
AIGC Evolution: วิถีเอกพจน์และความฉลาดหลักแหลม
ต้นฉบับ: วิถีเอกพจน์
ในปี 1999 Ray Kurzweil ได้ทำนายไว้ดังนี้:
ในปี พ.ศ. 2552 คอมพิวเตอร์จะเป็นแท็บเล็ตหรืออุปกรณ์ขนาดเล็กลงพร้อมจอแสดงผลคุณภาพสูงแต่ดั้งเดิม
ในปี 2562 คอมพิวเตอร์จะ "มองไม่เห็นโดยพื้นฐาน" โดยภาพส่วนใหญ่จะฉายโดยตรงไปยังเรตินา
ในปี 2029 คอมพิวเตอร์จะสื่อสารผ่านวิถีประสาทโดยตรง
เมื่อพิจารณาถึงพัฒนาการของปัญญาประดิษฐ์ วิทยาการหุ่นยนต์ และการผลิตในช่วง 20 ปีที่ผ่านมา โดยเฉพาะอย่างยิ่งความก้าวหน้าล่าสุดของ AIGC มีตัวบ่งชี้บางอย่างว่าการพัฒนาเทคโนโลยีกำลังเร่งไปสู่ความเป็นเอกฐาน
ความเป็นเอกเทศทางเทคโนโลยี
Singularity แต่เดิมหมายถึง "เอกพจน์ ความโดดเด่น และความหายาก" และความหมายเหล่านี้ค่อย ๆ ขยายไปสู่วิทยาศาสตร์ธรรมชาติ เริ่มแรกใช้กับสาขาคณิตศาสตร์ และต่อมาขยายไปสู่สาขาฟิสิกส์และดาราศาสตร์ มีการทำนาย "ภาวะเอกฐานทางเทคโนโลยี" เวอร์ชันต่างๆ ตามมา

ภาวะเอกฐานทางเทคโนโลยี "เวอร์ชัน 1.0":
ในปี 1958 แนวคิดของ "ภาวะเอกฐานทางเทคโนโลยี" ได้รับการเสนอครั้งแรกโดยนักคณิตศาสตร์ชาวโปแลนด์ Stanisław Marcin Ulam: "การเร่งความเร็วของการทำซ้ำทางเทคโนโลยีและการเปลี่ยนแปลงรูปแบบชีวิตของมนุษย์ดูเหมือนจะเปลี่ยนเส้นทางประวัติศาสตร์ของเรา นำไปสู่ 'ภาวะเอกฐาน' ที่สำคัญหลังจาก ซึ่งไม่มีอะไรที่เรารู้ว่ามันจะดำเนินต่อไป" และโลกจะกลับหัวกลับหาง
ภาวะเอกฐานทางเทคโนโลยี "เวอร์ชัน 2.0":
ในปี 1993 นักวิทยาศาสตร์คอมพิวเตอร์และนักเขียนนิยายวิทยาศาสตร์ Vernor Vinge เขียนในบทความของเขาเรื่อง "The Coming Technology Singularity" ว่าการมาถึงของ "Technological Singularity" จะเป็นเครื่องหมายของการมาถึงของมนุษย์ การสิ้นสุดของยุค และความฉลาดหลักแหลมเป็นสิ่งที่จำเป็นสำหรับ การเกิดขึ้นของ "ภาวะเอกฐานทางเทคโนโลยี" เนื่องจากความฉลาดหลักแหลมใหม่ ๆ จะยังคงยกระดับตนเองและสร้างความก้าวหน้าทางเทคโนโลยีในอัตราที่เหลือเชื่อ
ภาวะเอกฐานทางเทคโนโลยี "เวอร์ชัน 3.0":
ในปี พ.ศ. 2548 Ray Kurzweil ผู้ก่อตั้งและประธาน Singularity University และผู้อำนวยการด้านเทคนิคของ Google ได้ปรับแนวคิดของ "ภาวะเอกฐานทางเทคนิค" ในหนังสือของเขา "The Singularity Is Near" ใหม่ ซึ่งใกล้เคียงกับแนวคิดที่เราคุ้นเคยมากขึ้น และที่ เวลาทำนายว่าเอกฐานทางเทคโนโลยีจะปรากฏในปี 2588 เขาเชื่อว่า "ภาวะเอกฐานทางเทคโนโลยี" หมายถึงการเปลี่ยนแปลงที่แก้ไขไม่ได้ซึ่งการเปลี่ยนแปลงทางเทคโนโลยีอย่างรวดเร็วและกว้างขวางจะก่อให้เกิดชีวิตมนุษย์ในอนาคต โดยส่วนใหญ่หมายถึงการพัฒนาอย่างรวดเร็วของปัญญาประดิษฐ์ ภาวะเอกฐานจะช่วยให้เราก้าวข้ามข้อจำกัดของร่างกายทางชีวภาพและสมอง และในอนาคตจะไม่มีความแตกต่างระหว่างมนุษย์กับเครื่องจักร
ภาวะเอกฐานทางเทคโนโลยี "เวอร์ชัน 4.0":
ในปี 2013 Anders Sandberg นักวิจัยอาวุโสของ Institute for the Future of Humanity แห่งมหาวิทยาลัย Oxford ได้ขยายขอบเขตของ "ภาวะเอกฐานทางเทคโนโลยี" การพัฒนาและการเปลี่ยนแปลงทางเทคโนโลยีดังกล่าวสามารถเรียกว่า "ภาวะเอกฐานทางเทคโนโลยี"
ผู้ใช้ GPT ฝันถึงเพื่อน?
