
SignalPlus: ตัวเข้ารหัสอัตโนมัติ (ตัวเข้ารหัสอัตโนมัติ)
ผู้เขียนต้นฉบับ: สตีเวน หวัง

คำนำ
สองพี่น้อง N.Coder และ D.Coder เปิดแกลเลอรีศิลปะ สุดสัปดาห์วันหนึ่ง พวกเขามีนิทรรศการที่แปลกประหลาดเป็นพิเศษ เนื่องจากมีผนังเพียงด้านเดียวและไม่มีงานศิลปะทางกายภาพ เมื่อพวกเขาได้รับภาพวาดใหม่ N.Coder จะเลือกจุดบนผนังเป็นเครื่องหมายเพื่อแสดงภาพวาด จากนั้นจึงโยนงานศิลปะต้นฉบับทิ้งไป เมื่อลูกค้าขอดูภาพวาด D.Coder พยายามสร้างงานศิลปะขึ้นใหม่โดยใช้พิกัดของเครื่องหมายที่เกี่ยวข้องบนผนังเท่านั้น
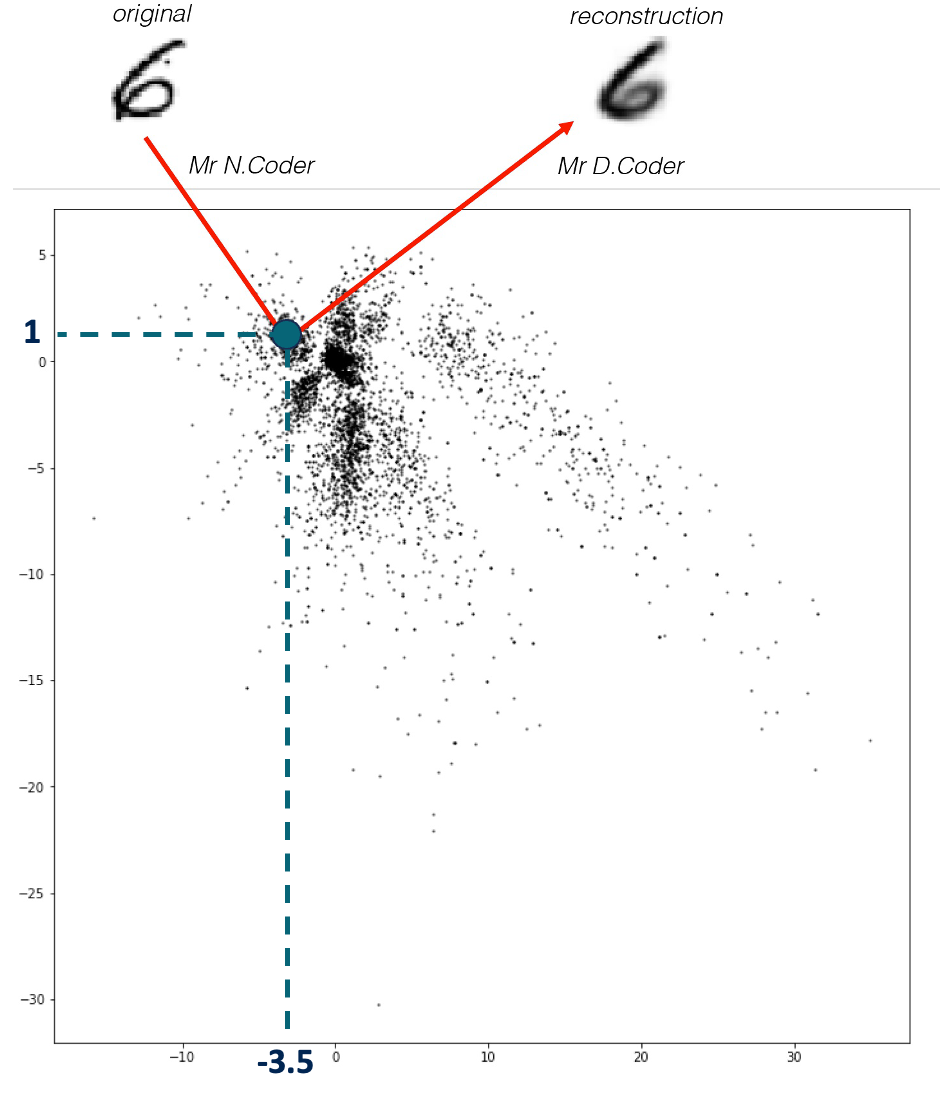
ผนังนิทรรศการมีดังภาพด้านล่าง แต่ละจุดสีดำ คือเครื่องหมายที่ N.Coder วางไว้แทนภาพวาด N.Coder สร้างภาพต้นฉบับของเลข 6 ขึ้นใหม่ ณ พิกัด [- 3.5, 1] บนผนัง
ภาพด้านล่างแสดงตัวอย่างเพิ่มเติม ตัวเลขในแถวบนคือภาพต้นฉบับ พิกัดในแถวกลางคือพิกัดที่ N.Coder แขวนภาพบนผนัง และแถวล่างเป็นผลงานที่ D.Coder สร้างขึ้นใหม่ ขึ้นอยู่กับพิกัด

คำถามเกิดขึ้นว่า N.Coder กำหนดพิกัดที่สอดคล้องกันของภาพวาดแต่ละภาพบนผนังนิทรรศการได้อย่างไร เพื่อให้ D.Coder สามารถสร้างภาพวาดต้นฉบับขึ้นใหม่โดยใช้เพียงภาพวาดนั้นเพียงอย่างเดียว ปรากฎว่าสองพี่น้องซึ่ง ฝึกฝน มานานหลายปีค่อยๆ เชี่ยวชาญ การวางตำแหน่งเครื่องหมายและสร้างงานขึ้นมาใหม่ได้ติดตามการสูญเสียรายได้ที่บ็อกซ์ออฟฟิศอย่างระมัดระวังเนื่องจากลูกค้าเรียกร้องเงินคืนเนื่องจากคุณภาพการสร้างใหม่ไม่ดี สร้างใหม่พร้อมกับลดการสูญเสียรายได้นี้ให้เหลือน้อยที่สุด ดังที่คุณเห็นจากการเปรียบเทียบระหว่างภาพต้นฉบับและการสร้างใหม่ในภาพด้านบน การที่พี่น้องทั้งสองเข้ากันได้ค่อนข้างดี ลูกค้าที่มาชมงานศิลปะมักไม่ค่อยบ่นว่าภาพวาดที่สร้างสรรค์ขึ้นใหม่ของ D.Coder นั้นแตกต่างจากผลงานต้นฉบับที่พวกเขาได้เห็นอย่างมาก
