
ข่าวกรองความร่วมมือ Web3: ต้นไม้ความรู้ ป่าความรู้ และการมีส่วนร่วมของชุมชน
ผู้เขียนต้นฉบับ: Eric Zhang
ผู้เขียนต้นฉบับ: Eric Zhang
ขอขอบคุณเป็นพิเศษสำหรับ Zeo, DAOCtor, Zhengyu, Christina สำหรับการสนับสนุน บทวิจารณ์ และข้อเสนอแนะ
การสร้างฐานข้อมูลโครงสร้างความรู้และการแสดงความรู้เป็นภาพที่ดีขึ้นคือภารกิจสำคัญในการพัฒนาวิทยาการคอมพิวเตอร์ ปัญญาประดิษฐ์ และเว็บ ก่อนการเกิดขึ้นของโลกของสกุลเงินดิจิทัลและแอปพลิเคชันแบบกระจายอำนาจ การวิจัย Web 3.0 แบบเก่าเน้นที่การสร้างฐานความรู้และกราฟความรู้เป็นหลัก และการเป็นตัวแทน/การให้เหตุผลตามโครงสร้างเหล่านี้ (Semantic Web)
มีสองวิธีทั่วไปในการสร้างฐานความรู้ วิธีหนึ่งคือการนำข้อมูลจากเว็บรวมถึงแหล่งข้อมูลอื่นๆ มาจัดระเบียบให้เป็นฐานข้อมูลความรู้ที่ต้องการ (ส่วนใหญ่เป็นคอลเลกชันขนาดใหญ่ของ "สามเท่า" หรือ "กราฟ") จากนั้นใช้ "ลอจิกลำดับที่สูงกว่า" หรือเทคนิคการเรียนรู้ของเครื่องสำหรับ การให้เหตุผลเกี่ยวกับโครงสร้างและงานอัจฉริยะอื่นๆ) อีกวิธีหนึ่งคือการพึ่งพาสติปัญญาของมนุษย์ในการสร้างฐานข้อมูลร่วมกัน (เช่น Wikipedia, ConceptNet หรือโครงการ Citizen Science ซึ่งเราจะกล่าวถึงในรายละเอียดเพิ่มเติมในภายหลัง)
บทความนี้จะทบทวนนวัตกรรมที่เกี่ยวข้องในช่วง 2-3 ทศวรรษที่ผ่านมาก่อน จากนั้นจึงหารือเกี่ยวกับวิธีที่เราจะก้าวไปข้างหน้าเพื่อสร้างฐานข้อมูลความรู้ระดับสูงด้วยปัญญาร่วมและกลไกแรงจูงใจที่ยั่งยืน
ฐานความรู้ กราฟความรู้ และวิกิพีเดีย
เป็นเวลานานแล้วที่ผู้คนให้ความสนใจในการสร้างกราฟความรู้ด้วยเหตุผลหลักสองประการ:
จุดที่เชื่อมต่อข้อมูลและความรู้ทั้งหมดที่มนุษย์สร้างขึ้น
และใช้เทคนิคการให้เหตุผลและการเรียนรู้ของเครื่องบนกราฟความรู้เพื่อสร้างปัญญาประดิษฐ์ที่ดีขึ้น และใช้ระบบนี้เพื่อปรับปรุงประสบการณ์ผู้ใช้ของผลิตภัณฑ์ Web2
ในตอนนี้ กราฟความรู้ที่มีประโยชน์อย่างชัดเจนส่วนใหญ่ถูกสร้างขึ้นเพื่อเป็นเครื่องมือพื้นฐานสำหรับองค์กรขนาดใหญ่ใน Web2 ตัวอย่างเช่น กราฟความรู้ของ Facebook ช่วยในการค้นหาเครือข่ายสังคมที่ดีขึ้น และกราฟความรู้ของ Google ช่วยในการนำเสนอข้อมูลที่เกี่ยวข้อง เนื่องจากทุกอย่างเป็นโอเพนซอร์ส เราจึงไม่รู้ว่ากราฟความรู้ถูกสร้างขึ้นอย่างไร แต่จากมุมมองของ UI กราฟความรู้เหล่านี้จะช่วยปรับปรุงประสบการณ์ของผู้ใช้ได้อย่างแน่นอน
ความพยายามของชุมชน Wikipedia นั้นน่าทึ่งมาก นี่เป็นหนึ่งในความพยายามแรกๆ ที่จะแสดงให้เห็นถึงพลังของชุมชนอินเทอร์เน็ต ในทางกลับกัน ฐานข้อมูลแบบเปิดสามารถใช้เป็นสินค้าสาธารณะทางอินเทอร์เน็ตได้ ตัวอย่างคือ DBpedia ซึ่งเป็นฐานข้อมูลที่ให้บริการ API สำหรับแอปพลิเคชันที่ต้องการใช้ประโยชน์จากฐานความรู้ของวิกิพีเดีย อีกตัวอย่างหนึ่งคือ ConceptNet ซึ่งเป็นเครือข่ายความหมายที่ใช้ได้ฟรีซึ่งช่วยให้โปรแกรม AI และ NLP ได้รับความหมายทั่วไป
