
DeepSeek的十萬億美元之路:用開源撬動萬億硬體生態
- 核心觀點:DeepSeek的終極目標並非短期應用層變現,而是透過一系列底層架構創新(如MoE、MLA、DSA、Engram等),重塑AI訓練與推理的成本結構,推動一個規模達10萬億美元的中國AI硬體生態形成,並以此衝擊1萬億美元估值。
- 關鍵要素:
- DeepSeek的技術創新(如MLA、DSA、mHC)大幅壓縮了KV Cache體積,顯著降低對HBM的依賴,使得長上下文推理成本大幅下降。
- 透過將KV Cache卸載到SSD、使用LPDDR進行權重串流載入和Engram記憶體儲存,DeepSeek有效緩解了中國在高階GPU、HBM及先進封裝上的瓶頸。
- 這些創新將直接受益於中國本土硬體廠商:長江存儲(NAND/SSD)、長鑫存儲(LPDDR),並為眾多國產GPU/ASIC晶片廠商(如摩爾執行緒、沐曦)創造了可行的市場空間。
- DeepSeek對TileLang的投入,旨在透過一次編寫程式碼即可在多平台執行,間接削弱CUDA的護城河,推動中國AI硬體生態獨立發展。
- 透過大規模強化學習(RSI)和自動研究,DeepSeek旨在利用更多可選硬體和更低的計算成本,推進更具野心的訓練專案,為AGI做準備。
- DeepSeek可能效仿OpenAI模式,與中國硬體廠商達成股權合作(認股權證),在幫助對方成長的同時,透過生態紅利獲取遠超訂閱收入的巨大回報。
Original title: DeepSeek's 10 trillion USD grand strategy
Original author: @bookwormengr
Original translation: Peggy, BlockBeats
Editor’s note: Over the past year, discussions around DeepSeek have mostly focused on model performance, open-source strategy, and price wars. However, if we understand DeepSeek only through the lens of "whether it sells subscriptions," "whether it has multimodal capabilities," or "whether it can build a coding agent," we might underestimate what it truly aims to change.
This article proposes a more radical assessment: DeepSeek’s goal may not be short-term monetization through the application layer. Instead, through a series of underlying architectural innovations, it aims to reshape the cost structure of AI training and inference, indirectly fostering the formation of a new hardware ecosystem. From MoE, MLA to DSA, CSA, mHC, Engram, and then Dual Path and TileLang, DeepSeek’s technological roadmap has consistently revolved around one core question: how to run stronger models with less high-end computing power when constrained by HBM, advanced process nodes, packaging, and the CUDA ecosystem.
The most noteworthy aspect of this article is not "whether DeepSeek can earn hundreds of millions of dollars through APIs or subscriptions," but whether it is binding together model capabilities, memory systems, and the domestic hardware ecosystem. KV Cache compression reduces reliance on HBM, NAND and SSDs can handle long-term caching, LPDDR can be used for weight streaming and Engram storage, and TileLang aims to erode the CUDA moat. If these innovations continue to spread, the beneficiaries will not just be DeepSeek itself, but also storage, ASIC, GPU, networking chip companies, and the entire AI infrastructure chain.
Of course, the article’s judgments about a "10 trillion dollar industrial ecosystem" and a "1 trillion dollar valuation" are still heavily speculative. However, it provides an important path for understanding DeepSeek: open sourcing does not necessarily mean abandoning commercialization, and low prices are not necessarily just about subsidizing the market. For DeepSeek, the real business might not be in the application layer, but in helping make more hardware usable and enabling lower-cost AI supply. In other words, what it sells may not be the model itself, but the feasibility of the next generation of AI infrastructure.
The following is the original text:

Have you ever wondered how DeepSeek is going to make money, and potentially a lot of it?
It hasn't launched competitive coding subscription plans like GLM, MoonShot, and MiniMax. It also doesn't have multimodal, audio, or video models. So far, it doesn't even have its own harness—the outer operational framework for model invocation, tool integration, and task execution. Although they have recently started recruiting for relevant positions to build this system.
