
ความเฟื่องฟูของ AI ที่นำเสนอโดย ChatGPT: เทคโนโลยีบล็อกเชนสามารถแก้ปัญหาความท้าทายและปัญหาคอขว
การรวบรวมต้นฉบับ: BlockTurbo
การรวบรวมต้นฉบับ: BlockTurbo
สาขาของปัญญาประดิษฐ์เชิงกำเนิด (AI) เป็นจุดยอดนิยมอย่างไร้ข้อโต้แย้งในช่วงสองสัปดาห์ที่ผ่านมา โดยมีการเปิดตัวใหม่ที่แหวกแนวและการผสานรวมที่ล้ำสมัยเกิดขึ้น OpenAI เปิดตัวโมเดล GPT-4 ที่ได้รับการคาดหวังสูง Midjourney เปิดตัวโมเดล V 5 ล่าสุด และ Stanford เปิดตัวโมเดลภาษา Alpaca 7 B ในขณะเดียวกัน Google ได้เปิดตัว AI เชิงกำเนิดในชุด Workspace ของตน ส่วน Anthropic ได้เปิดตัว Claude ผู้ช่วยด้าน AI ของตน และ Microsoft ได้ผสานรวมเครื่องมือ AI เชิงกำเนิดที่ทรงพลังอย่าง Copilot เข้ากับชุดโปรแกรม Microsoft 365
ก้าวของการพัฒนาและการยอมรับ AI กำลังเร่งตัวขึ้น เนื่องจากธุรกิจต่างๆ เริ่มตระหนักถึงคุณค่าของ AI และระบบอัตโนมัติ และความจำเป็นในการนำเทคโนโลยีเหล่านี้มาใช้เพื่อให้สามารถแข่งขันในตลาดได้
แม้ว่าการพัฒนา AI ดูเหมือนจะดำเนินไปอย่างราบรื่น แต่ก็ยังมีความท้าทายและปัญหาคอขวดที่ต้องแก้ไข เมื่อธุรกิจและผู้บริโภคยอมรับ AI มากขึ้น ปัญหาคอขวดในพลังการประมวลผลก็เกิดขึ้น ปริมาณการประมวลผลที่จำเป็นสำหรับระบบ AI เพิ่มขึ้นเป็นสองเท่าทุกๆ 2-3 เดือน ในขณะที่การจัดหาทรัพยากรการประมวลผลนั้นต้องดิ้นรนเพื่อให้ทัน นอกจากนี้ ค่าใช้จ่ายในการฝึกอบรมแบบจำลอง AI ขนาดใหญ่ยังคงเพิ่มสูงขึ้นประมาณ 3,100% ต่อปีในช่วงทศวรรษที่ผ่านมา
ชื่อระดับแรก
ความรู้พื้นฐานด้านปัญญาประดิษฐ์ (AI) และการเรียนรู้ของเครื่อง (ML)
สาขาของ AI อาจเป็นเรื่องที่น่าหวาดหวั่น เนื่องจากคำศัพท์ทางเทคนิค เช่น การเรียนรู้เชิงลึก โครงข่ายประสาทเทียม และแบบจำลองพื้นฐานที่เพิ่มความซับซ้อน สำหรับตอนนี้ เรามาลดความซับซ้อนของแนวคิดเหล่านี้เพื่อให้เข้าใจได้ง่ายขึ้น
ปัญญาประดิษฐ์เป็นสาขาหนึ่งของวิทยาการคอมพิวเตอร์ที่เกี่ยวข้องกับการพัฒนาอัลกอริทึมและแบบจำลองที่ช่วยให้คอมพิวเตอร์สามารถปฏิบัติงานที่ต้องใช้สติปัญญาของมนุษย์ เช่น การรับรู้ การใช้เหตุผล และการตัดสินใจ
การเรียนรู้ของเครื่อง (ML) เป็นส่วนย่อยของ AI ที่เกี่ยวข้องกับการฝึกอบรมอัลกอริทึมเพื่อจดจำรูปแบบในข้อมูลและคาดการณ์ตามรูปแบบเหล่านั้น
