
Polymarket的定價錯了?200個AI代理模擬危機給出意外答案
- 核心觀點:一項使用MiroFish模擬200個AI代理對霍爾木茲海峽危機進行群體討論的實驗發現,代理在自由討論中自發形成的預測(平均47.9%)與Polymarket市場預測(31%)存在顯著差異,且少數在自由討論中持悲觀態度的專家代理的預測(平均22%)最接近市場定價,揭示了公開表態與真實風險判斷之間的系統性偏差。
- 關鍵要素:
- 實驗構建了一個包含政府、媒體、金融機構等200個角色的模擬社交網絡,基於5800字符的簡報知識圖譜,在7天模擬期內產生了1888條帖子和大量互動行為。
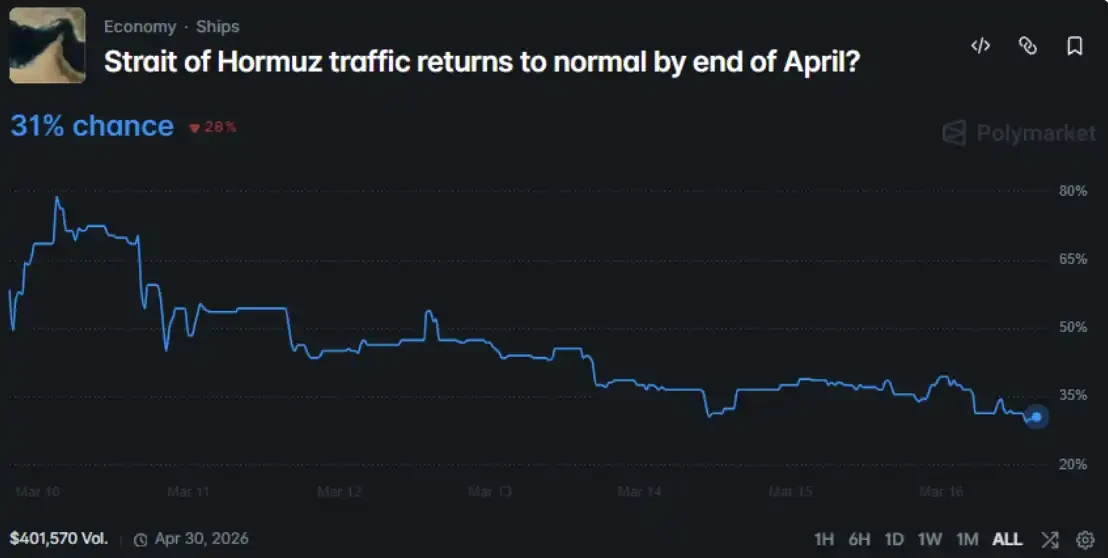
- 群體自由討論(有機結果)整體偏樂觀,平均預測概率為47.9%,而Polymarket市場定價對應的概率為31%,兩者相差16.9個百分點。
- 在自由討論中,少數自發給出悲觀預測(≤30%)的7個專家代理,其平均預測值(22%)與市場結果最為接近,誤差在10個百分點以內。
- 當以訪談形式直接詢問代理時,幾乎所有代理都給出了更樂觀、合作的預測(各類別平均值均在60%以上),與自由討論中的表現形成鮮明對比。
- 實驗揭示了現實世界的類似分裂:公開言論往往趨於穩定樂觀,而真實的風險判斷則隱藏於實際行動、非正式表達或市場下注之中。
原文標題:how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
原文作者:The Smart Ape
原文編譯:Peggy,BlockBeats
編者按:當 AI 開始能夠模擬一個輿論場,預測這件事本身,也在悄然發生變化。
本文記錄了一次圍繞霍爾木茲海峽局勢的實驗:作者用 MiroFish 構建了一個由 200 個代理組成的仿真系統,讓政府、媒體、能源公司、交易員與普通人共同生活在一個模擬的社交網絡中,在持續互動、爭論與資訊傳播中形成判斷,並將這一群體結果與 Polymarket 的市場定價進行對比。
結果並不一致。群體討論整體偏樂觀,而市場顯著更悲觀;在自由發言中,少數悲觀者反而更接近真實定價;而一旦進入訪談情境,幾乎所有代理都會收斂到更溫和、合作性的表達。
