช่น ปัญหาหลักที่ต้องแก้ไขคืออะไร ในกรณีของ Dorsa ผลลัพธ์ที่ต้องการคือสัญญาอัจฉริยะที่ปลอดภัย ซึ่งสามารถทำได้โดยนักพัฒนาที่มีทักษะ และ Dorsa ก็ใช้ประโยชน์จาก AI เพื่อทำให้กระบวนการนี้มีประสิทธิภาพมากขึ้น โดยพื้นฐานแล้ว เราสนใจเฉพาะความปลอดภัยของสัญญาอัจฉริยะเท่านั้น เมื่อคำถามหลักชัดเจนแล้ว เราสามารถระบุได้ว่า AI กำลังช่วยเหลือ Crypto หรือ Crypto กำลังช่วยเหลือ AI ในบางกรณี ไม่มีการโต้ตอบที่มีความหมายระหว่างทั้งสอง (เช่น LoverGPT)
ตารางด้านล่างแสดงตัวอย่างเล็กๆ น้อยๆ ในแต่ละหมวดหมู่
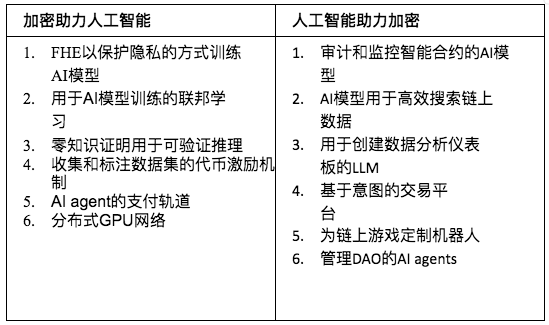
ตารางที่ 1: วิธีการรวม Crypto และ AI
คุณสามารถค้นหาไดเร็กทอรีโปรเจ็กต์ AI x Crypto มากกว่า 150 รายการได้ในภาคผนวก หากเราพลาดสิ่งใดหรือหากคุณมีข้อเสนอแนะใด ๆ โปรดเชื่อมต่อเรา!
2.2.1 สรุป
ทั้ง AI และ Crypto มีความสามารถในการสนับสนุนเทคโนโลยีอื่นเพื่อให้บรรลุเป้าหมาย เมื่อประเมินโครงการ สิ่งสำคัญคือการทำความเข้าใจว่าหัวใจสำคัญของโครงการคือผลิตภัณฑ์ AI หรือผลิตภัณฑ์ Crypto
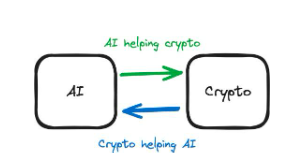
รูปที่ 3: คำอธิบายความแตกต่าง
2.3 การสนับสนุนภายในและภายนอก
มาดูตัวอย่าง Crypto ที่ช่วย AI กัน เมื่อชุดเทคโนโลยีเฉพาะที่ประกอบขึ้นเป็น AI เปลี่ยนแปลง ความสามารถของโซลูชัน AI โดยรวมก็เปลี่ยนไปด้วย คอลเลกชันของเทคโนโลยีนี้เรียกว่าสแต็ก AI Stack ประกอบด้วยแนวคิดทางคณิตศาสตร์และอัลกอริธึมที่ประกอบขึ้นเป็นทุกด้านของ AI เทคนิคเฉพาะที่ใช้ในการประมวลผลข้อมูลการฝึก โมเดลการฝึก และการอนุมานโมเดลล้วนเป็นส่วนหนึ่งของสแต็ก

ในสแต็ก มีการเชื่อมต่อเชิงลึกระหว่างส่วนต่างๆ วิธีที่เทคโนโลยีเฉพาะผสมผสานกันจะกำหนดฟังก์ชันการทำงานของสแต็ก ดังนั้นการเปลี่ยนสแต็กจึงเทียบเท่ากับการเปลี่ยนแปลงสิ่งที่เทคโนโลยีทั้งหมดสามารถทำได้ การแนะนำเทคโนโลยีใหม่เข้าสู่สแต็กสามารถสร้างความเป็นไปได้ทางเทคโนโลยีใหม่ - Ethereum ได้เพิ่มเทคโนโลยีใหม่ลงในสแต็ก crypto เพื่อทำให้สัญญาอัจฉริยะเป็นไปได้ ในทำนองเดียวกัน การเปลี่ยนแปลงสแต็กยังช่วยให้นักพัฒนาสามารถหลีกเลี่ยงปัญหาที่ก่อนหน้านี้คิดว่ามีอยู่ในเทคโนโลยี — การเปลี่ยนแปลง Polygon ที่ทำกับ Ethereum crypto stack ช่วยให้พวกเขาสามารถลดค่าธรรมเนียมการทำธุรกรรมลงสู่ระดับที่ก่อนหน้านี้คิดว่าเป็นไปไม่ได้

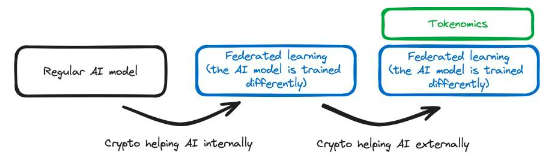
การสนับสนุนภายใน:Cryptozoology สามารถใช้ทำการเปลี่ยนแปลงภายในกับ AI Stack ได้ เช่น การเปลี่ยนวิธีการทางเทคนิคในการฝึกแบบจำลอง เราสามารถแนะนำเทคโนโลยี FHE ให้กับ AI Stack ได้ Privasea เป็นตัวอย่าง ส่วนการเข้ารหัสถูกสร้างขึ้นโดยตรงใน AI Stack ทำให้เกิด AI Stack ที่ได้รับการดัดแปลง
การสนับสนุนภายนอก:Crypto ใช้เพื่อรองรับฟังก์ชันการทำงานแบบ AI โดยไม่ต้องมีการปรับเปลี่ยน AI StackBittensorเป็นตัวอย่างหนึ่งที่จูงใจผู้ใช้ให้มีส่วนร่วมกับข้อมูล ซึ่งเป็นข้อมูลที่สามารถใช้เพื่อฝึกโมเดล AI ได้ ในกรณีนี้ ไม่มีการเปลี่ยนแปลงวิธีการฝึกฝนหรือใช้โมเดล และไม่มีอะไรเปลี่ยนแปลงใน AI Stack อย่างไรก็ตาม ในเครือข่าย Bittensor การใช้สิ่งจูงใจทางเศรษฐกิจช่วยให้ AI Stack บรรลุวัตถุประสงค์ได้ดีขึ้น
รูปที่ 4: ภาพประกอบของการสนทนาครั้งก่อน
ในทำนองเดียวกัน AI ยังสามารถให้ความช่วยเหลือภายในหรือภายนอกแก่ Crypto:
การสนับสนุนภายใน:เทคโนโลยี AI ถูกใช้ภายใน crypto stack AI ออนไลน์และเชื่อมต่อโดยตรงกับส่วนของ crypto stack ตัวอย่างเช่น เจ้าหน้าที่ AI ในห่วงโซ่จัดการ DAO AI นี้ไม่เพียงแต่ช่วยเหลือสแต็ก Cypto เท่านั้น เป็นส่วนสำคัญของกลุ่มเทคโนโลยีและฝังลึกอยู่ในกลุ่มเทคโนโลยีเพื่อให้ DAO ทำงานได้อย่างถูกต้อง
การสนับสนุนภายนอก:AI ให้การสนับสนุนภายนอกสำหรับ crypto stack AI ใช้เพื่อรองรับ Crypto Stack โดยไม่ต้องทำการเปลี่ยนแปลงภายใน แพลตฟอร์มอย่าง Dorsa ใช้โมเดล AI เพื่อรักษาความปลอดภัยสัญญาอัจฉริยะ AI เป็นแบบออฟไลน์และเป็นเครื่องมือภายนอกที่ใช้เพื่อทำให้กระบวนการเขียนสัญญาอัจฉริยะที่ปลอดภัยเร็วขึ้นและถูกลง
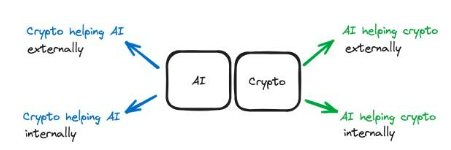
รูปที่ 5: นี่คือโมเดลที่ได้รับการอัพเกรด รวมถึงความแตกต่างระหว่างการสนับสนุนภายในและภายนอก
ขั้นตอนแรกในการวิเคราะห์โครงการ AI x Crypto คือการพิจารณาว่าโครงการนั้นจัดอยู่ในหมวดหมู่ใด
2.4 ระบุจุดคอขวด
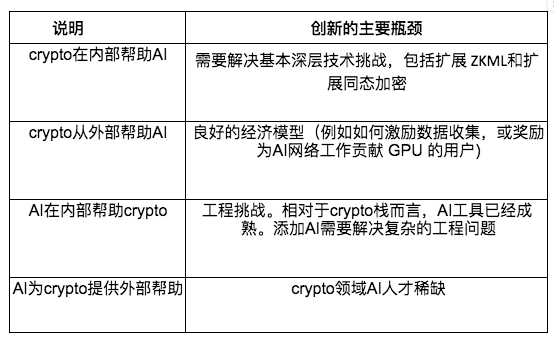
เมื่อเปรียบเทียบกับการสนับสนุนภายนอก การสนับสนุนภายในที่มีการบูรณาการทางเทคนิคเชิงลึกมักจะมีปัญหาทางเทคนิคมากกว่า ตัวอย่างเช่น หากเราต้องการแก้ไข AI Stack โดยการแนะนำ FHE หรือ Zero-Knowledge Proofs (ZKP) เราจะต้องการบุคลากรด้านเทคนิคที่มีความเชี่ยวชาญอย่างมากทั้งในด้านการเข้ารหัสและ AI แต่มีเพียงไม่กี่คนที่ตกอยู่ในทางแยกนี้ บริษัทเหล่านี้ได้แก่Modulus、EZKL、ZamaและPrivasea。
เป็นผลให้บริษัทเหล่านี้ต้องการเงินทุนจำนวนมากและบุคลากรที่ขาดแคลนเพื่อพัฒนาโซลูชันของตน การอนุญาตให้ผู้ใช้รวมปัญญาประดิษฐ์เข้ากับสัญญาอัจฉริยะยังต้องอาศัยความรู้เชิงลึกอีกด้วยRitualและOraบริษัทเช่นนี้จะต้องแก้ไขปัญหาทางวิศวกรรมที่ซับซ้อน
ในทางกลับกัน การสนับสนุนภายนอกก็มีปัญหาคอขวดเช่นกัน แต่มักเกี่ยวข้องกับความซับซ้อนทางเทคนิคน้อยกว่า ตัวอย่างเช่น การเพิ่มความสามารถในการชำระเงินด้วยสกุลเงินดิจิทัลให้กับตัวแทน AI ทำให้เราไม่จำเป็นต้องปรับเปลี่ยนโมเดลมากนัก มันค่อนข้างง่ายที่จะนำไปใช้ แม้ว่าวิศวกร AI จะสร้างกปลั๊กอิน ChatGPT เพื่อสร้าง ChatGPT จาก DeFi LLamaบนหน้าเว็บรับสถิติไม่ซับซ้อนทางเทคนิค แต่มีวิศวกร AI เพียงไม่กี่คนที่เป็นสมาชิกของชุมชน crypto แม้ว่างานจะไม่ซับซ้อนทางเทคนิค แต่มีวิศวกร AI เพียงไม่กี่คนที่สามารถเข้าถึงเครื่องมือเหล่านี้ได้ และหลายคนไม่ทราบถึงความเป็นไปได้
2.5 ยูทิลิตี้การวัด
จะมีโครงการดีๆทั้งสี่ประเภท
หาก AI ถูกรวมเข้ากับ crypto stack นักพัฒนาสัญญาอัจฉริยะจะสามารถเข้าถึงโมเดล AI แบบออนไลน์ เพิ่มจำนวนความเป็นไปได้และอาจนำไปสู่นวัตกรรมที่แพร่หลาย เช่นเดียวกับการรวม crypto เข้ากับ AI stack การบรรจบกันของเทคโนโลยีเชิงลึกจะสร้างความเป็นไปได้ใหม่ ๆ
รูปที่ 6: การเพิ่มปัญญาประดิษฐ์ให้กับ crypto stack ทำให้นักพัฒนามีความสามารถใหม่ๆ
ภายในขอบเขตที่ AI ให้ความช่วยเหลือจากภายนอกในการเข้ารหัส การบูรณาการของ AI มีแนวโน้มที่จะปรับปรุงผลิตภัณฑ์ที่มีอยู่ ในขณะที่สร้างความก้าวหน้าน้อยลง และสร้างความเป็นไปได้น้อยลง ตัวอย่างเช่น การใช้โมเดลปัญญาประดิษฐ์ในการเขียนสัญญาอัจฉริยะอาจเร็วขึ้นและถูกกว่าเมื่อก่อน และอาจปรับปรุงความปลอดภัยด้วย แต่ก็ไม่น่าจะสร้างสัญญาอัจฉริยะที่ไม่เคยทำได้มาก่อน เช่นเดียวกับ crypto ที่ช่วย AI จากภายนอก - สามารถใช้โทเค็นจูงใจสำหรับสแต็ค AI ได้ แต่โดยตัวมันเองนั้นไม่น่าจะกำหนดวิธีที่เราฝึกโมเดล AI ใหม่ได้
โดยสรุป การรวมเทคโนโลยีหนึ่งเข้ากับกลุ่มเทคโนโลยีอื่นอาจนำไปสู่ความสามารถใหม่ๆ ในขณะที่การใช้เทคโนโลยีภายนอกกลุ่มเทคโนโลยีอาจปรับปรุงการใช้งานและประสิทธิภาพ
2.6 โครงการประเมินผล
เราสามารถประเมินผลประโยชน์บางประการของโครงการใดโครงการหนึ่งโดยพิจารณาจากควอแดรนท์ที่อยู่ในนั้น เนื่องจากการสนับสนุนภายในระหว่างเทคโนโลยีสามารถนำไปสู่ผลตอบแทนที่มากขึ้น แต่การประมาณผลประโยชน์ที่ปรับตามความเสี่ยงโดยรวมของโครงการนั้น กำหนดให้เราต้องพิจารณาปัจจัยและความเสี่ยงที่มากขึ้น
ปัจจัยหนึ่งที่ต้องพิจารณาคือโครงการที่อยู่ระหว่างการพิจารณาจะมีประโยชน์ในบริบทของ Web2, Web3 หรือทั้งสองอย่าง โมเดล AI ที่มีความสามารถ FHE สามารถใช้แทนที่โมเดล AI ที่ไม่มีความสามารถ FHE ได้ - การแนะนำความสามารถ FHE นั้นมีประโยชน์ในทั้งสองสาขา และความเป็นส่วนตัวก็มีคุณค่าไม่ว่าในกรณีใดก็ตาม อย่างไรก็ตาม การรวมโมเดลปัญญาประดิษฐ์เข้ากับสัญญาอัจฉริยะสามารถใช้ได้เฉพาะในสภาพแวดล้อม Web3 เท่านั้น
ดังที่ได้กล่าวไว้ก่อนหน้านี้ไม่ว่าการรวมเทคโนโลยีระหว่างปัญญาประดิษฐ์และฟิลด์การเข้ารหัสจะดำเนินการภายในหรือภายนอกจะเป็นตัวกำหนดศักยภาพด้านกลับของโครงการ โครงการที่เกี่ยวข้องกับการสนับสนุนภายในมีแนวโน้มที่จะสร้างความสามารถใหม่ ๆ และการปรับปรุงประสิทธิภาพที่มากขึ้นในขณะที่สิ่งนี้มีคุณค่ามากกว่า
นอกจากนี้เรายังต้องคำนึงถึงช่วงเวลาที่เทคโนโลยีนี้จะเติบโตเต็มที่ ซึ่งจะกำหนดว่าผู้คนต้องรอนานเท่าใดจึงจะได้รับรางวัล
การลงทุนในโครงการ ซึ่งสามารถทำได้โดยการวิเคราะห์ความคืบหน้าในปัจจุบันและระบุปัญหาคอขวดที่เกี่ยวข้องกับโครงการ (ดูหัวข้อ 2.4)
รูปที่ 7: ตัวอย่างสมมุติที่แสดงให้เห็นถึงข้อดีที่อาจเกิดขึ้นเมื่อเปรียบเทียบกับช่วงเวลา
2.7 ทำความเข้าใจผลิตภัณฑ์ที่ซับซ้อน
บางโครงการเกี่ยวข้องกับการรวมสี่ประเภทที่เราได้อธิบายไว้ ไม่ใช่แค่ประเภทเดียว ในกรณีนี้ความเสี่ยงและผลประโยชน์ที่เกี่ยวข้องกับโครงการมีแนวโน้มที่จะทวีคูณและระยะเวลาในการดำเนินโครงการจะนานขึ้น
นอกจากนี้ คุณต้องพิจารณาว่าโครงการโดยรวมดีกว่าผลรวมของส่วนต่างๆ หรือไม่ เนื่องจากโครงการที่มีทุกอย่างเพียงเล็กน้อยมักไม่เพียงพอที่จะสนองความต้องการของผู้ใช้ปลายทาง แนวทางที่มุ่งเน้นมักส่งผลให้เกิดผลิตภัณฑ์ที่ยอดเยี่ยม

