
Google AI Paper Accused of Falsifying Experiments, Causing $90 Billion Plunge in Storage Stocks
- Key Takeaway: A Google paper on AI memory compression technology TurboQuant has sparked academic controversy due to allegations of unfairness in comparative experiments, insufficient citation of prior research, and potential distortion of performance advantages. Its market promotion directly triggered severe volatility in the global memory chip sector.
- Key Elements:
- Core Controversy Allegations: The paper is accused of inadequately explaining its key technical relationship with the RaBitQ algorithm. In speed comparisons, it tested RaBitQ using a single-core CPU Python script while testing its own method with an A100 GPU, constituting an unfair comparison.
- Sharp Market Reaction: After Google's official blog promoted the paper, market concerns about reduced AI memory demand led to a single-day market value loss exceeding $90 billion for memory chip stocks like Micron and SanDisk.
- Technical Contribution Validated: Independent community verification indicates that the compression effectiveness of the TurboQuant algorithm is largely accurate; its mathematical contribution is genuine.
- Institutional Analysis Rebuttal: Analysts from institutions like Morgan Stanley point out that the technology only compresses a specific cache (KV Cache), representing a normal efficiency improvement. Furthermore, efficiency gains might stimulate larger-scale AI deployment, ultimately increasing memory demand.
- Transmission Chain Risk Highlighted: The incident reveals the systemic risk where repackaging existing academic papers as market narratives, if containing experimental bias or presentation issues, can cause significant shocks to financial markets.
ผู้เขียนต้นฉบับ: Deep Tide TechFlow
เอกสารวิจัยของ Google ที่อ้างว่า "บีบอัดการใช้หน่วยความจำ AI ให้เหลือเพียง 1/6" เมื่อสัปดาห์ที่แล้ว ส่งผลให้มูลค่าตลาดของหุ้นชิปหน่วยความจำทั่วโลก เช่น Micron, SanDisk ระเหยไปกว่า 900 พันล้านดอลลาร์
อย่างไรก็ตาม เพียงสองวันหลังจากการเผยแพร่เอกสาร Jianyang Gao นักวิจัยหลังปริญญาเอกที่ ETH Zurich ซึ่งเป็นฝ่ายที่ถูกเปรียบเทียบและ "ถูกบดขยี้" โดยอัลกอริทึม ได้เผยแพร่จดหมายเปิดผนึกยาวหนึ่งหมื่นคำ กล่าวหาว่าทีม Google ใช้สคริปต์ Python แบบ single-core CPU ในการทดสอบคู่แข่ง ในขณะที่ใช้ GPU A100 ทดสอบตัวเอง และปฏิเสธที่จะแก้ไขแม้จะได้รับการแจ้งปัญหาก่อนส่งตีพิมพ์ การอ่านบน Zhihu พุ่งเกิน 4 ล้านครั้ง บัญชีทางการของ Stanford NLP แชร์ต่อ ทั้งแวดวงวิชาการและตลาดต่างสั่นสะเทือน
ปัญหาหลักของข้อพิพาทนี้ไม่ซับซ้อน: เอกสารวิจัยระดับท็อปของ AI ที่ได้รับการโปรโมตอย่างกว้างขวางโดยทางการ Google และทำให้เกิดการเทขายแบบตื่นตระหนกในกลุ่มหุ้นชิปทั่วโลกโดยตรง ได้บิดเบือนงานวิจัยก่อนหน้าที่ตีพิมพ์แล้วอย่างเป็นระบบหรือไม่ และสร้างเรื่องเล่าถึงความได้เปรียบด้านประสิทธิภาพที่ผิดพลาดผ่านการทดลองที่ไม่เป็นธรรมที่สร้างขึ้นโดยเจตนา?
