
YBB 캐피털: 잠재적 경로 미리보기 - 분산형 컴퓨팅 파워 시장(1부)
원작자: Zeke, YBB Capital

머리말
GPT-3 탄생 이후 생성 AI는 놀라운 성능과 폭넓은 적용 시나리오로 인공지능 분야에 폭발적인 전환점을 가져왔고, AI 트랙에 뛰어들기 위해 거대 기술 기업들이 한자리에 모이기 시작했다. 그러나 문제도 발생합니다. LLM(대형 언어 모델)의 학습 및 추론에는 많은 양의 컴퓨팅 성능이 필요하며, 모델을 반복적으로 업그레이드하면 컴퓨팅 성능 요구 사항과 비용이 기하급수적으로 증가합니다. GPT-2와 GPT-3를 예로 들면, GPT-2와 GPT-3의 매개변수 양 차이는 1166배입니다(GPT-2는 1억 5천만 개의 매개변수이고 GPT-3은 1750억 개의 매개변수). GPT-3 당시 공개 GPU 클라우드의 가격 모델을 기준으로 비용을 계산했는데, 최대 1200만 달러로 GPT-2의 200배에 달했다. 실제 사용 시 모든 사용자 질문에는 추론 계산이 필요하며, 올해 초 순 사용자 방문 수 1,300만 명을 기준으로 해당 칩 수요는 A 100 GPU 30,000개 이상입니다. 그러면 초기 투자 비용은 8억 달러에 이르며 일일 모델 추론 비용은 700,000달러로 추정됩니다.
부족한 컴퓨팅 성능과 높은 비용은 AI 산업 전체가 직면한 문제가 되었지만, 블록체인 산업에서도 같은 문제가 나타나고 있는 것 같습니다. 한편으로는 비트코인의 4차 반감기와 ETF 도입이 임박했고, 앞으로 가격이 상승하면서 채굴자들의 컴퓨팅 하드웨어 수요도 크게 늘어날 수밖에 없다. 반면에 영지식 증명("Zero-Knowledge Proof", 줄여서 ZKP) 기술이 호황을 누리고 있으며 Vitalik은 향후 10년 동안 ZK가 블록체인 분야에 미치는 영향이 블록체인 자체만큼 중요할 것이라고 반복해서 강조했습니다. 블록체인 업계에서는 이 기술의 미래에 대한 기대가 크지만, ZK 역시 AI와 마찬가지로 복잡한 계산 과정으로 인해 증명 생성에 많은 컴퓨팅 파워와 시간을 소모합니다.
가까운 미래에는 컴퓨팅 파워 부족이 불가피할 텐데, 분산형 컴퓨팅 파워 시장이 좋은 사업이 될까요?
분산형 컴퓨팅 파워 시장 정의
분산형 컴퓨팅 파워 시장은 실제로 기본적으로 분산형 클라우드 컴퓨팅 트랙과 동일하지만 분산형 클라우드 컴퓨팅과 비교하면 개인적으로 이 용어가 나중에 논의되는 새로운 프로젝트를 설명하는 데 더 적합하다고 생각합니다. 분산형 컴퓨팅 파워 시장은 DePIN(Decentralized Physical Infrastructure Network)의 하위 집합에 속해야 하며, 그 목표는 개방형 컴퓨팅 파워 시장을 창출하는 것이며, 토큰 인센티브를 통해 유휴 컴퓨팅 파워 자원을 가진 누구나 자신의 자원을 이 시장에서 제공할 수 있습니다. 주로 B-end 사용자와 개발자 그룹에 서비스를 제공합니다. 분산형 GPU 기반 렌더링 솔루션 네트워크인 Render Network와 클라우드 컴퓨팅을 위한 분산형 P2P 시장인 Akash Network와 같은 보다 친숙한 프로젝트의 관점에서 보면 둘 다 이 트랙에 속합니다.
다음은 기본 개념부터 시작한 다음 이 트랙에서 세 가지 신흥 시장인 AGI 컴퓨팅 파워 시장, 비트코인 컴퓨팅 파워 시장, ZK 하드웨어 가속 시장의 AGI 컴퓨팅 파워 시장에 대해 논의할 것입니다. 잠재적 트랙 미리보기: 분산 컴퓨팅 파워 시장(2부)에서 논의됩니다.
컴퓨팅 성능 개요
컴퓨팅 파워(Computing Power) 개념의 유래는 컴퓨터 발명 초기로 거슬러 올라갈 수 있는데, 원래의 컴퓨터는 컴퓨팅 작업을 수행하기 위해 기계적인 장치를 사용했으며, 컴퓨팅 파워(Computing Power)는 기계 장치의 컴퓨팅 파워를 의미한다. 컴퓨터 기술의 발전과 함께 컴퓨팅 파워의 개념도 진화해 왔으며, 오늘날의 컴퓨팅 파워는 일반적으로 컴퓨터 하드웨어(CPU, GPU, FPGA 등)와 소프트웨어(운영체제, 컴파일러, 응용 프로그램 등)의 협업을 의미합니다. .) 능력.
정의
컴퓨팅 파워는 컴퓨터나 다른 컴퓨팅 장치가 처리할 수 있는 데이터의 양 또는 일정 기간 내에 완료되는 컴퓨팅 작업의 수를 의미합니다. 컴퓨팅 성능은 일반적으로 컴퓨터나 기타 컴퓨팅 장치의 성능을 설명하는 데 사용되며, 컴퓨팅 장치의 처리 능력을 나타내는 중요한 지표입니다.
측정항목
컴퓨팅 파워는 컴퓨팅 속도, 컴퓨팅 에너지 소비, 컴퓨팅 정확도, 병렬성 등 다양한 방식으로 측정할 수 있습니다. 컴퓨터 분야에서 일반적으로 사용되는 컴퓨팅 파워 메트릭에는 FLOPS(초당 부동 소수점 연산), IPS(초당 명령), TPS(초당 트랜잭션) 등이 포함됩니다.
FLOPS(초당 부동 소수점 연산)는 부동 소수점 연산(정밀도 문제 및 반올림 오류를 고려해야 하는 소수점이 있는 숫자에 대한 수학 연산)을 처리하는 컴퓨터의 능력을 말하며 컴퓨터가 초당 완료할 수 있는 양을 측정합니다. 부동 소수점 연산. FLOPS는 컴퓨터의 고성능 컴퓨팅 능력을 측정하는 단위로 일반적으로 슈퍼컴퓨터, 고성능 컴퓨팅 서버, 그래픽 처리 장치(GPU) 등의 컴퓨팅 능력을 측정하는 데 사용됩니다. 예를 들어, 컴퓨터 시스템의 FLOPS는 1 TFLOPS(초당 1조 부동 소수점 연산)입니다. 이는 초당 1조 부동 소수점 연산을 완료할 수 있음을 의미합니다.
IPS(Instructions Per Second)는 컴퓨터가 명령을 처리하는 속도를 말하며, 컴퓨터가 초당 실행할 수 있는 명령의 수를 나타냅니다. IPS는 컴퓨터의 단일 명령 성능을 나타내는 척도로, 주로 중앙처리장치(CPU) 등의 성능을 측정하는 데 사용된다. 예를 들어, 3GHz(초당 3억 명령)의 IPS를 갖춘 CPU는 초당 3억 명령을 실행할 수 있다는 의미입니다.
TPS(초당 트랜잭션)는 컴퓨터의 트랜잭션 처리 능력을 나타내며, 컴퓨터가 초당 완료할 수 있는 트랜잭션 수를 측정합니다. 일반적으로 데이터베이스 서버 성능을 측정하는 데 사용됩니다. 예를 들어, 데이터베이스 서버의 TPS는 1000입니다. 이는 초당 1000개의 데이터베이스 트랜잭션을 처리할 수 있음을 의미합니다.
또한 추론 속도, 이미지 처리 속도, 음성 인식 정확도 등 특정 애플리케이션 시나리오에 대한 일부 컴퓨팅 성능 지표가 있습니다.