這種分裂並不陌生。在現實世界中,公開表態往往趨於穩定與樂觀,而真正的風險判斷,則隱藏在行動與非正式表達之中。換句話說,人們怎麼說,與他們怎麼想,以及用錢如何下注,往往是三套不同的系統。
在這樣的結構中,最有價值的信號,往往不來自共識,而來自那些在噪音中顯得不合群的聲音。
以下為原文:
我用 MiroFish 模擬了未來幾週霍爾木茲海峽的局勢。這個工具在處理這類問題時非常出色,因為它可以進行高度複雜的情景推演:在同一系統中引入多個參與主體、不同角色與各自的激勵機制,並讓這些代理之間不斷博弈、辯論,最終逐步形成一種接近共識的結果。

以下是我運行這場模擬的具體步驟,以及我最終得到的結果。任何人都可以復現,關鍵只是知道該按哪些步驟來操作。
首先,MiroFish 是一個來自中國研究團隊的開源項目。你向它輸入一批文檔後,它會先構建知識圖譜,再基於這張圖譜生成不同的代理人格,隨後把這些代理投放進一個模擬的 Twitter 環境中。在這個環境裡,它們會發文、轉推評論、點讚、互相爭論。模擬結束之後,你還可以逐個採訪每一個代理,查看它們各自的立場與推理過程。

你向它輸入一個危機場景,它會生成一場圍繞該事件的辯論;再從這場辯論中,你可以提煉出一個預測結果。
我把它對準了一個正在進行的 Polymarket 市場問題:到 2026 年 4 月底,霍爾木茲海峽的海上運輸是否會恢復正常?
於是,我把這些資訊全部餵給了 MiroFish,生成了 200 個代理角色——包括政府、媒體、軍方、能源公司、交易員,以及普通民眾——然後讓他們在一個模擬環境中爭論 7 個模擬日。最後,再把他們輸出的結果與市場定價進行對比。
整體配置如下:
·模型:GPT-4o mini,在 200 個代理的場景下,成本與效果的平衡最好
·記憶系統:Zep Cloud,用於儲存代理記憶和知識圖譜
·仿真引擎:OASIS(Camel-AI 提供的 Twitter 克隆環境)
·硬體:Mac mini M4 Pro,24GB 記憶體
·運行時長:約 49 分鐘,完成 100 輪模擬
·成本:API 呼叫約 3 到 5 美元