เมื่อวันที่ 30 พฤศจิกายน 2022 OpenAI ได้เปิดตัว ChatGPT ซึ่งเป็นอินเทอร์เฟซการสนทนาและโมเดลภาษาขนาดใหญ่ สำหรับหลายๆ คน นี่คือช่วงเวลาแห่งการปฏิวัติ ผลลัพธ์ที่ได้นั้นสวยงาม ประหยัดเวลา และคำตอบก็น่าเชื่อถือ (เมื่อ OpenAI คิดว่าปลอดภัยที่จะตอบ)

เป็นเรื่องน่าทึ่งที่คุณจะได้รับคำตอบที่ไม่สมบูรณ์แบบแต่ได้ผลกับ LLM ในวันนี้ภายในเวลาไม่กี่วินาที ซึ่งผู้เชี่ยวชาญโดเมนอาจใช้เวลาในการพิจารณานานหลายนาทีและการโต้เถียงกันหลายชั่วโมงในฟอรัมออนไลน์
Chatbots เป็นมิตรภาพที่ผู้คนปรารถนามาโดยตลอด แรงจูงใจเบื้องหลังการทดสอบทัวริงอาจต้องการแชทบอทที่ไม่ทำลายสมาธิ
สิ่งที่ยังคงต้องทดสอบคือมนุษย์ในฐานะสัตว์สังคมสามารถเสริมสมองดิจิทัลได้หรือไม่ เราล่าสัตว์ด้วยกัน เราทำฟาร์มด้วยกัน และสังคมซึ่งตอนนี้สามารถอธิบายได้ว่าเป็นเขตกันชนขนาดใหญ่ของผู้จัดการและผู้ควบคุมเครื่องจักรระดับอุตสาหกรรม เป็นสังคมมากขึ้นกว่าเดิม
มนุษย์เพิ่มประสิทธิภาพในเส้นทางที่มีการต่อต้านน้อยที่สุด โดยเลือกที่จะทำซ้ำหรือ "Google" ความรู้ต่างๆ ที่พวกเขาอาจได้รับจากการคิดอย่างมีวิจารณญาณและความล้มเหลวซ้ำแล้วซ้ำเล่า การถือกำเนิดของ ChatGPT: นักเรียนอาจใช้ LLM เพื่อเขียนรายงานให้พวกเขา ได้เกรดดีๆ Stack Overflow อาจถูกโจมตีโดย Sybil เพื่อผลประโยชน์ส่วนตัว และผู้ชม (โปรแกรมเมอร์) อาจเชื่อฟังซิมโฟนีของ Deepfakes สคริปต์ตัวเล็กอาจระบุว่า ChatGPT เป็นมัลแวร์ การใช้ LLM กระแสหลักทำให้ความสามารถของเรามีประสิทธิผลลดลงหรือไม่ โดยเฉพาะอย่างยิ่งในแง่ของการคิดที่ดี มีประสิทธิภาพ และแตกต่างหรือไม่?
