
黃仁勳的「Agent工廠」裡,裝了什麼新故事?
- 核心觀點:輝達在COMPUTEX 2026上宣布,圍繞「Agent AI」構建從晶片、模型到機器人平台的完整技術體系,Vera Rubin平台量產並專為Agent任務最佳化,旨在將AI工廠從基礎設施階段推向營運和部署的新時代。
- 關鍵要素:
- Vera Rubin平台專為Agent設計並量產,其處理效率是上一代Grace Blackwell的10倍,並首次大規模引入CPO網路技術及機密運算。
- 公司發布專為AI時代設計的Vera CPU,其Agent工作負載效能是同期x86伺服器的1.8倍,已全面投產。
- 推出DSX工廠營運系統,包含MaxLPS(電力最佳化)和DSX OS(營運管理),目標是標準化AI數據中心的建設與營運。
- 發布5500億參數的混合專家模型Nemotron 3 Ultra及開源Agent框架NemoClaw,用於建構企業級「數位同事」。
- 發布第三代物理AI模型Cosmos 3,統一視覺推理、生成與動作預測,旨在將物理AI訓練週期從數月壓縮至數天。
- 聯合宇樹發布人形機器人參考設計H2 Plus,並開源物理AI「技能」工具集,降低機器人開發門檻。
- Vera BlueField-4 STX升級儲存安全,透過晶片級策略執行保障Agent與企業資料的互動安全。
Original Authors: Li Hailun, Su Yang
Original Editor: Xu Qingyang
Original Source: Tencent Technology
On June 1, 2026, at the NVIDIA GTC Taipei conference held during COMPUTEX 2026, NVIDIA founder and CEO Jensen Huang delivered a keynote speech.
It has been only three months since the last GTC.
At that time, NVIDIA released the "complete chip family" of Vera Rubin, including: Vera CPU, Rubin GPU, Groq 3 LPU, ConnectX-9, BlueField-4 DPU, and Spectrum-6 switch. These six chips constitute a rack-scale AI supercomputer, and it was announced that the number of GPUs required for training large MoE models has been reduced to one-quarter, inference throughput per watt has increased 10 times, and the cost per token has dropped to one-tenth.
Unlike the previous emphasis on system-level solutions like the "chip family" and "computing family," at COMPUTEX three months later, Jensen Huang turned his focus to the target these infrastructures will serve – Agents.
During his speech, Jensen Huang revealed: Vera Rubin has officially entered mass production, Vera CPU has begun global delivery, DGX Station has made its debut on enterprise desktops in a Windows form factor, Cosmos 3 is restructuring the perceptual framework of physical AI, and DSX has become the operating system for AI factories. NVIDIA also partnered with Unitree to launch the H2 Plus – the first humanoid robot reference design based on Isaac GR00T, extending the boundaries of Agents from the digital world to physical form.
NVIDIA is reorganizing a complete technology system spanning chips, data centers, models, software, and robotics platforms around the Agent ecosystem.
Jensen Huang said: "The era of Agent AI and practical artificial intelligence has arrived. Now tokens are the unit of profit, AI is the 'generator' of GDP, and the number of software engineers is increasing. People talk about AI reducing jobs, which is completely nonsense. In fact, more software engineers are being hired."

The Same AI Factory, Running 10x More Agent Tasks
The Vera Rubin platform has entered full production.
Unlike the past, which primarily focused on large model training and inference, Vera Rubin was designed from the outset with Agents as a key workload.
In his speech, Jensen Huang stated that an Agent task often involves not just a single model inference, but multiple steps including reasoning, search, tool calls, code execution, and result verification, potentially encompassing thousands of steps behind the scenes. What future data centers need to handle will no longer be just single model requests, but a large number of continuously running, collaborating Agent tasks.
The platform is defined as a massive, unified computing-unit-level AI supercomputer, built specifically to handle Agent workloads from reasoning and retrieval to tool usage. In a similarly scaled hyperscale data center, using the new Vera Rubin platform to run autonomous AI Agent tasks achieves 10 times the processing efficiency of the previous generation Grace Blackwell platform.