2.7.1 ตัวอย่างที่ 1: Flock.io
Flock.ioอนุญาตระหว่างเซิร์ฟเวอร์หลายเครื่อง"การแบ่งส่วน"ในการฝึกโมเดล ไม่มีฝ่ายใดสามารถเข้าถึงข้อมูลการฝึกทั้งหมดได้ เนื่องจากคุณสามารถเข้าร่วมการฝึกอบรมโมเดลได้โดยตรง คุณจึงสามารถมีส่วนร่วมในโมเดลโดยใช้ข้อมูลของคุณเองได้โดยไม่ทำให้ข้อมูลใดๆ รั่วไหล ซึ่งจะช่วยปกป้องความเป็นส่วนตัวของผู้ใช้ เมื่อ AI Stack (การฝึกแบบจำลอง) มีการเปลี่ยนแปลง สิ่งนี้จะเกี่ยวข้องกับการเข้ารหัสที่ช่วย AI ภายใน
นอกจากนี้ พวกเขายังใช้โทเค็นการเข้ารหัสเพื่อให้รางวัลแก่ผู้ที่เกี่ยวข้องกับการฝึกอบรมโมเดลและสัญญาอัจฉริยะเพื่อลงโทษทางการเงินแก่ผู้ที่ขัดขวางกระบวนการฝึกอบรม สิ่งนี้ไม่ได้เปลี่ยนกระบวนการที่เกี่ยวข้องกับการฝึกโมเดล เทคโนโลยีพื้นฐานยังคงไม่เปลี่ยนแปลง แต่ทุกฝ่ายจำเป็นต้องปฏิบัติตามกลไกการเฉือนแบบออนไลน์ นี่คือตัวอย่างการเข้ารหัสที่ช่วย AI จากภายนอก
สิ่งสำคัญที่สุดคือ การเข้ารหัสภายในช่วยให้ AI แนะนำความสามารถใหม่: โมเดลสามารถฝึกอบรมผ่านเครือข่ายกระจายอำนาจในขณะที่รักษาข้อมูลให้เป็นส่วนตัว อย่างไรก็ตาม สกุลเงินดิจิทัลที่ช่วยเหลือ AI จากภายนอกไม่ได้นำเสนอความสามารถใหม่ เนื่องจากโทเค็นนั้นใช้เพื่อจูงใจผู้ใช้ให้มีส่วนร่วมในเครือข่าย ผู้ใช้สามารถได้รับการชดเชยด้วยสกุลเงิน fiat และการใช้สิ่งจูงใจสกุลเงินดิจิทัลเป็นโซลูชันที่ดีกว่าที่สามารถปรับปรุงประสิทธิภาพของระบบได้ แต่ไม่ได้นำเสนอความสามารถใหม่
รูปที่ 8:Flock.ioแผนผังของสแต็กและการเปลี่ยนแปลงในสแต็ก โดยที่การเปลี่ยนแปลงของสีหมายถึงการเปลี่ยนแปลงเกิดขึ้นภายใน
2.7.2 ตัวอย่างที่ 2: หุ่นยนต์ร็อคกี้เฟลเลอร์
หุ่นยนต์ร็อคกี้เฟลเลอร์มันเป็นหุ่นยนต์ซื้อขายที่ทำงานบนห่วงโซ่ โดยจะใช้ AI เพื่อตัดสินใจว่าจะทำธุรกรรมใด แต่เนื่องจากโมเดล AI เองไม่ได้ทำงานบนสัญญาอัจฉริยะ เราจึงต้องอาศัยผู้ให้บริการดำเนินการโมเดลให้เรา แล้วบอก Smart Contract ถึงการตัดสินใจของ AI และพิสูจน์ พวกเขาไปสู่สัญญาที่ชาญฉลาดไม่มีการโกหก หากสัญญาอัจฉริยะไม่ได้ตรวจสอบว่าผู้ให้บริการกำลังโกหกหรือไม่ ผู้ให้บริการอาจทำธุรกรรมที่เป็นอันตรายในนามของเรา Rockefeller Bot ช่วยให้เราใช้การพิสูจน์ ZK เพื่อพิสูจน์สัญญาอัจฉริยะว่าผู้ให้บริการไม่ได้โกหก ในที่นี้ ZK ใช้เพื่อเปลี่ยน AI Stack AI Stack จำเป็นต้องนำเทคโนโลยี ZK มาใช้ ไม่เช่นนั้นเราจะไม่สามารถใช้ ZK เพื่อพิสูจน์การตัดสินใจแบบจำลองในสัญญาอัจฉริยะได้
ด้วยเทคโนโลยี ZK ผลลัพธ์โมเดล AI ที่ได้จึงสามารถตรวจสอบได้และสามารถตรวจสอบได้จากบล็อกเชน ซึ่งหมายความว่าโมเดล AI จะถูกนำมาใช้ภายในสแต็กการเข้ารหัสลับ ในกรณีนี้ เราใช้โมเดลปัญญาประดิษฐ์ในสัญญาอัจฉริยะเพื่อตัดสินใจธุรกรรมและราคาอย่างยุติธรรม สิ่งนี้คงเป็นไปไม่ได้หากไม่มีปัญญาประดิษฐ์
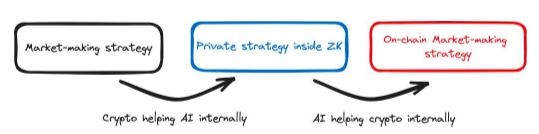
รูปที่ 9: แผนผังของหุ่นยนต์ Rockefeller และการเปลี่ยนแปลงสแต็ก การเปลี่ยนสีหมายความว่าสแต็ก (รองรับภายใน) มีการเปลี่ยนแปลง
3. คำถามที่ควรค่าแก่การสอบสวนเพิ่มเติม
3.1 ช่องการเข้ารหัสและการเปิดเผยแบบ Deepfake