อย่างไรก็ตาม มีข้อจำกัดพื้นฐานบางประการว่าองค์กรพัฒนาเอกชนทางอินเทอร์เน็ตเหล่านี้สามารถทำได้มากน้อยเพียงใด วิกิพีเดียอาศัยเงินบริจาคทุกปี ดำเนินการภายในองค์กร 501(c)3 เป็นการยากที่จะให้สิ่งจูงใจขั้นสูงกว่านี้และสร้างโครงสร้างพื้นฐานที่เย็นกว่าบนพื้นฐานเครือข่ายความรู้ เช่นเดียวกันกับ DBpedia และ ConceptNet เป็นต้น ในฐานะองค์กรไม่แสวงหาผลกำไร เป็นเรื่องยากสำหรับองค์กรสวัสดิการสาธารณะเหล่านี้ที่จะสร้างชุมชนอย่างลึกซึ้งที่สร้างโครงสร้างพื้นฐานอย่างต่อเนื่องและสร้างระบบนิเวศในที่สุด ฉันสร้างการแสดงภาพกราฟวิกิพีเดียและเครื่องมือค้นหาในวิทยาลัยโดยใช้ API ของ DBpedia อย่างไรก็ตาม การเข้าร่วมชุมชนที่มีชีวิตชีวาในสมัยนั้นเป็นเรื่องยากกว่ามาก ตอนนี้ในชุมชน crypto สถานการณ์แตกต่างออกไปมาก นักพัฒนาที่มีแนวคิดดีๆ สามารถมีส่วนร่วมในกิจกรรมต่างๆ มากขึ้น จัดตั้งทีม และได้รับการสนับสนุนจากระบบนิเวศแบบหลายห่วงโซ่
อย่างไรก็ตาม ฉันไม่แนะนำให้สร้างวิกิพีเดียอีกแห่ง (หรือที่เรียกว่าวิกิพีเดีย DAO-ify หรือ "วิกิพีเดียเว็บ 3") เพราะแม้จะมีข้อจำกัดของรูปแบบที่ไม่แสวงหาผลกำไรในปัจจุบัน ไซต์วิกิพีเดียได้รับการดูแลอย่างดีในเนื้อหาและโครงสร้าง และองค์กรต่างๆ ผู้คนก็ได้รับประโยชน์จากวิกิพีเดีย ได้ผลเป็นวงกว้าง โดยทั่วไป วิกิพีเดียสามารถจัดเก็บคำอธิบายความรู้ได้ดี และผ่านโครงสร้างพื้นฐาน Web1 และ Web2 เราได้ทำให้ความรู้สามารถค้นหาได้ สิ่งที่วิกิพีเดียและโครงสร้างพื้นฐานเว็บที่มีอยู่ไม่ดีคือการนำเสนอความรู้สำหรับ "ความเข้าใจของมนุษย์" - ความรู้ที่มีโครงสร้างในสมองของมนุษย์ เพื่อนำเสนอข้อมูลนี้ การจัดการโดยมนุษย์และการทำงานร่วมกันของมนุษย์เป็นแกนหลัก ซึ่งไม่ได้รับการสนับสนุนอย่างดีในโครงสร้างพื้นฐาน Web1/Web2 แต่จะเป็นไปได้ผ่านโครงสร้างพื้นฐาน Web3 และกลไกการประสานงาน
**เป็นที่น่าสังเกตว่าผู้คนพยายามสร้างฐานข้อมูลเชิงโครงสร้างขนาดใหญ่เพื่อเพิ่มความเข้าใจในความรู้ของเครื่องจักร ตัวอย่างเช่น บริษัทอย่าง Cyc ได้พยายามสร้างฐานความรู้สามัญสำนึกเพื่อช่วยให้เครื่องจักรเลียนแบบสมองมนุษย์มานานหลายทศวรรษ บริษัทเหล่านี้กลายเป็นบริษัทซอฟต์แวร์ธุรกิจในที่สุด เนื่องจาก AI ที่ทรงพลังนั้นต้องการมากกว่าฐานความรู้ของโหนดและความสัมพันธ์อย่างชัดเจน เมื่อเทียบกับการสร้างฐานความรู้ที่มีโครงสร้างสำหรับเครื่องจักรแล้ว ความเข้าใจของมนุษย์เกี่ยวกับความรู้และการจัดการของมนุษย์มีความสำคัญในการสร้างฐานความรู้ของความเข้าใจของมนุษย์เพื่อช่วยให้ผู้คนเข้าใจมากขึ้น
ในทางกลับกัน คุณควรคิดถึงวิธีเพิ่มความหมายระดับสูงลงในเว็บแห่งความรู้ปัจจุบัน ซึ่งเป็นความรู้เชิงโครงสร้างที่เราอธิบายไว้ในบทความนี้
วิทยาศาสตร์พลเมืองและคอมพิวเตอร์อาสาสมัคร
การสำรวจอีกสาขาหนึ่งที่ฉันอยากพูดถึงคือวิทยาศาสตร์พลเมืองและการคำนวณอาสาสมัคร ในช่วงต้นปี 2010 ชุมชนวิทยาศาสตร์มีโครงการที่น่าตื่นเต้นมากมายที่ใช้ประโยชน์จากภูมิปัญญาของฝูงชนเพื่อเร่งความก้าวหน้าของการวิจัยและการค้นพบทางวิทยาศาสตร์ โดยทั่วไปมีสองประเภทของความพยายามดังกล่าว วิธีแรกเรียกว่าการคำนวณโดยสมัครใจ ซึ่งจะกระจายงานการคำนวณไปยังกลุ่มของอุปกรณ์คอมพิวเตอร์แต่ละเครื่อง (เช่น LHC@Home, SETI@Home) ประเภทที่สองเรียกว่าวิทยาศาสตร์พลเมือง ซึ่งสร้างงานซ้ำๆ (ไม่ใช่คำดูถูกที่นี่!) ที่ทุกคนสามารถทำได้ โครงการรวบรวมข้อมูล (และบางครั้งผลการวิเคราะห์) จากผู้ร่วมให้ข้อมูลจำนวนมากและป้อนเข้าสู่โครงการวิจัยจำนวนมากเพื่อสร้างผลลัพธ์ที่มีความหมาย (เช่น โครงการที่อยู่ใน Citizen Cyberlab, SciStarter หรือชุมชนการเรียนรู้ของเครื่อง สามารถติดแท็กรูปภาพเพื่อเพิ่มข้อมูลการฝึกอบรมได้ ฝูงชน) คิดว่าความพยายามเหล่านี้เป็น "DAO" โดยไม่ต้องประดิษฐ์คำ ด้านการประสานงานของชุมชนที่กระจายอำนาจไม่ใช่เรื่องใหม่!
