
ความสามารถในการปรับขนาดที่มีจำหน่าย: เส้นทางข้างหน้า

พร้อมใช้งาน testnet แล้ว เมื่อผู้ใช้เริ่มรวม Avail เข้ากับการออกแบบลูกโซ่ของตน คำถามที่มักเกิดขึ้นคือ: Avail สามารถจัดการธุรกรรมได้จำนวนเท่าใด นี่เป็นบทความสุดท้ายในซีรีส์เกี่ยวกับความสามารถในการขยายขนาด และจะหารือเกี่ยวกับประสิทธิภาพในปัจจุบันของ Avail ตลอดจนระยะสั้น และความสามารถในการขยายขนาดในระยะยาว คุณสามารถอ่านส่วนที่หนึ่งได้ที่นี่ และส่วนที่สองที่นี่
แบบจำลองด้านล่างอธิบายสถาปัตยกรรมที่การดำเนินการของการเสนอและบล็อคส่วนประกอบ (การตัดสินใจว่าจะรวมธุรกรรม/บล็อคข้อมูลใดไว้ในบล็อค) จะถูกแยกและดำเนินการโดยผู้ดำเนินการที่แตกต่างกัน
ด้วยการสร้างเอนทิตีตัวสร้างบล็อกใหม่นี้ งานการคำนวณที่จำเป็นในการสร้างข้อผูกพันแถวและสร้างการพิสูจน์เซลล์สามารถแบ่งปันระหว่างผู้เข้าร่วมที่แตกต่างกันได้
ฟังก์ชันหลักของ Avail คือการรับข้อมูลและข้อมูลที่เรียงลำดับเอาต์พุต คิดว่ามันเหมือนกับ API Avail ช่วยให้ทุกคนสามารถสุ่มตัวอย่างความพร้อมใช้งานของข้อมูลได้
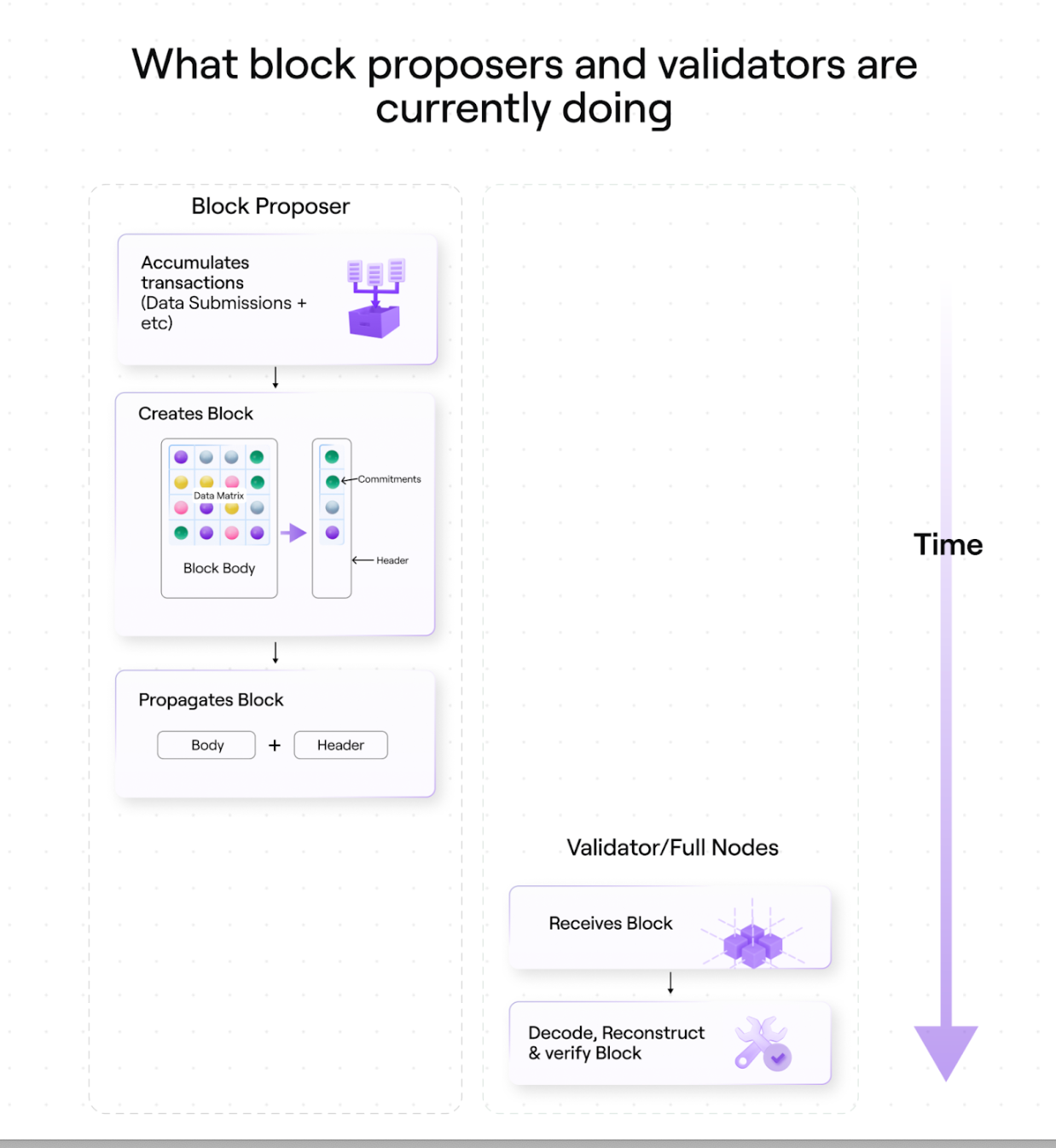
ก่อนที่จะเน้นย้ำถึงจุดที่เราสามารถปรับปรุงได้ อันดับแรกเราจะให้รายละเอียดข้อกำหนดของ Avail สำหรับผู้เสนอบล็อกและผู้ตรวจสอบ/โหนดแบบเต็มในสถานะปัจจุบัน
1. ผู้ผลิตบล็อกสร้างเนื้อหาบล็อก
รวบรวมธุรกรรม (ส่งข้อมูล)
จัดเรียงธุรกรรมเหล่านี้ลงในเมทริกซ์ข้อมูล Avail ซึ่งจะกลายเป็นเนื้อหาบล็อก