นักเชิดหุ่นคนสุดท้ายก่อนเอกพจน์
ผลกระทบที่ลึกซึ้งที่สุดที่ AI สามารถมีได้คือในวัฒนธรรมของการจัดสรรทุนมนุษย์ ความคิดเห็นล่าสุดอธิบายปฏิกิริยาต่อ ChatGPT ได้อย่างสวยงาม:
ผู้ที่มีความสุขที่สุดคือผู้ที่ตกตะลึงเมื่อพบว่าเครื่องจักรนั้นรองรับงานเขียนได้อย่างชัดเจน
จนถึงตอนนี้ทุกอย่างเป็นไปตามคาด หากย้อนดูประวัติศาสตร์ ผู้คนมักประเมินผลกระทบระยะสั้นของเทคโนโลยีการสื่อสารใหม่สูงเกินไป และประเมินผลกระทบระยะยาวต่ำเกินไป เช่นเดียวกับสิ่งพิมพ์ ภาพยนตร์ วิทยุ โทรทัศน์ และอินเทอร์เน็ต
ในการพยายามทำความเข้าใจผลกระทบของ AI เราพยายามแยกการหยุดชะงักในระยะสั้นออกเพื่อคาดเดาผลที่ตามมาในระยะกลางและระยะยาว
ต้องบอกว่า วิธีที่ดีในการอธิบายการชุมนุมครั้งนี้คือผ่านการเปลี่ยนแปลงของตลาด ผู้ช่วย AI เปลี่ยนความขาดแคลนของการสร้างเนื้อหา จึงกลายเป็นส่วนหนึ่งของผู้ทำการตลาด ทุกครั้งที่ "มาร" ที่เป็นสุภาษิตทิ้ง "ขวด" ผู้บริโภคจะได้รับผลตอบแทนที่ไม่สมดุลโดยการปรับราคาตลาดใหม่และเลิกจ้างซัพพลายเออร์ที่ด้อยประสิทธิภาพ ในทางกลับกัน ซัพพลายเออร์ของการผลิตที่ใช้ AI สะสมทุนเพิ่มขึ้นเมื่อเวลาผ่านไป
อาจมีคนเถียงว่ามีผู้ขายน้อยรายของบริษัทที่สามารถรวบรวมข้อมูลอินเทอร์เน็ตทั้งหมดเพื่อสร้างชุดข้อมูลการฝึกอบรมได้ อาจมีเพียง SaaS จำนวนจำกัดเท่านั้นที่สามารถที่จะใช้ทรัพยากรดังกล่าวเพื่อสร้างโมเดล ML ที่แปลกใหม่ หากการค้าบน ML ไม่เสถียรเพียงพอ ผู้คนจำนวนน้อยอาจสามารถบรรลุและรักษา PMF ได้ ในอดีตเราเคยถูกกลวิธีทางจิตวิทยาหลอก เช่น HAL 9000, Skynet และ Butlerian Jihad
บริษัทและตัวแทนอัจฉริยะจำนวนมากร่วมมือกันบนความขาดแคลนในระบบเศรษฐกิจ AI เป็นไปได้มากน้อยเพียงใดที่สังคมทุนนิยมในปัจจุบันของเราจะสร้างเทคโนแครตโดยปราศจากความคิดเห็นเชิงลบที่สามารถทำลายล้างชนชั้นทางเศรษฐกิจและสังคม หลักการพื้นฐาน เช่น สิทธิมนุษยชน/ทรัพย์สิน หรือเร่งให้เกิดการทำลายล้างสูงในรูปแบบใดรูปแบบหนึ่ง