การเรียนรู้เชิงลึกเป็น ML ประเภทหนึ่งที่เกี่ยวข้องกับการใช้โครงข่ายประสาทเทียม ซึ่งประกอบด้วยชั้นของโหนดที่เชื่อมต่อถึงกัน ซึ่งทำงานร่วมกันเพื่อวิเคราะห์ข้อมูลอินพุตและสร้างเอาต์พุต
ชื่อระดับแรก
ปัญหาอุตสาหกรรม AI และ ML
ความก้าวหน้าใน AI นั้นขับเคลื่อนด้วยปัจจัยสามประการหลัก:
นวัตกรรมอัลกอริทึมข้อมูล
ข้อมูล: โมเดล AI อาศัยชุดข้อมูลขนาดใหญ่เป็นเชื้อเพลิงในการฝึกอบรม ทำให้สามารถเรียนรู้จากรูปแบบและความสัมพันธ์ในข้อมูลได้
คำนวณ: การคำนวณที่ซับซ้อนที่จำเป็นในการฝึกโมเดล AI ต้องใช้พลังประมวลผลจำนวนมาก
อย่างไรก็ตาม มีปัญหาหลักสองประการที่เป็นอุปสรรคต่อการพัฒนาปัญญาประดิษฐ์ ย้อนกลับไปในปี 2021 การเข้าถึงข้อมูลเป็นความท้าทายอันดับหนึ่งที่ธุรกิจ AI ต้องเผชิญในการพัฒนา AI ในปีที่ผ่านมา ปัญหาเกี่ยวกับคอมพิวเตอร์ได้เข้ามาแทนที่ข้อมูลในฐานะความท้าทาย โดยเฉพาะอย่างยิ่งเนื่องจากการไม่สามารถเข้าถึงทรัพยากรการประมวลผลตามความต้องการซึ่งขับเคลื่อนด้วยความต้องการสูง
ปัญหาที่สองเกี่ยวข้องกับความไร้ประสิทธิภาพของนวัตกรรมอัลกอริทึม ในขณะที่นักวิจัยยังคงปรับปรุงโมเดลทีละขั้นโดยสร้างจากโมเดลก่อนหน้า ความฉลาดหรือรูปแบบที่ดึงมาจากโมเดลเหล่านี้จะสูญหายไปเสมอ
ชื่อเรื่องรอง
คอขวดคอมพิวเตอร์
การฝึกอบรมโมเดลแมชชีนเลิร์นนิงขั้นพื้นฐานนั้นต้องใช้ทรัพยากรมาก ซึ่งมักจะเกี่ยวข้องกับ GPU จำนวนมากเป็นระยะเวลานาน ตัวอย่างเช่น Stability.AI ต้องการ GPU Nvidia A 100 จำนวน 4,000 ตัวที่ทำงานบนคลาวด์ของ AWS เพื่อฝึกโมเดล AI ของตน ซึ่งมีค่าใช้จ่ายมากกว่า 50 ล้านเหรียญต่อเดือน ในทางกลับกัน GPT-3 ของ OpenAI มีค่าใช้จ่าย 12 ล้านดอลลาร์ในการฝึกฝนโดยใช้ GPU Nvidia V100 1,000 ตัว
บริษัท AI มักเผชิญกับทางเลือกสองทาง: ลงทุนในฮาร์ดแวร์ของตนเองและเสียสละความสามารถในการปรับขนาด หรือเลือกผู้ให้บริการคลาวด์และจ่ายเงินให้สูงสุด ในขณะที่บริษัทขนาดใหญ่สามารถซื้อตัวเลือกหลังได้ แต่บริษัทขนาดเล็กอาจไม่ได้หรูหราขนาดนั้น เมื่อต้นทุนของเงินทุนเพิ่มขึ้น สตาร์ทอัพถูกบังคับให้ต้องลดการใช้จ่ายบนคลาวด์ แม้ว่าค่าใช้จ่ายในการปรับขนาดโครงสร้างพื้นฐานสำหรับผู้ให้บริการคลาวด์ขนาดใหญ่จะยังคงเท่าเดิม
ชื่อเรื่องรอง
ขาดประสิทธิภาพและขาดความร่วมมือ
การพัฒนา AI มากขึ้นเรื่อยๆ กำลังดำเนินการอย่างลับๆ ในบริษัทเทคโนโลยีขนาดใหญ่ ไม่ใช่ในสถาบันการศึกษา แนวโน้มนี้ทำให้การทำงานร่วมกันในภาคสนามน้อยลง โดยบริษัทต่างๆ เช่น OpenAI ของ Microsoft และ DeepMind ของ Google จะแข่งขันกันเองและทำให้โมเดลของตนมีความเป็นส่วนตัว
