
万字深研:AI x Crypto入门指南(下)
ผู้เขียนต้นฉบับ: Mohamed Baioumy และ Alex Cheema
การรวบรวมต้นฉบับ: BeWater

เนื่องจากรายงานฉบับเต็มมีความยาว เราจึงได้แบ่งออกเป็นสองส่วนเพื่อเผยแพร่ ในบทความก่อนหน้านี้ ผู้เขียนได้แนะนำเฟรมเวิร์กหลักของ AI x Crypto ตัวอย่างเฉพาะ โอกาสสำหรับผู้สร้าง ฯลฯ บทความถัดไปนี้จะอธิบายโหมดการทำงานและความท้าทายของการเรียนรู้ของเครื่องเป็นหลัก หากต้องการดูฉบับแปลฉบับเต็ม โปรดคลิกที่นี่ลิงค์。
ก. แมชชีนเลิร์นนิงทำงานอย่างไร
ก่อนที่เราจะเจาะลึกถึงจุดบรรจบกันของปัญญาประดิษฐ์ (AI) และสกุลเงินดิจิตอล สิ่งสำคัญอันดับแรกคือต้องแนะนำแนวคิดบางอย่างในสาขาปัญญาประดิษฐ์เพียงอย่างเดียว เนื่องจากรายงานนี้เขียนขึ้นสำหรับผู้ชมในพื้นที่สกุลเงินดิจิทัล ผู้อ่านบางคนอาจมีความเข้าใจอย่างลึกซึ้งเกี่ยวกับแนวคิดปัญญาประดิษฐ์และการเรียนรู้ของเครื่อง การทำความเข้าใจแนวคิดเป็นสิ่งสำคัญเพื่อให้ผู้อ่านสามารถประเมินได้ว่าแนวคิดใดที่จุดตัดระหว่างปัญญาประดิษฐ์และสกุลเงินดิจิทัลเป็นที่สนใจอย่างแท้จริง และประเมินความเสี่ยงทางเทคนิคของโครงการได้อย่างแม่นยำ ในส่วนนี้มุ่งเน้นไปที่แนวคิดของปัญญาประดิษฐ์ นอกจากนี้ ในส่วนนี้ยังมุ่งเน้นไปที่ความสัมพันธ์ระหว่างปัญญาประดิษฐ์และสกุลเงินดิจิทัลอีกด้วย

ภาพรวมของหัวข้อที่กล่าวถึงในส่วนนี้:
การเรียนรู้ของเครื่อง (ML) เป็นสาขาหนึ่งของปัญญาประดิษฐ์ที่เครื่องจักรสามารถตัดสินใจโดยอาศัยข้อมูลโดยไม่ต้องตั้งโปรแกรมไว้อย่างชัดเจน
กระบวนการ ML แบ่งออกเป็นสามขั้นตอน: ข้อมูล การฝึกอบรม และการอนุมาน
โมเดลการฝึกอบรมมีราคาแพงมากในการคำนวณ ในขณะที่การอนุมานมีราคาค่อนข้างถูก
การเรียนรู้มีสามประเภทหลัก: การเรียนรู้แบบมีผู้สอน, การเรียนรู้แบบไม่มีผู้ดูแล และการเรียนรู้แบบเสริมกำลัง
การเรียนรู้แบบมีผู้สอนหมายถึงการเรียนรู้จากตัวอย่าง (จัดทำโดยครู) ครูสามารถแสดงภาพสุนัขให้โมเดลดูและบอกว่านี่คือสุนัข จากนั้นโมเดลจะสามารถเรียนรู้ที่จะแยกแยะสุนัขจากสัตว์อื่นๆ ได้
อย่างไรก็ตาม โมเดลยอดนิยมจำนวนมาก เช่น LLM (เช่น GPT-4 และ LLaMa) ได้รับการฝึกอบรมผ่านการเรียนรู้แบบไม่มีผู้ดูแล ในโหมดการเรียนรู้นี้ ผู้สอนไม่ได้ให้คำแนะนำหรือยกตัวอย่างใดๆ แบบจำลองเรียนรู้ที่จะค้นพบรูปแบบในข้อมูลแทน
การเรียนรู้แบบเสริมกำลัง (การเรียนรู้แบบลองผิดลองถูก) ส่วนใหญ่จะใช้ในงานการตัดสินใจอย่างต่อเนื่อง เช่น การควบคุมหุ่นยนต์และเกม (เช่น หมากรุกหรือหมาก)
ปัญญาประดิษฐ์และการเรียนรู้ของเครื่อง
ในปี 1956 ผู้มีความคิดที่เฉียบแหลมที่สุดในยุคนั้นมารวมตัวกันเพื่อสัมมนา เป้าหมายของพวกเขาคือเสนอหลักการทั่วไปของสติปัญญา พวกเขาชี้ให้เห็นว่า:
"ทุกแง่มุมของการเรียนรู้หรือคุณลักษณะอื่นๆ ของสติปัญญาสามารถอธิบายได้อย่างแม่นยำจนสามารถสร้างเครื่องจักรเพื่อจำลองมันได้"
ในช่วงแรกของการพัฒนาปัญญาประดิษฐ์ นักวิจัยเต็มไปด้วยการมองโลกในแง่ดี ในแง่หนึ่ง เป้าหมายของพวกเขาคือปัญญาประดิษฐ์ทั่วไป (AGI) ซึ่งมีความทะเยอทะยาน ตอนนี้เรารู้แล้วว่านักวิจัยเหล่านี้ไม่สามารถสร้างตัวแทน AI ที่มีความฉลาดทั่วไปได้ เช่นเดียวกับนักวิจัยด้านปัญญาประดิษฐ์ในช่วงทศวรรษ 1970 และ 1980 ในช่วงเวลานั้นนักวิจัยด้านปัญญาประดิษฐ์ได้พยายามพัฒนา"ระบบฐานความรู้"。
แนวคิดหลักของระบบฐานความรู้คือเราสามารถเขียนกฎที่แม่นยำมากสำหรับเครื่องจักรได้ โดยพื้นฐานแล้ว เราจะดึงความรู้เฉพาะด้านและแม่นยำจากผู้เชี่ยวชาญ และจดบันทึกไว้ในรูปแบบของกฎเกณฑ์สำหรับเครื่องจักรที่จะใช้ เครื่องจักรสามารถใช้กฎเหล่านี้เพื่อให้เหตุผลและตัดสินใจได้อย่างถูกต้อง ตัวอย่างเช่น เราอาจพยายามดึงหลักการการเล่นหมากรุกทั้งหมดออกจากแม็กนัส คาร์ลสัน แล้วสร้างปัญญาประดิษฐ์เพื่อเล่นหมากรุก
อย่างไรก็ตาม การทำเช่นนี้เป็นเรื่องยากมาก และแม้ว่าจะเป็นไปได้ แต่ก็ต้องใช้แรงงานคนจำนวนมากในการสร้างกฎเหล่านี้ ลองนึกดูว่าจะเขียนกฎในการระบุสุนัขเข้าไปในเครื่องได้อย่างไร? เครื่องจักรเปลี่ยนจากการมีพิกเซลมาเป็นการรู้ว่าสุนัขคืออะไร
ความก้าวหน้าล่าสุดในด้านปัญญาประดิษฐ์มาจากกลุ่มที่เรียกว่า"การเรียนรู้ของเครื่อง"สาขา. ในโมเดลนี้ แทนที่จะเขียนกฎที่แม่นยำสำหรับเครื่องจักร เราจะใช้ข้อมูลและปล่อยให้เครื่องจักรเรียนรู้จากมัน เครื่องมือ AI สมัยใหม่ที่ใช้การเรียนรู้ของเครื่องมีอยู่ทุกที่ เช่น GPT-4, FaceID บน iPhone, บอทเกม, ตัวกรองสแปม Gmail, โมเดลการวินิจฉัยทางการแพทย์, รถยนต์ไร้คนขับ... และอื่นๆ อีกมากมาย
ไปป์ไลน์การเรียนรู้ของเครื่อง
ไปป์ไลน์การเรียนรู้ของเครื่องสามารถแบ่งออกเป็นสามขั้นตอนหลัก ด้วยข้อมูล เราจำเป็นต้องฝึกโมเดล จากนั้นเราก็สามารถใช้โมเดลกับโมเดลได้ การใช้แบบจำลองเรียกว่าการอนุมาน ดังนั้นสามขั้นตอนคือข้อมูล การฝึกอบรม และการอนุมาน
ในระดับสูง ขั้นตอนข้อมูลเกี่ยวข้องกับการค้นหาข้อมูลที่เกี่ยวข้องและประมวลผลล่วงหน้า เช่น ถ้าเราต้องการสร้างโมเดลเพื่อแยกประเภทสุนัข เราจำเป็นต้องค้นหารูปภาพของสุนัขและสัตว์อื่นๆ เพื่อให้โมเดลสามารถรู้ว่าอะไรคือสุนัข และอะไรไม่ใช่สุนัข จากนั้นเราจำเป็นต้องประมวลผลข้อมูลและตรวจสอบให้แน่ใจว่าอยู่ในรูปแบบที่ถูกต้องเพื่อให้โมเดลสามารถเรียนรู้ได้อย่างถูกต้อง ตัวอย่างเช่น เราอาจกำหนดให้รูปภาพมีขนาดสม่ำเสมอ
ขั้นตอนที่สองคือการฝึกอบรม โดยเราใช้ข้อมูลเพื่อเรียนรู้ว่าโมเดลควรมีลักษณะอย่างไร สมการภายในแบบจำลองคืออะไร? โครงข่ายประสาทเทียมมีน้ำหนักเท่าใด? พารามิเตอร์คืออะไร? การคำนวณเกิดขึ้นอย่างไร? หากโมเดลนั้นดีเราก็สามารถทดสอบประสิทธิภาพแล้วใช้งานได้ นี่นำเราไปสู่ขั้นตอนที่สาม
ขั้นตอนที่สามเรียกว่าการอนุมาน ซึ่งเราใช้เพียงโครงข่ายประสาทเทียม ตัวอย่างเช่น ให้อินพุตแก่โครงข่ายประสาทเทียมและถามคำถาม: สามารถสร้างเอาต์พุตผ่านการอนุมานได้หรือไม่
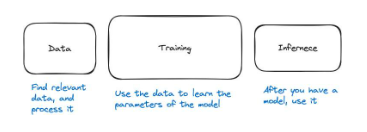
รูปที่ 28: ขั้นตอนหลักสามขั้นตอนของไปป์ไลน์การเรียนรู้ของเครื่องคือข้อมูล การฝึกอบรม และการอนุมาน
ข้อมูล
ตอนนี้เรามาดูแต่ละขั้นตอนให้ละเอียดยิ่งขึ้น ครั้งแรก: ข้อมูล พูดกว้างๆ หมายความว่าเราต้องรวบรวมข้อมูลและประมวลผลล่วงหน้า
ลองดูตัวอย่าง หากเราต้องการสร้างแบบจำลองที่แพทย์ผิวหนัง (แพทย์ที่เชี่ยวชาญด้านการรักษาโรคผิวหนัง) สามารถนำมาใช้ได้ ก่อนอื่นเราจำเป็นต้องรวบรวมข้อมูลจากหลาย ๆ ใบหน้า จากนั้นเราจะขอให้แพทย์ผิวหนังมืออาชีพประเมินว่ามีสภาพผิวหรือไม่ ความท้าทายมากมายอาจเกิดขึ้นในขณะนี้ ประการแรก หากข้อมูลทั้งหมดที่เรามีรวมใบหน้า โมเดลจะระบุสภาพผิวในส่วนอื่นของร่างกายได้ยาก ประการที่สอง ข้อมูลอาจมีอคติ ตัวอย่างเช่น ข้อมูลส่วนใหญ่อาจเป็นรูปภาพที่มีสีผิวหรือโทนสีเดียว ประการที่สาม แพทย์ผิวหนังสามารถทำผิดพลาดได้ ซึ่งหมายความว่าเราได้รับข้อมูลที่ไม่ถูกต้อง ประการที่สี่ ข้อมูลที่เราได้รับอาจละเมิดความเป็นส่วนตัว