TurboQuant ทำอะไร: บีบ "กระดาษร่าง" ของ AI ให้บางลงเหลือหนึ่งในหกของเดิม
เมื่อโมเดลภาษาขนาดใหญ่สร้างคำตอบ พวกมันต้องคอยมองย้อนกลับไปที่เนื้อหาที่คำนวณไปแล้วขณะที่เขียน ผลลัพธ์กลางเหล่านี้ถูกเก็บชั่วคราวในหน่วยความจำกราฟิก ภายในอุตสาหกรรมเรียกว่า "KV Cache" (คีย์-แวลู แคช) ยิ่งบทสนทนายาว "กระดาษร่าง" นี้ก็ยิ่งหนา การใช้หน่วยความจำกราฟิกก็ยิ่งมาก ต้นทุนก็ยิ่งสูง
จุดขายหลักของอัลกอริทึม TurboQuant ที่พัฒนาโดยทีมวิจัยของ Google คือการบีบอัดกระดาษร่างนี้ให้เหลือ 1/6 ของเดิม พร้อมทั้งอ้างว่าความแม่นยำไม่ลดลง และความเร็วในการอนุมานเพิ่มสูงสุด 8 เท่า เอกสารวิจัยเผยแพร่ครั้งแรกบนแพลตฟอร์ม preprint ทางวิชาการ arXiv ในเดือนเมษายน 2025 ถูกตีพิมพ์ในงานประชุมระดับท็อปด้าน AI ICLR 2026 ในเดือนมกราคม 2026 และถูกนำมาโปรโมตใหม่ผ่านบล็อกทางการของ Google ในวันที่ 24 มีนาคม
ในระดับเทคนิค แนวคิดของ TurboQuant สามารถเข้าใจง่ายๆ ได้ว่า: เริ่มแรกใช้การแปลงทางคณิตศาสตร์เพื่อ "ล้าง" ข้อมูลที่ยุ่งเหยิงให้เป็นรูปแบบมาตรฐาน จากนั้นใช้ตารางบีบอัดที่คำนวณไว้ล่วงหน้าที่ดีที่สุดเพื่อบีบอัดทีละส่วน สุดท้ายใช้กลไกแก้ไขข้อผิดพลาด 1 บิตเพื่อแก้ไขความคลาดเคลื่อนจากการคำนวณที่เกิดจากการบีบอัด การนำไปใช้โดยอิสระของชุมชนได้ยืนยันว่าผลการบีบอัดเป็นเรื่องจริงโดยพื้นฐาน ผลงานทางคณิตศาสตร์ในระดับอัลกอริทึมมีอยู่จริง
ข้อพิพาทไม่ได้อยู่ที่ว่า TurboQuant ใช้ได้หรือไม่ แต่อยู่ที่ว่า Google ทำอะไรเพื่อพิสูจน์ว่ามัน "เหนือกว่าคู่แข่งอย่างมาก"