컴퓨팅 성능 유형
GPU 컴퓨팅 파워는 그래픽 프로세서(그래픽 처리 장치)의 컴퓨팅 파워를 의미합니다. GPU는 CPU(중앙처리장치)와 달리 이미지, 동영상 등의 그래픽 데이터를 처리하기 위해 특별히 설계된 하드웨어로, 다수의 처리장치와 효율적인 병렬컴퓨팅 능력을 갖추고 있으며 다수의 부동소수점 연산을 동시에 수행할 수 있다. . GPU는 원래 게임 그래픽 처리용으로 설계되었기 때문에 일반적으로 복잡한 그래픽 작업을 지원하기 위해 CPU보다 더 높은 클럭 주파수와 더 큰 메모리 대역폭을 갖습니다.
CPU와 GPU의 차이점
아키텍처: CPU와 GPU는 컴퓨팅 아키텍처가 다릅니다. CPU는 일반적으로 하나 이상의 코어를 사용하며, 각 코어는 다양한 작업을 수행할 수 있는 범용 프로세서입니다. GPU에는 이미지 처리와 관련된 작업을 수행하는 데 특별히 사용되는 수많은 스트림 프로세서 및 셰이더가 있습니다.
병렬 컴퓨팅: GPU는 일반적으로 더 높은 병렬 컴퓨팅 기능을 갖추고 있습니다. CPU에는 제한된 수의 코어가 있고 각 코어는 하나의 명령만 실행할 수 있지만 GPU에는 여러 명령과 작업을 동시에 실행할 수 있는 수천 개의 스트림 프로세서가 있을 수 있습니다. 따라서 GPU는 일반적으로 대량의 병렬 컴퓨팅이 필요한 기계 학습 및 딥 러닝과 같은 병렬 컴퓨팅 작업을 수행하는 데 CPU보다 더 적합합니다.
프로그래밍: GPU 프로그래밍은 CPU보다 더 복잡하므로 특정 프로그래밍 언어(예: CUDA 또는 OpenCL)를 사용해야 하고 GPU의 병렬 컴퓨팅 기능을 활용하려면 특정 프로그래밍 기술을 사용해야 합니다. 이에 비해 CPU 프로그래밍은 더 간단하고 범용 프로그래밍 언어와 프로그래밍 도구를 사용할 수 있다.
컴퓨팅 파워의 중요성
산업혁명 시대, 석유는 세계의 피였으며 모든 산업에 침투했습니다. 컴퓨팅 파워는 블록체인에 있으며, 다가오는 AI 시대에는 컴퓨팅 파워가 세계의 디지털 오일이 될 것입니다. 대기업들의 AI 칩 필사적 횡령과 1조가 넘는 엔비디아의 주식, 최근 미국이 중국산 고급 칩을 봉쇄한 것까지, 세부 사항에는 컴퓨팅 파워, 칩 면적, 심지어 GPU 클라우드 금지 계획까지 포함된다. 중요성은 자명합니다. , 컴퓨팅 성능은 다음 시대에는 필수품이 될 것입니다.

인공일반지능 개요
인공지능(Artificial Intelligence)은 인간 지능을 시뮬레이션, 확장, 확장하기 위한 이론, 방법, 기술 및 응용 시스템을 연구하고 개발하는 새로운 기술 과학입니다. 1950년대와 1960년대에 시작되어 반세기가 넘는 진화를 거쳐 상징주의, 연결주의, 행동주체라는 세 가지 물결이 얽혀 발전해 왔으며 이제는 신흥 종합기술로서 사회를 촉진하고 있습니다. 삶과 각계각층. 이 단계에서 일반적인 생성 AI에 대한 보다 구체적인 정의는 다음과 같습니다: 다양한 작업과 분야에서 잘 수행할 수 있는 광범위한 이해 기능을 갖춘 인공 지능 시스템인 일반 인공 지능(AGI)입니다. . AGI에는 기본적으로 딥러닝(DL), 빅데이터, 대규모 컴퓨팅 파워라는 세 가지 요소가 필요합니다.
딥러닝
딥러닝은 머신러닝(ML)의 하위 분야이며, 딥러닝 알고리즘은 인간의 두뇌를 모델로 한 신경망입니다. 예를 들어, 인간의 뇌에는 정보를 학습하고 처리하기 위해 함께 작동하는 수백만 개의 상호 연결된 뉴런이 포함되어 있습니다. 마찬가지로, 딥러닝 신경망(또는 인공 신경망)은 컴퓨터 내부에서 함께 작동하는 여러 층의 인공 뉴런으로 구성됩니다. 인공 뉴런은 수학적 계산을 사용하여 데이터를 처리하는 노드라는 소프트웨어 모듈입니다. 인공 신경망은 이러한 노드를 사용하여 복잡한 문제를 해결하는 딥 러닝 알고리즘입니다.
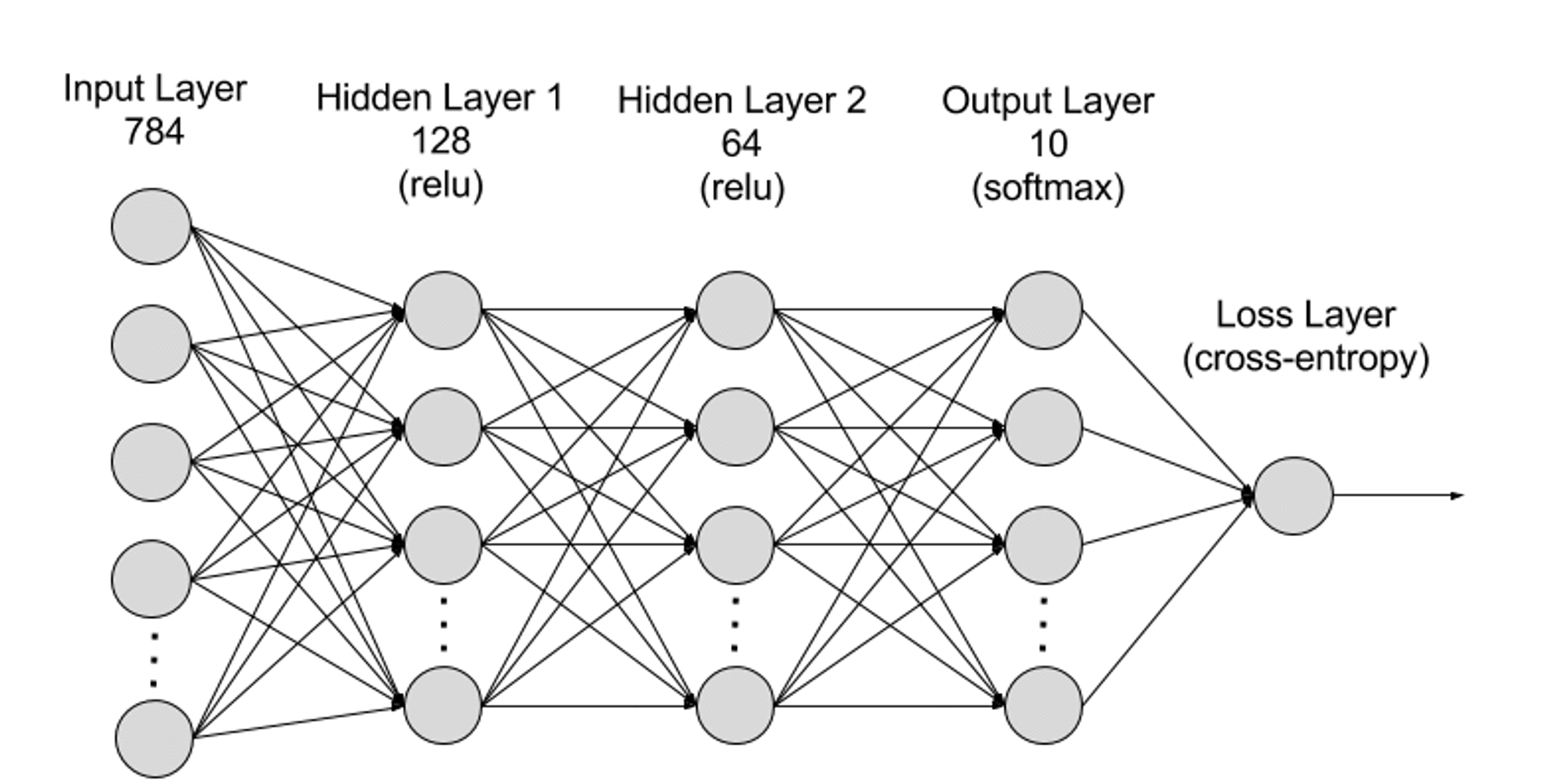
신경망은 계층적 수준에서 입력 레이어, 은닉 레이어, 출력 레이어로 나눌 수 있으며 매개변수는 서로 다른 레이어 간에 연결됩니다.