เราจะกล่าวถึงความท้าทายด้านข้อมูลที่ลึกซึ้งยิ่งขึ้นในบทที่ 2 อย่างไรก็ตาม สิ่งนี้จะทำให้คุณมีแนวคิดว่าการรวบรวมข้อมูลที่ดีและการประมวลผลล่วงหน้าอาจเป็นเรื่องท้าทาย

รูปที่ 29: การแสดงแผนผังของชุดข้อมูลยอดนิยมสองชุด MNIST มีตัวเลขที่เขียนด้วยลายมือ ในขณะที่ ImageNet มีรูปภาพที่มีคำอธิบายประกอบหลายล้านภาพในหมวดหมู่ต่างๆ
ในการวิจัย Machine Learning มีชุดข้อมูลที่มีชื่อเสียงมากมาย ที่ใช้กันทั่วไปได้แก่;
ชุดข้อมูล MNIST
คำอธิบาย: ประกอบด้วยตัวเลขที่เขียนด้วยลายมือ 70,000 หลัก (0-9) ในรูปแบบภาพระดับสีเทา
กรณีการใช้งาน: ส่วนใหญ่ใช้สำหรับเทคโนโลยีการรู้จำตัวเลขที่เขียนด้วยลายมือในคอมพิวเตอร์วิทัศน์ เป็นชุดข้อมูลที่เหมาะสำหรับผู้เริ่มต้นซึ่งมักใช้ในด้านการศึกษา
ImageNet
คำอธิบาย: ฐานข้อมูลขนาดใหญ่ที่มีรูปภาพมากกว่า 14 ล้านภาพ มีป้ายกำกับมากกว่า 20,000 หมวดหมู่
กรณีการใช้งาน: การฝึกอบรมและการเปรียบเทียบอัลกอริธึมการตรวจจับวัตถุและการจัดหมวดหมู่รูปภาพ ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) ประจำปีเป็นงานสำคัญที่ส่งเสริมการพัฒนาคอมพิวเตอร์วิทัศน์และเทคโนโลยีการเรียนรู้เชิงลึกมาโดยตลอด
ความคิดเห็นของ IMDb:
คำอธิบาย: ประกอบด้วยบทวิจารณ์ภาพยนตร์ 50,000 เรื่องจาก IMDb แบ่งออกเป็นสองกลุ่ม: การฝึกอบรมและการทดสอบ แต่ละกลุ่มมีจำนวนความคิดเห็นเชิงบวกและเชิงลบเท่ากัน
กรณีการใช้งาน: ใช้กันอย่างแพร่หลายในงานวิเคราะห์ความรู้สึกในการประมวลผลภาษาธรรมชาติ (NLP) ช่วยในการพัฒนาแบบจำลองที่สามารถเข้าใจและจำแนกความรู้สึก (เชิงบวก/เชิงลบ) ที่แสดงออกมาเป็นข้อความ
การเข้าถึงชุดข้อมูลขนาดใหญ่และมีคุณภาพสูงเป็นสิ่งสำคัญอย่างยิ่งสำหรับการฝึกฝนโมเดลที่ดี อย่างไรก็ตาม สิ่งนี้อาจเป็นเรื่องที่ท้าทาย โดยเฉพาะสำหรับองค์กรขนาดเล็กหรือผู้ค้นหารายบุคคล เนื่องจากข้อมูลมีคุณค่ามาก องค์กรขนาดใหญ่จึงมักไม่เปิดเผยข้อมูลดังกล่าวเนื่องจากจะสร้างความได้เปรียบทางการแข่งขัน

รถไฟ
ขั้นตอนที่สองของไปป์ไลน์คือการฝึกโมเดล แล้วการฝึกโมเดลหมายความว่าอย่างไรกันแน่? ก่อนอื่นเรามาดูตัวอย่างกันก่อน โมเดลแมชชีนเลิร์นนิง (หลังการฝึกเสร็จสิ้น) มักจะมีเพียง 2 ไฟล์เท่านั้น ตัวอย่างเช่น LLaMa 2 (โมเดลภาษาขนาดใหญ่ คล้ายกับ GPT-4) มี 2 ไฟล์:
พารามิเตอร์ ไฟล์ขนาด 140 GB รวมตัวเลข
run.c และไฟล์ธรรมดา (โค้ดประมาณ 500 บรรทัด)
ไฟล์แรกประกอบด้วยพารามิเตอร์ทั้งหมดของโมเดล LLaMa 2 ส่วน run.c มีคำแนะนำเกี่ยวกับวิธีการอนุมาน (โดยใช้โมเดล) โมเดลเหล่านี้เป็นโครงข่ายประสาทเทียม
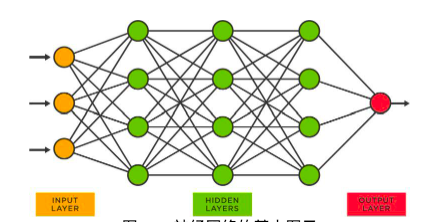
รูปที่ 30: แผนภาพพื้นฐานของโครงข่ายประสาทเทียม
ในโครงข่ายประสาทเทียมแบบข้างต้น แต่ละโหนดจะมีตัวเลขจำนวนมาก ตัวเลขเหล่านี้เรียกว่าพารามิเตอร์และจัดเก็บไว้ในพารามิเตอร์ไฟล์ (เซอร์ไพรส์!) กระบวนการรับพารามิเตอร์เหล่านี้เรียกว่าการฝึกอบรม สิ่งต่อไปนี้เป็นบทสรุประดับสูงของกระบวนการ
ลองนึกภาพการฝึกแบบจำลองให้จดจำตัวเลข (ตั้งแต่ 0 ถึง 9) ก่อนอื่นเรารวบรวมข้อมูล (ในกรณีนี้เราสามารถใช้ชุดข้อมูล MNIST ได้) จากนั้นจึงเริ่มฝึกโมเดล
เราใช้จุดข้อมูลแรกซึ่งก็คือ"5"。
จากนั้นเราจะแปลงรูปภาพ ("5") ถูกส่งผ่านไปยังเครือข่าย เครือข่ายดำเนินการทางคณิตศาสตร์กับอิมเมจอินพุต
เครือข่ายจะส่งออกตัวเลขระหว่าง 0 ถึง 9 ผลลัพธ์นี้เป็นการคาดการณ์ของเครือข่ายปัจจุบันสำหรับรูปภาพนั้น
ตอนนี้มีสองสถานการณ์ เครือข่ายนั้นถูกต้อง (คาดการณ์ไว้"5") หรือผิด (ตัวเลขอื่นใด)
หากตัวเลขที่ทำนายถูกเราก็ไม่ต้องทำอะไร
หากตัวเลขที่ทำนายไว้ไม่ถูกต้อง เราจะกลับไปที่เครือข่ายพร้อมกับแก้ไขพารามิเตอร์ทั้งหมดเล็กน้อย
หลังจากทำการเปลี่ยนแปลงเล็กๆ น้อยๆ เหล่านี้แล้ว ให้ลองอีกครั้ง ในทางเทคนิคแล้ว ขณะนี้เครือข่ายมีพารามิเตอร์ใหม่ ดังนั้นการคาดการณ์จะแตกต่างออกไป
เราทำเช่นนี้กับจุดข้อมูลทั้งหมดจนกว่าเครือข่ายจะถูกต้องเป็นส่วนใหญ่
กระบวนการนี้เป็นไปตามลำดับโดยธรรมชาติ ขั้นแรกเราจะส่งจุดข้อมูลผ่านเครือข่ายทั้งหมด ดูว่าการคาดการณ์เป็นอย่างไร จากนั้นจึงอัปเดตน้ำหนักของแบบจำลอง
กระบวนการฝึกอบรมสามารถครอบคลุมมากขึ้น ขั้นแรกเราต้องเลือกสถาปัตยกรรมแบบจำลอง เราควรเลือกโครงข่ายประสาทเทียมชนิดใด โมเดลการเรียนรู้ของเครื่องไม่ใช่ทุกโมเดลที่เป็นโครงข่ายประสาทเทียม ประการที่สอง หลังจากพิจารณาว่าสถาปัตยกรรมใดดีที่สุดสำหรับเรา หรืออย่างน้อยสถาปัตยกรรมที่เราคิดว่าเหมาะสมที่สุดแล้ว เราจำเป็นต้องกำหนดกระบวนการฝึกอบรม เช่น เราจะส่งข้อมูลไปยังเครือข่ายตามลำดับใด
ประการที่สาม เราต้องการการตั้งค่าฮาร์ดแวร์ ควรใช้ฮาร์ดแวร์ประเภทใด (CPU, GPU, TPU) จะฝึกมันได้อย่างไร?
สุดท้ายนี้ ในขณะที่ฝึกโมเดล เราต้องการตรวจสอบว่าโมเดลนั้นดีจริงหรือไม่ เราต้องการทดสอบเมื่อสิ้นสุดการฝึกอบรมว่าโมเดลนี้ให้ผลลัพธ์ที่เราต้องการหรือไม่ สปอยเลอร์ (ไม่ใช่สปอยเลอร์) การฝึกโมเดลมีราคาแพงมากในการคำนวณ ความไร้ประสิทธิภาพเล็กๆ น้อยๆ ย่อมมาพร้อมกับต้นทุนมหาศาล ดังที่เราจะได้เห็นในภายหลัง โดยเฉพาะอย่างยิ่งสำหรับโมเดลขนาดใหญ่ เช่น LLM การฝึกอบรมที่ไม่มีประสิทธิภาพอาจทำให้คุณเสียเงินหลายล้านดอลลาร์
ในบทที่ 2 เราจะพูดถึงความท้าทายของโมเดลการฝึกอบรมอีกครั้งโดยละเอียด
การใช้เหตุผล
ขั้นตอนที่สามในไปป์ไลน์การเรียนรู้ของเครื่องคือการอนุมาน ซึ่งกำลังใช้โมเดล เมื่อฉันใช้ ChatGPT และได้รับการตอบสนอง โมเดลกำลังทำการอนุมาน หากฉันปลดล็อค iPhone ด้วยใบหน้า รุ่น Face ID จะจดจำใบหน้าของฉันและเปิดโทรศัพท์ขึ้นมา แบบจำลองทำการอนุมาน ข้อมูลมีอยู่แล้ว และ Model ได้รับ Train แล้ว เมื่อ Model ได้รับ Train แล้ว เราก็สามารถใช้งานได้ การใช้มันเป็นการอนุมาน
พูดอย่างเคร่งครัด การอนุมานเป็นสิ่งเดียวกับการคาดการณ์ที่ทำโดยเครือข่ายในระหว่างขั้นตอนการฝึกอบรม โปรดจำไว้ว่าจุดข้อมูลผ่านเครือข่ายและทำการคาดการณ์ จากนั้นพารามิเตอร์โมเดลจะได้รับการอัปเดตตามคุณภาพของการคาดการณ์ การใช้เหตุผลก็ทำงานในลักษณะเดียวกัน ดังนั้นการอนุมานจึงมีราคาแพงมากในการคำนวณเมื่อเทียบกับการฝึกอบรม การฝึกอบรม LLaMa อาจมีค่าใช้จ่ายหลายสิบล้านดอลลาร์ แต่การอนุมานในแต่ละครั้งมีค่าใช้จ่ายเพียงเล็กน้อยเท่านั้น
ต้นทุนการคำนวณต่ำกว่าเมื่อเทียบกับการฝึกอบรม การฝึกอบรม LLaMa อาจมีค่าใช้จ่ายหลายสิบล้านดอลลาร์ แต่การอนุมานมีค่าใช้จ่ายเพียงเล็กน้อยเท่านั้น

