





Motivation and Challenges
The current field of artificial intelligence is dominated by centralized, closed-source, and oligopolistic tech giants. A handful of companies control the highest-performing models, in large part due to the power of extreme centralization that facilitates model development and inference.
Creating a machine learning model typically involves three main stages: pre-training, fine-tuning, and inference. These stages are critical to developing a strong and accurate model that generalizes well to new, unseen data.
pre-training phase
In the pre-training phase, the model is trained on a large, general-purpose data set. This dataset is not related to the task that the final model will perform, but is intended to help the model learn various features and patterns. For example, in the case of language models, this might involve learning language structure, grammar, and extensive vocabulary from large corpora of text. The goal here is to develop a model that has a good understanding of the basic structure of the data that will be processed, whether it is text, images, or other forms of data.
There is some concentration during the pre-training phase:
Data collection and sorting - The key to the pre-training phase is to assemble large data sets from a variety of sources, including literature, digital articles, and professional databases. Industry giants like Google have historically leveraged user-generated content to build unparalleled and efficient models, a practice that continues today, with entities like Microsoft and OpenAI gaining access to top-tier data through exclusive alliances and proprietary platforms. The concentration of these capabilities within a few companies has led to significant concentration in the AI industry.
Additionally, relying on proprietary datasets for model training introduces important ethical considerations and the risk of perpetuating bias. AI algorithms inherently derive operating paradigms from underlying data and thus create inherent biases that can be easily embedded and replicated. This situation highlights the need for careful review and ethical oversight during development to ensure that models reflect fair and intentional patterns and associations.
Resource Requirements - It has been established that model performance increases logarithmically with the amount of training data, indicating that models that benefit from the widest range of GPU compute cycles generally perform best. This dynamic introduces an important centralizing effect in the pre-training phase, driven by the economies of scale and productivity advantages enjoyed by major tech and data companies. This trend is evident in the dominance of industry giants OpenAI, Google, Amazon, Microsoft, and Meta. These companies own and operate the majority of the worlds data centers and have access to NVIDIAs latest and most advanced hardware.
fine-tuning phase
After the model is pre-trained, fine-tuning is performed. At this stage, the model is further trained on a smaller, task-specific dataset. The purpose is to adjust the weights and features learned by the model during pre-training to make it more suitable for the current specific task. This might involve teaching a language model to understand medical terminology, or training an image recognition model to distinguish between different species of birds.
The fine-tuning phase enables the model to focus and improve performance on tasks of interest to the end user. Again, there are some concentrated efforts in the fine-tuning phase, the most important of which are closed-source models and verifiability.
During the fine-tuning phase, the parameters of the model are refined and set, shaping its functionality and performance. The prevailing trend is toward proprietary AI models, such as OpenAI’s GPT family and Google’s Gemini, which means the inner workings and parameters of these models are not made public. Therefore, when users request inference, they cannot verify that the response actually comes from the model they think they are interacting with.
This lack of transparency can have detrimental effects on users, especially where trust and verifiability are critical. For example, in the medical field, artificial intelligence models may help diagnose diseases or recommend treatments, but doctors cannot confirm the source and accuracy of model inferences, which may lead to mistrust or even misdiagnosis. If medical professionals cannot be certain that AI recommendations are based on the most reliable and up-to-date models, the consequences can directly impact patient care and outcomes, underscoring the importance of transparency and accountability in AI deployment.
reasoning stage
The inference stage is the stage where the model is actually applied. At this point, the model has been trained and fine-tuned, and is ready to make predictions on new data. In the case of an AI model, this might mean answering questions, translating languages, or providing recommendations. This stage is the stage where the trained model is applied to actual problems, and is usually the stage where the value of the model is realized.
