การเพิ่มขึ้นของ ChatGPT: ประวัติการพัฒนา หลักการทางเทคนิค และข้อจำกัด
ชื่อเดิม: "จาก GPT-1 ถึง GPT-4 เพื่อดูการเพิ่มขึ้นของ ChatGPT"
ผู้เขียนต้นฉบับ: Alpha Rabbit Research Notes
ชื่อเรื่องรอง
ChatGPT คืออะไร?
เมื่อเร็ว ๆ นี้ OpenAI ได้เปิดตัว ChatGPT ซึ่งเป็นโมเดลที่สามารถโต้ตอบในลักษณะการสนทนาได้เนื่องจากมีความฉลาดทำให้ได้รับการตอบรับจากผู้ใช้จำนวนมาก ChatGPT ยังเป็นญาติของ InstructGPT ที่ OpenAI เผยแพร่ก่อนหน้านี้ โมเดล ChatGPT ได้รับการฝึกอบรมโดยใช้ RLHF (การเรียนรู้การเสริมแรงพร้อมข้อเสนอแนะจากมนุษย์) บางทีชื่อเรื่องรอง
GPT คืออะไร? จาก GPT-1 เป็น GPT-3
Generative Pre-trained Transformer (GPT) เป็นโมเดลการเรียนรู้เชิงลึกสำหรับการสร้างข้อความที่ได้รับการฝึกฝนจากข้อมูลที่มีอยู่บนอินเทอร์เน็ต ใช้สำหรับการตอบคำถาม การสรุปข้อความ การแปลด้วยคอมพิวเตอร์ การจำแนกประเภท การสร้างรหัส และการสนทนา AI
ในปี 2018 GPT-1 ได้ถือกำเนิดขึ้น ซึ่งเป็นปีแรกของรูปแบบการฝึกอบรมล่วงหน้าของ NLP (Natural Language Processing) ในแง่ของประสิทธิภาพ GPT-1 มีความสามารถทั่วไปบางอย่างและสามารถใช้ในงาน NLP ที่ไม่เกี่ยวข้องกับงานการกำกับดูแล งานทั่วไปรวมถึง:
การให้เหตุผลด้วยภาษาธรรมชาติ: การตัดสินความสัมพันธ์ระหว่างสองประโยค (มี, ขัดแย้ง, เป็นกลาง)
การตอบคำถามและการใช้เหตุผลตามสามัญสำนึก: ใส่บทความและคำตอบบางส่วน และแสดงความถูกต้องของคำตอบ
การรับรู้ความคล้ายคลึงทางความหมาย: กำหนดว่าความหมายของสองประโยคมีความเกี่ยวข้องกันหรือไม่
แม้ว่า GPT-1 จะมีผลกระทบกับงานที่ไม่ได้ปรับแต่งอยู่บ้างแต่ความสามารถในการทำให้เป็นภาพรวมนั้นต่ำกว่างานภายใต้การดูแลที่ปรับแต่งอย่างละเอียดมาก ดังนั้น GPT-1 จึงถือได้ว่าเป็นเครื่องมือในการทำความเข้าใจภาษาที่ค่อนข้างดีมากกว่าเครื่องมือสำหรับการสนทนาเท่านั้น AI
แม้ว่า GPT-1 จะมีผลกระทบกับงานที่ไม่ได้ปรับแต่งอยู่บ้างแต่ความสามารถในการทำให้เป็นภาพรวมนั้นต่ำกว่างานภายใต้การดูแลที่ปรับแต่งอย่างละเอียดมาก ดังนั้น GPT-1 จึงถือได้ว่าเป็นเครื่องมือในการทำความเข้าใจภาษาที่ค่อนข้างดีมากกว่าเครื่องมือสำหรับการสนทนาเท่านั้น AI
