
In-depth analysis of the next trillion track: the combination of zero-knowledge proof and distributed computing
1. History and market prospect of distributed computing
secondary title
1.1 Development history
At the beginning, each computer could only perform one computing task. With the emergence of multi-core and multi-threaded CPUs, a single computer can perform multiple computing tasks.
As the business of large-scale websites increases, it is difficult to expand the capacity of the single-server model, which increases hardware costs. A service-oriented architecture emerges, consisting of multiple servers. It consists of service registrants, service providers and service consumers.
However, with the increase of business and servers, the maintainability and scalability of point-to-point services will become more difficult under the SOA model. Similar to the microcomputer principle, the bus mode appears to coordinate various service units. Service Bus connects all systems together through a hub-like architecture. This component is called ESB (Enterprise Service Bus). As an intermediary role, it translates and coordinates service agreements in different formats or standards.
Then the application programming interface (API)-based REST model communication stands out for its simplicity and higher composability. Each service outputs an interface in the form of REST. When a client makes a request through a RESTful API, it passes a resource state representation to the requester or endpoint. This information or representation is transmitted over HTTP in one of the following formats: JSON (Javascript Object Notation), HTML, XLT, Python, PHP, or plain text. JSON is the most commonly used programming language, and although its name means "JavaScript Object Notation" in English, it is applicable to various languages and can be read by both humans and machines.
Virtual machines, container technology, and three papers from Google:GFS: The Google File System
Year 2003,MapReduce: Simplified Data Processing on Large Clusters
year 2004,Bigtable: A Distributed Storage System for Structured Data
year 2006,
They are distributed file system, distributed computing, and distributed database, which opened the curtain of distributed system. Hadoop's reproduction of Google papers, faster and easier-to-use Spark, and Flink for real-time computing.
The smart contract public chain represented by Ethereum can be abstractly understood as a decentralized computing framework, but the EVM is a virtual machine with a limited instruction set, which cannot do the general computing required by Web2. And the resources on the chain are also extremely expensive. Even so, Ethereum has also broken through the bottleneck of the point-to-point computing framework, point-to-point communication, network-wide consistency of calculation results, and data consistency.
secondary title
1.2 Market prospect
Starting from business needs, why is a decentralized computing network important? How big is the overall market size? What stage is it now, and how much space is there in the future? Which opportunities deserve attention? How to make money?
text
1.2.1 Why is decentralized computing important?
In the original vision of Ethereum, it was to become the computer of the world. After the explosion of ICO in 2017, everyone found that asset issuance was still the main focus. But in 2020, Defi summer appeared, and a large number of Dapps began to emerge. With the explosion of data on the chain, EVM is becoming more and more powerless in the face of more and more complex business scenarios. The form of off-chain expansion is needed to realize functions that cannot be realized by EVM. Roles such as oracles are decentralized computing to some extent.
Now that Dapp development has passed, it only needed to complete the process from 0 to 1. Now it needs more powerful underlying facilities to support it to complete more complex business scenarios. The entire Web3 has passed from the stage of developing toy applications, and needs to face more complex logic and business scenarios in the future.
text
1.2.2 How big is the overall market size?
How to estimate the market size? Estimated by the scale of distributed computing business in the Web2 field? Multiplied by the penetration rate of the web3 market? Do you add up the valuations of corresponding financing projects currently on the market?
We cannot transfer the distributed computing market size from Web2 to Web3 for the following reasons: 1. Distributed computing in the Web2 field meets most of the needs, and decentralized computing in the Web3 field is differentiated to meet market demands. If it is copied, it is contrary to the objective background environment of the market. 2. For decentralized computing in the Web3 field, the business scope of the market that will grow in the future will be global. So we need to be more rigorous in estimating the market size.
The overall scale budget of the potential track in the Web3 field is calculated based on the following points:
The revenue model comes from the design of the token economic model. For example, the current popular token revenue model is that tokens are used as a means of paying fees during transactions. Therefore, the fee income can indirectly reflect the prosperity of the ecology and the activity of transactions. Ultimately, it is used as the standard for valuation judgment. Of course, there are other mature models for tokens, such as for mortgage mining, or transaction pairs, or the anchor assets of algorithmic stablecoins. Therefore, the valuation model of the Web3 project is different from the traditional stock market and more like a national currency. The scenarios in which tokens can be adopted will vary. So for specific projects specific analysis. We can try to explore how the token model should be designed in the Web3 decentralized computing scenario. First of all, we assume that we are going to design a decentralized computing framework. What kind of challenges will we encounter? a). Because of the completely decentralized network, to complete the execution of computing tasks in such an untrustworthy environment, it is necessary to motivate resource providers to ensure the online rate and service quality. In terms of the game mechanism, it is necessary to ensure that the incentive mechanism is reasonable, and how to prevent attackers from launching fraudulent attacks, sybil attacks, and other attack methods. Therefore, tokens are needed as a pledge method to participate in the POS consensus network, and the consensus consistency of all nodes is guaranteed first. For resource contributors, the amount of work they contribute is required to implement a certain incentive mechanism. Token incentives must have positive cyclic growth for business growth and network efficiency improvement. b). Compared with other layer 1, the network itself will also generate a large number of transactions. In the face of a large number of dust transactions, each transaction pays a handling fee, which is a token model that has been verified by the market. c). If the token is only used for practical purposes, it will be difficult to further expand the market value. If it is used as the anchor asset of the asset portfolio, several layers of asset nested combinations will be carried out, which will greatly expand the effect of financialization. Overall Valuation = Pledge Rate * Gas Consumption Rate * (Reciprocal of Circulation) * Single Price
