
In-depth Analysis of $VVV: The Undervalued Privacy AI Infrastructure and Growth Trajectory
- Core Thesis: Venice, as a privacy-first AI inference platform, is experiencing rapid growth through its unique anonymous proxy, TEE, E2EE multi-layer privacy architecture, and uncensored model access. The market significantly underestimates the scale of the privacy AI inference track. At its current valuation, the VVV token's market cap represents only 2.5 times the expected revenue for the next 12 months, indicating substantial room for value re-rating.
- Key Elements:
- Technical Uniqueness: Venice is the only platform integrating four privacy modes—Anonymous, Private, TEE, and E2EE—into a single consumer product, allowing users to choose on demand. No competitor can offer this complete combination.
- User Drivers: The core user base is not actively searching for privacy tools but is "pushed" toward Venice by content policies, compliance requirements, or privacy threats from mainstream AI platforms. This includes professionals in regulated industries, developers, and high-risk individuals.
- Growth Acceleration: The latest three-week data (April 26 to May 16) shows a 34% acceleration in new subscription ARR growth rate, with the weekly new subscription rate jumping from approximately $2 million to $2.6 million. API revenue growth is also synchronized, with total incremental revenue expected to be around $200 million over the next 12 months.
- Market Size: The global inference market is projected to reach $140-160 billion by 2027, with the privacy segment accounting for 5-15% (approximately $70-23 billion). Venice currently holds less than 0.3% market share, leaving massive room for growth.
- Valuation Comparison: The current market cap is approximately $660 million, corresponding to 11 times the current ARR of $60 million. Based on an expected ARR of $260 million over the next 12 months, the price-to-sales ratio compresses to 2.5 times, far below the peer OpenRouter's 26 times.
- Token Design Advantages: The dual-token model (VVV and DIEM) captures platform growth through staking, buyback-and-burn mechanisms, and permanent API credits. The inflation rate is rapidly declining, with net supply about to turn negative, enhancing the token's value capture capability.
Original Author: Yan Liberman
Original Compilation: TechFlow
TechFlow Introduction: Venice's subscription data over the past three weeks shows a new ARR growth rate surging to 34%. At its current market cap, the valuation is only 2.5 times the expected revenue for the next 12 months. This former crypto investor deconstructs Venice's entire chain, from its privacy architecture to its business model, arguing that the market significantly underestimates the true scale of the "private AI inference" track and Venice's irreplaceable combination advantage on this track, and is bullish on $VVV.

Venice is a privacy-first AI inference platform that allows users to use cutting-edge and open-source models without exposing their identity to the underlying model providers. I believe it is the most complete privacy solution currently on the AI market: anonymous proxying, open-source model routing, hardware-attested TEE inference, and end-to-end encrypted inference. These four functions are all integrated into a single consumer product, with the privacy mode selectable per request. No other player can offer all four simultaneously.
This business has been growing significantly. Discussions about Venice on Crypto Twitter generally underestimate the current revenue, recent growth, and future trajectory. Venice recently began publishing daily subscription data. The granular data over three weeks shows a clear acceleration in new subscription ARR:
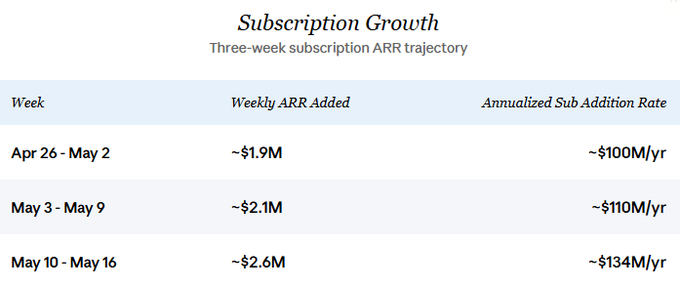
The sustained growth rate is the core assumption of this analysis. I also believe API revenue has recently been growing in tandem with subscription growth, an assumption detailed in the "Current State and Growth" section below. Anchoring at a conservative new subscription annualized rate of $100 million (roughly in line with late April's pace) and assuming API adds a similar amount, the total revenue increment over the next 12 months is approximately $200 million.
The recent acceleration trend suggests that if this pace holds, the actual figures could have significant upside.
This article will break down Venice's uniqueness point by point:
- Privacy Layers: A set of privacy architectures, far deeper than the standard "private AI chat" narrative.
- User Categories: Venice's user base is driven out of mainstream paths (by content policies, compliance, threat models, principles), not attracted by marketing.
