
YBB Capital:潛力賽道前瞻-去中心化算力市場(上)
原文作者:Zeke, YBB Capital

前言
自GPT-3 誕生以來,生成式AI 以其驚人的表現以及廣闊的應用場景,讓人工智能領域迎來了爆炸式的轉折點,科技巨頭開始扎堆抱團跳入AI 賽道。但問題也隨之而來,大型語言模型(LLM)訓練和推理的運作需要大量算力支撐,伴隨著模型的迭代升級,算力需求和成本更是指數級的增加。以GPT-2 和GPT-3 為例,GPT-2 和GPT-3 之間的參數量相差1166 倍(GPT-2 為1.5 億參數,GPT-3 為1750 億參數),GPT-3 的一次訓練成本以當時公有GPU 雲的價格模型計算最高可達1,200 萬美元,為GPT-2 的200 倍。而在實際使用過程中,用戶的每次提問都需要推理運算,以今年年初1300 萬獨立用戶訪問的情況來說,對應的芯片需求是3 萬多片A 100 GPU。那麼初始投入成本將達到驚人的8 億美元,每日模型推理費用預估費用為70 萬美元。
算力不足和成本過高成為整個AI 產業面臨的難題,然而同樣的問題似乎也將困擾區塊鏈產業。一方面比特幣的第四次減半與ETF 通過即將到來,隨著未來價格攀升,礦商對於算力硬件的需求必然大幅提高。而另一方面零知識證明("Zero-Knowledge Proof",簡稱ZKP)技術正在蓬勃發展,Vitalik 也曾多次強調ZK 在未來十年內對區塊鏈領域的影響將與區塊鏈本身一樣重要。雖然這項技術的未來被區塊鏈產業寄予厚望,但ZK 由於復雜的計算過程,在生成證明過程中同AI 一樣也需要消耗大量的算力和時間。
在可預見的未來裡,算力短缺將成為必然,那麼去中心化算力市場是否會是一門好生意?
去中心化算力市場定義
去中心化算力市場其實基本上等價於去中心化雲端運算賽道,但相較於去中心化雲端運算,我個人認為這個詞來描述之後所講的新項目會更為貼切。去中心化算力市場應屬於DePIN(去中心化實體基礎設施網絡)的子集,其目標旨在創建一個開放的算力市場,透過代幣激勵使得任何擁有閒置算力資源的人都可以在此市場上提供他們的資源,主要服務B 端用戶及開發者群。從更熟悉的項目來說,例如基於去中心化GPU 的渲染解決方案網絡Render Network 和用於雲端運算的分散式點對點市場Akash Network 都屬於這條賽道。
而下文將從基礎概念開始,再展開討論該賽道下的三個新興市場:AGI 算力市場、比特幣算力市場以及ZK 硬件加速市場中的AGI 算力市場,後兩個將在《潛力賽道前瞻:去中心化算力市場(下)》中進行討論。
算力概述
算力概念的起源可以追溯到計算機發明之初,最初的計算機是由機械裝置完成計算任務,而算力指的是機械裝置的計算能力。隨著電腦科技的發展,算力的概念也隨之演化,現在的算力通常指的是電腦硬件(CPU、GPU、FPGA 等)和軟件(操作系統、編譯器、應用程序等)協同工作的能力。
定義
算力(Computing Power)是指電腦或其他計算設備在一定時間內可以處理的資料量或完成的計算任務的數量。算力通常被用來描述電腦或其他計算設備的效能,它是衡量一台計算設備處理能力的重要指標。
衡量標準
算力可以用各種方式來衡量,例如計算速度、計算能耗、計算精度、並行度。在電腦領域,常用的算力衡量指標包括FLOPS(每秒浮點運算次數)、IPS(每秒指令數)、TPS(每秒事務數)等。
FLOPS(每秒浮點運算次數)是指電腦處理浮點運算(有小數點的數字進行數學運算,需要考慮精度問題和捨去誤差等問題)的能力,它衡量的是電腦每秒能夠完成多少次浮點運算。 FLOPS 是衡量電腦高效能運算能力的指標,通常用於衡量超級電腦、高效運算伺服器和圖形處理器(GPU)等的運算能力。例如,一個電腦系統的FLOPS 為1 TFLOPS(1 兆次浮點運算每秒),表示它每秒可以完成1 兆次浮點運算。