text
1.2.3 What stage is it now, and how much space is there in the future?
From 2017 to the present, many teams are trying to develop in the direction of decentralized computing, but all of them have failed. The reasons for the failure will be explained in detail later. The exploration path was originally a project similar to the Alien Exploration Program, and later developed to imitate the traditional cloud computing model, and then to the exploration of the Web3 native model.
The current status of the entire track is a breakthrough that has been verified from 0 to 1 at the academic level, and some large-scale projects have made great progress in engineering practice. For example, the current implementations of zkRollup and zkEVM are at the stage of just releasing products.
There is still a lot of room in the future for the following reasons: 1. The efficiency of verification calculations needs to be improved. 2. More instruction sets need to be enriched. 3. Optimization of truly different business scenarios. 4. Business scenarios that could not be realized with smart contracts in the past can be realized through decentralized computing.
Of course, this is just an application scenario proposed, and Web2 has many business scenarios that require computing power.
1.2.4 Which opportunities deserve attention? How to make money?
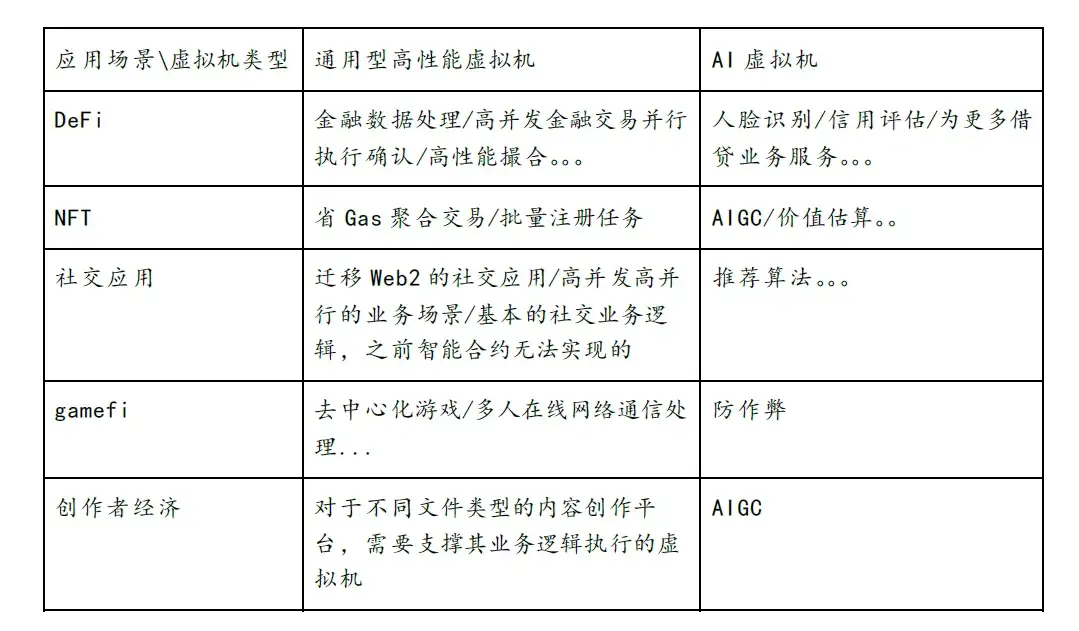
2. Decentralized distributed computing attempts
secondary title
2.1 Cloud service model
Currently Ethereum has the following problems:
Overall throughput is low. It consumes a lot of computing power, but the throughput is only equivalent to a smartphone.
Validation is low. This problem is known as Verifier's Dilemma. Nodes that have obtained packaging rights are rewarded, and other nodes need to verify, but they do not receive rewards, and the verification enthusiasm is low. Over time, calculations may not be verified, posing risks to data security on the chain.
The calculation amount is limited (gasLimit), and the calculation cost is high.
Some teams are trying to adopt the cloud computing model widely adopted by Web2. The user pays a certain fee, and the fee is calculated according to the usage time of the computing resources. The fundamental reason for adopting such a model is that it is impossible to verify whether the computing task is executed correctly, only through detectable time parameters or other controllable parameters.