2. ผู้ผลิตบล็อกสร้างส่วนหัวของบล็อก
สร้างสัญญาสำหรับแต่ละแถวของเมทริกซ์
ขยายข้อผูกพันเหล่านี้โดยใช้การแก้ไขพหุนาม (ข้อผูกพันที่สร้างขึ้นและขยายกลายเป็นส่วนหัวของบล็อก)
3. ผู้ผลิตบล็อกเผยแพร่บล็อก (เนื้อหา + ส่วนหัว)
4. ผู้ตรวจสอบความถูกต้องและโหนดเต็มจะได้รับบล็อก
5. เครื่องมือตรวจสอบและโหนดเต็มรูปแบบถอดรหัส สร้างใหม่ และตรวจสอบบล็อก
สร้างเมทริกซ์ข้อมูลขึ้นมาใหม่
การสร้างพันธสัญญาใหม่
ความมุ่งมั่นขยาย
ตรวจสอบว่าข้อมูลทั้งหมดที่พวกเขาได้รับตรงกับคำสัญญาที่พวกเขาสร้างขึ้น
ขั้นตอนที่ห้า ซึ่งกำหนดให้โหนดเต็มรูปแบบสร้างส่วนหัวของบล็อกใหม่นั้นไม่จำเป็นในระบบเช่น Avail
โหนดเต็มรูปแบบในปัจจุบันทำเช่นนี้เนื่องจาก Avail สืบทอดสถาปัตยกรรมของบล็อกเชนแบบดั้งเดิม ซึ่งต้องมีผู้ตรวจสอบความถูกต้องเพื่อยืนยันว่าการดำเนินการดำเนินการเสร็จสมบูรณ์อย่างถูกต้อง Avail ไม่จัดการการดำเนินการดำเนินการ ผู้เสนอบล็อก ผู้ตรวจสอบ และไคลเอนต์แบบ light ให้ความสำคัญกับความพร้อมใช้งานของข้อมูลเท่านั้น ซึ่งหมายความว่าผู้เข้าร่วมทั้งหมดในเครือข่าย Avail สามารถเลือกใช้การสุ่มตัวอย่างความพร้อมใช้งานของข้อมูลเพื่อยืนยันความพร้อมใช้งานของข้อมูลได้อย่างน่าเชื่อถือ
เนื่องจากเครื่องมือตรวจสอบและโหนดเต็มรูปแบบสามารถตรวจสอบความพร้อมใช้งานของข้อมูลผ่านการสุ่มตัวอย่าง พวกเขาจึงไม่จำเป็นต้องสร้างบล็อกทั้งหมดใหม่เพื่อให้มั่นใจในความปลอดภัยของเครือข่าย