During the inference phase, factors leading to centralization are:
access:Centralized front-ends for AI model access can come with risks that may prevent users from accessing APIs or inference. When a small number of entities control these portals, they can deny access to important AI services for a variety of reasons at their discretion, including policy changes or disputes. This centralization highlights the need for a decentralized approach to ensure broader and more resilient access to AI technologies, mitigating the risk of censorship and unequal access.
Resource requirements:The cost of performing inference in artificial intelligence, especially for tasks that require large amounts of computing resources, has become a concentrated force within the technology industry. High inference costs mean that only large companies with significant financial resources can afford to run advanced AI models at scale. This financial barrier limits the full potential of smaller entities or individual developers from leveraging cutting-edge AI technology.
As a result, the situation is increasingly dominated by a few powerful players, stifling competition and innovation. This centralization not only affects the diversity of AI development, it also limits access to AI’s benefits to a small group of well-funded organizations, creating a significant imbalance in the technology ecosystem.
There are some recurring themes emerging in the centralized AI space, particularly regarding the evolution of Web2 companies. These entities, originally established as open networks, often turn their focus to maximizing shareholder value. This shift often leads them to shut down their networks and adjust their algorithms to block external links, often against the best interests of their users.
This misalignment of corporate incentives and user needs often occurs when an organization matures and receives external funding. The fact that were already seeing this phenomenon with OpenAI, which started out as a non-profit aiming to democratize the use of artificial intelligence, illustrates how a shift in focus in the industry can manifest itself. Its easy to blame these individual companies, but we believe it reflects systemic problems caused by concentrated forces within the tech industry that often lead to misalignment between corporate incentives and broad user needs.
A possible future: Artificial Intelligence and Web3
The crypto world provides a foundation for artificial intelligence, making the exchange of information and value seamless, open and secure. Blockchain technology provides a clear and traceable system for managing transactions and recording data. At the intersection of cryptocurrency and artificial intelligence, many opportunities arise where the two fields can enhance each other and benefit from the capabilities of the other.
motivational alignment
Distributed computing is valuable during the pre-training and fine-tuning phases of model development. Base models often require a large number of GPU compute cycles, and these processes are typically run in centralized data centers. Decentralized Physical Infrastructure Networks (DePINs) can provide decentralized, permissionless access to computing. Through the economic incentives of cryptocurrency, software can autonomously compensate for hardware usage without the need for a central governance entity. This enables users of the network to control the network, adjust incentives, and ensure that data and model providers are adequately compensated.
Verifiability
Current AI infrastructure is heavily skewed towards proprietary models, and users need to trust the inference provider to execute queries through specified models and produce legitimate output. In this context, cryptographic proof systems have emerged as a key technology, providing a mechanism to verify model outputs on the blockchain. The process enables users to submit queries, which are processed by an inference provider using an agreed-upon model, subsequently producing an output with a cryptographic proof. This proof serves as verifiable evidence that the query was indeed processed by the specified model.
The main goal of these initiatives is to offload heavy computational tasks to off-chain environments while ensuring that results can be verified on-chain. This approach not only reduces the computational burden on the blockchain, but also introduces a layer of transparency and trustworthiness by providing immutable proof of the accuracy and completeness of off-chain calculations.
Incorporating these cryptographic proofs into the AI model verification process solves several key issues associated with closed-source AI systems. It mitigates the risk of opaque or unverified computation, enhances the integrity of the computation process, and promotes trust-based relationships between users and inference providers. Furthermore, this approach aligns with broader trends towards decentralized and transparent systems, echoing the fundamental principles of blockchain technology.
composability
One of the main advantages of decentralized finance and blockchain networks is the composability they enable. Composability allows for widespread use of “monetary LEGO” in DeFi, i.e. combining different protocols and outputs to create new applications. While this modularity introduces new forms of risk into the system, it also simplifies application development for developers, increases innovation and development speed, and provides a simpler user experience and convenience.