The final result is completely different from the original intention.
secondary title
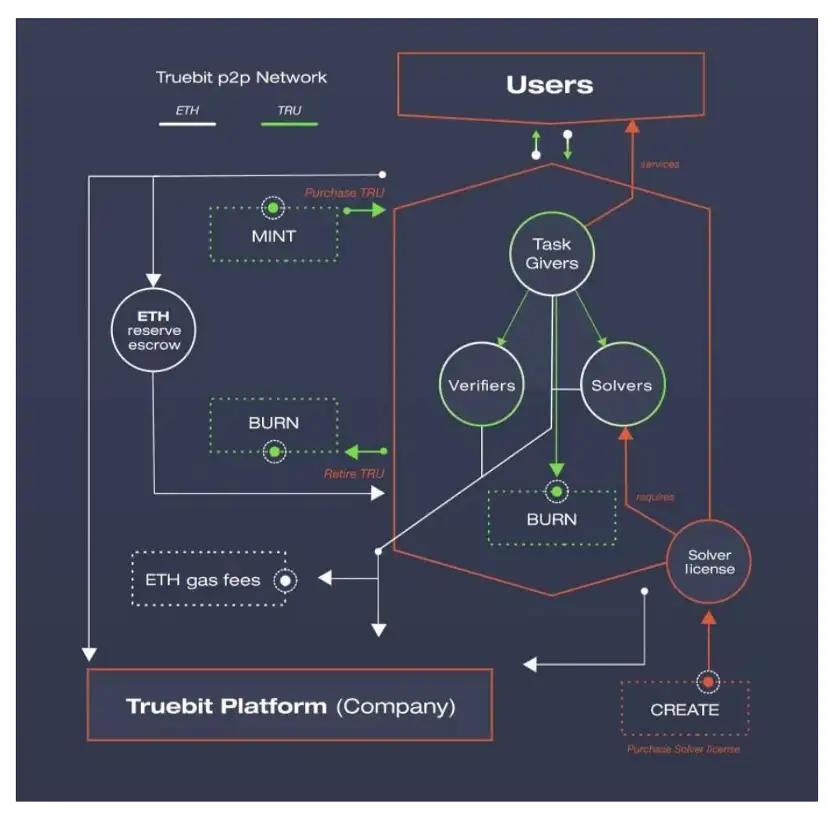
2.2 Challenger mode
https://www.aicoin.com/article/256862.html
On the other hand, TrueBit uses the game system to achieve the global optimal solution to ensure that the distributed computing tasks are executed correctly.
The core points of our fast computing framework:
Roles: Problem Solver, Challenger, and Judge
Problem solvers need to pledge funds before they can participate in receiving computing tasks
As a bounty hunter, the challenger needs to repeatedly verify whether the calculation results of the problem solver are consistent with their own local ones
The challenger will extract the most recent calculation task that is consistent with the calculation status of the two. If there is a divergence point, submit the Merkle tree hash value of the divergence point
At the end the judge judges whether the challenge is successful
Challengers can submit late, as long as they complete the submission task. This results in a lack of timeliness.
secondary title
2.3 Using zero-knowledge proof to verify calculation
So how to achieve it can not only ensure that the calculation process can be verified, but also ensure the timeliness of verification.
For example, in the implementation of zkEVM, a verifiable zkProof needs to be submitted for each block time. This zkProof contains the bytecode generated by the logic computing business code, and then the bytecode is executed to generate the circuit code. In this way, it is realized that the calculation business logic is executed correctly, and the timeliness of the verification is guaranteed through a short and fixed time.
Under the assumption that there are enough high-performance zero-knowledge proof acceleration hardware and enough optimized zero-knowledge proof algorithms, general-purpose computing scenarios can be fully developed. A large number of computing services in Web2 scenarios can be reproduced by zero-knowledge proof general-purpose virtual machines. As mentioned above, the profitable business direction.
3. Combination of zero-knowledge proof and distributed computing
secondary title
3.1 Academic level
Let's look back at the historical development and evolution of the zero-knowledge proof algorithm:
GMR 85 is the earliest origin algorithm, derived from the paper co-published by Goldwasser, Micali and Rackoff: The Knowledge Complexity of Interactive Proof Systems (ie GMR 85), which was proposed in 1985 and published in 1989. This paper mainly explains how much knowledge needs to be exchanged after K rounds of interactions in an interactive system to prove that a statement is correct.
