
DeepSeek V4 Goes Live: Zhipu & MiniMax Plummet, Nvidia Panics
- Core Thesis: The release of the DeepSeek V4 model has upended the valuation logic of the AI capital market, driving capital flows from closed-source large model companies to domestic computing infrastructure, marking the arrival of a dual inflection point for both open-source and domestic chip ecosystems.
- Key Factors:
- Model Parameters: Base MoE model with 1T parameters, Flash version with 285B, Pro version with 1.6T, all under the Apache 2.0 open-source license.
- Market Divergence: A-share computing chain stocks (Cambricon, Hygon, etc.) surged, Hong Kong-listed closed-source model companies (Zhipu, MiniMax) faced short selling, while Nvidia saw a moderate consolidation.
- Open-Source Advantage: Among 11 new models in the past 30 days, V4 is the first flagship open-source model to comprehensively pressure closed-source alternatives across performance, pricing, and openness.
- Domestic Computing Ecosystem: V4 achieved Day 0 full-stack adaptation for Cambricon Siyuan 590 and Huawei Ascend 950PR, with deployment code open-sourced, breaking the reliance on CUDA.
- Performance Data: Inference latency for V4 on Ascend super nodes is 35% lower than H100 clusters; Cambricon chips offer FP8 computing power comparable to H100 at a lower price.
- Ecosystem Inflection Point: vLLM has integrated non-Nvidia domestic GPU backends, decoupling China's AI inference demand from North America, with domestic alternatives entering a priceable production phase.
DeepSeek V4 has finally been released, a moment nearly five months in the making. It features a 1T-parameter MoE main model plus a 285B-parameter Flash version, with a full 1.6T Pro version following closely behind. Everything is fully open-sourced on GitHub under the Apache 2.0 license, with weights and deployment code released simultaneously.
As soon as the model was out, the capital markets responded in three distinct yet interconnected ways.
Different Reactions from the Capital Markets
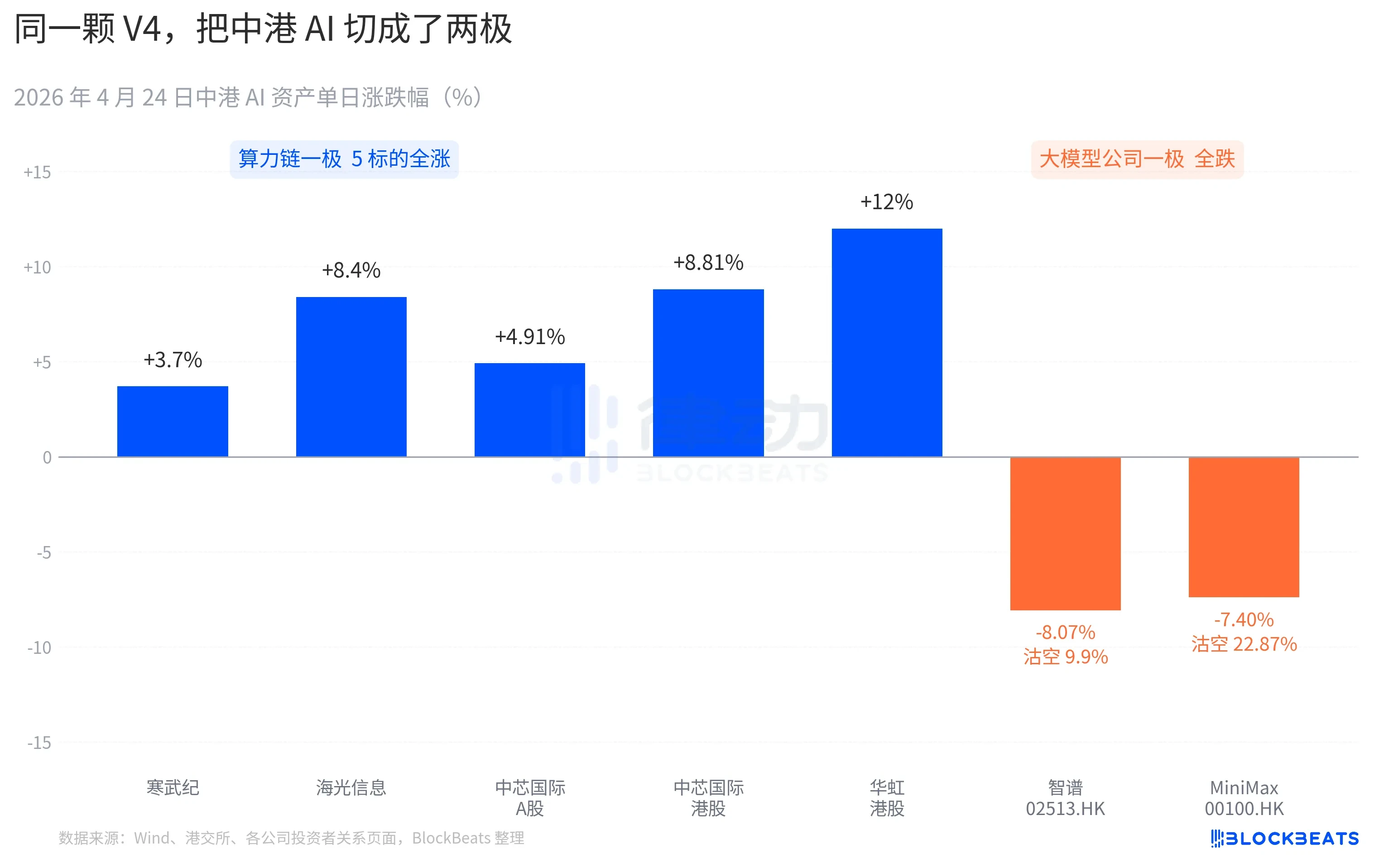