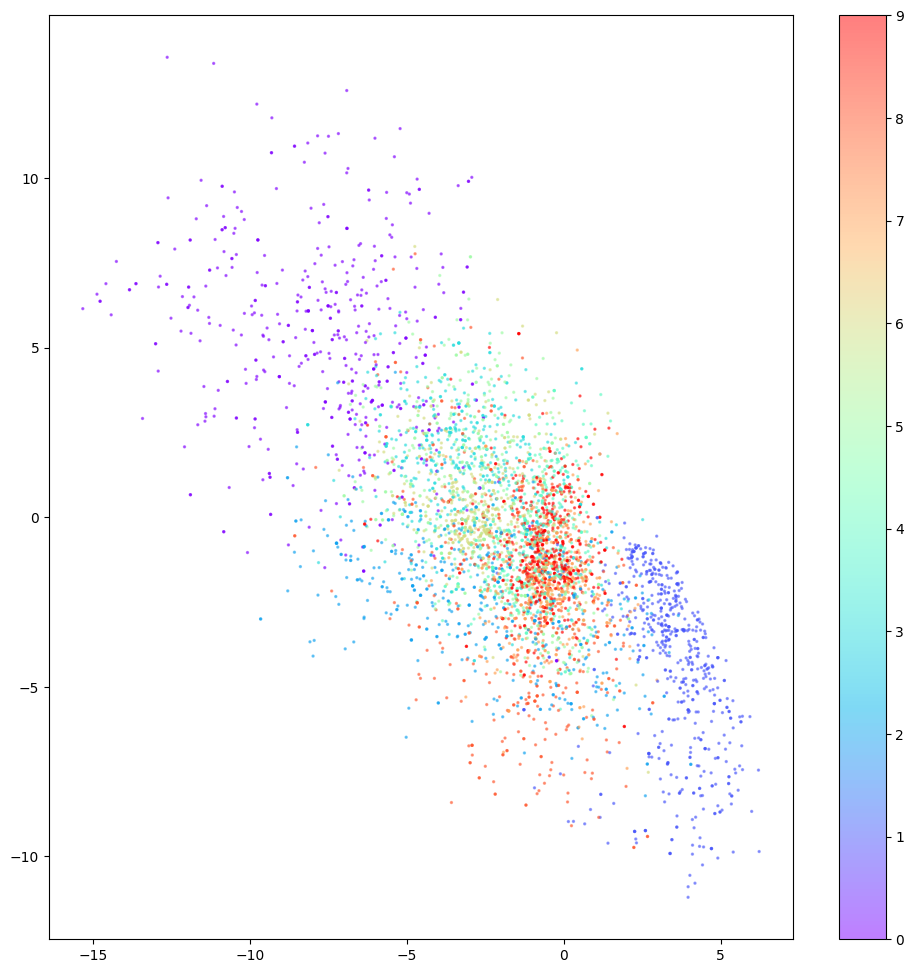
วันหนึ่ง N.Coder มองดูผนังนิทรรศการแล้วเกิดความคิดกล้าได้กล้าเสียว่าสำหรับส่วนต่างๆ ของกำแพงที่ยังไม่มีเครื่องหมายอยู่ในปัจจุบัน จะสร้างสรรค์ผลงานประเภทใดได้บ้างหาก D.Coder ได้รับอนุญาตให้สร้างขึ้นใหม่ได้ หากประสบความสำเร็จก็สามารถจัดนิทรรศการภาพวาดต้นฉบับของตนเอง 100% ได้ เมื่อคิดถึงเรื่องนี้ก็ทำให้ฉันรู้สึกตื่นเต้น ดังนั้น D.Coder จึงสุ่มเลือกพิกัดที่ไม่เคยถูกทำเครื่องหมายมาก่อน (จุดแดง) เพื่อสร้างใหม่ ผลลัพธ์จะแสดงในรูปด้านล่าง
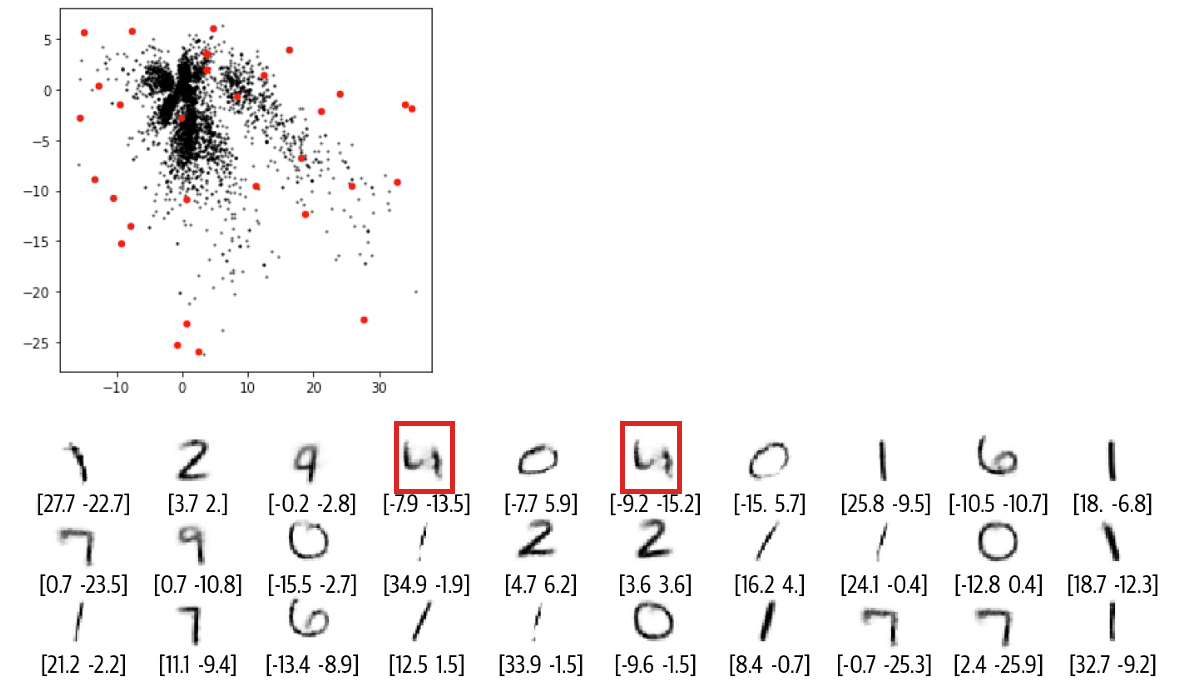
อย่างที่คุณเห็น การสร้างใหม่ทำได้ไม่ดี และตัวเลขบางส่วนก็ไม่สามารถบอกได้ว่าตัวเลขนั้นคืออะไรด้วยซ้ำ เกิดอะไรขึ้น และพี่น้อง Coder จะปรับปรุงวิธีแก้ปัญหาได้อย่างไร
1. ตัวเข้ารหัสอัตโนมัติ
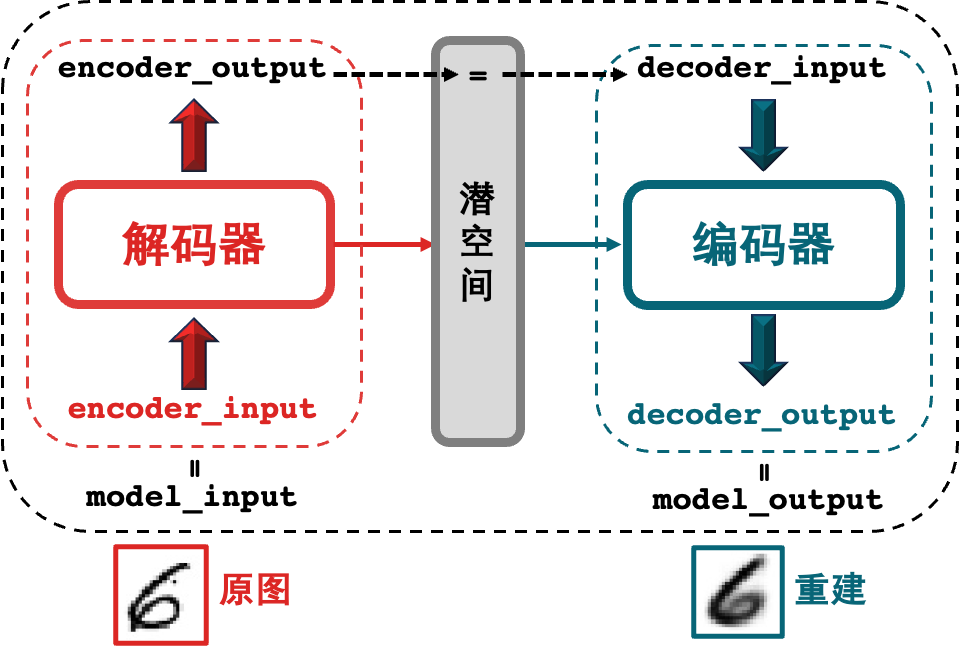
เรื่องราวในคำนำนั้นเป็นการเปรียบเทียบจริงๆโปรแกรมเข้ารหัสอัตโนมัติ(autoencoder) D.Coder จะถูกทับศัพท์เป็น encoder นั่นก็คือตัวเข้ารหัสสิ่งที่ทำคือการแปลงรูปภาพให้เป็นพิกัด และ N.Coder ก็ถูกทับศัพท์เป็นตัวถอดรหัสนั่นคือตัวถอดรหัสสิ่งที่ทำคือการคืนค่าพิกัดให้เป็นรูปภาพ การสูญเสียรายได้ที่ตรวจสอบโดยสองพี่น้องในส่วนที่แล้วคือฟังก์ชันการสูญเสียที่ใช้ในการฝึกโมเดล