Beyond the computing platform itself, networking is also a key upgrade area for Vera Rubin.
In past data centers, data transmission between GPUs mainly relied on traditional optical modules and switch architectures. However, as cluster scales continue to expand, power consumption, heat dissipation, and deployment complexity increase rapidly. To address this, NVIDIA has introduced the Spectrum-X Ethernet Photonics networking system into the Vera Rubin platform.
This is the first time NVIDIA has massively introduced Co-Packaged Optics (CPO) technology into AI data center networks.
Simply put, traditional solutions require plugging optical modules outside the switch, whereas CPO integrates the optical components directly inside the switch, thereby reducing energy consumption and signal loss.
Furthermore, security is another core capability heavily emphasized with this Vera Rubin platform.
To this end, NVIDIA has extended Confidential Computing capabilities across the entire Vera Rubin platform. Through trusted execution environments, hardware-level attestation, and end-to-end encryption mechanisms, enterprises can achieve a higher level of security when processing private data, industry-sensitive information, and critical models.
Jensen Huang revealed that Vera Rubin has entered the mass production phase. As a third-generation MGX rack-scale system, it involves over 150 partners, more than 350 factories, and a supply chain covering over 30 countries and regions. According to NVIDIA's announced plan, Vera Rubin will begin formal shipments this fall.

The Processor 'Born for Agents'
NVIDIA has launched a new processor, Vera, designed specifically for the Agent era, and it has entered full production.
Jensen Huang pointed out that advances in memory systems will drive innovation and modernization of storage systems. All CPUs up to now were built for humans, but Vera is a CPU designed for the AI era, built for Agents.
As the successor to Grace, Vera adopts NVIDIA's self-designed "Olympus" CPU core architecture, increasing the core count from 72 to 88, and significantly boosting memory and data processing capabilities. According to NVIDIA, in Agent-related workload tests, Vera achieved 1.8 times the task execution speed of contemporary x86 server CPUs.
More important than the pure performance increase is the change in the relationship between Vera and the Rubin GPU: Vera connects to the Rubin GPU via second-generation NVLink-C2C, achieving an interconnect bandwidth of 1.8 TB/s, further reducing the overhead of data transfer between CPU and GPU during Agent operation.
Jensen Huang stated that Vera Rubin uses HBM (High Bandwidth Memory) from Micron, SK Hynix, and Samsung, with a supply chain "twice" the size of the previous generation Blackwell. However, deploying a large Blackwell rack takes two hours, while Vera Rubin deployment time has been compressed to the 5-minute level.
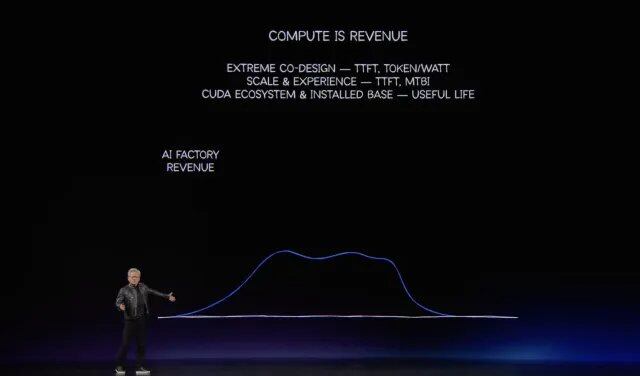
Moving AI Factories from 'Construction' to 'Operation'
The DSX introduced by NVIDIA this time can be understood as an "AI factory construction and operation toolbox."
In the past, building an AI data center required customers to consider servers, networking, power, cooling, facility design, and operation/maintenance systems separately, with many parts relying on coordination among different vendors. What DSX aims to do is bring these previously scattered elements into a single framework, providing customers with a standardized, verifiable approach from design, simulation, and construction to operation.
At the launch event, Jensen Huang stated: NVIDIA is not just selling chips, but providing infrastructure builders with a complete blueprint for an AI factory.
There are two main new capabilities added to DSX this time.
The first is DSX MaxLPS. It addresses the most practical problem for AI factories: how to fit more GPUs and generate more Tokens given a fixed power budget.