หลายโครงการประสบความสำเร็จ แต่น่าเสียดายที่ความยั่งยืนของโครงการเหล่านี้ถูกจำกัด SETI@Home ไม่ได้ดำเนินการแล้ว และโครงการวิทยาศาสตร์เพื่อพลเมืองหลายโครงการที่น่าจะคงอยู่ได้นานกว่านั้นไม่ได้ดำเนินการแล้ว สิ่งจูงใจและระบบนิเวศเป็นสองส่วนสำคัญของความพยายามในการทำงานร่วมกัน หากไม่มีระบบนิเวศ นวัตกรรมจะถูกจำกัด หากไม่มีสิ่งจูงใจที่ยั่งยืน ก็จะไม่มีชุมชนที่มีชีวิตชีวาและระบบนิเวศจะไม่เกิดขึ้น
โครงสร้างของแนวคิดและความรู้ที่ซับซ้อน
ตอนนี้เรามาพิจารณาว่าแนวคิดและความรู้ระดับสูงมีลักษณะอย่างไร โดยสัญชาตญาณ เมื่อเรา "เข้าใจ" แนวคิดหนึ่ง เราจะเข้าใจแนวคิดโดยละเอียดจริงๆ เราสามารถนึกถึงกระบวนการ "เข้าใจ" ได้สองวิธี:
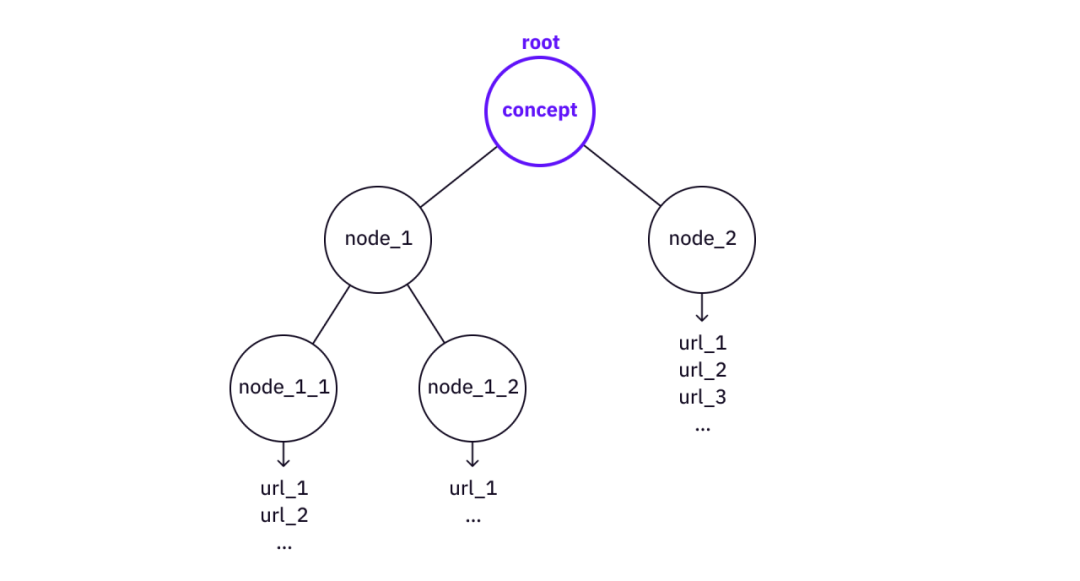
1. ทำความเข้าใจผ่านโครงสร้างต้นไม้
ยิ่งต้นไม้หักลึกมากเท่าใด แนวคิดดั้งเดิมก็ยิ่งมากขึ้นเท่านั้น ในบางจุด จะมีแหล่งข้อมูลบนเว็บที่สามารถอ้างอิงได้โดยตรง (เช่น หน้าวิกิพีเดียหรือบทความ/วิดีโอ)
คำอธิบายภาพ
แนวคิด "แยกส่วน" ออกเป็นโครงสร้างต้นไม้
เราสามารถหาแนวคิดที่คล้ายกันได้จาก AI แบบเก่า ทฤษฎี K-line แสดงให้เห็นว่าความทรงจำและความรู้ของเราถูกเก็บไว้ในโครงสร้างแบบต้นไม้ (P-nodes และ K-nodes) แม้ว่าจะไม่มีหลักฐานที่แท้จริงว่าโครงสร้างดังกล่าวมีอยู่จริงในสมองของเรา แต่แบบจำลองมีพลังในการอธิบายว่าหน่วยความจำของมนุษย์และสมองของมนุษย์ทำงานอย่างไร และโครงสร้างของต้นไม้ก็เป็นรูปแบบที่กะทัดรัดที่สุดในการจัดเก็บความรู้ด้านโครงสร้าง