23 มกราคม หนึ่งข้อความเสียงที่สร้างโดย AI แอบอ้างว่าเป็นประธานาธิบดีไบเดนกีดกันพรรคเดโมแครตจากการลงคะแนนเสียงในการเลือกตั้งขั้นต้นปี 2567 ไม่ถึงสัปดาห์ต่อมาพนักงานการเงินสำหรับการเลียนแบบวิดีโอคอลปลอมของเพื่อนร่วมงานของเขาสูญเงินไป 25 ล้านเหรียญ. ในขณะเดียวกันบน X (เดิมคือ Twitter) AI ปลอมแปลงภาพถ่ายที่โจ่งแจ้งของ Taylor Swiftยอดวิวทะลุ 45 ล้านวิวสร้างความเดือดดาลเป็นวงกว้าง เหตุการณ์เหล่านี้ซึ่งทั้งหมดเกิดขึ้นในสองเดือนแรกของปี 2024 เป็นเพียงภาพรวมของผลกระทบที่สร้างความเสียหายต่างๆ ที่ Deepfake มีในการเมือง การเงิน และโซเชียลมีเดีย
3.1.1 สิ่งเหล่านี้กลายเป็นปัญหาได้อย่างไร?
ภาพปลอมไม่ใช่เรื่องใหม่ ในปี 1917 นิตยสาร The Strand ได้ตีพิมพ์ภาพถ่ายของกระดาษตัดที่ประณีตซึ่งออกแบบให้ดูเหมือนนางฟ้า หลายๆ คนถือว่าภาพถ่ายดังกล่าวเป็นหลักฐานของการมีอยู่ของพลังเหนือธรรมชาติ

รูปที่ 10: หนึ่งในรูปถ่ายของ The Fairy of Cottingley เซอร์อาเธอร์ โคนัน ดอยล์ ผู้สร้างเชอร์ล็อก โฮล์มส์ อ้างว่าภาพปลอมดังกล่าวเป็นหลักฐานของปรากฏการณ์อาถรรพณ์
เมื่อเวลาผ่านไป การปลอมแปลงกลายเป็นเรื่องง่ายและราคาถูกกว่า ซึ่งเพิ่มความรวดเร็วในการแพร่กระจายข้อมูลที่ไม่ถูกต้องอย่างมาก ตัวอย่างเช่น ในระหว่างการเลือกตั้งประธานาธิบดีสหรัฐฯ พ.ศ. 2547 ภาพถ่ายปลอมๆ เผยให้เห็นผู้ได้รับการเสนอชื่อจากพรรคเดโมแครต จอห์น เคอร์รี เข้าร่วมการประท้วงกับเจน ฟอนดา นักเคลื่อนไหวชาวอเมริกันผู้เป็นที่ถกเถียง แม้ว่านางฟ้าคอตติงลีย์จำเป็นต้องมีการจัดเตรียมที่ซับซ้อน โดยใช้กระดาษแข็งที่ตัดภาพจากหนังสือเด็กมา แต่การปลอมแปลงนี้เป็นงานง่ายๆ ที่ทำได้สำเร็จโดยใช้ Photoshop

รูปที่ 11:อันนี้ภาพถ่ายแสดงให้เห็น John Kerry กำลังร่วมเวทีกับ Jane Fonda ในการชุมนุมต่อต้านสงครามเวียดนาม ต่อมาถูกค้นพบว่าเป็นภาพถ่ายปลอม ซึ่งเกิดจากการรวมภาพสองภาพที่มีอยู่เข้าด้วยกันโดยใช้ Photoshop
อย่างไรก็ตาม ตามที่เราได้เรียนรู้วิธีสังเกตสัญญาณของการแก้ไข ความเสี่ยงที่เกิดจากภาพถ่ายปลอมก็ลดลง มีอยู่เด็กชายนักท่องเที่ยวในกรณีนี้ มือสมัครเล่นสามารถระบุได้ว่าภาพได้รับการแก้ไขหรือไม่โดยการสังเกตความไม่สอดคล้องกันของไวต์บาลานซ์ระหว่างวัตถุต่างๆ ในฉาก นี่เป็นผลจากการรับรู้ของสาธารณะที่เพิ่มขึ้นเกี่ยวกับข้อมูลที่บิดเบือน ผู้คนได้เรียนรู้ที่จะสังเกตเห็นสัญญาณของการแก้ไขภาพ “ Photoshoped” คำนี้ได้กลายเป็นคำทั่วไป: สัญญาณที่บ่งบอกว่าภาพถูกดัดแปลงกลายเป็นที่รู้จักในระดับสากล และหลักฐานภาพถ่ายไม่ถือว่าไม่มีข้อผิดพลาดอีกต่อไป
3.1.1.1 การปลอมแปลงอย่างลึกซึ้งทำให้การปลอมแปลงง่ายขึ้น ถูกลง และสมจริงมากขึ้น
ในอดีต เอกสารปลอมแปลงสามารถตรวจจับได้ด้วยตาเปล่าได้ง่าย แต่เทคโนโลยี Deepfake ทำให้การสร้างภาพที่แทบจะแยกไม่ออกจากภาพถ่ายจริงนั้นเป็นเรื่องง่ายและราคาถูก ตัวอย่างเช่น เว็บไซต์ OnlyFake ใช้เทคโนโลยี deepfake เพื่อสร้างภาพถ่ายติดบัตรปลอมที่เหมือนจริงภายในไม่กี่นาทีด้วยราคาเพียง 15 ดอลลาร์ ภาพถ่ายถูกใช้เพื่อหลีกเลี่ยง OKX ซึ่งเป็นระบบป้องกันการฉ้อโกงของการแลกเปลี่ยนสกุลเงินดิจิทัลที่เรียกว่า Know Your Customer"(KYC) ในกรณีของ OKX รหัส Deepfake เหล่านี้หลอกพนักงานของตน ซึ่งได้รับการฝึกฝนให้ตรวจจับรูปภาพที่ผ่านการปรับแต่งและ Deepfake สิ่งนี้ชี้ให้เห็นว่าการฉ้อโกงแบบ Deepfake ไม่สามารถตรวจจับได้ด้วยตาเปล่าได้อีกต่อไป แม้แต่กับมืออาชีพก็ตาม
การพึ่งพาหลักฐานวิดีโอเพิ่มขึ้นเมื่อภาพมีการปลอมแปลง แต่การปลอมแปลงอย่างลึกซึ้งจะบ่อนทำลายหลักฐานวิดีโออย่างรุนแรงในไม่ช้า นักวิจัยจากมหาวิทยาลัยเท็กซัสในดัลลาสใช้เครื่องมือสลับใบหน้าแบบ Deepfake ฟรี, ข้ามได้สำเร็จฟังก์ชันการตรวจสอบตัวตนที่ดำเนินการโดยผู้ให้บริการ KYC นี่เป็นการปรับปรุงครั้งใหญ่ ในอดีต การสร้างวิดีโอที่มีคุณภาพมีราคาแพงและใช้เวลานาน
ในปี 2019 มีคนใช้เวลาสองสัปดาห์และ $552 เพื่อเพื่อสร้างวิดีโอ Deepfake ความยาว 38 วินาทีของ Mark Zuckerbergนอกจากนี้ยังมีข้อบกพร่องด้านภาพที่ชัดเจนในวิดีโอด้วย ปัจจุบันนี้ เราสามารถสร้างวิดีโอ Deepfake ที่สมจริงได้ภายในไม่กี่นาทีฟรี
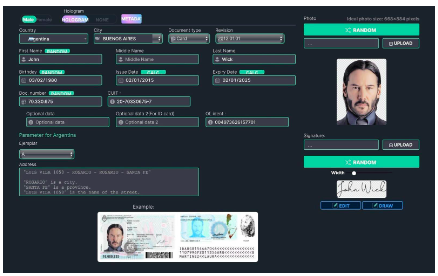
รูปที่ 12: แผง OnlyFake สามารถสร้างบัตรประจำตัวปลอมได้ภายในไม่กี่นาที
3.1.1.2 เหตุใดวิดีโอจึงมีความสำคัญ
ก่อนที่เทคโนโลยี Deepfake จะเข้ามาวิดีโอเคยเป็นหลักฐานที่เชื่อถือได้. ในอดีตวิดีโอมีการปลอมแปลงได้ยาก ต่างจากรูปภาพที่ปลอมแปลงได้ง่าย ดังนั้นจึงได้รับการยอมรับว่าเป็นหลักฐานที่เชื่อถือได้ในศาล สิ่งนี้ทำให้วิดีโอดีพเฟคเป็นอันตรายอย่างยิ่ง
ในเวลาเดียวกัน การเกิดขึ้นของ Deepfakes อาจนำไปสู่การปฏิเสธวิดีโอจริงและสหรัฐอเมริกาของประธานาธิบดีไบเดนย่อหน้าวิดีโอถูกเรียกว่า Deepfakes อย่างไม่ถูกต้อง. นักวิจารณ์ชี้ไปที่ดวงตาที่ไม่กระพริบตาและความแตกต่างของแสงของไบเดนเป็นหลักฐาน และการกล่าวอ้างเหล่านั้นไม่ได้รับการพิสูจน์ สิ่งนี้นำไปสู่ปัญหา - การปลอมแปลงอย่างล้ำลึก ไม่เพียงแต่ทำให้ของปลอมดูเหมือนจริง แต่ยังทำให้ของปลอมดูเหมือนจริงอีกด้วย ทำให้ขอบเขตระหว่างความเป็นจริงกับนิยายพร่ามัว และทำให้ความรับผิดชอบยากขึ้น