IPS(每秒指令數)是指電腦處理指令的速度,它衡量的是電腦每秒能夠執行多少條指令。 IPS 是衡量電腦單指令效能的指標,通常用來衡量中央處理器(CPU)等的效能。例如,一個CPU 的IPS 為3 GHz(每秒可執行3 億次指令),表示它每秒可以執行3 億次指令。
TPS(每秒交易數)是指電腦處理交易的能力,它衡量的是電腦每秒可以完成多少個交易。通常用於衡量數據庫服務器的效能。例如,一個資料庫伺服器的TPS 為1000 ,表示它每秒可以處理1000 個資料庫事務。
此外,還有一些針對特定應用情境的算力指標,例如推理速度、影像處理速度、語音辨識準確率。
算力的類型
GPU 算力指的是圖形處理器(Graphics Processing Unit)的運算能力。與CPU(Central Processing Unit)不同,GPU 是專門設計用於處理影像和視頻等圖形資料的硬件,它具有大量的處理單元和高效的並行運算能力,可以同時進行大量的浮點運算。由於GPU 最初是用於遊戲圖形處理的,因此它們通常比CPU 具有更高的時鐘頻率和更大的記憶體帶寬,以支援複雜的圖形運算。
CPU 和GPU 的區別
架構:CPU 和GPU 的運算架構不同。 CPU 通常採用一或多個核心,每個核心都是通用的處理器,能夠執行各種不同的操作。而GPU 則有大量的流處理器(Stream Processors)和著色器(Shader),這些處理器專門用於執行影像處理相關的運算;
並行運算:GPU 通常具有更高的並行運算能力。 CPU 的核心數量有限,每個核心只能執行一條指令,但GPU 可以擁有數千個流處理器,可以同時執行多個指令和操作。因此,GPU 通常比CPU 更適合執行平行運算任務,例如機器學習和深度學習等需要大量並行運算的任務;
程式設計:GPU 的程式設計相對於CPU 來說更為複雜,需要使用特定的程式語言(如CUDA 或OpenCL),並使用特定的程式設計技巧來利用GPU 的並行運算能力。相較之下,CPU 的程式設計更為簡單,可以使用通用的程式語言和程式設計工具。
算力的重要性
在工業革命時代,石油是世界的血液,滲透到各個產業之中。算力在區塊鏈中而在即將到來的AI 時代,算力會是全世界的「數字石油」。從各大企業對於AI 晶片的瘋搶以及Nvidia 股票突破萬億,再到美國近期對中國的高端芯片封鎖詳細到算力大小、芯片面積,甚至計劃禁用GPU 雲,其重要性已不言而喻,算力將是下個時代的大宗商品。

人工通用智慧概述
人工智能(Artificial Intelligence),是研究、開髮用於模擬、延伸和擴展人的智慧的理論、方法、技術及應用系統的一門新的技術科學。它起源於20 世紀五、六十年代,經過半個多世紀的演變,經歷了符號主義、連接主義和行為主體三次浪潮的相互交織發展,到如今,作為一項新興的通用技術,正在推動著社會生活與各行各業的巨變。而現階段常見的生成式AI 更具體的定義是:人工通用智能(Artificial General Intelligence, 簡稱AGI),一種具有廣泛理解能力的人工智能係統,它能在多種不同任務和領域中表現出與人類相似或超越人類的智慧。 AGI 基本上需要三個要素組成,深度學習(deep learning,簡稱DL)、大數據、大規模算力。
深度學習
深度學習是機器學習(ML)的一個子領域,深度學習演算法是仿照人腦建模的神經網路。例如,人腦包含數百萬個相互關聯的神經元,它們協同工作以學習和處理資訊。同樣,深度學習神經網絡(或人工神經網絡)是由在電腦內部協同工作的多層人工神經元組成的。人工神經元是稱為節點的軟體模組,它使用數學計算來處理資料。人工神經網路是使用這些節點來解決複雜問題的深度學習算法。
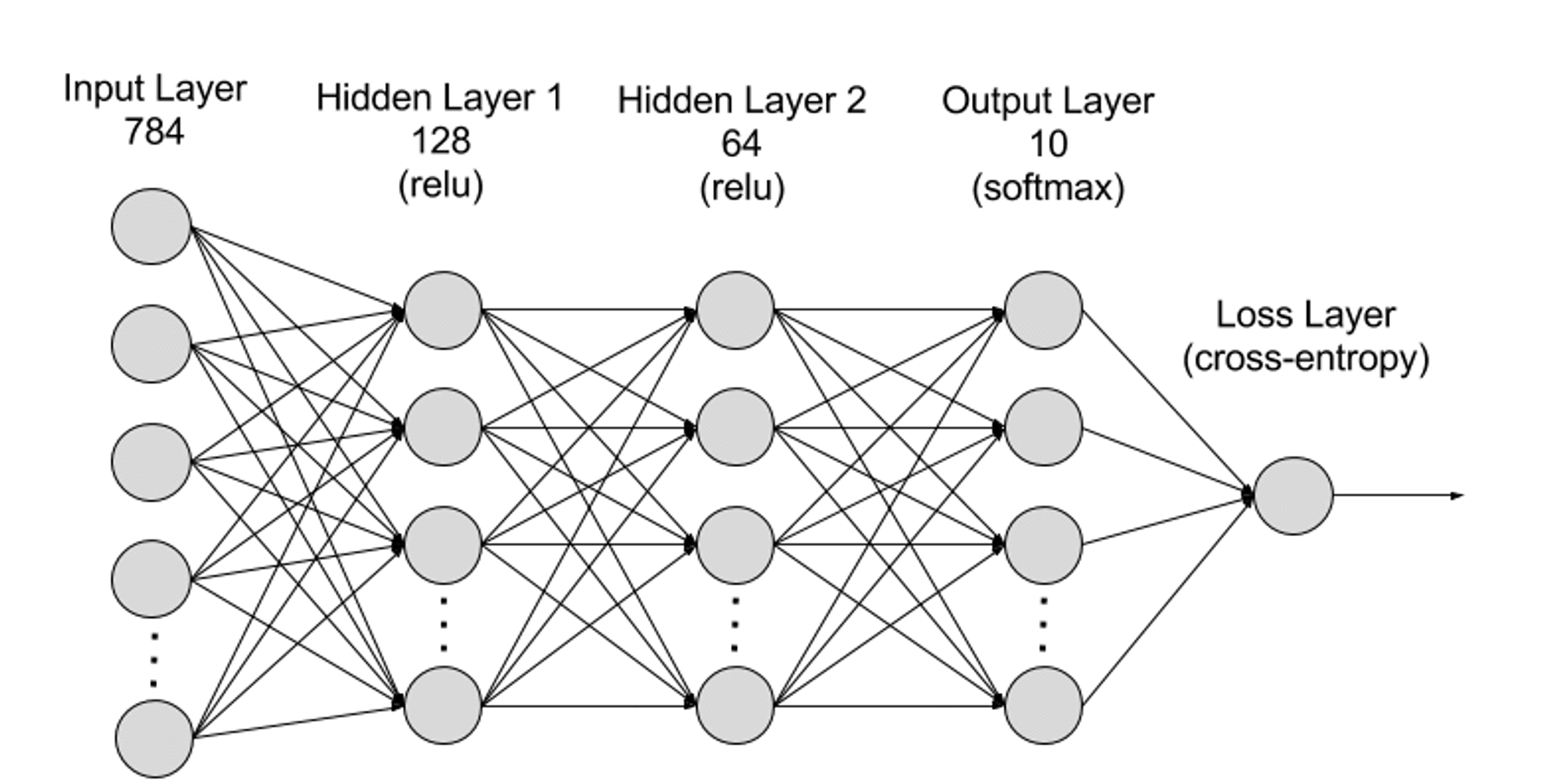
從層次劃分神經網絡可分為輸入層、隱藏層、輸出層,而不同層之間連接的便是參數。