อาจฟังดูซ้ำซากจำเจ แต่ก็มีจุดเปลี่ยนที่กำลังจะเกิดขึ้นที่ต้องระวังซึ่งจะส่งผลกระทบพื้นฐานต่อวิธีการทำงานของสังคม หนึ่งปีนับจากนี้ บางคนอาจกำลังเขียนกฎหมายด่วนหรือคลั่งไคล้ดอกทิวลิปเกี่ยวกับผลิตภัณฑ์ที่ขึ้นอยู่กับ AI โดยเฉพาะ ใน 5-10 ปี จะมีการเลิกกิจการของระบบเศรษฐกิจแบบเจ้าของคนเดียว รูปแบบของรัฐบาลที่มีอยู่ และการปกครองตนเอง/การบริโภคส่วนบุคคล โมเดล “เมกะคอร์ป” อาจยังคงโดดเด่นตลอดกระบวนการหยุดชะงัก และเราอาจพบว่าตัวเองอยู่ใน “สถานะไซเบอร์” หรือบางอย่างที่มากกว่านั้น ทั้งหมดเป็นเพราะคอมพิวเตอร์ (ไม่ว่าจะด้วยวิธีการใด) จะรวบรวมการใช้ภาษาธรรมชาติโดยรวมของเราเพื่อรวมหน้าที่การดำเนินงานและเศรษฐกิจของสังคมในปัจจุบัน ไม่ว่าไทม์ไลน์จะเป็นเช่นไร สิ่งนี้จะเป็นจุดเปลี่ยนที่ชัดเจนก่อนถึง "ภาวะเอกฐาน"
วิธีการและเทคโนโลยี
คำอธิบายภาพ
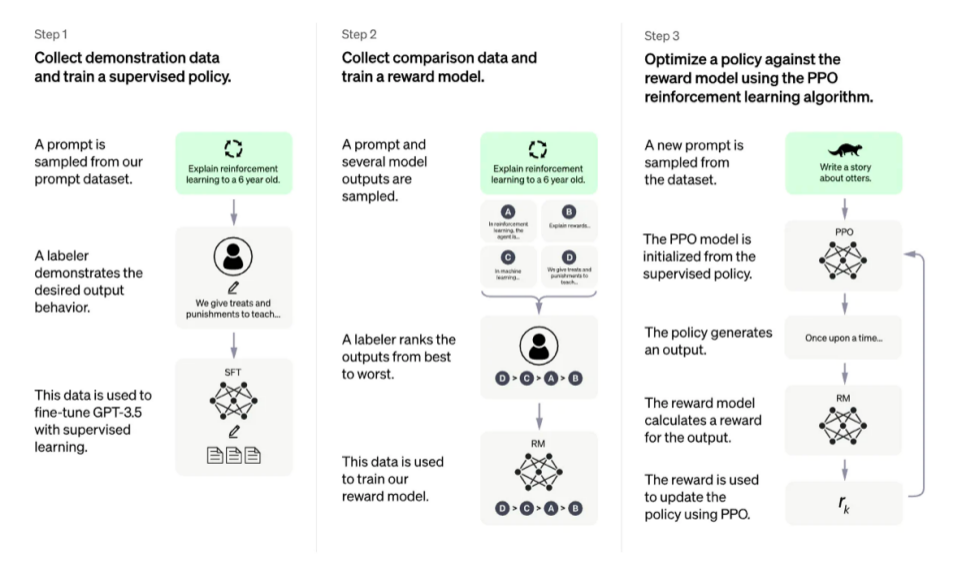
แผนภาพ RLHF ของ OpenAI
อย่างไรก็ตาม ยังมีความท้าทายในการทำให้ NLP "สมบูรณ์แบบ"
แม้ว่าเทคโนโลยีเหล่านี้มีแนวโน้มที่ดีและมีประสิทธิภาพอย่างมาก และได้รับความสนใจจากห้องปฏิบัติการวิจัยด้านปัญญาประดิษฐ์ที่ใหญ่ที่สุด แต่ก็มีข้อจำกัดที่ชัดเจน โมเดลเหล่านี้สามารถแสดงข้อความที่เป็นอันตรายหรือไม่ถูกต้องโดยปราศจากความไม่แน่นอน ความไม่สมบูรณ์นี้แสดงถึงความท้าทายที่มีมาอย่างยาวนานและแรงผลักดันสำหรับ RLHF การทำงานในโดเมนปัญหาของมนุษย์โดยเนื้อแท้ หมายความว่าไม่มีเส้นชัยที่ชัดเจนในการข้ามสำหรับแบบจำลองที่จะทำเครื่องหมายว่าเสร็จสมบูรณ์
เมื่อปรับใช้ระบบโดยใช้ RLHF การรวบรวมข้อมูลความพึงพอใจของมนุษย์นั้นมีราคาแพงเนื่องจากปัจจัยบังคับและปัจจัยมนุษย์โดยเจตนา ประสิทธิภาพของ RLHF นั้นดีพอๆ กับคุณภาพของคำอธิบายประกอบของมนุษย์ ซึ่งมีอยู่สองแบบ: ข้อความที่มนุษย์สร้างขึ้น เช่น การปรับแต่งการเริ่มต้น LM ใน InstructGPT และป้ายกำกับที่มนุษย์ต้องการระหว่างเอาต์พุตของโมเดล
การสร้างข้อความจากมนุษย์ที่เขียนอย่างดีเพื่อตอบข้อความแจ้งเฉพาะนั้นมีค่าใช้จ่ายสูง เนื่องจากมักต้องมีการจ้างคนนอกเวลา (แทนที่จะพึ่งพาผู้ใช้ผลิตภัณฑ์หรือการจัดหาฝูงชน) โชคดีที่ขนาดข้อมูล (ประมาณ 50 k ตัวอย่างค่ากำหนดที่มีป้ายกำกับ) ที่ใช้ในการฝึกโมเดลรางวัลสำหรับแอปพลิเคชัน RLHF ส่วนใหญ่นั้นไม่แพงขนาดนั้น อย่างไรก็ตาม ก็ยังมีราคาสูงกว่าที่ห้องปฏิบัติการทางวิชาการสามารถจ่ายได้