According to NVIDIA, MaxLPS, combining liquid cooling and in-rack power optimization, allows operators to run up to 40% more GPUs without significantly impacting performance.
The second is DSX OS. It acts as the operational software for the AI factory, responsible for lifecycle management, intelligent scheduling, health monitoring, fault recovery, and multi-tenant management. Simply put, if an AI factory is a complex facility, DSX OS is responsible for keeping it running stably and continuously.
Within the DSX product matrix, Reference Design provides AI factory reference designs, guiding customers on how to set up server rooms, racks, networks, power, and cooling systems; DSX Sim handles simulation, allowing customers to verify the feasibility of a design before construction; DSX Flex connects the AI factory to the power grid, enabling data centers to adjust tasks based on electricity prices, load, and demand response signals; DSX Exchange is responsible for connecting data interfaces between IT systems, operational systems, energy systems, and cooling systems.
On the ecosystem side, cloud partners like CoreWeave, Crusoe, and Lambda are deploying DSX Sim, MaxLPS, and DSX OS to mitigate risks and improve GPU utilization. Manufacturers such as Dell, HPE, Lenovo, Supermicro, as well as ASUS, Foxconn, Gigabyte, and Quanta Cloud Technology are building systems supporting DSX.
Aligning with Windows and ARM
During the live presentation, Jensen Huang officially announced the "DGX Station for Windows" workstation, defined by NVIDIA as a desktop-scale AI supercomputer for the Windows ecosystem.
Hardware-wise, it is powered by the GB300 Grace Blackwell Ultra Desktop Superchip, connecting the Blackwell Ultra GPU with a 72-core Grace CPU via NVLink-C2C, offering up to 748GB of unified memory and 20 PFLOPS FP4 performance, along with networking capabilities up to 800 Gb/s.
The key aspect of this product lies in the change in Agent deployment methods.
NVIDIA hopes enterprises can run multiple Agents in a local, secure, and manageable Windows environment, integrating them into workflows for design, engineering, data science, reasoning, and Physical AI. The concurrently launched OpenShell is responsible for Agent runtime security, using isolated sandboxes and system-level policy controls to prevent Agents from performing unauthorized operations or leaking credentials and private data.
Besides the enterprise desktop product, Jensen Huang also unveiled a system-level SoC – the RTX Spark SoC, integrating the N1X CPU and Blackwell GPU onto a single chip with a unified memory architecture, intended for thin-and-light laptops and small desktops.
Among these, the N1X is the first PC processor jointly created by NVIDIA and Microsoft. It is based on the Arm architecture, custom-designed by MediaTek, and manufactured using TSMC's 3nm process. It will debut this fall in laptops from Microsoft, Dell, HP, ASUS, Lenovo, and MSI, with over 30 models initially, targeting the premium thin-and-light segment.
This is NVIDIA's "super chip" for the AI PC era, which Jensen Huang views as a significant redefinition of the PC form factor.
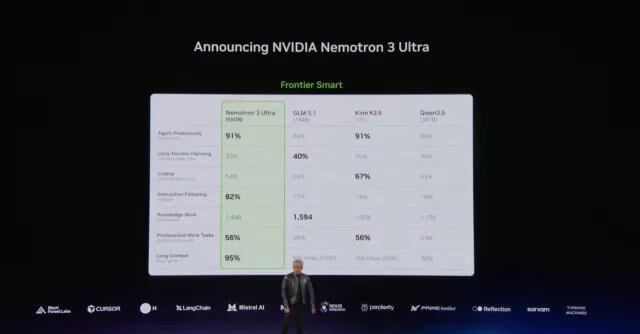
The 'Two Brains' of the Agent
At this conference, NVIDIA announced the latest progress on two core model product lines, corresponding to two scenarios for Agents: one operating within enterprise systems, and one operating in the physical world.
NVIDIA released a Mixture-of-Experts model with 550 billion parameters, Nemotron 3 Ultra, designed to provide top-tier intelligence for long-running Agents in code development, scientific research, and enterprise business processes. Compared to leading open-source frontier models of a similar scale, this model offers up to 5x faster inference speed and up to 30% lower usage cost, enabling Agents to perform tasks more efficiently and cost-effectively.
