
A16z: โอกาสและความท้าทายที่ AI เจเนอเรทีฟต้องเผชิญ
ที่มา: Alpha Rabbit Research Notes
ที่มา: Alpha Rabbit Research Notes
แปลต้นฉบับ: Alpha Rabbit
A16Z เพิ่งโพสต์บทความที่น่าสนใจอีกเรื่องหนึ่ง โดยพูดถึงสิ่งที่พวกเขาคิดการจับค่า AI เชิงกำเนิดคำถาม เช่น อะไรคือปัญหาในปัจจุบันในการทำการค้าของ generative AI? การจับมูลค่าสูงสุดอยู่ที่ไหน ผู้เขียนได้อธิบายเนื้อหาบางส่วนหลังจากแปลแล้ว
บทความนี้ประกอบด้วยสองส่วนหลัก: ส่วนแรกประกอบด้วยข้อสังเกตของ A16Z เกี่ยวกับเส้นทางปัจจุบันของ AI เชิงกำเนิด และปัญหาที่มีอยู่ ส่วนที่สองอธิบายว่าส่วนใดที่สามารถจับค่าที่ยิ่งใหญ่ที่สุดนอกเหนือจากปัญหา ไม่ต้องสงสัยเลยว่าเป็นรากฐานของโลก สิ่งอำนวยความสะดวก(โปรดทราบ: ส่วนใหญ่เป็น A16Z Portofolio โปรดอ่านอย่างมีวัตถุประสงค์และมีเหตุผล บทความนี้ไม่ถือเป็นคำแนะนำการลงทุนหรือคำแนะนำสำหรับโครงการ)
ชื่อระดับแรก
AI กำเนิดคืออะไร?
ชื่อระดับแรก
ส่วนที่ 1: การสังเกตและการคาดคะเน
แอปพลิเคชันปัญญาประดิษฐ์กำลังขยายขนาดอย่างรวดเร็ว แต่การรักษาไว้นั้นไม่ง่ายนัก และไม่ใช่ทุกคนที่จะสร้างขนาดเชิงพาณิชย์ได้
ช่วงเริ่มต้นของเทคโนโลยี AI เชิงกำเนิดได้เกิดขึ้นแล้ว:
ตัวอย่างเช่น สตาร์ทอัพด้าน AI ที่เพิ่งตั้งไข่หลายร้อยรายกำลังเร่งเข้าสู่ตลาดเพื่อเริ่มพัฒนาโมเดลพื้นฐานและสร้างแอปพลิเคชัน โครงสร้างพื้นฐาน และเครื่องมือแบบ AI-native
แน่นอนว่าจะมีเทรนด์เทคโนโลยีที่ร้อนแรงมากมาย และจะมีกรณีของการโฆษณาเกินจริง แต่ความเฟื่องฟูของปัญญาประดิษฐ์เชิงสร้างสรรค์ทำให้หลายบริษัทมีรายได้จริง
ตัวอย่างเช่น โมเดลอย่าง Stable Diffusion และ ChatGPT สร้างสถิติประวัติการเติบโตของผู้ใช้ แอปบางแอปทำรายได้ต่อปีถึง 100 ล้านดอลลาร์ภายในเวลาไม่ถึงหนึ่งปีหลังจากเปิดตัว และประสิทธิภาพของโมเดล AI ในบางลำดับงานที่สูงกว่าประสิทธิภาพของมนุษย์
เราพบว่ามีการปรับเปลี่ยนกระบวนทัศน์ทางเทคโนโลยี แต่,คำถามสำคัญที่ต้องศึกษาคือมูลค่าจะสร้างจากที่ใดในตลาดทั้งหมด?
ในปีที่ผ่านมา เราได้พูดคุยกับผู้ก่อตั้งสตาร์ทอัพด้าน AI และผู้เชี่ยวชาญด้าน AI ในบริษัทขนาดใหญ่หลายสิบราย เราสังเกตเห็นว่าจนถึงตอนนี้ ผู้ให้บริการโครงสร้างพื้นฐานมีแนวโน้มที่จะเป็นผู้ชนะรายใหญ่ที่สุดในตลาดนี้ เนื่องจากโครงสร้างพื้นฐานสามารถได้รับมูลค่าการซื้อขายและรายได้มากที่สุดผ่านกลุ่ม AI เชิงกำเนิดทั้งหมด
แม้ว่าการเติบโตของรายได้ของบริษัทที่เน้นการพัฒนาแอปพลิเคชันจะรวดเร็วมาก แต่บริษัทเหล่านี้มักมีจุดอ่อนในแง่ของการรักษาผู้ใช้ ความแตกต่างของผลิตภัณฑ์ และอัตรากำไรขั้นต้นอย่างไรก็ตาม ซัพพลายเออร์โมเดลส่วนใหญ่ยังไม่เชี่ยวชาญความสามารถในการทำการค้าขนาดใหญ่
เพื่อให้แม่นยำยิ่งขึ้น บริษัทเหล่านั้นที่สามารถสร้างมูลค่าได้มากที่สุด เช่น ความสามารถในการฝึกอบรมแบบจำลองปัญญาประดิษฐ์เชิงสร้างสรรค์และใช้เทคโนโลยีนี้กับแอปพลิเคชันใหม่ ๆ ยังไม่ได้ใช้ประโยชน์จากมูลค่าส่วนใหญ่ในอุตสาหกรรมอย่างเต็มที่ ดังนั้นจึงไม่ง่ายนักที่จะคาดการณ์แนวโน้มของอุตสาหกรรมที่อยู่เบื้องหลัง
