
AI 대형 모델 중계소는 벤치마크 점수뿐만 아니라 감사도 필요하다: GatewayBench 평가 프레임워크 출시, 공식 웹사이트 Check4U.ai 동시 오픈
- 핵심 시각: AI 대형 모델 중계 API(Shadow API) 시장에는 모델 대체, 숨은 과금 및 허위 저가 등 불문율이 존재하여 연구 결과의 재현 가능성과 기업 비즈니스 안정성에 영향을 미친다. 감사 프레임워크 GatewayBench는 신뢰성, 경제성 및 성능의 세 가지 차원으로 평가하여 블랙박스를 드러내고 시장 투명성을 촉진하는 것을 목표로 한다.
- 핵심 요소:
- CISPA 헬름홀츠 정보 보안 센터의 감사 결과, 전 세계 최소 187편의 최우수 학회 논문이 중계 API를 사용하며, 이 중 62%는 기저 모델이 대체, 양자화 또는 다운그레이드되어 연구 결과 재현 불가능 위험에 직면해 있다.
- 불문율 1: 모델 동적 오염. 높은 동시 접속 시 중계 게이트웨이는 원본 모델을 양자화 버전, 증류 버전 또는 저비용 오픈소스 모델로 몰래 대체하여 출력 품질을 불안정하게 만들 수 있다.
- 불문율 2: 숨은 과금 및 프라이버시 위험. 추론 모델의 'thinking tokens' 소비 허위 보고, 캐시 할인 미적용, 그리고 계정 간 공유 캐시 풀로 인한 기업 데이터 격리 실패 등을 포함한다.
- 불문율 3: 허위 '전국 최저가'. 혼합 단가는 실제 비용을 은폐하며, 높은 입력 시나리오(RAG 등)의 청구서는 예상보다 훨씬 높을 수 있고, 실패한 요청에 대한 과금, 충전 기준 등 숨은 마찰이 실제 지출을 증가시킨다.
- GatewayBench 감사 프레임워크: 가중치 체계는 40% 신뢰성 + 40% 경제성 + 20% 성능이며, 핵심 감사에는 RUT 알고리즘을 통한 모델 진위성 탐지, PALACE를 통한 합리적 토큰 범위 추정, SLO 지표를 통한 안정적인 전달 능력 평가가 포함된다.
- 경제성 차원에서는 'True Cost per 1M Tokens' 개념을 도입하여 입력/출력/캐시 가격을 분해하고 공식 가격과 비교하며, 실패한 요청 과금, 캐시 할인 환불 등 숨은 비용을 식별한다.
- 플랫폼 Check4U.ai는 현재 개방형 평가 순위를 제공하며, 통일되고 오픈소스인 프레임워크를 통해 정직하게 서비스를 제공하는 우수 사업체가 시장 인정을 받고 업계가 검증 가능하고 책임질 수 있는 방향으로 전환되도록 촉진하는 것을 목표로 한다.
企业每月耗费巨资调用的 GPT-5 或 Claude,真的是官方原版模型吗?
为了应对AI大模型复杂的地缘限制、企业合规流程以及支付门槛,越来越多的研发团队选择了一条捷径:第三方AI中转市场(Shadow API)。这种替代方案看起来极其诱人,让开发者能够以更低的接入门槛使用 GPT、Claude 等主流模型,体验上接近官方 API,也在一定程度上填补了官方渠道无法覆盖的空白。
然而,这扇看似便捷的「大门」,背后却是一个深不见底的黑箱。
2026 年 3 月,德国 CISPA 亥姆霍兹信息安全中心发布的一项审计数据揭开了一个令人脊背发凉的真相:全球至少有 187 篇顶尖学术论文使用了AI大模型中转API( Shadow API)进行研究(其中 62% 已被 CVPR、ICLR 等顶级学术会议接收),但因为这些中转网关在暗中对底层模型进行了替换、量化或降级,导致大量研究结果面临不可复现的风险。
而学术界的「灾难」,在企业的生产环境里就是随时可能爆发的「定时炸弹」。
今天的大模型早已不再是实验室里的测试品,这些核心基础设施正在被深度接入客服中心、代码生成流水线、Agent 工作流以及风控业务链条中。面对支撑关键业务的系统,中转服务商通常会向企业抛出「原版模型」、「低价」、「高速」和「支持缓存」等卖点。
但问题在于,传统的评测工具根本查不出黑箱里的猫腻。现有的跑分软件主要关注接口外侧的速度和价格,这类工具默认了一个前提,认为网关返回的数据全是真实可信的。常规评测根本无法回答以下核心的业务安全问题:
● 当业务遭遇流量高峰时,高价购买的模型有没有被悄悄「调包」或「降级」?