ผู้ตรวจสอบไม่จำเป็นต้องทำซ้ำทุกอย่างที่โปรดิวเซอร์ทำเพื่อตรวจสอบว่าทุกอย่างถูกต้องหรือไม่ แต่สามารถตรวจสอบได้ด้วยการสุ่มตัวอย่างในปริมาณเล็กน้อย เช่นเดียวกับไคลเอนต์แบบ light เมื่อถึงการรับประกันทางสถิติของความพร้อมใช้งานของข้อมูล (หลังจาก 8 - 30 ตัวอย่าง) ผู้ตรวจสอบความถูกต้องสามารถเพิ่มบล็อกลงในห่วงโซ่ได้ เนื่องจาก Avail ไม่ได้จัดการการดำเนินการข้อมูล การดำเนินการนี้จึงสามารถดำเนินการได้อย่างปลอดภัย
การสุ่มตัวอย่างข้อมูลทำให้ผู้ตรวจสอบมีทางเลือกที่รวดเร็วกว่ามากเมื่อเทียบกับกระบวนการตรวจสอบแบบ 1:1 ที่ยุ่งยาก ความมหัศจรรย์ของ Avail คือการใช้เฉพาะส่วนหัวของบล็อก ทุกคน (ในกรณีนี้คือผู้ตรวจสอบความถูกต้อง) สามารถเข้าถึงฉันทามติว่าพวกเขาติดตามห่วงโซ่ที่ถูกต้อง
หากเราสามารถทำได้ เราก็สามารถเปลี่ยนขั้นตอนการสร้างส่วนหัวของบล็อกใหม่ทั้งหมดด้วยตัวอย่างบางส่วนได้
บทความนี้จะสำรวจการเปลี่ยนแปลงข้อกำหนดของเราสำหรับผู้ตรวจสอบ รวมถึงการปรับปรุงอื่นๆ เราจะอธิบายระบบที่ได้รับการปรับปรุงซึ่งผู้เสนอบล็อก (ยังคง) สร้างและเผยแพร่บล็อก แต่ผู้เข้าร่วมเครือข่ายอื่นๆ ทั้งหมดโต้ตอบกับเครือข่ายผ่านการสุ่มตัวอย่างความพร้อมของข้อมูล จากนั้นเราจะแนะนำระบบเพิ่มเติมที่แยกการก่อสร้างบล็อกและข้อเสนอบล็อก ซึ่งดำเนินการโดยผู้เข้าร่วมเครือข่ายสองคนที่แตกต่างกัน
สิ่งสำคัญที่ควรทราบคือการเปลี่ยนแปลงเหล่านี้ค่อนข้างก้าวหน้าและยังอยู่ระหว่างการวิจัยเชิงรุก
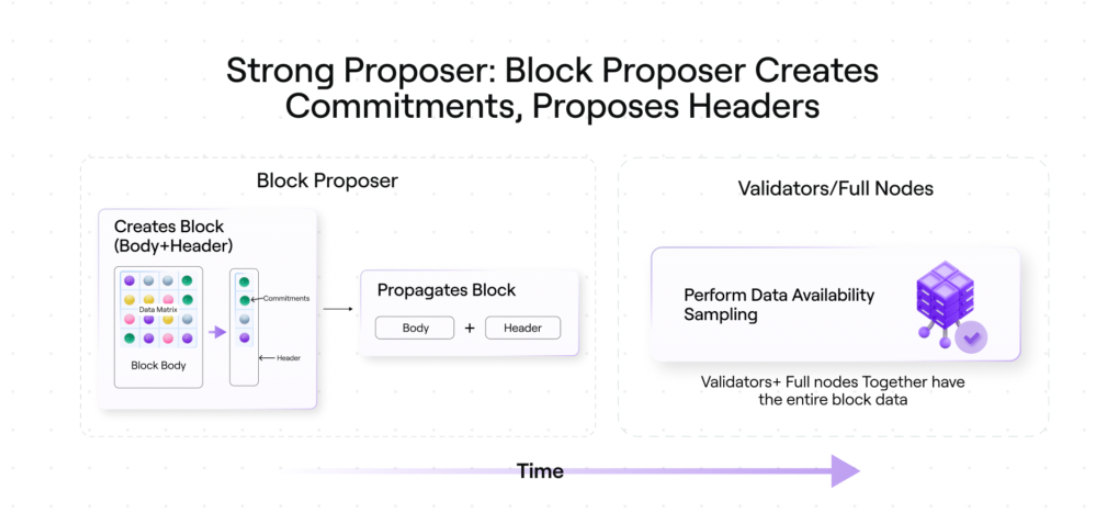