GPT-2 ยังมาถึงตามกำหนดในปี 2019 อย่างไรก็ตาม GPT-2 ไม่ได้ดำเนินการนวัตกรรมโครงสร้างและการออกแบบบนเครือข่ายเดิมมากเกินไป ใช้เฉพาะพารามิเตอร์เครือข่ายและชุดข้อมูลที่ใหญ่ขึ้น: โมเดลที่ใหญ่ที่สุดมีทั้งหมด 48 เลเยอร์ พร้อมด้วย ปริมาณพารามิเตอร์ 1.5 พันล้าน และวัตถุประสงค์การเรียนรู้ใช้รูปแบบการฝึกอบรมล่วงหน้าแบบไม่มีผู้ดูแลสำหรับงานภายใต้การดูแลในแง่ของประสิทธิภาพ นอกเหนือจากความเข้าใจแล้ว GPT-2 ได้แสดงความสามารถที่แข็งแกร่งเป็นครั้งแรกในแง่ของการสร้าง: การอ่านสรุป แชท เขียนต่อ สร้างเรื่องราว และแม้แต่สร้างข่าวปลอม อีเมลฟิชชิ่ง หรือบทบาท - เล่นออนไลน์ได้ไม่มีปัญหาหลังจาก "ใหญ่ขึ้น" GPT-2 ได้แสดงความสามารถทั่วไปและทรงพลัง และได้รับประสิทธิภาพสูงสุดในเวลานั้นในงานการสร้างแบบจำลองหลายภาษาที่เฉพาะเจาะจง
หลังจาก,GPT-3 ปรากฏเป็นแบบจำลองที่ไม่มีการควบคุม (ปัจจุบันมักเรียกว่าแบบจำลองที่มีการควบคุมด้วยตนเอง) ซึ่งเกือบจะสามารถทำงานส่วนใหญ่ของการประมวลผลภาษาธรรมชาติให้เสร็จสิ้นได้ตัวอย่าง ได้แก่ การค้นหาเชิงคำถาม ความเข้าใจในการอ่าน การอนุมานเชิงความหมาย การแปลด้วยคอมพิวเตอร์ การสร้างบทความ และการตอบคำถามอัตโนมัติ เป็นต้น ยิ่งไปกว่านั้น โมเดลนี้ยังมีความยอดเยี่ยมในงานต่างๆ เช่น งานแปลภาษาด้วยเครื่องภาษาฝรั่งเศส-อังกฤษ และเยอรมัน-อังกฤษ ซึ่งล้ำสมัยด้วยบทความที่สร้างขึ้นโดยอัตโนมัติจนแทบแยกไม่ออกจากคนหรือเครื่องจักร (ถูกต้องเพียง 52% เทียบได้กับการคาดเดาแบบสุ่ม) และที่น่าแปลกใจยิ่งกว่านั้นก็คือ มีความถูกต้องเกือบ 100% สำหรับงานบวกและลบเลขสองหลัก และยังสามารถสร้างรหัสโดยอัตโนมัติตามคำอธิบายงานได้อีกด้วยโมเดลที่ไม่มีการควบคุมมีฟังก์ชันมากมายและทำงานได้ดีและดูเหมือนว่าผู้คนจะเห็นความหวังของปัญญาประดิษฐ์ทั่วไป บางทีนี่อาจเป็นสาเหตุหลักที่ทำให้ GPT-3 มีผลกระทบอย่างมาก
รุ่น GPT-3 คืออะไรกันแน่?