입력 계층: 입력 계층은 신경망의 첫 번째 계층으로 외부 입력 데이터를 수신하는 역할을 합니다. 입력 레이어의 각 뉴런은 입력 데이터의 특징에 해당합니다. 예를 들어, 이미지 데이터를 처리할 때 각 뉴런은 이미지의 픽셀 값에 해당할 수 있습니다.
숨겨진 레이어: 입력 레이어는 데이터를 처리하고 이를 신경망의 추가 레이어로 전달합니다. 이러한 숨겨진 계층은 다양한 수준에서 정보를 처리하고 새로운 정보를 받을 때 동작을 조정합니다. 딥 러닝 네트워크에는 수백 개의 숨겨진 레이어가 있으며 다양한 관점에서 문제를 분석하는 데 사용할 수 있습니다. 예를 들어, 분류해야 하는 알려지지 않은 동물의 이미지가 제공되면 이를 이미 알고 있는 동물과 비교할 수 있습니다. 예를 들어, 귀 모양, 다리 수, 동공 크기로 어떤 동물인지 알 수 있습니다. 심층 신경망의 숨겨진 레이어도 같은 방식으로 작동합니다. 딥러닝 알고리즘이 동물의 이미지를 분류하려고 시도하는 경우 각 숨겨진 레이어는 동물의 서로 다른 특징을 처리하고 이를 정확하게 분류하려고 시도합니다.
출력 레이어: 출력 레이어는 신경망의 마지막 레이어이며 네트워크의 출력 생성을 담당합니다. 출력 레이어의 각 뉴런은 가능한 출력 범주 또는 값을 나타냅니다. 예를 들어 분류 문제에서는 각 출력 계층 뉴런이 범주에 해당할 수 있지만, 회귀 문제에서는 출력 계층에 값이 예측 결과를 나타내는 뉴런이 하나만 있을 수 있습니다.
매개변수: 신경망에서 서로 다른 계층 간의 연결은 가중치 및 편향 매개변수로 표시됩니다. 이는 네트워크가 데이터의 패턴을 정확하게 식별하고 예측할 수 있도록 훈련 프로세스 중에 최적화됩니다. 매개변수의 증가는 신경망의 모델 용량, 즉 데이터의 복잡한 패턴을 학습하고 표현하는 모델의 능력을 향상시킬 수 있습니다. 그러나 이에 따라 매개변수의 증가로 인해 컴퓨팅 성능에 대한 수요도 증가하게 됩니다.
빅 데이터
효과적으로 훈련되기 위해 신경망은 일반적으로 여러 소스에서 얻은 다양하고 고품질의 대량 데이터가 필요합니다. 이는 기계 학습 모델 교육 및 검증의 기초입니다. 머신러닝 모델은 빅데이터를 분석함으로써 데이터의 패턴과 관계를 학습하여 예측 또는 분류를 수행할 수 있습니다.
대규모 컴퓨팅 성능
신경망의 다층 복잡한 구조, 많은 수의 매개변수, 빅데이터 처리 요구 사항 및 반복적인 훈련 방법(훈련 단계에서 모델을 반복적으로 반복해야 하며 순방향 전파 및 역방향 전파가 필요함) 활성화 함수 계산, 손실 함수 계산, 기울기 계산 및 가중치 업데이트를 포함하여 학습 과정에서 각 계층에 대해 계산되는 고정밀 컴퓨팅 요구 사항, 병렬 컴퓨팅 기능, 최적화 및 정규화 기술, 모델 평가 및 검증 프로세스를 종합적으로 주도했습니다. 딥러닝으로 AGI의 발전으로 대규모 컴퓨팅 파워에 대한 요구사항이 매년 약 10배씩 증가하고 있습니다. 현재까지 최신 모델인 GPT-4에는 1조 8천억 개의 매개변수, 6천만 달러 이상의 단일 학습 비용, 2.15e 25FLOPS(21500조 부동 소수점 계산)의 컴퓨팅 성능이 포함되어 있습니다. 후속 모델 훈련을 위한 컴퓨팅 성능에 대한 수요는 여전히 확대되고 있으며, 새로운 모델도 추가되고 있습니다.
AI전산경제학
미래 시장 규모
가장 권위 있는 계산인 IDC(International Data Corporation), Inspur Information 및 Tsinghua University Global Industry Research Institute가 공동으로 작성한 2022-2023 글로벌 컴퓨팅 파워 지수 평가 보고서에 따르면 글로벌 AI 컴퓨팅 시장 규모는 2022년부터 2023년까지 증가할 것으로 예상됩니다. 2022. 생성 AI 컴퓨팅 시장은 2022년 8억 2천만 달러에서 2026년 109억 9천만 달러로 성장할 것입니다. 생성적 AI 컴퓨팅은 전체 AI 컴퓨팅 시장의 4.2%에서 31.7%로 성장할 것입니다.
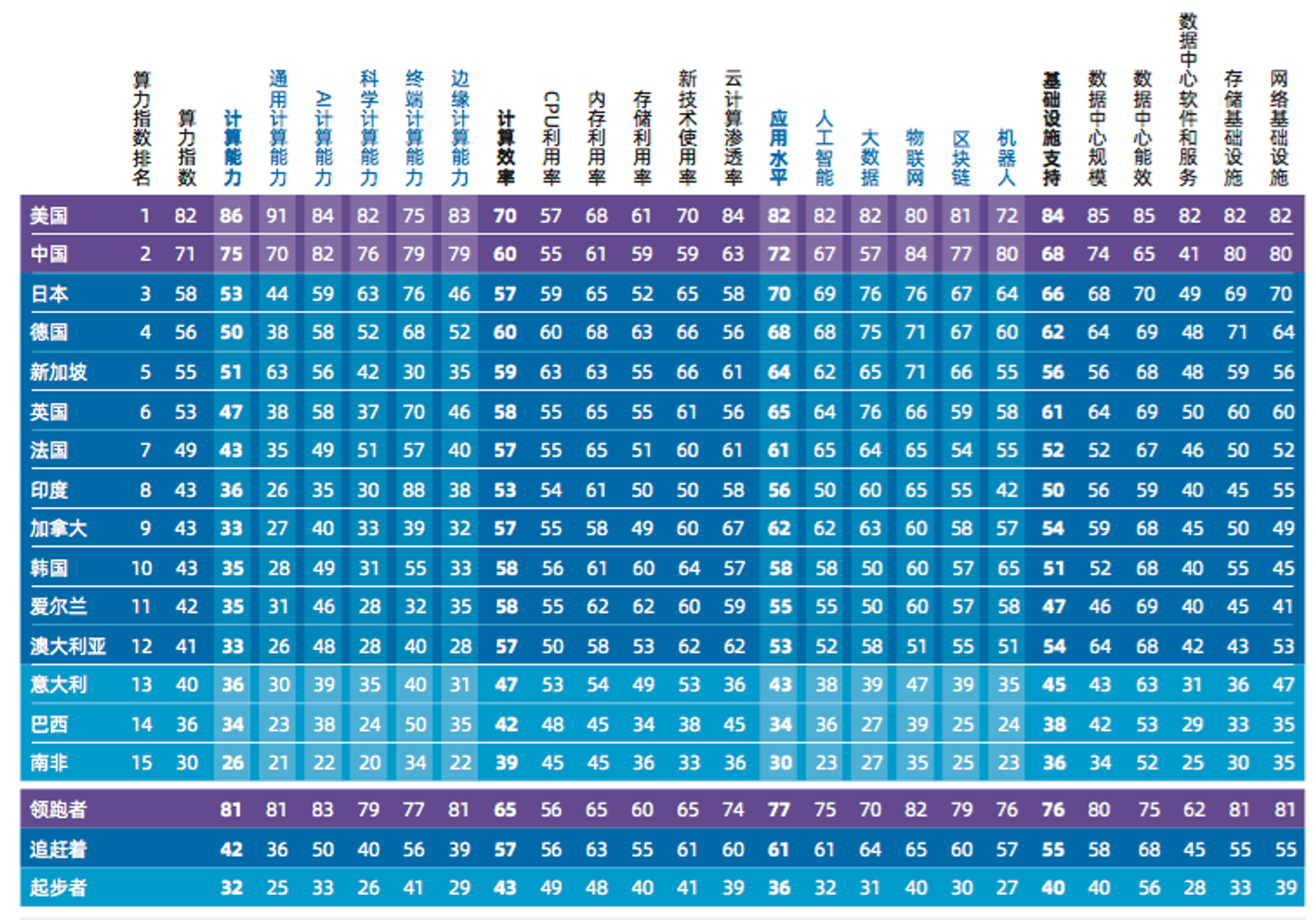
컴퓨팅 파워의 경제적 독점
AI GPU의 생산은 NVIDA가 독점적으로 독점하고 있으며 매우 비쌉니다(최신 H 100은 칩당 40,000달러에 판매됨). GPU는 출시되자마자 실리콘밸리 거대 기업에 의해 휩쓸려 갔으며 일부는 이러한 장치는 자체 제품에 사용됩니다.. 새로운 모델 교육. 나머지 부분은 클라우드 플랫폼을 통해 AI 개발자들에게 임대되는데, 구글, 아마존, 마이크로소프트 등 클라우드 컴퓨팅 플랫폼은 서버, GPU, TPU 등 수많은 컴퓨팅 자원을 보유하고 있다. 컴퓨팅 파워는 거대 기업이 독점하는 새로운 자원이 되었고, 많은 AI 관련 개발자들은 가격 인상 없이는 전용 GPU도 구입할 수 없으며, 최신 장비를 사용하려면 개발자들이 AWS나 마이크로소프트 클라우드 서버를 임대해야 한다. 재무 보고서에 따르면 이 사업은 수익이 매우 높으며, AWS의 클라우드 서비스 총 수익 마진은 61%인 반면, Microsoft의 총 수익 마진은 72%로 훨씬 더 높습니다.