ปัจจุบัน มีชุดข้อมูลขนาดใหญ่เพียงชุดเดียวสำหรับ RLHF ตามแบบจำลองภาษาทั่วไป (จาก Anthropic) และชุดข้อมูลเฉพาะงานขนาดเล็กหลายชุด (เช่น ข้อมูลสรุปจาก OpenAI) ความท้าทายด้านข้อมูล RLHF คืออคติของผู้เขียน ผู้เขียนคำอธิบายประกอบหลายคนอาจไม่เห็นด้วย ซึ่งนำไปสู่ความแปรปรวนที่อาจเกิดขึ้นในข้อมูลการฝึกอบรม
RLHF สามารถนำไปใช้กับแมชชีนเลิร์นนิงนอกเหนือจากการประมวลผลภาษาธรรมชาติ (NLP) ตัวอย่างเช่น Deepmind สำรวจการใช้งานสำหรับตัวแทนหลายรูปแบบ ความท้าทายเดียวกันนี้ใช้ในกรณีนี้:
การเรียนรู้การเสริมแรงที่ปรับขนาดได้ (RL) อาศัยฟังก์ชันการให้รางวัลที่แม่นยำซึ่งมีราคาถูกในการค้นหา เมื่อสามารถใช้ RL ได้ ก็ประสบความสำเร็จอย่างมาก โดยสร้าง AI ที่สามารถจับคู่กับการกระจายความสามารถของมนุษย์แบบสุดขั้ว (Silver et al., 2016; Vinyals et al., 2019) อย่างไรก็ตาม ฟังก์ชันการให้รางวัลนี้ไม่เป็นที่รู้จักกันดีสำหรับพฤติกรรมปลายเปิดหลายอย่างที่ผู้คนมีส่วนร่วมเป็นประจำ ตัวอย่างเช่น พิจารณาการโต้ตอบในชีวิตประจำวันโดยขอให้ใครสักคน "ถือแก้วน้ำใกล้ๆ คุณ" สำหรับรูปแบบรางวัลที่จะสามารถประเมินการโต้ตอบดังกล่าวได้อย่างเพียงพอนั้น จะต้องแข็งแกร่งในหลายๆ วิธีในการร้องขอในภาษาธรรมชาติ และหลายๆ วิธีในการบรรลุ (หรือไม่) ในขณะที่ต้องแข็งแกร่ง ไปจนถึงตัวแปรที่ไม่เกี่ยวข้องของการแปรผัน (สีของถ้วย) และความกำกวมโดยธรรมชาติของภาษา (คำว่า "ใกล้เคียง" คืออะไร) ความไม่ละเอียดอ่อน
ดังนั้น เพื่อปลูกฝังความสามารถระดับผู้เชี่ยวชาญให้กว้างขึ้นผ่าน RL เราจำเป็นต้องมีวิธีสร้างฟังก์ชันรางวัลที่แม่นยำและสืบค้นได้ ซึ่งเคารพความซับซ้อน ความแปรปรวน และความกำกวมของพฤติกรรมมนุษย์ ทางเลือกหนึ่งคือการใช้แมชชีนเลิร์นนิงเพื่อสร้างฟังก์ชันเหล่านี้แทนการเขียนโปรแกรมฟังก์ชันรางวัล แทนที่จะพยายามทำนายและกำหนดเหตุการณ์รางวัลอย่างเป็นทางการ เราสามารถขอให้มนุษย์ประเมินสถานการณ์และให้ข้อมูลภายใต้การดูแลเพื่อเรียนรู้การทำงานของรางวัล สำหรับสถานการณ์ที่มนุษย์สามารถตัดสินได้อย่างเป็นธรรมชาติ เป็นธรรมชาติ และรวดเร็ว RL โดยใช้แบบจำลองรางวัลการเรียนรู้ดังกล่าวสามารถปรับปรุงตัวแทนได้อย่างมีประสิทธิภาพ (Christiano et al., 2017; Ibarz et al., 2018; Stiennon et al., 2020 Year;)