Similar to how cryptocurrencies provide composability for financial products, it will also create composability for AI networks and applications by serving as a permissionless and trustless layer on which AI modules can be built and work independently , while remaining interconnected with other modules to form a network that can provide various services. Through blockchain network effects and cryptocurrencies, decentralized artificial intelligence projects and applications can be connected to each other to complete the overall architecture of artificial intelligence.
For example, you can use Akash or Filecoin preprocessed data to train a model using Marlin, Gensyn, or Together. After fine-tuning, these trained models can respond to user queries (inference) through Bittensor. Although it seems more complex, end users only need to interact with one front end, while developers and applications benefit from building on top of different stacks and applications.
Another important aspect of compositionality enabled by decentralized networks is data compositionality. As users become increasingly interested in owning the data they generate and demand the ability to carry data between different AI protocols, they will demand that their data is not restricted to a closed environment. Decentralized and open source AI applications make data portable.
Data protection
Decentralized computing, combined with external data and privacy solutions, provides users with more autonomy over their data, making it a more attractive option than their centralized counterparts. In particular, methods like fully homomorphic encryption (FHE) allow computations to be performed on encrypted data without first decrypting the data.
With FHE, machine learning models can be trained using encrypted datasets, keeping data private and secure throughout the training process. This provides an end-to-end security solution with strong cryptographic guarantees, allowing privacy-preserving model training in edge networks and allowing the development of AI systems that protect user privacy and leverage advanced AI capabilities.
The role of FHE extends to running large language models securely on encrypted data in cloud environments. This not only protects users’ privacy and sensitive information, but also enhances the ability to run models on applications with inherent privacy. With the integration of artificial intelligence in various fields, especially sensitive areas such as finance, the need for technologies like fully homomorphic encryption that can prevent potential information leakage has become critical.
Automatic upgrade capability
AI can be used to maintain, update, and automatically upgrade smart contracts based on a range of changes and conditions. For example, AI could be used on the protocol side to adjust risk parameters based on changes in risk and other market conditions. A common example is the currency market. Money markets currently rely on external organizations or DAO decisions to adjust the risk parameters of lending assets. AI agents can simplify updating and upgrading specific parameters, which will be a significant improvement compared to humans and DAO organizations, which can be slow and inefficient.
Challenges of decentralized artificial intelligence
Decentralized AI faces its own set of challenges, particularly in balancing the open source nature of cryptography with the security concerns of AI and the computational needs of AI. In cryptography, open source is critical to ensuring security, but in the field of artificial intelligence, exposing a model or its training data increases its risk of adversarial machine learning attacks. Developing applications using these two technologies presents significant challenges. In addition, the application of artificial intelligence in blockchain, such as artificial intelligence-based arbitrage bots, prediction markets and decision-making mechanisms, raises issues of fairness and manipulation. AI has the potential to improve efficiency and decision-making in these areas, but there is a risk that AI will not fully grasp the nuances of human-driven market dynamics, leading to unintended consequences.
Another area of concern is the use of artificial intelligence as an interface for cryptographic applications. While AI can help users navigate the complex world of cryptocurrency, it also carries risks, such as being susceptible to adversarial inputs or causing users to overly rely on AI to make important decisions. Additionally, there are risks associated with integrating artificial intelligence into the rules of blockchain applications, such as DAOs or smart contracts. Adversarial machine learning can exploit weaknesses in artificial intelligence models, leading to manipulated or incorrect results. Ensuring that AI models are accurate, user-friendly, and immune to manipulation is a significant challenge.
Furthermore, combining artificial intelligence with zero-knowledge proofs or multi-party computations is not only computationally intensive, but also faces obstacles such as high computational costs, memory limitations, and model complexity. The tools and infrastructure for zero-knowledge machine learning (zkML) are currently still underdeveloped, and there is a shortage of skilled developers in this area. These factors result in a significant amount of work required before zkML can be implemented at a scale suitable for consumer products.
summary
It is especially important to balance decentralization and trust while maintaining the decentralized spirit of blockchain and ensuring the reliability of AI systems, especially where AI uses trusted hardware or specific data governance models. In the next part of this article, we’ll dive into the technologies that can support decentralized AI and the critical role of Marlin infrastructure in making this possible.