On the A-share computing power chain, almost all stocks saw gains. Cambricon recorded 11 consecutive days of gains, rising 3.7% in a single day and pushing its monthly cumulative increase past 60%. Haiguang Information hit the daily 10% limit intraday, closing up 8.4%. SMIC's A-shares rose 4.91%, while its Hong Kong shares gained 8.81%. Hua Hong Semiconductor's Hong Kong shares peaked at +18% intraday, closing up 12%. The Kechuang Chip Guotai ETF attracted 2.4 billion yuan in a single day, reaching an all-time high in scale.
On the Hong Kong-listed large model company front, the picture was different. Zhipu (02513.HK) fell 8.07% with a short-selling ratio of 9.9%. MiniMax (00100.HK) dropped 7.40%, and its short-selling ratio surged to 22.87% — the highest single-day shorting data for AI stocks in Hong Kong over the past three months. Both companies are representative of the wave of AI listings in Hong Kong in the second half of 2025, with their IPO prospectuses highlighting the same core competency: "self-developed foundational large model."
The reaction on the other side of the Pacific was equally specific. Nvidia opened down 1.8% last night, briefly falling to -2.6% during trading, before closing flat. Bloomberg's market commentary compared this consolidation to the V3 "DeepSeek moment" on January 27. The difference is that the January event was a panic sell-off, evaporating $600 billion in market cap in a single day. This time, it felt more like a repricing — moderate in magnitude but clear in direction. A new phrase appeared in buy-side research notes: "China's AI inference demand is beginning to decouple from North America's AI inference demand."
Stack these three market segments together, and you get the first verdict written by the market within 24 hours of V4's release. As open-source wins out, money is starting to pick sides. What can be priced is no longer just the model itself, but which chip it runs on and which industry chain it sits in.
30 Days, 11 New Models: V4 Adds Fuel to the Open-Source Camp
The timing of V4's release is part of the reason for the amplified reaction.
