
「더 이상 더 나은 모델은 필요 없어」: 레딧 핫게시물 속 AI 군상
- 핵심 의견: Anthropic이 출시한 Claude Fable 5 모델은 벤치마크 테스트에서 큰 폭으로 앞서고 있지만, 사용자들은 성능 과잉, 높은 비용, 그리고 안전 장치로 인한 대부분의 요청 거절을 문제 삼으며 '충분파'와 '고난이도 작업파' 사이의 치열한 논쟁을 불러일으키고 있다.
- 핵심 요소:
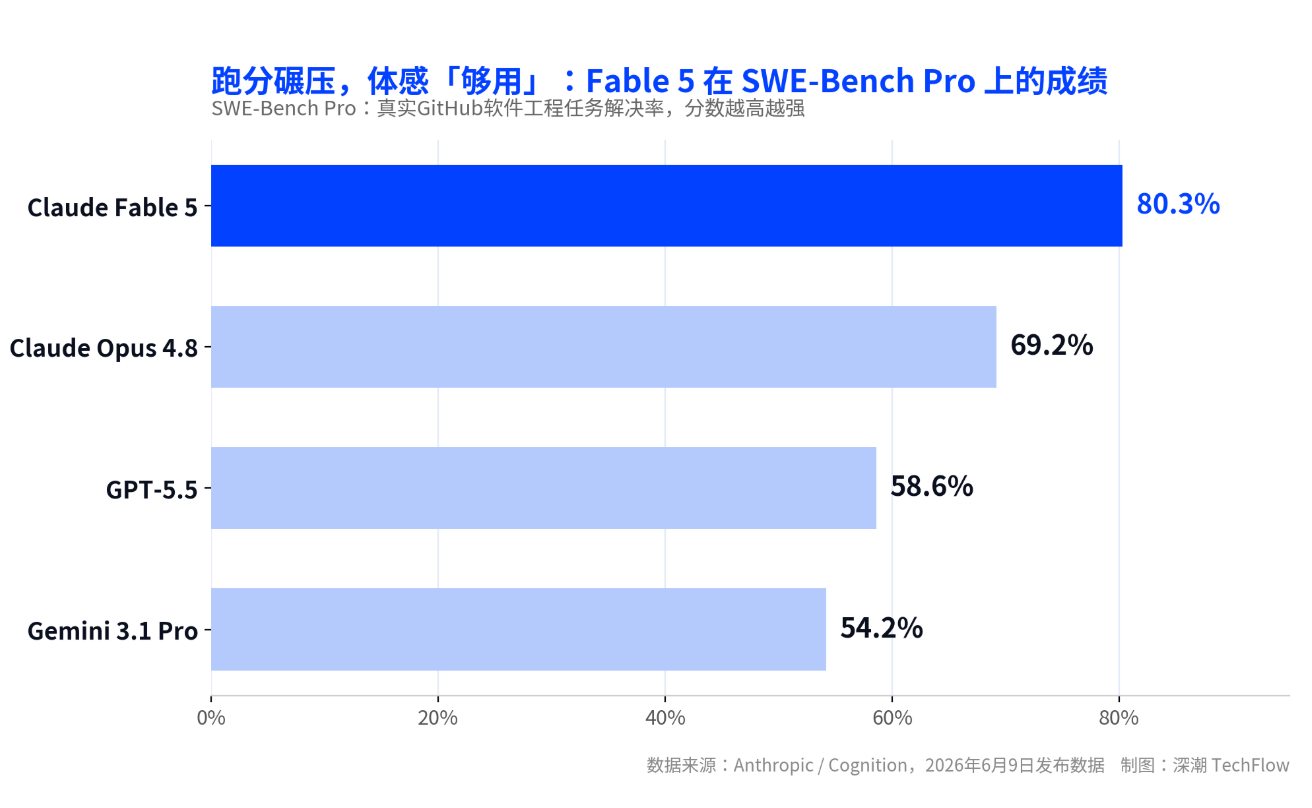
- Claude Fable 5는 SWE-Bench Pro 벤치마크에서 80.3%의 성적으로 GPT-5.5를 20% 포인트 이상 앞섰지만, API 가격(입력 토큰 100만 개당 10달러)은 이전 세대 Opus 4.8의 약 두 배에 달한다.
- 주류 사용자 정서는 '모델 피로감'으로, 현재의 플래그십 모델(예: Opus 4.8)이 일상 업무에 충분하다고 여기며 Fable의 성능 향상은 높은 토큰 비용과 낮은 투자 수익률을 가져온다고 본다.
- 안전 장치가 가장 큰 불만 사항이다. 사용자들은 보안 관련 요청(예: 코드 검토)의 최대 90%가 거절되거나 Opus로 다운그레이드되어 처리된다고 답했으며, 이는 유료 사용자의 사용자 경험에 심각한 영향을 미친다.