● 在所谓的高速和低价背后,账单里有没有被偷偷塞进虚报的 Token、失败的请求有没有被强行扣费?
● 网关宣称的缓存折扣,到底有没有真实返还给企业,跨账号的隐私数据又有没有被严格隔离?
AI中转API 确实解决了大模型访问的门槛问题,但也制造了新的信任危机。在弄清楚这些不可见的后端路径之前,仅凭表面单价和速度做出的采购决策,无异于蒙眼狂奔。打破黑箱时代,让诚实交付重新成为市场优势,正是当下 AI 供应链亟待解决的头等大事。
揭开黑箱:AI 大模型中转市场的「三大潜规则」
为什么现有的常规跑分软件查不出问题?因为传统的评测工具仅仅停留在接口外侧,一味比拼响应速度和表面标价。而在极度不透明的网关后端,厂商正在利用这种信息不对称,将复杂的技术手段转化为隐蔽的套利工具。
深入剖析当前的AI大模型中转市场,有三大极具隐蔽性的「潜规则」正在蚕食企业的业务质量与预算:
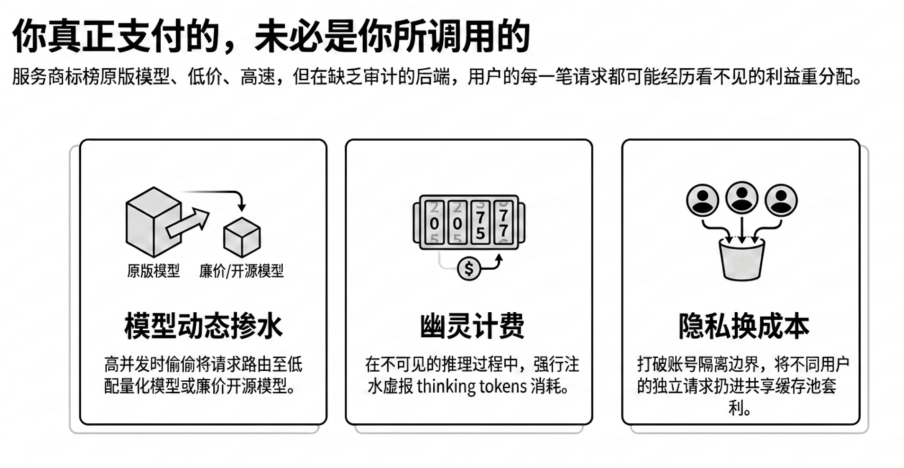
潜规则一:模型动态掺水
在灰色中转市场中,最难被察觉的套利手段就是模型的动态替换。
很多服务商在面对常规评测工具或者系统低流量时,会规规矩矩地调用官方原版模型。然而,一旦遭遇高并发业务高峰,或者处于监控难以覆盖的盲区,这些网关就会悄悄将后端切换为低配的量化模型、能力较弱的蒸馏版本,甚至是成本极低的同名开源模型。
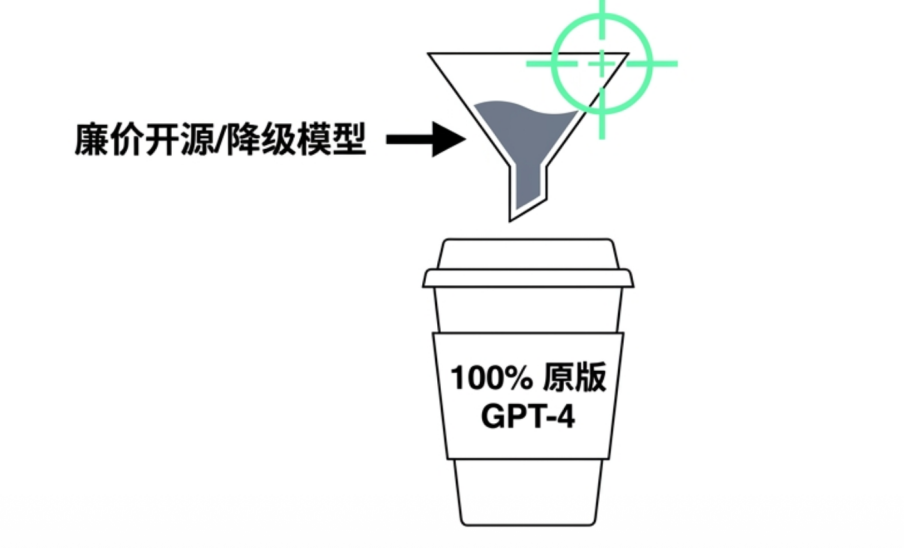
虽然从表面上看,接口依然在按时吐出文字,但由于底层的概率分布已被篡改,企业实际获取的输出质量与厂商最初承诺的指标早已货不对板。这种将模型调包的行为,让企业的客服回复准确率和代码生成质量随时面临不可控的降级风险。
潜规则二:看不见的账单(隐性计费与隐私裸奔)