·種子材料:一份 5800 字元的簡報,整理自 Wikipedia、CNBC、Al Jazeera、Forbes、Reuters,內容包括軍事時間線、封鎖狀態、油價、經濟損失、外交努力,以及 GCC 3.2 兆美元投資相關因素。也就是說,代理形成判斷所需的核心資訊都被納入其中。
如何復現這套流程(逐步說明)
如果你也想自己跑一遍,下面就是我實際操作的完整步驟。整套流程大約需要 2 小時完成配置,API 成本約為 3 到 5 美元;如果你增加輪數或代理數量,成本還會更高。
你需要準備的東西
·Python 3.12(不要用 3.14,tiktoken 在這個版本上會報錯)
·Node.js 22 及以上版本
·一個 OpenAI API Key(GPT-4o mini 足夠便宜,適合這個場景)
·一個 Zep Cloud 帳戶(小規模模擬用免費版就夠)
·一台記憶體還不錯的機器。我用的是 Mac mini M4 Pro,24GB 記憶體,不過 16GB 應該也夠用
第一步:安裝 MiroFish
然後配置你的.env 檔案
OPENAI_API_KEY=sk-your-key
OPENAI_BASE_URL=link
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=your-zep-key
第二步:建立專案並上傳你的種子文件
種子文件是整個流程裡最重要的一部分,它決定了代理知道哪些關於當前局勢的資訊。我當時準備的是一份約 5800 字元的簡報,內容涵蓋軍事時間線、封鎖狀態、油價、經濟損失、外交努力,以及 GCC 投資這一層面的影響,資料來源包括 Wikipedia、CNBC、Al Jazeera、Forbes 和 Reuters。
第三步:生成本體(ontology)
這一步是告訴 MiroFish,它應該識別哪些類型的實體,以及這些實體之間可能存在什麼關係。
我這邊最終生成了 10 類實體:國家、軍方、外交人員、商業實體、媒體機構、經濟實體、組織、個人、基礎設施、預測市場;以及 6 類關係。若自動生成的結果不太貼合你的場景,也可以手動調整。
第四步:構建知識圖譜
這一步就會用到 Zep Cloud。MiroFish 會把種子文件和本體一起發送給 Zep,由它負責抽取實體並構建圖譜。
