
分散型 ID は既存の Web2 ID システムよりどのように優れていますか?
作者: 探しているガラス
推奨される理由:
推奨される理由:
「私は誰であるか」とは、自意識のある人の自分自身についての自己認識であり、この自己認識において、彼は自分自身の思考の対象になります。アイデンティティは、個人またはグループの特性、信念、性格、外観、表現を心理的に構成する包括的で複雑な概念です。オンチェーン ID、デジタル ID、ネットワーク ID の概念をどのように表現するか、分散型の物語ではどのような ID 管理システムが必要になるでしょうか?分散型アイデンティティ (DID) は既存の Web2 アイデンティティ システムよりどのように優れていますか?
私たちは、あまりにも長い間、プライバシー漏洩、情報悪用、アルゴリズム悪用を抱えて、Web2 世界の孤島で生き延びてきました。この記事では、データ主権のリーダーシップの下、分散 ID テーブルを通じてまったく新しい ID テーブルを構築する方法を探ります。 。"I own my data"アイデンティティシステム。
「アイデンティティ」について書けば書くほど、その言葉は遍在するため、ますます理解不能な用語になります。 ——エリック・エリクソン
「アイデンティティ クライシス」という用語を作った心理学者、エリック エリクソンが言うように、私はそれが真実であるとよく感じます。アイデンティティは多くの含意を持つ漠然とした概念であり、その意味は文脈に大きく依存しています。これは Web3 でも例外ではありません。
この投稿では、この問題に対処しようとします。つまり、Web 上の ID を主に情報の保存、管理、取得のためのツールとして捉えるフレームワークを構築することです。
最初のレベルのタイトル
名前には何が入っていますか? 「アイデンティティ」の3つの意味
人々がアイデンティティについて語るとき、それらは通常、a) 一意の識別子、b) エンティティの全体像、または c) エンティティに関する特定のコンテキストという 3 つの関連はあるものの個別の範囲のいずれかを意味します。
一意の識別子は、あらゆる社会的環境において非常に重要です。友人、家族、または小さな部族 (ダンバーの基準である 150 人未満) の間では、よく知っていると思われるため、名前は十分な「識別子」です。さらに、より厳密な識別子は、より広範なシステム内で参加者を「見える」ようにするのに役立ちます。各州は税金、徴兵、社会プログラムを管理するために ID カードを導入しています。 Web アプリケーションのユーザー テーブルにはユーザー ID があり、顧客の追跡、管理、サービスに使用されます。
全体的なビューとは、ユーザーまたは他のアクターに関する考えられるすべての情報を指します。大量のデータを一意の識別子に添付しようとすると、個人またはエンティティに関する豊富な情報セットが作成される可能性があります。これの追求は、Facebook や Google のユーザー データベース、インドの Aadhaar や中国の社会信用システム、Segment や LiveRamp などの顧客データ プラットフォームに見ることができます。
特定のコンテキストは、ビュー全体の多くのサブセットのいずれかとして表すことができます。数十億ドル規模の産業である KYC (本人確認) は、誰かが国家システム内で主張する唯一の検証可能な身元を確認することを目的としています。同様に、認証、不正行為対策、スパム対策、クレジット アルゴリズムは、全体的な観点から情報のサブセットに焦点を当てた特定のサービスです。
最初のレベルのタイトル
ID: 識別子に情報を付加します。