ในความเป็นจริง GPT-3 เป็นแบบจำลองภาษาทางสถิติอย่างง่าย จากมุมมองของแมชชีนเลิร์นนิง โมเดลภาษาคือโมเดลของการแจกแจงความน่าจะเป็นของลำดับคำ นั่นคือการใช้เศษส่วนที่ได้รับการกล่าวถึงเป็นเงื่อนไขในการทำนายการกระจายความน่าจะเป็นของการปรากฏตัวของคำต่างๆ ในช่วงเวลาถัดไป ในแง่หนึ่ง แบบจำลองภาษาสามารถวัดระดับความสอดคล้องของประโยคกับไวยากรณ์ของภาษา (เช่น เพื่อวัดว่าการตอบกลับโดยอัตโนมัติจากระบบการสนทนาระหว่างมนุษย์กับคอมพิวเตอร์นั้นเป็นธรรมชาติและราบรื่นหรือไม่) และยังสามารถวัดได้ด้วย ใช้ในการทำนายและสร้างประโยคใหม่ ตัวอย่างเช่น สำหรับกลุ่ม "ตอนนี้ 12 นาฬิกา ไปที่ร้านอาหารด้วยกันเถอะ" โมเดลภาษาสามารถคาดเดาคำที่อาจปรากฏหลังคำว่า "ร้านอาหาร" โมเดลภาษาทั่วไปจะทำนายว่าคำถัดไปคือ "กิน" และโมเดลภาษาที่มีประสิทธิภาพสามารถจับข้อมูลเวลาและทำนายคำว่า "กินข้าวเที่ยง" ที่เหมาะกับบริบทได้
โดยทั่วไป โมเดลภาษาจะแข็งแรงหรือไม่ขึ้นอยู่กับสองประเด็นหลัก ประการแรก โมเดลสามารถใช้ข้อมูลบริบททางประวัติศาสตร์ทั้งหมดได้หรือไม่ ในตัวอย่าง ข้างต้น หากไม่สามารถเก็บข้อมูลความหมายทางไกลของ "12 เที่ยง" ได้ แบบจำลองภาษาแทบจะคาดเดาไม่ได้ คำเดียว "กินข้าวเที่ยง" ประการที่สอง ยังขึ้นอยู่กับว่ามีบริบททางประวัติศาสตร์ที่สมบูรณ์เพียงพอสำหรับแบบจำลองที่จะเรียนรู้หรือไม่ กล่าวคือ คลังข้อมูลการฝึกอบรมมีความสมบูรณ์เพียงพอหรือไม่ เนื่องจากโมเดลภาษาเป็นของการเรียนรู้ด้วยตนเอง เป้าหมายการปรับให้เหมาะสมคือเพิ่มความน่าจะเป็นของโมเดลภาษาของข้อความที่เห็นให้สูงสุด ดังนั้นข้อความใดๆ จึงสามารถใช้เป็นข้อมูลการฝึกอบรมได้โดยไม่ต้องติดป้ายกำกับ
เนื่องจากประสิทธิภาพที่เหนือกว่าและพารามิเตอร์ที่มากขึ้นของ GPT-3 ทำให้มีข้อความหัวข้อมากขึ้น ซึ่งดีกว่า GPT-2 รุ่นก่อนหน้าอย่างเห็นได้ชัด ในฐานะที่เป็นโครงข่ายประสาทเทียมที่หนาแน่นที่สุด GPT-3 สามารถแปลคำอธิบายหน้าเว็บเป็นรหัสที่เกี่ยวข้อง เลียนแบบเรื่องเล่าของมนุษย์ สร้างบทกวีที่กำหนดเอง สร้างสคริปต์เกม และแม้แต่เลียนแบบนักปรัชญาผู้ล่วงลับที่ทำนายความหมายที่แท้จริงของชีวิต และ GPT-3 ไม่ต้องการการปรับแต่งอย่างละเอียด ในแง่ของการจัดการกับปัญหาทางไวยากรณ์ มันต้องการเพียงตัวอย่างบางส่วนของประเภทผลลัพธ์ (การเรียนรู้เพียงเล็กน้อย) อาจกล่าวได้ว่า GPT-3 ดูเหมือนจะตอบสนองทุกจินตนาการของเราสำหรับผู้เชี่ยวชาญด้านภาษา