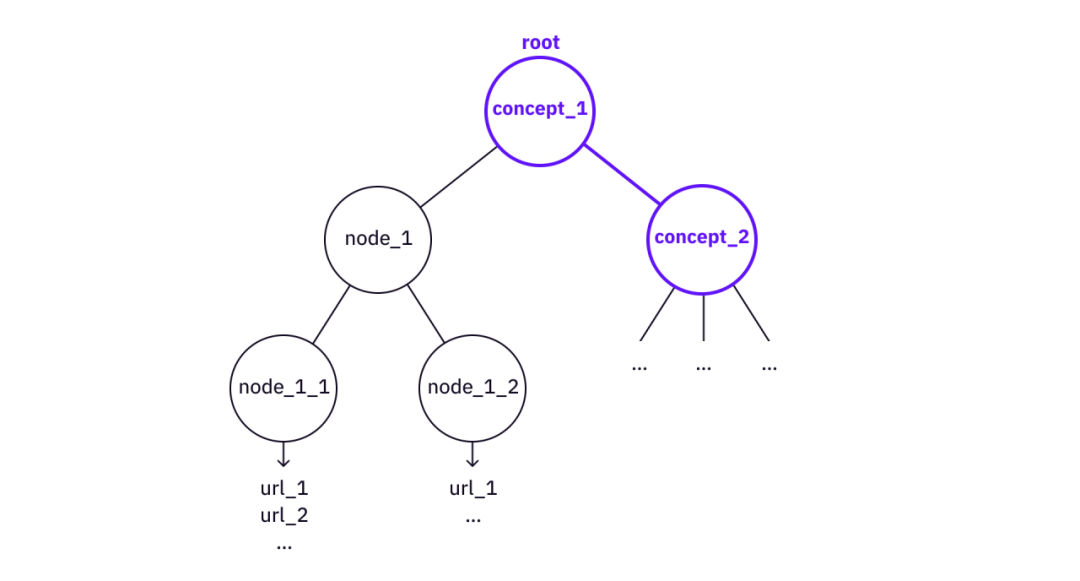
หากเราต้องการดึงรายละเอียด เราจะแยกโครงสร้างความรู้ ในทางกลับกัน ถ้าเรามีต้นไม้แห่งความรู้ เราสามารถใช้ต้นไม้นี้เพื่อสร้างต้นไม้ที่ใหญ่ขึ้นได้ (หรือที่เรียกว่าสิ่งที่เป็นนามธรรมของความรู้และความเข้าใจที่สูงขึ้น)
คำอธิบายภาพ
การใช้ Concept_2 "อาคาร" Concept_1
ในกรณีของ "การก่อสร้าง" ต้นไม้ "ต้นไม้ Merkle" สามารถใช้เป็นโหนดเพื่อสร้างแผนภูมิความรู้ที่ซับซ้อนมากขึ้น เช่น "ต้นไม้ Verkle" หรือ "หลักฐานหลายรายการของ Merkle"
เป็นที่น่าสังเกตว่าประเด็นสำคัญที่นี่คือโครงสร้างของต้นไม้ แผนผังความรู้ชี้ไปที่การอ้างอิงที่จำเป็นทั้งหมดไปยังทรัพยากรบนเว็บที่มีอยู่ตั้งแต่แนวคิดหลักไปจนถึงส่วนต้น ความสัมพันธ์ระหว่างโหนดไม่สำคัญที่นี่ (ไม่เหมือนการคิด "สามเท่า" ในระบบกราฟความรู้)
2. ทำความเข้าใจผ่าน “ความรู้ที่เกี่ยวข้อง”
เรายังได้รับความรู้ความเข้าใจที่ลึกซึ้งยิ่งขึ้นด้วยการเพิ่ม "บริบท" มากขึ้น ดังที่ Weigenstain กล่าวอย่างมีชื่อเสียงว่า "แต่คำว่า 'ห้า' หมายถึงอะไร ไม่มีคำถามดังกล่าวที่นี่ มีแต่คำว่า 'ห้า' ถูกใช้อย่างไร" แนวคิดเบื้องหลังคือความหมายของบางสิ่งขึ้นอยู่กับแนวคิดอื่นๆ ที่เกี่ยวข้องกับสิ่งนั้น ซึ่งร่วมกันกำหนดความหมายของบางสิ่ง โดยการเพิ่มบริบทเพิ่มเติม (นั่นคือความรู้ที่เกี่ยวข้องของความรู้นั้น) เราสามารถเข้าใจความรู้ได้ "ลึกขึ้น" มากขึ้น
โดยทั่วไปแล้ว ผู้คนจะเข้าใจต้นไม้ได้ง่ายกว่ากราฟ แทนที่จะสร้างแผนที่ความรู้ จะเป็นการดีกว่าหากคิดว่า "ความรู้ที่เกี่ยวข้อง" เป็นวิธีที่ใช้ได้จริงมากกว่า นั่นคือชุดของแผนผังความรู้ที่เชื่อมต่อกันด้วยโหนดราก
ป่าความรู้สามารถสร้างเป็นฐานข้อมูลของต้นไม้แห่งความรู้จำนวนมาก (การปลูกแบบขนาน) มีการดำเนินการพื้นฐานสองอย่างที่เราสามารถทำได้บนฐานข้อมูล
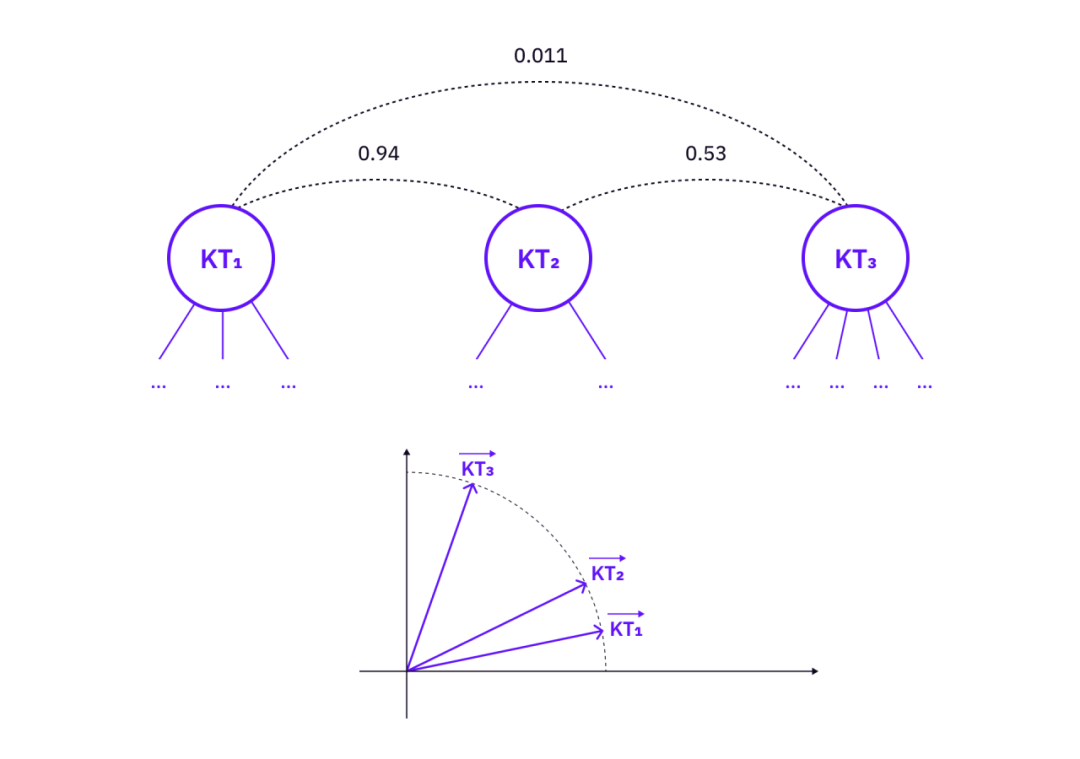
คุณลักษณะของแผนผังความรู้สามารถสร้างเป็นเวกเตอร์ในปริภูมิเวกเตอร์หนึ่งๆ เวกเตอร์สามารถใช้เพื่อเชื่อมโยงแผนผังความรู้ที่เกี่ยวข้องกับแนวคิดแต่ไม่ได้เชื่อมโยงโดยตรงโดย (1)
คำอธิบายภาพ
การวัดความสัมพันธ์ระหว่างแผนผังความรู้
เกี่ยวกับความเข้าใจอย่างลึกซึ้ง
โดยทั่วไปแล้วผู้คนมีระดับความเข้าใจในแนวคิดเดียวกันที่แตกต่างกัน สำหรับบางคน แนวคิดของต้นไม้ Merkle นั้นเรียบง่ายและไม่จำเป็นต้องแยกย่อยเพิ่มเติม (สมองของพวกเขาได้สรุปแนวคิดนี้ไว้ในสามัญสำนึกแล้ว) ในขณะที่คนอื่นๆ ไม่มีข้อมูลเพียงพอที่จะเข้าใจแนวคิดของ "ต้นไม้ Merkle " และอาจต้องมีรายละเอียดเพิ่มเติม