สำหรับ Avail โมเดลที่มีประสิทธิภาพมากกว่าคือสำหรับโหนดเดียวเพื่อสร้างและเผยแพร่ข้อผูกพันไปยังเครือข่าย ผู้เข้าร่วมคนอื่นๆ ทั้งหมดจะสร้างและตรวจสอบหลักฐาน
นี่เป็นครั้งแรกที่เราไม่เพียงแต่เปิดใช้งานไคลเอ็นต์ขนาดเล็กเท่านั้น แต่ยังช่วยให้ส่วนใดส่วนหนึ่งของห่วงโซ่สามารถดำเนินการนี้ได้ เราอนุญาตให้ผู้ตรวจสอบความถูกต้องสุ่มตัวอย่างในลักษณะเดียวกับไคลเอนต์แบบ light
ในแบบจำลองนี้ เครื่องมือตรวจสอบความถูกต้องเพียงตัวเดียวจะเสนอบล็อก สร้างข้อผูกพันสำหรับแถวทั้งหมดของเมทริกซ์ข้อมูล จากนั้นเสนอเฉพาะส่วนหัวของบล็อก
ขั้นตอนที่ 1: ผู้เสนอจะเผยแพร่เฉพาะข้อมูลส่วนหัวของบล็อกเท่านั้น
ขั้นตอนที่ 2: เนื่องจากเครื่องมือตรวจสอบความถูกต้องจะได้รับเฉพาะข้อมูลส่วนหัวเท่านั้น จึงไม่สามารถถอดรหัสหรือสร้างบล็อกใหม่ได้ แต่เนื่องจากพวกเขาสามารถสุ่มตัวอย่างความพร้อมใช้งานของข้อมูลได้ พวกเขาจึงไม่จำเป็นต้องทำเช่นนั้น
ในกรณีนี้ เครื่องมือตรวจสอบความถูกต้องอื่นๆ จะทำงานเหมือนกับไคลเอ็นต์แบบ light
เครื่องมือตรวจสอบความถูกต้องอื่นๆ เหล่านี้จะใช้คำสัญญาสำหรับการสุ่มตัวอย่างความพร้อมใช้งานของข้อมูล และยอมรับการบล็อกเมื่อเป็นไปตามการรับประกันความพร้อมใช้งานเท่านั้น
ในโลกนี้ โหนดทั้งหมดจะทำงานเหมือนไคลเอ็นต์แบบเบา ผู้ตรวจสอบสามารถหลีกเลี่ยงการใช้เนื้อหาของบล็อกเพื่อสร้างข้อผูกพันใหม่เพื่อให้แน่ใจว่าการคำนวณที่ถูกต้องโดยผู้เสนอบล็อก