Yao's Garbled Circuit (GC) [89]. A well-known oblivious transfer-based two-party secure computation protocol capable of evaluating any function. The central idea of obfuscation circuits is to decompose a computational circuit (we can perform any arithmetic operation with an AND circuit, an OR circuit, and a NOT circuit) into a generation phase and an evaluation phase. Each party is responsible for a stage in which the circuit is encrypted, so neither party can obtain information from the other, but they can still obtain results based on the circuit. The obfuscation circuit consists of an oblivious transfer protocol and a block cipher. The complexity of the circuit grows at least linearly with the input content. After the obfuscation circuit was published, Goldreich-Micali-Wigderson (GMW) [91] extended the obfuscation circuit to multiple parties to resist malicious adversaries.
The sigma protocol is also known as (special) zero-knowledge proofs for honest verifiers. That is, it is assumed that the verifier is honest. This example is similar to the Schnorr authentication protocol, except that the latter is usually non-interactive.
Pinocchio (PGHR 13) in 2013: Pinocchio: Nearly Practical Verifiable Computation, which compresses proof and verification time to the applicable scope, is also the basic protocol used by Zcash.
Groth 16 in 2016: On the Size of Pairing-based Non-interactive Arguments, which simplifies the size of the proof and improves the verification efficiency, is currently the most widely used ZK basic algorithm.
Bulletproofs (BBBPWM 17) Bulletproofs: Short Proofs for Confidential Transactions and More in 2017 proposed the Bulletproof algorithm, a very short non-interactive zero-knowledge proof that does not require trusted settings, and it will be applied to Monero 6 months later, which is very Fast theory-to-application integration.
In 2018, zk-STARKs (BBHR 18) Scalable, transparent, and post-quantum secure computational integrity proposed a ZK-STARK algorithm protocol that does not require trusted settings. Based on this, StarkWare, the most important ZK project, was born.
Bulletproofs are characterized by:
1) short NIZK without trusted setup
2) Build on Pedersen commitment
3) Support proof aggregation
4) Prover time is: O ( N ⋅ log ( N ) ) O(N\cdot \log(N))O(N⋅log(N)), about 30 seconds
5) Verifier time is: O ( N ) O(N)O(N), about 1 second
6) The proof size is: O ( log ( N ) ) O(\log(N))O(log(N)), about 1.3 KB
7) The security assumption based on: discrete log
The applicable scenarios of Bulletproofs are:
2 )inner product proofs
1) range proofs (only about 600 bytes)
4 )aggregated and distributed (with many private inputs) proofs
3) intermediary checks in the MPC protocol
The key features of Halo 2 are:
1) Efficiently combine accumulation scheme with PLONKish arithmetization without trusted setup.
2) Based on the IPA commitment scheme.
3) Prosperous developer ecology.\log N)O(N∗logN)。
4) Prover time is: O ( N ∗ log N ) O(N*
5) Verifier time is: O ( 1 ) > O ( 1) > O ( 1) > Groth 16.\log N)O(logN)。
6) Proof size is: O ( log N ) O(
7) The security assumption based on: discrete log.
Appropriate scenarios for Halo 2 include:
1) Any verifiable computation
2) Recursive proof composition
3) Circuit-optimized hashing based on lookup-based Sinsemilla function
Scenarios where Halo 2 is not suitable are:
1) Unless you replace Halo 2 with the KZG version, it will be expensive to verify on Ethereum.
The main features of Plonky 2 are:
1) Combine FRI with PLONK without trusted setup.
2) Optimized for processors with SIMD and employs 64 byte Goldilocks fields.\log N)O(logN)。
3) Prover time is: O ( log N ) O(\log N)O(logN)。
4) Verifier time is: O ( log N ) O(\log N)O(N∗logN)。
5) Proof size is: O ( N ∗ log N ) O(N*
6) The security assumption based on: collision-resistant hash function.
The scenarios that Plonky 2 is suitable for are:
1) Arbitrary verifiable computation.
2) Recursive proof composition.
3) Use a custom gate for circuit optimization.
Scenarios where Plonky 2 is not suitable are:
At present, Halo 2 has become the mainstream algorithm adopted by zkvm, supports recursive proof, and supports verification of any type of calculation. It lays the foundation for general computing scenarios of zero-knowledge proof type virtual machines.
secondary title
3.2 Engineering practice level
Now that zero-knowledge proofs are advancing by leaps and bounds at the academic level, what is the current progress when it comes to actual development?
We observe from multiple levels:
Programming language: There are currently specialized programming languages that help developers not need to have a deep understanding of how circuit codes are designed, thus lowering the development threshold. Of course there is also support for translating Solidity into circuit code. Developer friendliness is getting better and better.
