
Trí tuệ hợp tác Web3: Cây tri thức, Rừng tri thức và Đóng góp của cộng đồng
Tác giả gốc: Eric Zhang
Tác giả gốc: Eric Zhang
Đặc biệt cảm ơn Zeo, DAOctor, Zhengyu, Christina vì những đóng góp, đánh giá và phản hồi của họ.
Xây dựng cơ sở dữ liệu cấu trúc tri thức và trực quan hóa tốt hơn tri thức là những nhiệm vụ quan trọng để thúc đẩy khoa học máy tính, trí tuệ nhân tạo và Web. Trước khi xuất hiện thế giới tiền điện tử và các ứng dụng phi tập trung, nghiên cứu Web 3.0 cũ chủ yếu tập trung vào việc xây dựng cơ sở tri thức và biểu đồ tri thức cũng như biểu diễn/lập luận dựa trên các cấu trúc này (Web ngữ nghĩa).
Có hai cách tiếp cận chung để xây dựng một cơ sở tri thức. Một cách tiếp cận là lấy dữ liệu từ web cũng như các nguồn dữ liệu khác, sắp xếp chúng vào cơ sở dữ liệu tri thức mong muốn (chủ yếu là các bộ sưu tập "bộ ba" hoặc "đồ thị" khổng lồ), sau đó thực hiện các kỹ thuật "logic bậc cao" hoặc máy học để suy luận về cấu trúc và các nhiệm vụ thông minh khác). Một cách tiếp cận khác là dựa vào trí thông minh của con người để cộng tác xây dựng cơ sở dữ liệu (ví dụ: Wikipedia, ConceptNet hoặc dự án Khoa học Công dân, mà chúng ta sẽ thảo luận chi tiết hơn sau).
Bài viết này trước tiên sẽ xem xét một số đổi mới có liên quan trong vài thập kỷ qua, sau đó thảo luận về cách chúng ta có thể tiến tới xây dựng cơ sở dữ liệu tri thức cấp cao với trí tuệ tập thể và cơ chế khuyến khích bền vững.
Cơ sở tri thức, Sơ đồ tri thức và Wikipedia
Trong một thời gian dài, người ta đã quan tâm đến việc tạo ra các biểu đồ tri thức vì hai lý do chính:
Các dấu chấm kết nối tất cả thông tin và kiến thức do con người tạo ra,
Và thực hiện các kỹ thuật lập luận và máy học trên biểu đồ tri thức để tạo ra trí tuệ nhân tạo tốt hơn và sử dụng hệ thống này để cải thiện trải nghiệm người dùng của các sản phẩm Web2.
Ngay bây giờ, các biểu đồ tri thức rõ ràng hữu ích hầu hết được tạo ra làm công cụ nền tảng cho các tập đoàn lớn trong Web2. Ví dụ: Sơ đồ tri thức của Facebook giúp tìm kiếm trên mạng xã hội tốt hơn và Sơ đồ tri thức của Google giúp trình bày thông tin liên quan. Vì mọi thứ đều là nguồn đóng nên chúng tôi không biết biểu đồ tri thức được xây dựng như thế nào, nhưng từ quan điểm UI, những biểu đồ tri thức này chắc chắn sẽ giúp cải thiện trải nghiệm người dùng.
Những nỗ lực của cộng đồng Wikipedia thật tuyệt vời. Đó là một trong những nỗ lực đầu tiên để chứng minh sức mạnh của cộng đồng internet. Mặt khác, cơ sở dữ liệu mở có thể được sử dụng như hàng hóa công cộng trên Internet. Một ví dụ là DBpedia, một cơ sở dữ liệu cung cấp API cho các ứng dụng muốn tận dụng cơ sở tri thức Wikipedia. Một ví dụ khác là ConceptNet, một mạng ngữ nghĩa có sẵn miễn phí giúp các chương trình AI và NLP có được ngữ nghĩa chung.
Tuy nhiên, có một số giới hạn cơ bản về mức độ mà các tổ chức phi chính phủ trên Internet này có thể làm được. Wikipedia dựa vào các khoản đóng góp hàng năm, nó hoạt động trong một tổ chức 501(c)3, rất khó để đưa ra các biện pháp khuyến khích nâng cao hơn cho nó và xây dựng cơ sở hạ tầng tốt hơn dựa trên các mạng tri thức. Điều tương tự cũng xảy ra với DBpedia và ConceptNet, v.v. Là các tổ chức phi lợi nhuận, rất khó để các tổ chức phúc lợi công cộng này xây dựng sâu sắc một cộng đồng liên tục xây dựng cơ sở hạ tầng và cuối cùng hình thành một hệ sinh thái. Tôi đã xây dựng một công cụ tìm kiếm và trực quan hóa biểu đồ Wikipedia ở trường đại học bằng cách sử dụng API của DBpedia. Tuy nhiên, việc tham gia vào một cộng đồng sôi động hồi đó khó khăn hơn nhiều. Giờ đây, trong cộng đồng tiền điện tử, tình hình đã rất khác, các nhà phát triển có ý tưởng hay có thể tham gia nhiều hoạt động hơn, thành lập nhóm và được hỗ trợ bởi hệ sinh thái đa chuỗi.