輸入層(Input Layer):輸入層是神經網絡的第一層,負責接收外部輸入資料。輸入層的每個神經元對應於輸入資料的一個特徵。例如,在處理影像資料時,每個神經元可能對應於影像的一個像素值;
隱藏層(Hidden Layers):輸入層處理資料並將其傳遞到神經網絡中更遠的層。這些隱藏層在不同層級處理訊息,在接收新訊息時調整其行為。深度學習網絡有數百個隱藏層,可用於從多個不同角度分析問題。例如,你得到了一張必須分類的未知動物的圖像,則可以將其與你已經認識的動物進行比較。例如透過耳朵形狀、腿的數量、瞳孔的大小來判斷這是什麼動物。深度神經網絡中的隱藏層以相同的方式運作。如果深度學習演算法試圖對動物影像進行分類,則其每個隱藏層都會處理動物的不同特徵並嘗試對其進行準確的分類;
輸出層(Output Layer):輸出層是神經網路的最後一層,負責產生網路的輸出。輸出層的每個神經元代表一個可能的輸出類別或值。例如,在分類問題中,每個輸出層神經元可能對應於一個類別,而在回歸問題中,輸出層可能只有一個神經元,其值表示預測結果;
參數:在神經網絡中,不同層之間的連接由權重(Weights)和偏壓(Biases)參數表示,這些參數在訓練過程中被優化以使網絡能夠準確地識別資料中的模式和進行預測。參數的增加可以提高神經網絡的模型容量,也就是模型能夠學習和表示資料中複雜模式的能力。但相對應的是參數的增加會提升對算力的需求。
大數據
為了有效訓練,神經網絡通常需要大量、多樣且高品質且多來源的資料。它是機器學習模型訓練和驗證的基礎。透過分析大數據,機器學習模型可以學習數據中的模式和關係,從而進行預測或分類。
大規模算力
神經網絡的多層複雜結構、大量參數、大數據處理需求、迭代訓練方式(在訓練階段,模型需要重複迭代,訓練過程中需要對每一層計算前向傳播和反向傳播,包括激活函數的計算、損失函數的計算、梯度的計算和權重的更新)、高精度計算需求、平行計算能力、優化和正則化技術以及模型評估和驗證過程共同導致了對高算力的需求,隨著深度學習的推進,AGI 對大規模算力的要求每年增加10 倍左右。目前截止最新的模型GPT-4 包含1.8 兆參數,單次訓練成本超6000 萬美元,所需算力2.15 e 25 FLOPS(21500 兆次浮點計算)。而接下來的模型訓練對算力的需求還在擴大,新的模型也不斷增加。
AI 算力經濟學
未來市場規模
根據最權威的測算,國際數據公司IDC(International Data Corporation)與浪潮資訊和清華大學全球產業研究院聯合編制的《 2022-2023 全球計算力指數評估報告》,全球AI 計算市場規模將從2022 年的195.0 億美元成長到2026 年的346.6 億美元,其中生成式AI 運算市場規模將從2022 年的8.2 億美元成長到2026 年的109.9 億美元。生成式AI 運算佔整體AI 運算市場的比例將從4.2% 成長到31.7% 。
算力經濟壟斷
AI GPU 的生產已被NVIDA 獨家壟斷,還極其昂貴(最新的H 100 ,單片售價已炒至4 萬美元),並且GPU 一經發售就遭矽谷巨頭搶走一空,這些設備的其中一部分用於自家新模型的訓練。而另外一部分則透過雲端平台出租給AI 開發者,如Google、Amazon 和Microsoft 的雲端運算平台掌握了大量的伺服器、GPU 和TPU 等算力資源。算力已然成為巨頭壟斷的新資源,大量AI 相關開發者甚至購買不到一張不加價的專用GPU,為了使用最新的設備,開發者不得不租用AWS 或Microsoft 的雲端伺服器。從財報上看這項業務擁有極高的利潤,AWS 的雲端服務有61% 的毛利率,而微軟則更高有72% 的毛利率。

那麼我們是否不得不接受這種集中式的權威和控制,並為算力資源支付72% 的利潤費用?壟斷Web2的巨頭還會壟斷下一個時代嗎?
去中心化AGI 算力的難題
提到反壟斷,去中心化通常都是最優解,從現有的項目看我們是否能通過DePIN 中的存儲項目加RDNR 之類的空閒GPU 利用協議來實現AI 所需的大規模算力?答案是否定的,屠龍的道路並沒有那麼簡單,早期的項目並沒有為AGI 算力而專門設計,不具備可行性,算力上鍊至少需要面臨以下五個挑戰:
1.工作驗證:建立一個真正無需信任的計算網絡,並為參與者提供經濟激勵,網絡必須有辦法驗證深度學習計算工作是否實際執行。這個問題的核心是深度學習模型的狀態依賴;在深度學習模型中,每一層的輸入都依賴前一層的輸出。這意味著,不能僅僅驗證模型中的某一層而不考慮它之前的所有層。每一層的計算都是基於它前面所有層的結果。因此,為了驗證特定點(例如特定的層)完成的工作,必須執行從模型的開始到那個特定點的所有工作;
2.市場:AI 算力市場作為一個新興市場受制於供需困境,例如冷啟動問題,供應和需求流動性需要從一開始就大致匹配,以便市場能夠成功地成長。為了捕捉潛在的算力供應,必須為參與者提供明確的獎勵以換取他們的算力資源。市場需要一個機制來追蹤完成的計算工作,並及時向提供者支付相應的費用。在傳統的市場中,中介負責處理管理和入職等任務,同時透過設定最低支付額度來減少營運成本。然而,這種方式在擴展市場規模時成本較高。只有一小部分供應能夠在經濟上被有效捕獲,這導致了一個閾值平衡狀態,即市場只能捕獲和維持有限的供應,而無法進一步增長;
3.停機問題:停機問題是計算理論中的一個基本問題,它涉及判斷一個給定的計算任務是否會在有限的時間內完成或永遠不會停止。這個問題是不可解的,這意味著不存在一個通用的演算法能夠對所有的計算任務預判它們是否會在有限時間內停止。例如在以太坊上智慧合約執行也面臨類似的停機問題。即無法預先決定一個智慧合約的執行需要多少計算資源,或是否會在合理的時間內完成;
(在深度學習的背景下,這個問題將更複雜,因為模型和框架將從靜態圖構建切換到動態構建和執行。)
4.隱私:對隱私意識的設計和開發是專案方必須要做的事。雖然大量的機器學習研究可以在公開資料集上進行,但為了提高模型的效能和適應特定的應用,通常需要在專有的使用者資料上對模型進行微調。這種微調過程可能涉及個人資料的處理,因此需要考慮隱私保護的要求;
5.並行化:這一點是當前項目不具備可行性的關鍵因素,深度學習模型通常在擁有專有架構和極低的延遲的大型硬件集群上並行訓練,而分散式計算網絡中的GPU需要進行頻繁的資料交換將會帶來延遲,並且會受限於效能最低的GPU。算力源存在不可信與不可靠的情況下,如何異構並行化是必須解決的問題,目前可行的方法是透過變壓器模型(Transformer Model)來實現並行化,例如Switch Transformers,現在已經具有高度並行化的特性。
解決方案:雖然目前對於去中心化AGI 算力市場的嘗試還處於早期,但恰好存在兩個項目初步解決了去中心化網絡的共識設計及去中心化算力網絡在模型訓練和推理上的落地過程。下文將以Gensyn 和Together 為例進行分析去中心化AGI 算力市場的設計方式與問題所在。
Gensyn

Gensyn 是一個還處於構建階段的AGI 算力市場,旨在解決去中心化深度學習計算的多種挑戰,以及降低當前深度學習的成本。 Gensyn 本質上是基於Polkadot 網絡上的第一層權益證明協議,它通過智能合約直接獎勵求解者(Solver)換取他們的閒置GPU 設備用於計算,並執行機器學習任務。
那麼回到上文的問題,建構一個真正無需信任的運算網絡核心在於驗證已完成的機器學習工作。這是一個高度複雜的問題,需要在複雜性理論、博弈論、密碼學和優化的交會之間找到一個平衡點。
Gensyn 提出一個簡單的解決方案是,求解者提交他們完成的機器學習任務的結果。為了驗證這些結果是否準確,另一個獨立的驗證者會嘗試重新執行相同的工作。這個方法可稱為單一複製,因為只有一個驗證者會重新執行。這意味著只有一次額外的工作來驗證原始工作的準確性。然而,如果驗證工作的人不是原始工作的請求者,那麼信任問題仍然存在。因為驗證者本身可能也不誠實,而且他們的工作需要被驗證。這導致了一個潛在問題,如果驗證工作的人不是原始工作的請求者,那麼就需要另一個驗證者來驗證他們的工作。但這個新的驗證者也可能不被信任,因此需要另一個驗證者來驗證他們的工作,這可能會一直延續下去,形成一個無限的複製鏈。這裡需要引入三個關鍵概念並將其交織建構四個角色的參與者係統來解決無限鏈問題。
機率學習證明:使用基於梯度的優化過程的元資料來建立完成工作的證書。通過複製某些階段,可以快速驗證這些證書,從而確保工作已經如期完成。
基於圖表的精確定位協議:使用多粒度、基於圖的精確定位協議,以及交叉評估器的一致性執行。這允許重新運行和比較驗證工作以確保一致性,並最終由區塊鏈本身確認。
Truebit 風格的激勵遊戲:使用抵押和削減來建立激勵遊戲,確保每個經濟上合理的參與者都會誠實行事並執行其預期的任務。
參與者係統由提交者、解算者、驗證者和舉報者組成。
提交者(Submitters):
提交者是系統的終端用戶,提供將被計算的任務,並支付已完成工作單位的費用;
解題者(Solvers):