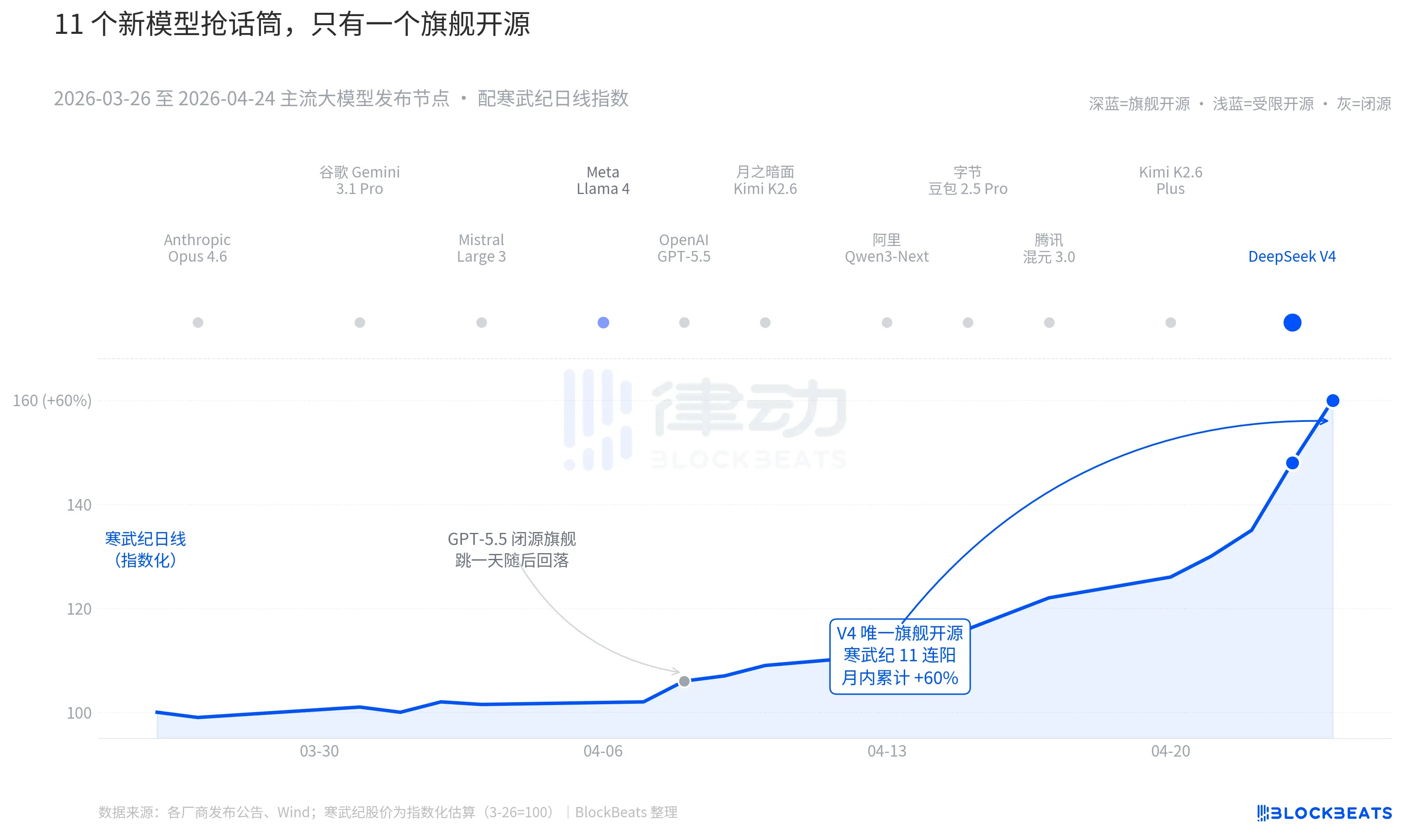
Zooming out to the past 30 days — between March 26 and April 24 — at least 11 influential large models were released or saw major updates globally, covering almost all major players: Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot AI Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, and finally, DeepSeek V4, released early on April 23.
On average, that's a new model every 2.7 days — a pace too fast for even fund managers to read through all the release notes. But looking at the K-line charts for Chinese and Hong Kong AI assets over these 30 days, only one name left a lasting mark on the board. GPT-5.5 on April 8 drove Nvidia up 4.2% in a single day, which peaked and then faded. Then came DeepSeek V4 on April 23-24, triggering consecutive surges in the Chinese and Hong Kong computing power chains.
The difference isn't in the model capabilities themselves. The gap between these 11 models on the LMArena leaderboard, in most cases, is no more than 50 points — all within a narrow band of "similar tier." The difference lies in two overlapping factors.