เรื่องราวก็คือเรื่องราว มาดูคำอธิบายที่เข้มงวดของตัวเข้ารหัสอัตโนมัติกัน โดยพื้นฐานแล้ว มันเป็นโครงข่ายประสาทเทียม ซึ่งรวมถึง:
หนึ่งตัวเข้ารหัส(ตัวเข้ารหัส): ใช้ในการบีบอัดข้อมูลมิติสูงให้เป็นเวกเตอร์การแสดงมิติต่ำ
หนึ่งตัวถอดรหัส(ตัวถอดรหัส): ใช้เพื่อกู้คืนเวกเตอร์การแสดงมิติต่ำให้เป็นข้อมูลมิติสูง
กระบวนการนี้แสดงในรูปด้านล่าง ข้อมูลอินพุตดั้งเดิมคือข้อมูลรูปภาพที่มีมิติสูง รูปภาพประกอบด้วยพิกเซลจำนวนมากดังนั้นจึงมีมิติสูง ในขณะที่เวกเตอร์การแทนค่าเป็นเวกเตอร์การแทนค่าในมิติต่ำ เวกเตอร์สองมิติ [ -2.0, -0.5] ที่ใช้ในตัวอย่างนี้คือมิติต่ำ
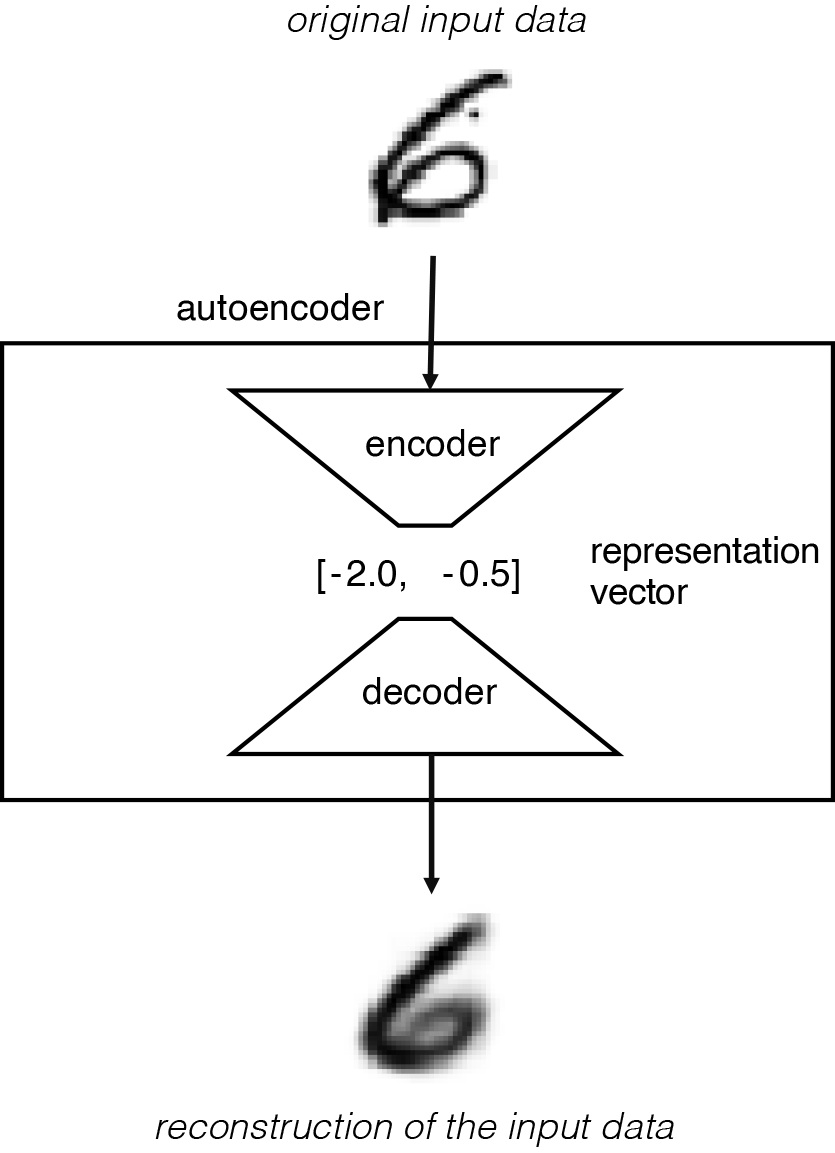
เครือข่ายได้รับการฝึกอบรมเพื่อค้นหาน้ำหนักตัวเข้ารหัสและตัวถอดรหัสที่ลดการสูญเสียระหว่างอินพุตดั้งเดิมและการสร้างอินพุตใหม่หลังจากที่ถูกส่งผ่านตัวเข้ารหัสและตัวถอดรหัส เวกเตอร์การเป็นตัวแทนจะบีบอัดรูปภาพต้นฉบับลงในพื้นที่แฝงในมิติที่ต่ำกว่า โดยทางเลือกพื้นที่แฝง(พื้นที่แฝง) เราควรสามารถสร้างภาพใหม่ได้โดยส่งผ่านจุดนั้นไปยังตัวถอดรหัส เนื่องจากตัวถอดรหัสได้เรียนรู้วิธีการแปลงจุดในพื้นที่แฝงให้เป็นภาพที่มองเห็นได้
ในคำอธิบายคำนำ N.Coder และ D.Coder เข้ารหัสแต่ละภาพโดยใช้เวกเตอร์ที่แสดงถึงพื้นที่แฝง (ผนัง) สองมิติ เหตุผลในการใช้สองมิติคือเพื่อแสดงภาพพื้นที่แฝง ในทางปฏิบัติ พื้นที่แฝงมักจะสูงกว่าสองมิติเพื่อให้จับภาพความแตกต่างที่ใหญ่กว่าในภาพได้อย่างอิสระมากขึ้น
2. การวิเคราะห์แบบจำลอง
2.1 การประชุมครั้งแรก
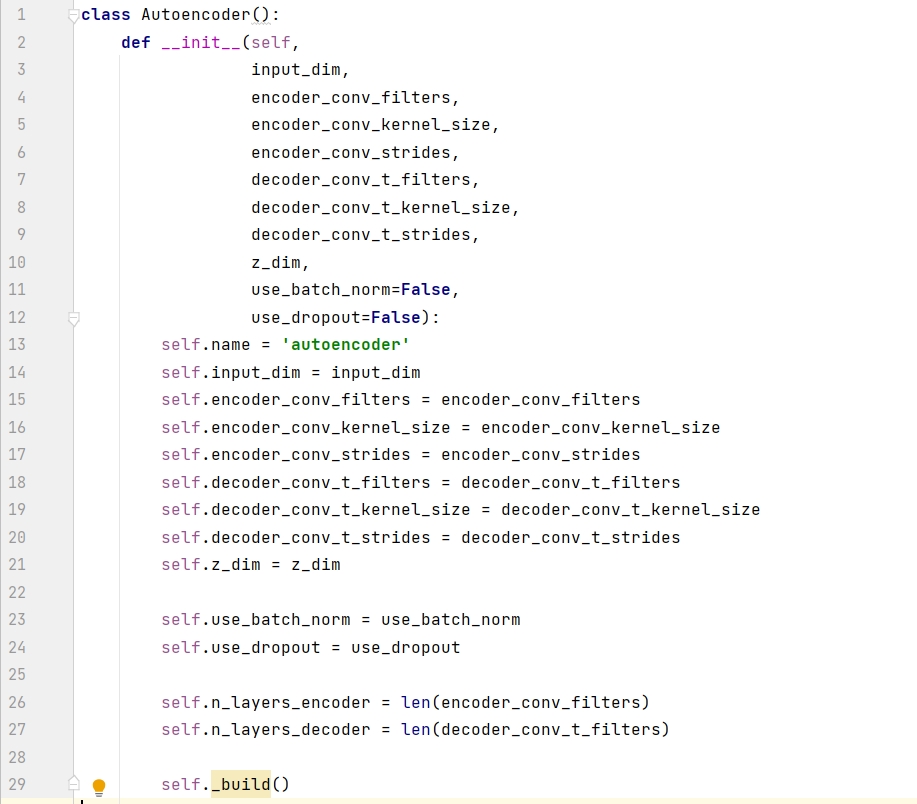