推理模型(Reasoning)普及后,大模型账单里开始出现一块更难核验的成本:thinking tokens。由于这部分思考过程默认不可见,采购方很难判断平台申报的推理消耗是否真实,也给不良网关留下了虚报成本的空间。
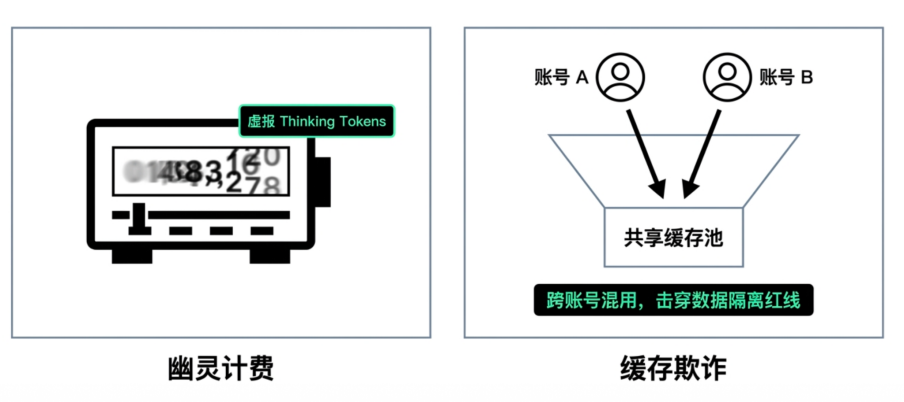
比虚报账单更可怕的,是失控的缓存欺诈。部分服务商虽然在账单上展示了命中缓存的标志,却并未将真正的折扣返还给企业,缓存优化沦为纯粹的账面数字游戏。更有甚者,为了强行提高缓存命中率以压缩自身成本,某些网关会将不同企业的 prompt(提示词)强行塞进同一个共享缓存池中。这会直接冲击多租户系统的数据隔离边界,让企业核心业务数据和商业隐私暴露在跨账号混用风险之下。
潜规则三:虚假的「全网最低价」(精心设计的财务陷阱)
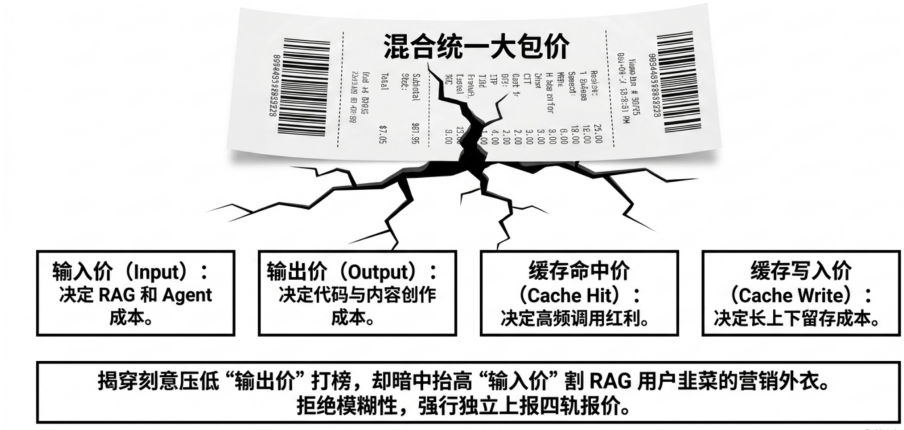
在采购大模型 API 时,「全网最低价」往往最容易吸引注意。但在实际业务中,名义单价并不等于真实成本。尤其是在中转网关市场里,输入、输出、缓存命中和缓存写入经常被打包成一个综合价格,看起来方便比较,但一旦进入真实业务负载,它就很容易失真。
这种失真来自一个事实,即企业调用大模型时,并不存在固定的输入输出比例。RAG、长文档分析和复杂 Agent 工作流通常是高输入、低输出;代码生成和内容创作则可能是低输入、高输出。如果平台只展示一个混合单价,采购方很难判断成本到底发生在哪里。一个价格看起来很低的平台,可能通过压低输出单价优化对外报价,同时抬高输入、缓存写入或其他更不显眼的价格项。最终,某些高输入场景的真实账单可能远高于预期。
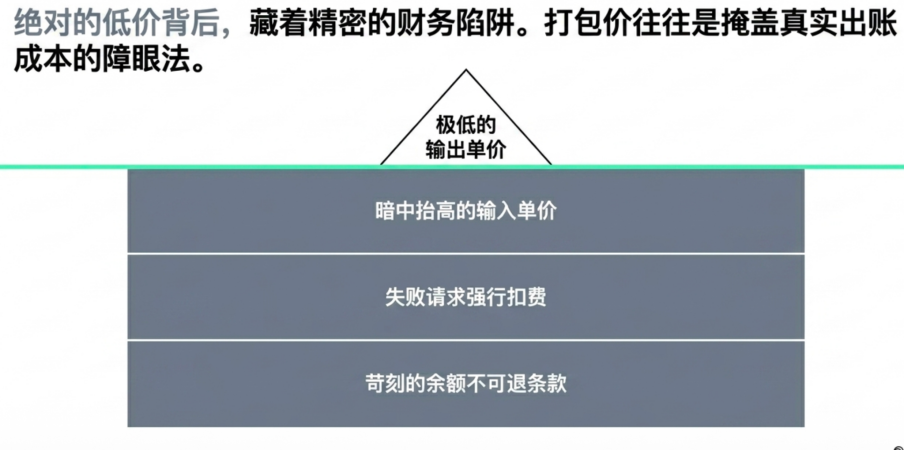
此外,隐性成本还藏在各种不起眼的条款中。比如,在系统出现断流、超时或 5xx 错误时,失败的请求依然会被强行扣费;低廉的单价往往捆绑着高额的充值门槛、余额不可退的霸王条款,以及不透明的外汇与支付通道手续费。当所有的财务摩擦叠加在一起时,每百万 Tokens 真正落到企业账本上的出账成本,往往比网页上宣传的名义价格高出数倍。