The first is open-source. Among the first 10 models, only Llama 4 is open-source, but its weights come with a long list of commercial use restrictions. The developer community in the US and Europe reacted tepidly; on OpenRouter, it fell out of the top 10 by the third day. V4, on the other hand, uses the Apache 2.0 license — no barriers to access weights, no restrictions on commercial use, and inference code released simultaneously. It's the first flagship open-source model in the past six months to put pressure on the closed-source camp across three dimensions: performance, price, and openness.
The second is timing. Against the backdrop of consecutive heavy hitters from the closed-source camp, the open-source narrative has been under repeated pressure. Opus 4.6 pushed SWE-Bench for coding tasks to new highs; GPT-5.5 set a pricing anchor for inference at $1.25 per million tokens. The debate over whether open-source can catch up to closed-source has been ongoing in Silicon Valley for two years. V4, as an open-source flagship with an estimated 90 million monthly active users, has pressed the pause button on this debate.
According to a major domestic fund manager during a roadshow, "Before V4, we applied a discount in our valuation of open-source large models. After V4, that discount is starting to reverse."
DeepSeek Rewrites the Pricing Table for the Computing Power Supply Chain
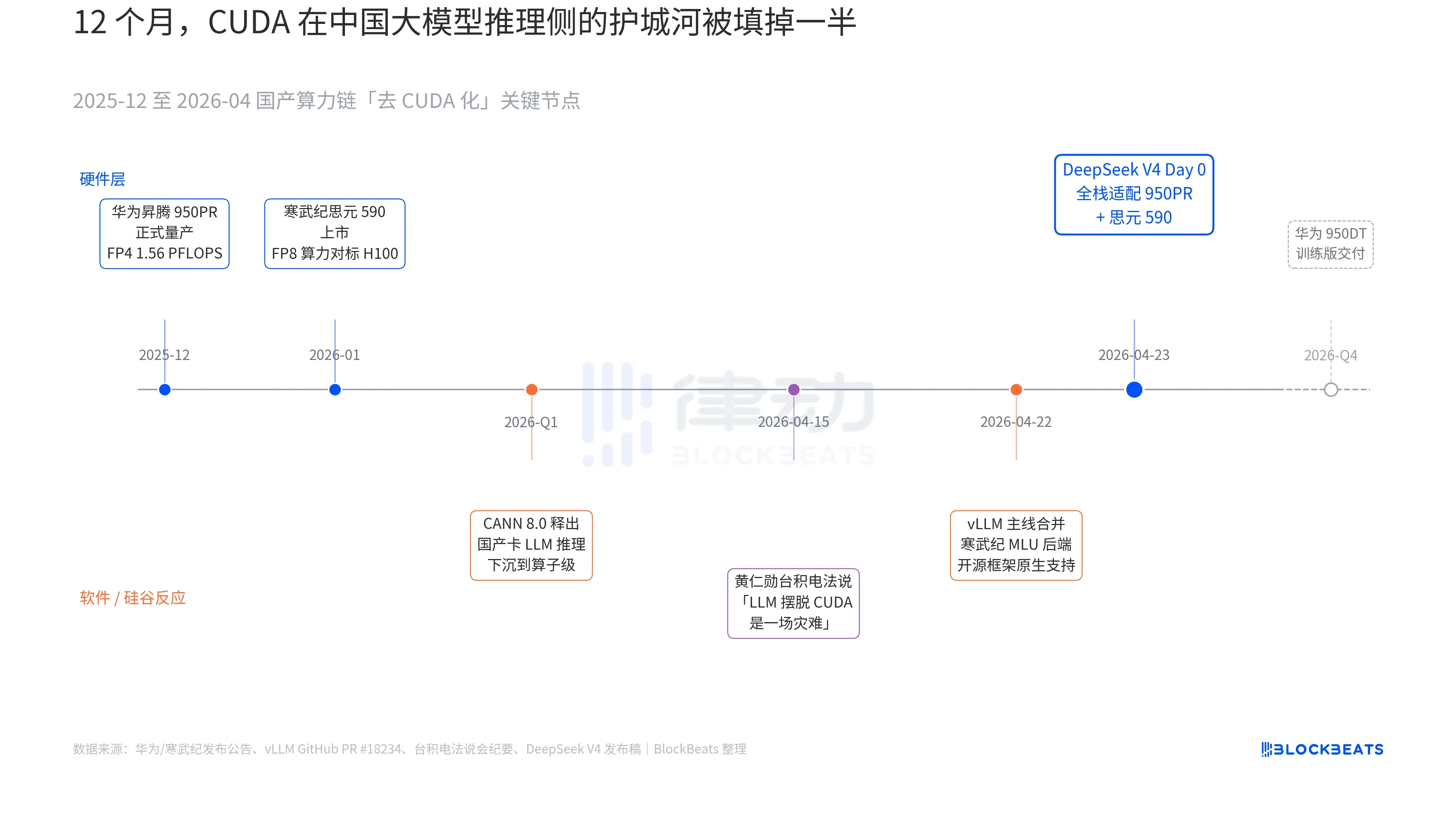
In V4's release announcement, there was a line that had never before appeared in any official documentation of a Chinese large model: "Day 0 full-stack adaptation for Cambricon Siyuan 590 and Huawei Ascend 950PR, with deployment code open-sourced simultaneously." To understand the weight of this line, you need to connect three parallel threads that have been unfolding over the past 12 months: hardware, software, and the reaction from Silicon Valley.
The first thread is on the chip side. Huawei Ascend 950PR officially entered mass production in December 2025, offering FP4 computing power of 1.56 PFLOPS and 112GB of HBM — the first time a domestic AI chip rivals Nvidia's B-series on hard specs. In inference tasks for a 1T-parameter MoE model like V4, its single-card throughput is 2.87 times higher than that of the H20. The accompanying CANN 8.0 software stack pushes LLM inference framework optimization down to the operator level. DeepSeek's published benchmarks show that V4's end-to-end inference latency on an Ascend supernode (8x 950PR) is 35% lower than on a comparable H100 cluster. The data for Cambricon Siyuan 590 is even more aggressive: single-chip FP8 computing power comparable to the H100, but at less than half the price.