ปัจจัยหลายอย่างที่นำไปสู่ภาวะเอกฐานนั้นยังไม่ได้รับการพัฒนา และเราสามารถระบุได้ว่าปัจจัยเหล่านี้คืออะไรด้วยความแน่นอนมากกว่ากรอบเวลาที่ใช้ในการดำเนินการ Chris Lattner กล่าวถึง "การจัดองค์ประกอบโดยผู้เชี่ยวชาญที่มีรั้วรอบขอบชิด" จาก POV ของเขา:
หากต้องการอธิบายสั้น ๆ อาจมีคนกลางที่ดูแลและรวมข้อมูลจาก "ผู้เชี่ยวชาญ" จำนวนมาก
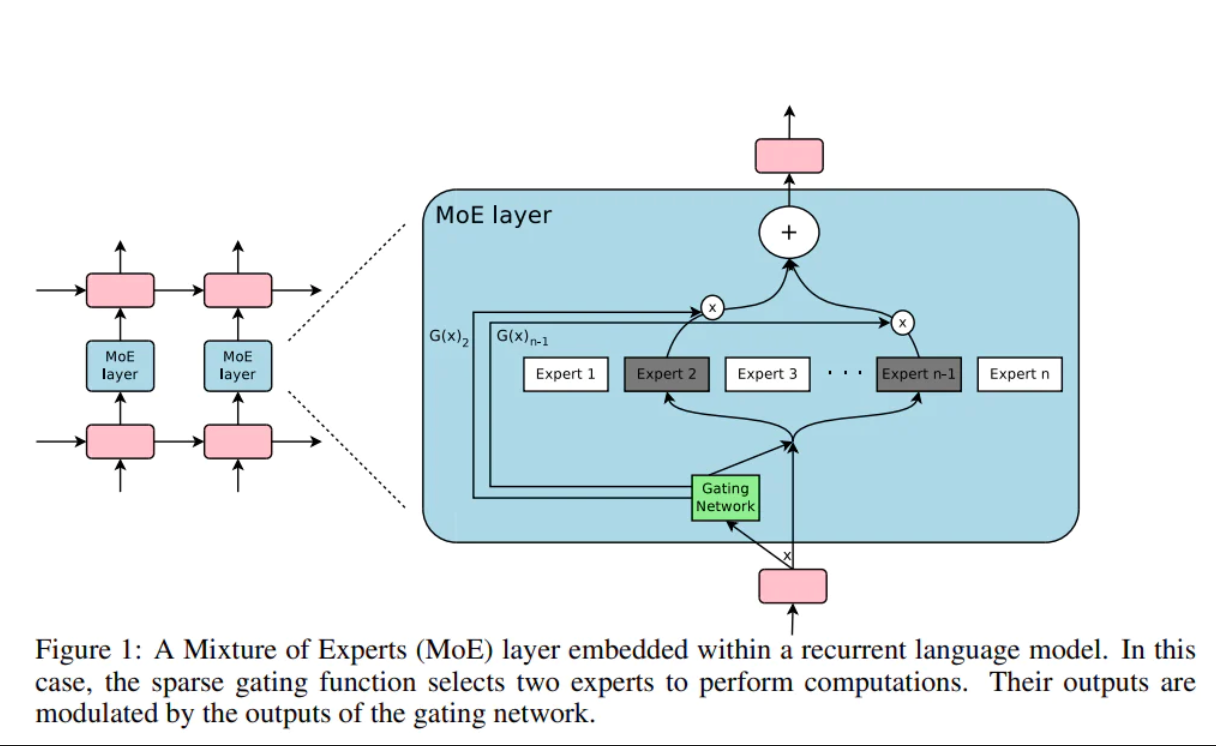
นี่เป็นพื้นที่การออกแบบที่กว้างขวางสำหรับการวิจัยเพิ่มเติม บางทีชั้นกลางควรเลือกที่แตกต่างกัน
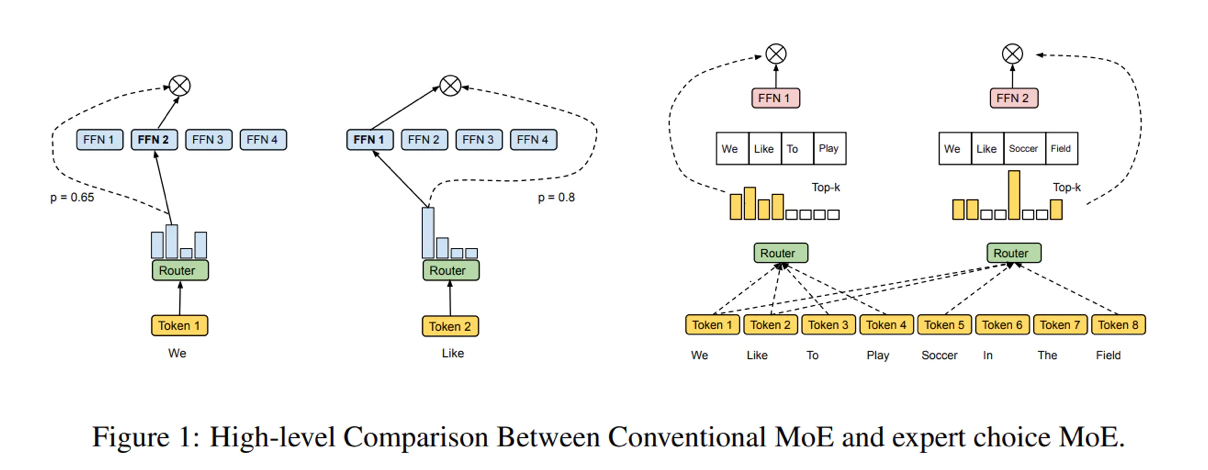
ตัวอย่างเช่น การใช้ข้อมูลเชิงพื้นที่
คำอธิบายภาพ
ข้อความ
ข้อความ
ผลตอบรับจากภาคการผลิตอยู่ในเกณฑ์ดี แต่ภาคส่วนด้านสุขภาพมีความจำเป็นมากที่สุด ขณะนี้ เราเป็นผู้ใช้รายแรกๆ ของไบโอเซนเซอร์สำหรับร้านค้าปลีก เมื่อเวลาผ่านไป การเข้ารหัสแบบโฮโมมอร์ฟิคจะช่วยให้แมชชีนเลิร์นนิงสามารถใช้ประโยชน์จากข้อมูลสุขภาพจำนวนมหาศาลได้ เราได้รวบรวมการบริโภคยาของเรามาเป็นเวลาหลายหมื่นปีแล้ว แต่ยังคงต้องรอดูว่าเราจะอยู่ร่วมกับปัญญาประดิษฐ์ที่สามารถจัดการปริมาณสารตามอำเภอใจได้อย่างไรในช่วงเวลาใดเวลาหนึ่ง ในเวลาเดียวกัน การเข้ารหัสแบบโฮโมมอร์ฟิกยังคงไม่ได้ใช้เนื่องจากปัญหาด้านประสิทธิภาพ
Google Brain เพิ่งเปิดตัว Robotics Transformer-1 ในรีลีสแรกอาจเป็นเพียงแขนที่ทำงานง่ายๆ แต่เป็นไปได้อย่างชัดเจนที่จะทำซ้ำด้วยการดำเนินการที่มีโทเค็นมากขึ้นในสภาพแวดล้อมการสร้างทั่วไป เนื่องจากเศรษฐกิจโลกมุ่งเน้นไปที่การขนส่งสินค้า จึงสมเหตุสมผลหากมีการสร้างตู้คอนเทนเนอร์ที่ "ปลอดมลพิษ" มากกว่า 100 ลำในโรงงานดังกล่าว เมื่อเทียบกับที่มีอยู่ประมาณ 6,000 ลำในโลก นอกจากนี้ยังเป็นการเปลี่ยนแปลงครั้งใหญ่ในวิกฤตที่อยู่อาศัยซึ่งกฎหมายแบ่งเขตอนุญาตให้มีผลอย่างเต็มที่
นอกจากนี้ ฉันต้องพูดถึงแผนอัลเบอร์ตา 12 ขั้นตอนที่สมเหตุสมผลสำหรับการพัฒนาความสามารถด้าน AGI