Tuy nhiên, tôi không khuyên bạn nên xây dựng một Wikipedia khác (hay còn gọi là DAO-ify Wikipedia, hoặc "Web3 Wikipedia"), bởi vì bất chấp những hạn chế của mô hình phi lợi nhuận hiện tại, các trang Wikipedia được quản lý tốt về nội dung và cấu trúc. Và các tổ chức, mọi người đã được hưởng lợi từ nó. kết quả ở mức độ lớn. Nói chung, Wikipedia rất giỏi trong việc lưu trữ các mô tả về kiến thức và thông qua cơ sở hạ tầng Web1 và Web2, chúng tôi đã làm cho kiến thức có thể tìm kiếm được. Điều mà Wikipedia và cơ sở hạ tầng web hiện tại không giỏi là trình bày kiến thức cho "sự hiểu biết của con người" - kiến thức được cấu trúc trong bộ não con người. Để trình bày thông tin này, sự hợp tác giữa con người và con người là cốt lõi, điều này không được hỗ trợ tốt trong cơ sở hạ tầng Web1/Web2, nhưng sẽ có thể thực hiện được thông qua cơ chế phối hợp và cơ sở hạ tầng Web3
**Điều đáng chú ý là mọi người cố gắng xây dựng cơ sở dữ liệu cấu trúc khổng lồ để nâng cao hiểu biết của máy về kiến thức. Ví dụ, các công ty như Cyc đã cố gắng trong nhiều thập kỷ để xây dựng một cơ sở tri thức hợp lý nhằm giúp máy móc bắt chước bộ não con người. Những công ty này cuối cùng đã tự biến mình thành công ty phần mềm kinh doanh, bởi vì AI mạnh mẽ rõ ràng đòi hỏi nhiều hơn một nền tảng kiến thức về các nút và mối quan hệ. So với việc xây dựng cơ sở tri thức có cấu trúc cho máy móc, hiểu biết của con người về tri thức và quản lý con người rất quan trọng ở đây - xây dựng cơ sở tri thức về hiểu biết của con người để giúp nhiều người hiểu hơn.
Mặt khác, đáng suy nghĩ về cách thêm ngữ nghĩa cấp cao hơn vào Web Kiến thức hiện tại, kiến thức có cấu trúc mà chúng tôi mô tả trong bài viết này.
Khoa học công dân và máy tính tình nguyện
Một nhánh khám phá khác mà tôi muốn đề cập là khoa học công dân và điện toán tình nguyện. Đầu những năm 2010, giới khoa học có nhiều dự án thú vị khai thác trí tuệ đám đông để đẩy nhanh tiến độ nghiên cứu và khám phá khoa học. Nói chung có hai loại nỗ lực như vậy. Đầu tiên được gọi là điện toán tự nguyện, phân phối các tác vụ điện toán cho một nhóm thiết bị điện toán riêng lẻ (ví dụ: LHC@Home, SETI@Home). Loại thứ hai được gọi là khoa học công dân, tạo ra các nhiệm vụ lặp đi lặp lại (không phải là một thuật ngữ mang tính miệt thị ở đây!) mà mọi người đều có thể thực hiện được. Dự án thu thập dữ liệu (và đôi khi là kết quả phân tích) từ nhiều người đóng góp và cung cấp chúng cho một số dự án nghiên cứu để tạo ra kết quả có ý nghĩa (ví dụ: các dự án được liệt kê trong Citizen Cyberlab, SciStarter hoặc Cộng đồng học máy, Hình ảnh được gắn thẻ để làm phong phú thêm dữ liệu đào tạo có thể được đóng góp cộng đồng). Hãy coi những nỗ lực này là "DAO" mà không phát minh ra từ này, khía cạnh phối hợp của các cộng đồng phi tập trung không có gì mới!
Nhiều dự án đã thành công, nhưng một lần nữa, thật không may, tính bền vững của những dự án này đã bị hạn chế. SETI@Home không còn hoạt động nữa và nhiều dự án khoa học công dân lẽ ra có thể tồn tại lâu hơn thì không. Khuyến khích và hệ sinh thái là hai khía cạnh quan trọng của bất kỳ nỗ lực hợp tác nào. Không có hệ sinh thái, sự đổi mới bị hạn chế. Nếu không có các khuyến khích bền vững, sẽ không có cộng đồng sôi động và sẽ không có hệ sinh thái nào xuất hiện.