โดยทั่วไป วิธีที่ดีที่สุดคือสร้างคลาสของโมเดลในไฟล์แยกต่างหาก เช่น คลาส Autoencoder ด้านล่าง วิธีนี้ทำให้โปรเจ็กต์อื่นสามารถเรียกคลาสนี้ได้อย่างยืดหยุ่น โค้ดต่อไปนี้จะแสดงเฟรมเวิร์กของ Autoencoder ก่อน __init__() เป็นตัวสร้าง โมเดลถูกสร้างขึ้นโดยการเรียก _build() ฟังก์ชันคอมไพล์() ใช้เพื่อตั้งค่าเครื่องมือเพิ่มประสิทธิภาพ ฟังก์ชัน save() ใช้เพื่อบันทึกโมเดล ฟังก์ชัน load_weights() ใช้เพื่อโหลดตุ้มน้ำหนักในครั้งต่อไปที่ใช้โมเดล และใช้ฟังก์ชัน train() เพื่อฝึกโมเดล
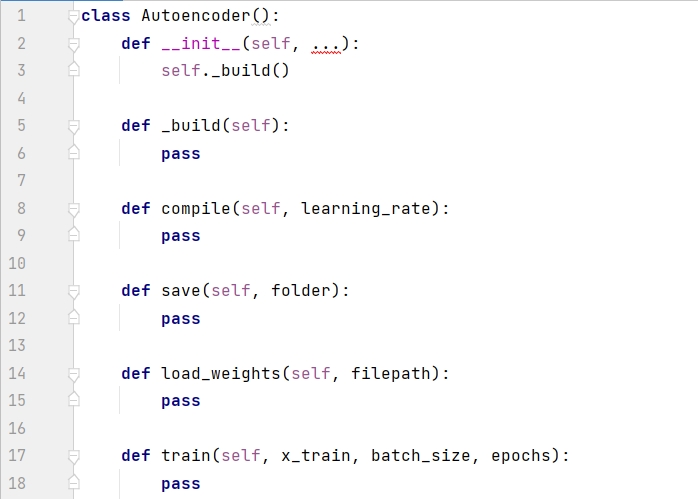
ฟังก์ชันการสร้างประกอบด้วยพารามิเตอร์ที่จำเป็น 8 รายการและพารามิเตอร์เริ่มต้น 2 รายการ input_dim คือขนาดของรูปภาพ z_dim คือขนาดของพื้นที่แฝง พารามิเตอร์ที่จำเป็นอีก 6 รายการที่เหลือคือจำนวนตัวกรอง (ตัวกรอง) และการกรองของตัวเข้ารหัสและตัวถอดรหัส ขนาดเคอร์เนล (kernel_size) ขนาดก้าวย่าง (ก้าว)
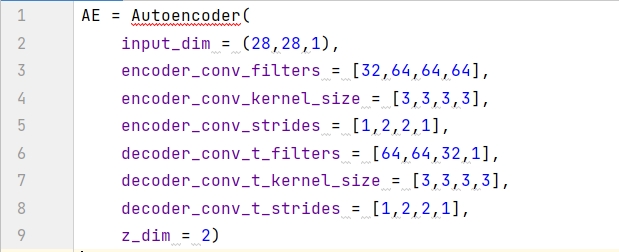
สร้างตัวเข้ารหัสอัตโนมัติโดยใช้ฟังก์ชัน Constructor และตั้งชื่อเป็น AE ข้อมูลอินพุตเป็นภาพขาวดำ มีขนาด (28, 28, 1) และพื้นที่แฝงเป็นระนาบ 2 มิติ ดังนั้น z_dim = 2 นอกจากนี้ค่าของพารามิเตอร์ทั้ง 6 ตัวยังมีขนาดเท่ากับ4 รายการ จากนั้นทั้งโมเดลการเข้ารหัสและโมเดลการถอดรหัสจะมีอยู่4 ชั้น.
กำหนดฟังก์ชัน _build() ในคลาส AutoEncoder เพื่อสร้างตัวเข้ารหัสและตัวถอดรหัสและเชื่อมต่อทั้งสองอย่างเข้าด้วยกัน กรอบโค้ดมีดังต่อไปนี้ (สามส่วนถัดไปจะวิเคราะห์ทีละส่วน):

ในสองส่วนถัดไป เราจะวิเคราะห์โมเดลการเข้ารหัสและโมเดลการถอดรหัสในตัวเข้ารหัสอัตโนมัติทีละตัว
2.2 รูปแบบการเข้ารหัส
