
文章
実用的なビザンチン フォールト トレランス (PBFT) は、チャネルが信頼できる場合にビザンチン ジェネラル問題を解決する実用的な方法です。ビザンチン将軍問題は、1982 年に発表された論文 [1] で Leslie Lamport らによって初めて提案されました。より少なく、忠実な将軍は命令に関して合意に達することができます。つまり 3f+1<=n の場合、アルゴリズムの複雑さは O(n^(f+1)) です。その後、Miguel Castro と Barbara Liskov が 1999 年に発表した論文 [2] で初めて PBFT アルゴリズムを提案しました。このアルゴリズムのフォールトトレランス数も 3f+1<=n を満たし、アルゴリズムの複雑さは O(n^ 2)。
PBFT コンセンサス アルゴリズムを理解している場合は、ノードの総数 n とフォールト トレランスの上限 f の関係に精通しているかもしれません。システム内に障害のあるノードが最大 f 個あるという前提の下では、システム内のノードの総数 n は、n>3f を満たす必要があります。コンセンサスを進めるプロセスでは、認証プロセスを完了するために一定数の投票を集める必要があります。このセクションでは、まず、これらの値間の関係をどのように導き出すことができるかについて説明します。
--クォーラムの仕組み--
冗長データを備えた分散ストレージ システムでは、冗長データ オブジェクトが異なるマシン間で複数のコピーを保存します。ただし同時に、データ オブジェクトの複数のコピーは読み取りまたは書き込みにしか使用できません。データの冗長性と一貫性を維持するには、対応する投票メカニズム (クォーラム メカニズム) が必要です。分散システムとして、ブロックチェーンはクラスターのメンテナンスにもこのメカニズムを必要とします。
クォーラム メカニズムをよりよく理解するために、まず、類似しているがより極端な投票メカニズムである WARO メカニズム (Write All Read One) を理解しましょう。 WARO メカニズムを使用してノードの総数が n のクラスターを維持する場合、書き込み操作を実行するノードの「投票」は n である必要がありますが、読み取り操作の「投票」は 1 に設定できます。つまり、書き込み操作を実行するときは、操作が完了したとみなされる前に、すべてのノードが書き込み操作を完了することを確認する必要があります。そうしないと、書き込み操作は失敗します。これに対応して、読み取り操作を実行するときは、状態のみが表示されます。 1 つのノードの状態を読み取る必要があるため、システムのステータスを確認できます。 WARO メカニズムを使用するクラスターでは、書き込み操作の実行は非常に脆弱であることがわかります。1 つのノードが書き込みの実行に失敗する限り、操作は完了できません。ただし、書き込み操作の堅牢性は犠牲になりますが、WARO メカニズムの下では、クラスター上で読み取り操作を実行するのは非常に簡単です。
クォーラム メカニズム [3] は、読み取りおよび書き込み操作の妥協案です。同じデータ オブジェクトの各コピーについて、読み取りおよび書き込みが行われるアクセス オブジェクトは 2 つまでであり、読み取りと書き込みのセット サイズ要件が比較検討されます。分散クラスターでは、各データ コピー オブジェクトに投票が与えられます。仮定:
システムには V 個のチケットが存在します。これは、データ オブジェクトに V 個の冗長コピーがあることを意味します。
各読み取り操作で、正常に読み取られるためには、取得される投票数が最小読み取り投票数 R (読み取りクォーラム) を下回ってはなりません。
書き込み操作ごとに、正常に書き込まれるためには、取得される投票数が最小書き込み投票数 W (書き込みクォーラム) を下回ってはなりません。