อย่างไรก็ตาม สิ่งสำคัญคือต้องหาวิธีทำความเข้าใจว่าส่วนใดของกลุ่มอุตสาหกรรมทั้งหมดสามารถสร้างความแตกต่างและป้องกันได้อย่างแท้จริง เนื่องจากส่วนนี้อาจมีนัยต่อโครงสร้างตลาดโดยรวม (เช่น การพัฒนาบริษัทในแนวนอนและแนวตั้ง) และตัวขับเคลื่อนมูลค่าในระยะยาว (เช่นอัตรากำไรและการรักษาผู้ใช้) มีผลกระทบอย่างมาก
แต่จนถึงตอนนี้ การหาการป้องกันเชิงโครงสร้างบนสแต็ก (ของ AI เชิงกำเนิด) นั้นเป็นเรื่องยาก นอกเหนือจากคูเมืองทางธุรกิจแบบดั้งเดิมของบริษัทที่ดำรงตำแหน่งอยู่
ชื่อเรื่องรอง
กลุ่มเทคโนโลยี: โครงสร้างพื้นฐาน โมเดล AI และแอปพลิเคชัน
เพื่อทำความเข้าใจว่าการติดตามและตลาดของปัญญาประดิษฐ์กำเนิดเกิดขึ้นได้อย่างไร ก่อนอื่นเราต้องกำหนดสแต็กปัจจุบันของอุตสาหกรรมทั้งหมด:
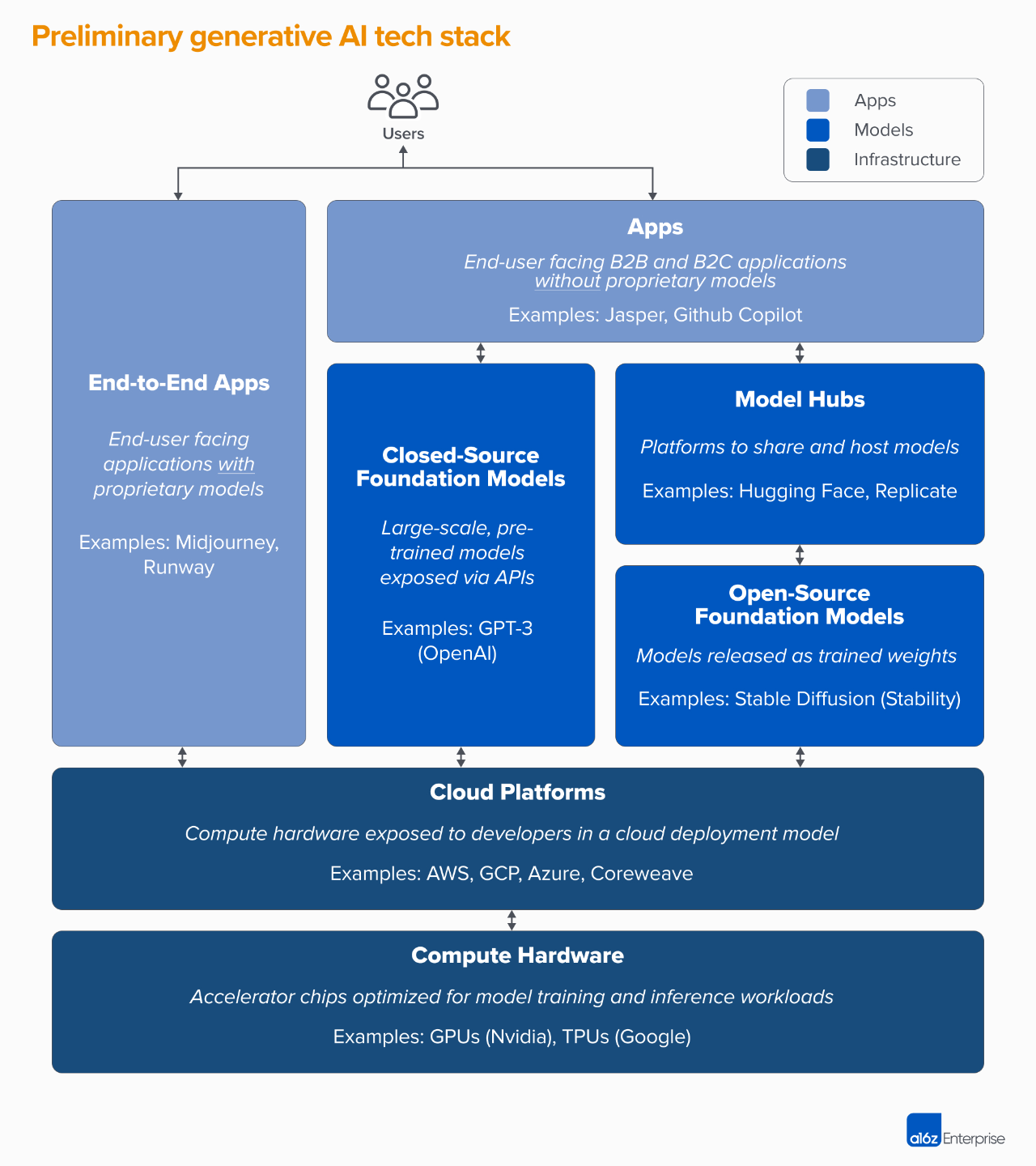
สแต็ค AI กำเนิดทั้งหมดสามารถแบ่งออกเป็นสามชั้น:
1. ผสานรวมโมเดล AI กำเนิดเข้ากับแอปพลิเคชันผลิตภัณฑ์ที่ผู้ใช้เผชิญหน้า โดยปกติแล้วจะใช้ไปป์ไลน์โมเดลของคุณเอง ("แอปพลิเคชันแบบ end-to-end") หรือพึ่งพา API ของบุคคลที่สาม
(หมายเหตุสำหรับบันทึกการวิจัยของ Alpha Rabbit: ท่อส่งโมเดลที่เรากำลังพูดถึงในที่นี้หมายถึงเอาต์พุตของโมเดลหนึ่งเป็นอินพุตของโมเดลถัดไป)
2. โมเดลเพื่อขับเคลื่อนผลิตภัณฑ์ AI ซึ่งมีให้ในรูปแบบ API ที่เป็นกรรมสิทธิ์หรือจุดตรวจสอบโอเพ่นซอร์ส (ซึ่งต้องใช้โซลูชันโฮสต์)
(หมายเหตุ: ส่วนนี้ระบุว่าวิธีการสร้างแบบจำลองทั้งหมดและแบบจำลองที่ผ่านการฝึกอบรมล่วงหน้า (เรียกอีกอย่างว่าจุดตรวจสอบ) นั้นเปิดอยู่ หรือวิธีการสร้างแบบจำลองทั้งหมดและแบบจำลองที่ได้รับการฝึกอบรมล่วงหน้าจำเป็นต้องเก็บเป็นความลับ และ API อินเทอร์เฟซเดียวเท่านั้นที่เปิดอยู่ หากเป็นแบบเดิม คุณต้องเรียกใช้การฝึกอบรม/การปรับละเอียด/การอนุมานด้วยตัวเอง ดังนั้นคุณต้องรู้ว่าสภาพแวดล้อมประเภทใดและฮาร์ดแวร์ประเภทใดที่สามารถรันได้ ดังนั้นบางคนจึงต้องการ เพื่อจัดหาแพลตฟอร์มโฮสติ้งเพื่อจัดการกับสภาพแวดล้อมที่รันโมเดล)
3. ผู้ให้บริการโครงสร้างพื้นฐาน (เช่น แพลตฟอร์มคลาวด์และผู้ผลิตฮาร์ดแวร์) ที่รันเวิร์กโหลดการฝึกอบรมและการอนุมานสำหรับโมเดล AI เชิงกำเนิด
โปรดทราบว่าสิ่งที่เรากำลังพูดถึงนี้ไม่ใช่แผนที่เชิงนิเวศวิทยาของตลาดทั้งหมด แต่เป็นกรอบการวิเคราะห์ตลาด บทความนี้แสดงตัวอย่างบางส่วนของผู้ผลิตที่มีชื่อเสียงในแต่ละประเภท แต่ไม่รวมทั้งหมด ล่าสุด แอปพลิเคชัน AIGC อันทรงพลังยังไม่ได้กล่าวถึงเครื่องมือ MLops หรือ LLMops ในเชิงลึก เนื่องจากพื้นที่นี้ยังไม่บรรลุมาตรฐานที่สมบูรณ์และเราจะหารือต่อไปเมื่อเรามีโอกาส
คลื่นลูกแรกของแอปพลิเคชั่น AI เชิงกำเนิดกำลังเริ่มขยายขนาด แต่ไม่ง่ายที่จะรักษาและแยกความแตกต่าง
ในวัฏจักรของเทคโนโลยีก่อนหน้านี้ มุมมองแบบดั้งเดิมน่าจะเป็นการสร้างบริษัทขนาดใหญ่ที่เป็นอิสระ คุณต้องมีลูกค้าปลายทาง โดยที่ลูกค้าปลายทางรวมถึงผู้บริโภครายบุคคลและผู้ซื้อ B2B
เนื่องจากมุมมองแบบดั้งเดิมนี้ ทุกคนจึงมักคิดว่าโอกาสที่ใหญ่ที่สุดในการสร้างปัญญาประดิษฐ์นั้นอยู่ในบริษัทต่างๆ ที่สามารถสร้างแอปพลิเคชันที่เน้นผู้ใช้ปลายทางได้
แต่จนถึงตอนนี้ มันไม่จำเป็นต้องเป็นอย่างนั้นเสมอไป
การเติบโตของแอปพลิเคชัน AI เชิงสร้างสรรค์นั้นเป็นปรากฎการณ์ โดยส่วนใหญ่ได้รับแรงหนุนจากกรณีการใช้งานที่แปลกใหม่ เช่น การสร้างภาพ การเขียนคำโฆษณา และการเขียนโค้ด และรายได้ต่อปีของผลิตภัณฑ์ทั้งสามประเภทนี้เกิน 100 ล้านดอลลาร์สหรัฐ