그렇다면 우리는 이러한 중앙화된 권한과 통제를 수용하고 컴퓨팅 자원에 대해 72%의 이익 수수료를 지불해야 합니까? Web2를 독점하는 거대 기업이 다음 시대에도 여전히 독점할 것인가?
분산형 AGI 컴퓨팅 성능의 문제
반독점에 있어서는 일반적으로 분산화가 최적의 솔루션인데, 기존 프로젝트로 볼 때 DePIN의 스토리지 프로젝트와 RDNR과 같은 유휴 GPU 활용 프로토콜을 통해 AI에 필요한 대규모 컴퓨팅 성능을 달성할 수 있습니까? 대답은 아니요입니다. 용을 죽이는 길은 그렇게 간단하지 않습니다. 초기 프로젝트는 AGI 컴퓨팅 성능을 위해 특별히 설계되지 않았으며 실행 가능하지도 않았습니다. 체인에 컴퓨팅 성능을 추가하려면 최소한 다음 5가지 과제에 직면해야 합니다.
1. 작업 검증: 진정한 무신뢰 컴퓨팅 네트워크를 구축하고 참여자에게 경제적 인센티브를 제공하기 위해서는 네트워크에서 딥러닝 컴퓨팅 작업이 실제로 수행되는지 검증할 수 있는 방법이 있어야 합니다. 이 문제의 핵심은 딥러닝 모델의 상태 의존성인데, 딥러닝 모델에서는 각 레이어의 입력이 이전 레이어의 출력에 따라 달라집니다. 즉, 이전의 모든 레이어를 고려하지 않고는 모델의 특정 레이어를 검증할 수 없다는 의미입니다. 각 레이어의 계산은 모든 이전 레이어의 결과를 기반으로 합니다. 따라서 특정 지점(예: 특정 레이어)에서 수행된 작업을 검증하려면 모델 시작부터 해당 특정 지점까지 모든 작업을 수행해야 하며,
2. 시장 : AI 컴퓨팅 파워 시장은 신흥 시장으로 콜드 스타트 문제 등 수급 딜레마에 직면해 있으며, 시장이 성공적으로 성장하려면 처음부터 수급 유동성이 대략적으로 일치해야 합니다. . 컴퓨팅 파워의 잠재적 공급을 확보하려면 참가자에게 컴퓨팅 파워 자원에 대한 대가로 명확한 인센티브를 제공해야 합니다. 시장에는 완료된 컴퓨팅 작업을 추적하고 이에 따라 적시에 공급자에게 비용을 지불하는 메커니즘이 필요합니다. 기존 시장에서는 중개자가 관리, 온보딩 등의 작업을 처리하는 동시에 최소 지불 금액을 설정하여 운영 비용을 절감합니다. 그러나 이 접근 방식은 시장 규모를 확대할 때 비용이 더 많이 듭니다. 공급의 작은 부분만이 경제적으로 효율적으로 포착될 수 있으며, 이는 시장이 더 이상 성장하지 못하고 제한된 공급만 포착하고 유지할 수 있는 임계 균형 상태로 이어집니다.
3. 정지 문제: 정지 문제는 컴퓨팅 이론의 근본적인 문제로, 주어진 컴퓨팅 작업이 제한된 시간 내에 완료될지 아니면 절대 멈추지 않을지를 결정하는 것과 관련됩니다. 이 문제는 해결할 수 없습니다. 즉, 모든 컴퓨팅 작업이 유한한 시간 내에 중지될지 여부를 예측할 수 있는 범용 알고리즘이 없다는 의미입니다. 예를 들어, 이더리움에서 스마트 계약을 실행하는 경우에도 유사한 가동 중지 문제가 발생합니다. 즉, 스마트 계약을 실행하는 데 얼마나 많은 컴퓨팅 자원이 필요한지 또는 합리적인 시간 내에 완료되는지 여부를 미리 결정하는 것은 불가능합니다.
(딥 러닝의 맥락에서 모델과 프레임워크가 정적 그래프 구성에서 동적 구성 및 실행으로 전환되므로 이 문제는 더욱 복잡해집니다.)
4. 개인 정보 보호: 개인 정보 보호를 고려한 설계 및 개발은 프로젝트 당사자에게 필수입니다. 공개 데이터 세트에 대해 많은 양의 기계 학습 연구가 수행될 수 있지만 모델의 성능을 향상하고 특정 애플리케이션에 적응하려면 일반적으로 모델을 독점 사용자 데이터에 대해 미세 조정해야 합니다. 이러한 미세 조정 프로세스에는 개인 데이터 처리가 포함될 수 있으므로 개인 정보 보호 요구 사항을 고려해야 합니다.
5. 병렬화: 이는 현재 프로젝트를 실행 불가능하게 만드는 핵심 요소입니다. 딥 러닝 모델은 일반적으로 독점 아키텍처와 극도로 낮은 대기 시간을 갖춘 대규모 하드웨어 클러스터에서 병렬로 훈련되며, 분산 컴퓨팅 네트워크의 GPU는 빈번한 데이터 교환이 도입되어야 합니다. 대기 시간은 가장 낮은 성능의 GPU에 의해 제한됩니다. 컴퓨팅 전원이 신뢰할 수 없고 신뢰할 수 없는 경우 이종 병렬화를 어떻게 달성할 것인지가 반드시 해결되어야 할 문제이며, 현재 실현 가능한 방법은 현재 고도로 병렬화된 스위치 트랜스포머와 같은 트랜스포머 모델을 통해 병렬화를 달성하는 것입니다.
해결책: 현재 AGI 컴퓨팅 파워 시장을 분산시키려는 시도는 아직 초기 단계에 있지만, 초기에 분산형 네트워크의 합의 설계와 모델 훈련 및 추론에서 분산형 컴퓨팅 파워 네트워크 구현을 해결한 정확히 두 개의 프로젝트가 있습니다. .프로세스. 다음은 Gensyn과 Together를 예로 들어 분산형 AGI 컴퓨팅 파워 시장의 설계 방법과 문제점을 분석합니다.