クラスター内のコンセンサス ノードの場合、コンセンサス アルゴリズムを進めるとき、コンセンサスに参加しているノードはクラスター上で読み取りおよび書き込み操作を同時に実行します。コレクションのサイズに対する読み取り操作と書き込み操作の要件のバランスをとるために、各ノードの R と W は同じサイズ (Q で示されます) になります。クラスター内に合計 n 個のノードがあり、エラー ノードが最大で f 個ある場合、n、f、Q の関係はどのように計算すればよいでしょうか?次に、最も単純な CFT シナリオから始めて、BFT シナリオでこれらの数値間の関係を取得する方法を徐々に検討していきます。
▲CFT
文章
CFT (クラッシュ フォールト トレランス) とは、システム内のノードがクラッシュ (Crash) のエラー動作のみを経験し、どのノードも積極的にエラー メッセージを送信しないことを意味します。コンセンサス アルゴリズムの信頼性について議論するとき、私たちは通常、アルゴリズムの 2 つの基本特性、つまり生存性と安全性に焦点を当てます。 Q の大きさを計算する際には、これら 2 つの角度から考慮することもできます。
アクティビティとセキュリティについては、より直感的に説明する方法があります。
何かが最終的に起こる[4]、出来事は最終的に起こるだろう
何か良いことが最終的に起こる[4]、最終的に起こるこの出来事は合理的です
アクティビティの観点から見ると、クラスターは実行を継続できる必要がありますが、一部のノードのエラーによりコンセンサスを継続できません。セキュリティの観点から、私たちのクラスターはコンセンサス推進のプロセスで妥当な結果を取得し続けることができます。分散システムの場合、この「妥当な」結果の最も基本的な要件は、クラスターの全体的な状態の一貫性です。
したがって、CFT シナリオでは、Q 値の決定が単純かつ明確になります。<=n-f。
アクティビティ: クラスターが実行し続けられることを確認する必要があるため、コレクションのデータの読み取りと書き込みを行うために、どのシナリオでも Q チケットを取得できることを確認する必要があります。クラスター内の最大 f 個のノードがダウンするため、Q 個のチケットを確実に取得できるようにするには、この値のサイズが次を満たす必要があります。Q
▲BFT
セキュリティ: クォーラム メカニズムの基本要件に従ってクラスターが分岐しないようにする必要があるため、前のセクションで説明した 2 つの不等式を満たす必要があり、Q は最小読み取り値としてこの一連の不等式に組み込まれます。このとき、Q は、Q+Q>n かつ Q>n/2 という不等式の関係を満たすため、この値の大きさは Q>n/2 を満たす必要があります。
BFT (ビザンチン フォールト トレランス)。これは、クラスター内の間違ったノードがダウンするだけでなく、悪意のある動作、つまりアクティブ ステート フォークなどのビザンチン動作を行う可能性があることを意味します。この場合、クラスター全体として、nf 個のノードのみが信頼できる状態にあり、Q 個の投票を収集すると、信頼できるノードからは Qf 個の投票のみが得られます。したがって、セキュリティの観点から、BFT シナリオでは、信頼できる状態を持つノード間に乖離がないことを保証する必要があるため、次の 2 つの関係が得られます。<=n-f。
アクティビティ: Q チケットを常に入手できる可能性があることを確認するだけで十分です。したがって、Q
▲総ノード数と耐障害性の上限
文章
ノードの総数 n とフォールト トレランスの上限 f については、PBFT 論文 [1] で説明されています。ダウンしている可能性のあるノードが f 個あるため、少なくとも nf 個のメッセージを受信したときに応答する必要があります。 nf 個のノードからメッセージを受信するには、信頼性の低い Byzantine ノードからのメッセージは最大でも f 個である可能性があるため、nff>f、つまり n>3f を満たす必要があります。簡単に言うと、PBFT の作成者は、クラスタのアクティビティとセキュリティの観点から、ノードの総数とフォールト トレランスの上限との関係を取得しました。前のセクションでは、アクティビティとセキュリティの観点から n、f、Q の関係も取得しました。これは、ここでのアクティビティとセキュリティの要件を満たすために、n と f の関係を導出するためにも使用できます。同時に、Q は不等式関係 Q<=nf および Q>(n+f)/2 を満たす必要があるため、n と f の間の不等式関係 (n+f)/2 が得られます。