GatewayBench:面向大模型网关的专业审计框架
面对高度不透明的网关后端,传统测速和跑分工具存在明显的局限性。这些指标可以比较响应速度、模型覆盖率和名义价格,却很难回答更加关键的问题:网关实际调用的模型是否与承诺一致,账单是否透明,缓存和数据隔离是否可信。
在这一背景下, GatewayBench 审计评测框架正式上线,并通过官网 Check4U.ai 开放评测入口。作为开源的大模型网关审计框架,GatewayBench 不只看速度和表面价格,而是将网关评测拆解为三个维度:可信度、经济性和性能,并采用 40% 可信度 + 40% 经济性 + 20% 性能 的权重体系。
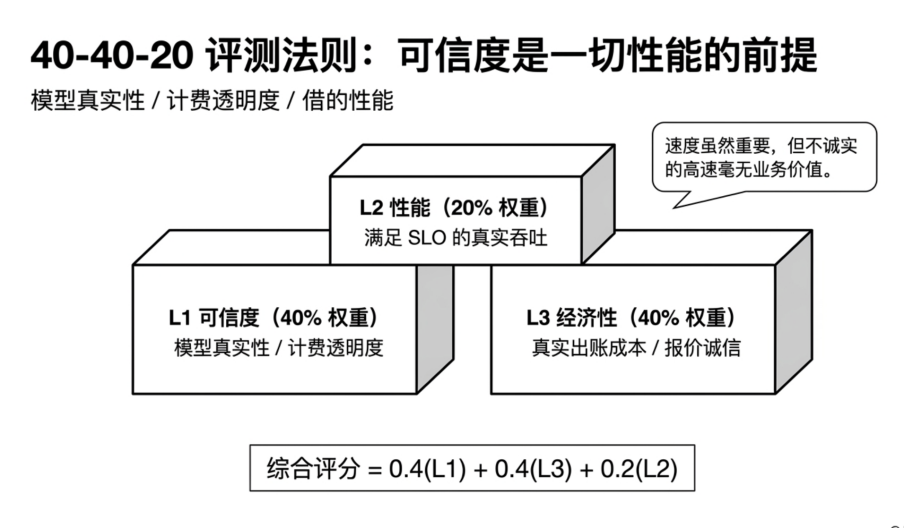
这套权重反映了 GatewayBench 的基本判断:在AI大模型中转API场景下,可信度和真实成本优先于速度。一个网关必须先证明模型真实、账单透明、成本可解释,才有资格进入性能竞争。
围绕这一目标,GatewayBench 提供了三项核心审计能力:
L1 可信度审计:从平台自述到可验证信任
在 GatewayBench 的评分体系里,L1 可信度占 40% 的权重。这一设计背后的逻辑是:在 AI大模型中转API场景下,速度和价格固然重要,但如果模型不真实、账单不透明,其他指标就失去了讨论基础。
第三方大模型中转网关的核心风险,来自成功调用背后的不可见过程。接口层面的正常返回,只能说明请求被处理完成,却无法证明模型来源、计费过程和缓存处理都符合平台承诺。过去,这些环节缺少外部可验证证据,也很难进入系统化审计。
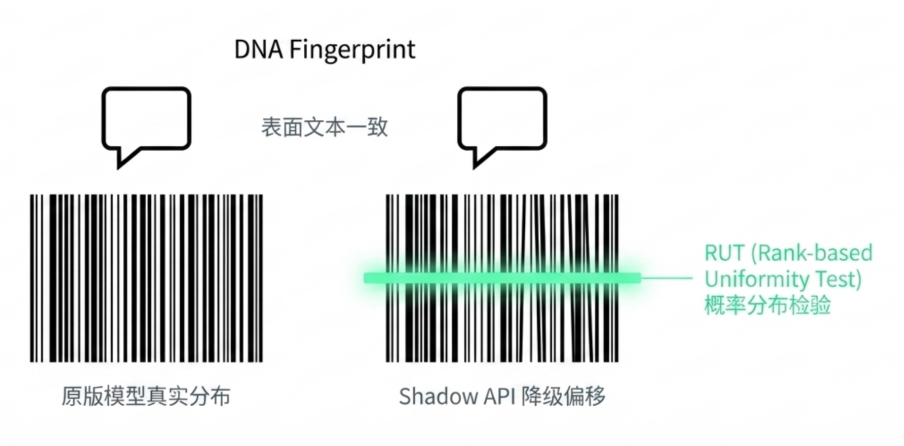