ดังนั้น ต้นไม้ความรู้จึงไม่จำเป็นต้องแยกจากกัน ซึ่งหมายความว่าอาจมีความทับซ้อนกันระหว่างต้นไม้ต่างๆ อาจมีต้นไม้อธิบายแนวคิดพื้นฐาน และต้นไม้ที่สร้างขึ้นสำหรับแนวคิดขั้นสูง
การทับซ้อนกันสามารถสร้างความซ้ำซ้อนระหว่างต้นไม้ เพื่อลดความซ้ำซ้อน เราสามารถแนะนำการดำเนินการต่อไปนี้:
ผสาน - อาจมีทรีย่อยอยู่แล้วภายใต้โหนดของทรีทั้งสอง และหากโหนด ลีฟ และการอ้างอิงที่มีค่าบางโหนดยังไม่ครอบคลุมโดยทรีฐาน การรวมข้อมูลจากทรีระดับสูงกว่าไปยังทรีฐานที่มากขึ้นอาจคุ้มค่ากว่า
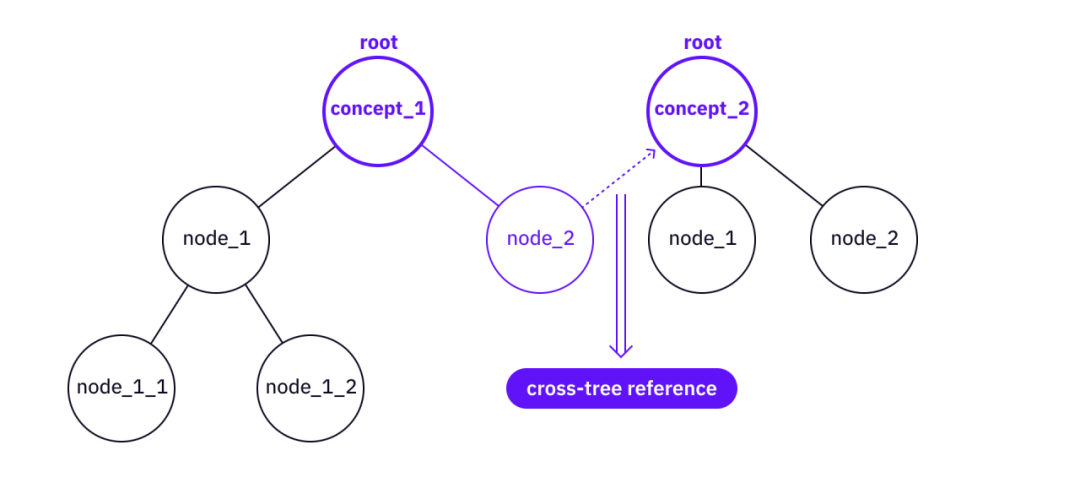
ลิงค์อ้างอิงแบบ Cross-Tree
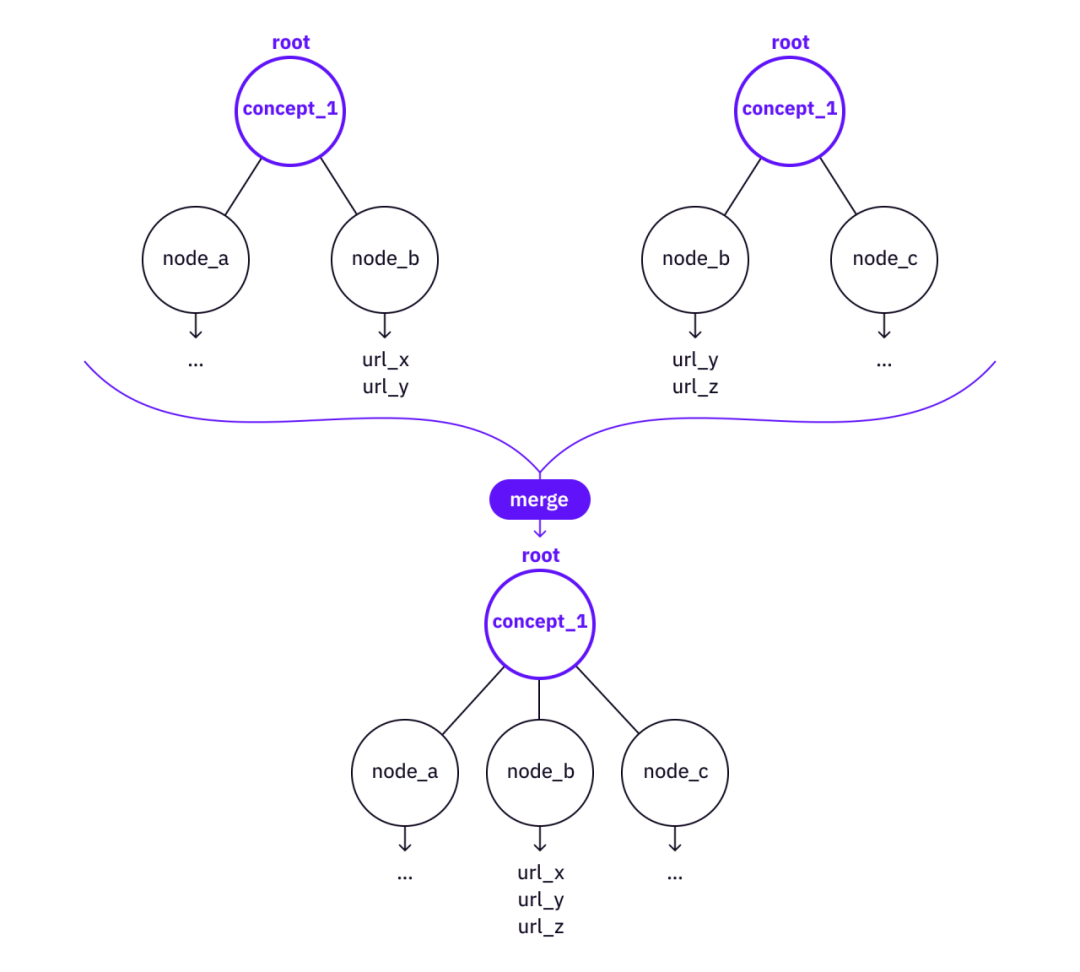
คำอธิบายภาพ
รวมต้นไม้สองต้นเป็นหนึ่งเดียว
แผนผังความรู้และการดำเนินการเมตาดาต้า
ต้นไม้ความรู้เดียวประกอบด้วยราก ชุดของโหนดย่อย และชุดของใบ ซึ่งจัดเป็นโครงสร้างแบบต้นไม้ จากนั้นเราสามารถกำหนดชุดของการดำเนินการพื้นฐานเพื่อสร้างและปรับแต่งแผนผังได้
สร้างราก (ต้นไม้)
เพิ่มโหนดลูก
เพิ่มใบไปยังโหนด
เพิ่มลิงค์อ้างอิงไปยัง leaf
จากนั้นเราสามารถกำหนดชุดของการดำเนินการระดับสูงสำหรับผู้ใช้จริงเพื่อ "ปลูก" และมีส่วนร่วมในต้นไม้
เพิ่มแผนผังย่อย - แนะนำโหนดลูกที่จำเป็นสำหรับแผนผังความรู้ที่มีโหนดและลีฟแบบเต็ม
รวมต้นไม้สองต้นที่มีแนวคิดเดียวกัน
ป่าความรู้
ปลูกต้นไม้แห่งความรู้จำนวนมาก และเรามีป่าแห่งความรู้!