คำว่า "แผนงาน" หมายถึงการวาดเส้นทางเชิงเส้น ชุดของขั้นตอนที่ควรดำเนินการและผ่านไปตามลำดับ นั่นไม่ผิดทั้งหมด แต่ไม่สามารถรับรู้ถึงความไม่แน่นอนและโอกาสของการวิจัย ขั้นตอนที่เราร่างไว้ด้านล่างมีการพึ่งพากันหลายขั้นตอนแทนที่จะเป็นลำดับขั้นตอนตั้งแต่ต้นจนจบ แผนงานแนะนำระเบียบตามธรรมชาติ แต่การปฏิบัติมักเบี่ยงเบนไปจากระเบียบนี้ การวิจัยที่เป็นประโยชน์สามารถทำได้โดยป้อนหรือแนบกับขั้นตอนใดก็ได้ ตัวอย่างเช่น พวกเราหลายคนเพิ่งมีความก้าวหน้าที่น่าสนใจในสถาปัตยกรรมแบบผสมผสาน แม้ว่าความก้าวหน้าเหล่านี้จะปรากฏในขั้นตอนสุดท้ายของลำดับเท่านั้น
ขั้นแรก เรามาทำความเข้าใจแนวคิดทั่วไปเกี่ยวกับแผนงานและเหตุผล มี 12 ขั้นตอน มีหัวข้อดังนี้
1. การเป็นตัวแทน I: การเรียนรู้ภายใต้การดูแลอย่างต่อเนื่องพร้อมคุณสมบัติที่กำหนด 2. การเป็นตัวแทน II: การค้นพบคุณสมบัติภายใต้การดูแล 3. การทำนายที่หนึ่ง: การเรียนรู้เชิงคาดการณ์ของฟังก์ชันค่าทั่วไปอย่างต่อเนื่อง (GVF) 4. การควบคุม I: การควบคุมการวิจารณ์นักแสดงอย่างต่อเนื่อง 5. การทำนายที่สอง: รางวัลการเรียนรู้ GVF เฉลี่ย 6. การควบคุม II: ปัญหาการควบคุมอย่างต่อเนื่อง 7. แผน I: แผนสำหรับรางวัลที่เท่าเทียมกัน 8. Prototype-AI I: การเรียนรู้การเสริมแรงแบบขั้นตอนเดียวตามแบบจำลองพร้อมการประมาณฟังก์ชันต่อเนื่อง 9. แผน II: การควบคุมการค้นหาและการสำรวจ 10. Prototype-AI II: กระบวนการ STOMP 11. ต้นแบบ-AI III: โอ๊ค 12. Prototype-IA: การขยายสัญญาณอัจฉริยะ
ขั้นตอนเหล่านี้พัฒนาจากการพัฒนาอัลกอริทึมใหม่สำหรับความสามารถหลัก (สำหรับการเป็นตัวแทน การทำนาย การวางแผน และการควบคุม) ไปจนถึงการรวมอัลกอริทึมเหล่านี้เพื่อสร้างระบบต้นแบบที่สมบูรณ์สำหรับ AI ที่ใช้โมเดลอย่างต่อเนื่อง
คำอธิบายภาพ

ผลลัพธ์ของ ChatGPT
"ความก้าวหน้าแบบทวีคูณ"
แผนอัลเบอร์ตาที่อธิบายไว้ข้างต้นเป็นสถานการณ์ในอุดมคติ มนุษย์มีความซับซ้อนอยู่แล้ว โดยเป็นปัจเจกบุคคลโดยใช้เครื่องมือโครงข่ายประสาทเทียมแบบกระจัดกระจาย เป็นกลุ่ม โดยมีคุณสมบัติในการจัดระเบียบตนเอง การเรียนรู้ทางสังคม และวิศวกรรมสิ่งแวดล้อม ในการพัฒนาล่าสุดในการเข้ารหัสและการประมวลผลแบบกระจาย (ฝ่ายตรงข้าม) มนุษย์มีอิสระมากพอที่จะรักษาสถานะโลก (ประวัติศาสตร์) ของทัวริงได้อย่างสมบูรณ์ นอกจากนี้ยังมีปรากฏการณ์ที่เรียกว่า Mechanical Turk ประเด็นก็คือผลิตภัณฑ์ AI จะลดลงในทุกช่วงเวลา และจะมีระบบนิเวศของนักพัฒนาที่เติบโตเต็มที่ซึ่งสามารถทำงานได้ดีกว่าระดับที่มีอยู่ด้วยการดำเนินการที่ประสานกัน เสริมด้วยเครื่องมือ AI ร่วมสมัยและงานที่ตรวจสอบได้