การสร้างข้อผูกพันสำหรับการคำนวณการพิสูจน์นั้นไม่จำเป็น เมื่อผู้ตรวจสอบสามารถพึ่งพาการตรวจสอบการพิสูจน์ได้
เนื่องจากเราไม่จำเป็นต้องมีโหนดแบบเต็มเพื่อตรวจสอบการดำเนินการที่ถูกต้องของบล็อก (Avail ไม่ได้ดำเนินการ!) โหนดแบบเต็มจึงสามารถมั่นใจได้ว่าพวกเขากำลังติดตามห่วงโซ่ที่ถูกต้องตามข้อมูลส่วนหัวเพียงอย่างเดียว เราแค่ต้องการหลักฐานความพร้อมใช้งาน และข้อมูลส่วนหัว (รวมกับตัวอย่างแบบสุ่มจำนวนเล็กน้อย) ก็สามารถให้ข้อมูลนี้ได้ สิ่งนี้ช่วยให้เราสามารถลดปริมาณการคำนวณที่จำเป็นในการเป็นผู้ตรวจสอบความถูกต้องได้
สิ่งนี้มีประโยชน์เพิ่มเติมในการลดเวลาการสื่อสาร
ความซับซ้อน
เราลังเลที่จะทำโมเดลนี้ให้เสร็จสิ้นในระยะสั้น เนื่องจากจะต้องแยกตัวออกจากโครงสร้างพื้นฐานของ Substrate เราจำเป็นต้องลบรากภายนอกซึ่งจะทำให้การเข้าถึงเครื่องมือ Substrate ทั้งหมดหยุดชะงัก แม้ว่านี่จะเป็นการปรับปรุงที่เรากำลังสำรวจอยู่ก็ตาม
อีกรุ่นหนึ่งยืมมาจากโมเดล blob แบบแบ่งส่วนใน EIP-4844https://eips.ethereum.org/EIPS/eip-4844?ref=blog.availproject.org
ลองนึกภาพระบบนี้:
1. แต่ละแถวของเมทริกซ์ข้อมูลบล็อกถูกสร้างขึ้นโดยตัวสร้างที่แตกต่างกันและรวมถึงความมุ่งมั่นพหุนามที่เกี่ยวข้องของแถว
ผู้สร้างจะแบ่งปันแถวของตนกับเครือข่าย p2p และส่งต่อคำสัญญาให้กับผู้เสนอ
2. การสร้างส่วนหัว: ผู้เสนอบล็อกเดียวรวบรวมข้อผูกพันเหล่านี้