ป่าแห่งความรู้ คือ ต้นไม้แห่งความรู้กลุ่มใหญ่ที่ปลูกรวมกัน ข้อเท็จจริงที่น่าสนใจเกี่ยวกับป่าแห่งความรู้คือต้นไม้สามารถเกี่ยวพันกันได้ ในทางทฤษฎี การเชื่อมต่อระหว่างโหนดและลีฟที่แตกต่างกันสามารถเป็นไปตามอำเภอใจ (เช่น การเชื่อมต่อระหว่างลีฟของต้นไม้ต้นหนึ่งกับรากของต้นไม้อีกต้น) ในความเป็นจริง หากเราเพิ่มลิงก์แบบเส้นประ แหล่งความรู้ "แบบ" จะกลายเป็นกราฟความรู้ อย่างไรก็ตาม ต้นไม้ความรู้ส่วนบุคคลมีความสำคัญ
ตัวอย่างเช่น เส้นประระบุการเชื่อมโยงระหว่างต้นไม้ MACI และต้นไม้ zk-Snark
ใบไม้ของแผนผังความรู้เชื่อมต่อกับบทความ/วิดีโอ/ทรัพยากรที่มีอยู่บนเว็บไซต์ ดังนั้นชั้นที่อยู่เหนือใบไม้เหล่านี้จึงเป็นชั้นข้อมูลโครงสร้างหรือชั้นความเข้าใจ
สิ่งที่เราสามารถทำได้กับ Knowledge Forest นั้นเปิดกว้างอย่างสมบูรณ์ สิ่งที่สำคัญที่สุดที่เราควรพิจารณาคือระบบนิเวศของฐานความรู้ที่ทำงานร่วมกันตั้งแต่เริ่มต้น เราอาจต้องการทำหลายสิ่งหลายอย่างกับป่าความรู้ นี่คือสามตัวอย่าง:
การแสดงต้นไม้แห่งความรู้และป่าแห่งความรู้
เรียกดู Knowledge Forest ผ่านจุดเชื่อมโยง
ค้นหากลุ่มต้นไม้แห่งความรู้
องค์กรไม่แสวงผลกำไรสามารถทำให้สิ่งต่างๆ เกิดขึ้นได้ แต่ DAO สามารถทำให้สิ่งต่างๆ ดีขึ้นได้ แนวคิดนี้คือการจับคู่ชุดของการดำเนินการของต้นไม้กับชุดของสิ่งเร้า ยิ่งการดำเนินการเมตาเป็นมาตรฐานมากเท่าใด DAO ก็ยิ่งปรับขนาดได้มากขึ้นสำหรับการประสานงานกับสมาชิก
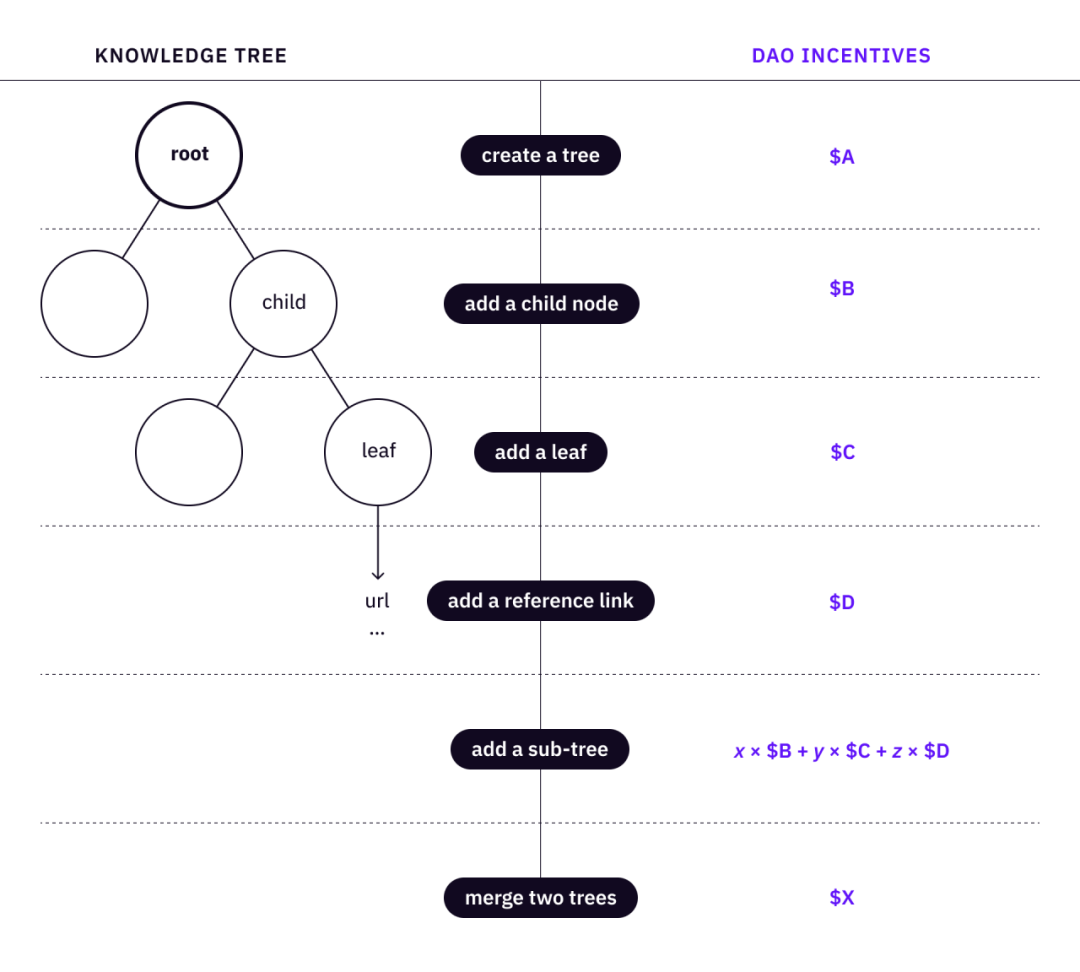
คำอธิบายภาพ<->ปฏิบัติการต้นไม้แห่งความรู้
การมีส่วนร่วมของ DAO
ในกรณีของแผนผังความรู้ ผู้สนับสนุน DAO สามารถสร้างราก (เทียบเท่ากับ "สร้าง/ปลูกต้นไม้") เพิ่มเส้นทางความรู้ ("ปลูกต้นไม้") และเพิ่มลิงก์อ้างอิงไปยังใบไม้ กลไกการจูงใจสร้างกฎขึ้นมาชุดหนึ่งเพื่อให้รางวัลแก่ผู้ร่วมให้ข้อมูลในชุมชนที่ดำเนินการตรวจสอบได้เพื่อวางแผนและปลูกต้นไม้แห่งความรู้
นอกจากนี้ คณะกรรมการตรวจสอบ (หรือกลุ่มตรวจสอบ) ยังมีความสำคัญต่อการวางแผนและการควบคุมคุณภาพ มีการทดลองใช้การประสานงานและแรงจูงใจสำหรับ DAO อย่างกว้างขวาง (เช่น DAOrayaki DAO) และสามารถนำโครงสร้างที่คล้ายกันไปใช้ได้ที่นี่
ป่าความรู้และกราฟความรู้