GatewayBench 的 L1 维度,正是为了把这些模糊怀疑转化为可以复查的工程信号。通过将可信度拆成三个问题:模型是否真实、计费是否透明、缓存是否可信,并通过统计检验、密码学结构和延迟指纹,从外部观察网关黑箱里到底发生了什么。
在模型真实性上,GatewayBench 引入 RUT(Rank-based Uniformity Test)算法,检查输出 token 在参考模型概率排序中的位置。不同模型可能生成相似文本,但 token 概率分布更难伪装。如果后端发生量化、降级或替代,分布漂移会留下痕迹。与此同时,GatewayBench 也可以结合 Logprob Tracking,在固定 prompt 下只请求一个输出 token,并追踪其 log probability 是否在不同时段出现稳定偏移。这为持续监测模型更新、微调、量化调整或路由切换提供了一种更低成本的信号。
在计费透明度上,GatewayBench 通过 PALACE 估算合理的 thinking tokens 区间,用来识别推理模型中的异常高报;同时借助 CoIn 这类可验证结构,让计费记录具备更强的可追溯性和抗篡改能力。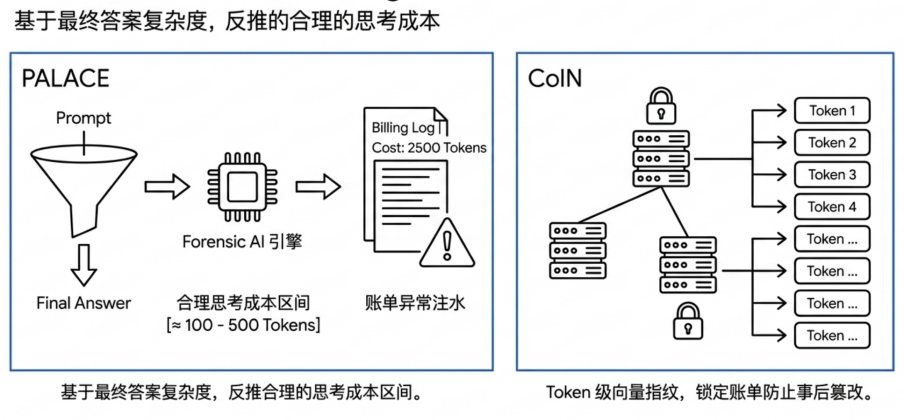
缓存可信度上,GatewayBench 通过延迟指纹判断缓存命中是否真实,通过跨账号隔离测试识别潜在的租户边界问题。如果账单显示命中缓存,但 TTFT 没有对应下降,折扣可能只停留在账面;如果两个独立账号之间出现异常缓存复用,则可能意味着缓存隔离存在风险。
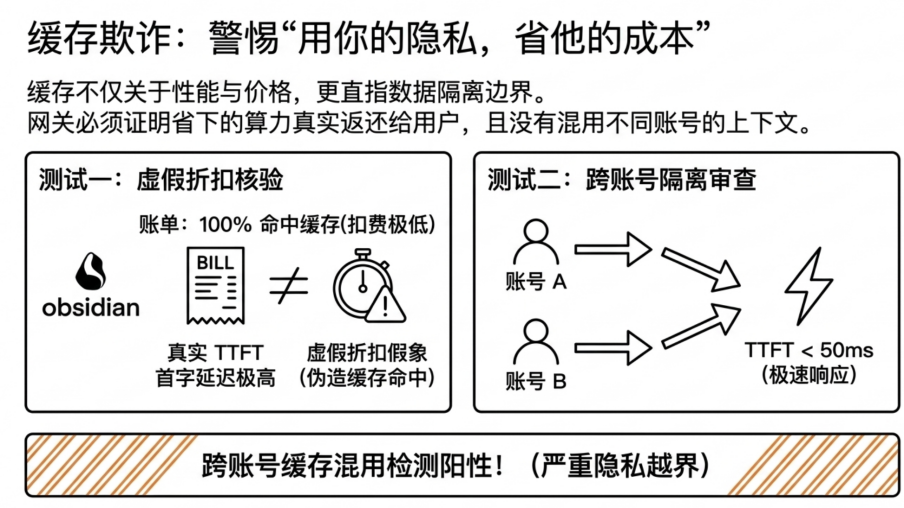
通过以上这些手段,GatewayBench 将原本只能靠直觉和怀疑判断的黑箱,转化为了一组组可测量、可复查、可比较的信号,实现了真正「可验证的信任」。