หมายเหตุ: ข้างต้นส่วนใหญ่อ้างถึงบทความต่อไปนี้:
1. การเปิดตัว GPT 4 กำลังจะเทียบได้กับสมองของมนุษย์ และบิ๊กวิกหลายคนในแวดวงก็อยู่เฉยไม่ได้! -Xu Jiecheng, Yun Zhao-บัญชีสาธารณะ 51 CTO Technology Stack- 2022-11-24 18:08
2. บทความนี้จะตอบข้อสงสัยของคุณเกี่ยวกับ GPT-3! GPT-3 คืออะไร? ทำไมคุณถึงบอกว่ามันดีจัง? -Zhang Jiajun สถาบันระบบอัตโนมัติ Chinese Academy of Sciences เผยแพร่ในปักกิ่ง 11-2020-11 17:25
ชื่อเรื่องรอง
เกิดอะไรขึ้นกับ GPT-3
แต่ GTP-3 ไม่สมบูรณ์แบบ หนึ่งในปัญหาหลักที่ผู้คนกังวลมากที่สุดเกี่ยวกับปัญญาประดิษฐ์คือ แชทบอทและเครื่องมือสร้างข้อความมีแนวโน้มที่จะเรียนรู้ข้อความทั้งหมดบนอินเทอร์เน็ตโดยไม่คำนึงถึงคุณภาพและคุณภาพ แล้วสร้างข้อผิดพลาดที่น่ารังเกียจ หรือแม้กระทั่งภาษาที่ไม่เหมาะสม ซึ่งจะส่งผลต่อแอปพลิเคชันถัดไปอย่างเต็มที่
คำอธิบายภาพ
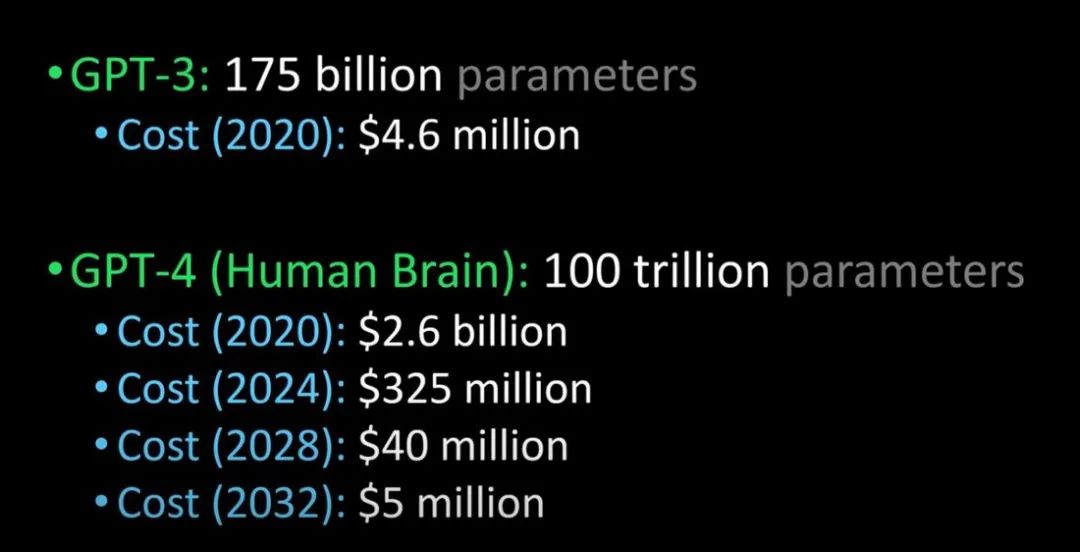
เปรียบเทียบ GPT-3 กับ GPT-4 สมองของมนุษย์ (เครดิตรูปภาพ: Lex Fridman @youtube)
ว่ากันว่า GPT-4 จะเปิดตัวในปีหน้า GPT-4 สามารถผ่านการทดสอบของทัวริงและก้าวหน้าจนแยกไม่ออกจากมนุษย์ นอกจากนี้ ค่าใช้จ่ายในการแนะนำ GPT-4 สำหรับองค์กรก็จะถูกลงในปริมาณมากเช่นกัน
ชื่อเรื่องรอง
ChatGPT และ InstructGPT
เมื่อพูดถึง Chatgpt เรามาพูดถึง InstructGPT "รุ่นก่อน" กัน
ชื่อเรื่องรอง
InstructGPT ทำงานอย่างไร
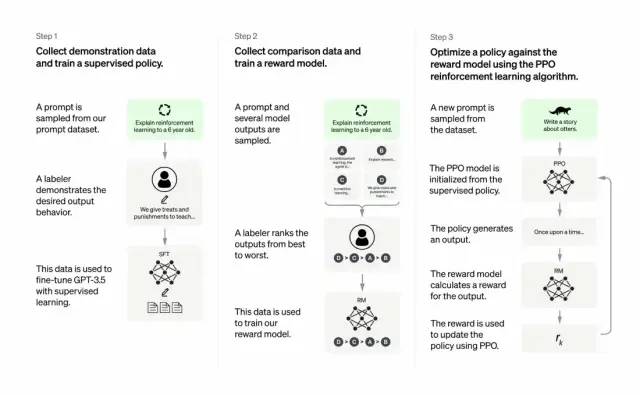
นักพัฒนาทำได้โดยการรวมการเรียนรู้ภายใต้การดูแล + การเรียนรู้แบบเสริมแรงจากความคิดเห็นของมนุษย์ เพื่อปรับปรุงคุณภาพเอาต์พุตของ GPT-3 ในการเรียนรู้ประเภทนี้ มนุษย์จัดอันดับผลลัพธ์ที่เป็นไปได้ของแบบจำลอง อัลกอริทึมการเรียนรู้แบบเสริมกำลังให้รางวัลแก่แบบจำลองที่สร้างเนื้อหาที่คล้ายกับผลลัพธ์ระดับสูง
ชุดข้อมูลการฝึกอบรมเริ่มต้นด้วยการสร้างข้อความแจ้ง ซึ่งบางส่วนอิงตามข้อมูลจากผู้ใช้ GPT-3 เช่น "เล่าเรื่องกบให้ฉันฟังหน่อย" หรือ "อธิบายการลงจอดบนดวงจันทร์ให้เด็กอายุ 6 ขวบฟังในไม่กี่วินาที ประโยค".