- Market Size: A growing privacy segment of the inference market, often underestimated by frameworks focusing on consumer chat.
- Competitive Landscape: Venice packages privacy depth, uncensored model access, and crypto-native distribution in a combination currently unique among competitors.
- Token Design and VVV Valuation: How the VVV and DIEM mechanisms translate platform growth into token value, and how VVV's valuation multiples compare to private inference peers like OpenRouter, Fireworks, and Together AI.
Following the recent rally and pullback to $14, VVV's market cap is approximately $660 million, with a fully diluted valuation (FDV) of approximately $1.12 billion. The current ARR is around $60 million (estimated in the "Current State and Growth" section below), increasing at an annualized rate of about $200 million, and accelerating. Based on the current ARR, VVV's price-to-sales ratio is approximately 11x (FDV approximately 19x), lower than the privacy inference peer OpenRouter's 26x. Based on a forward 12-month ARR of about $260 million ($60 million current base plus $200 million annualized new additions), VVV's price-to-sales ratio is approximately 2.5x (FDV approximately 4.3x).
Current State and Growth
Venice recently began publishing daily new subscription data. Combined with periodic public milestones for registered users, these two data streams allow me to construct an estimate of the current ARR and future trajectory.
To estimate the current ARR, I start with total registrations. Based on the cadence of public announcements, total registrations have been growing at about 300,000 per month. The most recently confirmed milestone is approximately 3 million registered users as of May 16, 2026, up from about 2 million on February 1st, consistent with the rate of 300,000 per month. Assuming a lifetime paid conversion rate of approximately 5% (which may be conservative given daily data suggests faster conversion for new registrants), this implies about 150,000 active paid subscribers by mid-May. Until mid-to-late April, only the basic Pro tier at $18 per month existed; the introduction of Pro+ ($68/month) and Max ($200/month) tiers has started to change the mix, but the vast majority of paid users remain on the $18 plan. The weighted ARPPU is around $18-$19 per month, implying a current subscription MRR of approximately $2.8 million, or about $33 million subscription ARR. This is just the subscription portion; API revenue is layered on later in this section to arrive at the full current ARR estimate.
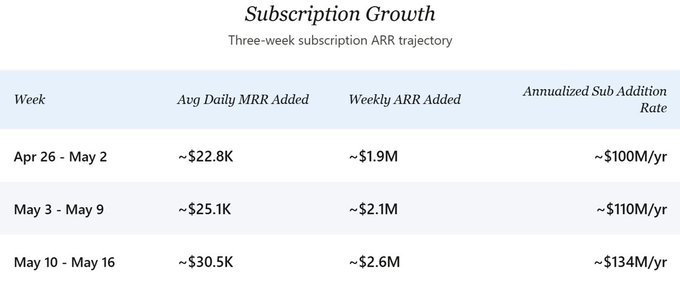
Looking at the future trajectory, the growth rate of new subscription ARR has been accelerating. At the pace seen in late April, the company was adding about $2 million in subscription ARR per week. By the most recent week (May 10-16), this rate had jumped to about $2.6 million per week, annualizing to a subscription new addition rate of $134 million. In the core scenario of this analysis, I anchor at a conservative $100 million annualized figure to avoid overstating the recent acceleration. Net growth after churn would be slightly lower, but at the current scale, this difference is directionally insignificant. The gross addition rate forms the core of the forward-looking analysis in this article.
The three weeks of granular data (April 26 - May 16) show a clear ramp-up:
From Week 1 to Week 3, the daily MRR addition grew by approximately 34%. Assuming API revenue tracks new subscription MRR at a 1:1 ratio (explained below), the implied total annualized new addition rate has jumped from about $200 million to about $268 million. Two factors seem to be driving this inflection point: the launch of Pro+ and Max tiers gave high-willingness-to-pay users options they didn't have before, lifting the weighted ARPPU; and paid conversion rates appear to have accelerated following the tier expansion.
API revenue is harder to measure as there is no direct disclosure. My base assumption is that recently added API operating revenue has a ratio of approximately 1:1 with new subscription MRR, while the historical ratio was lower. Consequently, the current API ARR base, while significant, is slightly lower than subscription ARR but is converging towards parity over time.
The rationale for the roughly 50/50 split starts with peer benchmarks. Among large closed-source model platforms, ChatGPT sees about 25% of revenue from API and 75% from subscriptions, due to its massive consumer subscription base making the API share smaller. Anthropic sees about 80% from API and 20% from subscriptions, as its user base leans heavily towards developers and enterprises. Venice sits structurally between these two: its privacy positioning doesn't attract the average consumer like ChatGPT, but its paid user base is broader than Anthropic's heavily enterprise-weighted mix. A 50/50 split lands in the middle of this range.