At the same time, DeepSeek seems firmly committed to the open-source side for the long term, even happily sharing its "secrets" publicly. Isn't this crazy? Isn't it just burning money? Are the investors planning to put 10 billion dollars into it just flushing their money down the drain?
Personally, I think the answer is quite the opposite.
Next, based on what DeepSeek has done so far, I will offer some observations and analyze a strategy it appears to be following. DeepSeek CEO Liang Wenfeng's ambition might extend far beyond the immediate model competition. He might be aiming for a much bigger prize: DeepSeek has the potential to reach a 1 trillion dollar valuation while driving the formation of a new 10 trillion dollar industry.

TechInAsia's report on DeepSeek's latest funding round
Revisiting DeepSeek's "Hero's Journey"
DeepSeek has been swimming against the current. It didn't choose to continuously release slightly stronger models and hastily package them into directly monetizable applications, like coding subscriptions. On January 27, 2025, I posted a widely circulated tweet describing what I saw as DeepSeek's "Hero's Journey." Now, the story has become even more interesting.
While others were trying to build dense models, DeepSeek opted for the more challenging to train Mixture of Experts (MoE) model.
Using a "first principles" approach, they invented the new GRPO algorithm to replace the mainstream but more expensive PPO reinforcement learning algorithm.
They discovered that Reinforcement Learning from Verified Rewards (RLVR) is a key strategy for enhancing model reasoning capabilities.
They also proposed a simple speculative decoding strategy through "Multi Token Prediction," while simultaneously making the training signal denser.
They perfected the "ZERO bubble" pipeline to improve the utilization efficiency of limited GPU resources.
They released an expert load balancer to make it easier for everyone to deploy MoE models. Specifically, through the "Wide Expert Parallel" strategy, models can be served with larger batches, significantly reducing inference costs.
They invented mechanisms like MLA, DSA, CSA, and HCA to reduce the demand for KV Cache and keep the computational demands of growing context lengths as close to constant as possible.
They invented Engram, trading memory for computational efficiency.
They also invented mHC, enabling stable training even as model scale increases. And many more similar examples exist.
In the most common narrative structure of the "Hero's Journey," the hero never decides exactly where his journey will lead from the start. He gradually discovers his truly great mission while learning along the way, and completes it amidst numerous obstacles. He encounters many skeptics but chooses to ignore them. He also faces many malicious actors. He has obvious flaws or shortcomings but ultimately overcomes them to fulfill his mission. He confronts seemingly insurmountable challenges, finds ways to form alliances, and learns to wisely use limited and precious resources. It is this that makes the audience want to cheer for the hero. This is also why DeepSeek has won followers, global respect, and opponents alike.
As I will detail next, DeepSeek has been on this path for a long time and is gradually discovering its ultimate destiny: its goal is not to sell coding subscriptions, but to drive a 10 trillion dollar Chinese AI hardware ecosystem and achieve a 1 trillion dollar valuation for itself. In this process, it will also create opportunities for many new entrants in the Western hardware ecosystem.

Let's start with some interesting KV Cache calculations
Check out this very timely post from @SemiAnalysis_:
DeepSeek has solved this problem better than anyone!
Let's do some fun KV Cache calculations. Don't worry if you don't like math. We'll use the recently released KV Cache calculator to see how much KV Cache savings DeepSeek V4 Pro offers, comparing it with the latest GLM and Qwen models.
Here I'm calculating with a context length of 1 million, assuming 8-bit KV precision and 16-bit indexer precision. You can also open this calculator and try it yourself: https://kvcache.ai/tools/kv-cache-calculator/
You can also open the calculator and try it yourself!
At a context length of 1 million:
·DeepSeek V4 needs only 5.48GB of HBM;
·GLM-5 needs 60GB of HBM;
·Qwen3-235B-A22B needs a whopping 89GB of HBM.