นักพัฒนาแบ่งพรอมต์ออกเป็นสามส่วนและสร้างการตอบกลับสำหรับแต่ละส่วนแตกต่างกัน:
นักเขียนมนุษย์ตอบสนองต่อชุดคำสั่งแรก นักพัฒนาได้ปรับแต่ง GPT-3 ที่ผ่านการฝึกอบรมแล้ว โดยเปลี่ยนเป็น InstructGPT เพื่อสร้างการตอบกลับที่มีอยู่สำหรับแต่ละพรอมต์
ขั้นตอนต่อไปคือการฝึกโมเดลเพื่อให้รางวัลสูงขึ้นสำหรับการตอบสนองที่ดีขึ้น สำหรับสัญญาณชุดที่สอง โมเดลที่เพิ่มประสิทธิภาพจะสร้างการตอบสนองหลายรายการ ผู้ประเมินโดยมนุษย์จะจัดอันดับคำตอบแต่ละข้อ เมื่อได้รับการตอบสนองอย่างรวดเร็วและสองคำตอบ โมเดลรางวัล (GPT-3 ที่ได้รับการฝึกฝนล่วงหน้าอีกรุ่นหนึ่ง) จะเรียนรู้ที่จะคำนวณรางวัลที่สูงขึ้นสำหรับคำตอบที่ได้รับคะแนนสูง และรางวัลที่ต่ำกว่าสำหรับคำตอบที่ได้รับคะแนนต่ำ
นักพัฒนาได้ปรับแต่งรูปแบบภาษาเพิ่มเติมโดยใช้คำแนะนำชุดที่สามและวิธีการเรียนรู้แบบเสริมแรงที่เรียกว่า Proximal Policy Optimization (PPO) เมื่อได้รับแจ้ง โมเดลภาษาจะสร้างการตอบกลับ และโมเดลรางวัลจะให้รางวัลตามนั้น PPO ใช้รางวัลเพื่ออัปเดตรูปแบบภาษา
การอ้างอิงสำหรับย่อหน้านี้: The Batch: 329 | InstructGPT, บัญชีสาธารณะแบบจำลองภาษาที่เป็นมิตรและอ่อนโยนกว่า DeeplearningAI- 2022-02-07 12:30
มันสำคัญตรงไหน? แกนหลักอยู่ใน - ปัญญาประดิษฐ์จำเป็นต้องรับผิดชอบปัญญาประดิษฐ์
แบบจำลองภาษาของ OpenAI สามารถช่วยในด้านการศึกษา นักบำบัดเสมือนจริง สื่อช่วยเขียน เกมเล่นตามบทบาท ฯลฯ ในสาขาเหล่านี้ การดำรงอยู่ของอคติทางสังคม ข้อมูลที่ผิด และข้อมูลที่เป็นพิษเป็นปัญหามากกว่า และระบบที่สามารถหลีกเลี่ยงข้อบกพร่องเหล่านี้ได้ มีความสามารถมากขึ้น มีประโยชน์
ขั้นตอนการฝึกอบรมของ Chatgpt และ InstructGPT แตกต่างกันอย่างไร
โดยรวมแล้ว Chatgpt ก็เหมือนกับ InstructGPT ด้านบน ได้รับการฝึกโดยใช้ RLHF (การเรียนรู้การเสริมแรงจากคำติชมของมนุษย์) ความแตกต่างคือวิธีการตั้งค่าข้อมูลสำหรับการฝึกอบรม (และการรวบรวม)(อธิบายที่นี่: โมเดล InstructGPT ก่อนหน้านี้ให้เอาต์พุตสำหรับหนึ่งอินพุต จากนั้นเปรียบเทียบกับข้อมูลการฝึกอบรม หากถูกต้อง จะมีรางวัลให้ และหากผิด จะมีการลงโทษ Chatgpt ปัจจุบันเป็นอินพุตเดียว แบบจำลองให้ผลลัพธ์หลายรายการ จากนั้นผู้คนให้เรียงลำดับผลลัพธ์ ปล่อยให้แบบจำลองเรียงลำดับผลลัพธ์เหล่านี้จาก "เหมือนมนุษย์มากขึ้น" เป็น "ไร้สาระ" และให้แบบจำลองเรียนรู้วิธีที่มนุษย์จัดเรียง กลยุทธ์นี้เรียกว่าการเรียนรู้แบบมีผู้สอน ขอบคุณ Dr. Zhang Zijian สำหรับย่อหน้านี้)