一意の識別子は必要ですが、それ自体では役に立ちません。これらはほとんどの場合、何らかの情報にジャンプするために使用されます。これには、州記録内の名前と住所、ファイル システム内の文書、アプリケーション データベース内のパスワード、ブロックチェーン上のトークン残高やトランザクション履歴などが考えられます。いずれの場合でも、識別子は関連情報を伝えるため便利です。
多くの状況では、識別子にリンクされた特定のコンテキストの取得または検証が必要になります。たとえば、Gitcoin には、Grants プラットフォームに対する外部からの攻撃を防ぐために「アイデンティティ システム」が必要です。実際には、人格の証拠 (KYC 検証、Twitter アカウント) を一意の識別子にマッピングする必要があります。個人の固有の可能性や不正行為の可能性についての情報が多ければ多いほど、プラットフォームはより効果的に機能します。
アイデンティティの全体的な見方は常に不完全です。私たちが空間内で「本当の自分」を完全に表現できないのと同じように、私たちのデジタル自己も完全に一貫したり包括的なものになることは決してありません。しかし、単一 (またはリンクされた一連の) 識別子を中心に収集されるデータが増えるほど、特定のコンテキストに対してより多くの情報を使用できるようになります。
共通点は次のとおりです。 ID システムは、情報を一意の識別子に確実に関連付ける機能を作成します。 ID システムの信頼性が高ければ高いほど、その有用性も高まります。
より信頼性の高い:利用可能、フォールトトレラント、改ざん防止機能
より柔軟に:より多くの種類の情報を扱えるようになります
より使いやすく:情報を分散させるのではなく統合して、より多くのコンテキストで使用可能
最初のレベルのタイトル
ウェブの 🔑 としてのデジタル アイデンティティ
最も単純化した言葉で言えば、Web はハードウェア、コード、データ上で実行されます。アクセスするすべての Web サイトにはコードで記述されたロジックとルールがあり、ほとんどすべての Web サイトはデータにエンコードされた情報で満たされています。このデータは、それが今日のニュースであれ、友人のツイートであれ、最新の電子メールの下書きであれ、サイトに到着したときに正確かつ確実に取得する必要があります。これは識別子を通じて行われます。
一意の識別子にデータが添付されていなければ役に立たないのと同じように、Web 上のデータは、適切なタイミングで取得できなければあまり役に立ちません。一意の識別子、およびそれらを中心に構築されたルーティング テーブルとロジックは、ネットワーク上に配置されるデータを整理するために使用されます。これらの識別子を作成しているのは誰ですか?彼らに関するデータを整理しているのは誰ですか?
画像の説明
アプリケーションデータベース上の従来のユーザーテーブル
この ID システムは上記の基準を満たしていますか?
信頼性のある:👍🏽は非常に信頼性がありますが、👎🏽👎🏽は監査可能ではなく、ハッキングやバグに対して非常に脆弱です
フレキシブル:👍🏽 少し混乱する可能性がありますが、データベースの種類を連鎖させてさまざまな情報を処理できます
利用可能:👎🏽👎🏽👎🏽 各アプリケーションには独自の識別子が必要で、情報 (およびその管理) は非常に断片化され、冗長で非効率的です
マクロの観点から見ると、これは Web にとって非常に悪い ID システムです。これは 1 つの ID システムではなく、多数の異なる ID システムであるためです。情報が断片化され、その価値と使用が各参加者に制限されます。 (これは、この記事の範囲を超えてユーザー データを蓄積したり悪用したりする恐ろしい動機にもなります)。
最初のレベルのタイトル
分散型アイデンティティ: Web3 が Web2 を超える方法
ブロックチェーンは分散台帳技術 (DLT) の一種であり、基本的には共有データベースです。共有データベースは、統合されたユーザー テーブルを配置し、各アプリケーションが独自の ID システムを作成するという時代遅れの必要性を取り除くのに適した場所のように思えます。