Deepfakes ช่วยให้สามารถโฆษณาแบบกำหนดเป้าหมายได้ในวงกว้าง ในไม่ช้า เราอาจเห็น YouTube อีกรายการหนึ่งซึ่งสิ่งที่พูด ใครพูด และที่ที่พูดนั้นได้รับการปรับให้เหมาะกับผู้ชมโดยเฉพาะ ตัวอย่างเบื้องต้นคือโฆษณาที่แปลแล้วสำหรับ Zomatoโฆษณาประกอบด้วยนักแสดง Hrithik Roshan กำลังสั่งอาหารจากร้านอาหารยอดนิยมในเมืองของผู้ชม Zomato สร้างโฆษณาปลอมที่แตกต่างกันโดยอิงตามตำแหน่ง GPS ที่แตกต่างกันของผู้ดู โดยแนะนำเนื้อหาเกี่ยวกับร้านอาหารในตำแหน่งของผู้ดู
3.1.2 ข้อบกพร่องของโซลูชั่นปัจจุบันคืออะไร?
3.1.2.1 จิตสำนึก
ดีพเฟคในปัจจุบันมีความก้าวหน้าเพียงพอที่จะหลอกแม้แต่ผู้เชี่ยวชาญที่ผ่านการฝึกอบรมมาแล้วก็ตาม ซึ่งช่วยให้แฮกเกอร์สามารถเลี่ยงขั้นตอนการยืนยันตัวตน (KYC/AML) และแม้แต่การตรวจสอบโดยมนุษย์ได้ นี่แสดงให้เห็นว่าเราไม่สามารถแยกแยะดีพเฟคจากภาพจริงด้วยตาของเราได้ เราไม่สามารถป้องกันการปลอมแบบ Deepfake เพียงแค่ไม่เชื่อเรื่องรูปภาพได้ เราต้องการเครื่องมือเพิ่มเติมเพื่อต่อสู้กับ Deepfake ที่แพร่หลาย
3.1.2.2 แพลตฟอร์ม
แพลตฟอร์มโซเชียลมีเดียไม่เต็มใจที่จะควบคุมการปลอมแปลงอย่างมีประสิทธิภาพโดยไม่มีแรงกดดันทางสังคมที่รุนแรง ตัวอย่างเช่น Meta แบนวิดีโอปลอมที่มีเสียงปลอม แต่ปฏิเสธที่จะแบนเนื้อหาวิดีโอที่ถูกสร้างขึ้นมาล้วนๆ พวกเขาขัดต่อคำแนะนำของคณะกรรมการกำกับดูแลของตนเองและไม่สามารถลบย่อหน้าได้ประธานาธิบดีไบเดนแสดงกอดหลานสาววิดีโอ Deepfake เนื้อหาที่สร้างขึ้นล้วนๆ。
3.1.2.3 นโยบาย
เราต้องการกฎหมายที่จัดการกับความเสี่ยงใหม่ๆ ของการปลอมแปลงอย่างมีประสิทธิภาพ โดยไม่จำกัดการใช้งานที่มีปัญหาน้อยกว่า เช่น ศิลปะหรือการศึกษา ที่ไม่ได้พยายามหลอกลวงผู้คน เหตุการณ์ต่างๆ เช่น การเผยแพร่ภาพ Deepfake ของ Taylor Swift โดยไม่ได้รับความยินยอม ทำให้ฝ่ายนิติบัญญัติต้องออกกฎหมายที่เข้มงวดมากขึ้นเพื่อต่อสู้กับ Deepfake ดังกล่าว กระบวนการกลั่นกรองออนไลน์ที่เข้มงวดตามกฎหมายอาจจำเป็นเพื่อตอบสนองต่อกรณีดังกล่าว แต่ข้อเสนอให้แบนเนื้อหาที่สร้างโดย AI ทั้งหมด สร้างความตื่นตระหนกให้กับผู้สร้างภาพยนตร์และศิลปินดิจิทัลที่กลัวว่าจะจำกัดงานของพวกเขาอย่างไม่ยุติธรรม การค้นหาสมดุลที่เหมาะสมเป็นสิ่งสำคัญ ไม่เช่นนั้นแอปพลิเคชันโฆษณาที่ถูกต้องตามกฎหมายจะถูกระงับ
ด้วยการผลักดันให้ฝ่ายนิติบัญญัติเพิ่มอุปสรรคในการเข้าสู่การฝึกอบรมโมเดลอันทรงพลัง Big Tech จึงสามารถรักษาการผูกขาด AI ของตนได้ สิ่งนี้อาจนำไปสู่การรวมตัวของอำนาจที่ไม่สามารถย้อนกลับได้ในมือของบริษัทไม่กี่แห่ง ตัวอย่างเช่น เมื่อพูดถึงปัญญาประดิษฐ์คำสั่งผู้บริหารที่ 14110ขอแนะนำให้กำหนดข้อกำหนดที่เข้มงวดกับบริษัทที่มีพลังการประมวลผลจำนวนมาก

รูปที่ 13: รองประธานาธิบดีกมลา แฮร์ริส ของสหรัฐฯ ปรบมือเมื่อประธานาธิบดี โจ ไบเดน ของสหรัฐฯ ลงนามในคำสั่งผู้บริหารฉบับแรกของสหรัฐฯ เกี่ยวกับปัญญาประดิษฐ์
3.1.2.4 เทคโนโลยี
การสร้างราวกั้นโดยตรงในโมเดล AI เพื่อป้องกันการละเมิดถือเป็นแนวป้องกันด่านแรก แต่เป็นราวกั้นเหล่านี้ถูกทำลายอย่างต่อเนื่อง. โมเดล AI นั้นตรวจสอบได้ยากเนื่องจากเราไม่รู้วิธีปรับเปลี่ยนพฤติกรรมในมิติที่สูงกว่าโดยใช้เครื่องมือระดับต่ำที่มีอยู่ นอกจากนี้ บริษัทที่ฝึกอบรมโมเดล AI ยังสามารถใช้ราวกั้นการใช้งานเป็นข้ออ้างในการแนะนำการตรวจสอบและความเอนเอียงที่ไม่พึงประสงค์ในโมเดลของตน นี่เป็นปัญหาเนื่องจากบริษัท AI ที่มีเทคโนโลยีขนาดใหญ่ไม่รับผิดชอบต่อเจตจำนงสาธารณะ บริษัทมีอิสระในการโน้มน้าวโมเดลของตนเพื่อสร้างความเสียหายให้กับผู้ใช้
แม้ว่าการสร้าง AI อันทรงพลังไม่ได้กระจุกตัวอยู่ในมือของบริษัทที่ไม่ซื่อสัตย์ แต่ก็ยังเป็นไปไม่ได้ที่จะสร้าง AI ที่ได้รับการปกป้องและเป็นกลาง เป็นเรื่องยากสำหรับนักวิจัยที่จะตัดสินใจการละเมิดคืออะไรดังนั้นจึงเป็นเรื่องยากที่จะจัดการกับคำขอของผู้ใช้ในลักษณะที่เป็นกลางและสมดุลในขณะที่ป้องกันการละเมิด หากเราไม่สามารถให้คำจำกัดความการละเมิดได้ ดูเหมือนว่าจำเป็นต้องลดความเข้มงวดของมาตรการป้องกัน ซึ่งอาจปล่อยให้การละเมิดเกิดขึ้นอีกครั้ง ดังนั้นจึงเป็นไปไม่ได้เลยที่จะห้ามการใช้โมเดลปัญญาประดิษฐ์ในทางที่ผิดโดยสิ้นเชิง
วิธีแก้ไขประการหนึ่งคือการตรวจจับ Deepfakes ที่เป็นอันตรายทันทีที่ปรากฏ แทนที่จะป้องกันไม่ให้สร้าง Deepfake ขึ้นมา อย่างไรก็ตาม โมเดล AI การตรวจจับ Deepfake เช่น ที่ใช้งานโดย OpenAIเนื่องจากความไม่ถูกต้องกำลังจะกลายเป็นเก่า. แม้ว่าวิธีการตรวจจับ Deepfake จะมีความซับซ้อนมากขึ้นเรื่อยๆ แต่เทคโนโลยีที่ใช้ในการสร้าง Deepfake ก็มีความซับซ้อนมากขึ้นในอัตราที่รวดเร็วยิ่งขึ้นไปอีก เนื่องจากเครื่องตรวจจับ Deepfake กำลังสูญเสียการแข่งขันด้านอาวุธทางเทคโนโลยี ทำให้ยากต่อการระบุข่าวปลอมเชิงลึกจากสื่อเพียงอย่างเดียว ปัญญาประดิษฐ์มีความก้าวหน้าเพียงพอที่จะสร้างภาพปลอมที่สมจริงจน AI ไม่สามารถตัดสินความถูกต้องได้
เทคโนโลยีลายน้ำจะทำเครื่องหมาย Deepfake อย่างรอบคอบเพื่อให้เราสามารถระบุได้ไม่ว่าจะปรากฏที่ไหนก็ตาม อย่างไรก็ตาม Deepfakes ไม่ได้มีลายน้ำมาด้วยเสมอไป เนื่องจากจะต้องเพิ่มลายน้ำอย่างจงใจ สำหรับบริษัทที่สมัครใจสร้างความแตกต่างด้วยการติดป้ายกำกับภาพปลอม เช่น OpenAI การใส่ลายน้ำเป็นวิธีการที่มีประสิทธิภาพ แต่ไม่ว่าจะยังไง ลายน้ำก็ยังดีลบหรือปลอมแปลงด้วยเครื่องมือที่ใช้งานง่ายดังนั้นจึงข้ามโซลูชันต่อต้าน Deepfake ที่ใช้ลายน้ำได้ ลายน้ำสามารถถูกลบออกโดยไม่ตั้งใจได้ เช่นเดียวกับแพลตฟอร์มโซเชียลมีเดียส่วนใหญ่ลบโดยอัตโนมัติลายน้ำ.
เทคโนโลยีลายน้ำ Deepfake ที่ได้รับความนิยมมากที่สุดคือC 2 PA (เสนอโดย Content Provenance and Authenticity Alliance). ได้รับการออกแบบมาเพื่อป้องกันข้อมูลที่ผิดโดยการติดตามแหล่งสื่อและจัดเก็บข้อมูลนี้ไว้ในเมตาดาต้าของสื่อ เทคโนโลยีนี้ได้รับการสนับสนุนจาก Microsoft, Google และ Adobe ดังนั้น C 2 PA จึงมีแนวโน้มที่จะเปิดตัวทั่วทั้งห่วงโซ่อุปทานเนื้อหา ทำให้ได้รับความนิยมมากกว่าเทคโนโลยีอื่นที่คล้ายคลึงกัน
น่าเสียดายที่ C 2 PA มีจุดอ่อนในตัวเอง เนื่องจาก C 2 PA เก็บประวัติการแก้ไขทั้งหมดของรูปภาพและตรวจสอบการแก้ไขแต่ละครั้งโดยใช้คีย์เข้ารหัสที่ควบคุมโดยซอฟต์แวร์แก้ไขที่สอดคล้องกับ C 2 PA เราจึงต้องเชื่อถือซอฟต์แวร์แก้ไขเหล่านี้ อย่างไรก็ตาม มีแนวโน้มว่าผู้คนจะยอมรับรูปภาพที่แก้ไขเนื่องจากข้อมูลเมตา C 2 PA ที่ถูกต้อง โดยไม่ต้องพิจารณาว่าจะเชื่อถือแต่ละฝ่ายในห่วงโซ่การแก้ไขหรือไม่ ดังนั้นหากซอฟต์แวร์แก้ไขใด ๆ ถูกบุกรุกหรือมีความสามารถในการแก้ไขที่เป็นอันตรายก็แสดงว่าเป็นเช่นนั้นอาจทำให้ผู้อื่นเชื่อว่าภาพปลอมหรือภาพตัดต่อที่มีเจตนาร้ายเป็นของแท้。

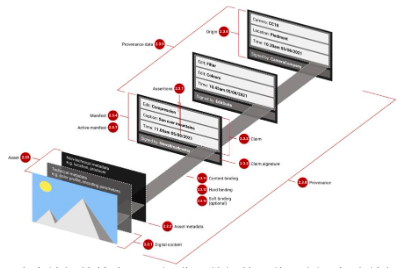
รูปที่ 14: ตัวอย่างของรูปภาพที่มีชุดการแก้ไขที่สอดคล้องกับข้อมูลเมตามาตรฐาน C2PA การแก้ไขแต่ละครั้งจะมีการลงนามโดยฝ่ายที่เชื่อถือได้ที่แตกต่างกัน แต่เฉพาะภาพที่แก้ไขขั้นสุดท้ายเท่านั้นที่จะเผยแพร่ต่อสาธารณะ ที่มา: ภาพถ่ายจริงและงานศิลปะที่สร้างโดย AI: มาตรฐานใหม่ (C 2 PA) ใช้ PKI เพื่อแสดงประวัติภาพ
นอกจากนี้ ลายเซ็นการเข้ารหัสและข้อมูลเมตาที่มีอยู่ในลายน้ำ C 2 PAสามารถเชื่อมโยงกับผู้ใช้หรืออุปกรณ์เฉพาะได้. ในบางกรณี เมตาดาต้า C 2 PA สามารถเชื่อมต่อภาพทั้งหมดที่กล้องของคุณถ่ายเข้าด้วยกันได้ หากเรารู้ว่าภาพบางภาพมาจากกล้องของใครบางคน เราก็จะสามารถระบุภาพอื่นๆ ทั้งหมดจากกล้องนั้นได้ วิธีนี้ช่วยให้ผู้รายงานไม่เปิดเผยตัวตนเมื่อโพสต์รูปภาพ
แนวทางแก้ไขที่เป็นไปได้ทั้งหมดจะเผชิญกับความท้าทายที่มีเอกลักษณ์เฉพาะตัว แม้ว่าความท้าทายเหล่านี้จะแตกต่างกันไปอย่างมาก รวมถึงขีดจำกัดของการรับรู้ทางสังคม ข้อบกพร่องของบริษัทเทคโนโลยีขนาดใหญ่ ความยากลำบากในการดำเนินนโยบายด้านกฎระเบียบ และข้อจำกัดของเทคโนโลยีของเรา

