
機械学習モデルのためのカーネルレベルの証明メカニズム
原作者:方志勇
「象をどうやって食べるかって?一口ずつだよ。」
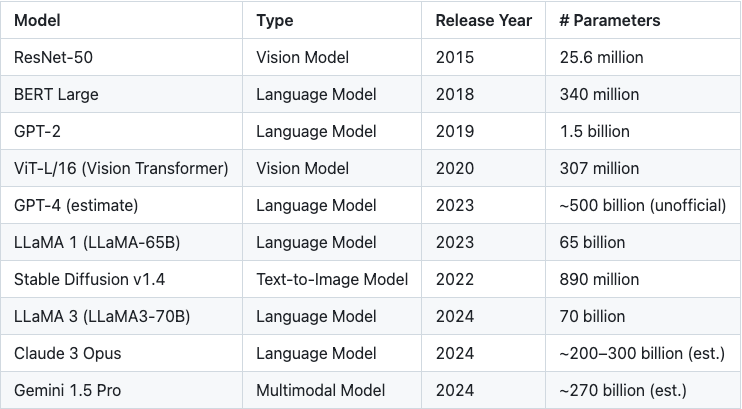
近年、機械学習モデルは驚異的な速度で飛躍的な進歩を遂げています。モデルの機能が向上すると同時に、その複雑さも増大しています。今日の高度なモデルは、数百万、あるいは数十億ものパラメータを含むことも珍しくありません。こうしたスケールの課題に対処するため、様々なゼロ知識証明システムが登場し、証明時間、検証時間、そして証明サイズの間で常に動的なバランスを追求しています。
表1: モデルパラメータサイズの指数関数的増加
ゼロ知識証明の分野における現在の研究のほとんどは、証明システム自体の最適化に焦点を当てていますが、ある重要な側面がしばしば見落とされています。それは、大規模なモデルを、証明のためにより小さく、より扱いやすいサブモジュールに適切に分割する方法です。なぜこれがそれほど重要なのか、疑問に思うかもしれません。
詳細に説明しましょう:
現代の機械学習モデルのパラメータ数は数十億に達することが多く、暗号処理を全く行わなくても膨大なメモリリソースを消費します。ゼロ知識証明(ZKP)の文脈では、この課題はさらに深刻化します。
各浮動小数点パラメータは代数体の要素に変換する必要があり、この変換処理自体がメモリ使用量を約5~10倍に増加させます。さらに、代数体における浮動小数点演算を正確にシミュレートするためには、追加の演算オーバーヘッド(通常は約5倍)が必要になります。
一般的に、モデル全体のメモリ要件は元のサイズの25~50倍に増加する可能性があります。例えば、10億個の32ビット浮動小数点パラメータを持つモデルでは、変換されたパラメータを格納するためだけに100~200GBのメモリが必要になる場合があります。中間計算値や証明システム自体のオーバーヘッドを考慮すると、全体のメモリ使用量は容易にTBレベルを超えます。
Groth 16やPlonkといった現在主流の証明システムでは、最適化されていない実装では、関連するすべてのデータが同時にメモリにロードできると仮定するのが一般的です。この仮定は技術的には実現可能ですが、実際のハードウェア環境では非常に困難であり、利用可能な証明計算リソースを大幅に制限します。
多面体の解法: zkCuda
zkCuda とは何ですか?
zkCUDA 技術ドキュメントで述べたように:
PolyhedraのzkCUDAは、高性能回路開発のためのゼロ知識コンピューティング環境であり、証明生成の効率を向上させるように設計されています。回路の表現力を犠牲にすることなく、zkCUDAは基盤となる証明器とハードウェアの並列機能を最大限に活用し、高速なZK証明生成を実現します。
zkCUDA言語は、構文とセマンティクスにおいてCUDAと非常に類似しており、CUDAの経験を持つ開発者にとって非常に使いやすい言語です。基盤となる実装はRustで行われ、セキュリティとパフォーマンスの両方を確保しています。
zkCUDA を使用すると、開発者は次のことが可能になります。
高性能な ZK 回路を迅速に構築します。
GPU や MPI をサポートするクラスター環境などの分散ハードウェア リソースを効率的にスケジュールして活用し、大規模な並列コンピューティングを実現します。
なぜ zkCUDA なのか?