This range is reinforced by two Venice-specific pieces of evidence.
First, Venice's API has already established significant developer distribution. OpenRouter routes Venice models, Fleek defaults all its hosted agents to Venice inference, and integrations with Cursor, Brave Leo (via BYOM), and VSCode community extensions all support Venice. These integrations have accumulated over the past year, supporting the thesis that the API is a real and material business with scaled production traffic.
Second, the recent ramp in token throughput far exceeds what subscription growth alone could explain. Daily token throughput grew from 20 billion in early February to over 60 billion in early May, roughly 3x in three months. Over the same window, the paid subscriber base grew by about 50% (from ~100k paid subs to ~150k). The mid-April expansion of Pro+/Max tiers only shifted a small portion of new registrants to higher ARPPU tiers, and even with generous assumptions about per-user token consumption on these tiers, it cannot fill the gap. The majority of the token ramp seems to come from usage-based API workloads: agent deployments, integrated partners scaling production traffic, and similar high-volume use cases.
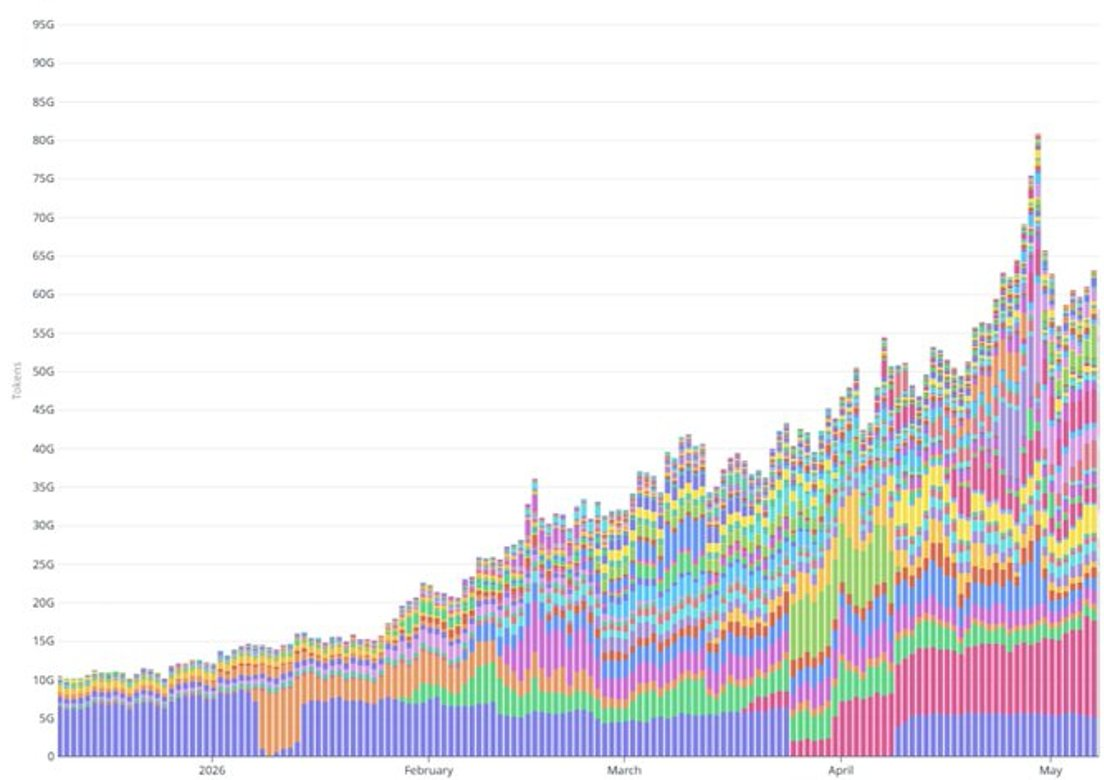
Estimating current API ARR is harder than subscription ARR because the 1:1 ratio appears to be a recent phenomenon; before mid-April, the API share was likely smaller. Using a midpoint assumption that API historically averaged about 70-80% of subscriptions, only recently reaching 1:1, the current API ARR is approximately $25-$30 million. Current total ARR estimate: approximately $55-$65 million, with a midpoint of about $60 million.