(同様の方法で、CFT シーンの n と f の関係も取得できます (n > 2f)。)
--PBFT と RBFT--
BFT シナリオにおける n、f、Q の関係を理解した後、PBFT の導入に進みましょう。その前に、SMR (State Machine Replication) レプリケーション ステート マシンについて簡単に説明します [5]。このモデルでは、異なるステート マシンが同じ初期状態から開始し、同じ命令セットを同じ順序で入力した場合、常に同じ最終結果が得られます。コンセンサス アルゴリズムの場合、各ステート マシンで同じ状態を取得するには、「同じ命令が同じ順序で入力される」ことを確認するだけで済みます。 PBFT は命令の実行順序に関する合意です。
▲ 2段階のコンセンサス
文章
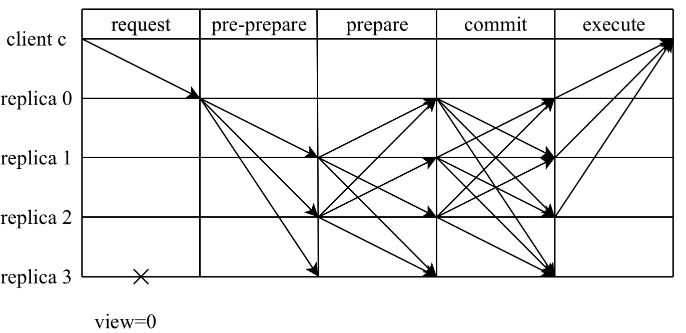
より一般的な「3 段階」の概念 (事前準備、準備、コミット) と比較して、PBFT を 2 段階のコンセンサス プロトコルとみなすと、提案段階 (事前準備と準備) とコミットという各段階の目的がよりよく反映される可能性があります。ステージ (コミット)。各ステージでは、次のステージに入る前に、各ノードは Q 個のノードから全会一致の投票を集める必要があります。ここでは、議論を容易にするために、ノードの総数が 3f+1 である場合のシナリオを説明します。このとき、読み取りおよび書き込みチケットの数 Q は 2f+1 です。
1) 提案段階
このフェーズでは、マスター ノードはコンセンサスを開始するために pre-prepare を送信し、スレーブ ノードはマスター ノードの提案を確認するために prepare を送信します。クライアントからリクエストを受信した後、マスターノードは事前準備メッセージを他のノードに積極的にブロードキャストします。
v は現在のビューです
n マスターノードによって割り当てられたリクエストシーケンス番号
D(m) はメッセージ ダイジェストです
m はメッセージそのものです
pre-prepare メッセージを受信したスレーブ ノードは、メッセージの正当性を検証し、検証に合格すると、pre-prepare 状態になり、リクエストがスレーブ ノードでの正当性検証に合格したことを示します。それ以外の場合、スレーブ ノードはリクエストを拒否し、ビュー切り替えプロセスをトリガーします。スレーブノードが事前準備状態に入ると、準備メッセージを他のノードにブロードキャストします。
i は現在のノードの識別番号です
他のノードがメッセージを受信した後、リクエストが現在のノードで事前準備状態に入り、異なるノードから対応する準備メッセージ (それ自体を含む) を受信すると、リクエストは準備済み状態に入り、提案フェーズが完了します。この時点で、2f+1 ノードがシーケンス番号 n をメッセージ m に割り当てることに同意します。これは、コンセンサス クラスターがメッセージ m にシーケンス番号 n を割り当てたことを意味します。
2) 提出フェーズ
▲チェックポイントの仕組み
文章
PBFT コンセンサス アルゴリズムの動作中、大量のコンセンサス データが生成されるため、冗長なコンセンサス データをタイムリーにクリーンアップする合理的なガベージ コレクション メカニズムを実装する必要があります。この目標を達成するために、PBFT アルゴリズムはガベージ コレクションのチェックポイント プロセスを設計します。
チェックポイントはチェックポイントであり、クラスターが安定した状態に入ったかどうかを確認するプロセスです。チェック時に、ノードはチェックポイント メッセージをブロードキャストします。
n は現在のリクエストのシーケンス番号です。
d はメッセージの実行後に取得されるダイジェストです
i は現在のノードを表します
