
LUCIDA: Cách sử dụng chiến lược đa yếu tố để xây dựng danh mục tài sản tiền điện tử mạnh mẽ (xử lý trước dữ liệu)
Lời nói đầu
Tiếp tục từ chương trước, chúng tôi đã xuất bảnBài viết đầu tiên trong loạt bài “Xây dựng danh mục tài sản tiền điện tử mạnh mẽ bằng chiến lược đa yếu tố” - Cơ sở lý thuyết, bài viết này là bài viết thứ hai - tiền xử lý dữ liệu.
Trước/sau khi tính toán dữ liệu hệ số và trước khi kiểm tra tính hợp lệ của một hệ số duy nhất, dữ liệu liên quan cần được xử lý. Quá trình tiền xử lý dữ liệu cụ thể liên quan đến việc xử lý các giá trị trùng lặp, giá trị ngoại lệ/giá trị bị thiếu/giá trị cực trị, tiêu chuẩn hóa và tần suất dữ liệu.
1. Giá trị trùng lặp
Các định nghĩa liên quan đến dữ liệu:
Khóa: Đại diện cho một chỉ mục duy nhất. ví dụ: Đối với một phần dữ liệu có tất cả mã thông báo và tất cả ngày, khóa là token_id/contract_address - date
Giá trị: Đối tượng được lập chỉ mục bởi khóa được gọi là giá trị.
Việc chẩn đoán các giá trị trùng lặp trước tiên đòi hỏi phải hiểu dữ liệu nên trông như thế nào. Thông thường dữ liệu có dạng:
Dữ liệu chuỗi thời gian. Điều quan trọng là thời gian. ví dụ: Dữ liệu về giá trong 5 năm cho một mã thông báo
Dữ liệu mặt cắt ngang (Cross Cut). Điều quan trọng là cá nhân. eg.2023.11.01 Dữ liệu giá của tất cả các token trên thị trường tiền điện tử vào ngày đó
Dữ liệu bảng (Panel). Điều quan trọng là sự kết hợp của “thời gian cá nhân”. Ví dụ: Dữ liệu giá của tất cả các token trong bốn năm từ 2019.01.01 đến 2023.11.01.
Nguyên tắc: Khi chỉ mục (khóa) của dữ liệu được xác định, bạn có thể biết dữ liệu sẽ không có giá trị trùng lặp ở cấp độ nào.
Phương pháp kiểm tra:
pd.DataFrame.duplicated(subset=[key 1, key 2, ...])
Kiểm tra số lượng giá trị trùng lặp: pd.DataFrame.duplicate(subset=[key 1, key 2, ...]).sum()
Lấy mẫu để xem các mẫu trùng lặp: df[df.duplicate(subset=[...])].sample() Sau khi tìm thấy mẫu, hãy sử dụng df.loc để chọn tất cả các mẫu trùng lặp tương ứng với chỉ mục
pd.merge(df 1, df 2, on=[key 1, key 2, ...], indicator=True, validate='1: 1')
Trong chức năng hợp nhất theo chiều ngang, việc thêm tham số chỉ báo sẽ tạo ra trường _merge. Sử dụng dfm[_merge].value_counts() để kiểm tra số lượng mẫu từ các nguồn khác nhau sau khi hợp nhất.
Bằng cách thêm tham số xác thực, bạn có thể xác minh xem chỉ mục trong tập dữ liệu đã hợp nhất có như mong đợi hay không (1 đến 1, 1 đến nhiều hoặc nhiều đối với nhiều, trường hợp cuối cùng thực sự có nghĩa là không cần xác minh). Nếu không như mong đợi, quá trình hợp nhất sẽ báo lỗi và hủy bỏ quá trình thực thi.
2. Giá trị ngoại lệ/giá trị thiếu/giá trị cực trị
Nguyên nhân phổ biến của các ngoại lệ:
trường hợp cực đoan.Ví dụ: nếu giá mã thông báo là 0,000001 đô la hoặc mã thông báo có giá trị thị trường chỉ 500.000 đô la Mỹ, nếu nó thay đổi một chút, sẽ có lợi nhuận gấp hàng chục lần.