หน้าที่ของตัวเข้ารหัสคือการแปลงอิมเมจอินพุตให้เป็นจุดในพื้นที่แฝง การใช้งานเฉพาะของโมเดลการเข้ารหัสในฟังก์ชัน _build() มีดังต่อไปนี้:

รหัสอธิบายไว้ด้านล่าง:
บรรทัดที่ 2-3 กำหนดรูปภาพเป็นอินพุตไปยังตัวเข้ารหัส
บรรทัดที่ 5-17 ซ้อนเลเยอร์ convolutional ตามลำดับ
บรรทัดที่ 19 บันทึกรูปร่างของ x การส่งคืนของ K.int_shape คือทูเพิล (ไม่มี, 7, 7, 64) องค์ประกอบที่ 0 คือขนาดตัวอย่าง ใช้ [1:] เพื่อส่งคืนรูปร่างข้อมูล (7, 7, 64)
บรรทัดที่ 20 ทำให้เลเยอร์ convolutional สุดท้ายเรียบเป็นเวกเตอร์ 1D
เลเยอร์หนาแน่นบนบรรทัดที่ 21 จะแปลงเวกเตอร์นี้เป็นเวกเตอร์ 1D อีกตัวที่มีขนาด z_dim
บรรทัดที่ 22 สร้างโมเดลตัวเข้ารหัสและกำหนดพารามิเตอร์อินพุต encoder_input และ encoder_output ในฟังก์ชัน Model() ตามลำดับ
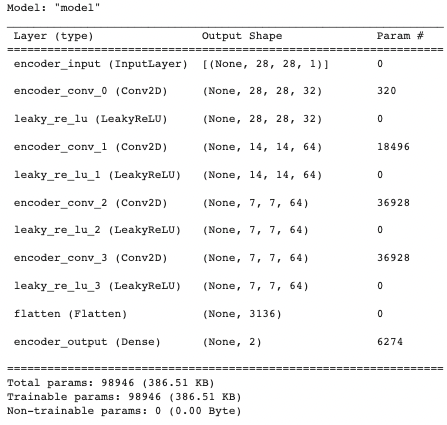
ใช้ฟังก์ชัน summary() เพื่อพิมพ์ข้อมูลของโมเดลการเข้ารหัส ซึ่งใช้เพื่ออธิบายประเภทของชื่อ (เลเยอร์ (ชนิด)) รูปร่างเอาต์พุต (รูปร่างเอาต์พุต) และจำนวนพารามิเตอร์ (Param #) ของแต่ละเลเยอร์

2.3 รูปแบบการถอดรหัส
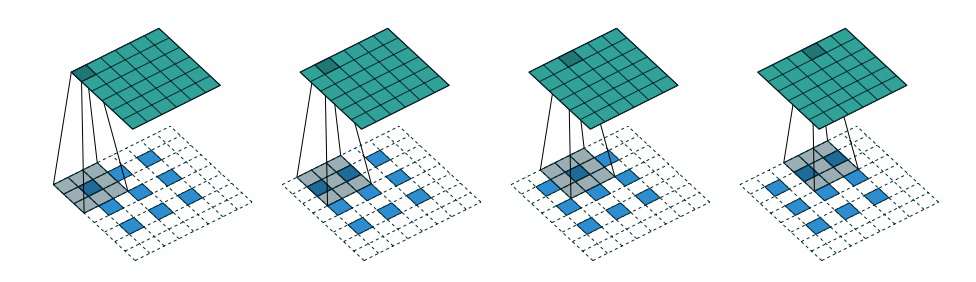
ตัวถอดรหัสเป็นภาพสะท้อนในกระจกของตัวเข้ารหัส ยกเว้นว่าแทนที่จะใช้เลเยอร์แบบหมุนวน ตัวถอดรหัสจะถูกสร้างขึ้นโดยใช้เลเยอร์แบบสลับแบบแบบหมุนวน เมื่อกำหนดก้าวย่างเป็น 2 เลเยอร์แบบหมุนวนจะลดความสูงและความกว้างของรูปภาพลงครึ่งหนึ่งในแต่ละครั้ง ในขณะที่เลเยอร์แบบสลับแบบหมุนวนจะเพิ่มความสูงและความกว้างของรูปภาพเป็นสองเท่า ดูรูปด้านล่างสำหรับการดำเนินการเฉพาะ