Virtual machine: There are currently many implementations of zkvm. The first is a self-designed programming language, which is compiled into circuit code through its own compiler, and finally zkproof is generated. The second is to support the solidity programming language, which is compiled into target bytecode by LLVM, and finally translated into circuit code and zkproof. The third is the true EVM equivalent compatibility, which finally translates the bytecode execution into circuit code and zkproof. Is this the endgame for zkvm? No, whether it is general-purpose computing scenarios that expand beyond smart contract programming, or the completion and optimization of zkvm for its own underlying instruction set in different schemes, it is still in the 1 to N stage. There is a long way to go, and a lot of engineering work needs to be optimized and realized. Each company has achieved landing from the academic level to the engineering realization, who can finally become the king and kill a bloody road. Not only does it need to make substantial progress in performance improvement, but it also needs to attract a large number of developers to enter the ecosystem. Timing is a very important premise element. Pushing to the market first, attracting funds to accumulate, and applications that emerge spontaneously in the ecosystem are all elements of success.
Peripheral supporting tools and facilities: editor plug-in support, unit test plug-in, Debug debugging tools, etc., to help developers develop zero-knowledge proof applications more efficiently.
Infrastructure for zero-knowledge proof acceleration: Because FFT and MSM take up a lot of computing time in the entire zero-knowledge proof algorithm, they can be executed in parallel on parallel computing devices such as GPU/FPGA to achieve the effect of compressing time overhead.
The emergence of star projects: zkSync, Starkware and other high-quality projects have announced the time of their official product releases. It shows that the combination of zero-knowledge proof and decentralized computing no longer stays at the theoretical level, but gradually matures in engineering practice.
4. Bottlenecks encountered and how to solve them
secondary title
4.1 The generation efficiency of zkProof is low
We mentioned earlier about the market capacity, the current industry development, and the actual progress in technology, but are there no challenges?