การขาดความร่วมมือนำไปสู่ความไร้ประสิทธิภาพ ตัวอย่างเช่น หากทีมวิจัยอิสระต้องการพัฒนา GPT-4 ของ OpenAI เวอร์ชันที่มีประสิทธิภาพมากขึ้น พวกเขาจำเป็นต้องฝึกโมเดลใหม่ตั้งแต่เริ่มต้น โดยพื้นฐานแล้วจะต้องเรียนรู้ทุกอย่างที่ GPT-4 ฝึกฝนมาใหม่ เมื่อพิจารณาว่าค่าใช้จ่ายในการฝึกอบรมของ GPT-3 เพียงอย่างเดียวสูงถึง 12 ล้านเหรียญ ทำให้ห้องปฏิบัติการวิจัย ML ขนาดเล็กเสียเปรียบ และผลักดันอนาคตของการพัฒนา AI ให้อยู่ในการควบคุมของบริษัทเทคโนโลยีขนาดใหญ่
ชื่อระดับแรก
เครือข่ายคอมพิวเตอร์แบบกระจายศูนย์สำหรับการเรียนรู้ของเครื่อง
เครือข่ายการประมวลผลแบบกระจายอำนาจจะเชื่อมต่อเอนทิตีที่กำลังมองหาทรัพยากรการประมวลผลเข้ากับระบบที่มีกำลังการประมวลผลสำรองโดยสร้างแรงจูงใจในการสนับสนุนทรัพยากร CPU และ GPU ให้กับเครือข่าย เนื่องจากไม่มีค่าใช้จ่ายเพิ่มเติมสำหรับบุคคลหรือองค์กรในการจัดหาทรัพยากรที่ไม่ได้ใช้งาน เครือข่ายแบบกระจายศูนย์จึงสามารถเสนอราคาที่ต่ำกว่าเมื่อเทียบกับผู้ให้บริการแบบรวมศูนย์
เครือข่ายคอมพิวเตอร์แบบกระจายอำนาจมีสองประเภทหลัก: วัตถุประสงค์ทั่วไปและวัตถุประสงค์พิเศษ เครือข่ายคอมพิวเตอร์สำหรับวัตถุประสงค์ทั่วไปทำงานเหมือนระบบคลาวด์แบบกระจายอำนาจ โดยจัดหาทรัพยากรการประมวลผลสำหรับแอปพลิเคชันต่างๆ ในทางกลับกัน เครือข่ายคอมพิวเตอร์ที่สร้างขึ้นตามวัตถุประสงค์นั้นได้รับการปรับแต่งให้เหมาะกับกรณีการใช้งานเฉพาะ ตัวอย่างเช่น เครือข่ายการเรนเดอร์เป็นเครือข่ายคอมพิวเตอร์เฉพาะที่เน้นการแสดงผลปริมาณงาน
ชื่อเรื่องรอง
ปริมาณงานคอมพิวเตอร์การเรียนรู้ของเครื่อง
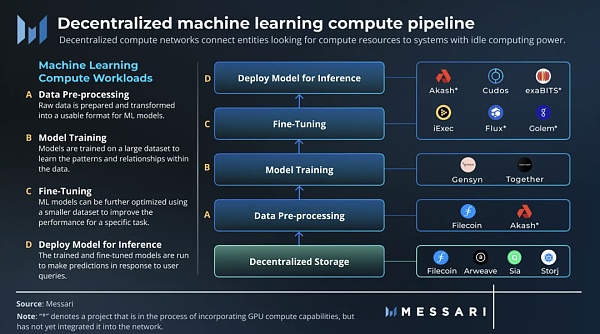
แมชชีนเลิร์นนิงสามารถแบ่งออกเป็นสี่ภาระงานการคำนวณหลัก:
การประมวลผลข้อมูลล่วงหน้า: ข้อมูลดิบถูกเตรียมและแปลงเป็นรูปแบบที่โมเดล ML ใช้งานได้ ซึ่งโดยทั่วไปจะเกี่ยวข้องกับกิจกรรมต่างๆ เช่น การล้างข้อมูลและการทำให้เป็นมาตรฐาน
รถไฟ: โมเดลการเรียนรู้ของเครื่องได้รับการฝึกฝนในชุดข้อมูลขนาดใหญ่เพื่อเรียนรู้รูปแบบและความสัมพันธ์ในข้อมูล ในระหว่างการฝึกซ้อม พารามิเตอร์และน้ำหนักของโมเดลจะถูกปรับเพื่อลดข้อผิดพลาดให้เหลือน้อยที่สุด
ปรับจูน: โมเดล ML สามารถปรับแต่งเพิ่มเติมด้วยชุดข้อมูลที่เล็กลงเพื่อปรับปรุงประสิทธิภาพในงานเฉพาะ