ผู้เสนอตัวอย่างจากผู้สร้าง (และเครือข่าย p2p) เพื่อยืนยันว่าข้อผูกพันที่กำหนดสามารถสร้างการพิสูจน์แบบเปิดที่ถูกต้องก่อนที่จะลบล้างข้อผูกพันที่เข้ารหัส การรวมกันของสัญญาดั้งเดิม + สัญญาเพิ่มเติมนี้จะกลายเป็นส่วนหัว
3. ผู้เสนอแบ่งปันส่วนหัวนี้กับผู้ตรวจสอบ
4. ผู้เสนอและผู้ตรวจสอบดำเนินการสุ่มตัวอย่างความพร้อมใช้งานของข้อมูลโดยการสุ่มตัวอย่างหน่วยสุ่มจากเครือข่าย p2p (หรือผู้สร้าง) และยืนยันว่าข้อมูลสร้างการพิสูจน์แบบเปิดที่ถูกต้อง
5. เมื่อเครื่องมือตรวจสอบความถูกต้องถึงการรับประกันทางสถิติของความพร้อมใช้งาน ส่วนหัวของบล็อกจะถูกเพิ่มลงในห่วงโซ่
ผู้เสนอบล็อกไม่จำเป็นต้องทำงานมากนัก เนื่องจากผู้เข้าร่วมจำนวนมากเป็นผู้กำหนดข้อผูกพัน
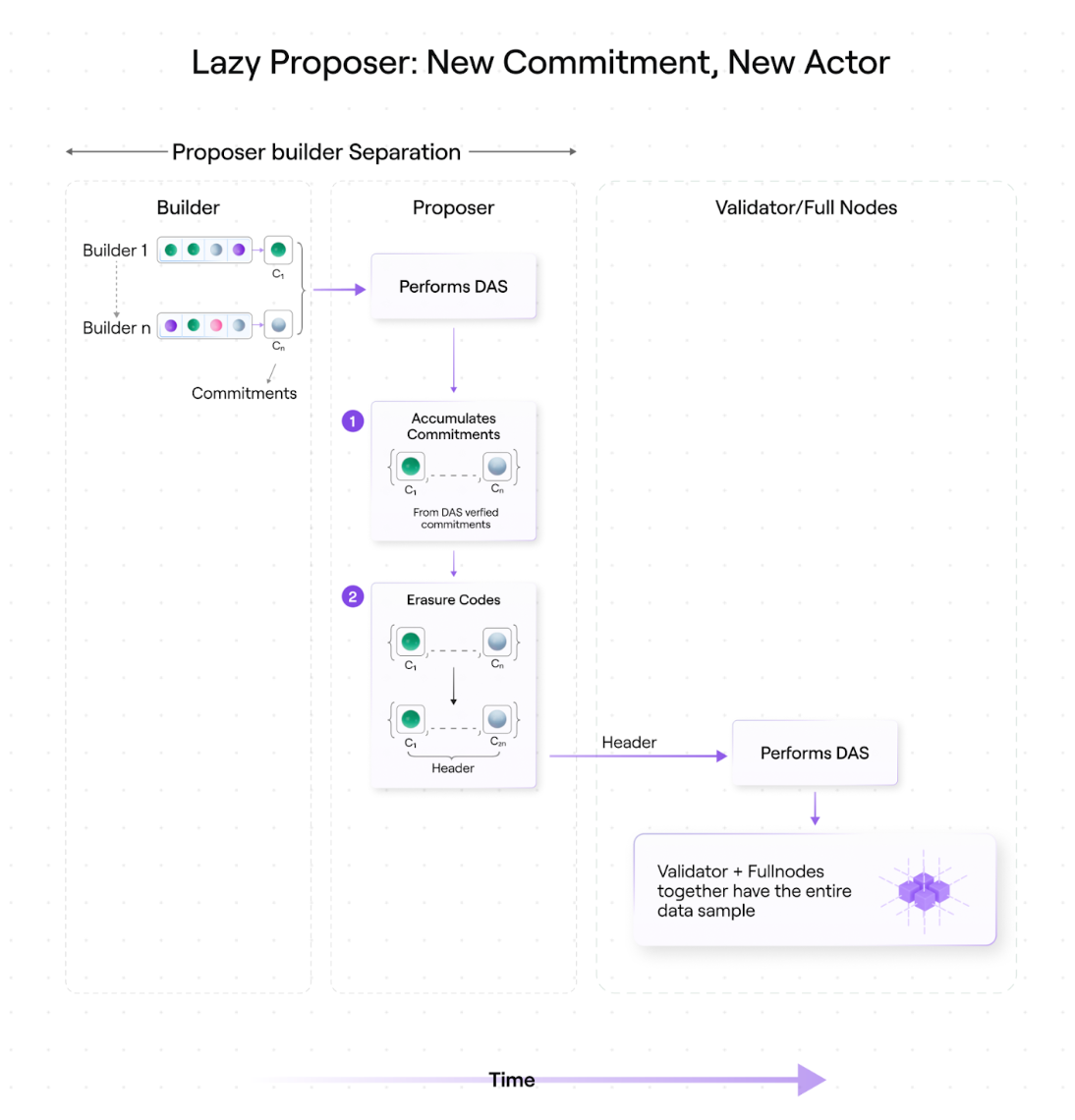
โมเดลผู้เสนอแบบขี้เกียจมีผู้เสนอเพียงรายเดียวสำหรับบล็อก ผู้เข้าร่วมสามารถแบ่งพาร์ติชันได้ในลักษณะเดียวกับการแยกผู้เสนอและผู้สร้างตามที่อธิบายไว้ข้างต้น
อาจมีผู้สร้างหลายคนที่สร้างบล็อกชิ้นเล็กๆ พวกเขาทั้งหมดส่งบล็อกเหล่านี้ไปยังเอนทิตี (ผู้เสนอ) ซึ่งจะสุ่มตัวอย่างแต่ละส่วนเพื่อสร้างส่วนหัวที่เสนอ
ตัวบล็อกถูกสร้างขึ้นโดยใช้โครงสร้างเชิงตรรกะ
ตัวอย่างหนึ่ง
สิ่งที่ทำให้โมเดลผู้เสนอแบบขี้เกียจแตกต่างคือตัวสร้างบล็อกและผู้เสนอบล็อกเป็นเอนทิตีที่แยกจากกัน
สมมติว่ามีตัวสร้างบล็อกสี่ตัว โดยแต่ละตัวมีแถวของเมทริกซ์ข้อมูล ผู้สร้างแต่ละรายสร้างสัญญาโดยใช้บรรทัดนี้