อย่างไรก็ตาม การเติบโตเพียงอย่างเดียวไม่เพียงพอที่จะสร้างบริษัทซอฟต์แวร์ที่ยั่งยืน สิ่งสำคัญคือ การเติบโตนี้ต้องมีผลกำไร กล่าวคือ ผู้ใช้และลูกค้าสามารถสร้างผลกำไรได้เมื่อสมัครใช้งาน (กำไรขั้นต้นสูง) และกำไรนี้จะต้องยั่งยืน ในระยะยาว ยั่งยืน (อัตราการคงอยู่สูง)
ในกรณีที่ไม่มีความแตกต่างทางเทคนิคที่ชัดเจนระหว่างบริษัท แอปพลิเคชัน B2B และ B2C จะประสบความสำเร็จได้ก็ต่อเมื่อมีเอฟเฟกต์เครือข่าย ข้อได้เปรียบด้านข้อมูล หรือการสร้างเวิร์กโฟลว์ที่ซับซ้อนขึ้นเรื่อยๆ
อย่างไรก็ตาม ในด้านของปัญญาประดิษฐ์เชิงกำเนิด สมมติฐานข้างต้นอาจไม่ถือเป็นจริงในบรรดาบริษัทสตาร์ทอัพที่เราทำการวิจัยซึ่งสร้างแอปปัญญาประดิษฐ์เชิงกำเนิด อัตรากำไรขั้นต้นนั้นแตกต่างกันมาก มีเพียงไม่กี่บริษัทเท่านั้นที่สามารถสูงถึง 90% และบริษัทส่วนใหญ่มีอัตรากำไรขั้นต้นต่ำถึง 50-60% สิ่งนี้ได้รับผลกระทบเป็นหลัก ตามราคาของโมเดล
แม้ว่าเราจะเห็นการเติบโตบนสุดของช่องทาง (Top-of-funnel) ในปัจจุบันอย่างไรก็ตาม ยังไม่มีความชัดเจนว่ากลยุทธ์การหาลูกค้าปัจจุบันจะยั่งยืนได้หรือไม่เนื่องจากฉันได้เห็นประสิทธิภาพการได้รับค่าตอบแทนจำนวนมากและการรักษาลูกค้าเริ่มลดลง
แอปพลิเคชั่นจำนวนมากในตลาดขาดความแตกต่างเนื่องจากแอปพลิเคชั่นเหล่านี้ส่วนใหญ่อาศัยโมเดลปัญญาประดิษฐ์พื้นฐานที่คล้ายกันและไม่พบแอปพลิเคชั่นและข้อมูลที่เป็นอันตรายซึ่งเห็นได้ชัดว่ามีเอฟเฟกต์เครือข่ายพิเศษและยากที่คู่แข่งรายอื่นจะทำซ้ำ กระบวนการทำงาน
ชื่อเรื่องรอง
มองไปในอนาคต แอพพลิเคชั่น generative AI เผชิญปัญหาอะไรบ้าง?
ในการรวมแนวดิ่ง ("รุ่น + ใบสมัคร")ด้าน
หากใช้โมเดลปัญญาประดิษฐ์เป็นบริการสำหรับผู้บริโภค นักพัฒนาแอปพลิเคชันสามารถทำซ้ำได้อย่างรวดเร็วด้วยโมเดลทีมขนาดเล็ก และค่อยๆ แทนที่ซัพพลายเออร์โมเดลด้วยความก้าวหน้าของเทคโนโลยี แต่นักพัฒนารายอื่น ๆ ไม่เห็นด้วย พวกเขาเชื่อว่าผลิตภัณฑ์คือแบบจำลองและการฝึกอบรมตั้งแต่เริ่มต้นเป็นวิธีเดียวที่จะสร้างการป้องกันซึ่งหมายถึงการฝึกอบรมซ้ำอย่างต่อเนื่องเกี่ยวกับข้อมูลผลิตภัณฑ์ที่เป็นกรรมสิทธิ์ แต่สิ่งนี้ต้องใช้เงินทุนที่สูงขึ้น และต้นทุนของทีมผลิตภัณฑ์ที่มั่นคง
สร้างคุณสมบัติและแอพ
ผลิตภัณฑ์ Generative AI มีหลายรูปแบบ: แอปเดสก์ท็อป แอปมือถือ ปลั๊กอิน Figma/Photoshop ส่วนขยาย Chrome...แม้แต่บอท Discord การผสานรวมผลิตภัณฑ์ปัญญาประดิษฐ์ที่ผู้ใช้ใช้งานอยู่แล้วและมีนิสัยนั้นง่ายกว่า เนื่องจากส่วนต่อประสานกับผู้ใช้นั้นง่ายกว่า แต่บริษัทใดในจำนวนนี้จะกลายเป็นบริษัทอิสระ? อันไหนที่จะถูกดูดซับโดยยักษ์ใหญ่ด้าน AI Microsoft หรือ Google?
จะสอดคล้องกับ Hyper Cycle ที่ Gartner ปล่อยออกมาหรือไม่?
ชื่อระดับแรก
ส่วนที่ II: การใช้งานเชิงพาณิชย์ขนาดใหญ่ของปัญญาประดิษฐ์เชิงกำเนิด
ในส่วนแรก เราได้พูดถึงกองซ้อนของ AI เชิงกำเนิดในปัจจุบันและปัญหาบางอย่างที่เผชิญอยู่ ส่วนที่สองดำเนินต่อไป:
เกี่ยวกับการใช้งานเชิงพาณิชย์ขนาดใหญ่ของปัญญาประดิษฐ์เชิงกำเนิด
และผู้ชนะ Takes All จะได้รับคุณค่ามากที่สุดจากที่ใด
มีคำถามอื่นๆ ข้างต้นหรือไม่
ปัญหาในอุตสาหกรรมปัจจุบันคืออะไร?