Note:
·DeepSeek is a 1.6 trillion parameter model;
·GLM-5 is approximately 700 billion parameters and already uses DeepSeek's MLA and DSA, but not the latest compressed attention mechanism;
·Qwen3-235B-A22B is approximately 235 billion parameters and uses the GQA attention mechanism.
DeepSeek has made fundamental contributions to alleviating memory pressure. If innovations like these are widely adopted, they will significantly reduce the operational costs of long-period agents and unlock the next wave of new applications.
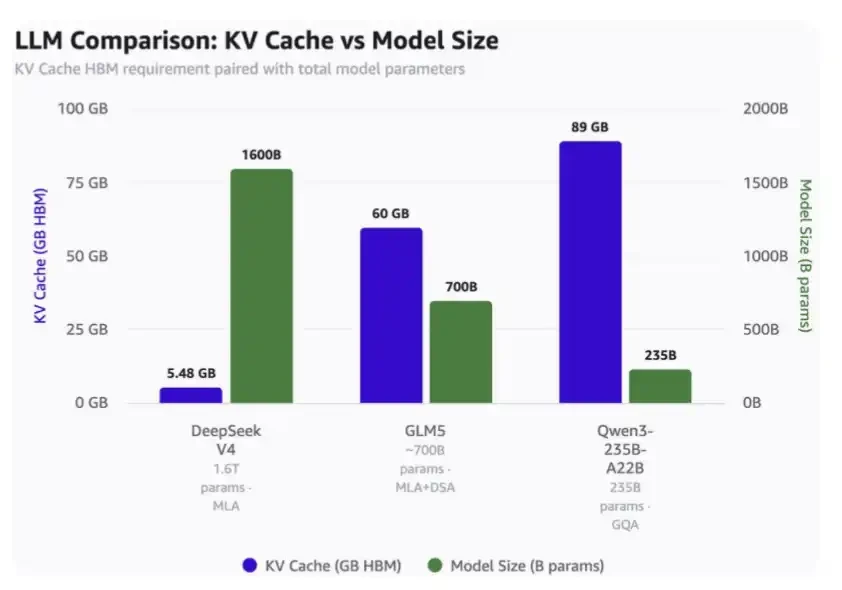
Comparison of KV Cache usage under 1 million token context and model scale
The Methodology Behind the "Madness"
The reason the KV Cache can be so small without sacrificing model quality is precisely why DeepSeek can offer long-term caching at incredibly low prices—less than 3% of the cost of a Sonnet 4.6 cache hit, and DeepSeek can retain the cache for several hours.
For long-duration tasks, a smaller KV Cache means it can be more economically offloaded to an SSD and reloaded when needed. This reduces reliance on HBM. From the perspective of the Chinese AI hardware industry, HBM is not only in tight supply but is also one of the most difficult memory types to manufacture.
Furthermore, DeepSeek has developed technology for faster loading of KV Cache from SSD, as described in its Dual Path paper.
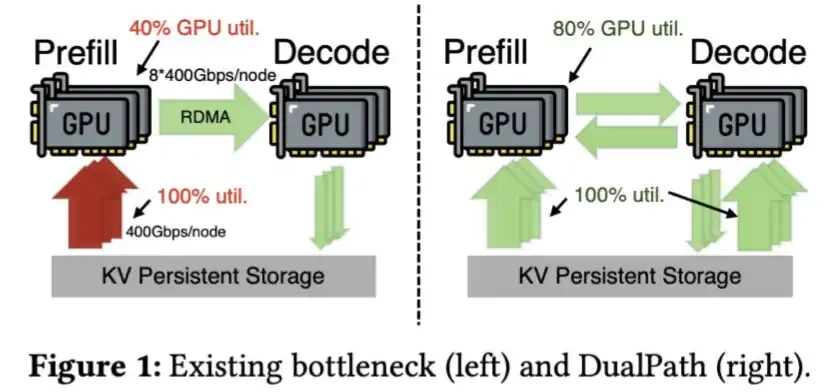
DeepSeek V4 compresses the KV Cache so aggressively that this step might not even be necessary anymore.