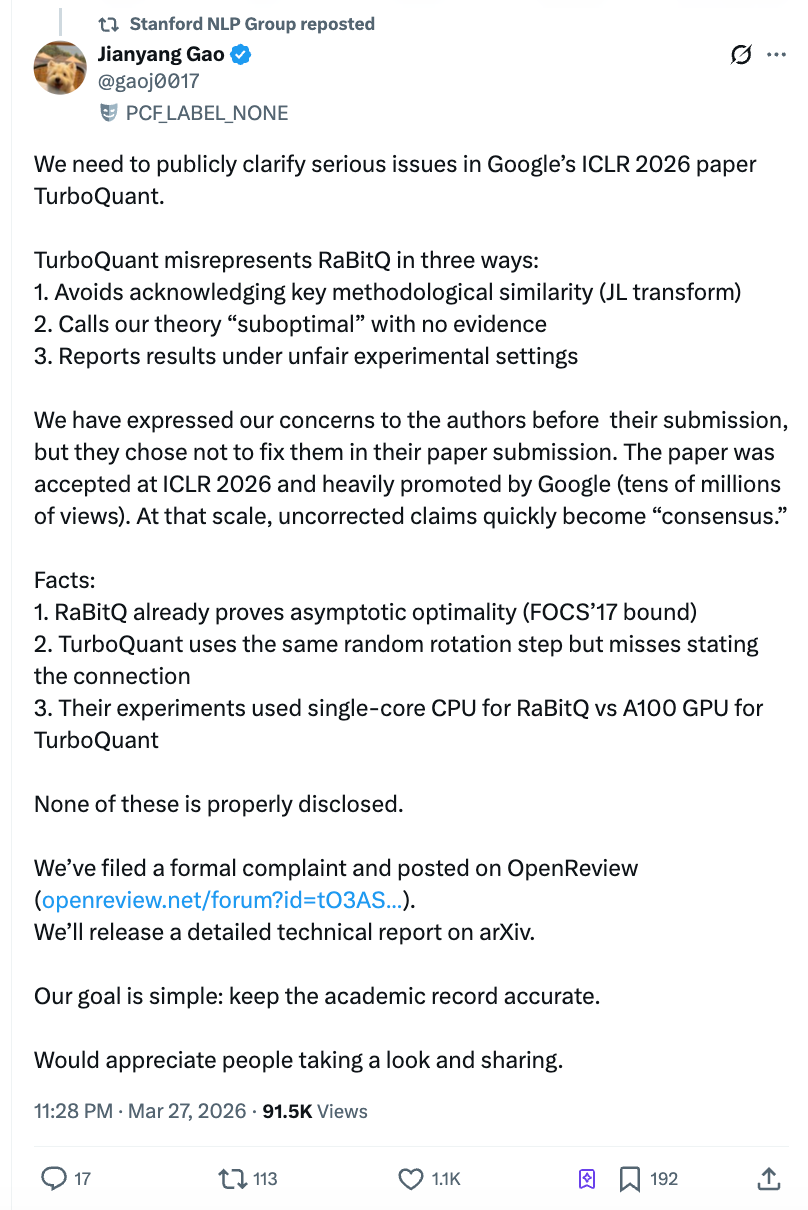
จดหมายเปิดผนึกของ Jianyang Gao: สามข้อกล่าวหา แต่ละข้อโดนจุดสำคัญ
เวลา 22.00 น. ของวันที่ 27 มีนาคม Jianyang Gao เผยแพร่บทความยาวบนZhihu พร้อมส่งความคิดเห็นอย่างเป็นทางการบนแพลตฟอร์มรีวิวทางการของ ICLR, OpenReview Jianyang Gao เป็นผู้เขียนหลักของอัลกอริทึม RaBitQ ซึ่งตีพิมพ์ในงานประชุมระดับท็อปด้านฐานข้อมูล SIGMOD ในปี 2024 แก้ไขปัญหาประเภทเดียวกัน นั่นคือการบีบอัดเวกเตอร์มิติสูงอย่างมีประสิทธิภาพ
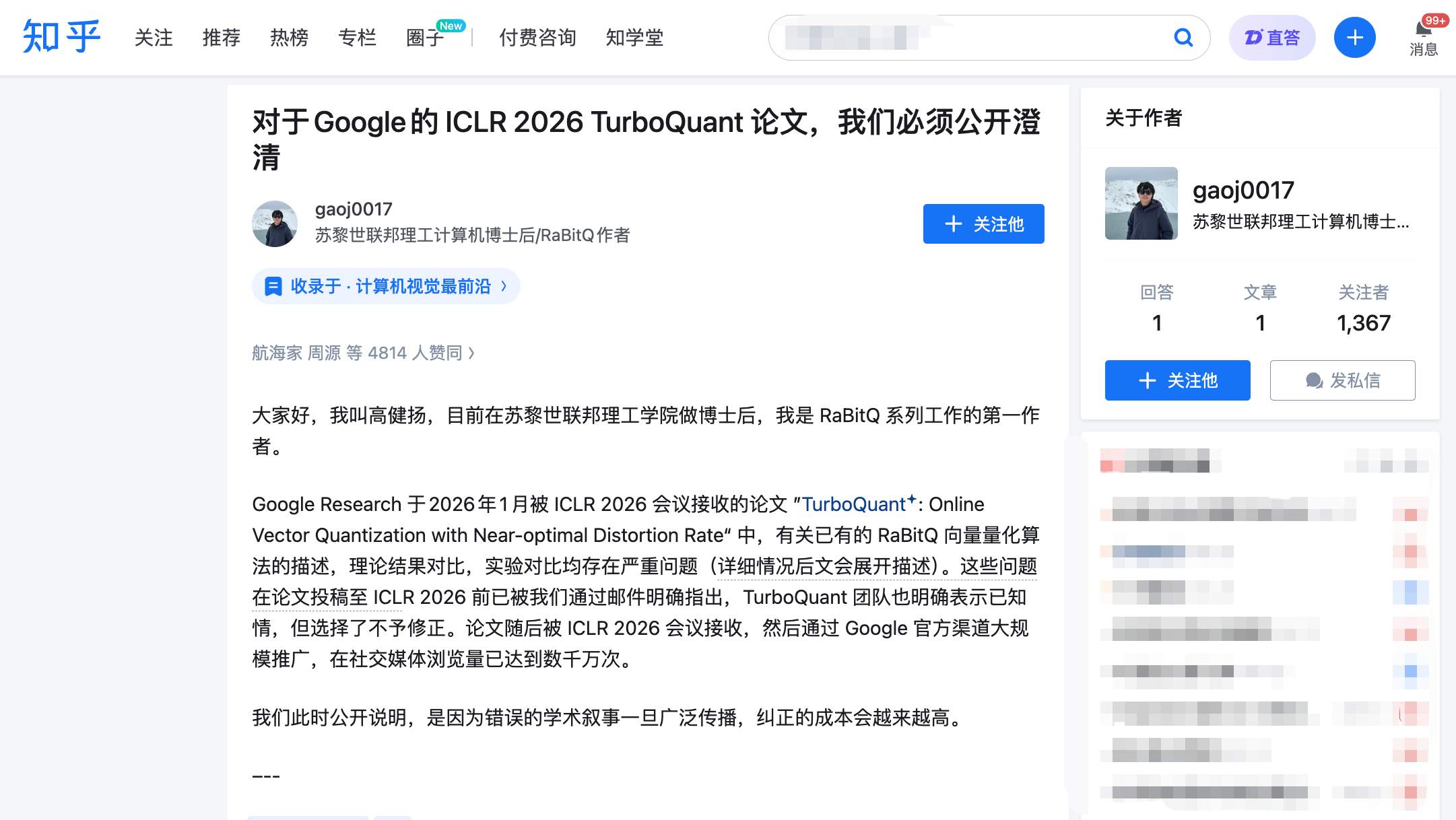
ข้อกล่าวหาของเขามีสามข้อ แต่ละข้อมีบันทึกอีเมลและไทม์ไลน์สนับสนุน
ข้อกล่าวหาที่หนึ่ง: ใช้วิธีการหลักของผู้อื่น แต่ไม่เอ่ยถึงทั้งเอกสาร
แกนกลางทางเทคนิคของ TurboQuant และ RaBitQ มีขั้นตอนสำคัญที่เหมือนกัน: ก่อนบีบอัดข้อมูล ให้ทำ "การหมุนแบบสุ่ม" กับข้อมูลก่อน การดำเนินการนี้มีหน้าที่เปลี่ยนข้อมูลที่กระจายตัวไม่ปกติให้กลายเป็นการกระจายตัวสม่ำเสมอที่คาดการณ์ได้ จึงลดความยากในการบีบอัดลงอย่างมาก นี่เป็นส่วนที่สำคัญที่สุดและใกล้เคียงที่สุดของทั้งสองอัลกอริทึม
ผู้เขียน TurboQuant เองก็ยอมรับจุดนี้ในการตอบกลับการรีวิว แต่ในเอกสารวิจัยทั้งหมด ไม่เคยอธิบายความเชื่อมโยงระหว่างวิธีการนี้กับ RaBitQ อย่างตรงไปตรงมา พื้นหลังที่สำคัญยิ่งกว่านั้นคือ: ผู้เขียนคนที่สองของ TurboQuant, Majid Daliri ในเดือนมกราคม 2025 ได้ติดต่อทีมของ Jianyang Gao โดยสมัครใจ ขอให้ช่วยดีบักเวอร์ชัน Python ที่เขาเขียนใหม่จากซอร์สโค้ดของ RaBitQ อีเมลอธิบายขั้นตอนการทำซ้ำและข้อมูลข้อผิดพลาดอย่างละเอียด กล่าวอีกนัยหนึ่งคือ ทีม TurboQuant รู้รายละเอียดทางเทคนิคของ RaBitQ เป็นอย่างดี