Cấu trúc của các khái niệm và kiến thức phức tạp
Bây giờ chúng ta hãy xem xét các khái niệm và kiến thức cấp cao trông như thế nào. Theo trực giác, khi chúng ta "hiểu" một khái niệm, chúng ta thực sự hiểu khái niệm đó rất chi tiết. Chúng ta có thể nghĩ về quá trình "hiểu" theo hai cách:
1. Tìm hiểu qua cấu trúc cây
Cây càng bị chia nhỏ thì khái niệm càng sơ khai. Tại một số điểm, sẽ có một số tài nguyên rất trực tiếp trên web có thể được tham chiếu trực tiếp (ví dụ: trang Wikipedia hoặc một số bài viết/video).
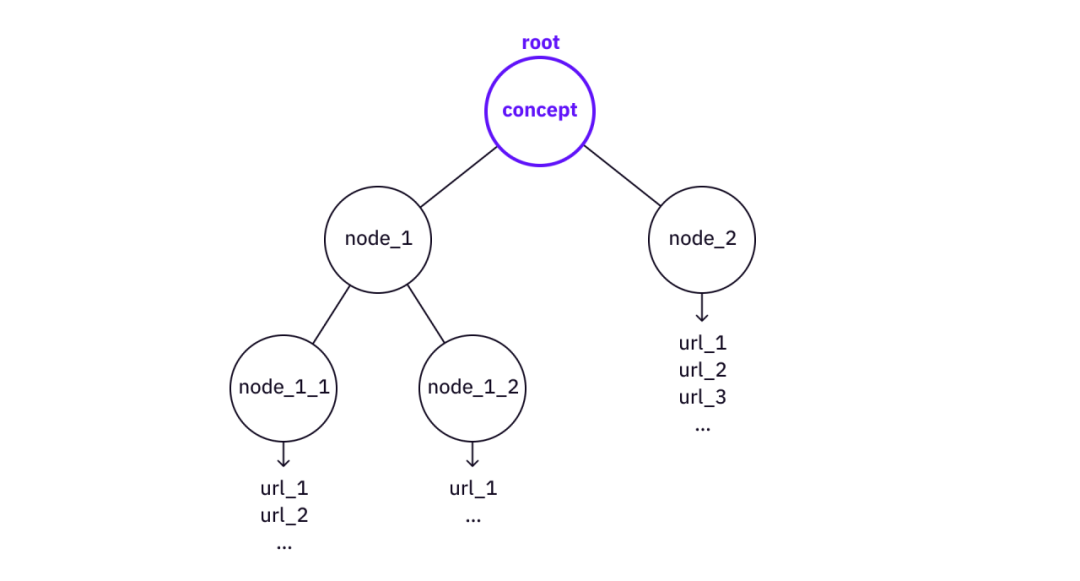
Mô tả hình ảnh
Khái niệm "chia nhỏ" thành cấu trúc cây
Chúng ta có thể tìm thấy một số ý tưởng tương tự từ AI cũ. Lý thuyết K-line cho thấy ký ức và kiến thức của chúng ta được lưu trữ trong các cấu trúc cây (P-node và K-node). Mặc dù thiếu bằng chứng thực tế cho thấy các cấu trúc như vậy thực sự tồn tại trong não của chúng ta, nhưng mô hình này có khả năng giải thích cách thức hoạt động của bộ nhớ con người và bộ não con người, và cấu trúc cây thực sự là hình thức lưu trữ kiến thức cấu trúc cô đọng nhất.
Nếu chúng tôi muốn truy xuất chi tiết, chúng tôi sẽ phân tách một cây tri thức. Mặt khác, nếu chúng ta có một cây kiến thức, chúng ta có thể sử dụng cây này để xây dựng những cây lớn hơn (hay còn gọi là kiến thức và hiểu biết trừu tượng cao hơn).