So, who is the most direct beneficiary of KV Cache compression?
Who is mass-producing SSDs? Remember, YMTC (Yangtze Memory Technologies) is growing into a giant in the 3D NAND space. NAND can help DeepSeek avoid recomputing KVs. In turn, DeepSeek creates a massive market for NAND and SSDs—benefiting not only YMTC but also other related manufacturers.

But it's not just about NAND and SSDs.
LPDDR memory also has immense potential. It can serve as a location to store model weights and stream these weights into HBM on demand, thus alleviating pressure on HBM. The SGLang team published a great blog post introducing this. The diagram below shows how this solution works.
Although DeepSeek hasn't specifically designed anything for this scheme, its MoE architecture, its inherently large number of expert models, and its 4-bit weights make this solution much easier to implement.
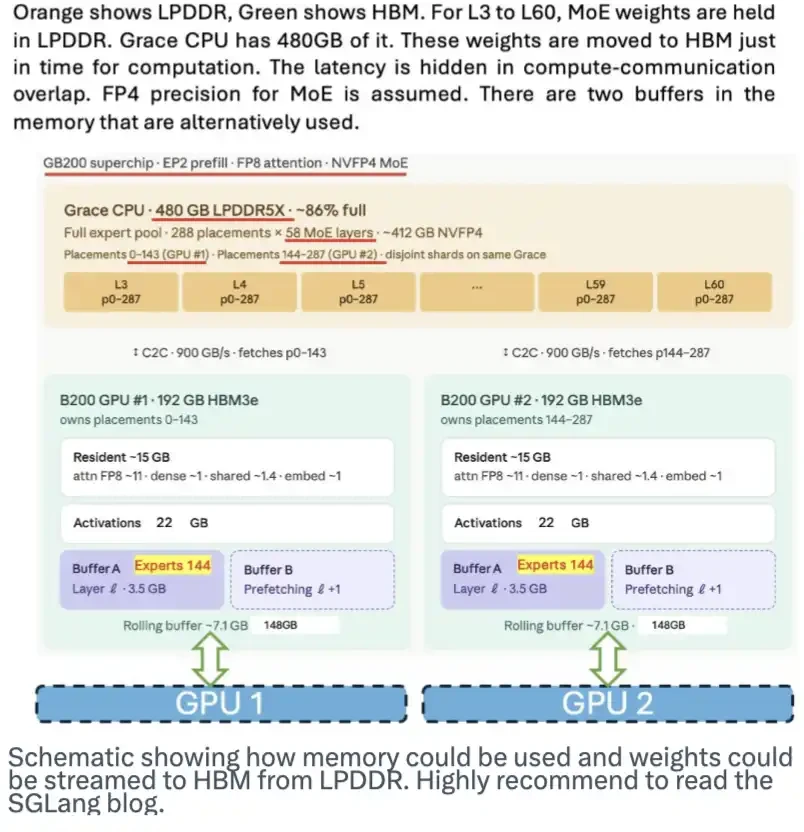
This diagram illustrates how memory might be used and how model weights could be streamed from LPDDR to HBM. I highly recommend reading the SGLang blog post.
This innovation, combined with extremely compact and lossless KV Cache, will significantly reduce the demand for HBM.
So, who produces LPDDR in China? The answer is CXMT, or Changxin Memory Technologies. They are only about half a generation behind in LPDDR speed and one generation behind in density—a relatively small gap.
Besides ample NAND, the Chinese AI ecosystem will soon have abundant LPDDR supply. Can this alleviate computing power pressure? The answer is: yes. Read on.

Using memory intelligently can also ease the pressure on GPUs / ASICs
The role of using NAND for KV Cache is easy to understand: it allows the KV Cache to be retained for longer, reduces pressure on HBM, and avoids recomputing the KV Cache, thereby easing the computational burden on GPUs and ASICs.
