




原文作者:Zhiyong Fang
如何吃掉一頭大象?一口一口地吃。
近年來,機器學習模型以驚人的速度實現跨越式發展。隨著模型能力的提升,其複雜性亦同步激增-現今先進模型往往包含數百萬甚至數十億參數。為因應此等規模挑戰,多種零知識證明系統應運而生,這些系統始終致力於在證明時間、驗證時間與證明大小三者間實現動態平衡。
表 1 :模型參數規模的指數級成長
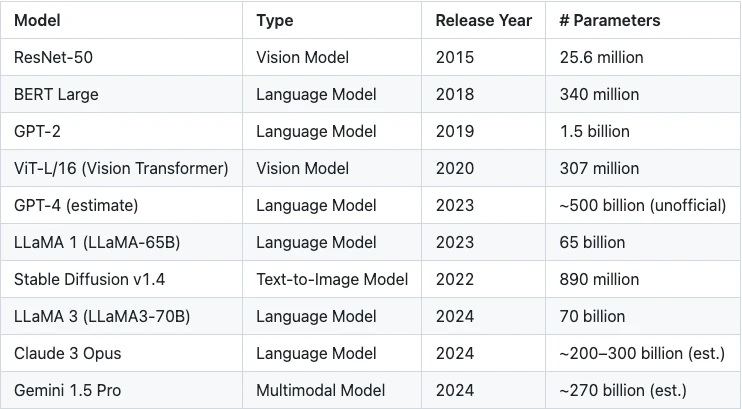
儘管當前零知識證明領域的大部分工作集中在優化證明系統本身,但一個關鍵維度卻常常被忽視——如何將大規模模型合理拆分為更小、更易於處理的子模組以進行證明。你可能會問,這一點為什麼這麼重要?
下面我們來詳細解釋:
現代機器學習模型的參數數量往往以十億計,即便在不涉及任何密碼學處理的情況下,也已佔用極高的記憶體資源。而在零知識證明(Zero-Knowledge Proof, ZKP)的場景下,這項挑戰被進一步放大。
每一個浮點數參數都必須轉換為代數域(Arithmetic Field)中的元素,而這個轉換過程本身會導致記憶體佔用增加約5 至10 倍。此外,為了在代數域中精確模擬浮點運算,還需額外引入操作開銷,通常也在5 倍左右。
綜合來看,模型整體記憶體需求可能提升至原始規模的25 至50 倍。例如,一個擁有10 億個32 位元浮點參數的模型,僅儲存轉換後的參數就可能需要100 至200 GB 記憶體。再考慮中間運算值與證明系統本身的開銷,整體記憶體佔用輕易突破TB 等級。
目前主流的證明系統,如Groth 16 和Plonk,在未經優化的實作中,通常假設所有相關資料可同時載入至記憶體。這種假設雖然在技術上可行,但在實際硬體條件下極具挑戰性,極大限制了可用的證明計算資源。
Polyhedra 的解決方案:zkCuda
什麼是zkCuda?
如我們在《zkCUDA 技術文件》中所述:
Polyhedra 推出的zkCUDA 是一個高效能電路開發的零知識運算環境,專為提升證明產生效率而設計。在不犧牲電路表達能力的前提下,zkCUDA 可充分利用底層證明器和硬體並行能力,實現快速的ZK 證明產生。
zkCUDA 語言在語法和語意上與CUDA 高度相似,對已有CUDA 經驗的開發者十分友好,且其底層以Rust 實現,確保安全性與效能兼備。
借助zkCUDA,開發者可以:
快速建構高性能ZK 電路;
高效調度並利用分散式硬體資源,如GPU 或支援MPI 的叢集環境,實現大規模平行運算。
為什麼選擇zkCUDA?
zkCuda 是一套受GPU 運算啟發設計的高效能零知識運算框架,能夠將超大規模的機器學習模型拆分為更小、更易管理的運算單元(kernels),並透過類似CUDA 的前端語言實現高效控制。這項設計帶來了以下關鍵優勢:
1. 精準匹配的證明系統選擇
zkCUDA 支援對每個計算kernel 進行細粒度分析,並為其匹配最適合的零知識證明系統。例如:
對於高度平行的運算任務,可選用如GKR 等擅長處理結構化並行度的協定;
對於規模較小或結構不規則的任務,則更適合使用如Groth 16 這類在緊湊計算場景下具有低開銷的證明系統。
透過客製化選擇後端,zkCUDA 可最大化發揮各類ZK 協定的效能優勢。
2. 更聰明的資源調度與並行優化
不同的證明kernel 對CPU、記憶體和I/O 的資源需求差異顯著。 zkCUDA 可準確評估每個任務的資源消耗,並智慧排程,最大化整體吞吐能力。
更重要的是,zkCUDA 支援在異質運算平台之間進行任務分發——包括CPU、GPU 和FPGA——從而實現硬體資源的最優利用,顯著提升系統級效能。
zkCuda 與GKR 協議的天然契合
儘管zkCuda 被設計為一個兼容多種零知識證明系統的通用計算框架,但它與GKR(Goldwasser-Kalai-Rothblum)協議在架構上具有天然的高度契合性。
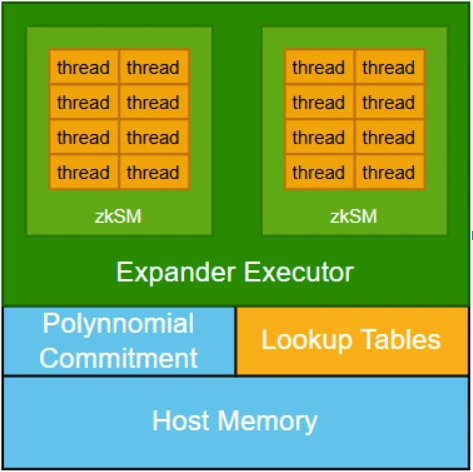
在架構設計上,zkCUDA 透過引入多項式承諾機制,將各個子運算核心連接起來,確保所有子運算都基於一致的共享資料運作。這項機制對於維持系統完整性至關重要,但也帶來了顯著的運算成本。
相比之下,GKR 協定提供了一種更有效率的替代路徑。與傳統零知識系統要求每個核心完整證明其內部約束的方式不同,GKR 允許將計算正確性的驗證從核心輸出遞歸回溯至輸入。這機制使得跨核心的正確性得以傳遞,而非在每個模組中完全展開驗證。其核心思想類似於機器學習中的梯度反向傳播,透過計算圖追蹤和傳導正確性主張。
雖然在多路徑中合併這類「證明梯度」帶來了一定複雜性,但正是這一機制,構成了zkCUDA 與GKR 之間的深度協同基礎。透過對齊機器學習訓練流程中的結構特性,zkCUDA 有望實現更緊密的系統整合和大模型場景下更有效率的零知識證明生成。
初步成果與未來方向
我們已完成zkCuda 框架的初始開發,並在多個場景中成功進行了測試,包括Keccak 和SHA-256 等密碼學雜湊函數,以及小規模的機器學習模型。
展望未來,我們希望進一步引入現代機器學習訓練中的一系列成熟工程技術,如內存優化調度(memory-efficient scheduling)與計算圖級優化(graph-level optimization)。我們相信,將這些策略整合進零知識證明產生流程,將大幅提升系統的效能邊界與適配彈性。
這只是一個起點,zkCuda 將持續朝向高效、高擴展性、高適配性的通用證明框架邁進。