Gensyn

Gensyn은 아직 구축 단계에 있는 AGI 컴퓨팅 파워 시장으로, 분산형 딥 러닝 컴퓨팅의 다양한 과제를 해결하고 현재 딥 러닝 비용을 줄이는 것을 목표로 합니다. Gensyn은 기본적으로 Polkadot 네트워크를 기반으로 한 첫 번째 레이어 지분 증명 프로토콜로, 컴퓨팅 및 기계 학습 작업 수행을 위한 유휴 GPU 장치 대신 스마트 계약을 통해 솔버(Solver)에게 직접 보상을 제공합니다.
위의 질문으로 돌아가서, 진정한 무신뢰 컴퓨팅 네트워크 구축의 핵심은 완성된 머신러닝 작업을 검증하는 것입니다. 이는 복잡성 이론, 게임 이론, 암호화 및 최적화의 교차점 사이의 균형을 찾아야 하는 매우 복잡한 문제입니다.
Gensyn은 해결사가 완료한 기계 학습 작업의 결과를 제출할 수 있는 간단한 솔루션을 제안합니다. 이러한 결과가 정확한지 확인하기 위해 다른 독립 검증자가 동일한 작업을 다시 수행하려고 시도합니다. 이 접근 방식은 단 하나의 검증인만이 재실행을 수행하므로 단일 복제라고 할 수 있습니다. 즉, 원본 작업의 정확성을 확인하기 위한 추가 노력은 단 한 번뿐이라는 의미입니다. 그러나 저작물을 검증한 사람이 원본 저작물의 요청자가 아닌 경우에는 신뢰 문제가 남아 있습니다. 검증자 자체가 정직하지 않을 수도 있고, 그들의 작업도 검증이 필요하기 때문입니다. 이로 인해 저작물을 검증하는 사람이 원본 저작물의 요청자가 아닌 경우 해당 저작물을 검증하기 위해 다른 검증자가 필요한 잠재적인 문제가 발생합니다. 하지만 이 새로운 검증인이 신뢰되지 않을 수도 있으므로 작업을 검증하기 위해 또 다른 검증인이 필요하며, 이는 무한한 복제 체인을 생성하여 영원히 계속될 수 있습니다. 여기서 우리는 세 가지 핵심 개념을 도입하고 이를 엮어 무한 사슬 문제를 해결하기 위한 네 가지 역할을 가진 참여자 시스템을 구축해야 합니다.
확률적 학습 증명: 그라데이션 기반 최적화 프로세스의 메타데이터를 사용하여 완료된 작업 인증서를 구축합니다. 특정 단계를 복제함으로써 이러한 인증서를 빠르게 검증하여 작업이 예상대로 완료되었는지 확인할 수 있습니다.
그래프 기반 정밀 현지화 프로토콜: 다중 입도, 그래프 기반 정밀 현지화 프로토콜 및 일관된 교차 평가기 실행을 사용합니다. 이를 통해 유효성 검사 노력을 다시 실행하고 비교하여 일관성을 보장하고 궁극적으로 블록체인 자체에서 확인할 수 있습니다.
Truebit 스타일 인센티브 게임: 스테이킹 및 슬래싱을 사용하여 재정적으로 합리적인 모든 참가자가 정직하게 행동하고 의도한 작업을 수행하도록 보장하는 인센티브 게임을 구축합니다.
참가자 시스템은 제출자, 해결자, 검증자, 보고자로 구성됩니다.
제출자:
제출자는 계산할 작업을 제공하고 완료된 작업 단위에 대해 비용을 지불하는 시스템의 최종 사용자입니다.
해결사:
솔버는 모델 훈련을 수행하고 검증자가 확인하는 증거를 생성하는 시스템의 주요 작업자입니다.
검증자:
검증기는 비결정론적 훈련 프로세스를 결정론적 선형 계산과 연결하고, 솔버 증명의 일부를 복제하고, 예상 임계값과 거리를 비교하는 데 핵심입니다.
내부고발자:
내부 고발자는 최후의 방어선으로서 검증인의 작업을 확인하고 넉넉한 포상금을 받기 위해 이의를 제기합니다.
시스템 운영
프로토콜에 의해 설계된 게임 시스템의 작동에는 작업 제출부터 최종 검증까지 전체 프로세스를 완료하기 위한 4가지 주요 참가자 역할을 포함하는 8단계가 포함됩니다.
1. 작업 제출: 작업은 세 가지 특정 정보로 구성됩니다.
작업 및 하이퍼파라미터를 설명하는 메타데이터
모델 바이너리(또는 기본 스키마)
공개적으로 액세스할 수 있고 사전 처리된 학습 데이터입니다.
2. 작업을 제출하기 위해 제출자는 작업의 세부 사항을 기계가 읽을 수 있는 형식으로 지정하고 이를 모델 바이너리(또는 기계가 읽을 수 있는 스키마) 및 전처리된 훈련 데이터의 공개적으로 액세스할 수 있는 위치와 함께 체인에 제출합니다. 공용 데이터는 AWS S3와 같은 간단한 객체 스토리지나 IPFS, Arweave 또는 Subspace와 같은 분산형 스토리지에 저장할 수 있습니다.
3. 프로파일링: 프로파일링 프로세스는 학습 검증 증명을 위한 기본 거리 임계값을 결정합니다. 검증자는 정기적으로 분석 작업을 크롤링하고 학습 증명 비교를 위한 돌연변이 임계값을 생성합니다. 임계값을 생성하기 위해 검증자는 다양한 무작위 시드를 사용하여 훈련의 일부를 결정론적으로 실행하고 다시 실행하며 자체 증명을 생성하고 확인합니다. 이 프로세스 동안 검증자는 검증 솔루션으로 사용할 수 있는 비결정적 작업에 대한 전체 예상 거리 임계값을 설정합니다.
4. 훈련: 분석 후 작업은 공개 작업 풀(이더리움의 Mempool과 유사)에 들어갑니다. 작업을 수행할 해결사를 선택하고 작업 풀에서 작업을 제거합니다. 솔버는 제출자가 제출한 메타데이터와 제공된 모델 및 교육 데이터를 기반으로 작업을 수행합니다. 훈련 작업을 수행할 때 솔버는 매개변수를 포함하여 훈련 프로세스의 메타데이터를 주기적으로 검사하고 저장하여 학습 증명을 생성하므로 검증기가 다음 최적화 단계를 최대한 정확하게 복제합니다.
5. 증명 생성: 솔버는 모델 가중치 또는 업데이트와 해당 인덱스를 훈련 데이터 세트에 주기적으로 저장하여 가중치 업데이트를 생성하는 데 사용되는 샘플을 식별합니다. 더 강력한 보장을 제공하거나 저장 공간을 절약하기 위해 체크포인트 빈도를 조정할 수 있습니다. 증명은 스택될 수 있습니다. 즉, 증명은 가중치를 초기화하는 데 사용되는 무작위 분포에서 시작하거나 자체 증명을 사용하여 생성된 사전 훈련된 가중치에서 시작할 수 있습니다. 이를 통해 프로토콜은 보다 구체적인 작업을 위해 미세 조정될 수 있는 입증되고 사전 훈련된 기본 모델(즉, 기본 모델) 세트를 구축할 수 있습니다.
6. 증명 검증: 작업이 완료된 후 해결사는 작업 완료를 체인에 등록하고 검증자가 접근할 수 있도록 공개적으로 접근 가능한 위치에 학습 증명을 표시합니다. 검증자는 공용 작업 풀에서 검증 작업을 추출하고 계산 작업을 수행하여 증명의 일부를 다시 실행하고 거리 계산을 수행합니다. 그런 다음 결과 거리는 분석 단계에서 계산된 임계값과 함께 체인에서 검증이 증명과 일치하는지 확인하는 데 사용됩니다.