การใช้งานเฉพาะของตัวถอดรหัสในฟังก์ชัน _build() มีดังต่อไปนี้:
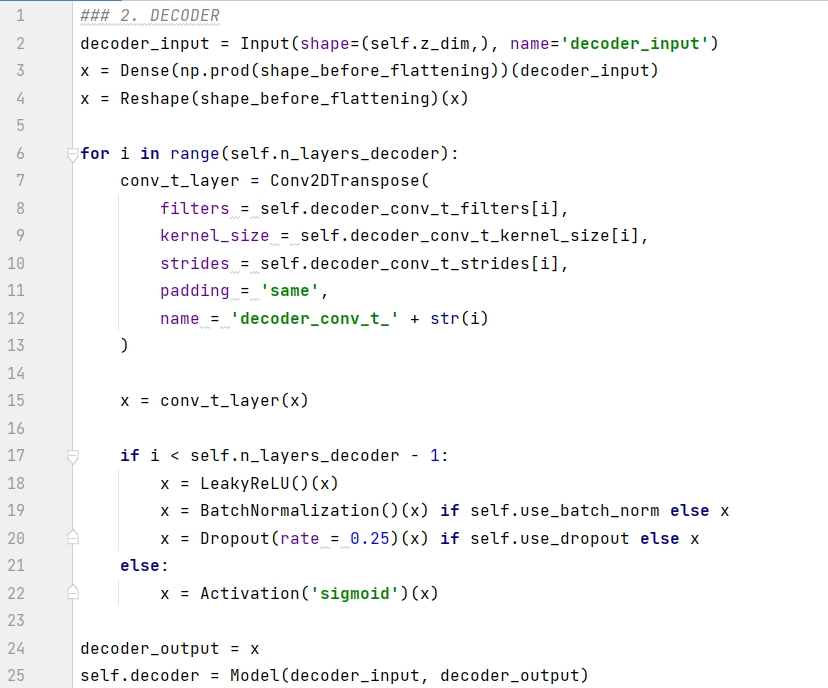
รหัสอธิบายไว้ด้านล่าง:
บรรทัดที่ 1 กำหนดเอาต์พุตของตัวเข้ารหัสเป็นอินพุตของตัวถอดรหัส
บรรทัดที่ 2-3 ปรับรูปร่างเวกเตอร์ 1D ให้เป็นเทนเซอร์ของรูปร่าง (7, 7, 64)
บรรทัดที่ 6-15 ซ้อนชั้นขนย้ายแบบหมุนวนตามลำดับ
บรรทัดที่ 7-22:
หากเป็นเลเยอร์สุดท้าย ให้ใช้ฟังก์ชัน sigmoid เพื่อแปลง และผลลัพธ์จะอยู่ระหว่าง 0-1 เป็นพิกเซล
หากไม่ใช่เลเยอร์สุดท้าย ให้ใช้ฟังก์ชัน relu ที่รั่วเพื่อแปลง และเพิ่มการทำให้เป็นมาตรฐานแบบแบตช์และการประมวลผลการออกกลางคันแบบสุ่ม
บรรทัดที่ 24-25 สร้างโมเดลตัวถอดรหัสและกำหนดพารามิเตอร์อินพุต decoder_input และ decoder_output ในฟังก์ชัน Model() ตามลำดับ อันแรกคือเอาท์พุตของตัวเข้ารหัส นั่นคือ จุดในพื้นที่แฝง ในขณะที่อันหลังคือที่สร้างขึ้นใหม่ ภาพ.
ใช้ฟังก์ชันสรุป() เพื่อพิมพ์ข้อมูลโมเดลการถอดรหัส


2.4 เชื่อมต่อแบบอนุกรม
เพื่อฝึกตัวเข้ารหัสและตัวถอดรหัสในเวลาเดียวกัน เราจำเป็นต้องเชื่อมต่อทั้งสองเข้าด้วยกัน

รหัสอธิบายไว้ด้านล่าง:
บรรทัดที่ 1 ใช้ encoder_input เป็นอินพุต model_input ของโมเดลโดยรวม (encoder_output ผลิตภัณฑ์ระดับกลางคือเอาต์พุตของตัวเข้ารหัส)
บรรทัดที่ 2 ใช้เอาต์พุตของตัวถอดรหัสเป็นเอาต์พุต model_output ของโมเดลโดยรวม (อินพุตของตัวถอดรหัสคือเอาต์พุตของตัวเข้ารหัส)
บรรทัดที่ 3 สร้างโมเดลการเข้ารหัสอัตโนมัติและกำหนดพารามิเตอร์อินพุต model_input และ model_output ในฟังก์ชัน Model() ตามลำดับ
ภาพที่มีค่าพันคำ.