Part 2: Implementation Technology Overview
In the previous part of this article, we explored the shortcomings of centralized AI and how Web3 can alleviate these issues. However, running the model on-chain is not possible due to extremely high gas fees. Attempting to increase the computing power of the underlying blockchain will increase the node requirements for validators, which may reduce decentralization due to the difficulties small home validators will face.
In the following chapters, we will introduce some popular tools and technologies necessary to further develop artificial intelligence in Web3, namely zero-knowledge proofs (ZKPs), fully homomorphic encryption (FHE), and trusted execution environments (TEEs).
ZKP and ZKML
Zero-knowledge proofs (ZKPs) are particularly important for artificial intelligence and Web3 because they can improve scalability and privacy protection. They allow calculations to be performed off-chain and then verified on-chain (validation calculations), which is much more efficient than re-executing calculations on all nodes of the blockchain, reducing network load and enabling more complex operations. zkML enables AI models to run in an on-chain environment. This ensures that the output of these off-chain calculations is trusted and verified.
Additionally, zkML can verify specific aspects of the machine learning process, such as confirming that a specific model was used to make a prediction or that a model was trained on a specific dataset. zkML can also be used to verify computational processes. For example, it allows computing providers to prove through verifiable evidence that they have used the correct model to process data. This is especially important for developers who rely on decentralized computing providers such as Akash and want to ensure the accuracy and integrity of their calculations.
zkML is also useful for users who need to run models on their data but want to keep the data private. They can execute the model on their own data, generate proofs, and subsequently verify the use of the correct model without compromising the privacy of the data.
FHE
As mentioned before, fully homomorphic encryption (FHE) allows calculations to be performed directly on encrypted data without first decrypting it. The technology has important applications in the field of artificial intelligence, especially in machine learning and sensitive data processing.
One of the main applications of FHE is the training of machine learning models using encrypted datasets. This approach ensures that data remains encrypted and secure throughout the training process. As a result, FHE provides a comprehensive security solution that keeps data private from the beginning to the end of the machine learning process. This is especially important in edge networks, where data security and privacy are critical and computing resources are often more limited than in centralized data centers.
Using fully homomorphic encryption technology can develop systems that protect user privacy while fully utilizing the advanced capabilities of artificial intelligence. By ensuring that data remains encrypted during storage and processing, Fully Homomorphic Encryption (FHE) provides strong cryptographic guarantees against unauthorized access and data leakage. This is particularly important in scenarios where sensitive information is handled, such as personal data in medical applications or confidential financial records.
Fully Homomorphic Encryption (FHE) extends its utility to the running of large language models in cloud environments. By enabling these models to process encrypted data, Fully Homomorphic Encryption (FHE) ensures that user privacy and sensitive information are protected. This capability becomes increasingly important as more and more AI applications are deployed in cloud environments and data security becomes an important issue. The ability to run models securely on encrypted data enhances the applicability of AI in areas where strict confidentiality is required, such as the legal, medical and financial industries.
Fully Homomorphic Encryption (FHE) addresses the critical need to protect sensitive data from potential information leakage and unauthorized access. In areas where data privacy is not just a preference but a regulatory requirement, fully homomorphic encryption (FHE) offers a way to leverage artificial intelligence without compromising data security and compliance standards.
TEE
Trusted Execution Environments (TEEs) have significant advantages in training and executing artificial intelligence inference, especially in terms of security assurance, isolation, data privacy and protection. Because TEEs act as secure isolation environments, they provide strong security and integrity for data and computation.
The first major benefit is the increased assurance of safety and security. TEEs are specifically designed to combat vulnerabilities in systems with extensive Trusted Computing Bases (TCBs), including operating system kernels, device drivers, and libraries. These components are more vulnerable due to their larger attack surface. By providing a secure execution environment, TEE protects critical applications and maintains the integrity and confidentiality of software within the compartment even if the host operating system is compromised.