Can LPDDR also play a similar role? Besides being a storage location for streaming weights into HBM "just in time," can it further reduce computational pressure?
The answer is: yes.
LPDDR can be used to store large amounts of content known as Engrams. In DeepSeek's Engram paper, they point out that MoE can expand model capacity through conditional computation, but the Transformer itself lacks a native "knowledge lookup" mechanism. Therefore, Transformers often have to inefficiently simulate retrieval through computation.
To solve this, DeepSeek proposed the Engram module. It modernizes the classic N-gram embedding, transforming it into a hash-based O(1) lookup mechanism, creating a complementary sparse path they call conditional memory.
This approach saves computation but requires memory to hold the embedding table, which can itself be very large.
Essentially, this is a classic "trade memory for compute" approach. But the key insight is: the "memory" side is much cheaper in terms of cost per bit read—a single LPDDR lookup is far less expensive than having data pass through multiple Transformer layers for a forward computation. Therefore, at scale, this is a very worthwhile exchange.
This is how DeepSeek sacrifices some memory to achieve computational savings.
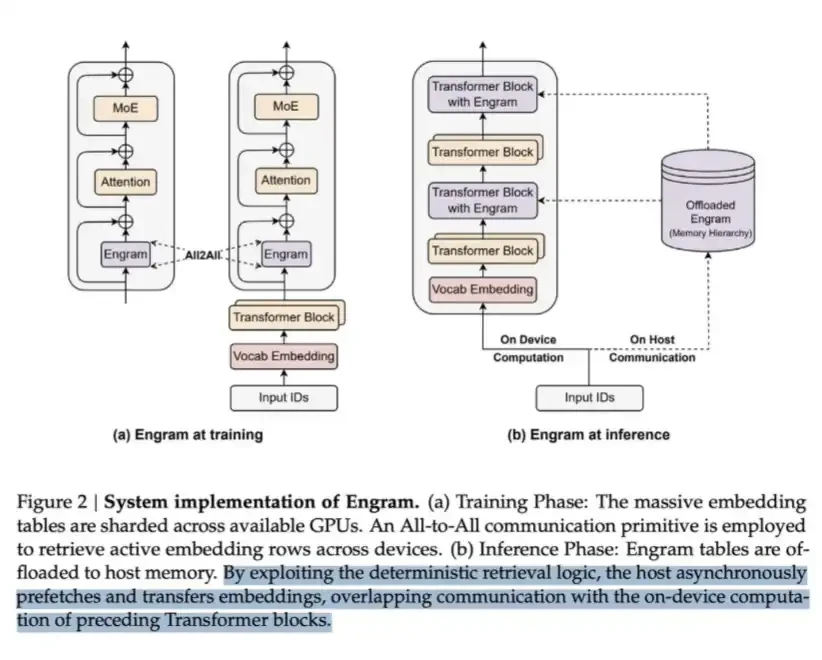
A worthwhile trade-off
Without equivalent chip transistor density and EUV lithography, Chinese GPUs and ASICs are likely to lag behind Western GPUs in raw FLOPs for the foreseeable future. They also still have significant gaps in advanced packaging. Therefore, this kind of trade-off is highly beneficial, especially given China's ability to mass-produce abundant NAND and LPDDR memory.
Reviewing DeepSeek's Long-Term Strategy
From these innovations, it seems DeepSeek's goal is not to make a few hundred million dollars in profit in the short term. Many of its past choices illustrate this: no multimodal capabilities yet, no voice model, let alone a video model.
It is truly engaged in a patient, potentially 10 trillion dollar long game: promoting the formation of an alternative AI hardware ecosystem.
This is not only about making Chinese memory manufacturers key players in the Chinese and global AI hardware markets, but also about fundamentally reducing resource requirements to make AI model training and serving more cost-effective. This allows many GPU, ASIC, and networking chip manufacturers to become viable options.