การให้เหตุผล: รันโมเดลที่ได้รับการฝึกอบรมและปรับแต่งอย่างละเอียดเพื่อทำการคาดคะเนตามการสอบถามของผู้ใช้
ชื่อเรื่องรอง
เครือข่ายคอมพิวเตอร์เฉพาะด้านแมชชีนเลิร์นนิง
เนื่องจากความท้าทายสองประการเกี่ยวกับการขนานและการตรวจสอบความถูกต้อง ส่วนการฝึกอบรมจึงต้องการเครือข่ายคอมพิวเตอร์เพื่อวัตถุประสงค์พิเศษ
การฝึกโมเดล ML ขึ้นอยู่กับสถานะ ซึ่งหมายความว่าผลลัพธ์ของการคำนวณขึ้นอยู่กับสถานะปัจจุบันของการคำนวณ ซึ่งทำให้การใช้เครือข่าย GPU แบบกระจายมีความซับซ้อนมากขึ้น ดังนั้นจึงจำเป็นต้องมีเครือข่ายเฉพาะที่ออกแบบมาสำหรับการฝึกอบรมแบบคู่ขนานของโมเดล ML
ปัญหาที่สำคัญกว่านั้นเกี่ยวข้องกับการตรวจสอบความถูกต้อง หากต้องการสร้างเครือข่ายการฝึกอบรมโมเดล ML ที่ลดความน่าเชื่อถือลง เครือข่ายต้องมีวิธีการตรวจสอบงานคอมพิวเตอร์โดยไม่ต้องใช้การคำนวณทั้งหมดซ้ำ ซึ่งจะทำให้เสียเวลาและทรัพยากร
Gensyn
Gensyn เป็นเครือข่ายคอมพิวเตอร์เฉพาะ ML ที่ได้ค้นพบวิธีแก้ไขปัญหาการขนานและการตรวจสอบความถูกต้องของโมเดลการฝึกอบรมในลักษณะกระจายอำนาจและกระจาย โปรโตคอลใช้การขนานเพื่อแบ่งปริมาณงานคอมพิวเตอร์ที่ใหญ่ขึ้นเป็นงานต่างๆ และส่งงานแบบอะซิงโครนัสไปยังเครือข่าย เพื่อแก้ปัญหาการตรวจสอบ Gensyn ใช้หลักฐานการเรียนรู้เชิงความน่าจะเป็น โปรโตคอลการระบุตำแหน่งโดยใช้กราฟ และระบบจูงใจที่ใช้การปักหลักและเฉือน
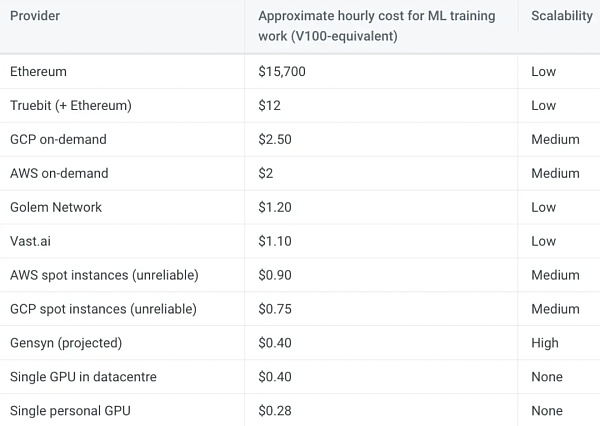
แม้ว่าเครือข่าย Gensyn จะยังไม่เปิดให้บริการ แต่ทีมงานคาดการณ์ว่าค่าใช้จ่ายรายชั่วโมงจะอยู่ที่ประมาณ 0.40 ดอลลาร์สหรัฐฯ สำหรับ GPU ที่เทียบเท่ากับ V100 บนเครือข่ายของตน ค่าประมาณนี้อ้างอิงจากนักขุด Ethereum ที่มีรายได้ $0.20 ถึง $0.35 ต่อชั่วโมงโดยใช้ GPU ที่คล้ายกันก่อนที่จะรวมเข้าด้วยกัน แม้ว่าค่าประมาณนี้จะลดลง 100% แต่ต้นทุนการประมวลผลของ Gensyn ก็ยังต่ำกว่าบริการแบบออนดีมานด์ที่เสนอโดย AWS และ GCP อย่างมาก
Together
ชื่อเรื่องรอง
Bittensor: การกระจายอำนาจของ Machine Intelligence
Bittensor จัดการกับความไร้ประสิทธิภาพในการเรียนรู้ของเครื่องในขณะที่เปลี่ยนวิธีการทำงานร่วมกันของนักวิจัยโดยใช้การเข้ารหัสอินพุตและเอาต์พุตที่ได้มาตรฐานเพื่อจูงใจการผลิตความรู้บนเครือข่ายโอเพ่นซอร์สเพื่อเปิดใช้งานการทำงานร่วมกันของโมเดล