Another key advantage is isolation. Within the quarantine, code and data are stored securely and can only be accessed by code within the quarantine. This design prevents external access, including from other virtual machines or hypermonitors, protecting against physical attacks and threats from other virtual machines.
TEE (Trusted Execution Environment) facilitates the remote verification process to verify that software is executing within a real TEE. This feature is critical to ensuring the authenticity and integrity of software running within the demilitarized zone. It establishes trust between the remote entity and the trusted execution environment, ensuring that the software and its execution environment are secure and have not been tampered with.
Finally, TEE excels at data protection. The TEEs hardware-implemented security features protect the confidentiality and integrity of computations. This includes secure delivery of code and data (such as keys) into quarantine. The TEE also establishes a trusted communication channel for retrieving calculation results and output, ensuring that the data remains secure throughout its lifecycle within the enclave. These characteristics make TEEs an ideal environment for training AI and performing AI inference, especially in applications that require high levels of security and data integrity.
Marlin Oyster
Marlin Oyster is an open platform for developers to deploy custom computing tasks or serve trusted execution environments. Similar to Intels SGX and AWSs Nitro Enclaves. With Oyster, developers can execute code in an isolated environment and ensure that neither the host nor any other application within it can alter the integrity of the computation in the trusted execution environment. In addition to the computational integrity and confidentiality guarantees provided by a Trusted Execution Environment (TEE), the Oyster Platform provides additional benefits:
Uptime:Oyster ensures application availability through a monitoring protocol that penalizes downtime and redistributes tasks to healthy nodes. This mechanism ensures that developers deploying on Oyster provide continued application functionality and vitality to end users.
Serverless:Similar to AWS Lambda, Oysters serverless framework allows developers to deploy applications without dedicatedly leasing specific nodes. Developers save costs and reduce administrative overhead by paying only for the time their application is running.
network:Oyster ghettos come pre-configured with networking capabilities that facilitate the establishment of secure TLS connections within the ghetto. This feature enables the execution of external API queries and operations on services with exposed endpoints, enhancing application integration with the Internet.
relay:Oyster supports the transfer of computationally intensive tasks to an off-chain environment for processing through relay contracts. These smart contracts make it possible to execute functions on Oyster, ensuring reliable results and event-based responses to optimize the use of on-chain resources.
benchmark
In the benchmark comparison between the zkML framework and TEE ML (Oyster), the performance metrics indicate that Oyster is more efficient. Specifically, the Oyster framework exhibits significantly lower total computation time across all tested machine learning models.

For the ordinary least squares model on the Iris data, the zkML framework (RisQ) takes more than 32 seconds to prove and verify, while Oyster only takes 0.047 seconds to complete the task. Likewise, on the same dataset, the total time of the neural network using zkML (EZKL framework) for 500 inputs was over 212 seconds, while Oyster only took 0.045 seconds. This significant difference in processing time suggests that Oyster is more efficient in these situations.
On the MNIST dataset, the LeNet model further deepens this observation. EZKL’s zkML framework takes 60 seconds to verify and prove, while Oyster only takes 0.056 seconds. Even though DDKang’s zkML framework performs better than EZKL, with a total time of about 3.33 seconds, it’s still not as good as Oyster’s 0.056 seconds.
Overall, the data shows that Oyster provides a more efficient solution to machine learning tasks compared to the tested zkML frameworks. Its faster computation time shows that, for the presented benchmarks, Oyster can handle the same task in significantly less processing time, giving it an advantage in terms of efficiency and speed.