求解者是系統的主要工作者,執行模型訓練並產生由驗證者檢查的證明;
驗證者(Verifiers):
驗證者是將非確定性訓練過程與確定性線性計算聯繫起來的關鍵,複製解決者的證明的一部分並將距離與預期閾值進行比較;
檢舉者(Whistleblowers):
舉報者是最後一道防線,檢查驗證者的工作並提出挑戰,希望獲得豐厚的獎金支付。
系統運作
該協議設計的博弈系統運作將包括八個階段,涵蓋四個主要參與者角色,用於完成從任務提交到最終驗證的完整流程。
1.任務提交(Task Submission): 任務由三個特定的資訊組成:
描述任務和超參數的元資料;
一個模型二進位(或基本架構);
公開可存取的、預處理過的訓練資料。
2.為了提交任務,提交者以機器可讀的格式指定任務的詳細信息,並將其連同模型二進製文件(或機器可讀架構)和預處理過的訓練數據的公開可訪問位置提交給鏈。公開的資料可以儲存在簡單的物件儲存如AWS 的S 3 中,或在一個去中心化的儲存如IPFS、Arweave 或Subspace 中。
3.分析(Profiling): 分析過程為學習驗證的證明確定了一個基線距離閾值。驗證者將定期抓取分析任務,並為學習證明比較產生變異閾值。為了產生閾值,驗證者將確定性地運行和重運行訓練的一部分,使用不同的隨機種子,產生並檢查自己的證明。在此過程中,驗證者將建立一個可用作驗證解決方案的非確定性工作的整體預期距離閾值。
4.訓練(Training): 在分析之後,任務進入公共任務池(類似以太坊的Mempool)。選擇一個求解者來執行任務,並從任務池移除任務。求解者根據提交者提交的元資料以及提供的模型和訓練資料執行任務。在執行訓練任務時,求解者還會透過定期檢查點並儲存訓練過程中的元資料(包括參數)來產生學習證明,以便驗證者盡可能準確地複製以下優化步驟。
5.證明產生(Proof generation): 解算者週期性地儲存模型權重或更新以及與訓練資料集的相應索引,以識別用於產生權重更新的樣本。可以調整檢查點頻率以提供更強的保證或節省儲存空間。證明可以“堆疊”,這意味著證明可以從用於初始化權重的隨機分佈開始,或從使用自己的證明產生的預訓練權重開始。這使協議能夠建立一組已證明的、預先訓練的基礎模型(即基礎模型),這些模型可以針對更具體的任務進行微調。
6.證明的驗證(Verification of proof): 任務完成後,求解者向鏈註冊任務完成,並在公開可訪問的位置展示其學習證明,以便驗證者訪問。驗證者從公共任務池中提取驗證任務,並執行計算工作以重運行證明的一部分並執行距離計算。然後鏈(連同在分析階段計算的閾值)使用所得的距離來確定驗證是否與證明相符。
7.基於圖的精確定位挑戰(Graph-based pinpoint challenge): 在驗證學習證明之後,舉報者可以復制驗證者的工作以檢查驗證工作本身是否正確執行。如果舉報者認為驗證已被錯誤執行(惡意或非惡意),他們可以向合約仲裁發起挑戰以獲得獎勵。這種獎勵可以來自解決者和驗證者的存款(在真正積極的情況下),或來自彩票庫獎金池(在假陽性的情況下),並使用鏈本身執行仲裁。舉報者(在他們的例子中是驗證者)只有在期望收到適當的補償時才會驗證並隨後挑戰工作。實際上,這意味著舉報者預計會根據其他活動的舉報者的數量(即,具有即時存款和挑戰)加入和離開網路。因此,任何舉報者的預期預設策略是在其他舉報者數量較少時加入網絡,發布存款,隨機選擇一個活動任務,並開始他們的驗證過程。在第一個任務結束後,他們將抓取另一個隨機活動任務並重複,直到舉報者的數量超過其確定的支付閾值,然後他們將離開網絡(或更可能地,根據他們的硬件能力轉向網絡中執行另一個角色-驗證者或解算者),直到情況再次逆轉。
8.合約仲裁(Contract arbitration):當驗證者被舉報人質疑時,他們會與鏈條進入一個流程,以找出有爭議的操作或輸入的位置,最終由鏈條執行最終的基本操作並確定質疑是否有理。為了保持舉報人的誠實可信並克服驗證者的困境,此處引入定期強制錯誤和頭獎支付。
9.結算(Settlement): 在結算過程中,根據機率和確定性檢查的結論來支付參與者。根據先前驗證和挑戰的結果,不同的場景會有不同的支付。如果認為工作已正確執行且所有檢查都已通過,則根據執行的操作獎勵解決方案提供者和驗證者。
項目簡評
Gensyn 在驗證層和激勵層上設計了一套精彩的博弈系統,透過找出網路中的分歧點能快速鎖定錯誤所在,但目前的系統中還缺少許多細節。比如說如何設定參數才能確保獎懲合理,又不會門檻過高?博弈中的環節是否有考慮極端情況與解算者算力不同的問題?在目前版本的白皮書中也沒有異構並行化運行的詳細說明,目前來看Gensyn 的落地還道阻且長。
Together.ai
Together 是一家專注於大模型的開源,致力於去中心化的AI 算力方案的公司,希望任何人在任何地方都能接觸和使用AI。嚴格來說Together 並非區塊鏈項目,但目前該項目初步解決了去中心化AGI 算力網絡中的延遲問題。所以下文只分析Together 的解決方案,對專案不做評價。
在去中心化網路比資料中心慢100 倍的情況下,如何實現大模型的訓練與推理?