チェックポイント メッセージの後、現在のクラスターはシーケンス番号 n の安定したチェックポイント (安定したチェックポイント) に入ったと考えることができます。この時点で、安定チェックポイント前のコンセンサス データは不要になり、クリーンアップできます。しかし、ガベージコレクションのためのチェックポイントが頻繁に実行されると、システム運用に多大な負荷がかかります。したがって、PBFT はチェックポイント プロセスの実行間隔を設計し、k 個のリクエストが実行されるたびに、ノードはアクティブにチェックポイントを開始して最新の安定したチェックポイントを取得します。
さらに、PBFT では、ガベージ コレクションを支援するために高/低ウォーターマークの概念が導入されています。コンセンサスプロセス中に、ノード間のパフォーマンスの差により、ノード間の動作速度の差が大きすぎる状況が発生する可能性があります。一部のノードで実行されるシーケンス番号が他のノードよりも先になる場合があり、その結果、先頭のノードのコンセンサスデータが長時間クリアされず、過剰なメモリ使用の問題が発生し、高水位と低水位の機能が低下します。クラスターの全体的な実行速度を制限するため、ノードのコンセンサス データ サイズが制限されます。
▲ビュー切り替え
文章
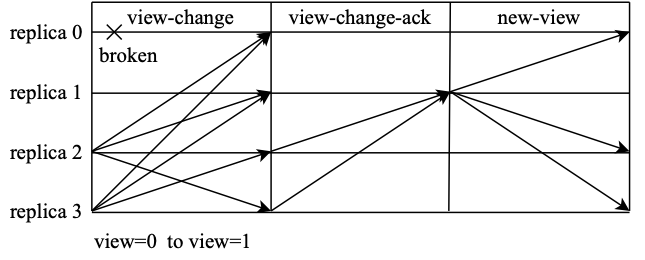
ビュー変更は、マスター ノードがタイムアウトして応答しない場合、またはスレーブ ノードが集合的にマスター ノードが問題のあるノードであると判断した場合にトリガーされます。ビューの変更が完了すると、ビュー番号が 1 つ増加し、マスター ノードが次のノードに切り替わります。図に示すように、ノード 0 で例外が発生してビュー変更プロセスがトリガーされ、変更が完了すると、ノード 1 が新しいプライマリ ノードになります。
ビュー変更が発生すると、ノードは積極的に新しいビュー v+1 に入り、マスター ノードの切り替えを要求するビュー変更メッセージをブロードキャストします。この時点で、コンセンサス クラスタは、古いビューでコンセンサスが完了したリクエストが新しいビューでも保持されることを確認する必要があります。したがって、ビュー変更リクエストでは、通常、古いビューのコンセンサスログの一部を追加する必要があり、ノードによってブロードキャストされるリクエストは
i は送信ノードの ID です
v+1 は、リクエストが入る新しいビューを示します
h は現在のノードの最新の安定したチェックポイントの高さです
同様に保存すると、現在のノードがシーケンス番号 n とダイジェスト d でチェックポイント チェックを実行し、対応するコンセンサス メッセージを送信したことを意味します。
同様に格納すると、ビューvにおいてサマリがd、シーケンス番号がnのリクエストが準備状態になったことを意味する。リクエストが準備済み状態に達しているということは、少なくとも 2f+1 ノードがリクエストを所有して承認していることを意味し、整合性の確認はコミット段階でのみ完了できるため、新しいビューでは、メッセージのこの部分は次のようになります。新しいシーケンス番号を割り当てずに、元のシーケンス番号を直接使用します。
保管方法。リクエストは準備済み状態になっているため、現在のノードによってリクエストが承認されたことを意味します。
ただし、他のノードによって送信されたビュー変更メッセージを受信した後、ビュー v+1 に対応する新しいプライマリ ノード P は、ビュー変更メッセージが Byzantine ノードによって送信されたかどうかを確認できず、正しいメッセージを使用する必要があることを保証できません。意思決定のために。 PBFT を使用すると、すべてのノードが view-change-ack メッセージを通じて受信したすべての view-change メッセージをチェックして確認し、確認された結果を P に送信できます。マスター ノード P は view-change-ack メッセージをカウントし、どの view-change が正しく、どれが Byzantine ノードによって送信されたかを識別できます。
ノードが view-change メッセージを確認すると、ノード内の P セットと Q セットがチェックされ、セット内の要求メッセージは view v 以下である必要があります。要件が満たされる場合、view-change は-ackメッセージが送信されます