Đặc điểm dữ liệu.Ví dụ: nếu dữ liệu giá mã thông báo bắt đầu được tải xuống vào ngày 1 tháng 1 năm 2020 thì đương nhiên không thể tính toán dữ liệu trả về vào ngày 1 tháng 1 năm 2020 vì không có giá đóng cửa của ngày hôm trước.
lỗi dữ liệu.Các nhà cung cấp dữ liệu chắc chắn sẽ mắc sai lầm, chẳng hạn như ghi 12 nhân dân tệ mỗi mã thông báo thành 1,2 nhân dân tệ mỗi mã thông báo.
Nguyên tắc xử lý các giá trị ngoại lệ và giá trị bị thiếu:
xóa bỏ. Các ngoại lệ không thể sửa chữa hoặc sửa chữa một cách hợp lý có thể được xem xét xóa.
thay thế. Thường được sử dụng để xử lý các giá trị cực trị, chẳng hạn như winorizing hoặc lấy logarit (không được sử dụng phổ biến).
đổ đầy. vìGiá trị bị mấtBạn cũng có thể cân nhắc việc điền một cách hợp lý. Các cách phổ biến bao gồmnghĩa là(hoặc đường trung bình động),phép nội suy(Interpolation)、Điền vào số 0df.fillna(0), df.fillna(ffill)/điền lùi df.fillna(bfill), v.v. Cần phải xem xét liệu các giả định mà việc điền dựa vào có nhất quán hay không.
Hãy thận trọng khi sử dụng tính năng điền ngược trong học máy vì có nguy cơ sai lệch Nhìn về phía trước.
Cách xử lý các giá trị cực trị:
1. Phương pháp phần trăm.
Bằng cách sắp xếp thứ tự từ nhỏ đến lớn, dữ liệu vượt quá tỷ lệ tối thiểu và tối đa sẽ được thay thế bằng dữ liệu quan trọng. Đối với dữ liệu có dữ liệu lịch sử phong phú, phương pháp này tương đối thô và không có tính áp dụng cao, việc buộc xóa một tỷ lệ dữ liệu cố định có thể gây ra một tỷ lệ tổn thất nhất định.
2,3σ / ba phương pháp độ lệch chuẩn

Thực hiện các điều chỉnh sau cho tất cả các yếu tố trong phạm vi dữ liệu:
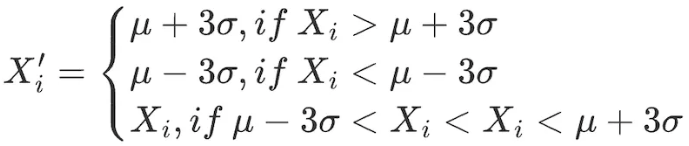
Nhược điểm của phương pháp này là dữ liệu thường được sử dụng trong lĩnh vực định lượng, chẳng hạn như giá cổ phiếu và giá token, thường thể hiện phân phối đỉnh và đuôi dày, không phù hợp với giả định về phân phối chuẩn. Phương pháp 3 σ sẽ xác định nhầm một lượng lớn dữ liệu là giá trị bất thường.
3. Phương pháp độ lệch tuyệt đối trung vị (MAD)
Phương pháp này dựa trên độ lệch trung bình và độ lệch tuyệt đối, làm cho dữ liệu được xử lý ít nhạy cảm hơn với các giá trị cực trị hoặc các giá trị ngoại lệ. Mạnh mẽ hơn các phương pháp dựa trên giá trị trung bình và độ lệch chuẩn.