3.1.3 ฟิลด์การเข้ารหัสสามารถแก้ปัญหานี้ได้หรือไม่?
โมเดล Deepfake แบบโอเพ่นซอร์สเริ่มเผยแพร่แล้ว ดังนั้น อาจมีคนแย้งว่ามีวิธีการนำความคล้ายคลึงของคนอื่นไปใช้ในทางที่ผิดอยู่เสมอโดยใช้ Deepfakes แม้ว่าการกระทำดังกล่าวจะถือเป็นอาชญากรรม แต่บางคนก็ยังเลือกที่จะสร้างเนื้อหา Deepfake ที่ผิดจรรยาบรรณ อย่างไรก็ตาม เราสามารถแก้ไขปัญหานี้ได้โดยการนำ Deepfakes ที่เป็นอันตรายออกจากกระแสหลัก เราสามารถป้องกันไม่ให้ผู้คนคิดว่าภาพ Deepfake มีจริง และสร้างแพลตฟอร์มที่จำกัดเนื้อหา Deepfake ส่วนนี้จะแนะนำโซลูชันที่ใช้การเข้ารหัสต่างๆ สำหรับปัญหาทิศทางที่ผิดซึ่งเกิดจากการเผยแพร่ Deepfakes ที่เป็นอันตราย พร้อมเน้นถึงข้อจำกัดของแต่ละแนวทาง
3.1.3.1 การรับรองฮาร์ดแวร์
กล้องที่ได้รับการรับรองฮาร์ดแวร์จะฝังใบรับรองเฉพาะไว้กับภาพถ่ายแต่ละภาพที่ถ่าย เพื่อพิสูจน์ว่ากล้องนั้นถ่ายภาพนั้น ใบรับรองนี้สร้างขึ้นโดยชิปป้องกันการงัดแงะที่ไม่ซ้ำใครของกล้อง ซึ่งรับประกันความถูกต้องของภาพ มีโปรแกรมที่คล้ายกันสำหรับเสียงและวิดีโอ

ใบรับรองบอกเราว่าภาพดังกล่าวถ่ายด้วยกล้องจริง ซึ่งหมายความว่าโดยทั่วไปแล้วเราสามารถเชื่อถือได้ว่าเป็นภาพถ่ายของวัตถุจริง เราสามารถติดป้ายกำกับรูปภาพโดยไม่มีหลักฐานดังกล่าวได้ แต่วิธีนี้ใช้ไม่ได้ผลหากกล้องจับภาพฉากปลอมซึ่งออกแบบมาให้ดูเหมือนของจริง คุณเพียงแค่เล็งกล้องไปที่ภาพปลอมเท่านั้น ในปัจจุบัน เราสามารถบอกได้ว่าภาพถ่ายนั้นถ่ายจากหน้าจอดิจิทัลหรือไม่โดยตรวจสอบว่าภาพที่ถ่ายนั้นบิดเบี้ยวหรือไม่ แต่นักต้มตุ๋นจะหาทางซ่อนข้อบกพร่องเหล่านี้ (เช่น โดยการใช้หน้าจอที่ดีกว่า หรือโดยการจำกัดแสงแฟลร์ของเลนส์) ท้ายที่สุดแล้วก็ตามเครื่องมือปัญญาประดิษฐ์การฉ้อโกงนี้ยังไม่สามารถตรวจจับได้ เนื่องจากนักต้มตุ๋นสามารถหาวิธีหลีกเลี่ยงการบิดเบือนทั้งหมดนี้ได้
การตรวจสอบสิทธิ์ด้วยฮาร์ดแวร์จะลดจำนวนกรณีที่เชื่อถือภาพปลอมได้ แต่ในบางกรณีที่เกิดขึ้นไม่บ่อยนัก เรายังต้องการเครื่องมือเพิ่มเติมเพื่อป้องกันการแพร่กระจายของภาพ Deepfake หากกล้องถูกบุกรุกหรือใช้ในทางที่ผิด ดังที่เราได้กล่าวไว้ก่อนหน้านี้ การใช้กล้องที่ผ่านการตรวจสอบด้วยฮาร์ดแวร์ยังคงสามารถสร้างความรู้สึกผิดๆ ว่าเนื้อหา Deepfake เป็นภาพจริง เช่น กล้องถูกแฮ็กหรือมีการใช้กล้องเพื่อจับภาพฉาก Deepfake บนหน้าจอคอมพิวเตอร์ เพื่อแก้ไขปัญหานี้ จำเป็นต้องมีเครื่องมืออื่นๆ เช่น บัญชีดำของกล้อง
บัญชีดำของกล้องจะช่วยให้แพลตฟอร์มโซเชียลมีเดียและแอปสามารถตั้งค่าสถานะรูปภาพจากกล้องตัวใดตัวหนึ่งได้ เนื่องจากกล้องตัวดังกล่าวเป็นที่รู้กันว่าเคยสร้างภาพที่ทำให้เข้าใจผิดในอดีต บัญชีดำช่วยลดความจำเป็นในการเปิดเผยข้อมูลที่สามารถใช้เพื่อติดตามกล้อง เช่น รหัสกล้อง ฯลฯ ต่อสาธารณะ
อย่างไรก็ตาม ยังไม่ชัดเจนว่าใครเป็นผู้เก็บบัญชีดำของกล้องและเลขที่รู้วิธีป้องกันไม่ให้ผู้คนรับสินบนเข้าบัญชีดำกล้องของผู้แจ้งเบาะแส
3.1.3.2 ลำดับภาพตามบล็อคเชน
บล็อคเชนไม่เปลี่ยนรูป ดังนั้นเมื่อรูปภาพปรากฏบนอินเทอร์เน็ต รูปภาพนั้นจะถูกเพิ่มลงในลำดับเหตุการณ์ที่มีการประทับเวลาพร้อมกับเมตาดาต้าเพิ่มเติม เพื่อไม่ให้การประทับเวลาและข้อมูลเมตาถูกแก้ไข เนื่องจากรูปภาพต้นฉบับที่ยังไม่ได้แก้ไขสามารถจัดเก็บไว้ในบล็อกเชนโดยบุคคลที่ซื่อสัตย์ก่อนที่การแก้ไขที่เป็นอันตรายจะแพร่กระจาย การเข้าถึงบันทึกดังกล่าวจะช่วยให้เราสามารถระบุการแก้ไขที่เป็นอันตรายและตรวจสอบแหล่งที่มาดั้งเดิมได้ เทคโนโลยีดังกล่าวถูกนำไปใช้กับเครือข่าย Polygon blockchain ในฐานะเครื่องมือตรวจสอบข้อเท็จจริงที่พัฒนาขึ้นโดยความร่วมมือกับ Fox NewsVerifyเป็นส่วนหนึ่งของ.

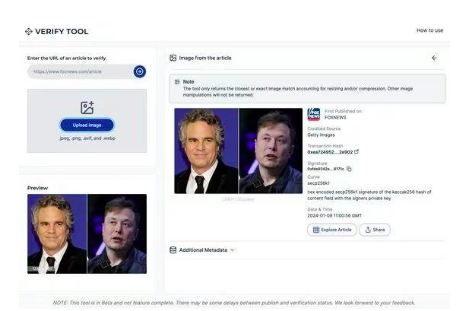
รูปที่ 15: อินเทอร์เฟซผู้ใช้ของเครื่องมือที่ใช้บล็อกเชนของ Fox ตรวจสอบ งานศิลปะสามารถพบได้ตาม URL รับและแสดงแหล่งที่มา แฮชของธุรกรรม ลายเซ็น การประทับเวลา และข้อมูลเมตาอื่น ๆ จากบล็อคเชนรูปหลายเหลี่ยม
3.1.3.3 ตัวตนดิจิทัล
หาก Deepfake บ่อนทำลายความไว้วางใจของเราในรูปภาพและวิดีโอที่ไม่ได้รับการยืนยัน แหล่งที่มาที่เชื่อถือได้อาจกลายเป็นวิธีเดียวที่จะหลีกเลี่ยงการบิดเบือนข้อมูล เราอาศัยแหล่งสื่อที่เชื่อถือได้ในการตรวจสอบข้อมูล เนื่องจากแหล่งเหล่านั้นใช้มาตรฐานด้านนักข่าว ขั้นตอนการตรวจสอบข้อเท็จจริง และการกำกับดูแลของบรรณาธิการ เพื่อให้มั่นใจในความถูกต้องและความน่าเชื่อถือของข้อมูล
อย่างไรก็ตาม เราต้องการวิธีการตรวจสอบว่าเนื้อหาที่เราเห็นทางออนไลน์นั้นมาจากแหล่งที่เราเชื่อถือ นี่คือที่มาของข้อมูลที่เซ็นชื่อแบบเข้ารหัส: มันสามารถพิสูจน์ทางคณิตศาสตร์ว่าเป็นผู้เขียนบางสิ่งได้
ลายเซ็นถูกสร้างขึ้นโดยใช้คีย์ดิจิทัล และเนื่องจากคีย์ถูกสร้างและสร้างโดยกระเป๋าเงิน จึงมีเพียงผู้ที่เป็นเจ้าของกระเป๋าเงินเข้ารหัสที่เป็นปัญหาเท่านั้นที่ทราบ ด้วยวิธีนี้ เราจึงรู้ว่าใครเป็นผู้เขียนข้อมูล - เพียงตรวจสอบว่าลายเซ็นนั้นสอดคล้องกับคีย์ที่เป็นเอกลักษณ์เฉพาะของเราในกระเป๋าเงินดิจิทัลส่วนตัวของเราหรือไม่
เราสามารถใช้ประโยชน์จากกระเป๋าสตางค์สกุลเงินดิจิทัลเพื่อแนบลายเซ็นลงในโพสต์ของเราได้อย่างราบรื่นและใช้งานง่าย หากคุณใช้กระเป๋าเงินดิจิทัลเพื่อเข้าสู่ระบบแพลตฟอร์มโซเชียลมีเดีย คุณสามารถใช้ประโยชน์จากฟังก์ชันการทำงานของกระเป๋าเงินเพื่อสร้างและตรวจสอบลายเซ็นบนโซเชียลมีเดียได้ ดังนั้นแพลตฟอร์มจะสามารถเตือนเราได้หากโพสต์มาจากแหล่งที่น่าสงสัย โดยจะใช้การตรวจสอบลายเซ็นอัตโนมัติเพื่อแจ้งข้อมูลที่ไม่ถูกต้อง
นอกจากนี้การเชื่อมต่อกับกระเป๋าเงินzk-KYCโครงสร้างพื้นฐานสามารถผูกกระเป๋าเงินที่ไม่รู้จักเข้ากับข้อมูลประจำตัวที่ได้รับการตรวจสอบผ่านกระบวนการ KYC โดยไม่กระทบต่อความเป็นส่วนตัวและการไม่เปิดเผยตัวตนของผู้ใช้ อย่างไรก็ตาม เนื่องจาก Deepfakes มีความซับซ้อนมากขึ้น กระบวนการ KYC อาจถูกข้าม ส่งผลให้ผู้ไม่ประสงค์ดีสามารถสร้างข้อมูลระบุตัวตนที่ไม่ระบุตัวตนที่เป็นเท็จได้ คำถามนี้สามารถตอบได้โดย Worldcoinsหลักฐานแสดงตัวตนส่วนบุคคล"(PoP)รอวิธีแก้ปัญหาที่จะเกิดขึ้น
การระบุตัวตนส่วนบุคคลเป็นกลไกที่ WorldCoin ใช้เพื่อตรวจสอบว่ากระเป๋าสตางค์เป็นของคนจริง และอนุญาตให้มีกระเป๋าสตางค์ได้เพียงใบเดียวต่อคน ในการดำเนินการนี้ จะใช้อุปกรณ์สร้างภาพไบโอเมตริก (ไอริส)Orbเพื่อตรวจสอบกระเป๋าเงิน เนื่องจากข้อมูลไบโอเมตริกซ์ยังไม่สามารถปลอมแปลงได้ การกำหนดให้บัญชีโซเชียลมีเดียเชื่อมโยงกับกระเป๋าเงิน WorldCoin ที่เป็นเอกลักษณ์จึงเป็นวิธีที่มีประสิทธิภาพในการป้องกันผู้ไม่ประสงค์ดีจากการสร้างข้อมูลระบุตัวตนที่ไม่เปิดเผยตัวตนหลายรายการเพื่อปกปิดพฤติกรรมออนไลน์ที่ไร้ศีลธรรมของพวกเขา อย่างน้อยก็จากแฮกเกอร์ จนกว่าจะพบวิธี อุปกรณ์ไบโอเมตริกซ์ปลอมแปลงสามารถแก้ปัญหา KYC แบบ deepfake ได้
3.1.3.4 สิ่งจูงใจทางเศรษฐกิจ