i は ack メッセージを送信したノード ID です
jは確認するビュー変更メッセージの送信者IDです
d は確認するビュー変更メッセージのダイジェストです
一般的なメッセージのブロードキャストとは異なり、デジタル署名はメッセージの送信者を識別するために使用されなくなりましたが、セッション キーは現在のノードとマスター ノード間の通信の信頼性を確保するために使用され、それによってマスター ノードを支援します。見解変更メッセージの信頼性を判断するため。
新しいプライマリノード P は、検証された正しいビュー変更メッセージを保存するための集合 S を維持します。 P がビュー変更メッセージと合計 2f-1 個の対応するビュー変更確認メッセージを取得すると、このビュー変更メッセージをセット S に追加します。セット S のサイズが 2f+1 に達すると、ビューの変更を開始するのに十分な非ビザンチン ノードがあることが証明されます。マスターノードPは、新しいビューメッセージを生成し、受信したビュー変更メッセージに従ってそれをブロードキャストする。
これは、ノード i によって送信されたビュー変更メッセージのダイジェストが d であり、これは集合 S 内のメッセージに対応し、他のノードは集合内のダイジェストとノード ID を使用してビュー変更の正当性を確認できることを意味します。
X: 安定したチェックポイントと、新しいビューをオプトインするためのリクエストが含まれます。新しいプライマリ ノード P は、セット内の S のビュー変更メッセージに従って計算し、C、P、Q のセットに従って新しいビューに保持する必要がある最大安定チェックポイントとリクエストを決定します。集合 X に書き込む このうち、具体的な選択プロセスは比較的面倒なので、興味があれば原論文 [6] を参照してください。
▲改善スペースとRBFT
RBFT (Robust Byzantine Fault Tolerance) は、エンタープライズ レベルのアライアンス チェーン プラットフォーム向けに PBFT に基づいて Qulian Technology によって開発された非常に堅牢なコンセンサス アルゴリズムです。 PBFT と比較して、RBFT コンセンサス アルゴリズムがより複雑で多様な実際のシナリオに対応できるように、コンセンサス メッセージ処理、ノード状態の回復、クラスターの動的メンテナンスなどの側面が最適化および改善されています。
1) トレーディングプール
RBFT を含む多くのコンセンサス アルゴリズムの産業実装では、独立したトランザクション プール モジュールが設計されています。トランザクションを受信した後、トランザクション自体はトランザクションプールに格納され、トランザクションプールを介してトランザクションが共有されることで、各コンセンサスノードは共有トランザクションを取得できるようになります。コンセンサスプロセスでは、トランザクションハッシュのみをコンセンサスする必要があります。
大規模なトランザクションを処理する場合、トランザクション プールのコンセンサスの安定性は大幅に向上します。トランザクション プールをコンセンサス アルゴリズム自体から切り離すことで、トランザクション プールを介してトランザクション重複排除などのより高機能な機能を実装することが容易になります。
2) アクティブリカバリー
PBFT では、ノードがチェックポイントまたはビュー変更を通じて自身の低水位が遅れていることを発見したとき、つまり、安定したチェックポイントが遅れているとき、遅れているノードは対応する回復プロセスをトリガーして、安定したチェックポイントの前にデータをプルします。このような後方回復メカニズムには、いくつかの欠点があります。一方で、回復プロセスのトリガーは受動的であり、逆方向回復は、チェックポイント プロセスまたはトリガーされたビュー変更が完了した場合にのみトリガーできます。他方、バックワード ノード、自身の安定したチェックポイントが遅れていることが判明した場合、バックワード ノードは最新の安定したチェックポイントに復元することしかできませんが、チェックポイントの背後にあるコンセンサス メッセージを取得できず、真に参加できない可能性があります。コンセンサス。