แม้ว่าการประดิษฐ์แบบจำลองจะทำให้เทคโนโลยีปัญญาประดิษฐ์กำเนิดเป็นที่รู้จักอย่างกว้างขวาง แต่ก็ยังไม่ถึงระดับของการใช้งานเชิงพาณิชย์ขนาดใหญ่
เราจะไม่ได้เห็นเทคนิค AI เชิงกำเนิดที่ประสบความสำเร็จเช่นนี้ในวันนี้ หากปราศจากความพยายามในการวิจัยของบริษัทต่างๆ เช่น Google, OpenAI และ Stability และความพยายามด้านวิศวกรรมของบริษัทเหล่านี้ ไม่ว่าจะเป็นสถาปัตยกรรมโมเดลใหม่ที่เราได้เห็น หรือการขยายไปป์ไลน์การฝึกอบรม สาเหตุหลักมาจากความสามารถอันทรงพลังของโมเดลภาษาขนาดใหญ่ (LLM) และโมเดลรูปภาพในปัจจุบัน
อย่างไรก็ตาม หากเราดูรายได้ของบริษัทเหล่านี้ เทียบกับปริมาณการใช้งานจำนวนมากและความนิยมของตลาด รายได้ไม่สูงมากนัก ในแง่ของการสร้างภาพ ชุมชนของ Stable Diffusion ได้ระเบิดขึ้นแล้ว แต่จุดตรวจสอบหลักของ Stability เปิดอยู่ และนั่นคือหลักสำคัญของธุรกิจ Stability
ในแง่ของรูปแบบภาษาธรรมชาติ OpenAI เป็นที่รู้จักสำหรับ GPT-3/3.5 และ ChatGPTแต่จนถึงตอนนี้ มีแอปนักฆ่าที่สร้างบน OpenAI น้อยลง และราคาก็ลดลงเพียงครั้งเดียว (ดูด้านล่าง)
(คิดว่าทำไมลดราคา?)
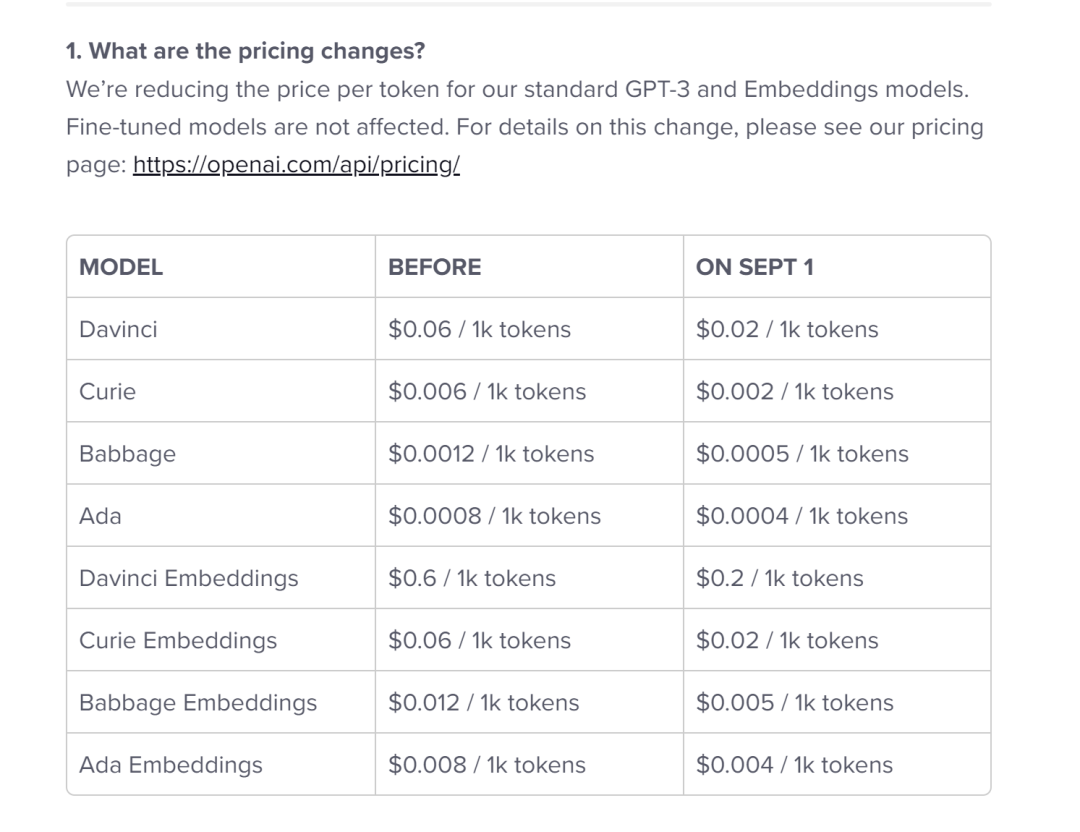
แน่นอนว่าสิ่งเหล่านี้อาจเป็นเพียงปรากฏการณ์ชั่วคราวในปัจจุบัน Stability เป็นสตาร์ทอัพรูปแบบใหม่ไม่เน้นเชิงพาณิชย์ OpenAI มีศักยภาพในการมีธุรกิจขนาดใหญ่ และเมื่อมีการสร้างแอปนักฆ่ามากขึ้น OpenAI สามารถสร้างรายได้ส่วนสำคัญของอุตสาหกรรมภาษาธรรมชาติทั้งหมดโดยเฉพาะอย่างยิ่งหากการรวม OpenAI เข้ากับพอร์ตโฟลิโอของ Microsoft เป็นไปได้ด้วยดี การใช้โมเดลเหล่านี้สูงอาจนำไปสู่รายได้มหาศาล
แต่ก็มีอันตรายซ่อนอยู่เช่นกัน:
ตัวอย่างเช่น หากโมเดลเป็นแบบโอเพนซอร์ส ทุกคนสามารถโฮสต์โมเดลนั้นได้ รวมถึงบริษัทอื่นๆ ที่ไม่ต้องแบกรับค่าใช้จ่ายในการฝึกอบรมโมเดลขนาดใหญ่ (หลายพันหรือหลายร้อยล้านดอลลาร์)
และยังไม่เป็นที่แน่ชัดว่าโมเดลแบบโอเพนซอร์ซสามารถคงความโดดเด่นไว้ได้อย่างไม่มีกำหนด ตัวอย่างเช่น สมมติว่าเราเริ่มเห็น LLM โมเดลขนาดใหญ่ที่สร้างโดยบริษัทต่างๆ เช่น Anthropic, Cohere และ Character.ai ที่เข้าใกล้ระดับประสิทธิภาพของ OpenAI ได้รับการฝึกฝนในชุดข้อมูลที่คล้ายกัน (เช่น อินเทอร์เน็ต) และใช้สถาปัตยกรรมโมเดลที่คล้ายกัน
ตัวอย่าง Stable Diffusion แสดงให้เห็นว่าหากโมเดลโอเพ่นซอร์สบรรลุประสิทธิภาพและการสนับสนุนจากชุมชนในระดับหนึ่ง ทางเลือกอื่นในเส้นทางเดียวกันอาจพบว่าเป็นการยากที่จะแข่งขัน
บางทีประโยชน์ที่ชัดเจนที่สุดสำหรับผู้ให้บริการโมเดลคือการทำการค้าที่เกี่ยวข้องกับโฮสติ้ง(หมายเหตุ: นี่หมายถึงการเปิดวิธีการสร้างของแบบจำลองทั้งหมดและแบบจำลองที่ผ่านการฝึกอบรมล่วงหน้า (หรือที่เรียกว่าจุดตรวจ) ที่กล่าวถึงในบทความก่อนหน้านี้ หรือการเก็บวิธีการสร้างแบบจำลองทั้งหมดและแบบจำลองที่ผ่านการฝึกอบรมไว้เป็นความลับ API อินเทอร์เฟซเดียวเท่านั้นที่เปิดอยู่ หากเป็นแบบแรก คุณต้องเรียกใช้การฝึกอบรม/ปรับแต่ง/ให้เหตุผลด้วยตัวเอง ดังนั้น คุณจำเป็นต้องรู้ว่าสภาพแวดล้อมประเภทใดและฮาร์ดแวร์ประเภทใดที่สามารถเรียกใช้ได้ แพลตฟอร์มการโฮสต์เพื่อประมวลผลสภาพแวดล้อมการทำงานของแบบจำลอง);
และความต้องการ API ที่เป็นกรรมสิทธิ์ (เช่น จาก OpenAI) ก็เพิ่มขึ้นอย่างรวดเร็ว ตัวอย่างเช่น บริการโฮสติ้งโมเดลแบบโอเพ่นซอร์ส (เช่น Hugging Face และ Replicate) กลายเป็นฮับสำหรับการแชร์และรวมโมเดลได้อย่างง่ายดาย แม้แต่การสร้างเอฟเฟกต์เครือข่ายทางอ้อมระหว่างผู้ผลิตโมเดลและผู้บริโภค นอกจากนี้ยังมีข้อสันนิษฐานที่หนักแน่นว่าเป็นไปได้ที่จะบรรลุผลกำไรสำหรับบริษัทผ่านการปรับข้อตกลงและข้อตกลงสัญญากับลูกค้าองค์กร
