
Web3底層基建?簡析昨天CloudFlare服務中斷的原因
原文來源:阿法兔研究筆記

原文來源:阿法兔研究筆記
本篇文章,會講一下什麼是CloudFlare,到底是個什麼公司,CloudFlare和Web3的緣起,以及從技術上解釋一下本次故障的原因。
一級標題
一級標題
1.事件背景
本文結構
1.事件背景
2022年6月底(本週二)發生了什麼?
什麼是CDN
CDN公司通常都是安全公司?
什麼是路由
CDN公司通常都是安全公司?
3.Cloudflare是個什麼公司?
4.Cloudflare和Web3的緣起
一級標題
一級標題
結論
事件背景
事件背景
本篇文章,會講一下什麼是CloudFlare,到底是個什麼公司,CloudFlare和Web3的緣起,以及從技術上解釋一下本次故障的原因。
一級標題
在講Cloudflare之前,我們先普及一個概念(CDN)
二級標題
二級標題二級標題
什麼是CDN?CDN,全稱為Content Distribute Network(內容分發網絡)或者Content Delivery Network;
那麼,什麼是內容分發網絡呢?是可以通過互聯網互相連接的電腦網絡系統,利用最近每位用戶的服務器,更快、更可靠地將音樂、圖片、視頻、應用程序及其他文件發送給用戶,來提供高性能、可擴展性及低成本的網絡內容傳遞給用戶。
形象的說,CDN有點類似於京東物流模式,通過在全國各地建立物流點(緩存服務器),當有人從京東購買貨物時(用戶資源請求),京東上次可以根據用戶的收貨地址(CDN進行用戶域名解析)找最近的或者最快的一個物流點進行派送(將訪問用戶連接到最近的緩存服務器進行資源傳輸)。