讓我們想像去中心化的情況下,參與網路的GPU 裝置分佈會是怎麼樣?這些設備將分佈於不同的大洲,不同的城市,設備之間需要連接,而連接的延遲和帶寬又各不相同。如下圖所示,模擬了一個分散式的情況,設備分佈處於北美洲、歐洲和亞洲,設備之間的帶寬和延遲各不相同。那麼需要如何做才能將其串聯?
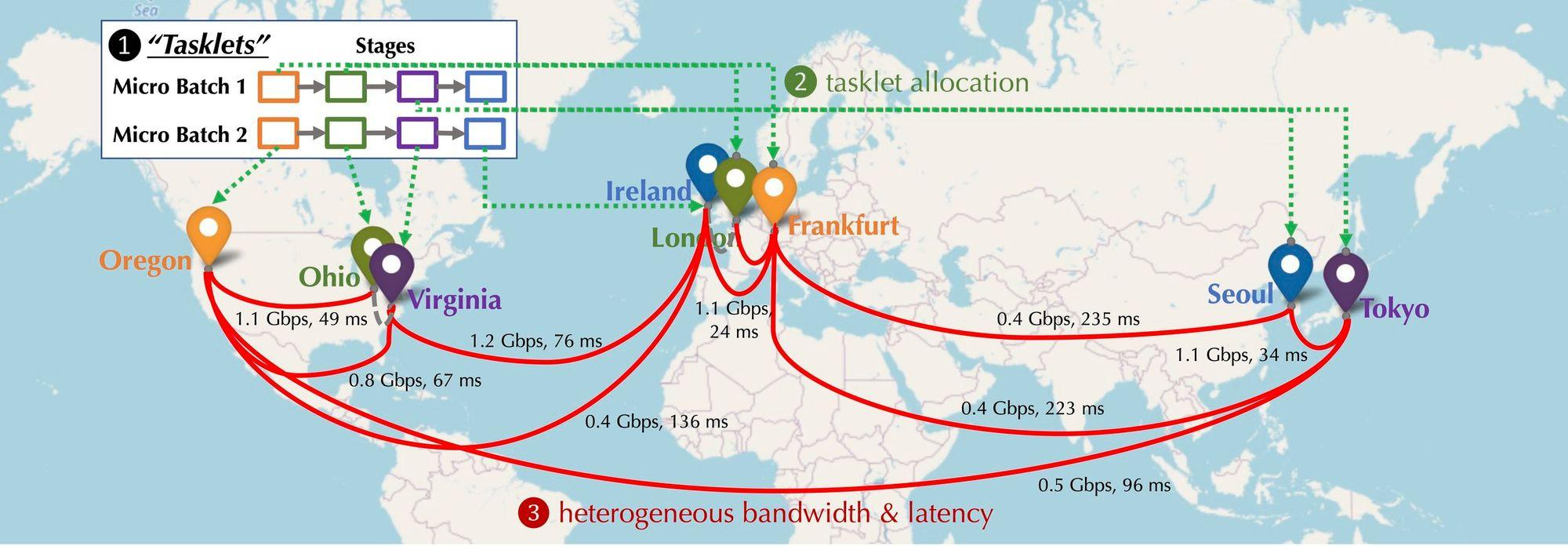
分散式訓練計算建模:下圖為在多台裝置上進行基礎模型訓練的情況,從通訊類型來看具有前向啟動(Forward Activation)、反向梯度(Backward Gradient)、橫向通訊三種通訊類型。
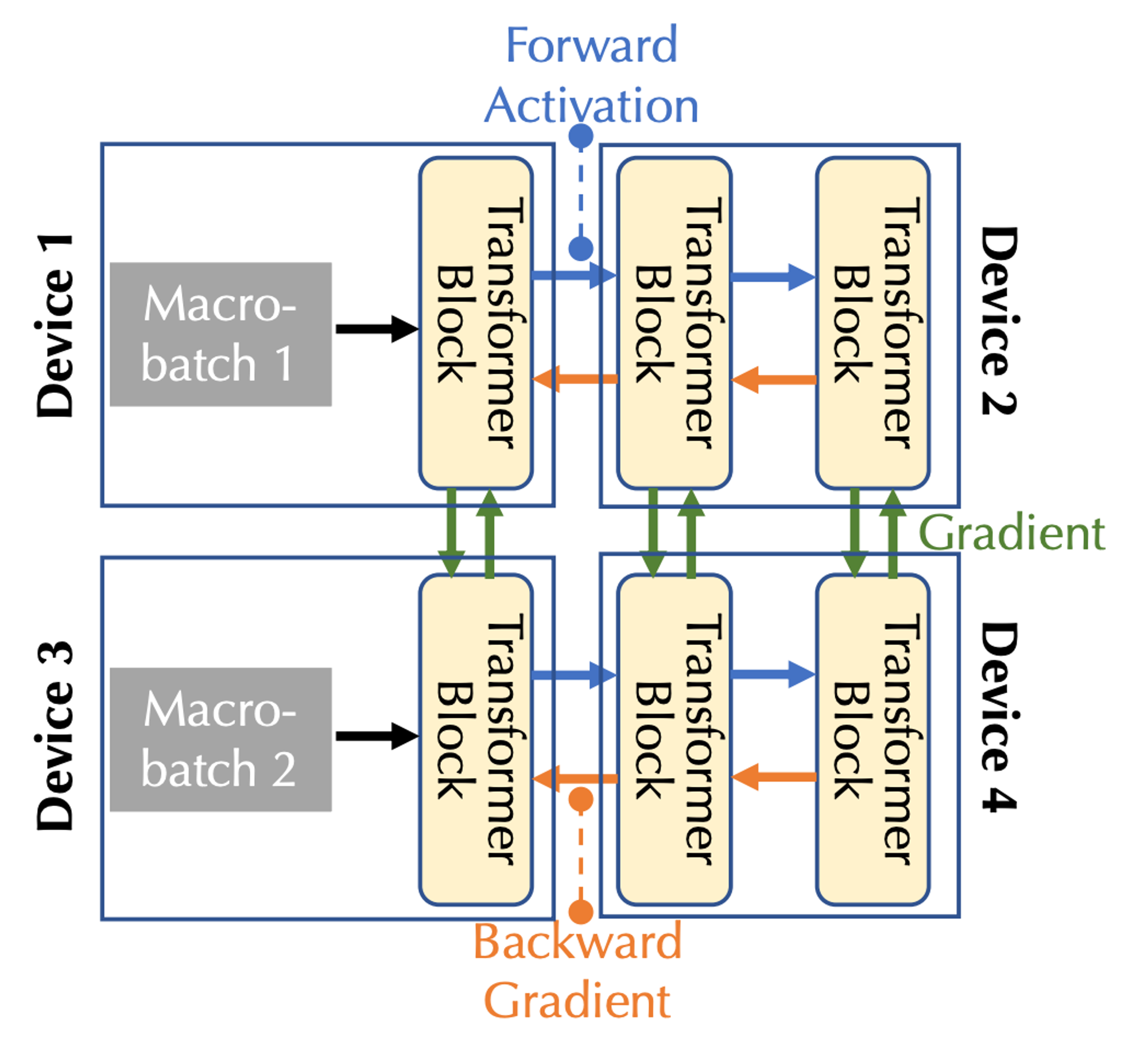
結合通訊帶寬和延遲,需要考慮兩種形式的並行性:管道並行性和資料並行性,對應於多設備情況下的三種通訊類型:
在管道並行中,模型的所有層都分為多個階段,其中每個設備處理一個階段,該階段是連續的層序列,例如多個Transformer 區塊;在前向傳遞中,激活被傳遞到下一個階段,而在後向傳遞中,活化的梯度被傳遞到前一階段。
在資料並行中,設備獨立計算不同微批次的梯度,但需要透過通訊來同步這些梯度。
調度優化:
在一個去中心化的環境中,訓練過程通常受到溝通限制。調度算法一般會將需要大量通訊的任務分配給連接速度更快的設備,考慮到任務之間的依賴關係和網絡的異構性,首先需要對特定的調度策略的成本進行建模。為了捕捉訓練基礎模型的複雜通訊成本,Together 提出了一個新穎的公式,並透過圖論將成本模型分解為兩個層次:
圖論是數學的一個分支,主要研究圖(網絡)的性質和結構。圖由頂點(節點)和邊(連接節點的線)組成。圖論中的主要目的是研究圖的各種性質,如圖的連通性、圖的色彩、圖中路徑和循環的性質。
第一層是平衡圖分割(將圖的頂點集合分割成幾個相等大小或近似相等大小的子集,同時使得子集之間的邊的數量最小。在這種分割中,每個子集代表一個分區,並且透過最小化分區間的邊來減少通訊成本)問題,對應於資料並行的通訊成本。
第二層是一個聯合圖匹配和旅行商問題(聯合圖匹配和旅行商問題是一個組合優化問題,它結合了圖匹配和旅行商問題的元素。圖匹配問題是在圖中找到一個匹配,使得某種成本最小化或最大化。而旅行商問題是尋找一條訪問圖中所有節點的最短路徑),對應於管道並行的通訊成本。
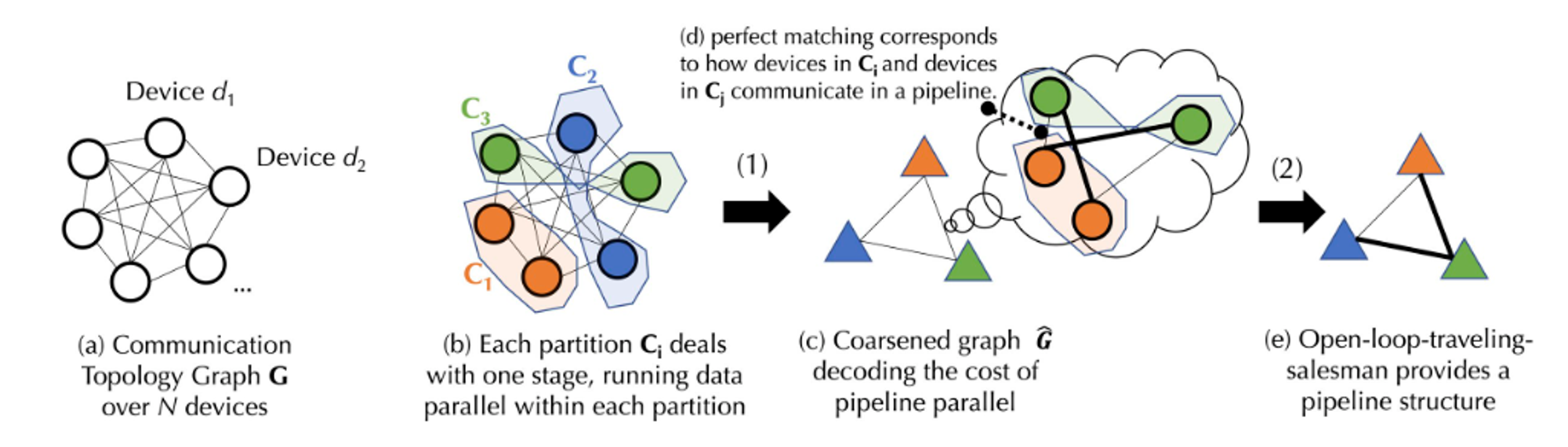 上圖為流程示意圖,由於實際的實施過程中涉及一些複雜的計算公式。為了便於理解,下文將把圖中的流程說的通俗一些,詳細的實施過程可以自行查詢Together 官網中的文件。