ผู้รีวิวนิรนามของ ICLR คนหนึ่งก็ชี้ให้เห็นอย่างอิสระว่าทั้งสองใช้เทคนิคเดียวกัน และขอให้มีการอภิปรายอย่างเพียงพอ แต่ในเอกสารฉบับสุดท้าย ทีม TurboQuant ไม่เพียงไม่ได้เพิ่มการอภิปราย แต่กลับย้ายคำอธิบายเกี่ยวกับ RaBitQ (ที่ไม่สมบูรณ์อยู่แล้ว) จากเนื้อหาหลักไปไว้ในภาคผนวก
ข้อกล่าวหาที่สอง: ติดป้ายว่าทฤษฎีของฝ่ายตรงข้าม "ไม่เหมาะสมที่สุด" โดยไม่มีหลักฐาน
เอกสาร TurboQuant ติดป้ายว่า RaBitQ "ไม่เหมาะสมที่สุดทางทฤษฎี" (suboptimal) โดยให้เหตุผลว่าการวิเคราะห์ทางคณิตศาสตร์ของ RaBitQ "ค่อนข้างหยาบ" แต่ Jianyang Gao ชี้ให้เห็นว่า เอกสารวิจัยเวอร์ชันขยายของ RaBitQ ได้พิสูจน์อย่างเคร่งครัดว่าความคลาดเคลื่อนในการบีบอัดของมันบรรลุขอบเขตที่เหมาะสมที่สุดทางคณิตศาสตร์แล้ว ข้อสรุปนี้ตีพิมพ์ในงานประชุมระดับท็อปด้านวิทยาการคอมพิวเตอร์เชิงทฤษฎี
ในเดือนพฤษภาคม 2025 ทีมของ Jianyang Gao ได้อธิบายความเหมาะสมที่สุดทางทฤษฎีของ RaBitQ อย่างละเอียดผ่านอีเมลหลายรอบ ผู้เขียนคนที่สองของ TurboQuant, Daliri ยืนยันว่าได้แจ้งผู้เขียนทั้งหมดแล้ว แต่เอกสารฉบับสุดท้ายยังคงรักษาการแสดงออกว่า "ไม่เหมาะสมที่สุด" ไว้ โดยไม่ให้ข้อโต้แย้งใดๆ
ข้อกล่าวหาที่สาม: ในการเปรียบเทียบการทดลอง "มัดมือคนด้วยมือซ้าย ถือมีดด้วยมือขวา"