CDN服務可用於確保快速可靠地分發靜態內容,這些內容可以緩存,最適合在網速龐大的網絡中存儲和分發,這樣就能把主幹網絡通道空出來給必須實時傳輸的動態內容,比如網絡直播,降低時延。
二級標題
二級標題
路由二級標題路由
我們前面提到過網絡路由,
路由是啥呢?其實路由解決的主要問題,就是兩點之間的通信,究竟走什麼線路的問題。
二級標題
二級標題
CDN公司通常都是安全公司?
注:本部分關於CDN的解釋內容,部分來自於Youtube博主老科談科技股
一級標題
一級標題一級標題
除此之外,Cloudflare收購了一系列網絡服務和安全公司,2014年收購StopTheHacker 、CryptoSeal;2016年收購Eager Platform Co.;17年及以後收購Neumob、S2 Systems、Linc、Zaraz;今年收購了Vectrix和Area 1 Security.
一級標題
一級標題一級標題並且,官網提到,Web 1.0讓世界有了快速傳播信息的能力,而Web 2.0則讓這些信息具有互動性。 Web 3.0,或Web3,被認為是互聯網的下一次迭代,建立在IPFS和以太坊等去中心化的技術之上。

圖片描述
圖片描述

圖片來自Cloudflare官網
Cloudflare為什麼會發生服務中斷?
二級標題
二級標題
對此次中斷,Cloudflare 深表歉意,這是Cloudflare 的錯誤,而不是因為攻擊或其他惡意活動的。
二級標題
二級標題
二級標題
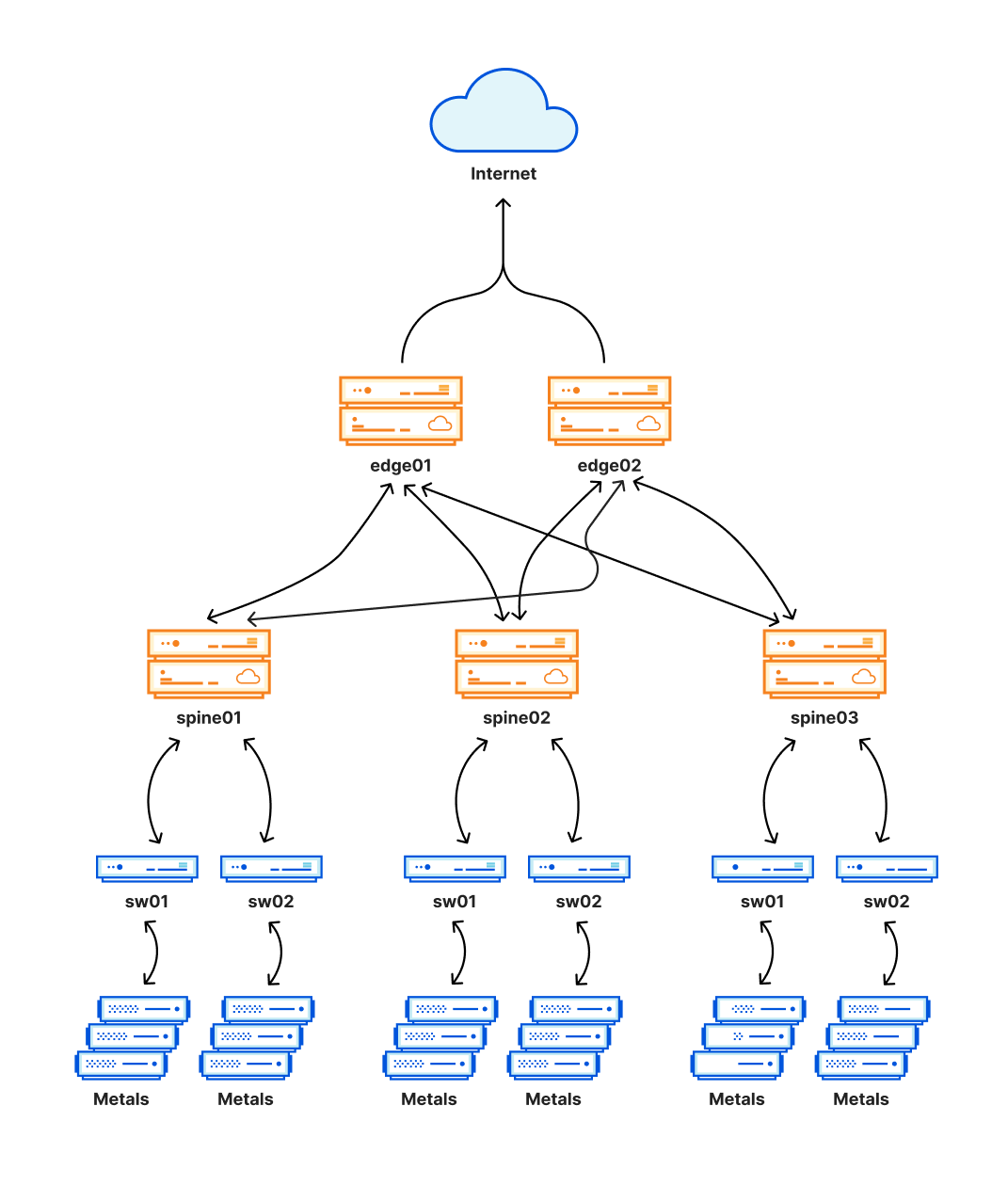
本次架構轉型的背景