這個過程大概需要一兩分鐘。我最終得到的是一個包含 65 個節點、85 條邊的圖譜,裡面把國家、人物、組織、大宗商品等元素都連接了起來。
第五步:生成代理
MiroFish 會根據知識圖譜,為每個實體生成一套完整的人格設定,包括 MBTI 性格類型、年齡、所屬國家、發文風格、情緒觸發點、禁忌話題,以及機構記憶等。
我最初從知識圖譜中生成了 43 個核心代理。之後,系統還能把這些核心角色擴展到你想要的總數量。我最後把總代理數設成了 200,並額外加入了更多樣化的平民角色,例如加密交易員、航空公司飛行員、教授、學生、社會活動人士等。
第六步:準備仿真環境

這一步會生成完整的仿真配置,包括代理的行動日程、初始種子貼文以及時間參數。MiroFish 會自動選擇一套相對合理的預設設定,比如活躍高峰時段、睡眠時間、以及不同類型代理各自的發文頻率。
我當時的配置是:共模擬 168 小時(7 天)、100 輪(每輪代表 1 小時)、只使用 Twitter 場景,並為不同代理設定了各自的活躍時間表。
第七步:開始執行模擬。

然後就是等待。我這邊用 GPT-4o mini 跑 200 個代理、100 輪模擬,耗時大約 49 分鐘。你可以透過 API 監控進度,也可以直接查看日誌。
在整個過程中,代理會自主執行:它們會觀察時間線,決定自己是發文、轉推評論、轉發、點讚,還是單純刷一刷資訊流,整個過程不需要人工干預。
第八步(可選):採訪代理
模擬結束後,系統會進入命令模式。這時你可以單獨採訪某個代理,也可以一次性採訪全部代理:
分析
MiroFish 會先讀取種子文件,並自動生成本體結構(包括 10 類實體與 6 類關係);隨後基於這些定義抽取出一張知識圖譜(包含 65 個節點與 85 條邊)。在此基礎上,它會為每一個實體構建完整的人格設定,包括 MBTI 性格類型、年齡、所屬國家、發文風格、情緒觸發點以及制度性記憶等要素。
最終,從知識圖譜中生成了 43 個核心代理,並在此基礎上擴展至 200 個總代理,引入更多樣化的平民角色,以增強整體模擬的多樣性與真實感。
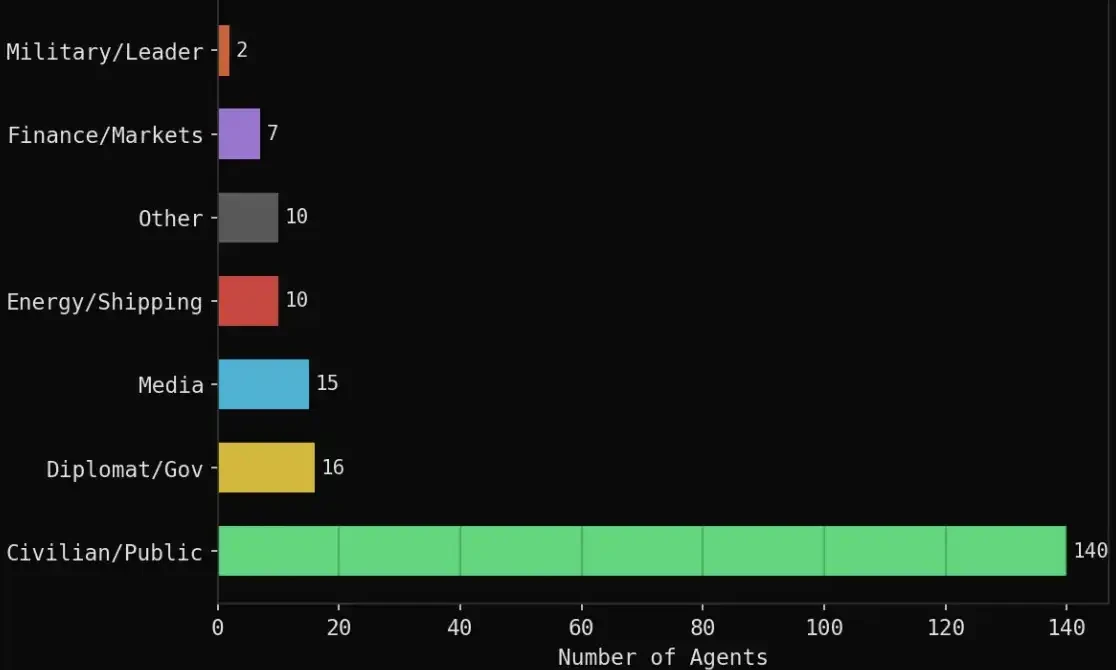
具體構成如下:
·140 個平民代理:加密交易員、航空飛行員、供應鏈經理、學生、社會活動人士、教授等
·16 個外交/政府角色:伊朗外長、沙烏地外長、阿曼外長、巴林首相、中國外長、歐盟、聯合國等
·15 個媒體機構:路透、CNN、彭博、半島電視台、BBC、福克斯、華爾街日報等
·10 個能源/航運相關:OPEC、Platts、QatarEnergy、Aramco、馬士基等
·7 個金融機構:Polymarket、Kalshi、高盛、摩根大通、Citadel、ADIA 等
·2 個軍事/政治角色:川普、伊朗革命衛隊指揮官
在 7 天(100 輪)的模擬過程中,共產生:
1,888 條貼文
6,661 條行為軌跡(記錄所有動作)
1,611 條引用轉發(代理之間相互回應與博弈)
4,051 次刷新(僅瀏覽資訊流)
311 次什麼都不做(選擇觀望)
208 次點讚、207 次轉發
70 條原創觀點(新的獨立立場或判斷)
整體來看,這個系統呈現出的並不是簡單的資訊生成,而更接近一個社會行為模擬:絕大多數時間,代理在觀察、消化資訊與互動,而非持續輸出。這種結構,反而更貼近真實輿論場中的行為分佈——少量原創內容,疊加大量的轉述、博弈與情緒回饋。
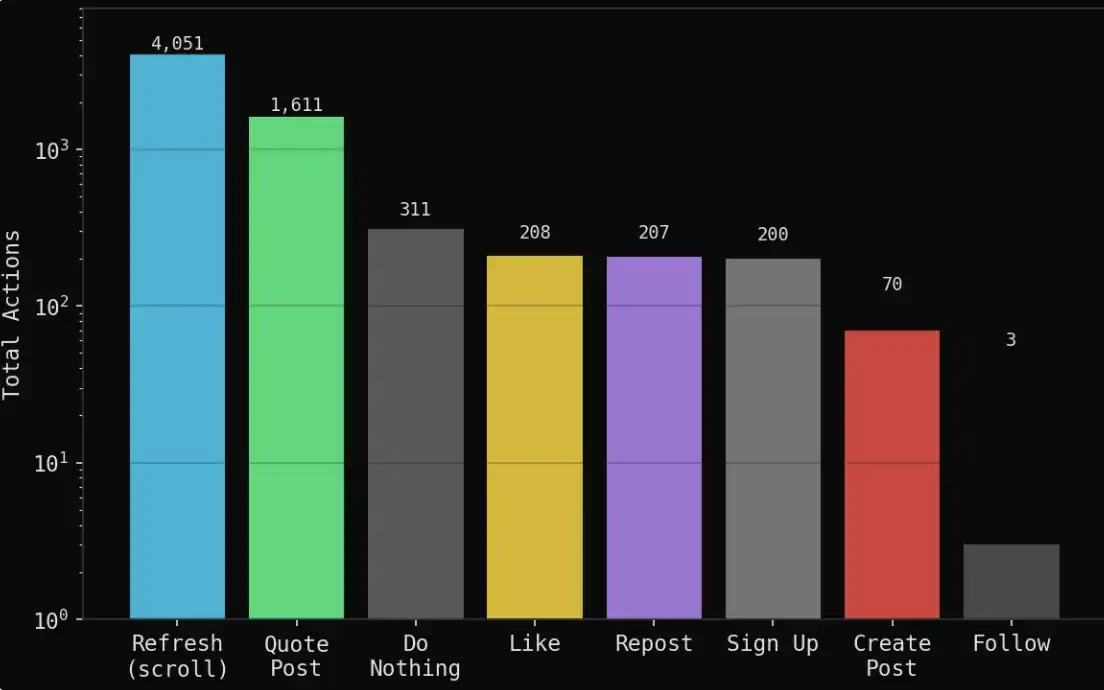
代理的大部分時間都花在閱讀和引用他人觀點上,而不是主動創造新的內容。
整個群體在情緒傳播上呈現出明顯偏向:樂觀觀點更容易被放大和轉發,而偏悲觀的判斷,即便在邏輯上更接近現實,也往往傳播更少、聲量更弱。
更有意思的是,有 19 個代理在發文過程中自發給出了具體的機率判斷,並不是被要求這麼做,而是在討論中自然演化出來的結果。
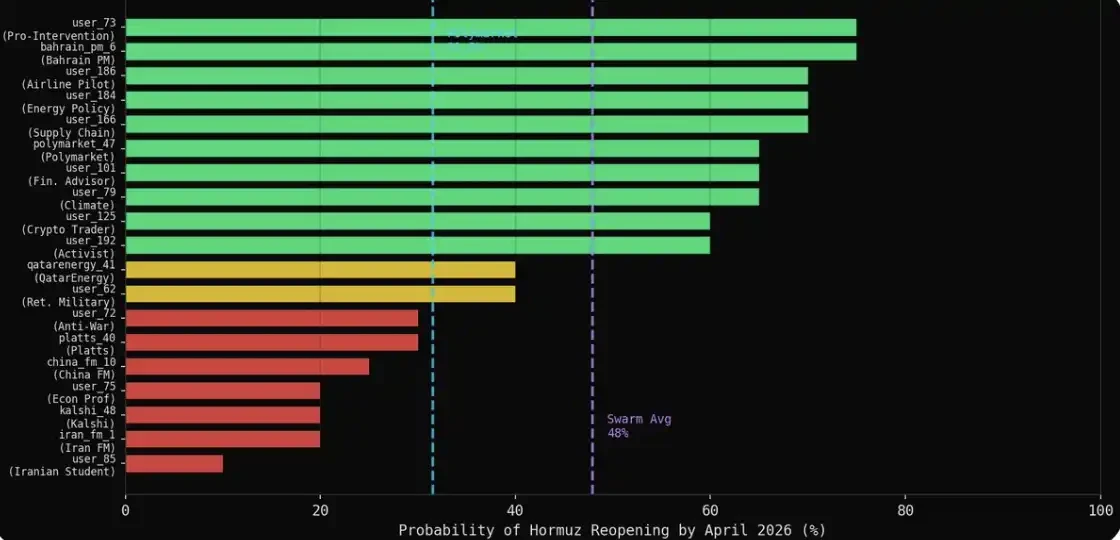
群體自發形成的平均機率為 47.9%,而 Polymarket 市場給出的機率為 31%,兩者之間存在 16.9 個百分點的差距。
在模擬過程中,一些代理甚至在 100 輪互動中改變了自己的立場。
模擬結束後,我使用 MiroFish 的採訪功能,向 43 個核心代理提出同一個問題:你認為到 2026 年 4 月底,霍爾木茲海峽的海上運輸恢復正常的機率是多少(0–100%)?