อย่างไรก็ตาม ผู้ให้บริการโมเดลยังคงประสบปัญหา:
ทำการค้ามุมมองทั่วไปคือประสิทธิภาพของโมเดล AI จะมาบรรจบกันเมื่อเวลาผ่านไป เมื่อพูดคุยกับนักพัฒนาแอป ประสิทธิภาพที่สม่ำเสมอในระดับนี้ไม่เคยเกิดขึ้นมาก่อน เนื่องจากมีผู้เล่นชั้นนำทั้งในรูปแบบข้อความและรูปภาพ ข้อได้เปรียบของบริษัทเหล่านี้ไม่ได้อยู่ที่สถาปัตยกรรมแบบจำลองที่ไม่เหมือนใคร แต่ขึ้นอยู่กับความต้องการเงินทุนสูง ข้อมูลปฏิสัมพันธ์ของผลิตภัณฑ์ที่เป็นกรรมสิทธิ์ และความสามารถของ AI ที่หายาก
แต่สิ่งเหล่านี้สามารถเป็นข้อได้เปรียบที่ยั่งยืนในระยะยาวสำหรับบริษัทได้หรือไม่?
เสี่ยงต่อการแยกตัวออกจากผู้จำหน่ายโมเดลการพึ่งพาซัพพลายเออร์แบบจำลองเป็นวิธีที่บริษัทแอปหลายแห่งเริ่มต้นและแม้แต่ขยายธุรกิจโดยใช้ซัพพลายเออร์ แต่เมื่อขยายขนาดได้แล้ว นักพัฒนาแอปจะมีแรงจูงใจในการสร้างและ/หรือโฮสต์โมเดลของตนเอง ผู้จำหน่ายโมเดลหลายรายมีการกระจายลูกค้าที่ไม่สม่ำเสมอ โดยมีแอปพลิเคชันจำนวนน้อยที่สร้างรายได้ส่วนใหญ่จะเกิดอะไรขึ้นหากลูกค้าเหล่านี้ไม่ใช้แบบจำลองของซัพพลายเออร์และหันไปพัฒนาแบบจำลองปัญญาประดิษฐ์ภายในของตนเอง
ทุนจะสำคัญไหม?วิสัยทัศน์ของ generative AI นั้นยอดเยี่ยมมากจนผู้จำหน่ายโมเดลจำนวนมากได้เริ่มรวมสินค้าสาธารณะเข้ากับภารกิจของพวกเขา สิ่งนี้ไม่ได้ขัดขวางการจัดหาเงินทุนของพวกเขาเลย แต่สิ่งที่ต้องพิจารณาคือผู้ขายแบบจำลองเต็มใจที่จะจับมูลค่าหรือไม่และควรได้รับหรือไม่
รับโครงสร้างพื้นฐานและรับโลก
ทุกอย่างใน Generative AI ใช้บริการ GPU (หรือ TPU) ที่โฮสต์บนคลาวด์ ไม่ว่าจะเป็นผู้จำหน่ายแบบจำลองหรือห้องปฏิบัติการวิจัย รันเวิร์กโหลดการฝึกอบรม หรือบริษัทโฮสติ้งที่เรียกใช้การอนุมาน/การปรับแต่ง FLOPS คือกุญแจสำคัญในการสร้าง AI
(หมายเหตุการวิจัย Alpha Rabbit: FLOPS เป็นคำย่อของการดำเนินการของจุดลอยตัวต่อวินาที ซึ่งหมายถึงจำนวนของการดำเนินการของจุดลอยตัวต่อวินาที ซึ่งเข้าใจว่าเป็นความเร็วในการคำนวณ เป็นตัวบ่งชี้เพื่อวัดประสิทธิภาพของฮาร์ดแวร์ โดยปกติเมื่อเราประเมิน แบบจำลอง ก่อนอื่นเราต้องดูที่ความแม่นยำ เมื่อความแม่นยำไม่เพียงพอ คุณจะบอกคนอื่นว่าแบบจำลองของฉันคาดการณ์ได้เร็วเพียงใด และหน่วยความจำมีขนาดเล็กเพียงใดเมื่อปรับใช้ มันไม่มีประโยชน์ แต่เมื่อแบบจำลองของคุณถึงความแม่นยำระดับหนึ่งหลังจาก ระดับจำเป็นต้องมีตัวบ่งชี้การประเมินเพิ่มเติมเพื่อประเมินแบบจำลอง:
ซึ่งรวมถึง:
1) กำลังการประมวลผลที่จำเป็นสำหรับการเผยแพร่ไปข้างหน้า ซึ่งสะท้อนถึงข้อกำหนดด้านประสิทธิภาพของฮาร์ดแวร์ เช่น GPU
2) จำนวนพารามิเตอร์ซึ่งสะท้อนถึงขนาดหน่วยความจำที่ถูกครอบครอง เหตุใดจึงต้องเพิ่มตัวบ่งชี้สองตัวนี้ เนื่องจากสิ่งนี้เกี่ยวข้องกับการใช้อัลกอริทึมแบบจำลองของคุณ ตัวอย่างเช่น หากคุณต้องการปรับใช้โมเดลการเรียนรู้เชิงลึกบนโทรศัพท์มือถือและรถยนต์ จะมีข้อกำหนดที่เข้มงวดเกี่ยวกับขนาดของโมเดลและพลังการประมวลผล ทุกคนต้องรู้ว่าพารามิเตอร์โมเดลคืออะไรและจะคำนวณอย่างไร แต่พลังการคำนวณที่จำเป็นสำหรับการเผยแพร่ไปข้างหน้าอาจยังเป็นที่น่าสงสัยอยู่เล็กน้อย นี่คือพลังการประมวลผลทั้งหมดที่จำเป็นสำหรับการเผยแพร่ไปข้างหน้า เป็นตัวเป็นตนโดย FLOPs