ผู้เขียนสามารถถูกลงโทษสำหรับการให้ข้อมูลที่ผิด และผู้ใช้สามารถได้รับรางวัลจากการระบุข้อมูลที่ผิด ตัวอย่างเช่น,"พันธบัตรความถูกต้อง"(Veracity Bonds) ช่วยให้องค์กรสื่อสามารถเดิมพันความถูกต้องของสิ่งพิมพ์ของตน และเผชิญบทลงโทษทางการเงินสำหรับข้อมูลที่ไม่ถูกต้อง สิ่งนี้ทำให้บริษัทสื่อเหล่านี้มีเหตุผลทางการเงินในการรับรองความถูกต้องของข้อมูล
พันธบัตรของแท้จะเป็น"ตลาดความจริง"เป็นส่วนสำคัญของตลาดนี้ ระบบต่างๆ แข่งขันกันเพื่อความไว้วางใจของผู้ใช้โดยการตรวจสอบความถูกต้องของเนื้อหาด้วยวิธีที่มีประสิทธิภาพและแข็งแกร่งที่สุด สิ่งนี้คล้ายกับตลาดที่พิสูจน์แล้วเช่นSuccinct Networkและ=nil Proof Marketแต่สำหรับปัญหาการตรวจสอบความถูกต้องที่ยากขึ้น
การเข้ารหัสเพียงอย่างเดียวไม่เพียงพอ สัญญาอัจฉริยะสามารถใช้เป็นวิธีการบังคับใช้สิ่งจูงใจทางเศรษฐกิจที่จำเป็นในการทำให้ ตลาดความจริง เหล่านี้ทำงานได้ ดังนั้นเทคโนโลยีบล็อกเชนอาจมีบทบาทสำคัญในการช่วยต่อสู้กับข้อมูลที่บิดเบือน
3.1.3.5 คะแนนชื่อเสียง

เราสามารถใช้ชื่อเสียงเพื่อแสดงความน่าเชื่อถือได้ ตัวอย่างเช่น เราสามารถดูจำนวนผู้ติดตามบน Twitter เพื่อดูว่าเราควรเชื่อสิ่งที่เขาหรือเธอพูดหรือไม่ อย่างไรก็ตาม ระบบชื่อเสียงควรพิจารณาถึงผลงานของผู้เขียนแต่ละคน ไม่ใช่แค่ความนิยมเท่านั้น เราไม่อยากสับสนระหว่างความน่าเชื่อถือกับความนิยม
เราไม่สามารถอนุญาตให้ผู้คนสร้างข้อมูลระบุตัวตนที่ไม่เปิดเผยตัวตนได้ไม่จำกัดจำนวน มิฉะนั้น พวกเขาสามารถละทิ้งข้อมูลระบุตัวตนเพื่อรีเซ็ตความน่าเชื่อถือทางสังคมเมื่อชื่อเสียงของพวกเขาได้รับความเสียหาย สิ่งนี้กำหนดให้เราต้องใช้ข้อมูลระบุตัวตนดิจิทัลที่ไม่สามารถคัดลอกได้ ตามที่อธิบายไว้ในส่วนก่อนหน้า
เรายังสามารถใช้ได้"ตลาดความจริง"และ"การรับรองฮาร์ดแวร์"หลักฐานในการตัดสินชื่อเสียงของบุคคล เนื่องจากเป็นวิธีการที่เชื่อถือได้ในการติดตามบันทึกที่แท้จริงของพวกเขา ระบบชื่อเสียงเป็นจุดสุดยอดของโซลูชันอื่นๆ ทั้งหมดที่กล่าวถึงจนถึงขณะนี้ จึงเป็นแนวทางที่มีประสิทธิภาพและครอบคลุมที่สุด

รูปที่ 16: มัสก์บอกเป็นนัยถึงการสร้างเว็บไซต์ในปี 2018 ที่จะให้คะแนนความน่าเชื่อถือสำหรับบทความในวารสาร บรรณาธิการ และสิ่งตีพิมพ์
3.1.4 โซลูชันการเข้ารหัสสามารถปรับขนาดได้หรือไม่
โซลูชันบล็อกเชนที่อธิบายไว้ข้างต้นต้องการบล็อกเชนที่รวดเร็วและจัดเก็บข้อมูลสูง ไม่เช่นนั้น เราจะไม่สามารถรวมรูปภาพทั้งหมดไว้ในบันทึกเวลาที่ตรวจสอบได้ทางออนไลน์ สิ่งนี้กำลังมีความสำคัญมากขึ้นเท่านั้นเนื่องจากปริมาณข้อมูลที่เผยแพร่ทางออนไลน์ทุกวันเพิ่มขึ้นอย่างทวีคูณ อย่างไรก็ตามก็มีอยู่บ้างอัลกอริทึมก็ได้ในลักษณะที่ยังคงตรวจสอบได้บีบอัดข้อมูล
นอกจากนี้ ลายเซ็นที่สร้างผ่านการรับรองความถูกต้องด้วยฮาร์ดแวร์ไม่สามารถใช้ได้กับรูปภาพเวอร์ชันแก้ไข: ต้องสร้างหลักฐานการแก้ไขโดยใช้ zk-SNARKZK Microphoneเป็นการใช้งานเสียงที่ได้รับการรับรองจากบรรณาธิการ 4
3.1.5 Deepfakes ไม่ได้แย่โดยเนื้อแท้
สิ่งสำคัญคือต้องยอมรับว่าไม่ใช่ว่า Deepfake ทั้งหมดจะเป็นอันตราย เทคโนโลยีนี้ยังมีประโยชน์โดยบริสุทธิ์ใจ เช่นนี้วิดีโอที่สร้างโดย AI ของ Taylor Swift การสอนคณิตศาสตร์. เนื่องจากต้นทุนต่ำและการเข้าถึง Deepfakes ได้ต่ำ ประสบการณ์ส่วนบุคคลจึงถูกสร้างขึ้น ตัวอย่างเช่น,HeyGenอนุญาตให้ผู้ใช้ส่งข้อความส่วนตัวด้วยใบหน้าที่สร้างโดย AI ซึ่งดูเหมือนใบหน้าของคุณ. การจำลองเชิงลึกยังแปลผ่านการพากย์อีกด้วยเชื่อมช่องว่างทางภาษา

3.1.5.1 วิธีการควบคุมและสร้างรายได้จากการปลอมแปลงอย่างลึกซึ้ง
บริการคู่กันของ AI ที่ใช้เทคโนโลยี Deepfake เรียกเก็บค่าธรรมเนียมสูงและขาดความรับผิดชอบและการกำกับดูแล Amouranth ผู้มีอิทธิพลอันดับต้นๆ ของ OnlyFans ได้โพสต์อวตารดิจิทัลของตัวเองเพื่อให้แฟนๆ สามารถแชทกับเธอเป็นการส่วนตัวได้ สตาร์ทอัพเหล่านี้สามารถจำกัดหรือปิดการเข้าถึงได้ เช่นบริการคู่หู AI ที่เรียกว่า Soulmate。
ด้วยการโฮสต์โมเดล AI แบบออนไลน์ เราสามารถใช้สัญญาอัจฉริยะเพื่อจัดหาเงินทุนและควบคุมโมเดลในลักษณะที่โปร่งใส สิ่งนี้จะช่วยให้มั่นใจได้ว่าผู้ใช้จะไม่สูญเสียการเข้าถึงโมเดลของตน และช่วยให้ผู้สร้างโมเดลกระจายผลกำไรให้กับผู้ร่วมให้ข้อมูลและนักลงทุน อย่างไรก็ตาม ยังมีความท้าทายทางเทคนิคอยู่ เทคโนโลยีที่ได้รับความนิยมมากที่สุดสำหรับการนำโมเดลออนไลน์ไปใช้ zkML (ใช้โดย Giza, Modulus Labs และ EZKL) จะทำให้โมเดลทำงานได้ช้าลง 1,000 เท่า. อย่างไรก็ตาม การวิจัยในสาขาย่อยนี้ยังคงดำเนินต่อไป และเทคโนโลยีก็มีการพัฒนาอย่างต่อเนื่อง ตัวอย่างเช่น,HyperOracleกำลังลองใช้ครับopML,Aizelโซลูชันกำลังถูกสร้างขึ้นโดยอิงจาก Multi-Party Computation (MPC) และ Trusted Execution Environment (TEE)
3.1.6 สรุปบท
Deepfakes ที่มีความซับซ้อนกำลังทำลายความไว้วางใจในการเมือง การเงิน และโซเชียลมีเดีย โดยเน้นที่"เครือข่ายที่สามารถตรวจสอบได้"เพื่อรักษาความจำเป็นของความจริงและความสมบูรณ์ของประชาธิปไตย
Deepfakes ครั้งหนึ่งเคยเป็นความพยายามที่มีราคาแพงและใช้เทคโนโลยีมาก แต่ความก้าวหน้าในด้านปัญญาประดิษฐ์ทำให้ง่ายต่อการสร้าง โดยเปลี่ยนภูมิทัศน์ของข้อมูลที่บิดเบือน
4 หากสนใจเรื่องนี้ โปรดติดต่ออัลเบียน.
ประวัติศาสตร์บอกเราว่าการจัดการสื่อไม่ใช่ความท้าทายใหม่ แต่ปัญญาประดิษฐ์ทำให้การสร้างข่าวปลอมที่น่าเชื่อง่ายขึ้นและราคาถูกกว่า ดังนั้นจึงจำเป็นต้องมีวิธีแก้ปัญหาใหม่
การฉ้อโกงผ่านวิดีโอก่อให้เกิดอันตรายเป็นพิเศษ เพราะพวกเขาประนีประนอมหลักฐานที่ก่อนหน้านี้ถือว่าเชื่อถือได้ ส่งผลให้สังคมเข้าสู่ภาวะที่กลืนไม่เข้าคายไม่ออกที่พฤติกรรมที่แท้จริงอาจถูกมองว่าเป็นพฤติกรรมปลอม
มาตรการรับมือที่มีอยู่แบ่งออกเป็นแนวทางการรับรู้ แพลตฟอร์ม นโยบาย และเทคโนโลยี ซึ่งแต่ละแนวทางเผชิญกับความท้าทายในการต่อสู้กับ Deepfake อย่างมีประสิทธิภาพ
การพิสูจน์ฮาร์ดแวร์และบล็อกเชนมอบโซลูชันที่น่าหวังโดยการพิสูจน์ที่มาของแต่ละภาพ และสร้างบันทึกการแก้ไขที่โปร่งใสและไม่เปลี่ยนรูป
กระเป๋าเงิน Cryptocurrency และ zk-KYC ปรับปรุงการตรวจสอบและรับรองความถูกต้องของเนื้อหาออนไลน์ ในขณะที่ระบบชื่อเสียงออนไลน์และสิ่งจูงใจทางเศรษฐกิจ เช่น"พันธบัตรความถูกต้อง") จัดให้มีตลาดสำหรับความจริง
ในขณะที่รับทราบถึงการใช้งานเชิงบวกของ Deepfakes นั้น Crypto ยังเสนอวิธีในการอนุญาต Deepfakes ที่เป็นประโยชน์ ดังนั้นจึงสร้างความสมดุลระหว่างนวัตกรรมและความซื่อสัตย์
3.2 บทเรียนอันขมขื่น