2.5 รูปแบบการฝึกอบรม
หลังจากสร้างโมเดลแล้ว คุณเพียงแค่ต้องกำหนดฟังก์ชันการสูญเสียและคอมไพล์เครื่องมือเพิ่มประสิทธิภาพเท่านั้น โดยปกติแล้วฟังก์ชันการสูญเสียจะถูกเลือกเป็นค่าคลาดเคลื่อนกำลังสองเฉลี่ย (RMSE) การใช้งานฟังก์ชันคอมไพล์() มีดังต่อไปนี้ โดยใช้ Adam Optimizer และตั้งค่าอัตราการเรียนรู้เป็น 0.0005:


ใช้ฟังก์ชัน fit() เพื่อฝึกโมเดล ตั้งค่าขนาดแบตช์เป็น 32 และตั้งค่ายุคเป็น 200 รหัสมีดังนี้:


สุ่มเลือก 10 ชุดทดสอบเพื่อดูผล:
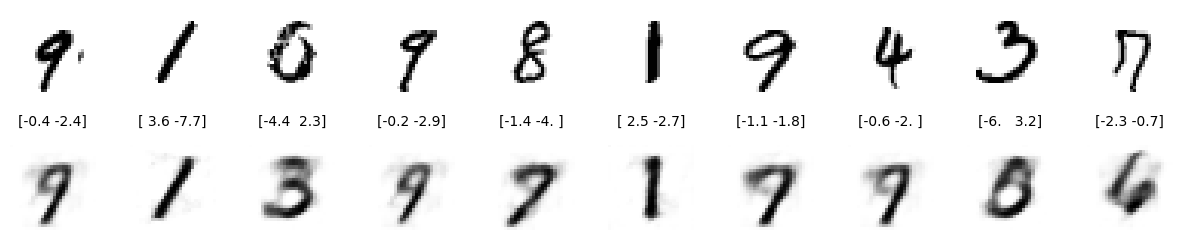
มีเพียง 4 ภาพจาก 10 ภาพเท่านั้นที่มีผลลัพธ์การสร้างใหม่ที่ดี
3. ข้อบกพร่องที่สำคัญสามประการ
หลังจากที่โมเดลได้รับการฝึกฝนแล้ว เราจะเห็นภาพในพื้นที่แฝงได้ พิกัดที่สร้างขึ้นในชุดการทดสอบโดยตัวเข้ารหัสในแบบจำลองจะแสดงในรูปแบบกระจาย 2 มิติ
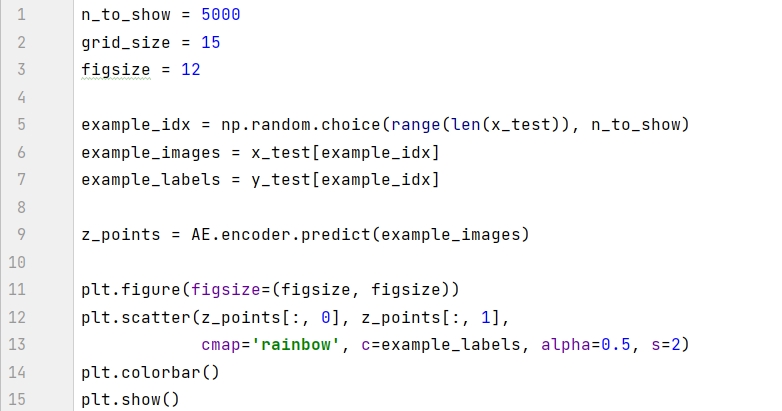
มีปรากฏการณ์สามประการที่ควรสังเกตในภาพ:
ตัวเลขบางตัวใช้พื้นที่ขนาดเล็ก เช่น 9 สีแดง และตัวเลขบางตัวใช้พื้นที่ขนาดใหญ่ เช่น 0 สีม่วง
จุดในกราฟไม่สมมาตรถึง (0, 0) ตัวอย่างเช่น มีจุดค่าลบมากกว่าจุดค่าบวกบนแกน x หลายจุด และบางจุดถึง x =-15 ด้วยซ้ำ
มีช่องว่างขนาดใหญ่ระหว่างสีที่มีจุดน้อยมาก เช่น มุมซ้ายบนของภาพด้านบน
ข้อบกพร่องสำคัญสามประการข้างต้นทำให้ยากสำหรับเราที่จะสุ่มตัวอย่างจากพื้นที่แฝง:
สำหรับข้อบกพร่อง 1 เนื่องจากหมายเลข 9 ครอบครองพื้นที่มากกว่า 0 เราจึงสุ่มตัวอย่าง 9 ได้ง่ายกว่า
สำหรับข้อบกพร่องที่ 2 ในทางเทคนิคแล้ว เราสามารถสุ่มตัวอย่างจุดใดก็ได้บนเครื่องบิน แต่การแจกแจงของแต่ละตัวเลขนั้นไม่แน่นอน หากการแจกแจงไม่สมมาตร การสุ่มตัวอย่างจะทำได้ยาก
เกี่ยวกับข้อบกพร่องที่ 3 จะเห็นได้จากรูปด้านล่างว่าไม่สามารถสร้างตัวเลขที่เหมาะสมบางตัวขึ้นมาใหม่จากช่องว่างในพื้นที่แฝงได้