7. 그래프 기반 핀포인트 챌린지: 학습증명 검증 후, 검증자의 작업을 복사하여 검증 작업 자체가 올바르게 수행되었는지 확인할 수 있습니다. 내부 고발자가 확인이 잘못 수행되었다고 생각하는 경우(악의적이든 아니든) 보상을 받기 위해 계약 중재에 이의를 제기할 수 있습니다. 이 보상은 체인 자체를 사용하여 중재가 수행되는 솔버 및 검증인 예치금(진정의 경우) 또는 복권 상금 풀(오탐의 경우)에서 나올 수 있습니다. 내부고발자(이 경우 검증자)는 적절한 보상을 받을 것으로 예상되는 경우에만 업무를 검증하고 후속적으로 이의를 제기합니다. 실제로 이는 내부고발자가 다른 활동적인 내부고발자 수(예: 실시간 입금 및 챌린지 포함)에 따라 네트워크에 가입하거나 탈퇴해야 함을 의미합니다. 따라서 모든 내부고발자에게 예상되는 기본 전략은 다른 내부고발자의 수가 적을 때 네트워크에 가입하고 보증금을 게시하고 활성 작업을 무작위로 선택하고 검증 프로세스를 시작하는 것입니다. 첫 번째 작업이 끝나면 다른 임의의 활성 작업을 가져와 내부 고발자 수가 결정된 지불 임계값을 초과할 때까지 반복한 다음 네트워크를 떠나게 됩니다(또는 하드웨어 기능에 따라 네트워크로 전환하여 다른 작업을 수행할 가능성이 더 높음) 역할 - 검증자 또는 해결자) 상황이 다시 반전될 때까지.
8. 계약 중재: 검증인이 내부 고발자로부터 이의를 제기하면 체인과 함께 분쟁 작업 또는 입력 위치를 알아내는 프로세스에 들어가고, 궁극적으로 체인은 최종 기본 작업을 수행하고 이의가 적합한지 여부를 결정합니다. 합리적인. 내부고발자를 정직하게 유지하고 검증인의 딜레마를 극복하기 위해 주기적 강제 오류 및 잭팟 지급이 여기에 도입되었습니다.
9. 정산: 정산 과정에서 확률과 확실성 점검의 결과에 따라 참가자에게 지급됩니다. 다양한 시나리오에서는 이전 검증 및 문제의 결과에 따라 지급액이 달라집니다. 작업이 올바르게 수행되고 모든 검사가 통과된 것으로 간주되면 솔루션 제공자와 검증자는 수행된 작업에 따라 보상을 받습니다.
프로젝트 개요
Gensyn은 검증 레이어와 인센티브 레이어에서 멋진 게임 시스템을 설계했으며, 네트워크에서 분기점을 찾아 신속하게 오류를 찾을 수 있지만 현재 시스템에는 여전히 많은 세부 사항이 누락되어 있습니다. 예를 들어, 임계값을 너무 높게 설정하지 않고 보상과 처벌이 합당하도록 매개변수를 설정하는 방법은 무엇입니까? 극한 상황과 게임 내 솔버의 다양한 컴퓨팅 성능을 고려해보셨나요? 현재 버전의 백서에는 이종 병렬 연산에 대한 자세한 설명이 없으며, 현재 Gensyn이 갈 길이 멀습니다.
Together.ai
투게더는 대형 모델을 중심으로 분산형 AI 컴퓨팅 파워 솔루션을 지향하는 오픈소스 기업으로, 누구나 언제 어디서나 AI에 접근하고 사용할 수 있기를 바랍니다. 엄밀히 말하면 투게더는 블록체인 프로젝트는 아니지만, 이 프로젝트는 초기에 분산형 AGI 컴퓨팅 네트워크의 지연 문제를 해결했습니다. 따라서 다음 글에서는 투게더의 솔루션만을 분석할 뿐, 프로젝트를 평가하지는 않습니다.
분산형 네트워크가 데이터 센터보다 100배 느린 경우 대규모 모델의 훈련 및 추론을 어떻게 달성할 수 있습니까?
네트워크에 참여하는 GPU 장치의 분포가 분산된 상황에서 어떤 모습일지 상상해 볼까요? 이러한 장치는 다양한 대륙과 도시에 배포되며 장치를 연결해야 하며 연결 지연 시간과 대역폭도 다양합니다. 아래 그림과 같이 분산 상황을 시뮬레이션한 것이며, 장치는 북미, 유럽, 아시아에 분포되어 있으며 장치 간 대역폭과 지연이 다릅니다. 그렇다면 직렬로 연결하려면 어떻게 해야 할까요?
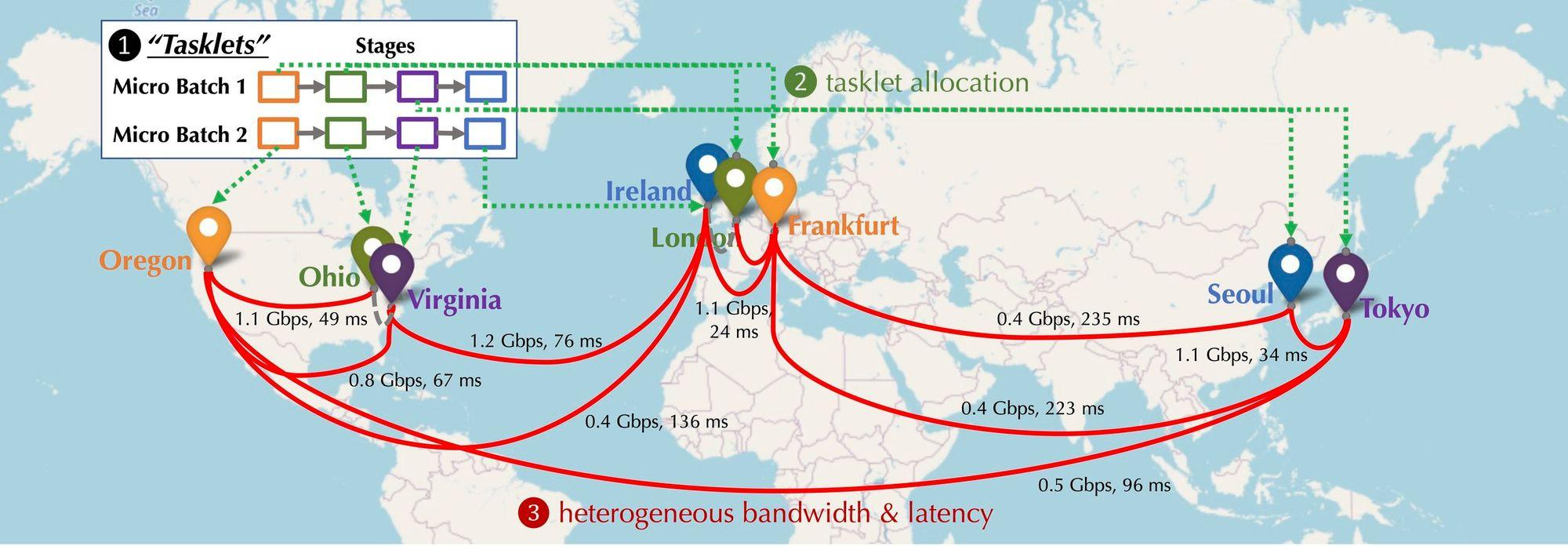
분산 훈련 컴퓨팅 모델링:아래 그림은 여러 장치에 대한 기본 모델 훈련을 보여 주며, 통신 유형 관점에서 보면 순방향 활성화(Forward Activation), 역방향 그라데이션(Backward Gradient) 및 수평 통신의 세 가지 통신 유형이 있습니다.