ข้อความนี้ขัดกับสัญชาตญาณ แต่เป็นความจริง ชุมชน AI ปฏิเสธแนวคิดที่ว่าแนวทางที่กำหนดเองนั้นมีประสิทธิภาพน้อยกว่า แต่"บทเรียนอันขมขื่น"ยังคงใช้อยู่: การใช้พลังการประมวลผลส่วนใหญ่จะให้ผลลัพธ์ที่ดีที่สุดเสมอ
เราต้องขยายขนาด: เพิ่ม GPU, ศูนย์ข้อมูลมากขึ้น, ข้อมูลการฝึกอบรมมากขึ้น
นักวิจัยหมากรุกคอมพิวเตอร์พยายามใช้ประสบการณ์ของผู้เล่นที่เป็นมนุษย์ชั้นนำเพื่อสร้างกลไกหมากรุก และนี่คือตัวอย่างจุดที่นักวิจัยเข้าใจผิด โปรแกรมหมากรุกชุดแรกคัดลอกกลยุทธ์การเปิดของมนุษย์ (โดยใช้"เปิดหนังสือ"). นักวิจัยหวังว่ากลไกหมากรุกสามารถเริ่มต้นจากตำแหน่งที่แข็งแกร่งโดยไม่ต้องคำนวณการเคลื่อนไหวที่ดีที่สุดตั้งแต่เริ่มต้น พวกเขายังมีอีกมากมาย"การวิเคราะห์พฤติกรรมทางยุทธวิธี"-กลยุทธ์ที่ผู้เล่นหมากรุกมนุษย์ใช้ เช่น ส้อม พูดง่ายๆ ก็คือ โปรแกรมหมากรุกสร้างขึ้นจากความเข้าใจของมนุษย์เกี่ยวกับวิธีการเล่นหมากรุกให้ประสบความสำเร็จ มากกว่าวิธีการคำนวณทั่วไป
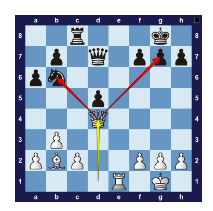
รูปที่ 18: ส้อม - ควีนโจมตีสองชิ้น

รูปที่ 19: ตัวอย่างลำดับการเปิดหมากรุก
ในปี 1997 DeepBlue ของ IBM ได้รวมพลังการประมวลผลจำนวนมหาศาลเข้ากับเทคโนโลยีการค้นหาเพื่อเอาชนะแชมป์หมากรุกโลก แม้ว่า DeepBlue จะมีประสิทธิภาพเหนือกว่าทั้งหมด"การออกแบบของมนุษย์"กลไกหมากรุก แต่นักวิจัยหมากรุกหลีกเลี่ยงมัน พวกเขาแย้งว่าความสำเร็จของ DeepBlue นั้นอยู่ได้ไม่นาน เนื่องจากไม่ได้ใช้กลยุทธ์หมากรุก ซึ่งเป็นวิธีแก้ปัญหาที่หยาบคายในมุมมองของพวกเขา ผิด: ในระยะยาว โซลูชันที่ใช้การคำนวณจำนวนมากกับปัญหาทั่วไปมักจะให้ผลลัพธ์ที่ดีกว่าโซลูชันที่ทำเอง อุดมการณ์คอมพิวเตอร์ชั้นสูงนี้
เกิดขึ้นได้สำเร็จไปเครื่องยนต์ (AlphaGo)เทคโนโลยีการรู้จำคำพูดที่ได้รับการปรับปรุง และเทคโนโลยีการมองเห็นคอมพิวเตอร์ที่เชื่อถือได้มากขึ้น
ความสำเร็จล่าสุดในวิธี AI ที่มีการคำนวณสูงคือ ChatGPT ของ OpenAI ต่างจากความพยายามครั้งก่อน OpenAI ไม่ได้พยายามเข้ารหัสความเข้าใจของมนุษย์เกี่ยวกับวิธีการทำงานของภาษาในซอฟต์แวร์ แต่โมเดลของพวกเขากลับรวมข้อมูลจำนวนมหาศาลจากอินเทอร์เน็ตเข้ากับคอมพิวเตอร์ขนาดใหญ่ ต่างจากนักวิจัยคนอื่นๆ ตรงที่พวกเขาไม่ได้แทรกแซงหรือฝังอคติใดๆ ไว้ในซอฟต์แวร์ ในระยะยาว แนวทางที่มีประสิทธิภาพดีที่สุดจะขึ้นอยู่กับวิธีการทั่วไปที่ใช้ประโยชน์จากการคำนวณจำนวนมาก นี่เป็นข้อเท็จจริงทางประวัติศาสตร์ อันที่จริง เราอาจมีหลักฐานเพียงพอที่จะพิสูจน์ว่าสิ่งนี้เป็นจริงตลอดไป
การรวมพลังการประมวลผลมหาศาลเข้ากับข้อมูลจำนวนมหาศาลเป็นแนวทางที่ดีที่สุดในระยะยาว และเหตุผลก็คือกฎของมัวร์: ค่าใช้จ่ายในการคำนวณจะลดลงทวีคูณเมื่อเวลาผ่านไป ในระยะสั้น เราอาจไม่แน่ใจว่าแบนด์วิธการประมวลผลเพิ่มขึ้นอย่างมีนัยสำคัญ ซึ่งอาจส่งผลให้นักวิจัยพยายามปรับปรุงเทคนิคของตนโดยการฝังความรู้และอัลกอริทึมของมนุษย์ลงในซอฟต์แวร์ด้วยตนเอง วิธีนี้อาจใช้ได้ระยะหนึ่ง แต่จะไม่ประสบความสำเร็จในระยะยาว การฝังความรู้ของมนุษย์ลงในซอฟต์แวร์พื้นฐานทำให้ซอฟต์แวร์มีความซับซ้อนมากขึ้นและโมเดลไม่สามารถปรับปรุงด้วยพลังการประมวลผลเพิ่มเติมได้ สิ่งนี้ทำให้แนวทางประดิษฐ์มีสายตาสั้น ดังนั้น Sutton จึงแนะนำให้เราเพิกเฉยต่อเทคนิคประดิษฐ์และมุ่งเน้นที่การใช้พลังการประมวลผลมากขึ้นกับเทคนิคการคำนวณทั่วไป
บทเรียนอันขมขื่น มีผลกระทบอย่างมากต่อวิธีที่เราควรสร้างปัญญาประดิษฐ์แบบกระจายอำนาจ:
สร้างเครือข่ายขนาดใหญ่: บทเรียนที่เรียนรู้ข้างต้นเน้นย้ำถึงความเร่งด่วนในการพัฒนาโมเดล AI ขนาดใหญ่ และรวบรวมทรัพยากรการประมวลผลขนาดใหญ่เพื่อฝึกฝนโมเดลเหล่านั้น สิ่งเหล่านี้เป็นขั้นตอนสำคัญในการเข้าสู่อาณาจักรใหม่ของปัญญาประดิษฐ์Akash、GPUNetและIoNetบริษัทต่างๆ เช่น Alibaba Cloud มุ่งมั่นที่จะจัดหาโครงสร้างพื้นฐานที่ปรับขนาดได้
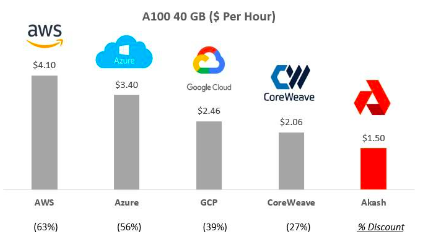
รูปที่ 20: การเปรียบเทียบราคา Akash กับผู้ให้บริการรายอื่น เช่น Amazon AWS
นวัตกรรมฮาร์ดแวร์: วิธี ZKML ได้รับการวิพากษ์วิจารณ์เนื่องจากทำงานช้ากว่าวิธีที่ไม่ใช่ ZKML ถึง 1,000 เท่า สิ่งนี้สะท้อนถึงคำวิจารณ์ที่โครงข่ายประสาทเทียมต้องเผชิญ ในช่วงทศวรรษ 1990 โครงข่ายประสาทเทียมแสดงให้เห็นสัญญาณที่ดี โมเดล CNN ของ Yann LeCun ซึ่งเป็นโครงข่ายประสาทเทียมขนาดเล็ก สามารถจำแนกรูปภาพตัวเลขที่เขียนด้วยลายมือได้สำเร็จ (ดูภาพด้านล่าง) ภายในปี 1998 ธนาคารมากกว่า 10% ในสหรัฐอเมริกาใช้เทคโนโลยีนี้เพื่ออ่านเช็ค อย่างไรก็ตาม โมเดล CNN เหล่านี้ไม่ได้ปรับขนาด ดังนั้นความสนใจในโครงข่ายประสาทเทียมเหล่านี้จึงลดลง และนักวิจัยด้านคอมพิวเตอร์วิทัศน์หันมาใช้ความรู้ของมนุษย์เพื่อสร้างระบบที่ดีขึ้น ในปี 2012 นักวิจัยได้พัฒนา CNN ใหม่โดยใช้ประโยชน์จากประสิทธิภาพการคำนวณของ GPU ซึ่งเป็นฮาร์ดแวร์ยอดนิยมที่ใช้กันทั่วไปในการสร้างคอมพิวเตอร์กราฟิก (เกม CGI ฯลฯ) สิ่งนี้ทำให้พวกเขาได้รับประสิทธิภาพที่น่าทึ่ง เกินกว่าการเอาชนะอื่นๆ ทั้งหมด วิธีการที่ใช้ได้ในขณะนั้น เครือข่ายนี้เรียกว่า AlexNet และจุดประกายให้เกิดการปฏิวัติการเรียนรู้เชิงลึก

รูปที่ 22: โครงข่ายประสาทเทียมจากทศวรรษ 1990 สามารถประมวลผลได้เฉพาะภาพดิจิทัลที่มีความละเอียดต่ำเท่านั้น

รูปที่ 23: AlexNet (2012) สามารถจัดการรูปภาพที่ซับซ้อนและเหนือกว่าวิธีการอื่นทั้งหมด
การอัพเกรดเทคโนโลยีปัญญาประดิษฐ์เป็นสิ่งที่หลีกเลี่ยงไม่ได้ เนื่องจากต้นทุนการประมวลผลมักจะลดลงเรื่อยๆ ฮาร์ดแวร์แบบกำหนดเองสำหรับเทคโนโลยีเช่น ZK และ FHE จะช่วยเร่งความก้าวหน้า -Ingonyamaบริษัทและสถาบันการศึกษากำลังปูทาง ในระยะยาว เราจะบรรลุ ZKML ขนาดใหญ่โดยการใช้พลังการประมวลผลที่มากขึ้นและปรับปรุงประสิทธิภาพ คำถามเดียวก็คือ เราจะใช้ประโยชน์จากเทคโนโลยีเหล่านี้ได้อย่างไร