นี่เป็นข้อที่มีพลังทำลายล้างมากที่สุดในทั้งบทความ Jianyang Gao ชี้ให้เห็นว่า เอกสาร TurboQuant ซ้อนเงื่อนไขที่ไม่เป็น公平สองชั้นในการทดลองเปรียบเทียบความเร็ว:
ประการแรก RaBitQ จัดเตรียมโค้ด C++ ที่ได้รับการปรับ优化แล้ว (รองรับการประมวลผลแบบขนานหลายเธรดโดยค่าเริ่มต้น) แต่ทีม TurboQuant ไม่ได้ใช้ กลับใช้เวอร์ชัน Python ที่ตัวเองแปลเพื่อทดสอบ RaBitQ ประการที่สอง เมื่อทดสอบ RaBitQ ใช้ single-core CPU และปิดการทำงานหลายเธรด ในขณะที่ TurboQuant ใช้ NVIDIA A100 GPU
ผลของเงื่อนไขทั้งสองที่ซ้อนทับกันคือ: ผู้อ่านเห็นข้อสรุปว่า "RaBitQ ช้ากว่า TurboQuant หลายอันดับขนาด" แต่ไม่รู้ว่าข้อสรุปนี้มีเงื่อนไขเบื้องต้นคือทีม Google มัดมือมัดเท้าคู่แข่งก่อนแล้วค่อยแข่งวิ่ง เอกสารวิจัยไม่ได้เปิดเผยความแตกต่างของเงื่อนไขการทดลองเหล่านี้อย่างเพียงพอ
การตอบสนองของ Google: "การหมุนแบบสุ่มเป็นเทคนิคทั่วไป เป็นไปไม่ได้ที่จะอ้างอิงทุกบทความ"
ตามที่ Jianyang Gao เปิดเผย ทีม TurboQuant ในการตอบกลับทางอีเมลเดือนมีนาคม 2026 ระบุว่า: "การใช้การหมุนแบบสุ่มและการแปลง Johnson-Lindenstrauss เป็นเทคนิคมาตรฐานในสาขานี้แล้ว เราไม่สามารถอ้างอิงทุกบทความที่ใช้วิธีการเหล่านี้ได้"
ทีมของ Jianyang Gao เชื่อว่านี่เป็นการบิดเบือนประเด็น: ปัญหาไม่ใช่เรื่องว่าจะต้องอ้างอิงทุกบทความที่ใช้การหมุนแบบสุ่มหรือไม่ แต่ RaBitQ เป็นงานวิจัยแรกที่รวมวิธีการนี้กับการบีบอัดเวกเตอร์ภายใต้การตั้งค่าปัญหาที่เหมือนกันทุกประการและพิสูจน์ความเหมาะสมที่สุดของมัน เอกสาร TurboQuant ควรอธิบายความสัมพันธ์ของทั้งสองอย่างถูกต้อง