在過去18 個月,Cloudflare 一直致力於將所有最繁忙的數據中心的架構轉型,讓它們更為靈活、且更具彈性。目前,已經有19個數據中心,成功轉換為此架構,Cloudflare內部稱其為Multi-Colo PoP(MCP);這19個數據中心分別位於:阿姆斯特丹,亞特蘭大,阿什本,芝加哥,法蘭克福,倫敦,洛杉磯,馬德里,曼徹斯特,邁阿密,米蘭,孟買,紐瓦克,大阪,聖保羅,聖何塞,新加坡,悉尼和東京。不過,由於這些地點同時也承載著Cloudflare流量的很大部分,任何這裡的問題都會產生非常廣泛的影響,不幸的是,這就是6月21日Cloudflare服務終端的原因所在。
二級標題
二級標題二級標題"服務中斷的時間線和影響"Cloudflare應用了名為BGP的協議(邊界網關協議,Border Gateway Protocol,是運行於TCP 上的一種自治系統的路由協議)。
該協議的由運營商定義政策,決定有哪些前綴(相鄰IP地址的集合)會被廣播給對等的節點(他們連接的其他網絡)。這些策略有單獨的組成部分,按順序進行評估。最終的結果是,任何給定的前綴要么被廣播,要么不被廣播。政策的變化可能意味著以前會廣播的前綴不再被廣播,被稱為
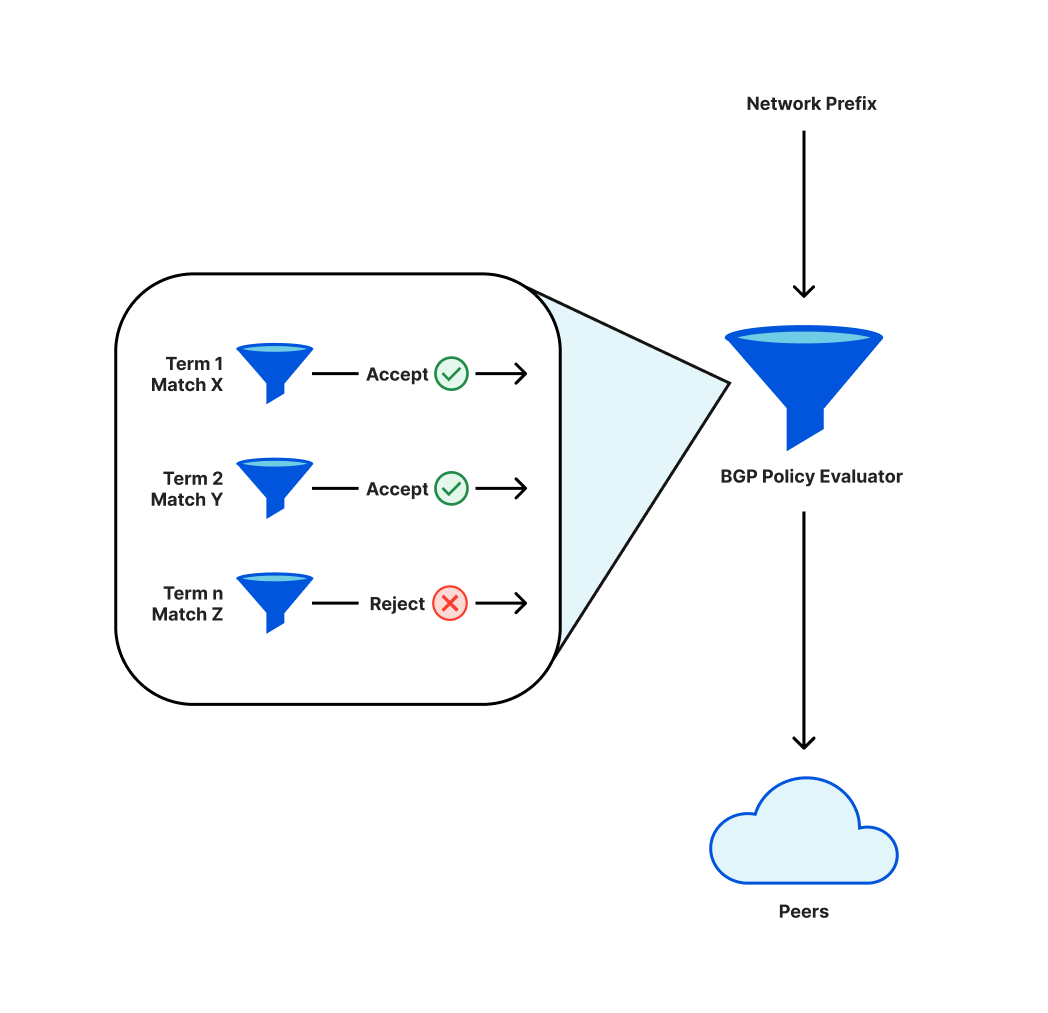
撤銷
,這些IP地址將不再能在互聯網上正常運行。
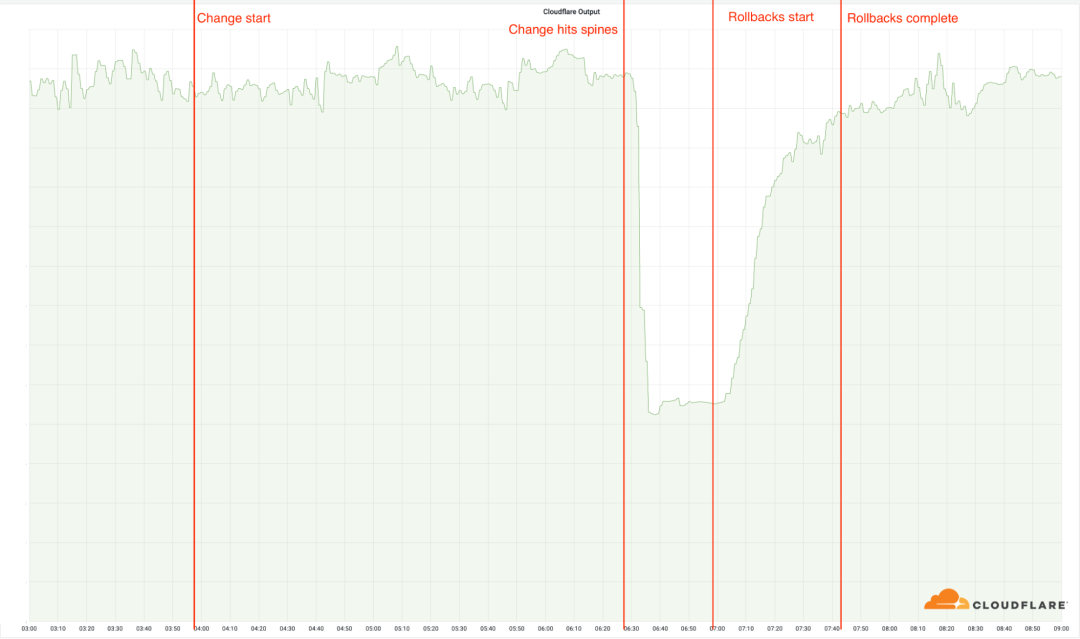
03:56 UTC:運營商制定了某種策略,決定某些路由前綴可以被廣播(這裡的廣播指的是,路由可以被其他邊緣bgp路由器學習到,進而其他的bgp網絡知道這些路由變化,前綴就是prefix,是用來唯一地標識著連入Internet的一個網絡號)
06:17:前綴通告策略更改時,術語的重新編排,導致Cloudflare必須撤回前綴的關鍵子集。