上圖為流程示意圖,由於實際的實施過程中涉及一些複雜的計算公式。為了便於理解,下文將把圖中的流程說的通俗一些,詳細的實施過程可以自行查詢Together 官網中的文件。
假設有一個包含N 個設備的設備集D,其間的通訊有不確定的延遲(A 矩陣)和帶寬(B 矩陣)。基於設備集D,我們先產生一個平衡的圖分割。每個分割或設備組中的設備數量大致相等,並且它們都處理相同的管線階段。這確保了資料並行時,各設備組執行相似量的工作。 (資料並行是指多個設備執行相同的任務,而管線階段則是指設備依照特定的順序執行不同的任務步驟)。根據通訊的延遲和帶寬,透過公式可以計算出在設備組間傳輸資料的「成本」。每個平衡的設備組都被合併,產生一個全連接的粗糙圖,其中每個節點代表流水線的階段,邊代表兩個階段之間的通訊成本。為了最小化通訊成本,使用匹配算法來確定哪些設備組應該一起工作。
為了進一步優化,也可以把這個問題被建模成一個開環的旅行商問題(開環意味著不需要返迴路徑起點),從而找到一個在所有設備間傳輸資料的最優路徑。最後Together 再透過一個他們創新的調度算法找到給定成本模型的最佳分配策略,從而實現最小化通訊成本,最大化訓練吞吐量。根據實測,在這個調度優化下即使網路慢100 倍,端到端的訓練吞吐量大概只慢了1.7 至2.3 倍。
通訊壓縮優化:
對於通訊壓縮的優化,Together 引入了AQ-SGD 算法(詳細計算過程,可參考論文Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees),AQ-SGD 算法是為了解決在低速網路上進行管道並行訓練的通訊效率問題而設計的一種新穎的活性壓縮技術。與以往直接壓縮活性值的方法不同,AQ-SGD 聚焦於壓縮相同訓練樣本在不同時期的活性值的變化,這種獨特的方法引入了一個有趣的「自我執行」動態,隨著訓練的穩定,該算法的表現預計會逐漸提高。 AQ-SGD 演算法經過嚴格的理論分析,證明了在一定的技術條件和有界誤差的量化函數下具有良好的收斂率。該算法不僅可以有效實現,而且不會增加額外的端對端運行時開銷,儘管它需要利用更多的記憶體和SSD 來儲存活性值。通過在序列分類和語言建模資料集上的廣泛實驗驗證,AQ-SGD 可以將活性值壓縮到2-4 位元而不犧牲收斂性能。此外,AQ-SGD 還可以與最先進的梯度壓縮算法集成,實現“端到端通訊壓縮”,即所有機器之間的數據交換,包括模型梯度、前向活性值和反向梯度,都被壓縮成低精度,從而大幅提高分散式訓練的通訊效率。與在中心化算力網絡(例如10 Gbps)無壓縮情況下的端對端訓練效能相比,目前只慢了31% 。結合調度優化的數據來看,雖然距離中心化算力網絡還有一定差距,但未來追趕的希望是比較大的。
結語