The second thread is on the software side. The vLLM mainline merged the Cambricon MLU backend PR on April 22, marking the first time an open-source inference framework natively supports non-Nvidia domestic GPUs. Haiguang Information's DCU takes a different path via the ROCm ecosystem but can fully run V4's MoE routing layer. This means V4 deployment is no longer "only works on a specific domestic card" but rather "can choose among multiple domestic cards." The dependency on a single-point supplier within the ecosystem has been broken — a key inflection point for production deployment.
The third thread comes from Silicon Valley. On April 15, during TSMC's earnings call, Jensen Huang was pressed by analysts on the progress of domestic computing power in China. His response was blunt and specific: "If they can truly get LLMs off of CUDA, it would be a disaster for us." Nine days later, DeepSeek provided the answer with a single line in its Day 0 announcement.
The term "domestic substitution" has been overused to the point of meaninglessness over the past three years. But after the morning of April 24, this concept finally had concrete data that the capital market could price: single-card throughput, end-to-end inference latency, inference costs, and commercially viable deployment code. Silently and steadily, it pushed this protracted war of words to the threshold of production deployment.
The logic behind Cambricon's 11 consecutive days of gains is embedded here. It is no longer just a "domestic GPU concept stock." It is now a "DeepSeek V4 inference infrastructure supplier." The same logic can explain Hua Hong Semiconductor's 12% gain in Hong Kong — it manufactures the 7nm equivalent process for the 950PR. Every V4 token running on a domestic Ascend chip represents production capacity that would have otherwise flowed to Nvidia and TSMC, being partially captured in the Pearl River Delta.
And the next step is already mapped out. On Huawei's roadmap, the 950DT (training version) is scheduled for delivery in Q4 2026, with the target being "full-stack training of V5 or an equivalent model on a 10,000-card cluster." If this path succeeds, CUDA's moat on the training side of large models in China will be downgraded from "necessary" to "optional."