06:27:政策的變化可能意味著以前會廣播的前綴不再被廣播,Cloudflare工程師在受影響的數據中心,對有問題部分進行恢復時,就遇到了額外困難,不過Cloudflare有處理此類問題的備份程序。
06:32:Cloudflare將更改部署到第一個(數據中心)位置,所有位置都沒有受到此次更改的影響,因為這些位置使用的舊的架構。
06:51:部署更改到Cloudflare最繁忙的地點,但是沒有部署到具備MCP(Multi-Colo PoP) 體系結構的位置。
06:58:部署到達了啟用MCP (Multi-Colo PoP)的位置,並且更改已部署到關鍵部位。這是服務中斷事件開始的時候,這個時候,19個數據中心迅速離線。
07:42:Cloudflare內部宣布本次服務中斷事件。
08:00:在路由器上進行的首次更改,以驗證根本原因。
排查故障,找出根本原因,還原出現問題的部分
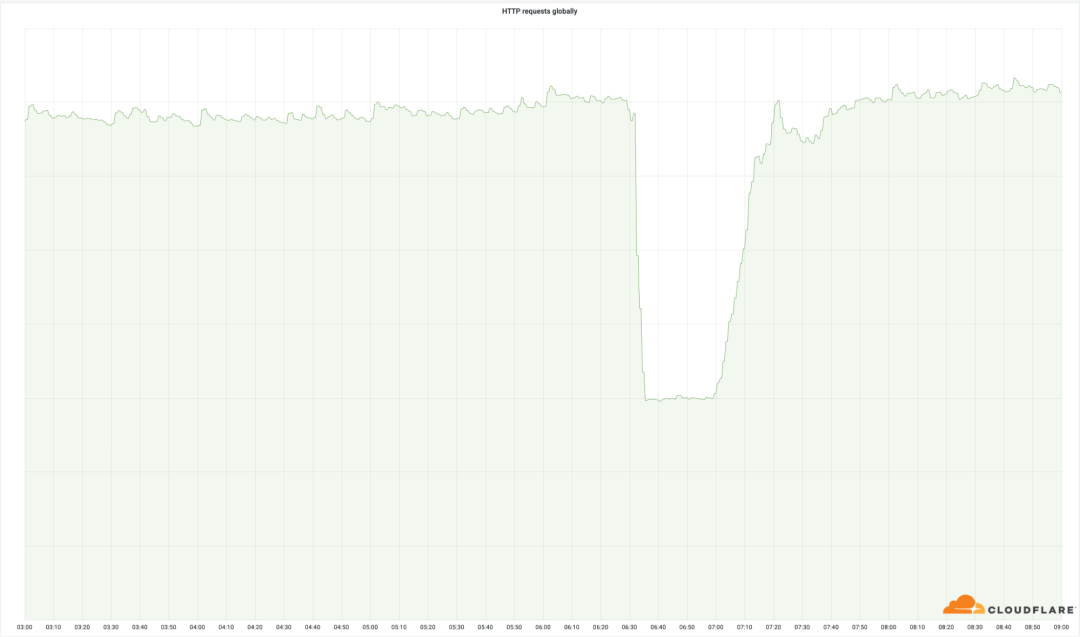
服務中斷事件結束。
(本部分有小部分代碼,此處略去,感興趣的網絡工程小伙伴可查看原文:
https://blog.cloudflare.com/cloudflare-outage-on-june-21-2022/)
正文
正文
補救和後續步驟流程:
本次服務終端事件造成了廣泛且嚴重的影響,Cloudflare一貫對可用性是非常重視,目前已經提出了幾個需要改進的領域,而後將繼續努力,發現可能潛在導致服務終端的所有問題。流程:
雖然MCP 計劃旨在提高可用性,但我們在更新這些數據中心方面的程序性差距,導致造成了嚴重影響。雖然Cloudflare確實為設計了交錯策略,但是它並不完美,部署過程和自動化中,需要包含MCP 的測試和具體部署過程,以確保不會產生意外後果。架構:"二級標題"二級標題
結論
結論