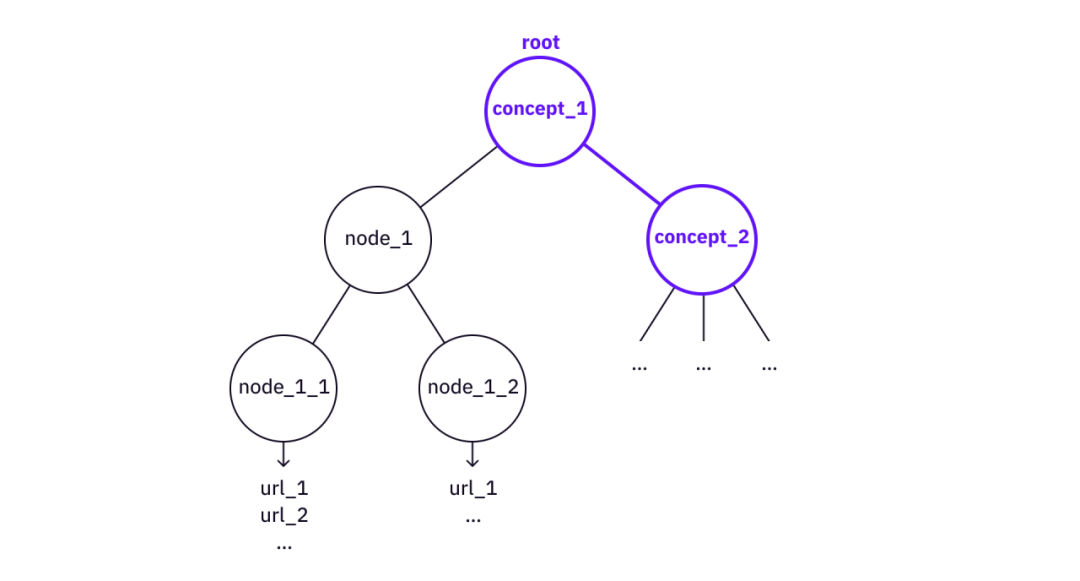
Mô tả hình ảnh
Sử dụng Concept_2 "Tòa nhà" Concept_1
Trong trường hợp "xây dựng", cây "Cây Merkle" có thể được sử dụng làm nút để xây dựng cây tri thức phức tạp hơn, chẳng hạn như "Cây Verkle" hoặc "Merkle Multiple Proofs".
Điều đáng chú ý là điểm mấu chốt ở đây là cấu trúc của cây. Cây tri thức trỏ đến tất cả các tham chiếu cần thiết đến các tài nguyên web hiện có từ khái niệm gốc cho đến các lá. Mối quan hệ giữa các nút không quan trọng ở đây (không giống như tư duy "bộ ba" trong các hệ thống biểu đồ tri thức).
2. Hiểu thông qua “kiến thức liên quan”
Chúng tôi cũng hiểu sâu hơn về kiến thức bằng cách thêm nhiều "ngữ cảnh". Như Weigenstain đã nói một câu nổi tiếng, "Nhưng từ 'năm' nghĩa là gì? Không có câu hỏi nào như vậy ở đây, chỉ có cách sử dụng từ 'năm'". Ý tưởng đằng sau nó là ý nghĩa của một cái gì đó thực sự phụ thuộc vào các khái niệm khác liên quan đến nó, những khái niệm này cùng xác định ý nghĩa của một cái gì đó. Bằng cách bổ sung thêm ngữ cảnh (tức là kiến thức liên quan của chính kiến thức đó), chúng ta có thể hiểu kiến thức “sâu hơn” hơn.
Nói chung, mọi người dễ hiểu cây hơn đồ thị. Thay vì xây dựng một bản đồ tri thức, tốt hơn là nên nghĩ về "kiến thức liên quan" như một cách thực tế hơn - một tập hợp các cây tri thức được kết nối bởi các nút gốc, về cơ bản tạo thành một khu rừng tri thức.
Một khu rừng tri thức có thể được xây dựng như một cơ sở dữ liệu của nhiều cây tri thức (trồng song song). Có hai thao tác cơ bản chúng ta có thể thực hiện trên cơ sở dữ liệu.
Các đặc trưng của cây tri thức có thể được xây dựng dưới dạng các vectơ trong một không gian vectơ nhất định. Các vectơ sau đó có thể được sử dụng để liên kết các cây tri thức có liên quan về mặt khái niệm nhưng không được liên kết trực tiếp bởi (1).