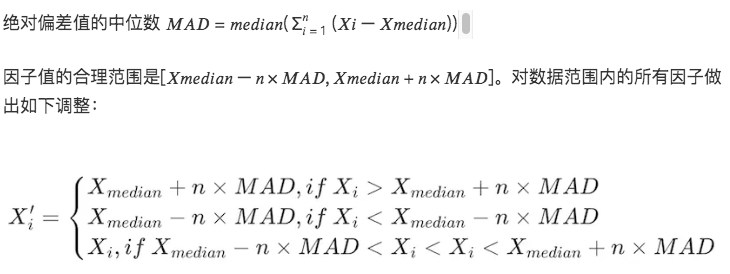
# Xử lý các tình huống có giá trị cực trị của dữ liệu hệ số
class Extreme(object):
def __init__(s, ini_data):
s.ini_data = ini_data
def three_sigma(s, n= 3):
mean = s.ini_data.mean()
std = s.ini_data.std()
low = mean - n*std
high = mean + n*std
return np.clip(s.ini_data, low, high)
def mad(s, n= 3):
median = s.ini_data.median()
mad_median = abs(s.ini_data - median).median()
high = median + n * mad_median
low = median - n * mad_median
return np.clip(s.ini_data, low, high)
def quantile(s, l = 0.025, h = 0.975):
low = s.ini_data.quantile(l)
high = s.ini_data.quantile(h)
return np.clip(s.ini_data, low, high)
3. Tiêu chuẩn hóa
Tiêu chuẩn hóa điểm 1.Z

2. Tiêu chuẩn hóa chênh lệch giá trị tối đa và tối thiểu (Tỷ lệ tối thiểu)
Chuyển đổi từng dữ liệu yếu tố thành dữ liệu trong khoảng (0, 1), cho phép so sánh dữ liệu có kích thước hoặc phạm vi khác nhau, nhưng nó không thay đổi sự phân bố trong dữ liệu và cũng không làm cho tổng trở thành 1.
Do xem xét các giá trị tối đa và tối thiểu, nó rất nhạy cảm với các giá trị ngoại lệ
Việc thống nhất các kích thước tạo điều kiện thuận lợi cho việc so sánh dữ liệu ở các kích thước khác nhau.
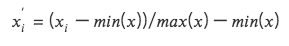
3. Thang xếp hạng
Chuyển đổi các đặc điểm dữ liệu thành thứ hạng của chúng và chuyển đổi các thứ hạng này thành điểm từ 0 đến 1, thường là phần trăm của chúng trong tập dữ liệu. *
Phương pháp này không nhạy cảm với các giá trị ngoại lệ vì thứ hạng không bị ảnh hưởng bởi các giá trị ngoại lệ.
Khoảng cách tuyệt đối giữa các điểm trong dữ liệu không được duy trì mà được chuyển thành thứ hạng tương đối.
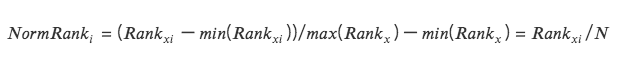
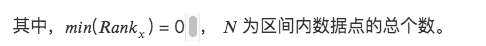
# Lớp dữ liệu nhân tố được chuẩn hóa Thang đo (đối tượng):
def __init__(s, ini_data, date):
s.ini_data = ini_data
s.date = date
def zscore(s):
mean = s.ini_data.mean()
std = s.ini_data.std()
return s.ini_data.sub(mean).div(std)
def maxmin(s):
min = s.ini_data.min()
max = s.ini_data.max()
return s.ini_data.sub(min).div(max - min)
def normRank(s):
# Xếp hạng cột được chỉ định, phương thức=min nghĩa là cùng một giá trị sẽ có cùng thứ hạng chứ không phải thứ hạng trung bình
ranks = s.ini_data.rank(method='min')
return ranks.div(ranks.max())
4. Tần số dữ liệu
Đôi khi dữ liệu thu được không có tần suất cần thiết cho phân tích của chúng tôi. Ví dụ: nếu mức độ phân tích là hàng tháng và tần suất dữ liệu gốc là hàng ngày thì bạn cần sử dụng downsampling, tức là dữ liệu tổng hợp là hàng tháng.
Lấy mẫu xuống
giới thiệuTổng hợp dữ liệu trong một bộ sưu tập thành một hàng dữ liệu, ví dụ: dữ liệu hàng ngày được tổng hợp thành dữ liệu hàng tháng. Lúc này cần xem xét đặc điểm của từng chỉ số tổng hợp, các thao tác phổ biến bao gồm:
giá trị đầu tiên/giá trị cuối cùng
trung bình/trung vị
độ lệch chuẩn
lấy mẫu lại
Nó đề cập đến việc chia một hàng dữ liệu thành nhiều hàng dữ liệu, chẳng hạn như dữ liệu hàng năm được sử dụng để phân tích hàng tháng. Tình huống này thường yêu cầu sự lặp lại đơn giản và đôi khi cần tổng hợp dữ liệu hàng năm vào từng tháng theo tỷ lệ.