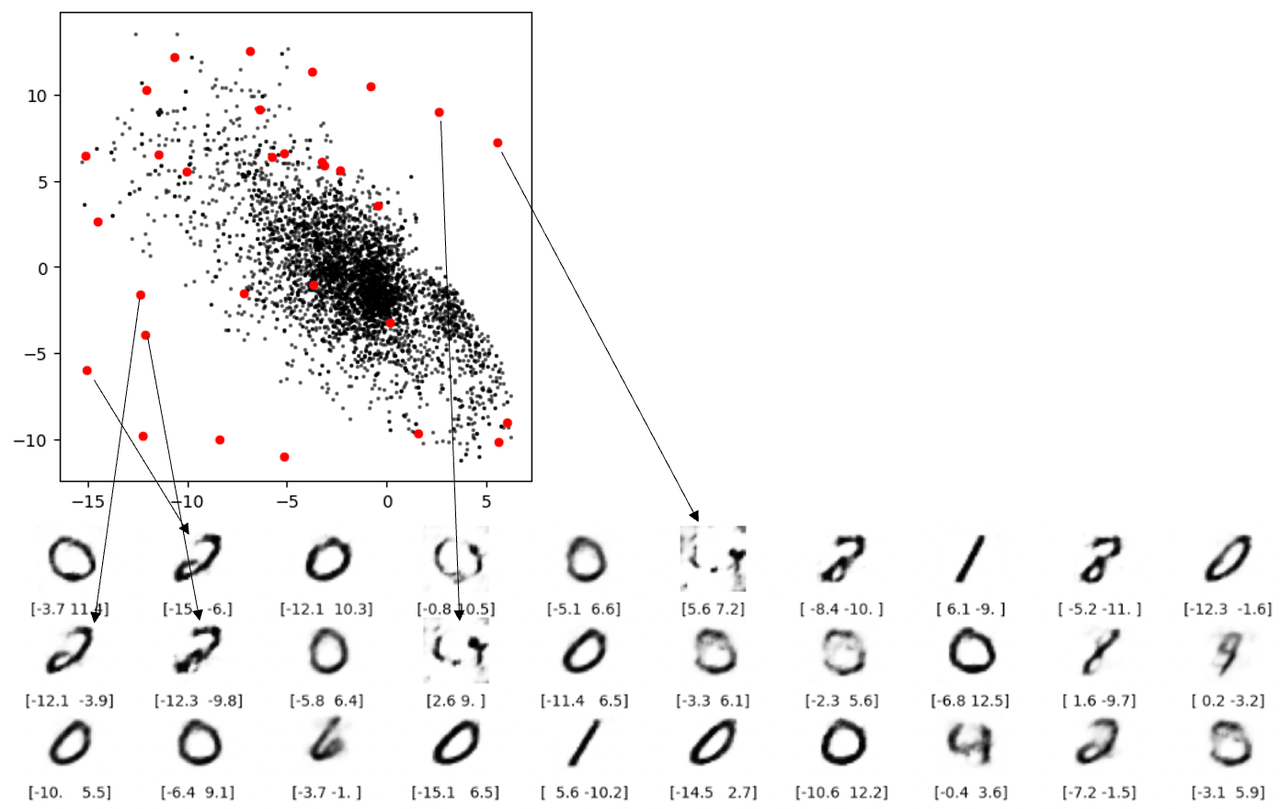
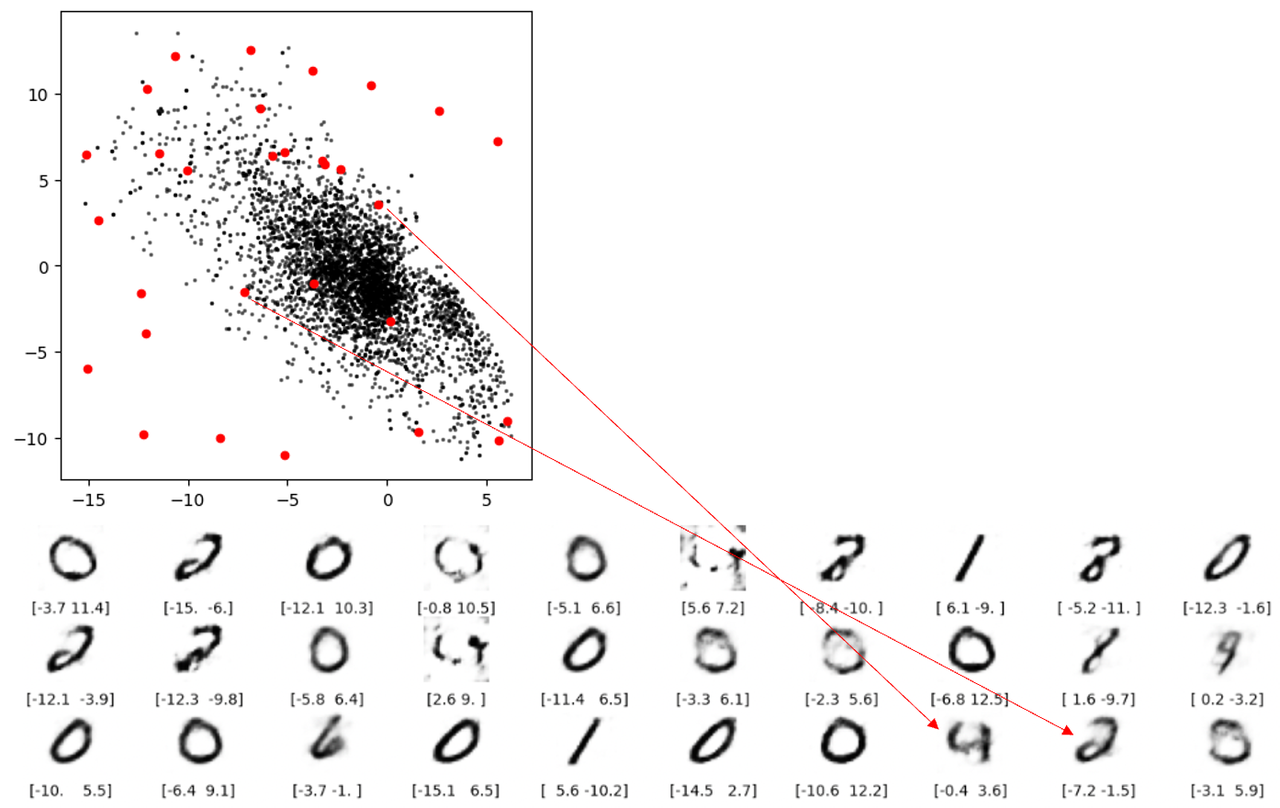
ข้อบกพร่อง 3: เป็นเรื่องง่ายที่จะเข้าใจว่าการสร้างใหม่ไม่สามารถสร้างตัวเลขได้เมื่อว่างเปล่า แต่การสร้างใหม่ที่แสดงด้วยเส้นสีแดงสองเส้นในรูปด้านล่างน่ากังวล ไม่มีจุดใดอยู่ในระยะขอบ แต่ก็ยังไม่สามารถถอดรหัสเป็นตัวเลขที่เหมาะสมได้ เหตุผลพื้นฐานคือตัวเข้ารหัสอัตโนมัติไม่ได้บังคับใช้การรับประกันว่าพื้นที่แฝงที่สร้างขึ้นนั้นมีความต่อเนื่อง ตัวอย่างเช่น แม้ว่า (2,-2) จะสามารถสร้างเลข 4 ที่น่าพอใจได้ แต่โมเดลก็ไม่มีกลไกเพื่อให้แน่ใจว่าจุดนั้น (2.1, – 2.1 ) ก็ให้เลข 4 ที่น่าพอใจเช่นกัน
สรุป
โปรแกรมเข้ารหัสอัตโนมัติต้องการเพียงคุณสมบัติและไม่จำเป็นต้องมีป้ายกำกับ เป็นโมเดลการเรียนรู้แบบไม่มีผู้ดูแลที่ใช้ในการสร้างข้อมูลใหม่ โมเดลนี้เป็นโมเดลกำเนิด แต่จากข้อบกพร่องหลักสามประการที่กล่าวถึงในส่วนที่แล้ว โมเดลกำเนิดนี้ไม่เหมาะสำหรับตัวเลขขาวดำมิติต่ำ และเอฟเฟกต์สำหรับใบหน้าสีที่มีมิติสูงจะยิ่งแย่ลงไปอีก
เฟรมเวิร์กตัวเข้ารหัสอัตโนมัตินี้ดี ดังนั้นเราจะแก้ไขข้อบกพร่องทั้งสามนี้เพื่อสร้างตัวเข้ารหัสอัตโนมัติที่ทรงพลังได้อย่างไร นี่คือเนื้อหาของบทความถัดไปตัวเข้ารหัสอัตโนมัติแบบแปรผัน (Variational AutoEncoder, VAE)。

คุณสามารถค้นหา SignalPlus ได้ใน Plugin Store ของ ChatGPT 4.0 เพื่อรับข้อมูลการเข้ารหัสแบบเรียลไทม์ หากคุณต้องการรับข้อมูลอัปเดตของเราทันที โปรดติดตามบัญชี Twitter ของเรา @SignalPlus_Web 3 หรือเข้าร่วมกลุ่ม WeChat ของเรา (เพิ่มผู้ช่วย WeChat: SignalPlus 123) กลุ่ม Telegram และชุมชน Discord เพื่อสื่อสารและโต้ตอบกับเพื่อน ๆ มากขึ้น
SignalPlus Official Website:https://www.signalplus.com