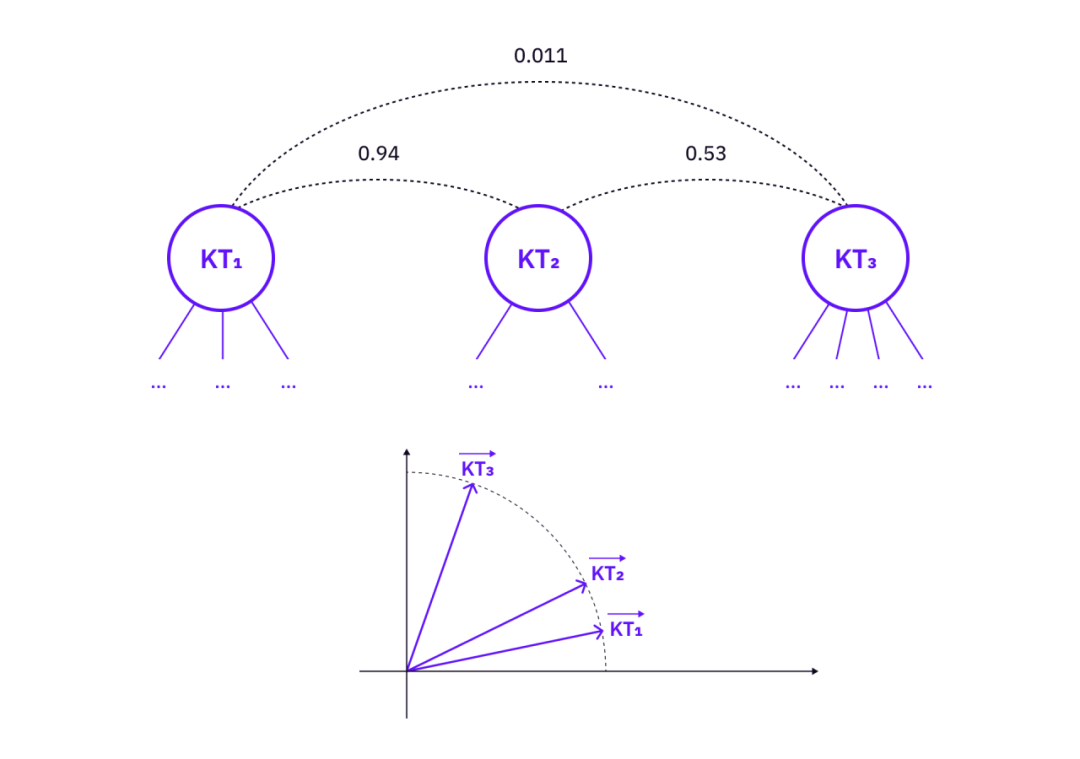
Mô tả hình ảnh
Đo lường mối quan hệ giữa các cây tri thức
về chiều sâu của sự hiểu biết
Nói chung, mọi người có mức độ hiểu biết khác nhau về cùng một khái niệm. Đối với một số người, khái niệm về cây Merkle rất đơn giản và không cần phải chia nhỏ thêm (bộ não của họ đã gói gọn khái niệm này vào một ý nghĩa thông thường nào đó), trong khi những người khác không có đủ thông tin để hiểu khái niệm về một “cây Merkle”. " và có thể cần Phân tích thêm.
Do đó, cây tri thức không nhất thiết phải loại trừ lẫn nhau, nghĩa là có thể có sự chồng chéo giữa các cây khác nhau. Có thể có các cây giải thích các khái niệm cơ bản và các cây được xây dựng cho các khái niệm nâng cao.
Chồng chéo có thể tạo ra sự dư thừa giữa các cây. Để giảm sự dư thừa, chúng tôi có thể giới thiệu các hoạt động sau:
Hợp nhất - Có thể đã có các cây con bên dưới các nút của cả hai cây và nếu một số nút, lá và tham chiếu có giá trị chưa được bao phủ bởi cây cơ sở, thì có thể hợp nhất thông tin từ cây cấp cao hơn sang cây cơ sở hơn.
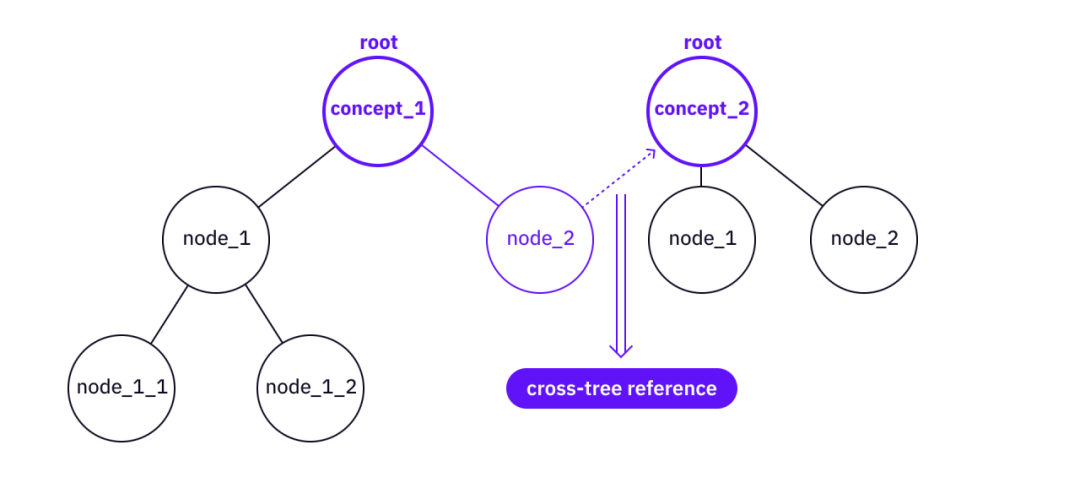
Liên kết tham chiếu cây chéo
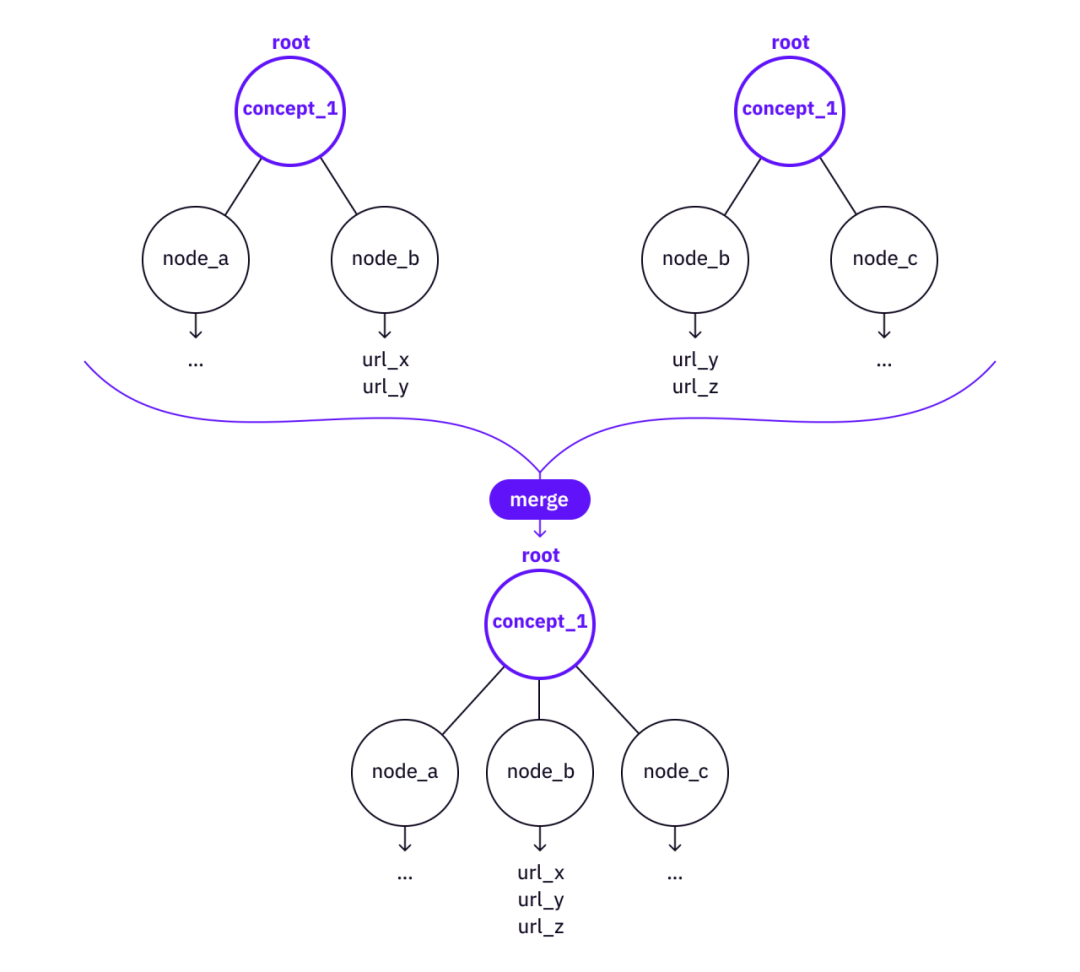
Mô tả hình ảnh
Hợp nhất hai cây thành một
Cây tri thức và siêu hoạt động
Một cây tri thức duy nhất bao gồm một gốc, một tập hợp các nút con và một tập hợp các lá, được tổ chức thành một cấu trúc cây. Sau đó, chúng ta có thể xác định một tập hợp các thao tác cơ bản để tạo và tinh chỉnh một cây.
tạo gốc (cây)
thêm nút con
Thêm lá vào nút
Thêm liên kết tham chiếu đến lá
Sau đó, chúng tôi có thể xác định một loạt các hành động cấp cao để người dùng thực tế "trồng" và đóng góp cho cây.
Thêm cây con - giới thiệu các nút con cần thiết cho cây tri thức với đầy đủ các nút và lá
Hợp nhất hai cây của cùng một khái niệm
rừng tri thức
Hãy trồng thật nhiều cây tri thức, và chúng ta có một khu rừng tri thức!