在AI 浪潮帶來的紅利期下,AGI 算力市場無疑是許多算力市場中潛力最大、需求最多的市場。但開發難度,硬體需求,資金需求也是最高的。結合上文兩個項目的情況來看,AGI 算力市場的落地還有一定距離,真正的去中心化網絡也要比理想情況復雜的多,目前顯然還不足以跟雲巨頭競爭。而在撰寫這篇文章時,也觀察到現在一些處於襁褓期(PPT 階段)體量不大的項目已經開始探尋一些新的切入點,比如將重心放在難度更低的推理階段或者是小模型在的訓練上,這些更為實際的嘗試中。
AGI 算力市場最終將以怎樣的姿態實現目前還尚未可知,雖然面臨著諸多挑戰,但從長遠來看AGI 算力去中心化和無需許可的意義是重要的,推理與訓練的權利不應該集中於少數幾個中心化巨頭。因為人類不需要新的“神教“也不需要新的“教皇”,更不該支付昂貴的“會費”。
參考文獻
1.Gensyn Litepaper:https://docs.gensyn.ai/litepaper/
2.NeurIPS 2022: Overcoming Communication Bottlenecks for Decentralized Training :https://together.ai/blog/neurips-2022-overcoming-communication-bottlenecks-for-decentralized-training-12
3.Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees:https://arxiv.org/abs/2206.01299
4.The Machine Learning Compute Protocol and our future:https://mirror.xyz/gensyn.eth/_K2v2uuFZdNnsHxVL3Bjrs4GORu3COCMJZJi7_MxByo
5.Microsoft:Earnings Release FY 23 Q2:https://www.microsoft.com/en-us/Investor/earnings/FY-2023-Q2/performance
6.爭奪AI 入場券:BAT、字節美團們競逐GPU:https://m.huxiu.com/article/1676290.html
7.IDC:2022-2023全球計算力指數評估報告:https://www.tsinghua.edu.cn/info/1175/105480.htm
8.國盛證券大模型訓練估算:https://www.fxbaogao.com/detail/3565665
9.資訊之翼:算力與AI 是什麼關係? :https://zhuanlan.zhihu.com/p/627645270