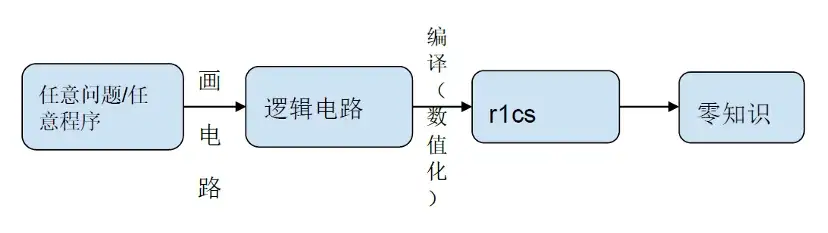
We disassemble the entire zkProof generation process:
At the stage of logic circuit compilation and numericalization r 1 cs, 80% of the calculations are in computing services such as NTT and MSM. In addition, the hash algorithm is performed on different levels of the logic circuit. As the number of levels increases, the time overhead of the Hash algorithm increases linearly. Of course, the industry now proposes a GKR algorithm that reduces time overhead by 200 times.
However, the computing time overhead of NTT and MSM remains high. If you want to reduce the waiting time for users and improve the user experience, you must accelerate at the level of mathematical implementation, software architecture optimization, GPU/FPGA/ASIC, etc.
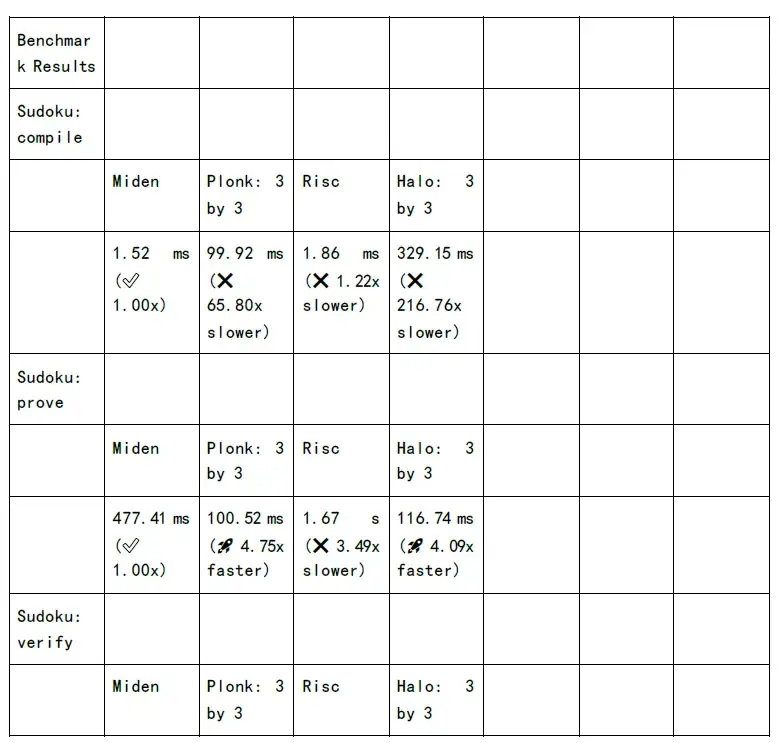
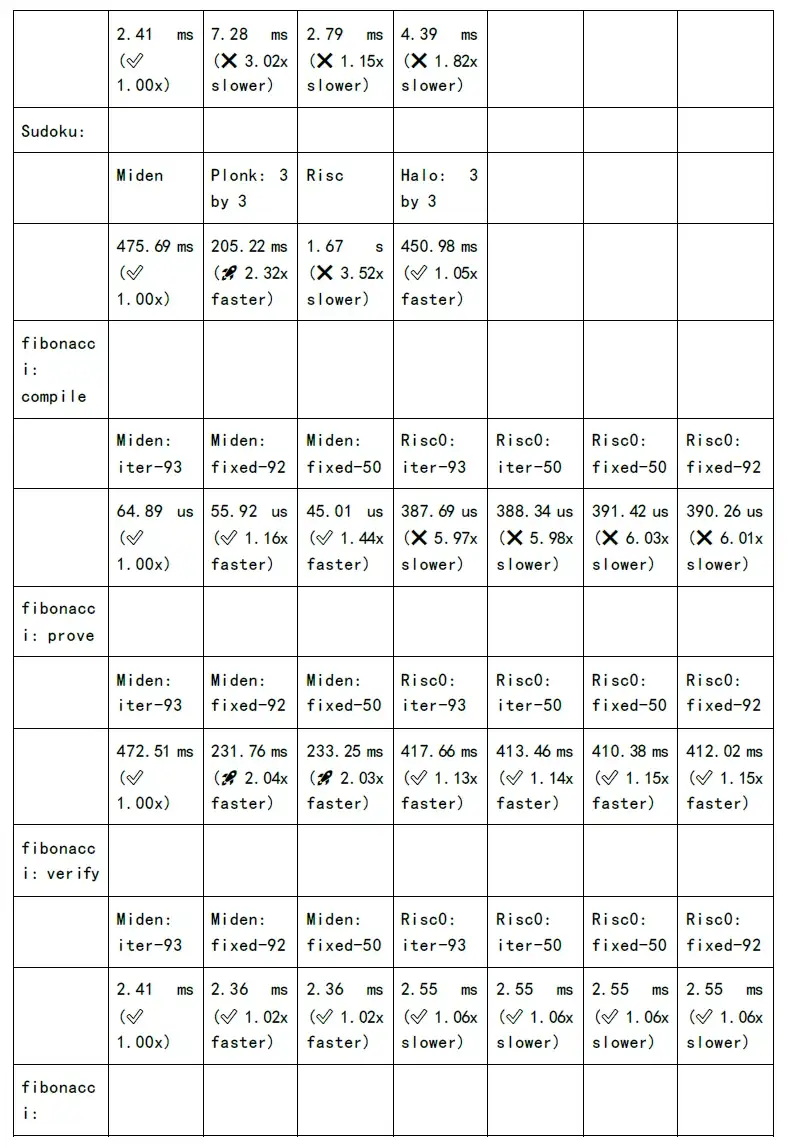
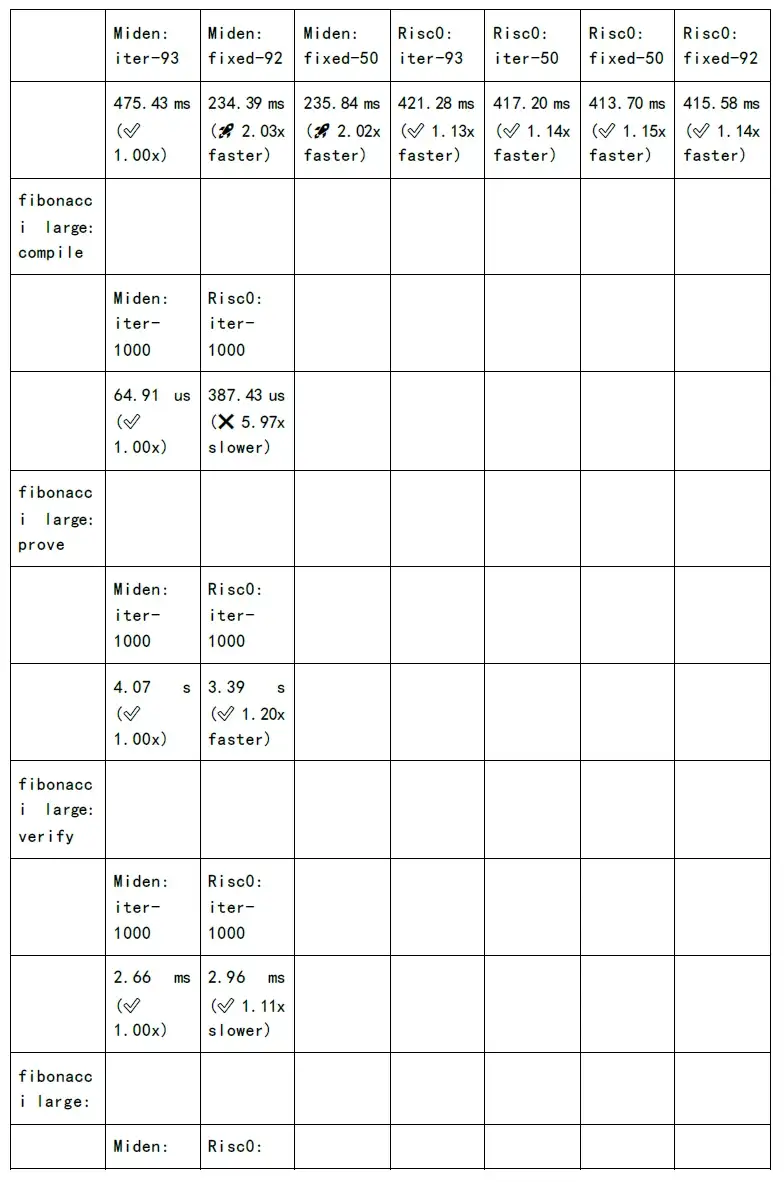
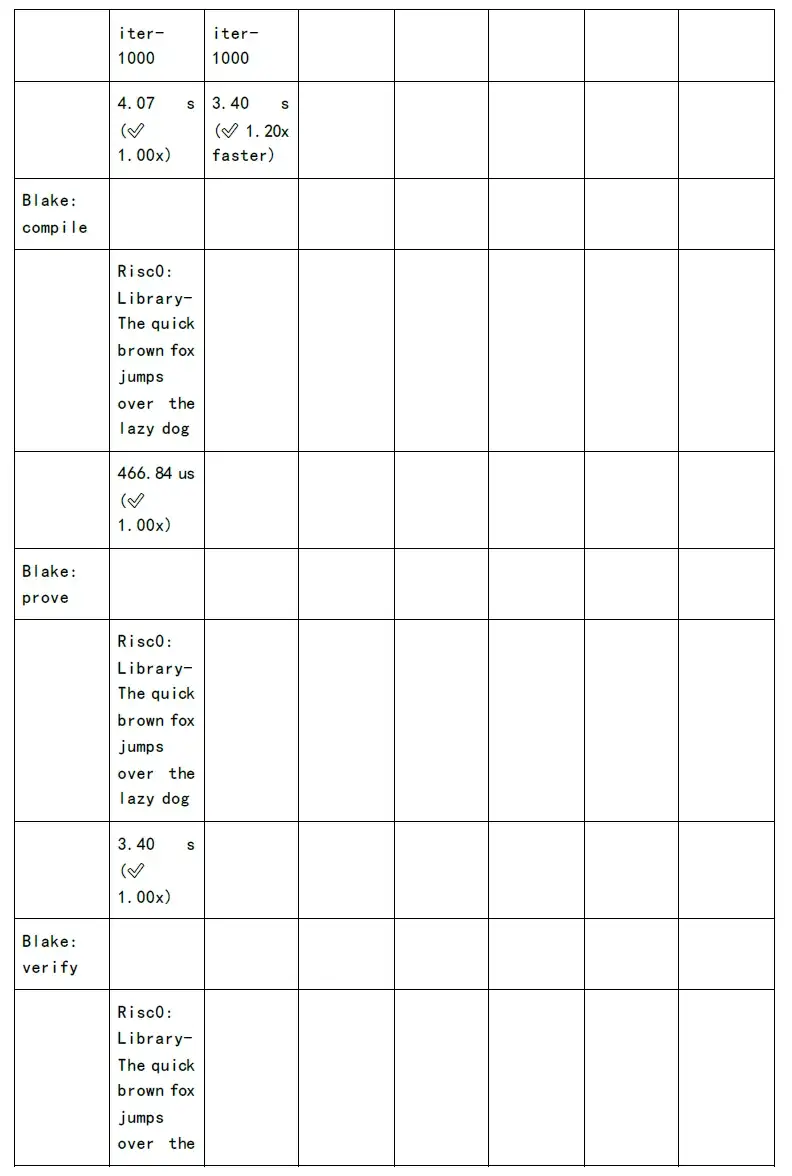
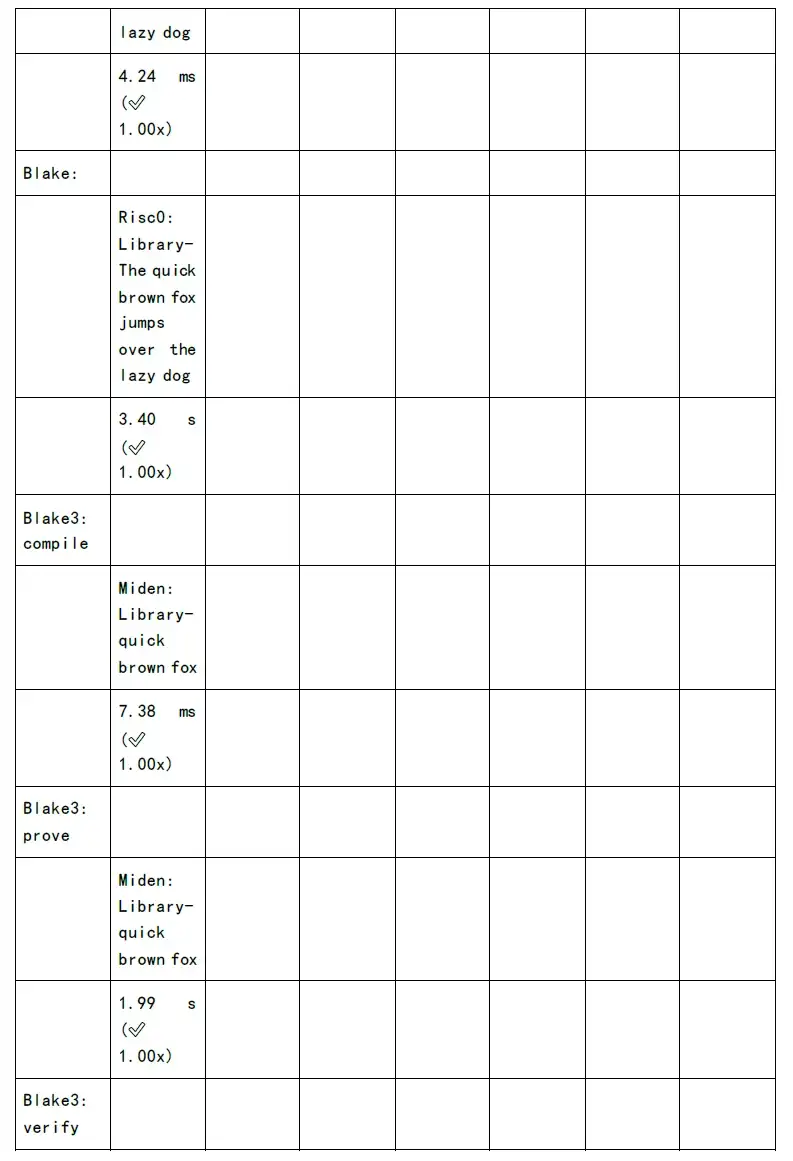
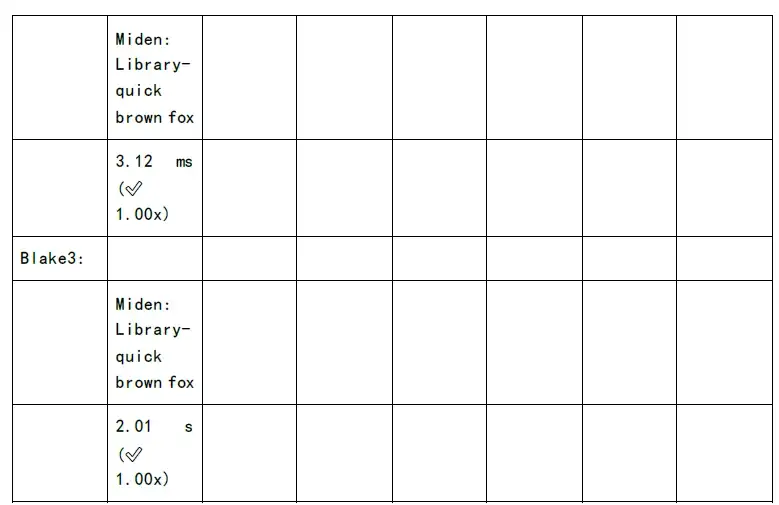
The following figure shows the test of proof generation time and verification time of each zkSnark family algorithm:
Now that we can see the pitfalls and challenges, it also means that there are deep opportunities:
Graphics card accelerated Saas service uses graphics card for acceleration, which costs less than ASIC design, and the development cycle is also shorter. However, software innovation will eventually be eliminated by hardware acceleration in the long run.
secondary title
4.2 Occupy a lot of hardware resources
In the future, if you want to popularize zkSnark applications on a large scale, it is imperative to optimize at different levels.
secondary title
4.3 Gas Consumption Cost
Therefore, many zkp projects propose that the data effective layer and the zkProof submitted by using recursive proof compression are all to reduce the gas cost.
secondary title
At present, most zkvm platforms are oriented to smart contract programming. If more general computing scenarios are required, there is a lot of work to be done on the underlying instruction set of zkvm. For example, the bottom layer of the zkvm virtual machine supports libc instructions, instructions that support matrix operations, and other more complex calculation instructions.
first level title
5 Conclusion