これは分散型アイデンティティの将来のビジョンであり、Web3 ビジョンの中核となる柱です。つまり、すべてのユーザーと構築者が自分のデータ、価値、関係、情報を管理します。このビジョンでは、各ユーザーが自分のデータの統一された検出ポイントとなり、アプリケーション全体での再利用と構成可能性が生まれます。これにより、サイロ化された集中型アプリケーションでは競合できない共有ネットワーク効果、相互運用性、複合エクスペリエンスが生み出されます。
オリジナル バージョンのビジョンでは、(1 つの DLT 上に) 統合されたユーザー レジストリと、すべてのアプリケーションがそのレジストリに情報を追加する標準的な方法を想定していました。ユーザーは、オープン環境でデータに必要な信頼を確立するために、すべてのデータに署名する際に使用する暗号化されたソブリン アドレス (または識別子) を制御します。すべてのアプリが同じレジストリ (ブロックチェーン) を使用し、標準形式 (NFT) を使用してデータを公開できるようにし、理論的にはアイデンティティの涅槃にいます。これは、視聴者やコミュニティから独立して、アプリにソーシャル グラフをもたらすネットワークであり、プラットフォームとシームレスに対話します。新しい製品やサービスはすべて相互運用可能であるため、利用可能になるとすぐにそれらの間を簡単に移行できます。
ただし、アドレスと NFT に依存する分散型アイデンティティのこのビジョンは、実際にはすぐに崩れてしまいます。 ID システムとして大規模にデータを管理およびルーティングするには、柔軟性が高すぎます。当社の基準では:
信頼性のある:👎🏽 今日のブロックチェーンは、希少な金融資産に関するコンセンサスを目的として設計されており、大量のデータに合わせて拡張することができず、オフチェーン (または部分的) 更新も処理できません。
フレキシブル:👍🏽👎🏽 ほとんどのオンチェーン台帳は新しいデータ構造と標準をサポートしていますが、コンセンサス システムの制約内にあります。これにより、システムのユースケースとアプリケーションが制限されます
アクセシビリティ:👎🏽 単一のレジストリはユーザーとアプリケーションを単一の DLT またはブロックチェーンに制限しますが、私たちは必然的に異なるチェーンとネットワークを使用します
私たちは、元の暗号化 ID システムの欠陥から学び、より信頼性の高い分散型 ID システムに何が必要かを理解できます。明らかに、単一のレジストリ (インデックス)、識別子標準、またはデータ構造標準は常に厳格すぎます。
最初のレベルのタイトル
Web3 がユーザー テーブルを処理する方法
データを管理するには、識別子に関する情報を簡単に保存、検出、ルーティングするためのプロトコルが必要です。 Web3 がその約束を果たすためには、このルーティング テーブルが a) アプリケーションやその他の境界によって分離されずに統合され、b) 主権があり、データの制御を各識別子に直接委任する必要があります。
これは単純な設計を示唆しています。各識別子は独自のデータを含むテーブルを維持します。これらのアイデンティティ中心のユーザー テーブルを組み合わせると、インターネットの分散ユーザー テーブルが形成されます。この分散ユーザー テーブルは実際のテーブルではなく、従来のユーザー テーブルの部分に対応するいくつかのコンポーネントによって生成される仮想テーブルです。
識別子:分散型識別子はアプリケーション データベースのエントリであってはなりませんが、一意であることが証明され、暗号的に制御されている必要があります。アクセシビリティには、分散型識別子の DID 標準と同様に、さまざまなネットワークにわたって複数形式の識別子を受け入れることが必要です。