A brief caveat on the API portion: it is based on annualizing current usage-based operating revenue, not a recurring subscription commitment. Therefore, it has higher inherent volatility than the subscription portion. A heavy API customer reducing usage could lead to a significant drop in API operating revenue without a similar churn event in the subscription base.
Cross-validation with year-to-date revenue: based on token throughput ramping from 20 billion per day in early February to over 60 billion per day in early May, Venice has generated at least $30 million in cumulative revenue in 2026. This figure is consistent with an current ARR in the $55-$65 million range, a base that is rapidly growing at a $200 million annualized new addition rate.
Importantly, the annualized new addition rate is not the same as revenue earned over the next 12 months. New ARR adds linearly over the year, so a $200 million annualized new addition rate, if sustained through 2026, translates into roughly $100 million in new revenue earned over the year, plus another roughly $60 million contributed by the current ARR base. Total revenue earned over the next 12 months should fall in the $150-$200 million range, with ARR at the end of that 12-month window around $260 million (before churn) ($60 million current + $200 million new ARR).
Looking backwards is mainly a footnote. Venice's current ARR annualized new addition rate is around $200 million. The real question is whether today's rate is the floor or the starting point. The important variables: whether subscription growth holds, whether API usage continues to expand faster than subscriptions, how much churn emerges as cohorts mature, and whether the addressable market can sustain growth at this pace.
The market size question becomes easier to answer after understanding what Venice actually does. The clearest foundation is a privacy ladder for LLM interactions, with each rung representing a different set of privacy assumptions. Venice's modes embed into specific rungs.
Privacy Layers
The ladder below ranks cloud-based AI usage along a narrow but important axis: who can associate plaintext prompts with a user's identity. It does not solve all privacy problems. Device compromise, payment trails, account metadata, subpoena risk, and endpoint security remain separate issues. But it clarifies what actually changes when a user moves from a default chatbot to Venice's higher privacy modes. The level numbers (0-7) are mine, used to place Venice within the broader landscape. Venice's own taxonomy only uses four named modes: Anonymous, Private, TEE, and E2EE, mapping to the Levels 3, 4, 6, and 7 below.
The strongest privacy option isn't on the ladder at all. Running an open-source model on hardware you own, with no cloud involvement, beats everything downstream. Running GLM 5.1 or Qwen 3.6 on a powerful Mac or workstation, with no network calls, no third party involved. Nothing beats "the prompt never leaves my machine," provided the machine itself is reasonably hardened. But this isn't the path most people will take. Hardware is expensive. Open-source models that can run locally still lag behind the frontier of closed-source labs on the hardest tasks. You lose integrations and 24/7 cloud uptime, and you assume responsibility for maintaining the entire stack. Setting local deployment aside, the ladder below covers the realistic options for cloud-based inference.
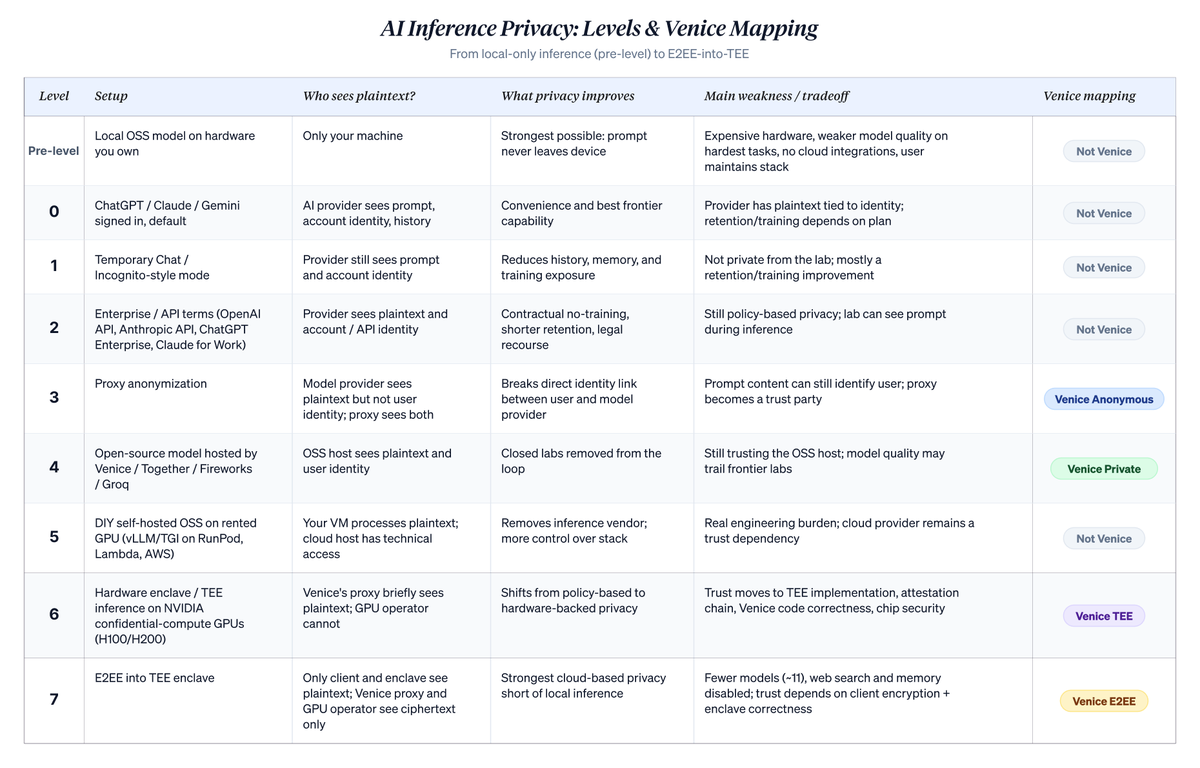
A detailed, level-by-level breakdown follows, including a metaphor that underpins each layer:
Level 0: "ChatGPT, Claude, or Gemini, logged in, default state." Your prompts are sent to the lab associated with your account. They know who you are and what you asked. On consumer tiers, conversations may be used to improve future models unless you opt out, and are stored in your server-side chat history. There are real commitments (no data sale, retention windows, deletion controls), but you are identified, retained, and potentially part of training flows on consumer tiers. Most people are on this level. Architecturally, any hosted API consumption service applies the same posture, regardless of where the provider is located. Hosted offerings from China-based providers (DeepSeek hosted version, GLM/Zhipu, MiniMax, Qwen direct access) are at the same architectural level: the provider sees plaintext, identity is linked to an account, and retention/training policies vary. Users often choose these services for price, as they tend to be significantly cheaper than Anthropic or OpenAI. The jurisdiction governing your data depends on the specific provider, the endpoint you access, your location, and the contract. Do not assume you have US or EU-style data handling just because the model is cheap.
Metaphor: You go directly to a big company (the AI provider) to see a consultant (the model). They read your memo, answer your questions, and file a copy under your name. They might use anonymized versions of past memos to train other consultants or improve their service.
Level 1: "ChatGPT Temporary Chat / Claude Incognito Chat." Same provider, same identity, same plaintext on their servers. The conversation doesn't appear in your history, the model doesn't continue it, and it's excluded from training according to policy. Useful for sensitive one-off conversations you don't want tied to your account. The provider still knows it's you, still sees the full prompt; they just can't retain it long-term or use it for training. Hidden from your own history, but not from the lab.
Metaphor: Same direct interaction with the consultant (model), but you ask them to keep this particular memo out of your main file. They read it, answer, and put it in a temporary drawer (incognito chat) that gets cleared out after some time. They still know it's you and saw what you sent.
Level 2: "Anthropic API, Claude for Work, ChatGPT Enterprise, OpenAI API." Moving from consumer chat to commercial terms. Contracts exclude your data from training. Retention periods are short, often ~30 days for security review, sometimes zero at enterprise tiers. You have legal recourse if policies are violated. The lab still sees plaintext during inference and associates traffic with your API key, but the safeguards are stronger and contractually enforceable. This is the privacy posture most companies actually use, a genuine upgrade from consumer chat. But it is still policy-based, not architecture-based. The reason to keep climbing is real: future policy changes, compelled disclosure, data breaches, or the lab itself turning bad.
Metaphor: You sign a contract with a consulting firm (enterprise/API terms) that includes clauses about no copying, no cross-client use, short retention periods, and legal recourse if breached. Same direct interaction with the consultant (model) who reads your memo and knows it's from you, just with stricter rules about what happens to the memo afterward.
Level 3: "Venice Anonymous Mode." A proxy sits between you and the lab, stripping your identity before forwarding the request. The lab sees the prompt content in plaintext but doesn't know it's you. They see "a request from Venice." For prompts where the content doesn't identify you, this breaks the link between your query and your name, making long-term profiling by the lab much harder. For prompts where the content *does* identify you (your company, your deal, your name), this is largely cosmetic. The content exposes you anyway. You also add Venice