กระบวนการให้เหตุผลมีหลายขั้นตอน ก่อนอื่นเราต้องทดสอบก่อนนำไปใช้จริง เราดำเนินการอนุมานข้อมูลที่มองไม่เห็นในระหว่างขั้นตอนการฝึกอบรมเพื่อตรวจสอบคุณภาพของแบบจำลอง ประการที่สอง เมื่อเราปรับใช้โมเดล มีข้อกำหนดด้านฮาร์ดแวร์และซอฟต์แวร์บางประการ ตัวอย่างเช่น หากฉันมีโมเดลการจดจำใบหน้าบน iPhone รุ่นนั้นก็สามารถอยู่บนเซิร์ฟเวอร์ของ Apple ได้ อย่างไรก็ตาม สิ่งนี้ไม่สะดวกนัก เพราะตอนนี้ทุกครั้งที่ต้องการปลดล็อคโทรศัพท์ จะต้องเชื่อมต่ออินเทอร์เน็ตและส่งคำขอไปยังเซิร์ฟเวอร์ของ Apple แล้วทำการอนุมานกับรุ่นนั้น อย่างไรก็ตาม หากคุณต้องการใช้เทคโนโลยีนี้ตลอดเวลา ต้องมีรุ่นที่มีการจดจำใบหน้าอยู่ในโทรศัพท์ของคุณ ซึ่งหมายความว่ารุ่นนั้นจะต้องเข้ากันได้กับประเภทของฮาร์ดแวร์บน iPhone ของคุณ
สุดท้ายนี้ ในทางปฏิบัติ เราต้องรักษาโมเดลนี้ไว้ด้วย เราต้องปรับตัวอยู่ตลอดเวลา โมเดลที่เราฝึกและใช้งานไม่ได้สมบูรณ์แบบเสมอไป ข้อกำหนดด้านฮาร์ดแวร์และข้อกำหนดซอฟต์แวร์มีการเปลี่ยนแปลงอยู่ตลอดเวลา
ไปป์ไลน์การเรียนรู้ของเครื่องเป็นแบบวนซ้ำ
จนถึงตอนนี้ ฉันได้ออกแบบไปป์ไลน์นี้เป็นสามขั้นตอนที่เกิดขึ้นตามลำดับ คุณได้รับข้อมูล คุณประมวลผลข้อมูล คุณล้างข้อมูล ทุกอย่างดำเนินไปอย่างราบรื่น จากนั้นคุณฝึกฝนโมเดล และเมื่อโมเดลได้รับการฝึกฝนแล้ว คุณจะอนุมานได้ นี่เป็นภาพที่สวยงามของการเรียนรู้ของเครื่องในทางปฏิบัติ ในความเป็นจริงแล้ว แมชชีนเลิร์นนิงจำเป็นต้องมีการทำซ้ำหลายครั้ง ดังนั้นจึงไม่ใช่โซ่แต่มีหลายห่วงดังภาพด้านล่าง
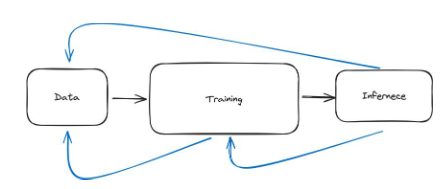
รูปที่ 31: ไปป์ไลน์การเรียนรู้ของเครื่องสามารถเข้าใจได้เป็นลูกโซ่ซึ่งประกอบด้วยสามขั้นตอน: ข้อมูล การฝึกอบรม และการอนุมาน อย่างไรก็ตาม ในทางปฏิบัติ กระบวนการนี้ต้องใช้การทำซ้ำมากกว่า ดังที่แสดงโดยลูกศรสีน้ำเงิน
เพื่อทำความเข้าใจเรื่องนี้ เราสามารถยกตัวอย่างบางส่วนได้ ตัวอย่างเช่น เราอาจรวบรวมข้อมูลสำหรับแบบจำลองแล้วลองฝึกแบบจำลองนั้น ในระหว่างกระบวนการฝึกอบรมเราจะพบว่าปริมาณข้อมูลที่เราต้องการควรจะมากกว่านี้ ซึ่งหมายความว่าเราต้องหยุดการฝึกอบรมชั่วคราว กลับไปที่ขั้นตอนข้อมูล และรับข้อมูลเพิ่มเติม เราอาจจำเป็นต้องประมวลผลข้อมูลใหม่ หรือดำเนินการเพิ่มข้อมูลบางรูปแบบ การเพิ่มข้อมูลเปรียบเสมือนการเปลี่ยนโฉมข้อมูล สร้างสิ่งใหม่จากสิ่งเก่า ลองนึกภาพคุณมีอัลบั้มรูปและต้องการทำให้มันน่าสนใจยิ่งขึ้น คุณทำสำเนาภาพถ่ายแต่ละภาพหลายชุด แต่ในแต่ละสำเนาคุณได้ทำการเปลี่ยนแปลงเล็กๆ น้อยๆ คุณอาจหมุนภาพหนึ่ง ขยายอีกภาพหนึ่ง หรือเปลี่ยนขนาดของแสงอื่น ตอนนี้ อัลบั้มรูปของคุณมีการเปลี่ยนแปลงมากขึ้น แต่คุณไม่ได้ถ่ายรูปใหม่เลย ตัวอย่างเช่น หากคุณกำลังฝึกโมเดลให้จดจำสุนัข คุณอาจพลิกภาพแต่ละภาพในแนวนอนและป้อนภาพนั้นให้กับโมเดลด้วยเช่นกัน หรือเปลี่ยนท่าทางของสุนัขในรูปภาพดังที่แสดงด้านล่าง เท่าที่เกี่ยวข้องกับโมเดล สิ่งนี้จะเพิ่มชุดข้อมูล แต่เราจะไม่ออกไปสู่โลกแห่งความเป็นจริงเพื่อรวบรวมข้อมูลเพิ่มเติม