zkCudaは、GPUコンピューティングに着想を得た高性能ゼロ知識コンピューティングフレームワークです。大規模な機械学習モデルをより小規模で管理しやすいコンピューティングユニット(カーネル)に分割し、CUDAに類似したフロントエンド言語を通じて効率的な制御を実現します。この設計には、以下の主要な利点があります。
1. 完全一致のための証明システムの選択
zkCUDAは、各コンピューティングカーネルのきめ細かな分析をサポートし、最適なゼロ知識証明システムとマッチングさせます。例えば、
高度に並列化されたコンピューティング タスクの場合、構造化された並列処理の処理に適した GKR などのプロトコルを使用できます。
小規模なタスクや不規則に構造化されたタスクの場合、コンパクトなコンピューティング シナリオでオーバーヘッドが低い Groth 16 などの証明システムを使用する方が適切です。
バックエンドの選択をカスタマイズすることで、zkCUDA はさまざまな ZK プロトコルのパフォーマンス上の利点を最大限に活用できます。
2. よりスマートなリソーススケジューリングと並列最適化
異なるプルーフカーネルには、CPU、メモリ、I/O のリソース要件が大きく異なります。zkCUDA は、各タスクのリソース消費を正確に評価し、全体的なスループットを最大化するようにインテリジェントにスケジュールできます。
さらに重要なのは、zkCUDA は CPU、GPU、FPGA などの異機種コンピューティング プラットフォーム間でのタスク分散をサポートし、ハードウェア リソースを最適に利用してシステム レベルのパフォーマンスを大幅に向上させることです。
zkCudaはGKRプロトコルに自然にフィットします
zkCuda は、さまざまなゼロ知識証明システムと互換性のある汎用コンピューティング フレームワークとして設計されていますが、GKR (Goldwasser-Kalai-Rothblum) プロトコルとの高いアーキテクチャ互換性を自然に備えています。
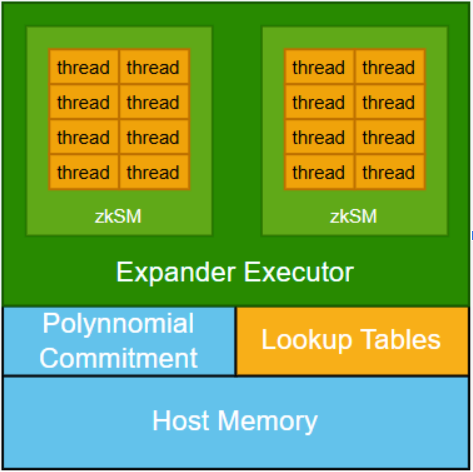
アーキテクチャ設計の観点から見ると、zkCUDAは、様々なサブコンピューティングカーネルを接続する多項式コミットメントメカニズムを導入し、すべてのサブコンピューティングが一貫した共有データに基づいて実行されることを保証します。このメカニズムはシステムの整合性を維持するために不可欠ですが、同時に大きなコンピューティングコストも伴います。
対照的に、GKRプロトコルはより効率的な代替パスを提供します。各カーネルが内部制約を完全に証明することを要求する従来のゼロ知識システムとは異なり、GKRでは計算の正しさの検証をカーネル出力から入力まで再帰的に遡ることができます。このメカニズムにより、各モジュールで検証を完全に拡張するのではなく、正しさをカーネル間で転送できます。その中核となる考え方は、機械学習における勾配バックプロパゲーションに似ており、計算グラフを通じて正しさの主張を追跡および伝達します。
このような「証明勾配」を複数のパスで統合することはある程度の複雑さをもたらしますが、このメカニズムこそがzkCUDAとGKRの緊密な連携の基盤となっています。機械学習の学習プロセスの構造的特性を整合させることで、zkCUDAはより緊密なシステム統合と、大規模モデルシナリオにおけるより効率的なゼロ知識証明生成を実現することが期待されます。
予備的な結果と今後の方向性
私たちはzkCudaフレームワークの初期開発を完了し、KeccakやSHA-256などの暗号化ハッシュ関数や小規模機械学習モデルを含む複数のシナリオでテストに成功しました。
今後は、メモリ効率の高いスケジューリングやグラフレベルの最適化といった、成熟したエンジニアリング技術を現代の機械学習トレーニングにさらに導入したいと考えています。これらの戦略をゼロ知識証明生成プロセスに統合することで、システムのパフォーマンス限界と適応柔軟性が大幅に向上すると考えています。
これは単なる出発点です。zkCuda は、効率的で、拡張性と適応性に優れた汎用的な証明フレームワークを目指して進化し続けます。