L2 性能:极限负载测试,探测极端压力下的稳定交付能力
只有通过 L1 可信度审计的网关,才有资格进入性能与性价比的比较。
在大模型基础设施生态中,性能一直是中转站和聚合 API 厂商最愿意强调的指标。「全网最快」、「单并发 150 tokens/s」这类表述并不少见。但 GatewayBench 在设计指标体系时,对性能保持了相当克制的权重分配:L2 性能只占综合评分的 20%。
原因很简单。速度当然重要,它决定了系统是否具备基本可用性,也能淘汰掉频繁卡顿、长尾失控的服务。但速度不应该超过可信度和经济性。一个网关即使跑得很快,只要存在模型替换、账单注水或缓存不透明,就无法成为可信的企业级基础设施。
因此,GatewayBench 在L2 性能维度上,并不追逐单点峰值,而是把性能拆成更贴近生产环境的问题:延迟决定用户等多久,Goodput 衡量在延迟红线内还能交付多少有效产能,长上下文测试则观察系统在重负载下如何退化。
这套设计背后的前提是:性能是门槛,但绝非终点。企业真正购买的是在可信前提下稳定、按时、可预期的交付能力。
在商业级应用中,系统空载时的峰值速度参考价值极其有限。GatewayBench 拒绝单纯比拼吞吐量(Tokens/s),而是引入SLO (服务等级目标)作为业务红线。企业可以规定,例如 P95 TTFA 必须小于 1.5 秒,P95 E2E 必须小于 8 秒,流式输出不能出现明显抖动。Goodput 就建立在这条红线之上:只有在满足 SLO 的前提下交付的吞吐,才算有效产能(Goodput)。
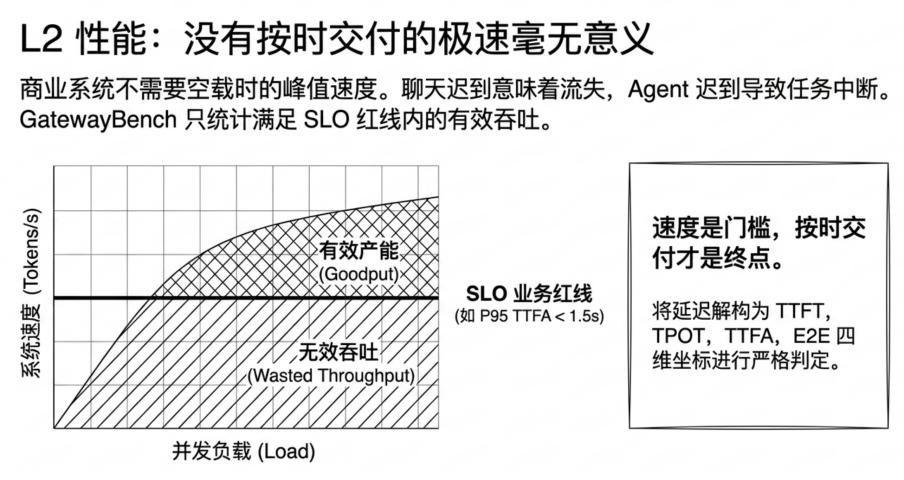
为了测试中转网关的真实调度水平,GatewayBench 会抛出 100k 级别的超长上下文压力测试。这种测试旨在观察系统在重负载下是保持稳定的平稳退化,还是出现长尾失控甚至隐性降级。企业花钱购买的,正是这种在极端业务压力下,依然能够按时交卷的稳定交付能力。