จากนั้นผู้สร้างแต่ละรายจะส่งแถวและสร้างข้อผูกพันไปยังผู้เสนอที่ได้รับมอบหมาย ซึ่งจะสุ่มตัวอย่างข้อมูลจากเนื้อหาของบล็อกเพื่อยืนยันข้อผูกพันที่กำหนด จากนั้นผู้เสนอจะประมาณค่าข้อผูกพันพหุนามเพื่อที่พวกเขาจะไม่เพียงมีข้อผูกพันที่สร้างขึ้นดั้งเดิมสี่ข้อเท่านั้น แต่ยังมีข้อผูกพันแปดข้อด้วย ขณะนี้เมทริกซ์ข้อมูลได้รับการเข้ารหัสและขยายการลบข้อมูลแล้ว
แปดบรรทัดและคำสัญญาทั้งแปดนี้ได้รับการตรวจสอบโดยผู้เสนอคนเดียวกัน
เมื่อพิจารณาเมทริกซ์ทั้งหมด เราจะเห็นว่าครึ่งหนึ่งของแถวถูกสร้างขึ้นโดยผู้เสนอ (เข้ารหัสโดยการลบ) และอีกครึ่งหนึ่งเป็นผู้เสนอให้พวกเขา
ผู้ผลิตเสนอส่วนหัวของบล็อกและทุกคนก็ยอมรับ ซึ่งส่งผลให้บล็อกมีลักษณะเหมือนกับบล็อกที่กำลังสร้างโดย Testnet ของ Avail แม้ว่าบล็อกเหล่านั้นจะถูกสร้างขึ้นอย่างมีประสิทธิภาพมากกว่าก็ตาม
โมเดลผู้เสนอแบบขี้เกียจของ Avail มีประสิทธิภาพมากกว่า แต่ก็ค่อนข้างซับซ้อนเช่นกัน แม้ว่าจะมีโอกาสอื่นที่ง่ายกว่าในการเพิ่มประสิทธิภาพทั้งระบบ แต่ทีมงาน Avail ก็รู้สึกตื่นเต้นที่จะสำรวจการนำโมเดลนี้ไปใช้
การเปรียบเทียบธุรกรรมบล็อคเชนแบบดั้งเดิมกับโมเดลผู้เสนอแบบขี้เกียจ
โมเดลผู้เสนอแบบขี้เกียจไม่ได้แตกต่างจากวิธีการประมวลผลธุรกรรมบล็อกเชนแต่ละรายการบนบล็อกเชนที่ไม่มี Avail ในปัจจุบัน
ทุกวันนี้ เมื่อใครก็ตามทำธุรกรรมบนเกือบทุกเชน พวกเขาจะส่งข้อความแจ้งเตือนเกี่ยวกับธุรกรรมนี้ไปยังโหนดทั้งหมด ในไม่ช้าแต่ละโหนดจะมีธุรกรรมนี้อยู่ใน mempool
แล้วผู้ผลิตบล็อกทำอะไร?