สิ่งนี้นำไปสู่การทดลองทางความคิดในปัจจุบัน: เราจำเป็นต้องบรรลุจุดเปลี่ยนทุกจุดตามที่คาดการณ์ไว้ก่อน The Singularity™ หรือไม่ สำหรับทุกการปรับปรุงที่เป็นกรรมสิทธิ์ในการฝึกอบรมโมเดลเชิงพาณิชย์ อาจมีวิธีที่ปฏิบัติได้ในสาธารณสมบัติ StableDiffusion ได้จุดประกายการสนทนาเกี่ยวกับแนวคิดนี้ Crowdsourcing ได้เร่งตัวขึ้นมากพอสมควรในช่วงทศวรรษที่ผ่านมา (ตามที่เห็นได้จาก Twitch Plays Pokemon, Social Networks และ The DAO) ว่าความเป็นเอกเทศเป็นสิ่งที่เบี่ยงเบนความสนใจอยู่แล้ว เช่นเดียวกับที่โซลูชันการปรับขนาด Ethereum พยายามใช้การเข้ารหัสเช่น zk-SNARK เพื่อลดความต้องการด้านโครงสร้างพื้นฐานของเครือข่าย เราจะพยายามใช้โซลูชันที่มีน้ำหนักเบาซึ่งลดความจำเป็นขององค์กรขนาดใหญ่ที่มีอยู่ในการบังคับเดรัจฉานและสร้างรายได้จาก AI
อันที่จริง วิธีที่ดีที่สุดวิธีหนึ่งในการหักล้างโมเดล OpenAI คือระบบทุนทางสังคมที่คล้ายคลึงกันในตลาดการเงินและโซเชียลเน็ตเวิร์กค่อนข้างจะคาดเดาพฤติกรรมได้ Twitter รวบรวมข่าวสารเนื่องจากผู้ใช้สามารถออกอากาศและขยายข่าวไปทั่วโลกด้วยบุคลิกที่ถูกต้องตามกฎหมาย ด้วยแนวโน้มทั่วโลก เช่น การล็อกดาวน์ของ COVID และนโยบายการเงินของธนาคารกลาง หุ้นเติบโตสามารถขยับขึ้นและลงอย่างรวดเร็ว ไม่ต้องใช้จินตนาการมากนักในการจินตนาการถึงสตาร์ทอัพที่สามารถแสดง PMF ที่เหมือน AI เป็นชุมชนที่ควบคุมตนเองและจัดการตนเองได้ในเสี้ยวหนึ่งของเวลา อาจมีต้นทุนการดำเนินงานหลายแสนล้านดอลลาร์ที่สามารถปลดล็อกได้ในหลายภาคส่วนผ่านเทคโนโลยีที่มีอยู่และการพัฒนาธุรกิจเพิ่มเติม
ในละครโทรทัศน์เรื่อง Westworld ระบบปัญญาประดิษฐ์ที่ชื่อว่า Rehoboam ทำหน้าที่สั่งการมนุษย์โดยการวิเคราะห์ชุดข้อมูลขนาดใหญ่เพื่อจัดการและทำนายอนาคต นับตั้งแต่การปฏิวัติอุตสาหกรรม นวัตกรรมก่อกวนได้เกิดขึ้นนอกระบบราชการซ้ำแล้วซ้ำเล่า ทุกวันนี้ สิ่งเหล่านี้กำลังเกิดขึ้นในอัตราที่เพิ่มขึ้น ความลึกและขอบเขตของสาธารณสมบัติได้เพิ่มขึ้นในช่วงไม่กี่ทศวรรษที่ผ่านมา และเทคโนโลยีหลายอย่างไม่ว่าจะเป็นเชิงพาณิชย์เพียงใด กำลังถูกบังคับให้ใช้โอเพ่นซอร์ส