Một khu rừng tri thức là một nhóm lớn các cây tri thức được trồng cùng nhau. Một sự thật thú vị về khu rừng tri thức là có thể có sự vướng víu giữa các cây. Về lý thuyết, các kết nối giữa các nút và lá khác nhau có thể tùy ý (ví dụ: liên kết giữa lá của cây này với gốc của cây khác). Trên thực tế, nếu chúng ta thêm các liên kết chấm, "đại loại" Rừng tri thức sẽ trở thành Sơ đồ tri thức. Tuy nhiên, cây tri thức cá nhân mới là vấn đề quan trọng.
Ví dụ: các đường đứt nét chỉ ra các liên kết giữa cây MACI và cây zk-Snark.
Các lá của cây tri thức kết nối với các bài viết/video/tài nguyên hiện có trên web. Do đó, các lớp phía trên những chiếc lá này là thông tin cấu trúc hoặc lớp hiểu biết.
Những gì chúng ta có thể làm với Khu rừng tri thức là hoàn toàn mở. Có lẽ điều quan trọng nhất mà chúng ta nên xem xét là một hệ sinh thái gồm các cơ sở tri thức hợp tác ngay từ đầu. Chúng ta có thể muốn làm nhiều thứ với rừng tri thức, đây là ba ví dụ:
Trực quan hóa Cây tri thức và Rừng tri thức
Duyệt qua Rừng kiến thức qua các liên kết chấm
Tìm cụm cây tri thức
Các tổ chức phi lợi nhuận có thể khiến mọi thứ xảy ra, nhưng DAO có thể làm mọi thứ tốt hơn. Ý tưởng ở đây là ánh xạ một tập hợp các hoạt động của cây thành một tập hợp các tác nhân kích thích. Các siêu hoạt động càng được tiêu chuẩn hóa thì DAO càng có khả năng mở rộng để điều phối các thành viên của nó.
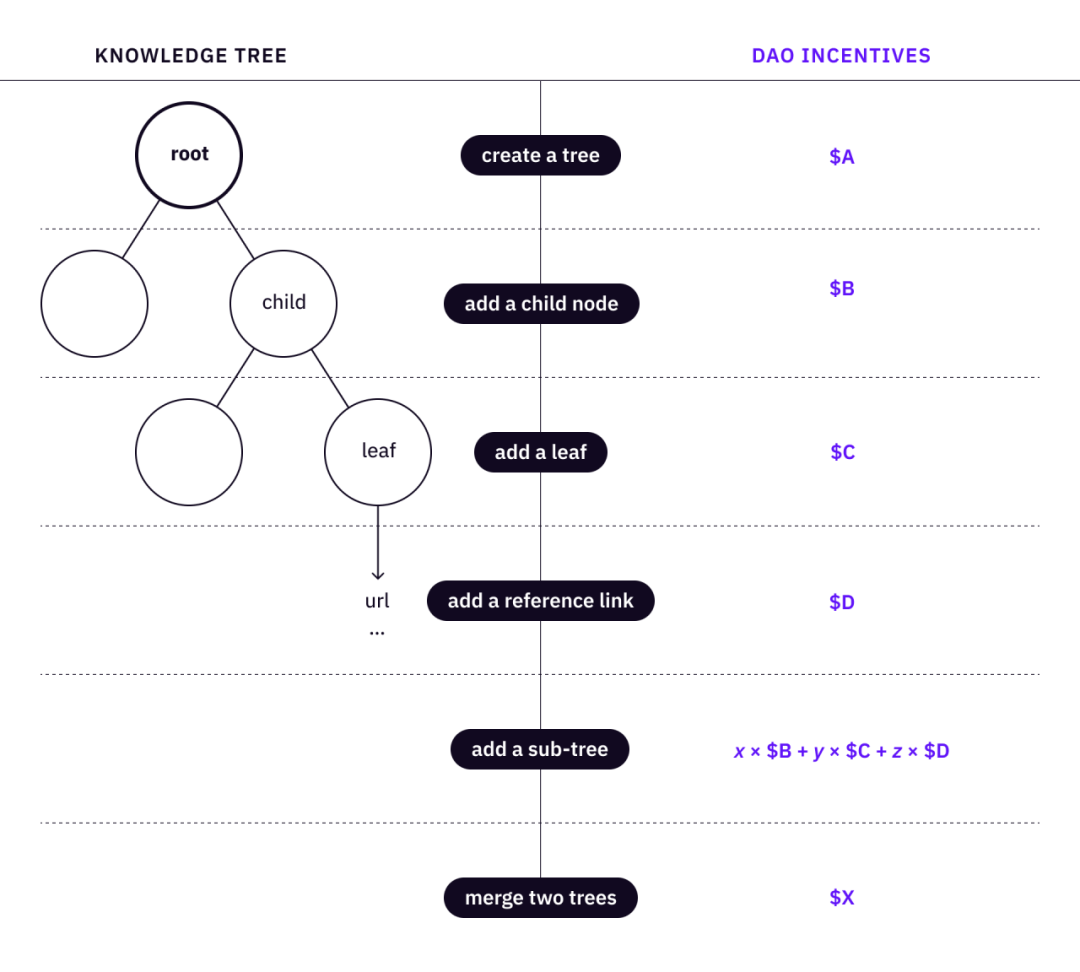
Mô tả hình ảnh<->vận hành cây tri thức
DAO Đóng góp
Trong trường hợp cây tri thức, người đóng góp DAO có thể tạo gốc (tương đương với "tạo/trồng cây"), thêm đường dẫn tri thức ("trồng cây") và thêm liên kết tham chiếu đến các lá. Cơ chế khuyến khích tạo ra một bộ quy tắc để thưởng cho những người đóng góp cho cộng đồng, những người thực hiện các hành động có thể kiểm chứng để lập kế hoạch và phát triển cây tri thức.