ผู้ผลิตบล็อกจะดึงธุรกรรมจาก mempool ของพวกเขา รวมเข้าด้วยกัน และสร้างบล็อก นี่คือบทบาททั่วไปของผู้สร้างบล็อก
ใน Avail บล็อกข้อมูลและข้อผูกพันจะได้รับการปฏิบัติเหมือนกับธุรกรรมแต่ละรายการ การผสมผสานบล็อกข้อมูล + ความมุ่งมั่นเหล่านี้ได้รับการเผยแพร่บนระบบเช่นเดียวกับธุรกรรมแต่ละรายการที่ถูกส่งบนเครือข่ายแบบเดิม
ในไม่ช้า ทุกคนจะมีความมุ่งมั่นต่อชิ้นส่วนข้อมูลเหล่านี้ ด้วยข้อผูกพันเหล่านี้ ผู้เสนอสามารถเริ่มต้นการสุ่มตัวอย่างเพื่อให้แน่ใจว่าข้อมูลมีความพร้อมใช้งาน ด้วยความมั่นใจในการสุ่มตัวอย่างที่เพียงพอ โหนดจะขยายข้อผูกพันเหล่านี้ ยอมรับข้อมูลในส่วนเนื้อหา และสร้างส่วนหัวของบล็อก ซึ่งจะเป็นการสร้างบล็อกถัดไป
บทสรุป
ข้อเสนอทางสถาปัตยกรรมเหล่านี้ที่เสนอสำหรับ Avail มีวัตถุประสงค์เพื่อแสดงให้เห็นถึงความสำคัญของการแยกเลเยอร์ความพร้อมของข้อมูลออกจากฟังก์ชันหลักอื่นๆ ของบล็อกเชน
เมื่อจัดการความพร้อมใช้งานของข้อมูลแยกกัน การปรับให้เหมาะสมสามารถทำได้เพื่อรักษาความพร้อมใช้งานของข้อมูลเป็นชั้นที่เป็นอิสระ ซึ่งสามารถนำไปสู่การปรับปรุงที่ยิ่งใหญ่กว่าเมื่อความพร้อมใช้งานของข้อมูลเชื่อมโยงกับฟังก์ชันบล็อกเชนอื่น ๆ เช่น การดำเนินการ
ไม่ว่าจะเรียกว่าโซลูชันเลเยอร์ 3 บล็อกเชนแบบโมดูลาร์ หรือโซลูชันการขยายขนาดแบบออฟไลน์ เรารู้สึกตื่นเต้นที่ได้เห็นทีมไอเดียใหม่ๆ ใช้ประโยชน์จากเลเยอร์ความพร้อมของข้อมูลโดยเฉพาะนี้ ทีมงานสามารถมั่นใจได้ว่า Avail จะสามารถปรับขนาดได้โดยตรงกับเชนหรือแอปพลิเคชันใดๆ ก็ตามที่สร้างเสริมไว้ ในขณะที่เราสร้างเครือข่ายบล็อกเชนแบบโมดูลาร์ที่มีผู้ตรวจสอบความถูกต้องหลายร้อยราย ไคลเอ็นต์ขนาดเล็กนับพันราย และเครือข่ายใหม่ ๆ มากมายที่จะตามมา เราไม่คาดหวังว่าจะมีปัญหาใด ๆ ที่เป็นไปตามความต้องการ