รูปที่ 32: ตัวอย่างการเพิ่มข้อมูล การขยายจุดข้อมูลดั้งเดิมแบบหลายจุดช่วยลดความจำเป็นในการเดินทางรอบโลกเพื่อรวบรวมจุดข้อมูลที่ไม่ซ้ำกันมากขึ้น
ตัวอย่างที่สองที่ชัดเจนกว่าของการวนซ้ำคือ เมื่อเราฝึกโมเดลจริงแล้วนำไปใช้ในทางปฏิบัติ เช่น สำหรับการอนุมาน เราอาจพบว่าโมเดลนั้นทำงานได้ไม่ดีในทางปฏิบัติหรือมีอคติ ซึ่งหมายความว่าเราต้องหยุดกระบวนการอนุมาน ย้อนกลับและฝึกโมเดลใหม่เพื่ออธิบายปัญหาเหล่านี้ เช่น อคติและเหตุผล
ขั้นตอนที่สามที่พบบ่อยมากคือ เมื่อเราใช้แบบจำลองในทางปฏิบัติ (ทำการอนุมาน) เราจะทำการแก้ไขขั้นตอนข้อมูลเนื่องจากการอนุมานจะสร้างข้อมูลใหม่ขึ้นมา ตัวอย่างเช่น ลองจินตนาการถึงการสร้างตัวกรองสแปม ก่อนอื่นเราต้องรวบรวมข้อมูล ข้อมูลในตัวอย่างนี้คือชุดอีเมลขยะและไม่ใช่สแปม เมื่อโมเดลได้รับการฝึกอบรมและใช้งานจริง ฉันอาจได้รับอีเมลสแปมในกล่องจดหมาย ซึ่งหมายความว่าโมเดลนั้นทำผิดพลาด มันไม่ได้จัดว่าเป็นสแปม แต่เป็นสแปม ดังนั้นเมื่อผู้ใช้ Gmail เลือก"อีเมลนี้เป็นสแปม"จุดข้อมูลใหม่จะถูกสร้างขึ้น หลังจากนั้น จุดข้อมูลใหม่เหล่านี้จะเข้าสู่ขั้นตอนข้อมูล และเราสามารถปรับปรุงประสิทธิภาพของแบบจำลองได้โดยการฝึกอบรมเพิ่มเติมอีกเล็กน้อย
อีกตัวอย่างหนึ่ง ลองจินตนาการว่า AI กำลังเล่นหมากรุก ข้อมูลที่เราต้องฝึกปัญญาประดิษฐ์เพื่อเล่นหมากรุกคือเกมหมากรุกจำนวนมากและผลลัพธ์ว่าใครจะชนะหรือแพ้ แต่เมื่อมีการใช้โมเดลนี้ในการเล่นหมากรุกจริงๆ ก็จะสร้างข้อมูลสำหรับปัญญาประดิษฐ์มากขึ้น ซึ่งหมายความว่าเราสามารถย้อนกลับไปยังข้อมูลจากขั้นตอนการอนุมานและปรับปรุงแบบจำลองของฉันได้อีกครั้งโดยใช้จุดข้อมูลใหม่เหล่านี้ แนวคิดในการเชื่อมโยงการใช้เหตุผลและข้อมูลนี้ใช้ได้กับหลายสถานการณ์
ส่วนนี้มีจุดมุ่งหมายเพื่อให้คุณมีความเข้าใจในระดับสูงเกี่ยวกับกระบวนการสร้างโมเดลการเรียนรู้ของเครื่องซึ่งมีการทำซ้ำมาก มันไม่เหมือน"โอ้ เราเพิ่งได้รับข้อมูล ฝึกแบบจำลองในการลองครั้งเดียว และนำไปใช้จริง"。

ประเภทของการเรียนรู้ของเครื่อง
เราจะแนะนำโมเดลการเรียนรู้ของเครื่องหลักสามโมเดล
การเรียนรู้แบบมีผู้สอน:"อาจารย์ครับ สอนผมหน่อยว่าต้องทำอย่างไร"
การเรียนรู้แบบไม่มีผู้ดูแล:"แค่หารูปแบบที่ซ่อนอยู่
การเรียนรู้แบบเสริมกำลัง:"ให้มันลองดูและดูว่าอะไรทำงาน"
การเรียนรู้ภายใต้การดูแล
"อาจารย์ครับ สอนผมหน่อยว่าต้องทำอย่างไร"
ลองจินตนาการว่าคุณกำลังสอนลูกให้แยกแยะระหว่างแมวกับสุนัข คุณ (ครูที่รู้ทุกอย่าง) โชว์รูปแมวและสุนัขให้พวกเขาดูมากมาย บอกว่ารูปไหนเป็นรูปไหนในแต่ละครั้ง ในที่สุดเด็กๆ ก็เรียนรู้ที่จะแยกแยะได้ด้วยตัวเอง นี่เป็นวิธีการทำงานของการเรียนรู้แบบมีผู้สอนในการเรียนรู้ของเครื่อง
ในการเรียนรู้แบบมีผู้สอน เรามีข้อมูลมากมาย (เช่น รูปภาพแมวและสุนัข) และเรารู้คำตอบอยู่แล้ว (ครูบอกว่าอันไหนคือสุนัขและอันไหนคือแมว) เราใช้ข้อมูลนี้เพื่อฝึกโมเดล แบบจำลองดูตัวอย่างมากมายและเรียนรู้ที่จะเลียนแบบครูอย่างมีประสิทธิภาพ
ในตัวอย่างนี้ แต่ละภาพเป็นจุดข้อมูลดิบ เรียกว่าคำตอบ (หมาหรือแมว)"ฉลาก". ดังนั้น นี่คือชุดข้อมูลที่มีป้ายกำกับ จุดข้อมูลแต่ละจุดประกอบด้วยรูปภาพดิบและป้ายกำกับ
วิธีการนี้เป็นแนวคิดที่เรียบง่ายแต่มีประสิทธิภาพในการใช้งาน มีแอปพลิเคชันมากมายที่ใช้โมเดลการเรียนรู้ภายใต้การดูแลในการวินิจฉัยทางการแพทย์ รถยนต์ไร้คนขับ และการคาดการณ์ราคาหุ้น
อย่างไรก็ตาม ดังที่คุณสามารถจินตนาการได้ แนวทางนี้เผชิญกับความท้าทายมากมาย ตัวอย่างเช่น ไม่เพียงแต่เราจำเป็นต้องได้รับข้อมูลจำนวนมากเท่านั้น เรายังต้องมีป้ายกำกับอีกด้วย อาจมีราคาแพงมากScale.aiบริษัทเช่นนี้ให้บริการที่มีคุณค่าในเรื่องนี้ คำอธิบายประกอบข้อมูลก่อให้เกิดความท้าทายมากมายต่อความมีเสถียรภาพ บุคคลที่ติดป้ายกำกับข้อมูลอาจผิดพลาดหรือไม่เห็นด้วยกับป้ายกำกับก็ได้ ไม่ใช่เรื่องแปลกที่ 20% ของแท็กทั้งหมดที่รวบรวมจากมนุษย์จะใช้งานไม่ได้

การเรียนรู้แบบไม่มีผู้ดูแล
"เพียงแค่ค้นหารูปแบบที่ซ่อนอยู่"
ลองจินตนาการว่าคุณมีตะกร้าใบใหญ่ที่เต็มไปด้วยผลไม้นานาชนิด แต่คุณกลับไม่คุ้นเคยกับตะกร้าทั้งหมด คุณเริ่มจัดเรียงพวกมันเป็นหมวดหมู่ตามรูปลักษณ์ ขนาด สี เนื้อสัมผัส และแม้แต่กลิ่น คุณไม่รู้ชื่อผลไม้แต่ละชนิดมากนัก แต่คุณสังเกตเห็นว่าผลไม้บางชนิดมีความคล้ายคลึงกัน นั่นคือคุณพบรูปแบบบางอย่างในข้อมูล
สถานการณ์นี้คล้ายกับการเรียนรู้แบบไม่มีผู้ดูแลในแมชชีนเลิร์นนิง ในการเรียนรู้แบบไม่มีผู้ดูแล เราจะให้ข้อมูลจำนวนมากแก่โมเดล (เช่น การรวมกันของผลไม้ต่างๆ) แต่เราไม่ได้บอกโมเดลว่าข้อมูลแต่ละอย่างคืออะไร (เราไม่ได้ติดป้ายกำกับผลไม้) จากนั้นโมเดลจะตรวจสอบข้อมูลทั้งหมดนี้และพยายามค้นหารูปแบบหรือการจัดกลุ่มด้วยตัวเอง อาจจัดกลุ่มผลไม้ตามสี รูปร่าง ขนาด หรือลักษณะอื่นใดที่เห็นว่าเกี่ยวข้อง อย่างไรก็ตาม คุณลักษณะที่โมเดลพบอาจไม่เกี่ยวข้องเสมอไป สิ่งนี้นำไปสู่ปัญหาหลายประการ ดังที่เราจะเห็นในบทที่ 2
เช่น แบบจำลองอาจลงเอยด้วยการจัดกลุ่มกล้วยและกล้ายเป็นกลุ่มเดียวเนื่องจากทั้งยาวและเป็นสีเหลือง ในขณะที่แอปเปิ้ลและมะเขือเทศอาจจัดกลุ่มเป็นอีกกลุ่มหนึ่งเนื่องจากทั้งกลมและอาจเป็นสีแดง . สิ่งสำคัญที่นี่คือแบบจำลองจะระบุการจัดกลุ่มเหล่านี้โดยไม่ต้องมีความรู้หรือป้ายกำกับใดๆ มาก่อน โดยจะเรียนรู้จากข้อมูลนั้นเอง เช่นเดียวกับที่คุณจัดกลุ่มผลไม้ที่ไม่รู้จักออกเป็นกลุ่มต่างๆ ตามลักษณะที่สังเกตได้ เช่นเดียวกับใน
การเรียนรู้แบบไม่มีผู้ดูแลเป็นหัวใจสำคัญของโมเดลการเรียนรู้ของเครื่องยอดนิยมมากมาย เช่น โมเดลภาษาขนาดใหญ่ (LLM) ChatGPT ไม่ต้องการให้มนุษย์สอนวิธีพูดแต่ละประโยคด้วยการติดป้ายกำกับ เพียงวิเคราะห์รูปแบบในข้อมูลทางภาษาและเรียนรู้ที่จะทำนายคำถัดไป
โมเดล AI เจนเนอเรชั่นที่ทรงพลังอื่นๆ อีกมากมายอาศัยการเรียนรู้แบบไม่มีผู้ดูแล ตัวอย่างเช่น สามารถใช้ GAN (Generative Adversarial Networks) เพื่อสร้างใบหน้าได้ แม้ว่าบุคคลนั้นจะไม่มีอยู่ก็ตามดู https://thispersondoesnotexist.com/

รูปที่ 33: ปัญญาประดิษฐ์สร้างภาพจากhttps://thispersondoesnotexist.com

รูปที่ 34: รูปภาพที่สองที่สร้างโดย AI มาจากhttps://thispersondoesnotexis t.com
ภาพด้านบนนี้สร้างโดยปัญญาประดิษฐ์ เราไม่ได้สอนโมเดลนี้"ใบหน้าคืออะไร". ได้รับการฝึกฝนบนใบหน้าจำนวนมาก และด้วยสถาปัตยกรรมอันชาญฉลาด เราสามารถใช้แบบจำลองนี้เพื่อสร้างใบหน้าที่ดูสมจริงได้ โปรดทราบว่าด้วยการเพิ่มขึ้นของ Generative AI และการปรับปรุงโมเดล ทำให้การตรวจสอบเนื้อหาทำได้ยากขึ้น