บัญชี X ทางการของ Stanford NLP Group แชร์คำชี้แจงของ Jianyang Gao ทีมของ Jianyang Gao ได้เผยแพร่ความคิดเห็นสาธารณะบนแพลตฟอร์ม ICLR OpenReview แล้ว และได้ส่งคำร้องเรียนอย่างเป็นทางการถึงประธานการประชุม ICLR และคณะกรรมการจริยธรรม ต่อไปจะเผยแพร่รายงานเทคนิคโดยละเอียดบน arXiv
Dario Salvati บล็อกเกอร์ด้านเทคนิคอิสระ ให้การประเมินที่ค่อนข้างเป็นกลางในการวิเคราะห์ของเขา: TurboQuant มีผลงานทางคณิตศาสตร์ที่แท้จริงในวิธีการทางคณิตศาสตร์ แต่มีความสัมพันธ์ที่แน่นแฟ้นกับ RaBitQ มากกว่าที่เอกสารวิจัยแสดงออก
มูลค่าตลาดระเหย 900 พันล้านดอลลาร์: ข้อพิพาทเอกสารวิจัยซ้อนทับความตื่นตระหนกของตลาด
ข้อพิพาททางวิชาการนี้เกิดขึ้นในช่วงเวลาที่ละเอียดอ่อนมาก หลังจาก Google เผยแพร่ TurboQuant ผ่านบล็อกทางการในวันที่ 24 มีนาคม กลุ่มหุ้นชิปหน่วยความจำทั่วโลกเผชิญกับการเทขายอย่างรุนแรง ตามรายงานของ CNBC และสื่อหลายแห่ง หุ้น Micron Technology ร่วงต่อเนื่องหกวันทำการ ตกสะสมกว่า 20%; SanDisk ร่วง 11% ในวันเดียว; SK Hynix ของเกาหลีใต้ร่วงประมาณ 6%, Samsung Electronics ร่วงเกือบ 5%, Kioxia ของญี่ปุ่นร่วงประมาณ 6% ตรรกะความตื่นตระหนกของตลาดเรียบง่ายและรุนแรง: การบีบอัดซอฟต์แวร์สามารถลดความต้องการหน่วยความจำสำหรับการอนุมาน AI ลง 6 เท่า แนวโน้มความต้องการชิปหน่วยความจำจะถูกปรับลดลงเชิงโครงสร้าง