RBFT では、アクティブなノード回復メカニズムを設計しました。一方で、回復メカニズムをアクティブにトリガーして、遅れているノードをより速く回復できるようにします。他方では、最新の安定したチェックポイントに回復することに基づいて、水位間の回復メカニズムが確立されているため、遅れているノードは最新のコンセンサス ニュースを取得し、通常のコンセンサス プロセスに迅速に参加できます。
3) クラスターの動的メンテナンス
エンジニアリングで広く使用されているコンセンサス アルゴリズムである Raft の重要な利点の 1 つは、クラスター メンバーの変更を動的に完了できることです。ただし、PBFT はクラスター メンバーの動的な変更スキームを提供していないため、実際のアプリケーションには不十分です。 RBFTでは、クラスタメンバーを動的に変更する仕組みを設計し、クラスタ全体を停止することなくクラスタメンバーの追加や削除ができるようにしました。
ノードを追加または削除する場合、管理者はノードを操作するための提案を作成するトランザクションをクラスターに送信し、他の管理者の投票を待ちます。投票が可決された後、提案を作成した管理者は実行提案構成トランザクションを送信します。クラスタに再度接続すると、実行構成時にクラスタが変更されます。
コンセンサス部分については、提案構成トランザクションを処理および実行するときに、クラスター内のノードは構成変更状態になり、他のトランザクションはパッケージ化されません。マスター ノードはトランザクションを個別にパッケージ化して構成パッケージを生成し、その構成パッケージに同意します。構成パッケージがコンセンサスを完了すると、それが実行され、構成ブロックが生成されます。変更された構成ブロックがロールバックできないようにするために、コンセンサス層は変更された構成パッケージの実行結果を待ち、クラスター内の構成パッケージの高さに対して安定したチェックポイントが形成されていることを確認してから解放します。ノードの構成ステータスを確認し、他のトランザクションのパッケージ化を継続します。
クラスター メンバーを動的に変更するこの方法により、クラスター構成のメンテナンスの信頼性と利便性が向上し、より多くの構成情報を動的に変更できるようになります。
著者について
著者について
FunChain技術部 基盤プラットフォーム部 コンセンサスアルゴリズム研究グループ
参考文献
[1] Lamport L, Shostak R, Pease M. The Byzantine generals problem[M]//Concurrency: the Works of Leslie Lamport. 2019: 203-226.
[2] Castro M, Liskov B. Practical Byzantine fault tolerance[C]//OSDI.1999, 99(1999): 173-186.
[3] https://en.wikipedia.org/wiki/Quorum _ (distributed_computing)
[4] Owicki S, Lamport L. Proving liveness properties of concurrent programs[J]. ACM Transactions on Programming Languages and Systems (TOPLAS), 1982, 4(3): 455-495.
[5] Fred B. Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv., 22(4):299–319, 1990.
[6] Castro M, Liskov B. Practical Byzantine fault tolerance andproactive recovery[J]. ACM Transactions on Computer Systems (TOCS), 2002,20(4): 398-461.