Ngoài ra, các ủy ban đánh giá (hoặc các nhóm đánh giá) rất quan trọng đối với việc lập kế hoạch và kiểm soát chất lượng. Sự phối hợp và khuyến khích cho DAO đã được thử nghiệm rộng rãi với (ví dụ: DAOrayaki DAO) và một cấu trúc tương tự có thể được triển khai tại đây.
Rừng tri thức và Sơ đồ tri thức
Cây dễ hiểu hơn khi chúng ta học các khái niệm mới và thu được kiến thức. Đối với bất kỳ chủ đề cụ thể nào, con người dễ dàng hiểu cấu trúc kiến thức trong cây vì không có vòng lặp trong cây và nếu độ sâu của cây được giới hạn ở một mức nhất định, bộ não con người sẽ dễ dàng hiểu hơn nhiều. xử lý và ghi nhớ.
Hơn nữa, các biểu diễn đồ thị tri thức bị hạn chế trong việc biểu diễn các kết nối không rõ ràng hoặc không rõ ràng giữa các nút tri thức (vấn đề tương tự như biểu diễn tri thức thông thường).
Một nhóm các BUIDLer đang làm việc để triển khai thực tế Cây tri thức và Rừng tri thức có nhiều chi tiết - cấu trúc dữ liệu, thiết kế sản phẩm, chi tiết đóng góp và khuyến khích, giao diện người dùng, v.v. Tuy nhiên, nếu một khu rừng tri thức được xây dựng, tôi cảm thấy rằng nhìn chung nó nên được tổ chức như một hàng hóa công cộng và cung cấp cho mọi người trên thế giới. Nhưng hãy xem những gì cộng đồng Dora nghĩ ra!
Tóm lại là
Ý tưởng là xây dựng một loại cơ sở tri thức mới trên cơ sở hạ tầng web hiện có (chẳng hạn như Wikipedia, v.v.) và cung cấp cho mọi người, do đó giảm thiểu sự phức tạp của việc hiểu kiến thức trừu tượng (thông qua Định tuyến web trên biểu đồ tri thức như Wikipedia hoặc Wikipedia có thể phức tạp như O(nlog(n)), nhưng một cây có n nút chỉ sâu log(n), giúp điều hướng dễ dàng hơn). Phối hợp với những người đóng góp trong DAO và sử dụng các ưu đãi tiền điện tử tiên tiến để đảm bảo tính bền vững của tổ chức. Các ý tưởng trong bài viết này chưa hoàn chỉnh, còn rất nhiều chỗ để thảo luận và cải tiến, cũng như có rất nhiều vấn đề về kỹ thuật và sản phẩm cần xem xét nếu một nhóm muốn biến nó thành hiện thực.
người giới thiệu
người giới thiệu
Web ngữ nghĩa: https://en.wikipedia.org/wiki/Semantic_Web
Ba: https://conceptnet.io/
ConceptNet:https://conceptnet.io/
DBpedia:https://www.dbpedia.org/
Logic bậc cao hơn: https://en.wikipedia.org/wiki/Cyc
https://github.com/zhangjiannan/Graphpedia
Các công cụ tìm kiếm và trực quan hóa biểu đồ Wikipedia:
Cyc:https://en.wikipedia.org/wiki/Cyc
Hệ sinh thái đa chuỗi: https://hackerlink.io/grant/dora-factory/top
LHC@Home:https://lhcathome.cern.ch/lhcathome/
SETI@Home:https://setiathome.berkeley.edu/
Citizen Cyberlab:https://www.citizencyberlab.org/projects/
SciStarter:https://scistarter.org/
Máy tính tình nguyện: https://en.wikipedia.org/wiki/Volunteer_computing
Công cụ xây dựng biểu đồ tri thức 1: https://obsidian.md/