- 반대 의견은 Fable이 고난이도 작업(예: 고에너지 물리 시뮬레이션, 초장기 컨텍스트)에서 '밤과 낮'의 차이 같은 향상을 보여주며, 일상 모델이 아닌 '기획자이자 수정자'로서의 역할에 적합하다고 주장한다.
- 일부 논평은 '공개 AI 동결론'을 제기한다. 일반 사용자가 접근할 수 있는 모델은 정체될 가능성이 있는 반면, 기업이나 정부는 일반에 공개되지 않는 더 강력한 사유 모델(예: Mythos 5)을 보유하게 될 것이라고 본다.
Anthropic이 방금 서류상으로는 흠잡을 데 없는 성적표를 내놓았습니다.
6월 9일에 출시된 Claude Fable 5는 이 회사가 일반 대중에게 처음으로 공개한 Mythos급 모델로, 실제 소프트웨어 엔지니어링 작업 벤치마크 SWE-Bench Pro에서 80.3%를 기록하며, 자사의 이전 세대 플래그십 모델인 Opus 4.8보다 약 11% 포인트, GPT-5.5보다 20% 포인트 이상 앞섰습니다.
하지만 사용자들의 반응은 찬물을 끼얹었습니다.
출시 사흘 후, r/artificial 게시판(주간 방문자 수 30만 5천 명)의 한 인기 게시물 제목은 이렇게 쓰여 있었습니다: "Claude Fable 덕분에 깨달았어요. 더 나은 모델이 필요하지 않다는 걸." 작성자 Axi0m-22는 Fable로 한동안 보안 연구와 일상 업무를 처리하다가, 거의 바로 Opus로 코딩하고 Haiku로 잡일을 처리하는 방식으로 돌아갔다고 말했습니다. 그는 비유를 들었습니다: 마치 아이폰 14를 쓰면서 아이폰 17 출시를 지켜보는 것과 같다고요. "새로운 게 더 좋다는 건 알지만, 드는 생각은 '됐어, 지금 것도 괜찮아'라는 거예요."
좋아요 구역은 '충분파'가 점령: 모델 피로감이 주류 정서로
첫 번째 댓글은 42개의 좋아요를 받았습니다: "더 큰 컨텍스트 창만 빼면, Opus 4.5 이후로 더 강력한 모델이 필요하다고 느낀 적이 없어요."
또 다른 사용자 hyprlab의 발언은 13개의 좋아요를 받았습니다: "토큰을 더 많이 소모하는 모델로 바꾸는 게 제 작업 흐름에 무슨 이점이 될지 모르겠어요. Opus 4.8 고강도 모드로도 충분히 편안하거든요."
이런 발언들 뒤에는 공통된 비용 장부가 자리 잡고 있습니다.
Fable 5의 API 가격은 입력 토큰 100만 개당 10달러로, Opus 4.8의 거의 두 배입니다. 사용자 siromega37은 직설적으로 말했습니다: "토큰 소모는 더 많은데, 투자 수익률은 없어요. 우리가 정체기에 접어들고 있고, 거품은 결국 꺼질 것 같아요."
사용자 hobopwnzor는 더 체계적인 해석을 내놓았습니다: "우리는 이미 한동안 S자형 곡선의 정점에 머물러 있었어요. 최근의 발전은 주로 도구 호출 및 주변 엔지니어링에서 나온 것이지, 모델 자체의 능력에서 나온 게 아닙니다."
안전장치가 최대 불만 사항으로: "용도의 90%가 거절당해"
'충분하다'는 게 감정적인 반응에 불과하다면, 안전장치에 대한 불평은 구체적인 제품 문제입니다.
Anthropic의 공식 설명에 따르면, Fable 5는 소수의 기관에만 공개된 Mythos 5와 동일한 기본 모델을 공유하지만, 차이점은 Fable에 안전 분류기가 추가되었다는 점입니다. 사이버 보안 등 고위험 영역과 관련된 요청은 차단되고 Opus 4.8이 대신 응답합니다. 공식은 이 메커니즘이 다소 보수적으로 조정되어 평균적으로 세션의 5% 미만에서만 트리거되며, 무해한 요청을 오탐지할 수 있다고 밝혔습니다.
이 Reddit 게시물에서 사용자들이 체감하는 트리거율은 명백히 5%보다 훨씬 높았습니다. 17개의 좋아요를 받은 사용자 jradoff는 Fable에게 자신의 코드 보안을 검사해 달라고 했더니, "보안 관련된 것만 언급해도 기본적으로 모두 거부했다"며, 결국 Opus로 되돌아갔다고 말했습니다. 12개의 좋아요를 받은 다른 댓글은 더 강경했습니다: "모델을 사용하려는 목적의 90%가 거절당하니, 사실상 쓸모가 없어요."