การเรียนรู้แบบเสริมกำลัง (RL)
"ให้มันลองดูและดูว่าอะไรทำงาน"หรือ"เรียนรู้จากการลองผิดลองถูก"
ลองจินตนาการว่าคุณกำลังสอนสุนัขให้ทำสิ่งใหม่ๆ เช่น หยิบลูกบอล เมื่อไหร่ก็ตามที่สุนัขของคุณทำอะไรบางอย่างที่ใกล้เคียงกับที่คุณต้องการ เช่น วิ่งไปหาลูกบอลหรือหยิบลูกบอล ให้ขนมแก่เขา ถ้าสุนัขทำอะไรที่ไม่เกี่ยวข้องกัน เช่น วิ่งสวนทางกัน มันจะไม่ได้รับอาหาร สุนัขจะค่อยๆ ค้นพบว่าสามารถหยิบลูกบอลขึ้นมากินอาหารอร่อยๆ ได้ จึงทำต่อไป นี่คือการเรียนรู้แบบเสริมกำลัง (RL) โดยพื้นฐานแล้วในด้านการเรียนรู้ของเครื่อง
ใน RL คุณมีโปรแกรมคอมพิวเตอร์หรือตัวแทน (เช่น สุนัข) ที่เรียนรู้ที่จะตัดสินใจโดยการลองทำสิ่งต่าง ๆ (เช่น สุนัขที่พยายามกระทำสิ่งต่าง ๆ ) หากตัวแทนประพฤติตนดี (เช่น หยิบลูกบอล) จะได้รับรางวัล (อาหาร) หากประพฤติตัวไม่ดีก็ไม่ได้รับรางวัล เมื่อเวลาผ่านไป ตัวแทนเรียนรู้ที่จะทำสิ่งดีๆ ที่ได้รับการตอบแทนมากขึ้น และทำสิ่งที่ไม่ดีที่ไม่ได้รับผลตอบแทนให้น้อยลง อย่างเป็นทางการ นี่คือฟังก์ชันการให้รางวัลสูงสุด
สิ่งที่ยอดเยี่ยมคือ: เจ้าหน้าที่จะคิดออกทั้งหมดด้วยตัวเองผ่านการลองผิดลองถูก ตอนนี้หากเราต้องการสร้าง AI เพื่อเล่นหมากรุก AI ก็สามารถลองเคลื่อนไหวแบบสุ่มได้ในตอนแรก หากจบลงด้วยการชนะเกม AI จะได้รับรางวัล จากนั้นโมเดลจะเรียนรู้ที่จะทำการเคลื่อนไหวเพื่อชัยชนะมากขึ้น
ซึ่งสามารถนำไปใช้กับปัญหาต่างๆ มากมาย โดยเฉพาะปัญหาที่ต้องตัดสินใจอย่างต่อเนื่อง ตัวอย่างเช่น วิธี RL สามารถใช้ในวิทยาการหุ่นยนต์และการควบคุม หมากรุกหรือ Go (เช่น AlphaGo) และการซื้อขายอัลกอริทึม
วิธีการ RL เผชิญกับความท้าทายมากมาย ประการแรกอาจใช้เวลานานในการเป็นตัวแทน"เรียนรู้"กลยุทธ์ที่มีความหมาย นี่เป็นที่ยอมรับสำหรับการเรียนรู้การเล่นหมากรุกของ AI แต่คุณจะลงทุนเงินส่วนตัวของคุณไปกับการซื้อขายอัลกอริทึมของ AI เมื่อ AI เริ่มดำเนินการแบบสุ่มเพื่อดูว่าอันไหนได้ผล? หรือคุณจะปล่อยให้หุ่นยนต์อาศัยอยู่ในบ้านของคุณถ้ามันเริ่มทำตัวแบบสุ่ม?

รูปที่ 35: นี่คือวิดีโอของการเรียนรู้แบบเสริมกำลังระหว่างการฝึกอบรม: ของจริงหุ่นยนต์และกหุ่นยนต์จำลอง
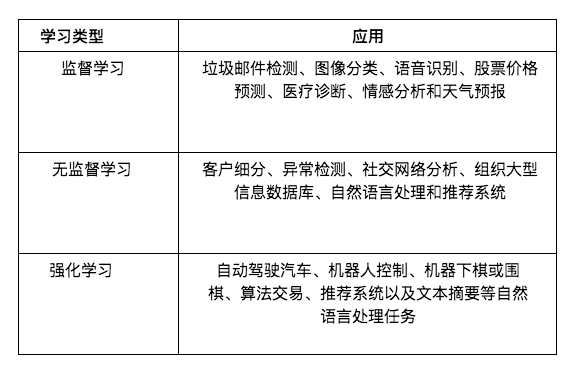
ด้านล่างนี้คือคำอธิบายโดยย่อของตัวอย่างแอปพลิเคชันสำหรับการเรียนรู้ของเครื่องแต่ละประเภท
B. ความท้าทายที่แมชชีนเลิร์นนิงต้องเผชิญ
บทนี้ให้ภาพรวมของปัญหาในด้านการเรียนรู้ของเครื่อง เราจะขยายประเด็นบางประเด็นในพื้นที่นี้โดยคัดเลือก สิ่งนี้ทำด้วยเหตุผลสองประการ: 1) เพื่อให้ภาพรวมที่กระชับและครอบคลุมของความท้าทายในสาขานี้และเพื่อคำนึงถึงความแตกต่างที่จะทำให้รายงานมีความยาวมาก 2) เมื่อพูดถึงจุดตัดกับสกุลเงินดิจิทัลเราจะมุ่งเน้นไปที่ประเด็นที่เกี่ยวข้อง . อย่างไรก็ตาม ส่วนนี้เขียนจากมุมมองของปัญญาประดิษฐ์เท่านั้น อย่างไรก็ตาม เราจะไม่พูดถึงวิธีการเข้ารหัสในส่วนนี้
ภาพรวมของหัวข้อที่กล่าวถึงในส่วนนี้:
ตั้งแต่ความลำเอียงไปจนถึงการเข้าถึง ข้อมูลต้องเผชิญกับความท้าทายครั้งใหญ่ นอกจากนี้ การโจมตีที่เป็นอันตรายในระดับข้อมูลยังสามารถนำไปสู่การตัดสินที่ผิดพลาดในโมเดลการเรียนรู้ของเครื่องอีกด้วย
โมเดลขัดข้องเกิดขึ้นเมื่อโมเดล (เช่น GPT-X) ได้รับการฝึกเกี่ยวกับข้อมูลสังเคราะห์ สิ่งนี้อาจทำให้เกิดความเสียหายอย่างถาวรได้
ข้อมูลการติดฉลากอาจมีราคาแพง ช้า และไม่น่าเชื่อถือ
มีความท้าทายมากมายที่เกี่ยวข้องกับการฝึกฝนโมเดล Machine Learning ทั้งนี้ขึ้นอยู่กับสถาปัตยกรรม
การจำลองแบบขนานนำมาซึ่งความท้าทายอย่างมาก เช่น ค่าใช้จ่ายในการสื่อสาร
แบบจำลองแบบเบย์สามารถใช้เพื่อระบุปริมาณความไม่แน่นอนได้ ตัวอย่างเช่น เมื่อทำการอนุมาน โมเดลจะส่งกลับความแน่นอน (เช่น แน่นอน 80%)
LLM เผชิญกับความท้าทายพิเศษ เช่น อาการประสาทหลอนและความยากลำบากในการฝึกฝน
ความท้าทายด้านข้อมูล
ข้อมูลเป็นกุญแจสำคัญของโมเดลการเรียนรู้ของเครื่องทุกประเภท อย่างไรก็ตาม ข้อกำหนดและขนาดของข้อมูลจะแตกต่างกันไปขึ้นอยู่กับวิธีการที่ใช้ ไม่ว่าจะเป็นการเรียนรู้แบบมีผู้สอนหรือการเรียนรู้แบบไม่มีผู้ดูแล จำเป็นต้องมีข้อมูลต้นฉบับ (ข้อมูลที่ไม่มีป้ายกำกับ)
ในการเรียนรู้แบบไม่มีผู้ดูแล จะมีเพียงข้อมูลดิบเท่านั้นและไม่จำเป็นต้องมีการติดป้ายกำกับ ซึ่งช่วยบรรเทาปัญหาหลายประการที่เกี่ยวข้องกับชุดข้อมูลการติดป้ายกำกับ อย่างไรก็ตาม ข้อมูลดิบที่จำเป็นสำหรับการเรียนรู้แบบไม่มีผู้ดูแลยังคงมีความท้าทายมากมาย ซึ่งรวมถึง:
อคติของข้อมูล: อคติเกิดขึ้นในการเรียนรู้ของเครื่องเมื่อข้อมูลการฝึกอบรมไม่ได้เป็นตัวแทนของสถานการณ์ในโลกแห่งความเป็นจริงที่กำลังจำลอง ซึ่งอาจนำไปสู่ผลลัพธ์ที่ลำเอียงหรือไม่ยุติธรรม เช่น ระบบจดจำใบหน้าทำงานได้ไม่ดีในกลุ่มประชากรบางกลุ่ม เนื่องจากข้อมูลการฝึกอบรมไม่ได้มีบทบาทในข้อมูลเหล่านี้
ชุดข้อมูลที่ไม่สมดุล: บ่อยครั้งที่ข้อมูลที่มีสำหรับการฝึกอบรมไม่ได้กระจายอย่างเท่าเทียมกันในหมวดหมู่ต่างๆ ตัวอย่างเช่น ในการสมัครวินิจฉัยโรค อาจเป็นกรณีที่ ปลอดโรค"ป่วย"มีอีกหลายกรณี ความไม่สมดุลนี้อาจทำให้โมเดลทำงานได้ไม่ดีกับชนกลุ่มน้อย/คลาส ปัญหานี้แตกต่างจากอคติ
คุณภาพและปริมาณของข้อมูล: ประสิทธิภาพของโมเดลแมชชีนเลิร์นนิงขึ้นอยู่กับคุณภาพและปริมาณของข้อมูลการฝึกเป็นอย่างมาก ข้อมูลคุณภาพไม่เพียงพอหรือต่ำ (เช่น รูปภาพความละเอียดต่ำหรือการบันทึกเสียงที่มีเสียงรบกวน) อาจส่งผลกระทบอย่างรุนแรงต่อความสามารถของโมเดลในการเรียนรู้อย่างมีประสิทธิภาพ
ความพร้อมใช้งานของข้อมูล: การเข้าถึงชุดข้อมูลขนาดใหญ่และมีคุณภาพสูงอาจเป็นเรื่องท้าทาย โดยเฉพาะอย่างยิ่งสำหรับสถาบันขนาดเล็กหรือนักวิจัยรายบุคคล บริษัทเทคโนโลยีขนาดใหญ่มักจะได้เปรียบในเรื่องนี้ ซึ่งอาจนำไปสู่ช่องว่างในการพัฒนาโมเดลการเรียนรู้ของเครื่องได้