For widespread adoption of verifiable, decentralized AI, off-chain cryptographic verification systems must go beyond performing simple tasks such as ordinary least squares calculations. The key advancement required is the ability to handle more complex tasks, specifically, running prompts efficiently through popular LLMs. This requires increased computing power, algorithmic efficiency, and scalability to handle the complex and resource-intensive needs of modern LLMs, enabling more complex and diverse AI applications within a decentralized framework. zkML frameworks are still in their infancy, and at this stage their ability to handle these cues is severely hampered because generating zk proofs is a computationally intensive task.
Although the zkML protocol has not been shown to process LLMs, it is reasonable to assume that the processing time difference between Oysters trusted TEE and these zkML frameworks is at least as significant as the previously discussed examples. Using Marlin’s Oyster, it is possible to establish benchmark results for various LLMs:
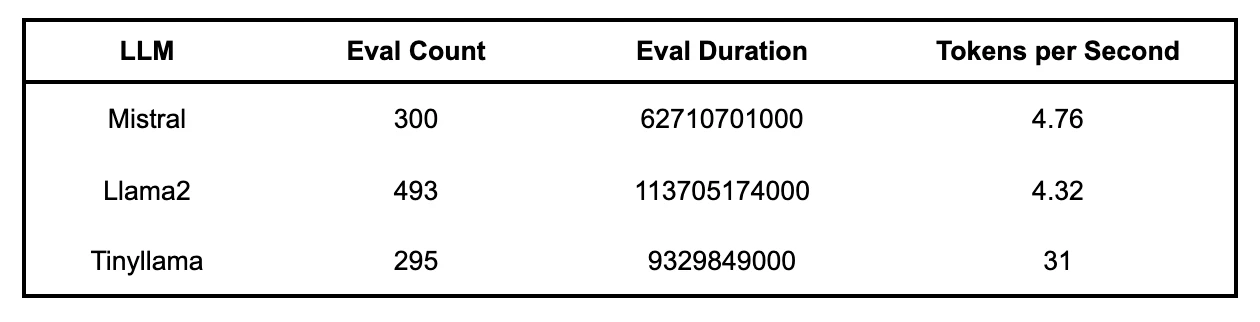
Evaluation Count: The number of tokens in the response; Evaluation Duration: The nanoseconds it took to generate the response
GPT2-XL benchmark results within Oyster:
Quarantine configuration: 12 CPU, 28 GB memory (c6a.4xlarge)
Tip: Ethereum is a community-operated technology
Result: Ethereum is the community-run technology that enables the Internet to function. Just like Linux did for computers, Ethereum will empower the Internet into the future.
Time taken to generate output: 22.091819524765015 seconds
Marks per second: 1.6295624703815754 seconds
Part 2: Conclusion
The development and distribution of AI technology is increasingly dominated by a small number of large enterprises with advanced hardware and sophisticated models. This level of concentration raises concerns about censorship, inherent bias, and verifying the integrity and fairness of AI systems. In contrast, the fundamental principles of cryptocurrency—namely, being permissionless and censorship-resistant—offer a path to democratizing AI technology.
The decentralized and open-source nature of blockchain technology enables decentralized artificial intelligence to compete with centralized opponents. This is achieved through DePINs, cryptographic proofs and the use of public and private key equivalence mechanisms, which together ensure the safe, transparent and fair development and use of AI. In order to realize the full potential of decentralized artificial intelligence, especially in the blockchain ecosystem, a robust off-chain computing infrastructure is required. This is critical for handling complex AI tasks efficiently, accurately and verifiably.
Currently, Trusted Execution Environments (TEEs) emerge as the most feasible solution to meet this requirement. TEE provides a secure and isolated execution space for code, protecting the confidentiality and integrity of the data being processed. This makes them the best choice for off-chain computing required on blockchains for AI applications. As the field evolves, advancements in technologies like zkML, FHE, and enhancements to Trusted Execution Environments (TEEs) will be critical for the decentralized AI ecosystem to overcome current limitations. This development will promote a more open, accessible, and secure field of artificial intelligence, consistent with the crypto community’s philosophy of decentralization.