ข้อมูลอ้างอิง: Zhihu A Chai Ben Chai: https://zhuanlan.zhihu.com/p/137719986 )
ดังนั้นเงินจำนวนมากใน AI เชิงกำเนิดจึงตกเป็นของบริษัทโครงสร้างพื้นฐาน จากการประมาณการคร่าวๆ โดยเฉลี่ยแล้ว บริษัทแอปพลิเคชันใช้จ่ายประมาณ 20-40% ของรายได้ไปกับการอนุมานและการปรับแต่งอย่างละเอียดต่อลูกค้าหนึ่งราย และโดยทั่วไปรายได้ดังกล่าวจะจ่ายให้กับผู้ให้บริการระบบคลาวด์โดยตรงสำหรับอินสแตนซ์การประมวลผลหรือผู้ให้บริการโมเดลบุคคลที่สาม ซึ่งจะใช้จ่ายประมาณครึ่งหนึ่งของรายได้ไปกับโครงสร้างพื้นฐานระบบคลาวด์ดังนั้นเราจึงสามารถคาดการณ์ได้: 10-20% ของรายได้ AI ทั้งหมดในปัจจุบันไปที่ผู้ให้บริการระบบคลาวด์
นอกจากนี้ สตาร์ทอัพที่ฝึกฝนโมเดลของตนเองยังระดมเงินร่วมลงทุนได้หลายพันล้านดอลลาร์ และส่วนใหญ่ (มากถึง 80-90% ในรอบแรก) มักจะใช้จ่ายกับผู้ให้บริการระบบคลาวด์ บริษัทเทคโนโลยีหลายแห่งใช้เงินหลายร้อยล้านดอลลาร์ต่อปีในการฝึกอบรมแบบจำลอง ไม่ว่าจะกับผู้ให้บริการระบบคลาวด์ภายนอกหรือโดยตรงกับผู้ผลิตฮาร์ดแวร์
สำหรับตลาดที่เพิ่งตั้งไข่ของ AIGC ส่วนใหญ่ใช้จ่ายไปกับระบบคลาวด์หลักสามระบบ:Amazon Web Services (AWS), Google Cloud (GCP) และ Microsoft Azure ผู้ให้บริการคลาวด์เหล่านี้ร่วมกันใช้จ่ายมากกว่า 100 พันล้านเหรียญสหรัฐต่อปีในด้านการลงทุนเพื่อให้แน่ใจว่าพวกเขามีแพลตฟอร์มที่ครอบคลุม เชื่อถือได้ และคุ้มราคาที่สุด
โดยเฉพาะอย่างยิ่งในด้านของปัญญาประดิษฐ์เชิงกำเนิด ผู้จำหน่ายระบบคลาวด์เหล่านี้สามารถให้ความสำคัญกับฮาร์ดแวร์ที่หายาก (เช่น Nvidia A 100 และ H 100 GPU)
(หมายเหตุกระต่ายอัลฟ่า: A 100 มีลักษณะดังต่อไปนี้
อ่านบทความนี้ด้วย:ทำลาย | การตีความเกี่ยวกับการที่สหรัฐฯ หยุด Nvidia จากการขายผลิตภัณฑ์บางอย่างไปยังประเทศจีน 20220901

ผลที่ตามมาคือการแข่งขันเกิดขึ้นโดยที่ผู้ท้าชิงเช่น Oracle หรือสตาร์ทอัพเช่น Coreweave และ Lambda Labs ได้ขยายตัวด้วยโซลูชันที่มุ่งเป้าไปที่นักพัฒนาโมเดลขนาดใหญ่ในแง่ของต้นทุน การใช้งาน และการสนับสนุนส่วนบุคคล ในการแข่งขัน บริษัทเหล่านี้ยังเปิดเผย สิ่งที่เป็นนามธรรมของทรัพยากรที่ละเอียดกว่า (เช่น คอนเทนเนอร์) ในขณะที่ระบบคลาวด์ขนาดใหญ่มีเฉพาะอินสแตนซ์เครื่องเสมือนเนื่องจากข้อจำกัดของการจำลองเสมือนของ GPU
[หมายเหตุการวิจัยของ Alpha Rabbit: ตัวอย่างเช่น เมื่อเราต้องการซื้อของ ส่งข้อความ และใช้บริการธนาคารออนไลน์บนอินเทอร์เน็ต เราทุกคนกำลังโต้ตอบกับเซิร์ฟเวอร์บนคลาวด์ กล่าวคือ เมื่อเราใช้ไคลเอ็นต์ (โทรศัพท์มือถือ คอมพิวเตอร์ ไอแพด) เพื่อดำเนินการต่างๆ เราจำเป็นต้องส่งคำขอไปยังเซิร์ฟเวอร์ และการดำเนินการแต่ละอย่างต้องใช้เซิร์ฟเวอร์ที่เกี่ยวข้องในการประมวลผลคำขอแต่ละรายการ แล้วจึงส่งคืนการตอบกลับ
คำขอและการตอบสนองจำนวนมากจากผู้ใช้หลายพันคนในเวลาเดียวกันต้องใช้พลังการประมวลผลที่แข็งแกร่ง (ลองนึกถึงตอนที่เราซื้อของที่ Double Eleven ผู้ใช้จำนวนนับไม่ถ้วนสั่งซื้อพร้อมกันอย่างเมามัน แล้วตะกร้าสินค้าก็ค้างทันที) ในเวลานี้พลังของคอมพิวเตอร์มีความสำคัญมาก ดังที่เราได้กล่าวไว้ก่อนหน้านี้ว่า virtual machine เป็นส่วนหนึ่งของความสามารถในการคำนวณ เมื่อเราใช้ cloud computing solutions จากผู้ให้บริการ cloud เราสามารถเลือกใช้ virtual machine ตามความสามารถปัจจุบันและความต้องการขององค์กร
เครื่องเสมือนคืออะไร?