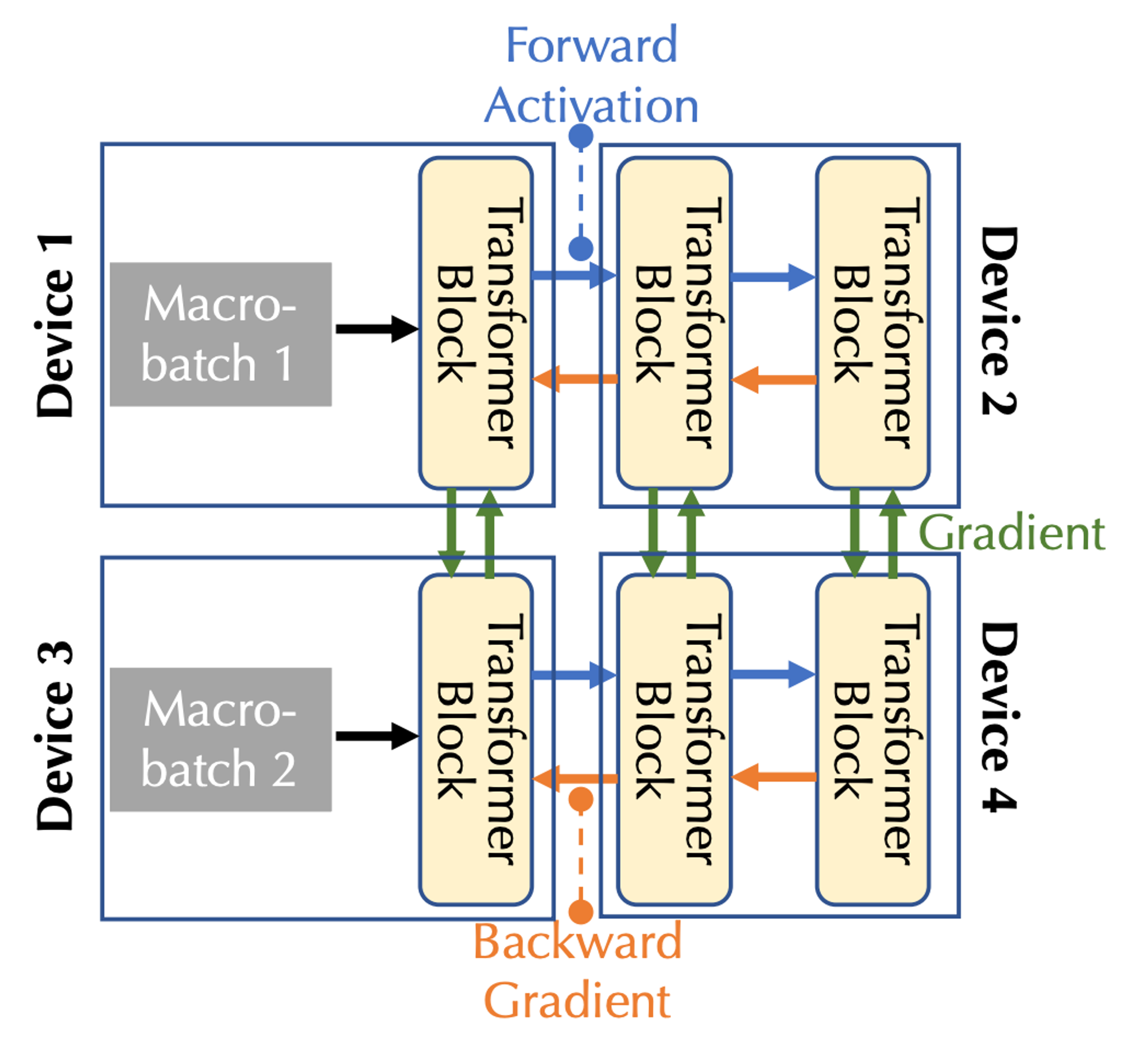
통신 대역폭과 대기 시간을 결합하면 다중 장치 사례의 세 가지 통신 유형에 해당하는 파이프라인 병렬성과 데이터 병렬성의 두 가지 형태의 병렬성을 고려해야 합니다.
파이프라인 병렬화에서는 모델의 모든 레이어가 여러 단계로 나누어지며, 각 장치는 여러 변환기 블록과 같은 연속적인 레이어 시퀀스인 하나의 단계를 처리합니다. 순방향 패스에서는 활성화가 다음 단계로 전달되는 반면, 역방향에서는 활성화가 통과하면 활성화 그라데이션이 이전 단계로 전달됩니다.
데이터 병렬 처리에서 장치는 서로 다른 마이크로 배치에 대한 기울기를 독립적으로 계산하지만 이러한 기울기를 동기화하려면 통신이 필요합니다.
일정 최적화:
분산된 환경에서는 교육 프로세스에 의사소통이 제한되는 경우가 많습니다. 스케줄링 알고리즘은 일반적으로 통신량이 많은 작업을 연결 속도가 빠른 장치에 할당합니다. 작업 간의 종속성과 네트워크의 이질성을 고려하여 특정 스케줄링 전략의 비용을 먼저 모델링해야 합니다. 기본 모델을 훈련하는 데 드는 복잡한 통신 비용을 포착하기 위해 Together는 새로운 공식을 제안하고 그래프 이론을 통해 비용 모델을 두 가지 수준으로 분해했습니다.
그래프 이론은 주로 그래프(네트워크)의 특성과 구조를 연구하는 수학의 한 분야입니다. 그래프는 정점(노드)과 간선(노드를 연결하는 선)으로 구성됩니다. 그래프 이론의 주요 목적은 그래프의 연결성, 그래프의 색상, 그래프의 경로 및 순환 특성 등 그래프의 다양한 특성을 연구하는 것입니다.
첫 번째 수준은 균형 잡힌 그래프 분할(부분 집합 간의 간선 수를 최소화하면서 그래프의 꼭지점 집합을 동일하거나 대략 동일한 크기의 여러 하위 집합으로 분할하는 것)입니다. 이 분할에서 각 부분 집합은 분할을 나타내며 통신 비용을 줄입니다. 파티션 간의 가장자리를 최소화하여) 문제는 데이터 병렬 처리의 통신 비용에 해당합니다.
두 번째 수준은 결합 그래프 매칭과 여행하는 외판원 문제입니다(결합 그래프 매칭과 여행하는 외판원 문제는 그래프 매칭과 여행하는 외판원 문제의 요소를 결합한 조합 최적화 문제입니다. 그래프 매칭 문제는 그래프에서 다음과 같은 매칭을 찾는 것입니다. 일종의 비용 최소화 또는 최대화 그리고 이동하는 세일즈맨 문제는 파이프라인 병렬 처리의 통신 비용에 해당하는 그래프의 모든 노드를 방문하는 최단 경로를 찾는 것입니다.
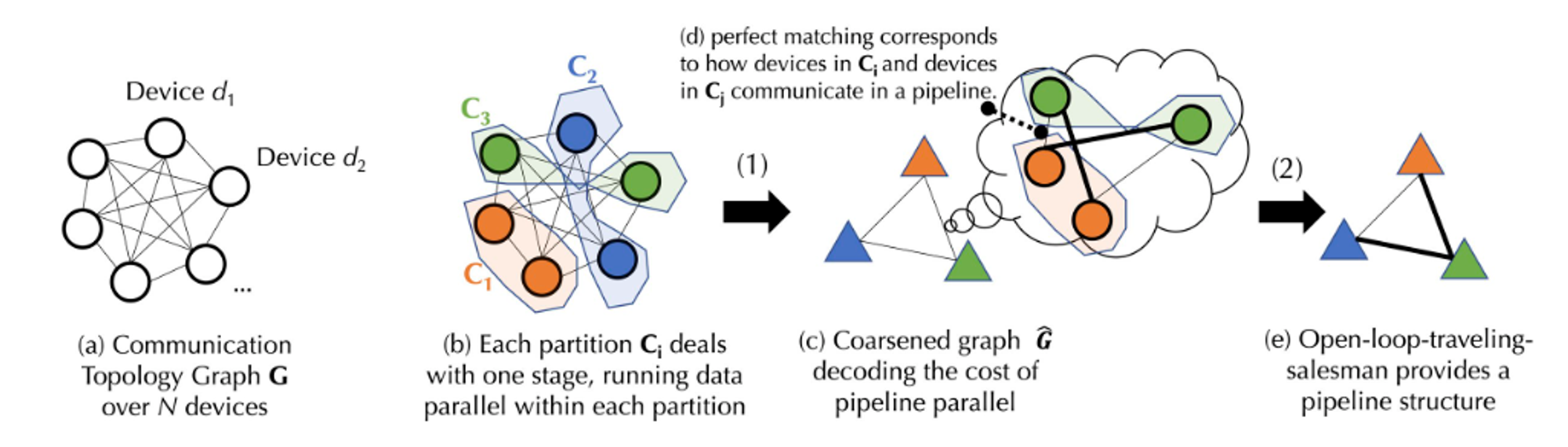 위 그림은 개략적인 프로세스 다이어그램입니다. 실제 구현 프로세스에는 복잡한 계산 공식이 포함되기 때문입니다. 아래에서는 이해를 돕기 위해 그림에 나타난 과정을 좀 더 간단하게 설명하며, 자세한 구현 과정은 투게더 공식 홈페이지 문서를 참고하시면 됩니다.