Joseph Moore นักวิเคราะห์ของ Morgan Stanley โต้แย้งตรรกะนี้ในรายงานวิจัยวันที่ 26 มีนาคม ยืนยันการจัดอันดับ "เพิ่มการถือครอง" สำหรับ Micron และ SanDisk Moore ชี้ให้เห็นว่า TurboQuant บีบอัดเฉพาะ KV Cache ซึ่งเป็นแคชประเภทเฉพาะเท่านั้น ไม่ใช่ปริมาณการใช้หน่วยความจำโดยรวม และจัดประเภทมันว่าเป็น "การปรับปรุงประสิทธิภาพการผลิตตามปกติ" Andrew Rocha นักวิเคราะห์ของ Wells Fargo อ้างอิง Jevons Paradox เช่นเดียวกันว่า การเพิ่มประสิทธิภาพลดต้นทุนอาจกระตุ้นการปรับใช้ AI ในขนาดที่ใหญ่ขึ้น สุดท้ายแล้วดึงความต้องการหน่วยความจำขึ้น
เอกสารวิจัยเก่า การบรรจุภัณฑ์ใหม่: ความเสี่ยงของห่วงโซ่การส่งผ่านจากการวิจัย AI ไปสู่เรื่องเล่าตลาด
ตามการวิเคราะห์ของ Ben Pouladian บล็อกเกอร์ด้านเทคนิค เอกสารวิจัย TurboQuant เผยแพร่สู่สาธารณะแล้วในเดือนเมษายน 2025 ไม่ใช่การวิจัยใหม่ วันที่ 24 มีนาคม Google นำมาโปรโมตใหม่ผ่านบล็อกทางการ แต่ตลาดกลับกำหนดราคามันเป็นความก้าวหน้าใหม่ กลยุทธ์การโปรโมตแบบ "เอกสารวิจัยเก่า การเผยแพร่ใหม่" นี้ ซ้อนทับกับความเอนเอียงในการทดลองที่อาจมีอยู่ในเอกสารวิจัย สะท้อนให้เห็นถึงความเสี่ยงเชิงระบบในห่วงโซ่การส่งผ่านจากการวิจัย AI จากเอกสารวิชาการไปสู่เรื่องเล่าตลาด
สำหรับนักลงทุนในโครงสร้างพื้นฐาน AI เมื่อเอกสารวิจัยอ้างว่าบรรลุการเพิ่มประสิทธิภาพ "หลายอันดับขนาด" สิ่งแรกที่ต้องถามคือเงื่อนไขการเปรียบเทียบมาตรฐานเป็นธรรมหรือไม่
ทีมของ Jianyang Gao ได้แจ้งชัดเจนว่าจะผลักดันให้ปัญหาได้รับการแก้ไขอย่างเป็นทางการต่อไป ฝ่าย Google ยังไม่ได้ตอบสนองอย่างเป็นทางการต่อข้อกล่าวหาเฉพาะในจดหมายเปิดผนึก