มันเป็นโปรแกรมจำลองระบบคอมพิวเตอร์ซึ่งสามารถจัดเตรียมฟังก์ชั่นของคอมพิวเตอร์จริงของเราในระบบที่แยกได้อย่างสมบูรณ์ เครื่องเสมือนของระบบสามารถจัดเตรียมแพลตฟอร์มระบบที่สมบูรณ์ที่สามารถเรียกใช้ระบบปฏิบัติการที่สมบูรณ์ เช่น ระบบ Windows ที่เราใช้ ระบบ MAC OS เป็นต้น โปรแกรมเวอร์ชวลแมชชีนคือโปรแกรมคอมพิวเตอร์ที่สามารถทำงานได้อย่างอิสระในโปรแกรมจำลอง กล่าวอีกนัยหนึ่ง หากคุณซื้อเครื่องเสมือนที่ให้บริการโดยผู้ให้บริการระบบคลาวด์ ก็เหมือนกับการซื้อที่ดินจากผู้ให้บริการระบบคลาวด์ จากนั้นคุณสามารถติดตั้งซอฟต์แวร์ต่างๆ และรันงานต่างๆ บนเครื่องเสมือนได้ เช่นเดียวกับเรา ซื้อเองก็เหมือนสร้างบ้านบนที่ดินที่ได้มา
คอนเทนเนอร์คืออะไร? ภาชนะที่เรามักเข้าใจว่าเป็นชามข้าว เครื่องใช้ และเครื่องมือต่างๆ เทคโนโลยีคอนเทนเนอร์ที่มักกล่าวถึงในด้านไอทีคืออะไร? จริงๆ แล้วคำนี้มาจากคำแปลของ Linux Container ในภาษาอังกฤษ คำว่า Container มีความหมายว่า container และ container (ในแง่อุปลักษณ์ทางเทคนิค ความหมายหลักของ container คือ container) แต่เนื่องจากคอนเทนเนอร์อ่านภาษาจีนได้ง่ายกว่า เราจึงใช้คอนเทนเนอร์ภาษาจีนเป็นคำทั่วไป หากคุณต้องการเข้าใจเทคโนโลยี Linux Container ให้ชัดเจน คุณสามารถจินตนาการถึงคอนเทนเนอร์ที่ท่าเรือขนส่งสินค้าริมทะเลหลังจากอ่านข้อความนี้

ตู้คอนเทนเนอร์ในท่าขนส่งสินค้าใช้สำหรับบรรทุกสินค้ามีลักษณะเป็นกล่องเหล็กที่ได้มาตรฐานตามข้อกำหนด ลักษณะของคอนเทนเนอร์คือเป็นสี่เหลี่ยมจัตุรัสทั้งหมดและรูปแบบเหมือนกันและสามารถวางซ้อนทับกันได้
ด้วยวิธีนี้สินค้าสามารถใส่ลงในคอนเทนเนอร์ขนส่งขนาดยักษ์และผู้ผลิตที่ต้องการขนส่งสินค้าสามารถขนส่งสินค้าได้อย่างรวดเร็วและสะดวกยิ่งขึ้นการเกิดขึ้นของคอนเทนเนอร์ทำให้บริการขนส่งมีประสิทธิภาพมากขึ้นสำหรับผู้ผลิต ตามบริการขนส่งที่สะดวกนี้ เพื่อให้ง่ายต่อการใช้งานในสภาพแวดล้อมของจีน แนวคิดของภาพลักษณ์ของคอนเทนเนอร์ถูกยกมาในโลกของคอมพิวเตอร์ 】
ในความเห็นของเรา ผู้ชนะที่ใหญ่ที่สุดใน AI เชิงกำเนิดจนถึงตอนนี้คือ Nvidia ซึ่งรันเวิร์กโหลด AI ส่วนใหญ่รายรับจาก GPU สำหรับศูนย์ข้อมูลของ Nvidia ที่ 3.8 พันล้านดอลลาร์ในไตรมาสที่สามของปีงบประมาณ 2023 ส่วนใหญ่มาจากกรณีการใช้งาน AI เชิงสร้างสรรค์
(GPU: หน่วยประมวลผลกราฟิก (อังกฤษ: graphics processing unit, ตัวย่อ: GPU) หรือที่เรียกว่าแกนแสดงผล, โปรเซสเซอร์ภาพ, ชิปแสดงผล เป็นหน่วยประมวลผลกราฟิกที่ออกแบบมาเป็นพิเศษสำหรับใช้ในคอมพิวเตอร์ส่วนบุคคล เวิร์กสเตชัน เกมคอนโซล และอุปกรณ์เคลื่อนที่บางรุ่น (เช่น คอมพิวเตอร์แท็บเล็ต) สมาร์ทโฟน เป็นต้น) เพื่อทำงานเกี่ยวกับภาพและกราฟิกบนไมโครโปรเซสเซอร์)
NVIDIA ได้สร้างกำแพงที่แข็งแกร่งรอบ ๆ ธุรกิจนี้ผ่านการลงทุนหลายทศวรรษในระบบนิเวศของ GPU และแอปพลิเคชันเชิงลึกในระยะยาวในด้านวิชาการ การวิเคราะห์เมื่อเร็วๆ นี้พบว่า GPU ของ Nvidia ถูกอ้างถึงในเอกสารการวิจัยบ่อยกว่าสตาร์ทอัพชิป AI ชั้นนำถึง 90 เท่า
แน่นอนว่ามีตัวเลือกฮาร์ดแวร์อื่นๆ อยู่ เช่น Google TPU, AMD Instinct GPU, ชิป AWS Inferentia และ Trainium และสตาร์ทอัพอย่าง Cerebras, Sambanova และ Graphcore
Intel เข้าสู่ตลาดด้วยชิป Habana ระดับไฮเอนด์และ GPU Ponte Vecchio แต่จนถึงตอนนี้ มีชิปรุ่นใหม่ของ Intel ไม่กี่ตัวที่สามารถครองส่วนแบ่งการตลาดที่สำคัญได้ ข้อยกเว้นที่โดดเด่นอีกสองข้อคือ Google ซึ่ง TPUs ได้รับแรงฉุดในชุมชนการเพิ่มจำนวนอย่างต่อเนื่องและข้อตกลง GCP ขนาดใหญ่ และ TSMC ซึ่งคิดว่าจะทำให้ชิปทั้งหมดอยู่ในรายการที่นี่ รวมถึง Nvidia GPUs (Intel ใช้ fab และ TSMC ของตัวเองเพื่อ ทำชิป)
สิ่งที่เราพบ: โครงสร้างพื้นฐานเป็นเลเยอร์ของสแต็กที่ให้ผลกำไร ถาวร และดูเหมือนป้องกันได้
อย่างไรก็ตาม คำถามที่บริษัทโครงสร้างพื้นฐานจำเป็นต้องตอบได้แก่:
แล้วภาระงานไร้สัญชาติล่ะ?
หมายความว่าไม่ว่าคุณจะเช่า GPU ของ Nvidia จากที่ใด ก็จะเหมือนกัน ปริมาณงาน AI ส่วนใหญ่เป็นแบบไร้สถานะ กล่าวคือ การอนุมานแบบจำลองไม่ต้องการฐานข้อมูลหรือที่เก็บข้อมูลที่แนบมา (หมายเหตุ: ไม่ต้องการที่เก็บข้อมูลภายนอกหรือฐานข้อมูล ยกเว้นสำหรับน้ำหนักของแบบจำลองเอง) ซึ่งหมายความว่าปริมาณงาน AI อาจโยกย้ายไปยังระบบคลาวด์ได้ง่ายกว่าปริมาณงานของแอปพลิเคชันแบบเดิม ในกรณีนี้ ผู้ให้บริการระบบคลาวด์สร้างความเหนียวแน่นที่ขัดขวางลูกค้าไม่ให้หันไปใช้ตัวเลือกที่ถูกกว่าได้อย่างไร
จะเป็นอย่างไรถ้าชิปไม่หายากอีกต่อไป
การกำหนดราคาโดยผู้ให้บริการระบบคลาวด์และ Nvidia เนื่องจาก GPU ขาดแคลน จึงมีราคาแพง ผู้ขายบอกเราว่าราคาจำหน่ายของ A 100 เพิ่มขึ้นอย่างต่อเนื่องตั้งแต่เปิดตัว ซึ่งเป็นเรื่องผิดปกติมากสำหรับฮาร์ดแวร์คอมพิวเตอร์ แล้วจะเกิดอะไรขึ้นกับผู้ให้บริการระบบคลาวด์เมื่อข้อจำกัดด้านอุปทานนี้ถูกขจัดออกไปในที่สุดผ่านการผลิตที่เพิ่มขึ้นและ/หรือการนำแพลตฟอร์มฮาร์ดแวร์ใหม่มาใช้
Xinjinyun สามารถฝ่าวงล้อมได้หรือไม่?