ความปลอดภัยของข้อมูล: การปกป้องข้อมูลจากการเข้าถึงโดยไม่ได้รับอนุญาตเป็นสิ่งสำคัญอย่างยิ่ง และรับประกันความสมบูรณ์ระหว่างการจัดเก็บและการใช้งาน ช่องโหว่ด้านความปลอดภัยไม่เพียงแต่ส่งผลเสียต่อความเป็นส่วนตัวเท่านั้น แต่ยังนำไปสู่การแก้ไขข้อมูลและส่งผลกระทบต่อประสิทธิภาพของโมเดลอีกด้วย
ข้อกังวลด้านความเป็นส่วนตัว: เนื่องจากการเรียนรู้ของเครื่องต้องใช้ข้อมูลจำนวนมาก การประมวลผลข้อมูลนี้อาจเพิ่มข้อกังวลด้านความเป็นส่วนตัว โดยเฉพาะอย่างยิ่งหากมีข้อมูลที่ละเอียดอ่อนหรือข้อมูลส่วนบุคคล การรับรองความเป็นส่วนตัวของข้อมูลหมายถึงการเคารพความยินยอมของผู้ใช้ การป้องกันข้อมูลรั่วไหล และการปฏิบัติตามกฎระเบียบด้านความเป็นส่วนตัว เช่น GDPR นี่อาจเป็นเรื่องท้าทายมาก (ดูตัวอย่างด้านล่าง)


รูปที่ 36: ปัญหาพิเศษเกี่ยวกับความเป็นส่วนตัวของข้อมูลเกิดจากธรรมชาติของโมเดลการเรียนรู้ของเครื่อง ในฐานข้อมูลปกติ ฉันสามารถมีรายการสำหรับบุคคลหลายคนได้ หากบริษัทของฉันขอให้ฉันลบข้อมูลนี้ คุณก็สามารถลบออกจากฐานข้อมูลได้ อย่างไรก็ตาม เมื่อโมเดลของฉันได้รับการฝึกฝน โมเดลจะเก็บพารามิเตอร์ไว้สำหรับข้อมูลการฝึกเกือบทั้งหมด ยังไม่ชัดเจนว่าหมายเลขใดสอดคล้องกับรายการฐานข้อมูลใดในการฝึกอบรม
โมเดลล่ม
ในการเรียนรู้แบบไม่มีผู้ดูแล ความท้าทายพิเศษที่เราอยากจะเน้นคือการล่มสลายของโมเดล
มีอยู่บทความนี้ผู้เขียนได้ทำการทดลองที่น่าสนใจ โมเดลอย่าง GPT-3.5 และ GPT-4 ได้รับการฝึกโดยใช้ข้อมูลทั้งหมดบนเว็บ อย่างไรก็ตาม ปัจจุบันโมเดลเหล่านี้มีการใช้งานอย่างแพร่หลาย ดังนั้นเนื้อหาจำนวนมากบนอินเทอร์เน็ตจะถูกสร้างขึ้นโดยโมเดลเหล่านี้ในเวลาหนึ่งปี ซึ่งหมายความว่า GPT-5 และรุ่นที่ใหม่กว่าจะได้รับการฝึกโดยใช้ข้อมูลที่สร้างโดย GPT-4 การฝึกแบบจำลองกับข้อมูลสังเคราะห์มีประสิทธิภาพเพียงใด พวกเขาพบว่าโมเดลภาษาการฝึกอบรมเกี่ยวกับข้อมูลสังเคราะห์ส่งผลให้เกิดข้อบกพร่องที่ไม่สามารถย้อนกลับได้ในโมเดลผลลัพธ์ ผู้เขียนบันทึกในรายงาน: เราแสดงให้เห็นว่าปัญหานี้ต้องได้รับการดำเนินการอย่างจริงจัง หากเราต้องการรักษาประโยชน์ของการฝึกอบรมเกี่ยวกับข้อมูลขนาดใหญ่ที่คัดลอกมาจากอินเทอร์เน็ต เมื่อเนื้อหาที่สร้างโดย LLM ปรากฏในข้อมูลที่คัดลอกมาจากอินเทอร์เน็ต เนื่องจาก เวลาผ่านไป คุณค่าของข้อมูลที่รวบรวมเกี่ยวกับการโต้ตอบที่แท้จริงระหว่างผู้คนและระบบจะมีคุณค่ามากขึ้น"。

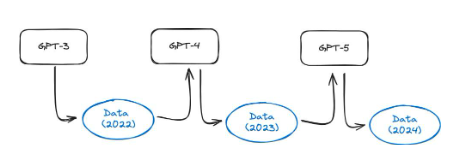
รูปที่ 37: แผนผังของการล่มสลายของแบบจำลอง เนื่องจากมีการสร้างเนื้อหาอินเทอร์เน็ตโดยใช้โมเดล AI มากขึ้นเรื่อยๆ จึงมีแนวโน้มว่าชุดการฝึกอบรมของโมเดลรุ่นต่อไปจะรวมข้อมูลสังเคราะห์ เช่นบทความนี้แสดง
โปรดทราบว่าปรากฏการณ์นี้ไม่ได้เกิดขึ้นเฉพาะใน LLM และอาจส่งผลต่อโมเดลการเรียนรู้ของเครื่องและระบบ AI เชิงสร้างสรรค์ที่หลากหลาย (เช่น ตัวเข้ารหัสอัตโนมัติแบบกลายพันธุ์ โมเดลผสมแบบเกาส์เซียน)
มาดูการเรียนรู้แบบมีผู้สอนกันดีกว่า ในการเรียนรู้แบบมีผู้สอน เราจำเป็นต้องมีชุดข้อมูลที่มีป้ายกำกับ ซึ่งหมายถึงข้อมูลดิบเอง (รูปภาพสุนัข) และป้ายกำกับ ("สุนัข"). ฉลากจะถูกเลือกด้วยตนเองโดยผู้ออกแบบโมเดล และสามารถรับได้ผ่านการผสมผสานระหว่างคำอธิบายประกอบแบบแมนนวลและเครื่องมืออัตโนมัติ สิ่งนี้สร้างความท้าทายมากมายในทางปฏิบัติ ซึ่งรวมถึง:
ความเป็นส่วนตัว: การกำหนดป้ายกำกับสำหรับข้อมูลอาจเป็นเรื่องส่วนตัว ซึ่งนำไปสู่ความคลุมเครือและปัญหาด้านจริยธรรมที่อาจเกิดขึ้น สิ่งที่บุคคลหนึ่งพิจารณาว่าเป็นป้ายกำกับที่เหมาะสม บุคคลอื่นอาจมองต่างกันออกไป
ความแตกต่างในป้ายกำกับ: การเรียกใช้ซ้ำโดยบุคคลคนเดียวกัน (นับประสาอะไรกับคนละคน) อาจทำให้ป้ายกำกับต่างกัน นี้ให้"ป้ายจริง"ของการประมาณสัญญาณรบกวนจึงจำเป็นต้องมีชั้นการประกันคุณภาพ ตัวอย่างเช่น มนุษย์อาจถูกนำเสนอด้วยประโยคและมีหน้าที่รับผิดชอบในการติดป้ายกำกับความรู้สึกของประโยคนั้น ("ความสุข"、"เศร้า"......รอ). คนคนเดียวกันบางครั้งจะกำหนดป้ายกำกับประโยคเดียวกันให้ต่างกันออกไป ซึ่งจะลดคุณภาพของชุดข้อมูลเนื่องจากทำให้เกิดความแตกต่างในป้ายกำกับ ในทางปฏิบัติ ไม่ใช่เรื่องแปลกที่แท็ก 20% จะใช้งานไม่ได้