データ構造:アプリケーション開発者が独自のデータ構造を定義する方法と同様に、分散データ層では、開発者がカスタム データ モデルを定義できるようにすると同時に、これらのモデルが再利用可能でパブリックに保存できるようにする必要があります。
索引:画像の説明
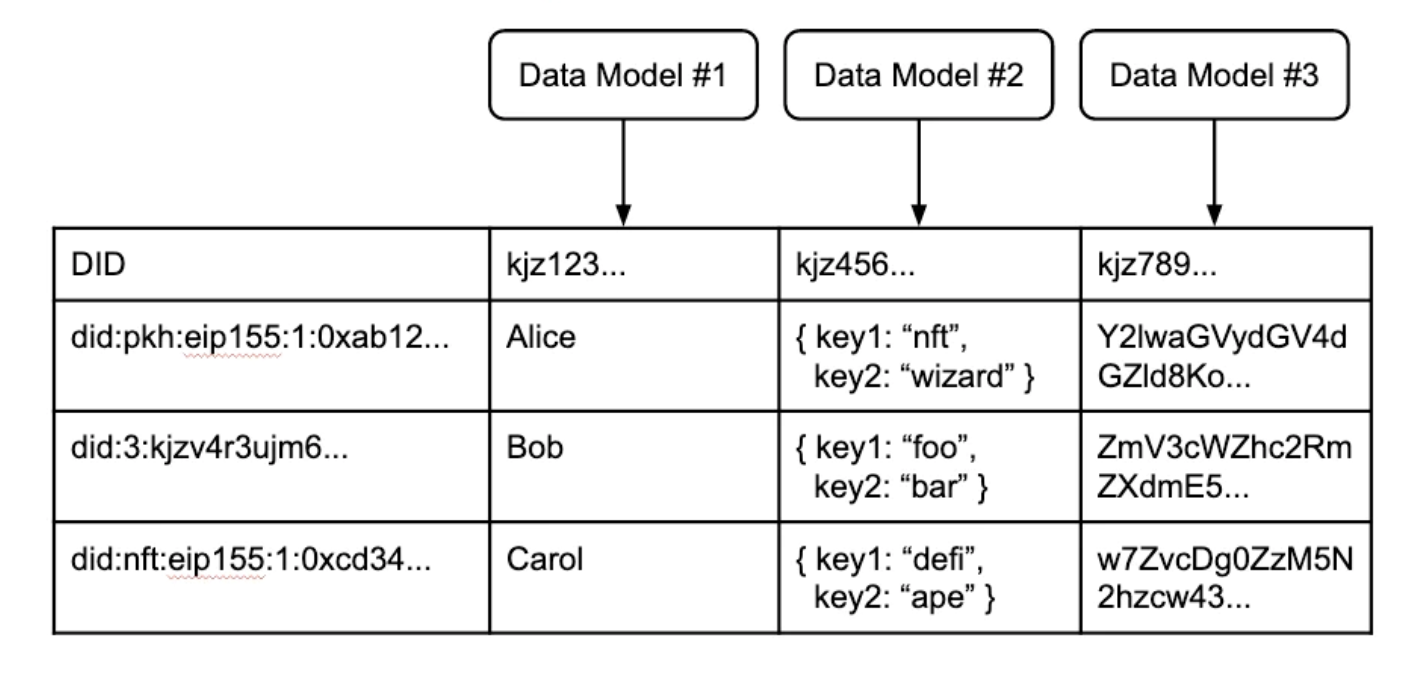
さまざまなネットワークからのさまざまな DID、開発者定義のデータ モデル、およびそれぞれに関連付けられたレコードを含む分散仮想ユーザー テーブル
最初のレベルのタイトル
分散ユーザーテーブルを使用した構築
DID、データ モデル、分散ユーザー テーブルに基づくこの ID システムは、どのように基準を満たしているのでしょうか?
信頼性のある:👍🏽👍🏽 パーティション化されたネットワークやローカル ネットワークなど、誰でも参加できるネットワークのパブリック コレクション上で実行されます。
フレキシブル:👍🏽👍🏽 開発者が定義できるあらゆるデータ構造で動作します
可用性:👍🏽👍🏽 あらゆるオープンネットワークと一意の識別子で動作します
このシステムには、柔軟性と信頼性の高い ID システムを実現する追加のプロパティも多数あります。含む:
まずはカナ:開始するためにアカウントを作成したり検証したりする必要はありません。ユーザー (または他のエンティティ) は、暗号化キーのペアを持ち歩き、それに関する情報の蓄積を開始するだけで済みます。
以下を生成できます:情報は時間の経過とともに蓄積され、新たな全体的なアイデンティティが形成されます
コンポーザブル:事前に定義された統合や移植性の標準を必要とせずに、コンテキスト全体で情報を発見して共有します
分離可能かつ選択的: 情報セットは、暗号化または難読化されるか、複数の識別子に分割されるか、またはコントローラーの設定に応じて分割される場合があります。
前述したように、「アイデンティティ システムが情報を一意の識別子に確実に関連付けることができる」場合は、管理と信頼できるデータへのルーティングのための最小限のプロトコルを確立し、他のすべてを創意工夫とアプリケーション開発者の多様性に任せるインターネット アイデンティティ システムが必要になります。
私たちは、特定のアプリケーション、レジストリ、ブロックチェーンなどのサイロ化されたシステムを回避し、データ型の柔軟性を最大限に高めたいと考えています。私たちは、豊富な形式のデータを使用してアプリケーションを構築し、それらのデータを適切な識別子に関連付け、アイデンティティと集合情報から最大限の有用性を引き出すことができる、使いやすいシステムを必要としています。
翻訳者注:
翻訳者注:
Web3 とメタバースの将来により、オフチェーンの世界とオンチェーン空間の境界があいまいになるため、アイデンティティ管理システムを構築するには、オフチェーンのアイデンティティとオンチェーンのデータの間のマッピング関係をどのように確立するかが重要になります。新しい社会システムを構築するためのデジタルライフスペース、やらなければならない宿題と足場の基礎。
分離された ID システムは、将来のシームレスな Dapp エクスペリエンスの障害になります。分散ユーザー テーブルの構築は、既存のアプリケーションの孤立を打破するのに役立ちます。DID システムの柔軟性、オープン性、信頼性のバランスを見つけるにはどうすればよいですか? 著者は次のように推奨しています。セラミックスやその他のインフラストラクチャについては、後で関連記事でプロジェクト分析を行います。
H.Forest Ventures は、各共有コンテンツの関連情報を十分に理解するよう最善を尽くしますが、この記事の内容についてご意見がありましたら、H.Forest Ventures チームまでご連絡ください。
Effective communication is everything.