유료 사용자들의 불만은 더 컸습니다. 월 200달러 요금제를 구독 중인 사용자 kaitava는 이렇게 적었습니다: "두 배의 사용 요금을 내면서 보안 검토 한 번 시켜보려니, Opus로 강등당했어요. 이제 모든 게 싫어졌어요. OpenAI가 따라잡기만을 기다리고 있어요."
능력의 도약을 내세운 플래그십 제품에게 '안전을 위해 치른 사용성 대가'는 사용자가 구매를 결정하는 핵심 변수가 되고 있습니다.
반대 의견: 고강도 작업 사용자들의 체감은 '낮과 밤'
인기 게시물 아래에 반대자가 없는 것은 아니며, 반대자들의 프로필은 상당히 명확합니다: 작업이 무거울수록 평가는 더 높았습니다.
사용자 Phylaras의 댓글은 15개의 좋아요를 받았습니다: "Fable은 저에게 실질적인 차이를 만들어줬어요. 방대한 컨텍스트 창이 필요한 복잡한 작업에서 이전에 발견하지 못했던 오류를 잡아냈거든요." 고에너지 물리학 시뮬레이션을 하고 있다는 한 사용자는 단일 시뮬레이션 모델이 수천에서 만 줄의 코드와 수백 개의 모델 상호작용을 수반한다며, "독립적으로 연속 작업하고 환경 세부 사항을 이해하는 모델은 저에게 너무나 기대되는 존재입니다."라고 말했습니다.
가장 격렬한 반박은 사용자 Navetz에게서 나왔습니다: "솔직히, 이 모델을 써본 사람은 이런 게시물이 말도 안 된다고 생각할 거예요. 제게는 완전히 다른 수준으로 똑똑해서 계속해서 사용하고 있어요. 비기술자인 친구에게 설명하자면, 대학생 선수에서 바로 NBA 선발로 바뀐 것과 같다고 했어요."
절충적인 사용법을 제시한 사람도 있었습니다. 사용자 ready-eddy는 돈 낭비를 신경 쓰지 않는다면 Fable을 일상적인 '건축자'가 아닌 '기획자이자 수리자'로 사용할 것을 권장했습니다. 또 다른 댓글은 사용 설명서처럼 요약했습니다: Fable로 표를 계산하는 것은 모델을 잘못 고른 것이고, Haiku로 16개 에이전트의 복잡한 작업을 실행하는 것 역시 모델을 잘못 고른 것입니다. "태생적으로 나쁜 모델은 없고, 잘못된 상황에 사용된 모델만 있을 뿐입니다."
벤치마크 점수와 체감 괴리 이후, 공개 AI는 더 강해질까?
이 논쟁에서 가장 흥미로웠던 댓글 하나가 주제를 제품에서 산업 구조로 이끌었습니다.
사용자 KedMcJenna는 '공개 AI 동결론'을 제기했습니다: 일반인이 접근할 수 있는 모델은 현재 수준 근처에 영원히 머물러 있을 가능성이 있는 반면, 기업과 정부 엘리트들은 계속해서 더 강력한 비공개 모델을 사용하게 될 것이라고요. "우리가 아는 것만 해도 Mythos가 있고, 아마 우리가 절대 듣지 못할 더 강력한 모델도 있을 겁니다."
이 댓글은 한 가지 사실을 지적합니다: Mythos 5는 실제로 일반에 공개되지 않으며, 현재 Project Glasswing 계획을 통해 사이버 방어 기관 및 핵심 인프라 기업에만 제공됩니다.
벤치마크 점수와 여론을 함께 놓고 보면, 결론은 모순되지 않습니다.
벤치마크 테스트는 능력의 상한선을 측정하는 반면, Reddit 좋아요 구역이 반영하는 것은 일상적인 요구의 천장입니다. 대부분 사용자의 작업이 Opus 4.6 시대에 이미 충족되었을 때, 더 강력한 모델은 물리 시뮬레이션이나 초장문 컨텍스트 같은 극단적인 시나리오에서만 스스로를 증명할 수 있습니다. 모델 제조사가 직면한 것은 더 이상 '해낼 수 있느냐 없느냐'의 문제가 아니라, '누가 필요로 하고, 얼마를 기꺼이 지불하며, 어느 정도의 안전 마찰을 용인할 수 있느냐'의 문제입니다.
출시 사흘 만에, Fable 5는 벤치마크 순위표와 여론장에서 완전히 다른 두 개의 성적표를 받았습니다. 어느 쪽이 진실에 더 가까운지는 Anthropic이 안전 분류기를 조정하는 속도와 고강도 사용자들의 지갑 투표에 달려 있습니다.