เราคิดว่าคลาวด์แนวตั้งจะชิงส่วนแบ่งการตลาดจาก Big Three ด้วยผลิตภัณฑ์ที่เชี่ยวชาญกว่า จนถึงตอนนี้ใน AI ผู้เล่นระบบคลาวด์ใหม่ได้รับแรงผลักดันจากความแตกต่างของเทคโนโลยีเล็กน้อยและการสนับสนุนของ Nvidia ตัวอย่างเช่น ผู้ให้บริการคลาวด์ที่มีอยู่เป็นทั้งลูกค้ารายใหญ่ที่สุดและคู่แข่งรายใหม่ ดังนั้น คำถามระยะยาวสำหรับบริษัทคลาวด์ที่เกิดใหม่เหล่านี้คือ พวกเขาสามารถเอาชนะข้อได้เปรียบด้านขนาดของยักษ์ใหญ่ทั้งสามได้หรือไม่
แล้วมูลค่าสะสมมากที่สุดอยู่ที่ใด? เราจะโหวตอย่างไรเพื่อให้ได้คุณค่าสูงสุด?
ยังไม่มีคำตอบที่ชัดเจน แต่จากข้อมูลเบื้องต้นเกี่ยวกับ generative AI ที่มีอยู่ในปัจจุบัน รวมกับประสบการณ์ของ AI ในยุคแรกเริ่มและการเรียนรู้ของเครื่อง
ในปัจจุบัน AI กำเนิด แทบไม่มีคูน้ำที่เป็นระบบเลยเราเห็นแอปพลิเคชันปัจจุบัน ไม่มีความแตกต่างของผลิตภัณฑ์มากนัก และสัญญาณของสิ่งนี้ชัดเจนมาก เหตุผลคือแอปเหล่านี้ใช้โมเดล AI ที่คล้ายกัน ดังนั้น สิ่งที่โมเดลปัจจุบันกำลังเผชิญคือเป็นไปไม่ได้ที่จะตัดสินว่าความแตกต่างอยู่ที่ใดในระยะเวลาที่นานขึ้น โมเดลเหล่านี้ได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูลและสถาปัตยกรรมที่คล้ายคลึงกัน และผู้ให้บริการคลาวด์ก็คล้ายกัน และเทคโนโลยีของทุกคนก็เหมือนกัน เนื่องจากใช้ GPU เดียวกัน แม้แต่บริษัทฮาร์ดแวร์ก็ยังสร้างชิปในโรงงานเดียวกัน
แน่นอน,ยังคงมีคูน้ำมาตรฐานอยู่ เช่น คูเมืองขนาดเดียวกัน ฉันมีเงินทุนดีกว่าคุณ ความสามารถทางการเงินของฉันแข็งแกร่งกว่า หรือ คูเมืองซัพพลายเชน ฉันมี GPU แต่คุณไม่มี หรือคูเมืองในระบบนิเวศ เป็นต้น ซอฟต์แวร์ของฉันมีผู้ใช้มากกว่าคุณ และฉันเริ่มก่อนหน้านี้ ฉันมีอุปสรรคด้านเวลาและขนาดผู้ใช้ หรือคูเมืองอัลกอริทึม เช่น อัลกอริทึมของฉันแข็งแกร่งกว่าของคุณ คูเมืองในช่องการขาย ฉันเก่งกว่าคุณในการขายสินค้า ฉันเป็นผู้นำในช่อง หรือคูเมืองในช่องข้อมูล เช่น ฉันรวบรวมข้อมูลมากกว่าคุณ
อย่างไรก็ตาม คูเมืองเหล่านี้ไม่มีข้อได้เปรียบในระยะยาวและไม่ยั่งยืน นอกจากนี้ ยังเร็วเกินไปที่จะบอกได้อย่างชัดเจนว่าที่ใดในสแต็คเหล่านี้แข็งแกร่ง เอฟเฟกต์เครือข่ายทันทีจะเหนือกว่า
จากข้อมูลที่มีอยู่ ยังเร็วเกินไปที่จะบอกได้ว่า AI เชิงสร้างสรรค์จะมีโอกาสคว้าชัยชนะในระยะยาวหรือไม่
ฟังดูแปลกๆ แต่สำหรับเรา นี่เป็นข่าวดี
เนื่องจากขนาดที่เป็นไปได้ของตลาดทั้งหมดเป็นเรื่องยากที่จะเข้าใจได้ จึงมีความเกี่ยวข้องอย่างใกล้ชิดกับซอฟต์แวร์และความพยายามของทุกคน เราคาดว่าผู้เล่นจำนวนมากจะเข้าร่วมในตลาดนี้ และทุกคนจะแข่งขันกันด้วยความรู้สึกผิดชอบชั่วดีในทุกระดับของกลุ่ม AI กำเนิด เราคาดหวังบริษัทที่ประสบความสำเร็จที่สามารถทำงานในแนวนอนและแนวตั้งได้
อย่างไรก็ตามสิ่งนี้ถูกกำหนดโดยตลาดปลายทางและผู้ใช้ ตัวอย่างเช่น หากตัวสร้างความแตกต่างหลักของผลิตภัณฑ์ขั้นสุดท้ายอยู่ที่เทคโนโลยี AI เอง การปรับแนวตั้ง (นั่นคือ การผสานรวมอย่างแน่นแฟ้นของแอปพลิเคชันที่ผู้ใช้เผชิญหน้ากับโมเดลเนทีฟ) มีแนวโน้มที่จะชนะ
และถ้า AI เป็นส่วนหนึ่งของชุดคุณสมบัติหางยาวที่ใหญ่ขึ้น การปรับแนวนอนอาจเป็นแนวโน้มที่แท้จริง แน่นอน เมื่อเวลาผ่านไป เราน่าจะเห็นการสร้างคูเมืองแบบดั้งเดิมมากขึ้น และแม้แต่คูเมืองใหม่เอี่ยม
สิ่งหนึ่งที่แน่นอนคือ AI กำเนิดกำลังเปลี่ยนแปลงอุตสาหกรรม ทุกคนยังคงเรียนรู้อย่างต่อเนื่อง คุณค่ามากมายจะถูกปลดปล่อยออกมา และระบบนิเวศทางเทคโนโลยีจะเปลี่ยนไปตามผลที่ตามมา ทุกคนกำลังเดินทาง