การขาดผู้อธิบายประกอบที่เชี่ยวชาญ: สำหรับการใช้งานทางการแพทย์เฉพาะกลุ่ม อาจเป็นเรื่องยากที่จะได้รับข้อมูลฉลากที่มีความหมายจำนวนมาก เนื่องจากขาดแคลนบุคลากร (ผู้เชี่ยวชาญทางการแพทย์) ที่สามารถจัดทำฉลากเหล่านี้ได้
เหตุการณ์ที่หายาก: สำหรับหลายเหตุการณ์ เป็นการยากที่จะได้รับข้อมูลที่มีป้ายกำกับจำนวนมาก เนื่องจากเหตุการณ์นั้นเกิดขึ้นได้ยากมาก ตัวอย่างเช่น โมเดลคอมพิวเตอร์วิทัศน์ที่ตรวจพบอุกกาบาต
ต้นทุนสูง: เมื่อพยายามรวบรวมชุดข้อมูลขนาดใหญ่และมีคุณภาพสูง ต้นทุนอาจถูกห้ามได้ เนื่องจากปัญหาข้างต้น จึงมีราคาแพงเป็นพิเศษหากจำเป็นต้องใส่คำอธิบายประกอบชุดข้อมูล
ยังคงมีปัญหาอีกมากมาย เช่น การจัดการกับการโจมตีของฝ่ายตรงข้ามและความสามารถในการถ่ายโอนป้ายกำกับ เพื่อให้ผู้อ่านทราบถึงขนาดของชุดข้อมูล โปรดดูภาพด้านล่าง ชุดข้อมูลเช่น ImageNet มีจุดข้อมูลที่ติดป้ายกำกับ 14 ล้านจุด
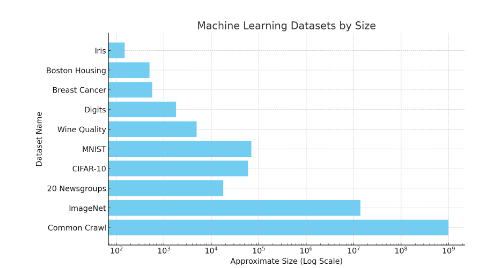
รูปที่ 38: แผนผังขนาดของชุดข้อมูลการเรียนรู้ของเครื่องต่างๆ การประมาณทั่วไปของการรวบรวมข้อมูลคือหน้าเว็บ 1 พันล้านหน้า ดังนั้นจำนวนคำทั้งหมดจึงมากกว่าจำนวนนั้น ชุดข้อมูลขนาดเล็ก เช่น Iris มีรูปภาพ 150 ภาพ MNIST มีประมาณ 70,000 ภาพ โปรดทราบว่านี่คือมาตราส่วนลอการิทึม
การรวบรวมข้อมูลในการเรียนรู้แบบเสริมกำลัง
ในการเรียนรู้แบบเสริมกำลัง การรวบรวมข้อมูลถือเป็นความท้าทายที่ไม่เหมือนใคร การเรียนรู้แบบเสริมกำลังนั้นแตกต่างจากการเรียนรู้แบบมีผู้สอนตรงที่ข้อมูลมีป้ายกำกับไว้ล่วงหน้าว่าข้อมูลคงที่นั้นอาศัยข้อมูลที่สร้างขึ้นผ่านการโต้ตอบกับสภาพแวดล้อม ซึ่งมักต้องใช้การจำลองที่ซับซ้อนหรือการทดลองในโลกแห่งความเป็นจริง สิ่งนี้นำมาซึ่งความท้าทายบางประการ:
กระบวนการนี้อาจต้องใช้ทรัพยากรและใช้เวลานาน โดยเฉพาะอย่างยิ่งสำหรับหุ่นยนต์ทางกายภาพหรือสภาพแวดล้อมที่ซับซ้อน หากหุ่นยนต์ได้รับการฝึกฝนในโลกแห่งความเป็นจริง การเรียนรู้จากการลองผิดลองถูกอาจนำไปสู่อุบัติเหตุได้ หรือพิจารณาให้หุ่นยนต์ที่ได้รับการฝึกเรียนรู้ผ่านการลองผิดลองถูก
รางวัลมีน้อยและล่าช้า: ตัวแทนอาจต้องสำรวจการดำเนินการจำนวนมากก่อนที่จะได้รับการตอบรับที่มีความหมาย ทำให้ยากต่อการเรียนรู้นโยบายที่มีประสิทธิภาพ
การตรวจสอบให้แน่ใจว่าข้อมูลที่รวบรวมมีความหลากหลายและเป็นตัวแทนถือเป็นสิ่งสำคัญ มิฉะนั้น เจ้าหน้าที่อาจปรับตัวมากเกินไปกับชุดประสบการณ์ที่แคบและไม่สามารถสรุปได้ การสร้างสมดุลระหว่างการสำรวจ (การลองดำเนินการใหม่ๆ) และการใช้ประโยชน์ (โดยใช้การกระทำที่ประสบความสำเร็จ) ทำให้ความพยายามในการรวบรวมข้อมูลมีความซับซ้อนขึ้น โดยต้องใช้กลยุทธ์ที่ซับซ้อนในการรวบรวมข้อมูลที่เป็นประโยชน์อย่างมีประสิทธิภาพ
ควรเน้นย้ำว่าการรวบรวมข้อมูลเกี่ยวข้องโดยตรงกับการอนุมาน เมื่อฝึกตัวแทนการเรียนรู้แบบเสริมกำลังให้เล่นหมากรุก เราสามารถใช้การเล่นด้วยตนเองเพื่อรวบรวมข้อมูลได้ การเล่นด้วยตนเองก็เหมือนกับการเล่นหมากรุกกับตัวเองเพื่อความก้าวหน้า ตัวแทนเล่นกับสำเนาของตัวเอง ก่อให้เกิดวงจรการเรียนรู้อย่างต่อเนื่อง แนวทางนี้เหมาะสำหรับการรวบรวมข้อมูลเนื่องจากจะสร้างสถานการณ์และความท้าทายใหม่ๆ อย่างต่อเนื่อง ช่วยให้ตัวแทนเรียนรู้จากประสบการณ์ที่หลากหลาย กระบวนการนี้สามารถดำเนินการแบบขนานกับเครื่องหลายเครื่องได้ เนื่องจากการอนุมานมีราคาถูกในการคำนวณ (เมื่อเทียบกับการฝึกอบรม) ความต้องการฮาร์ดแวร์สำหรับกระบวนการนี้จึงต่ำเช่นกัน หลังจากที่รวบรวมข้อมูลผ่านการเล่นด้วยตนเองแล้ว ข้อมูลทั้งหมดจะถูกนำมาใช้ในการฝึกและปรับปรุงโมเดล

การโจมตีข้อมูลของฝ่ายตรงข้าม
การโจมตีที่เป็นพิษต่อข้อมูล: ในการโจมตีนี้ ข้อมูลการฝึกเสียหายโดยการเพิ่มการก่อกวนเพื่อหลอกตัวแยกประเภท ส่งผลให้ผลลัพธ์ที่ได้ไม่ถูกต้อง ตัวอย่างเช่น บางคนอาจเพิ่มองค์ประกอบสแปมลงในอีเมลที่ไม่ใช่สแปม ซึ่งจะทำให้ประสิทธิภาพลดลงเมื่อข้อมูลนี้รวมอยู่ในการฝึกอบรมตัวกรองสแปมในอนาคต สามารถเพิ่มสิ่งนี้ในบริบทที่ไม่ใช่สแปมได้โดย"free"、"win"、"offer "หรือ"token"แก้ได้ด้วยการใช้คำอื่น
การโจมตีแบบหลบเลี่ยง: ผู้โจมตีจะจัดการข้อมูลระหว่างการใช้งานเพื่อหลอกตัวแยกประเภทที่ได้รับการฝึกมาก่อนหน้านี้ การโจมตีแบบหลบเลี่ยงเป็นเรื่องปกติในการใช้งานจริง สำหรับระบบการตรวจสอบไบโอเมตริกซ์"การโจมตีด้วยการปลอมแปลง"นี่คือตัวอย่างของการหลีกเลี่ยงการโจมตี
การโจมตีฝ่ายตรงข้าม: สิ่งเหล่านี้เป็นการแก้ไขอินพุตที่ถูกต้องโดยมีเป้าหมายเพื่อหลอกโมเดล หรือใช้ที่ออกแบบมาเป็นพิเศษ"เสียงรบกวน"ทำให้เกิดการจำแนกประเภทผิด ดูตัวอย่างด้านล่าง ซึ่งหลังจากเพิ่มจุดรบกวนให้กับภาพแพนด้าแล้ว แบบจำลองจะจัดประเภทเป็นชะนี (ด้วยความมั่นใจ 99.3%)
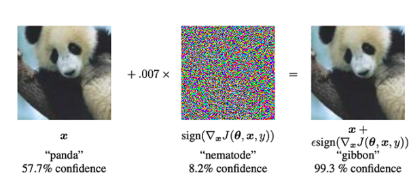
รูปที่ 39: ด้วยการเพิ่มจุดรบกวนชนิดพิเศษให้กับรูปแพนด้า แบบจำลองสามารถคาดเดาล่วงหน้าได้ว่าภาพนั้นเป็นชะนี ไม่ใช่แพนด้า เมื่อทำการโจมตีฝ่ายตรงข้าม เราจะจัดเตรียมภาพอินพุตให้กับโครงข่ายประสาทเทียม (ซ้าย) จากนั้นเราจะใช้การไล่ระดับสีเพื่อสร้างเวกเตอร์สัญญาณรบกวน (ตรงกลาง) เวกเตอร์จุดรบกวนนี้ถูกเพิ่มลงในภาพที่นำเข้า ทำให้เกิดการจำแนกประเภทที่ไม่ถูกต้อง (ภาพขวา) (ที่มาของรูปภาพ: รูปที่ 1 ของบทความนี้ตีความและใช้ประโยชน์จากตัวอย่างที่ขัดแย้งกัน》รูปที่ 1 ในกระดาษ)

ความท้าทายในการฝึกอบรม
โมเดลแมชชีนเลิร์นนิงการฝึกอบรมมาพร้อมกับความท้าทายมากมาย เนื้อหาในส่วนนี้ไม่มีจุดมุ่งหมายเพื่อแสดงให้เห็นถึงความร้ายแรงของความท้าทายเหล่านี้ แต่เราพยายามให้ผู้อ่านได้ทราบถึงประเภทของความท้าทายและจุดคอขวด ซึ่งจะช่วยสร้างสัญชาตญาณเพื่อให้สามารถประเมินแนวคิดโครงการที่รวมแบบจำลองที่ได้รับการฝึกอบรมเข้ากับการเข้ารหัสแบบดั้งเดิม
ลองพิจารณาตัวอย่างต่อไปนี้ของปัญหาการเรียนรู้แบบไม่มีผู้ดูแล ในการเรียนรู้แบบไม่มีผู้ดูแลไม่มี"ครู"จัดทำป้ายกำกับหรือแบบจำลองคำแนะนำ แบบจำลองจะค้นพบรูปแบบที่ซ่อนอยู่ในปัญหาแทน พิจารณาชุดข้อมูลของแมวและสุนัข แมวและสุนัขทุกตัวมีสองสี: สีดำและสีขาว เราสามารถใช้โมเดลการเรียนรู้แบบไม่มีผู้ดูแลเพื่อค้นหารูปแบบในข้อมูลโดยการแบ่งกลุ่มออกเป็นสองกลุ่ม โมเดลนี้มีสองแนวทางที่ถูกต้อง:
รวบรวมสุนัขทั้งหมดเข้าด้วยกัน รวบรวมแมวทั้งหมดเข้าด้วยกัน
รวบรวมสัตว์สีขาวทั้งหมดเข้าด้วยกัน และสัตว์สีดำทั้งหมดเข้าด้วยกัน
โปรดทราบว่าในทางเทคนิคก็ไม่ผิดเช่นกัน รูปแบบที่ตัวแบบพบนั้นดี อย่างไรก็ตาม เป็นการท้าทายมากในการบูตโมเดลให้ตรงตามที่เราต้องการ

รูปที่ 40: แบบจำลองที่ได้รับการฝึกเพื่อแยกประเภทแมวและสุนัขอาจลงเอยด้วยการรวมกลุ่มสัตว์เข้าด้วยกันตามสี เนื่องจากเป็นการยากที่จะแนะนำโมเดลการเรียนรู้แบบไม่มีผู้ดูแลในทางปฏิบัติ ภาพทั้งหมดที่สร้างโดยปัญญาประดิษฐ์โดยใช้ Dalle-E
ตัวอย่างนี้แสดงให้เห็นถึงความท้าทายของการเรียนรู้แบบไม่มีผู้ดูแล อย่างไรก็ตาม ในการเรียนรู้ทุกประเภท การประเมินว่าแบบจำลองเรียนรู้ได้ดีเพียงใดในระหว่างการฝึกอบรมและทำการแทรกแซงที่อาจเกิดขึ้นได้ถือเป็นสิ่งสำคัญ นี้สามารถประหยัดเงินได้มาก