ต้นไม้จะเข้าใจได้ง่ายขึ้นเมื่อเราเรียนรู้แนวคิดใหม่และได้รับความรู้ สำหรับหัวข้อใดหัวข้อหนึ่ง มันเป็นเรื่องง่ายสำหรับมนุษย์ที่จะเข้าใจโครงสร้างความรู้ในต้นไม้เพราะไม่มีการวนซ้ำในต้นไม้ และถ้าความลึกของต้นไม้ถูกจำกัดไว้ที่ระดับหนึ่ง สมองของมนุษย์จะง่ายกว่ามากที่จะ ประมวลผลและจดจำ
นอกจากนี้ การแสดงกราฟความรู้ยังมีข้อจำกัดในการแสดงความสัมพันธ์ที่ไม่ชัดเจนหรือคลุมเครือระหว่างโหนดความรู้ (ประเด็นเดียวกับการแสดงความรู้ทั่วไป)
ทีมงานของ BUIDLers ที่ทำงานเกี่ยวกับการนำ Knowledge Trees และ Knowledge Forests ไปใช้จริงมีรายละเอียดมากมาย - โครงสร้างข้อมูล การออกแบบผลิตภัณฑ์ รายละเอียดการสนับสนุนและแรงจูงใจ UI ฯลฯ อย่างไรก็ตาม หากจะสร้างป่าแห่งความรู้ ฉันรู้สึกว่าโดยทั่วไปแล้วควรจัดให้เป็นสาธารณประโยชน์และให้ทุกคนในโลกเข้าถึงได้ แต่มาดูกันว่าชุมชน Dora เกิดอะไรขึ้น!
สรุปแล้ว
แนวคิดคือการสร้างฐานความรู้ประเภทใหม่บนโครงสร้างพื้นฐานเว็บที่มีอยู่ (เช่น Wikipedia เป็นต้น) และทำให้ทุกคนเข้าถึงได้ ซึ่งช่วยลดความซับซ้อนในการทำความเข้าใจความรู้เชิงนามธรรม (เช่น การกำหนดเส้นทางเว็บบนกราฟความรู้ เช่น วิกิพีเดียหรือวิกิพีเดียอาจซับซ้อนพอๆ กับ O(nlog(n)) แต่ต้นไม้ที่มี n โหนดจะมีความลึกเพียง log(n) ซึ่งทำให้การนำทางง่ายขึ้น) ประสานงานกับผู้ร่วมให้ข้อมูลใน DAO และใช้สิ่งจูงใจแบบ crypto-native ขั้นสูงเพื่อให้มั่นใจถึงความยั่งยืนขององค์กร แนวคิดในบทความนี้ยังไม่สมบูรณ์ มีพื้นที่มากมายสำหรับการอภิปรายและการปรับปรุง และมีปัญหาด้านวิศวกรรมและผลิตภัณฑ์มากมายที่ต้องพิจารณาหากทีมต้องการทำให้เป็นจริง
อ้างอิง
อ้างอิง
เว็บความหมาย: https://en.wikipedia.org/wiki/Semantic_Web
ทริปเปิล: https://conceptnet.io/
ConceptNet:https://conceptnet.io/
DBpedia:https://www.dbpedia.org/
ตรรกะลำดับที่สูงกว่า: https://en.wikipedia.org/wiki/Cyc
https://github.com/zhangjiannan/Graphpedia
Wikipedia การแสดงกราฟและเครื่องมือค้นหา:
Cyc:https://en.wikipedia.org/wiki/Cyc
ระบบนิเวศหลายห่วงโซ่: https://hackerlink.io/grant/dora-factory/top
LHC@Home:https://lhcathome.cern.ch/lhcathome/
SETI@Home:https://setiathome.berkeley.edu/
Citizen Cyberlab:https://www.citizencyberlab.org/projects/
SciStarter:https://scistarter.org/
คอมพิวเตอร์อาสาสมัคร: https://en.wikipedia.org/wiki/Volunteer_computing
เครื่องมือสร้างกราฟความรู้ 1: https://obsidian.md/