At the same time, these innovations will also benefit the Western open-source ecosystem and a new generation of hardware manufacturers.
All the signs are already there. Let's review in detail the innovations DeepSeek has proposed so far:
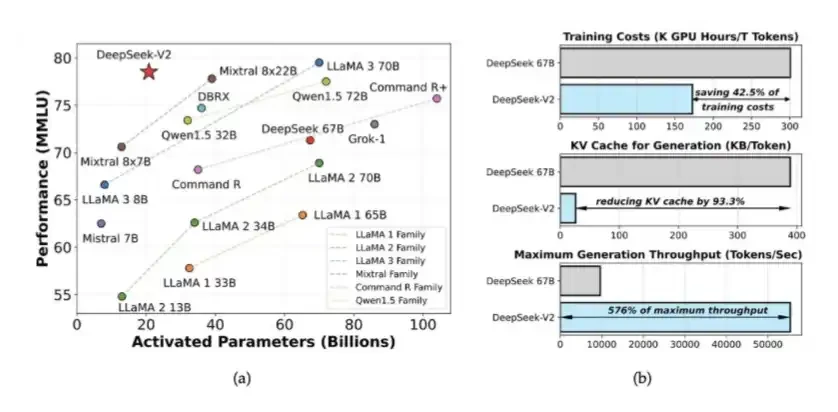
1. Mixture of Experts (MoE) and MLA introduced in DeepSeek V2
DeepSeek introduced MoE and MLA in V2. MoE reduced the computation required to train a highly intelligent model by about 40% to 50%; MLA reduced the KV Cache by 90%.
This made offloading the KV Cache to SSD quite efficient.
These ideas first appeared in DeepSeek's V2 paper released in May 2024. Later, they laid the foundation for training DeepSeek V3. At the time, DeepSeek trained a system with performance close to closed-source models using only 2048 crippled H800 GPUs.
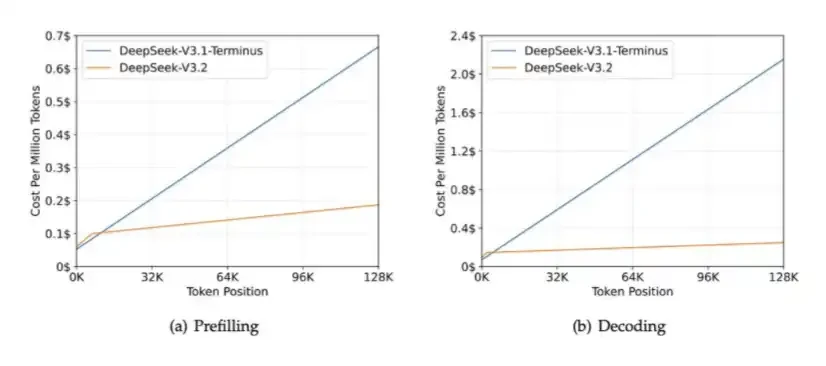
2. DSA: Introduced in DeepSeek V3.2 Exp to reduce computational overhead in long-context scenarios while alleviating HBM bandwidth pressure.
The core function of DSA is to ensure that computation does not grow continuously with context length. Look at the chart below: as context length increases, the processing time for DeepSeek-V3.2 remains largely stable.
3. mHC: Proposed by DeepSeek in a paper titled "mHC: Manifold-Constrained Hyper-Connections" in December 2025.
mHC is an innovation at the macro-architecture level, redesigning how information flows between Transformer layers.
Traditionally, since ResNet, models have used standard residual connections, i.e., x + F(x). mHC expands the residual stream into multiple parallel information channels and allows the model to perform learnable mixing between these channels. The key is constraining the mixing matrix to be a doubly stochastic matrix, i.e., projecting it onto the Birkhoff polytope via Sinkhorn-Knopp projection. This mathematically guarantees signal amplitude stability regardless of how deep