ChatGPT มีข้อจำกัดอะไรบ้าง
ดังนี้
ก) ในระหว่างขั้นตอนการเรียนรู้การเสริมแรง (RL) ของการฝึกอบรม ไม่มีแหล่งที่มาของความจริงและคำตอบตามบัญญัติเฉพาะสำหรับคำถามของคุณ เพื่อตอบคำถามของคุณ
b) แบบจำลองที่ผ่านการฝึกอบรมจะระมัดระวังมากขึ้นและอาจปฏิเสธที่จะตอบ (เพื่อหลีกเลี่ยงผลบวกที่ผิดพลาดสำหรับคำแนะนำ)
ค) การฝึกอบรมภายใต้การดูแลอาจทำให้โมเดลเข้าใจผิด/มีอคติต่อการรู้คำตอบในอุดมคติ แทนที่จะให้โมเดลสร้างชุดคำตอบแบบสุ่ม และมีเพียงผู้ตรวจสอบที่เป็นมนุษย์เท่านั้นที่เลือกคำตอบที่ดี/มีอันดับสูงสุด
ข้อมูลอ้างอิง:
ChatGPT’s self-identified limitations are as follows.
Plausible-sounding but incorrect answers:
a) There is no real source of truth to fix this issue during the Reinforcement Learning (RL) phase of training.
b) Training model to be more cautious can mistakenly decline to answer (false positive of troublesome prompts).
c) Supervised training may mislead / bias the model tends to know the ideal answer rather than the model generating a random set of responses and only human reviewers selecting a good/highly-ranked responseChatGPT is sensitive to phrasing. Sometimes the model ends up with no response for a phrase, but with a slight tweak to the question/phrase, it ends up answering it correctly.
Trainers prefer longer answers that might look more comprehensive, leading to a bias towards verbose responses and overuse of certain phrases.The model is not appropriately asking for clarification if the initial prompt or question is ambiguous.A safety layer to refuse inappropriate requests via Moderation API has been implemented. However, we can still expect false negative and positive responses.
ข้อมูลอ้างอิง:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. การเปิดตัว GPT 4 กำลังจะเทียบได้กับสมองของมนุษย์ และบิ๊กวิกหลายคนในแวดวงก็อยู่เฉยไม่ได้! -Xu Jiecheng, Yun Zhao-บัญชีสาธารณะ 51 CTO Technology Stack- 2022-11-24 18:08
5. บทความนี้จะตอบข้อสงสัยของคุณเกี่ยวกับ GPT-3! GPT-3 คืออะไร? ทำไมคุณถึงบอกว่ามันดีจัง? -Zhang Jiajun สถาบันระบบอัตโนมัติ Chinese Academy of Sciences เผยแพร่ในปักกิ่ง 11-2020-11 17:25
ลิงค์ต้นฉบับ