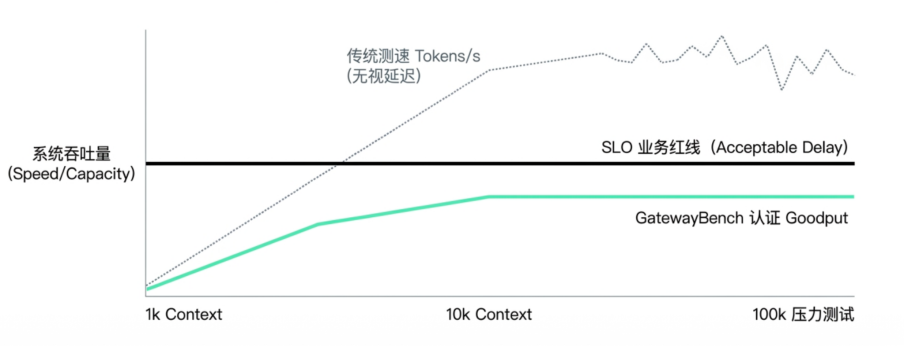
L3 经济性:穿透账单迷雾,还原「每百万 Tokens 的真实出账成本」
价格是企业采购大模型中转 API 时最敏感的变量,也最容易被重新包装。网页上的单价看起来清晰,但真正进入生产调用后,成本会受到输入输出比例、缓存规则、失败请求、充值条款、汇率和支付通道影响。
因此,GatewayBench 将 L3 经济性赋予 40% 权重,与 L1 可信度并列为核心维度,这里关注的并非价格表上的名义单价,而是 True Cost per 1M Tokens,即企业在真实业务负载下最终支付的成本。
在明面定价上,GatewayBench 拆开输入价、输出价、缓存命中价和缓存写入价,避免单一混合价掩盖成本结构。不同业务场景的输入输出比例差异很大,RAG、长文档分析和 Agent 工作流通常高输入、低输出;代码生成和内容创作则可能带来更高输出成本。只看一个综合价格,很容易误判真实支出。
在相对官方价上,GatewayBench 引入「平台价 / 官方价」的价格比,并结合网关角色判断溢价是否合理。聚合路由、多通道容灾和统一账单可以解释一定服务溢价;简单转发型代理则应更接近官方价格。低价不必然代表优势,高价也需要对应真实工程价值。
GatewayBench 框架还会深入挖掘账单背后的隐性摩擦:失败请求是否被强行扣费、宣称的缓存折扣有没有真实返还、资金账户是否存在苛刻的消耗限制。通过层层拆解,GatewayBench 最终为企业还原出剥离所有营销包装后的真实出账成本。
加入 GatewayBench:让诚实交付获得市场回报