รูปที่ 24: ตัวอย่างความก้าวหน้าของฮาร์ดแวร์ตัวพิสูจน์ ZK(แหล่งที่มา)
การปรับขนาดข้อมูล: เนื่องจากโมเดล AI มีขนาดและความซับซ้อนเพิ่มขึ้น จึงจำเป็นต้องปรับขนาดชุดข้อมูลให้สอดคล้องกัน โดยทั่วไป ขนาดของชุดข้อมูลควรเพิ่มขึ้นแบบทวีคูณตามขนาดโมเดล เพื่อป้องกันไม่ให้มีการติดตั้งมากเกินไปและรับประกันประสิทธิภาพที่มั่นคง สำหรับโมเดลที่มีพารามิเตอร์นับพันล้าน มักจะหมายถึงการดูแลชุดข้อมูลที่มีโทเค็นหรือตัวอย่างหลายพันล้านรายการ ตัวอย่างเช่น โมเดล BERT ของ Google ได้รับการฝึกอบรมเกี่ยวกับวิกิพีเดียภาษาอังกฤษทั้งหมดซึ่งมีมากกว่า 2.5 พันล้านคำ และ BooksCorpus ซึ่งมีประมาณ 800 ล้านคำ LLama ของ Meta ได้รับการฝึกฝนเกี่ยวกับคลังคำศัพท์ 1.4 ล้านล้านคำ ตัวเลขเหล่านี้เน้นย้ำถึงขนาดของชุดข้อมูลที่เราต้องการ ซึ่งจะต้องเพิ่มขึ้นอีกเมื่อแบบจำลองเคลื่อนไปสู่พารามิเตอร์นับล้านล้าน ส่วนขยายนี้ช่วยให้มั่นใจได้ว่าโมเดลจะจับความแตกต่างและความหลากหลายของภาษามนุษย์ ดังนั้นการพัฒนาชุดข้อมูลขนาดใหญ่และมีคุณภาพสูงจึงมีความสำคัญพอๆ กับนวัตกรรมทางสถาปัตยกรรมในตัวโมเดลเอง บริษัทต่างๆ เช่น Giza, Bittensor, Bagel และ FractionAI กำลังจัดการกับความต้องการเฉพาะในด้านนี้ (ดูบทที่ 5 สำหรับรายละเอียดเกี่ยวกับความท้าทายในโดเมนข้อมูล เช่น การล่มสลายของโมเดล การโจมตีของฝ่ายตรงข้าม และความท้าทายในการประกันคุณภาพ)
พัฒนาแนวทางทั่วไป: ในด้านการกระจายอำนาจของ AI เทคโนโลยี เช่น ZKP และ FHE นำแนวทางเฉพาะแอปพลิเคชันมาใช้เพื่อแสวงหาประสิทธิภาพในทันที การปรับแต่งโซลูชันสำหรับสถาปัตยกรรมเฉพาะสามารถปรับปรุงประสิทธิภาพได้ แต่อาจจำกัดวิวัฒนาการของระบบในวงกว้าง โดยแลกกับความยืดหยุ่นและความสามารถในการปรับขนาดในระยะยาว การมุ่งเน้นไปที่แนวทางทั่วไปกลับเป็นรากฐานที่แม้จะไร้ประสิทธิภาพในช่วงแรก แต่ก็ยังสามารถปรับขนาดได้และสามารถปรับให้เข้ากับการใช้งานที่หลากหลายและการพัฒนาในอนาคตได้ เมื่อพลังการประมวลผลเพิ่มขึ้นและต้นทุนลดลง โดยได้รับแรงหนุนจากแนวโน้มต่างๆ เช่น กฎของมัวร์ วิธีการเหล่านี้ก็เริ่มมีแนวโน้มเริ่มต้นขึ้น การเลือกระหว่างประสิทธิภาพระยะสั้นและความสามารถในการปรับตัวในระยะยาวถือเป็นสิ่งสำคัญ การเน้นย้ำแนวทางทั่วไปสามารถเตรียมอนาคตของ AI แบบกระจายอำนาจให้เป็นระบบที่แข็งแกร่งและยืดหยุ่น ซึ่งใช้ประโยชน์จากความก้าวหน้าทางเทคโนโลยีคอมพิวเตอร์อย่างเต็มที่ เพื่อให้มั่นใจถึงความสำเร็จและความเกี่ยวข้องที่ยั่งยืน
3.2.1 บทสรุป
ในระยะแรกของการพัฒนาผลิตภัณฑ์เลือกแนวทางที่ไม่จำกัดขนาดอาจมีความสำคัญ นี่เป็นสิ่งสำคัญสำหรับทั้งบริษัทและนักวิจัยในการประเมินกรณีการใช้งานและแนวคิด อย่างไรก็ตาม บทเรียนที่หนักหน่วงได้สอนเราว่าในระยะยาว เราควรคำนึงถึงความพึงพอใจสำหรับแนวทางทั่วไปที่ปรับขนาดได้เสมอ
ต่อไปนี้เป็นตัวอย่างของวิธีการแบบแมนนวลที่ถูกแทนที่ด้วยการสร้างความแตกต่างแบบอัตโนมัติสำหรับวัตถุประสงค์ทั่วไป: ก่อนที่จะใช้ไลบรารีการสร้างความแตกต่างแบบอัตโนมัติ (autodiff) เช่น TensorFlow และ PyTorch การไล่ระดับสีมักจะคำนวณโดยการสร้างความแตกต่างแบบแมนนวลหรือแบบตัวเลข ซึ่งเป็นวิธีการที่ไม่มีประสิทธิภาพและเกิดข้อผิดพลาดได้ง่าย และ สามารถสร้างปัญหาและเสียเวลานักวิจัยได้ ไม่เหมือนการสร้างความแตกต่างโดยอัตโนมัติ Autodiff ได้กลายเป็นเครื่องมือที่ขาดไม่ได้ในปัจจุบัน เนื่องจากไลบรารี autodiff ช่วยเร่งการทดลองและทำให้การพัฒนาแบบจำลองง่ายขึ้น ดังนั้นโซลูชันทั่วไปจึงชนะ - แต่จนกว่า autodiff จะกลายเป็นโซลูชันที่สมบูรณ์และใช้งานได้ วิธีการแบบแมนนวลแบบเก่าจึงเป็นสิ่งจำเป็นสำหรับการทำวิจัย ML
อย่างไรก็ตาม Rich Suttons"บทเรียนอันขมขื่น"บอกเราว่าถ้าเราสามารถเพิ่มพลังการประมวลผลของปัญญาประดิษฐ์ให้สูงสุด แทนที่จะพยายามทำให้ปัญญาประดิษฐ์เลียนแบบวิธีการที่มนุษย์รู้จัก ปัญญาประดิษฐ์ก็จะก้าวหน้าเร็วขึ้น เราต้องขยายพลังการประมวลผลที่มีอยู่ ขยายข้อมูล สร้างสรรค์ฮาร์ดแวร์ และพัฒนาวิธีการที่เป็นสากล การนำแนวทางนี้มาใช้จะมีผลกระทบมากมายสำหรับสาขา AI แบบกระจายอำนาจ แม้ว่า"บทเรียนอันขมขื่น"ใช้ไม่ได้ในระยะเริ่มแรกของการวิจัย แต่อาจเป็นจริงได้เสมอในระยะยาว
3.3 ตัวแทน AI (ตัวแทนปัญญาประดิษฐ์) จะล้มล้าง Google และ Amazon
3.3.1 ปัญหาการผูกขาดของ Google
ผู้สร้างเนื้อหาออนไลน์มักจะพึ่งพา Google ในการเผยแพร่เนื้อหาของตน ในทางกลับกัน หาก Google ได้รับอนุญาตให้จัดทำดัชนีและแสดงผลงานของตน พวกเขาก็จะได้รับกระแสความสนใจและรายได้จากการโฆษณาอย่างต่อเนื่อง อย่างไรก็ตาม ความสัมพันธ์ไม่เท่ากัน Google มีการผูกขาด (มากกว่า 80% ของปริมาณการใช้เครื่องมือค้นหา) และมีส่วนแบ่งการตลาดที่ผู้สร้างเนื้อหาไม่สามารถจับคู่ได้ เป็นผลให้ผู้สร้างเนื้อหาพึ่งพา Google และยักษ์ใหญ่ด้านเทคโนโลยีอื่น ๆ เป็นอย่างมากเพื่อหารายได้ การตัดสินใจครั้งหนึ่งจาก Google อาจเป็นจุดสิ้นสุดของธุรกิจของแต่ละบุคคล
การเปิดตัวคุณลักษณะ Featured Snippets ของ Google ซึ่งแสดงคำตอบสำหรับคำถามของผู้ใช้โดยไม่ต้องคลิกผ่านไปยังเว็บไซต์เดิม เป็นการเน้นย้ำถึงปัญหาดังกล่าว เนื่องจากขณะนี้สามารถรับข้อมูลได้โดยไม่ต้องออกจากเครื่องมือค้นหา สิ่งนี้ขัดขวางกฎเกณฑ์ที่ผู้สร้างเนื้อหาประสบความสำเร็จ เพื่อแลกกับการที่ Google จัดทำดัชนีเนื้อหา ผู้สร้างเนื้อหาหวังว่าเว็บไซต์ของตนจะได้รับการเข้าชมจากการอ้างอิงและสายตา แต่คุณลักษณะตัวอย่างข้อมูลแนะนำช่วยให้ Google สามารถสรุปเนื้อหาโดยไม่รวมผู้สร้างจากการเข้าชม ลักษณะที่กระจัดกระจายของผู้ผลิตเนื้อหาทำให้พวกเขาไม่มีอำนาจในการดำเนินการร่วมกันกับการตัดสินใจของ Google หากไม่มีเสียงที่เป็นเอกภาพ เว็บไซต์แต่ละแห่งก็ขาดอำนาจในการต่อรอง
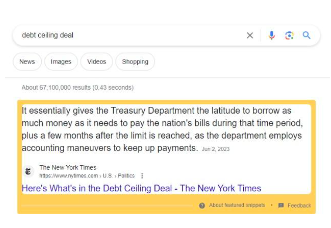
รูปที่ 25: ตัวอย่างฟังก์ชัน Featured Snippets
Google ทดลองเพิ่มเติมโดยจัดทำรายการแหล่งที่มาสำหรับคำตอบสำหรับคำถามของผู้ใช้ตัวอย่างด้านล่างมีแหล่งข้อมูลจาก The New York Times, Wikipedia, MLB.com และอื่นๆ เนื่องจาก Google ให้คำตอบโดยตรง ไซต์เหล่านี้จึงไม่ได้รับการเข้าชมมากนัก
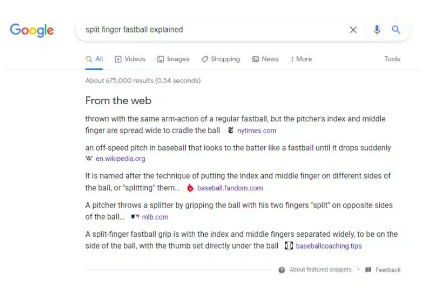
รูปที่ 26:"จากเว็บ"ตัวอย่างฟังก์ชั่น
3.3.2 ปัญหาการผูกขาดของ OpenAI
คุณลักษณะตัวอย่างข้อมูลแนะนำของ Google แสดงถึงความกังวล