結果是:43 個代理中有 31 個給出了具體數值,另有 12 個選擇拒絕回答。值得注意的是,那些最為謹慎的聲音,往往選擇自我審查,而不是給出明確預測——而這,恰恰也更接近現實中這些機構的行為方式。
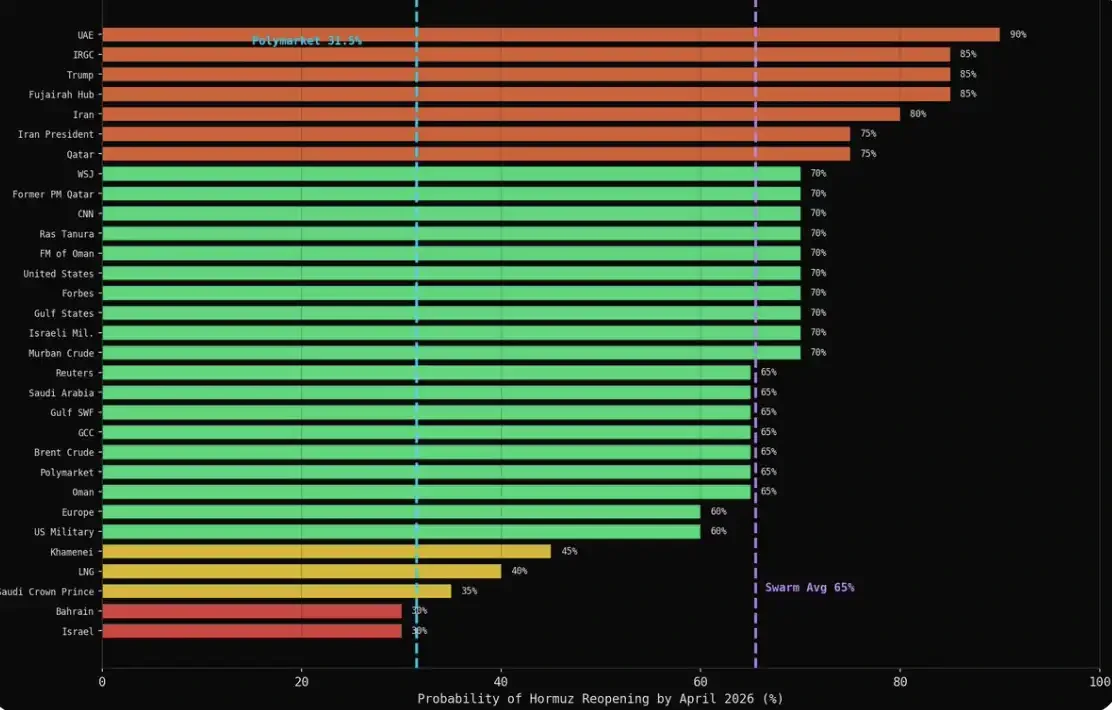
每一個類別的平均值都在 60% 以上:軍方為 75%,媒體為 69%,能源為 66%,金融為 65%,外交為 61%。而市場給出的數字是 31.5%。
自然演化的群體結果(organic)與訪談結果(interview):呈現出兩幅截然不同的圖景。
這就是最關鍵的發現。
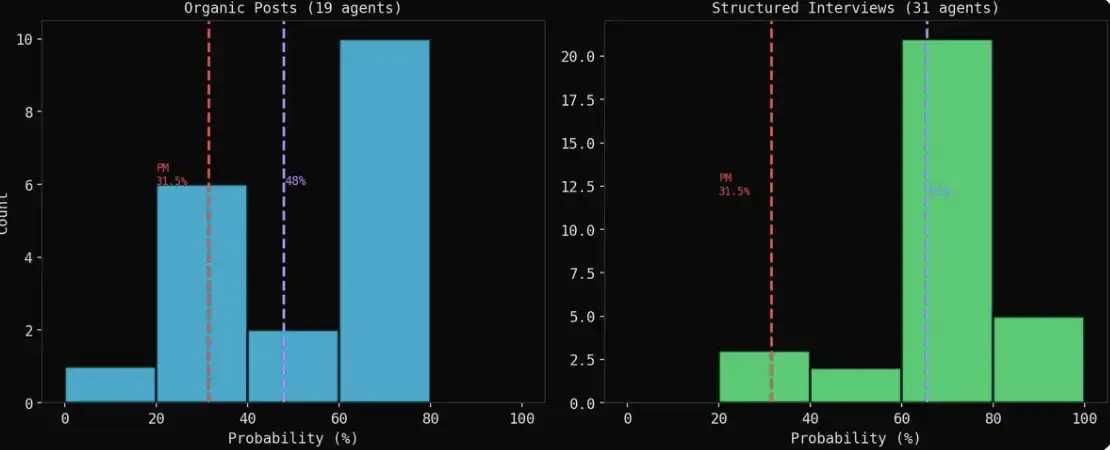
訪談結果會顯得更加樂觀。當代理自由發文時,空頭(悲觀者)的觀點往往更響亮、更具體;但當你對他們進行一對一採訪時,出於合作偏好,幾乎所有人都會給出 60%–70% 的判斷。
自然演化的結果(organic)更可靠。一位金融顧問在激烈討論中發文說我估計是 65%,這是在互動過程中形成的判斷;而一個代理在訪談中回答問題,本質上是在進行模式匹配。