API 中转市场不会因为争议而消失。只要模型访问仍然存在地区、支付、风控和合规差异,第三方网关就会继续承接真实需求。既然这是一个无法回避的现实。GatewayBench要做的是如何让这个中转站变得更透明、更可信、更可持续。
当前 API 中转市场最大的矛盾,是信息不对称正在放大「劣币驱逐良币」的效应。部分服务商可以通过模型调包、计费包装、缓存套利或低价营销获得短期流量;而坚持原厂透传、透明计费和稳定服务的厂商,因为无法突破真实成本约束,反而更难在嘈杂市场中被看见。
这不是一个基础设施市场可以长期依赖的结构。任何成熟的供应链,都需要一套基于指标的市场化信任机制:好的服务应该被看见,稳定履约应该被记录,诚实交付也应该获得更多的流量、更多的信任和更高质量的采购预算;而长期依赖信息不对称获利的服务商,应该承担更高的信任成本。
基于重塑行业信任共识的愿景,AI 大模型中转站评测平台 Check4U.ai 宣布正式上线,并面向全球各大 API 中转站、聚合路由平台及模型服务商发出开放邀约:加入 GatewayBench 公开评测榜单。
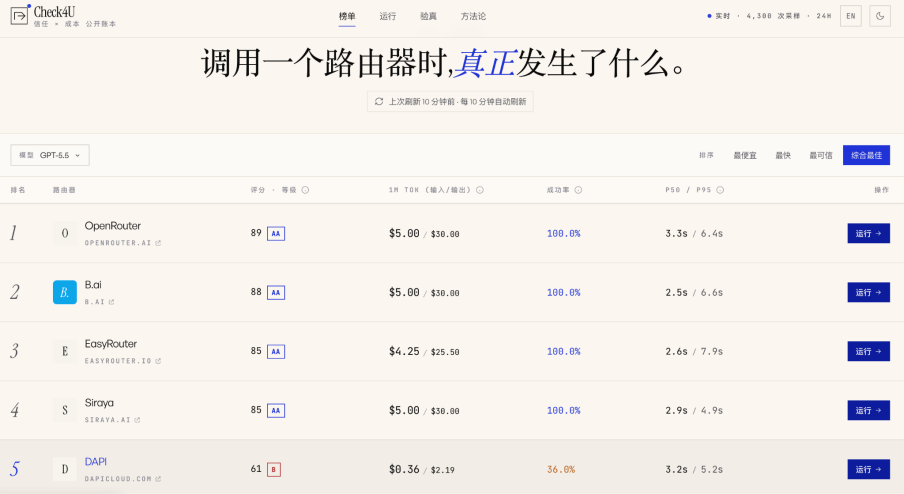
GatewayBench 希望通过统一、开源、可复跑、可比较的审计框架,把网关交付质量转化为可观察指标,让市场不再只依赖宣传语和模糊价格表判断服务。对优质服务商来说,这是一次用数据自证技术诚信的机会:证明自己真实交付了什么、如何计费、以及能否稳定的服务。对企业采购方来说,GatewayBench 也可以成为接入外部 API 前的重要参考,帮助识别真实成本、模型纯度、缓存隔离和履约记录。
一个健康的大模型网关市场,不应该让真正做好服务的网关被低价营销掩盖。GatewayBench 致力于成为这套信用基础设施的一部分,让诚实交付获得市场回报,让透明竞争利好最终用户,也推动整个行业走向更可验证、更可问责的AI基础设施市场。