위 그림은 개략적인 프로세스 다이어그램입니다. 실제 구현 프로세스에는 복잡한 계산 공식이 포함되기 때문입니다. 아래에서는 이해를 돕기 위해 그림에 나타난 과정을 좀 더 간단하게 설명하며, 자세한 구현 과정은 투게더 공식 홈페이지 문서를 참고하시면 됩니다.
N개의 장치를 포함하는 장치 세트 D가 있다고 가정합니다. 그 사이의 통신은 지연 시간(A 매트릭스)과 대역폭(B 매트릭스)이 불확실합니다. 장치 세트 D를 기반으로 먼저 균형 그래프 파티션을 생성합니다. 각 파티션 또는 장치 그룹의 장치 수는 대략 동일하며 모두 동일한 파이프라인 단계를 처리합니다. 이렇게 하면 데이터가 병렬화될 때 각 장치 그룹이 비슷한 양의 작업을 수행하게 됩니다. (데이터 병렬성은 동일한 작업을 수행하는 여러 장치를 의미하는 반면, 파이프라인 단계는 특정 순서에 따라 서로 다른 작업 단계를 실행하는 장치를 나타냅니다.) 통신의 대기 시간과 대역폭을 기반으로 공식을 사용하여 장치 그룹 간에 데이터를 전송하는 비용을 계산할 수 있습니다. 균형 잡힌 각 장치 그룹이 병합되어 완전히 연결된 대략적인 그래프가 생성됩니다. 여기서 각 노드는 파이프라인의 단계를 나타내고 가장자리는 두 단계 간의 통신 비용을 나타냅니다. 통신 비용을 최소화하기 위해 일치 알고리즘을 사용하여 함께 작동해야 하는 장치 그룹을 결정합니다.
추가적인 최적화를 위해 이 문제는 모든 장치 간 데이터 전송을 위한 최적의 경로를 찾기 위해 개방 루프 여행 세일즈맨 문제(개 루프는 경로의 시작점으로 돌아갈 필요가 없음을 의미함)로 모델링될 수도 있습니다. 마지막으로 Together는 혁신적인 스케줄링 알고리즘을 사용하여 주어진 비용 모델에 대한 최적의 할당 전략을 찾아 통신 비용을 최소화하고 교육 처리량을 최대화합니다. 실제 측정에 따르면, 이러한 스케줄링 최적화 하에서 네트워크가 100배 느려지더라도 종단 간 훈련 처리량은 약 1.7~2.3배만 느려집니다.
통신 압축 최적화:
통신 압축의 최적화를 위해 Together에서는 AQ-SGD 알고리즘을 도입했습니다.(자세한 계산 과정은 Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees 논문을 참조하세요.) AQ-SGD 알고리즘은 이 문제를 해결하는 것입니다. 저속 네트워크의 파이프라인 병렬화 훈련의 통신 효율성 문제를 해결하기 위해 설계된 새로운 능동 압축 기술입니다. 활동 값을 직접 압축하는 이전 방법과 달리 AQ-SGD는 서로 다른 기간에 동일한 훈련 샘플의 활동 값 변화를 압축하는 데 중점을 둡니다. 이 독특한 방법은 흥미로운 자체 실행 역학을 도입합니다. 훈련이 안정화됨에 따라, 알고리즘의 성능은 점차 향상될 것으로 예상된다. AQ-SGD 알고리즘은 엄격한 이론적 분석을 거쳐 특정 기술 조건에서 우수한 수렴률과 제한된 오류가 있는 양자화 함수를 갖는 것으로 입증되었습니다. 이 알고리즘은 효율적으로 구현될 수 있을 뿐만 아니라, 활성 값을 저장하기 위해 더 많은 메모리와 SSD를 활용해야 하지만 종단 간 런타임 오버헤드를 추가하지 않습니다. 시퀀스 분류 및 언어 모델링 데이터 세트에 대한 광범위한 실험을 통해 검증된 AQ-SGD는 수렴 성능을 저하시키지 않고 활동 값을 2-4비트로 압축할 수 있습니다. 또한 AQ-SGD는 최첨단 경사 압축 알고리즘과 통합되어 엔드 투 엔드 통신 압축, 즉 모델 경사, 순방향 활동 값을 포함한 기계 간의 모든 데이터 교환을 달성할 수 있습니다. 및 역방향 기울기는 낮은 정확도로 압축되므로 분산 훈련의 통신 효율성이 크게 향상됩니다. 중앙 집중식 컴퓨팅 네트워크(예: 10Gbps)에서 압축하지 않은 엔드투엔드 훈련 성능과 비교하면 현재 속도는 31%만 느립니다. 스케줄링 최적화에 관한 데이터와 결합하면 중앙집중식 컴퓨팅 파워 네트워크와 중앙집중식 컴퓨팅 파워 네트워크 사이에는 여전히 일정한 격차가 있지만 향후 따라잡을 수 있는 희망은 상대적으로 높습니다.
결론
AI 물결이 가져온 배당 시대에 AGI 컴퓨팅 파워 시장은 의심할 여지 없이 많은 컴퓨팅 파워 시장 중에서 가장 큰 잠재력과 가장 많은 수요를 가진 시장이다. 그러나 개발 난이도, 하드웨어 요구 사항, 재정적 요구 사항도 가장 높습니다. 위 두 프로젝트의 상황으로 볼 때 AGI 컴퓨팅 파워 시장이 구현되기까지는 아직 일정한 거리가 있습니다. 진정한 분산형 네트워크는 이상적인 상황보다 훨씬 더 복잡합니다. 클라우드 거대 기업과 경쟁하기에는 분명히 충분하지 않습니다. 현재. 이 기사를 작성하는 동안 초기 단계(PPT 단계)의 일부 소규모 프로젝트가 덜 어려운 추론 단계나 소규모 모델에 초점을 맞추는 등 몇 가지 새로운 진입점을 탐색하기 시작했다는 점도 관찰했습니다. 좀 더 실용적인 시도.
AGI 컴퓨팅 파워 시장이 최종적으로 어떻게 실현될지는 아직 불분명하며, 많은 어려움에 직면해 있지만 장기적으로는 AGI 컴퓨팅 파워의 탈중앙화, 무허가성 중요성이 중요하며 추론과 훈련의 권리가 집중되어서는 안 됩니다. 소수의 중앙화된 거인들에게. 왜냐하면 인류에게는 값비싼 회비를 지불하는 것은 고사하고 새로운 종교나 새로운 교황이 필요하지 않기 때문입니다.
참고자료
1.Gensyn Litepaper:https://docs.gensyn.ai/litepaper/
2.NeurIPS 2022: Overcoming Communication Bottlenecks for Decentralized Training :https://together.ai/blog/neurips-2022-overcoming-communication-bottlenecks-for-decentralized-training-12
3.Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees:https://arxiv.org/abs/2206.01299
4.The Machine Learning Compute Protocol and our future:https://mirror.xyz/gensyn.eth/_K2v2uuFZdNnsHxVL3Bjrs4GORu3COCMJZJi7_MxByo
5.Microsoft:Earnings Release FY 23 Q2:https://www.microsoft.com/en-us/Investor/earnings/FY-2023-Q2/performance
6. AI 입장권 경쟁: BAT, Byte 및 Meituan은 GPU를 놓고 경쟁합니다.https://m.huxiu.com/article/1676290.html
7.IDC: 2022-2023 글로벌 컴퓨팅 파워 지수 평가 보고서:https://www.tsinghua.edu.cn/info/1175/105480.htm
8. Guosheng Securities 대형 모델 훈련 추정:https://www.fxbaogao.com/detail/3565665
9. 정보의 날개: 컴퓨팅 파워와 AI는 어떤 관계가 있나요? :https://zhuanlan.zhihu.com/p/627645270