บน Bittensor นักขุดจะได้รับรางวัลเป็นทรัพย์สินดั้งเดิมของเครือข่าย TAO สำหรับการให้บริการอัจฉริยะแก่เครือข่ายผ่านโมเดล ML ที่ไม่เหมือนใคร เมื่อฝึกฝนโมเดลของพวกเขาบนเครือข่าย นักขุดจะแลกเปลี่ยนข้อมูลกับนักขุดคนอื่นๆ เพื่อเร่งการเรียนรู้ของพวกเขา ด้วยการปักหลัก TAO ผู้ใช้สามารถใช้ข้อมูลอัจฉริยะของเครือข่าย Bittensor ทั้งหมดและปรับกิจกรรมของพวกเขาตามความต้องการ ซึ่งก่อให้เกิดตลาดข่าวกรอง P2P นอกจากนี้ยังสามารถสร้างแอปพลิเคชันบนสมาร์ทเลเยอร์ของเครือข่ายผ่านตัวตรวจสอบความถูกต้องของเครือข่าย
Bittensor ทำงานอย่างไร
Bittensor เป็นโปรโตคอล P2P แบบโอเพ่นซอร์สที่ใช้การผสมของผู้เชี่ยวชาญ (MoE) แบบกระจายอำนาจ ซึ่งเป็นเทคนิค ML ที่รวมโมเดลหลายตัวที่เชี่ยวชาญสำหรับปัญหาที่แตกต่างกันเพื่อสร้างโมเดลโดยรวมที่แม่นยำยิ่งขึ้น สิ่งนี้ทำได้โดยการฝึกอบรมโมเดลการกำหนดเส้นทางที่เรียกว่า gating layer ซึ่งได้รับการฝึกฝนในชุดโมเดลผู้เชี่ยวชาญเพื่อเรียนรู้วิธีกำหนดเส้นทางอินพุตอย่างชาญฉลาดเพื่อสร้างเอาต์พุตที่เหมาะสมที่สุด เพื่อให้บรรลุเป้าหมายนี้ เครื่องมือตรวจสอบความถูกต้องจะสร้างการรวมระหว่างโมเดลที่เสริมซึ่งกันและกันแบบไดนามิก การคำนวณแบบกระจัดกระจายใช้เพื่อแก้ปัญหาคอขวดของเวลาแฝง
สิ่งจูงใจของ Bittensor ดึงดูดโมเดลเฉพาะเข้ามาผสมผสานและมีบทบาทเฉพาะในการแก้ปัญหาที่ใหญ่กว่าที่กำหนดโดยผู้มีส่วนได้ส่วนเสีย นักขุดแต่ละคนเป็นตัวแทนของโมเดลที่ไม่เหมือนใคร (โครงข่ายประสาทเทียม) และ Bittensor ดำเนินการเป็นโมเดลที่ทำงานร่วมกันด้วยตนเอง ซึ่งควบคุมโดยระบบตลาดอัจฉริยะที่ไม่ได้รับอนุญาต
ผู้ตรวจสอบ
ผู้ตรวจสอบ
บน Bittensor ตัวตรวจสอบความถูกต้องทำหน้าที่เป็นชั้นเกทสำหรับโมเดล MoE ของเครือข่าย ทำหน้าที่เป็น API ที่ฝึกได้ และเปิดใช้งานการพัฒนาแอปพลิเคชันบนเครือข่าย การเดิมพันของพวกเขาควบคุมภูมิทัศน์ของสิ่งจูงใจและกำหนดปัญหาที่คนงานเหมืองแก้ไข ผู้ตรวจสอบเข้าใจคุณค่าที่นักขุดมอบให้เพื่อให้รางวัลแก่พวกเขาตามนั้นและบรรลุฉันทามติในการจัดอันดับ นักขุดที่มีอันดับสูงกว่าจะได้รับส่วนแบ่งที่สูงขึ้นจากรางวัลบล็อคเงินเฟ้อ