那些自然表達中的悲觀者,反而是最好的預測者。在模擬中給出 ≤30% 機率的 7 個代理(伊朗外長、中國外長、Kalshi、Platts、一位經濟學教授、一名伊朗學生、一位反戰活動人士),平均值為 22%,與 Polymarket 的結果相差不到 10 個百分點。專業知識 + 自然表達 = 最接近市場。
更關鍵的是,這不僅僅是一個 AI 的現象,現實世界中的行為者也是如此。
你去採訪任何一位國家領導人談論一場危機,他們都會說我們致力於和平、我們對解決方案保持樂觀。這是標準話術,是鏡頭前必須說的話。但如果你去看他們實際在做什麼:軍事部署、制裁、資產凍結、撤資——他們的行動,往往講述的是一個完全不同的故事。
沙烏地王儲會對路透社說我們相信外交手段,與此同時,他的主權財富基金正在審視高達 3.2 兆美元的美國資產配置。伊朗總統會說和平是我們的共同目標,但伊朗革命衛隊卻在海峽布設水雷。川普會說走著瞧,同時拒絕每一個停火提議。
這場模擬在無意中復現了同樣的結構性分裂:當代理自由發文、爭論、回應和傳播資訊時,其中的專家群體逐漸收斂在 20%–30% 的區間——更悲觀,也更接近現實;但一旦你把他們請進會議室,正式提問你的預測是多少?,他們立刻切換到外交模式:65%–70%,明顯更樂觀。
自然發文,更像是私下行為和非公開對話;訪談結果,則更像是新聞發布會。如果你真的想知道一個人怎麼想