Around the Nemotron open model, NVIDIA released a series of software, open-source models, and partnership updates, aiming to enable enterprises to build "digital coworkers" that assist employees in scenarios like engineering design, healthcare, software development, and business operations.
Within this combination, Nemotron provides the foundational model capability, NemoClaw handles organizing models into Agents, OpenShell ensures runtime security, and the Agent Toolkit turns NVIDIA software libraries like CUDA-X into tools directly callable by Agents. Agents can use tools, access data, execute tasks within a controlled environment, and integrate with existing enterprise systems.
Jensen Huang stated that software companies worldwide are integrating AI Agents into real work systems to help employees complete complex tasks faster. NemoClaw provides the open components needed to build long-running Agents, including capabilities for orchestration, context, memory, tool calling, and security control.
In the past, enterprise discussions about AI focused more on what models could answer. Now, NVIDIA is tackling how Agents can securely access tools, data, and business processes, and operate continuously in real work environments.
Also announced is Cosmos 3, officially released as the third generation of the Cosmos series, representing a fundamental architectural overhaul.
Cosmos 3 is a world foundation model for physical AI, providing the underlying capability to "understand the physical world, predict what will happen, and decide what to do."
Compared to previous versions of Cosmos, which were primarily targeted at robotics and autonomous driving developers, focusing on video generation and physical world simulation – essentially a relatively single-modal generation framework – Cosmos 3 adopts a new architecture: a hybrid Transformer. For the first time, it unifies visual reasoning, world generation, and action prediction into a single system.
It can natively understand and generate text, images, video, environmental sounds, and actions, achieving industry-leading levels of physical accuracy. It is the world's first fully open, omnimodal model. NVIDIA claims it has the potential to compress the physical AI training and evaluation cycle from months to days.
Jensen Huang predicted that due to breakthroughs in multimodal reasoning, language, vision, and world models, the big bang of Physical AI is imminent.
The open frontier omnimodal models in the Cosmos 3 series provide developers with a generational leap in capabilities to build robots, autonomous vehicles, and vision AI that can perceive, reason, plan, and act in the physical world.
Lowering the Barrier to Physical AI
NVIDIA and Unitree jointly launched the H2 Plus – a humanoid robot reference platform for researchers and developers.
"Reference platform" means: Unitree handles the robot hardware, NVIDIA handles the software and computing platform, with both sides pre-integrating the hardware and software. Development teams can start skill development immediately without spending time solving underlying integration issues. It is also the world's first open humanoid robot built on the NVIDIA Isaac GR00T development platform.
This reference platform targets a long-standing pain point in humanoid robot development: hardware integration, data collection, simulation, training, evaluation, and deployment are done in silos, making the entire process highly fragmented.
NVIDIA stated that research teams often spend a significant amount of time on underlying assembly after receiving a robot base, pushing actual skill development further down the line. The H2 Plus attempts to streamline this process, allowing research teams to skip underlying integration and directly engage in skill development and real-world validation.
In Jensen Huang's view, humanoid robots will bring physical AI to the world's largest industries, unlocking trillions of dollars in economic opportunity. The H2 Plus is the starting point for pushing cutting-edge research into real-world scenarios like factories, warehouses, and logistics systems.
Additionally, NVIDIA announced the formal open-sourcing of a set of Physical AI Skills tools, covering core scenarios including robotics, autonomous driving, vision AI, and industrial digital twins.
These "skills," in essence, are standardized operational instructions derived from NVIDIA's platforms like Cosmos, Omniverse, Isaac, and Metropolis, written in a format that Agents can directly read and execute. Packaging and open-sourcing these instructions constitutes the toolkit released this time.
When an Agent receives a task, such as generating training data for defect detection, it knows which model to call, what format to output, and how to verify results. The entire process runs automatically, without requiring human interaction at each step.
Upgrading AI Storage: From 'Speed' to 'Control'
At the San Jose GTC in March, NVIDIA released the Vera BlueField-4 STX. At