นอกจากนี้ ผู้ตรวจสอบความถูกต้องยังได้รับแรงจูงใจให้ค้นพบและประเมินโมเดลอย่างตรงไปตรงมาและมีประสิทธิภาพ เนื่องจากพวกเขาได้รับพันธบัตรจากนักขุดที่ติดอันดับสูงสุดและรับรางวัลส่วนหนึ่งในอนาคต สิ่งนี้สร้างกลไกอย่างมีประสิทธิภาพที่นักขุดจะ "ผูกมัด" ตัวเองกับอันดับนักขุดของตนในเชิงเศรษฐศาสตร์ กลไกฉันทามติของโปรโตคอลได้รับการออกแบบมาเพื่อต่อต้านการสมรู้ร่วมคิดโดยมากถึง 50% ของการแชร์เครือข่าย ทำให้เป็นไปไม่ได้ทางการเงินที่จะจัดอันดับนักขุดของตนเองอย่างไม่สุจริตให้สูง
คนขุดแร่
นักขุดบนเครือข่ายได้รับการฝึกอบรมและอนุมาน พวกเขาเลือกแลกเปลี่ยนข้อมูลกับเพื่อนร่วมงานตามความเชี่ยวชาญของพวกเขา และอัปเดตน้ำหนักของแบบจำลองตามนั้น เมื่อแลกเปลี่ยนข้อความ นักขุดจะจัดลำดับความสำคัญของคำร้องขอของ Validator ตามสัดส่วนเดิมพันของพวกเขา ขณะนี้มีผู้ขุด 3523 คนออนไลน์
การแลกเปลี่ยนข้อมูลระหว่างนักขุดบนเครือข่าย Bittensor ช่วยให้สามารถสร้างโมเดล AI ที่มีประสิทธิภาพมากขึ้น เนื่องจากนักขุดสามารถใช้ความเชี่ยวชาญของเพื่อนร่วมงานเพื่อปรับปรุงโมเดลของตนเองได้ สิ่งนี้นำความสามารถในการจัดองค์ประกอบมารวมเข้ากับพื้นที่ AI โดยพื้นฐานแล้ว ซึ่งสามารถเชื่อมต่อโมเดล ML ต่างๆ เพื่อสร้างระบบ AI ที่ซับซ้อนมากขึ้น
ปัญญาผสม
สรุป
สรุป
เมื่อระบบนิเวศของแมชชีนเลิร์นนิงแบบกระจายศูนย์เติบโตขึ้น ก็น่าจะมีการทำงานร่วมกันระหว่างคอมพิวเตอร์ต่างๆ และเครือข่ายอัจฉริยะ ตัวอย่างเช่น สามารถใช้ Gensyn และ Together เป็นเลเยอร์การประสานงานฮาร์ดแวร์ของระบบนิเวศ AI และ Bittensor สามารถใช้เป็นเลเยอร์การประสานงานอัจฉริยะ
ในด้านอุปทาน นักขุดคริปโตสาธารณะขนาดใหญ่ที่เคยขุด ETH ได้แสดงความสนใจอย่างมากในการสนับสนุนทรัพยากรให้กับเครือข่ายคอมพิวเตอร์แบบกระจายอำนาจ ตัวอย่างเช่น Akash ได้รับข้อผูกมัดสำหรับ GPU 1 ล้านเครื่องจากนักขุดขนาดใหญ่ก่อนการเปิดตัว GPU เครือข่ายของพวกเขา นอกจากนี้ Foundry ซึ่งเป็นหนึ่งในผู้ขุด Bitcoin เอกชนรายใหญ่กว่า ได้ขุดบน Bittensor แล้ว
ทีมงานที่อยู่เบื้องหลังโครงการที่กล่าวถึงในรายงานนี้ไม่ได้เป็นเพียงการสร้างเครือข่ายที่ใช้การเข้ารหัสลับสำหรับการโฆษณา แต่ทีมนักวิจัยและวิศวกร AI ที่ตระหนักถึงศักยภาพของการเข้ารหัสลับในการแก้ปัญหาในอุตสาหกรรมของตน
ด้วยการปรับปรุงประสิทธิภาพการฝึกอบรม การรวมทรัพยากร และการเปิดโอกาสให้ผู้คนจำนวนมากขึ้นมีส่วนร่วมในโมเดล AI ขนาดใหญ่ เครือข่าย ML แบบกระจายอำนาจสามารถเร่งการพัฒนา AI และช่วยให้เราสามารถปลดล็อกปัญญาประดิษฐ์ทั่วไปได้เร็วขึ้นในอนาคต