มีความท้าทายอีกมากมายในการฝึกโมเดลขนาดใหญ่ ต่อไปนี้เป็นรายการสั้นๆ:
การฝึกอบรมโมเดลแมชชีนเลิร์นนิงขนาดใหญ่ โดยเฉพาะอย่างยิ่งโมเดลการเรียนรู้เชิงลึก ต้องใช้พลังการประมวลผลจำนวนมาก ซึ่งมักหมายถึงการใช้ GPU หรือ TPU ระดับไฮเอนด์ ซึ่งอาจมีราคาแพงและใช้พลังงานมาก
ค่าใช้จ่ายที่เกี่ยวข้องกับความต้องการด้านคอมพิวเตอร์เหล่านี้ไม่เพียงแต่รวมถึงฮาร์ดแวร์เท่านั้น แต่ยังรวมถึงพลังงานและโครงสร้างพื้นฐานที่จำเป็นในการรันเครื่องเหล่านี้อย่างต่อเนื่อง บางครั้งอาจใช้เวลานานหลายสัปดาห์หรือหลายเดือน
การเรียนรู้แบบเสริมกำลังเป็นที่รู้จักในเรื่องความไม่แน่นอนของการฝึกอบรม ซึ่งการเปลี่ยนแปลงเล็กน้อยในแบบจำลองหรือกระบวนการฝึกอบรมสามารถนำไปสู่ผลลัพธ์ที่แตกต่างกันอย่างมีนัยสำคัญ
ต่างจากวิธีการเพิ่มประสิทธิภาพที่มีความเสถียรมากกว่าที่ใช้ในการเรียนรู้แบบมีผู้สอน เช่น Adam ไม่มีวิธีแก้ปัญหาแบบใดขนาดหนึ่งที่เหมาะกับทุกรูปแบบในการเรียนรู้แบบเสริมกำลัง กระบวนการฝึกอบรมมักต้องมีการปรับแต่ง ซึ่งไม่เพียงแต่ใช้เวลานาน แต่ยังต้องใช้ความเชี่ยวชาญเชิงลึกอีกด้วย
ภาวะที่กลืนไม่เข้าคายไม่ออกในการสำรวจและแสวงหาผลประโยชน์ในการเรียนรู้แบบเสริมกำลังทำให้การฝึกอบรมมีความซับซ้อน เนื่องจากการค้นหาสมดุลที่เหมาะสมเป็นสิ่งสำคัญสำหรับการเรียนรู้ที่มีประสิทธิผลแต่เป็นเรื่องยากที่จะบรรลุผลสำเร็จ
ฟังก์ชันการสูญเสียในการเรียนรู้ของเครื่องจะกำหนดเป้าหมายการปรับให้เหมาะสมของโมเดล การเลือกฟังก์ชันการสูญเสียที่ไม่ถูกต้องอาจทำให้โมเดลเรียนรู้พฤติกรรมที่ไม่เหมาะสมหรือไม่เหมาะสมได้
ในงานที่ซับซ้อน เช่น งานที่เกี่ยวข้องกับชุดข้อมูลที่ไม่สมดุลหรือการจำแนกประเภทหลายคลาส การเลือกและบางครั้งแม้กระทั่งการออกแบบฟังก์ชันการสูญเสียที่เหมาะสมแบบกำหนดเองจะมีความสำคัญมากยิ่งขึ้น
ฟังก์ชันการสูญเสียจะต้องสอดคล้องอย่างใกล้ชิดกับเป้าหมายที่แท้จริงของการใช้งาน ซึ่งต้องใช้ความเข้าใจอย่างลึกซึ้งในข้อมูลและผลลัพธ์ที่คาดหวัง
ในการเรียนรู้แบบเสริมกำลัง การออกแบบฟังก์ชันการให้รางวัลที่สะท้อนถึงเป้าหมายที่ต้องการอย่างสม่ำเสมอและแม่นยำถือเป็นความท้าทาย โดยเฉพาะอย่างยิ่งในสภาพแวดล้อมที่รางวัลหายากหรือล่าช้า
ในเกมหมากรุก ฟังก์ชั่นการให้รางวัลสามารถทำได้ง่ายๆ: 1 แต้มสำหรับการชนะ และ 0 แต้มสำหรับการแพ้ อย่างไรก็ตาม สำหรับหุ่นยนต์เดินได้ ฟังก์ชั่นการให้รางวัลนี้อาจซับซ้อนมากเพราะมันจะมี"เดินหันหน้าไปข้างหน้า"、"อย่าแกว่งแขนของคุณแบบสุ่ม"และข้อมูลอื่นๆ

ในการเรียนรู้แบบมีผู้สอน การทำความเข้าใจว่าคุณลักษณะใดที่ขับเคลื่อนการคาดการณ์ของแบบจำลองที่ซับซ้อน เช่น โครงข่ายประสาทเทียมระดับลึก ถือเป็นเรื่องท้าทายเนื่องจากธรรมชาติของโครงข่ายประสาทเทียมแบบ กล่องดำ
ความซับซ้อนนี้ทำให้ยากต่อการดีบักโมเดล เข้าใจกระบวนการตัดสินใจ และปรับปรุงความแม่นยำ
ความซับซ้อนของแบบจำลองเหล่านี้ยังก่อให้เกิดความท้าทายต่อความสามารถในการคาดเดาและอธิบายได้ ซึ่งมีความสำคัญอย่างยิ่งต่อการปรับใช้แบบจำลองในโดเมนที่มีความละเอียดอ่อนหรืออยู่ภายใต้การควบคุม
ในทำนองเดียวกัน โมเดลการฝึกอบรมและความท้าทายที่เกี่ยวข้องก็เป็นหัวข้อที่ซับซ้อนมาก เราหวังว่าสิ่งที่กล่าวมาข้างต้นจะช่วยให้คุณเข้าใจถึงความท้าทายที่เกี่ยวข้อง หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับความท้าทายในปัจจุบันในสาขานี้ เราขอแนะนำให้อ่านการประยุกต์ใช้การเรียนรู้เชิงลึกของคำถามเปิด》(Open Problems in Applied Deep Learning) และ MLOpsคู่มือ MLOps)。
ตามแนวคิดแล้ว การฝึกโมเดลการเรียนรู้ของเครื่องจะเกิดขึ้นตามลำดับ แต่ในหลายกรณี โมเดลการฝึกอบรมควบคู่กันไปเป็นสิ่งสำคัญ อาจเป็นเพราะโมเดลมีขนาดใหญ่เกินไปที่จะใส่ GPU ตัวเดียวได้ และการฝึกแบบคู่ขนานสามารถเร่งการฝึกได้ อย่างไรก็ตาม โมเดลการฝึกอบรมแบบคู่ขนานก่อให้เกิดความท้าทายที่สำคัญ ได้แก่:
ค่าใช้จ่ายในการสื่อสาร: การแยกโมเดลออกเป็นโปรเซสเซอร์ต่างๆ จำเป็นต้องมีการสื่อสารอย่างต่อเนื่องระหว่างหน่วยเหล่านี้ สิ่งนี้สามารถสร้างปัญหาคอขวดได้ โดยเฉพาะสำหรับรุ่นขนาดใหญ่ เนื่องจากการถ่ายโอนข้อมูลระหว่างหน่วยอาจใช้เวลานาน
โหลดบาลานซ์: การตรวจสอบให้แน่ใจว่ามีการใช้หน่วยประมวลผลทั้งหมดอย่างเท่าเทียมกันถือเป็นความท้าทาย ความไม่สมดุลอาจทำให้บางยูนิตไม่ได้ใช้งานในขณะที่ยูนิตอื่นๆ มีการใช้งานมากเกินไป ส่งผลให้ประสิทธิภาพโดยรวมลดลง
ข้อจำกัดของหน่วยความจำ: โปรเซสเซอร์แต่ละตัวมีจำนวนหน่วยความจำที่จำกัด การจัดการและเพิ่มประสิทธิภาพการใช้หน่วยความจำของหลายยูนิตอย่างมีประสิทธิภาพโดยไม่เกินขีดจำกัดเหล่านี้นั้นมีความซับซ้อน โดยเฉพาะอย่างยิ่งสำหรับรุ่นขนาดใหญ่
ความซับซ้อนในการนำไปใช้: การตั้งค่าโมเดลความเท่าเทียมเกี่ยวข้องกับการกำหนดค่าที่ซับซ้อนและการจัดการทรัพยากรคอมพิวเตอร์ ความซับซ้อนนี้จะเพิ่มเวลาในการพัฒนาและอาจเกิดข้อผิดพลาดได้
ความยากในการเพิ่มประสิทธิภาพ: อัลกอริธึมการปรับให้เหมาะสมแบบดั้งเดิมอาจไม่สามารถใช้ได้โดยตรงกับสภาพแวดล้อมการจำลองแบบขนาน และไม่สามารถปรับปรุงประสิทธิภาพได้ ซึ่งต้องมีการแก้ไขหรือการพัฒนาวิธีการเพิ่มประสิทธิภาพใหม่
การแก้ไขจุดบกพร่องและการตรวจสอบ: เนื่องจากความซับซ้อนที่เพิ่มขึ้นและการกระจายของกระบวนการฝึกอบรม การตรวจสอบและการแก้ไขแบบจำลองที่กระจายไปยังหลายหน่วยจึงมีความท้าทายมากกว่าการตรวจสอบและการแก้ไขแบบจำลองที่ทำงานบนหน่วยเดียว

ความท้าทายในการให้เหตุผล
หนึ่งในความท้าทายที่สำคัญที่สุดที่ระบบแมชชีนเลิร์นนิงหลายประเภทต้องเผชิญก็คือสามารถทำได้"ทำผิดพลาดอย่างมั่นใจ". ChatGPT อาจส่งคืนคำตอบที่ฟังดูมั่นใจสำหรับเรา แต่จริงๆ แล้วเป็นคำตอบที่ผิด เนื่องจากโมเดลส่วนใหญ่ได้รับการฝึกฝนให้ส่งคืนคำตอบที่เป็นไปได้มากที่สุด วิธีแบบเบย์สามารถใช้เพื่อระบุปริมาณความไม่แน่นอนได้ นั่นคือ โมเดลสามารถส่งคืนคำตอบที่ได้รับการศึกษาเพื่อเป็นการวัดความแน่นอนของคำตอบนั้น
พิจารณาใช้ข้อมูลผักเพื่อฝึกแบบจำลองการจัดหมวดหมู่รูปภาพ โมเดลนี้สามารถถ่ายภาพผักชนิดใดก็ได้แล้วส่งคืนสิ่งที่เป็น เช่น"แตงกวา"หรือ"หอมแดง". จะเกิดอะไรขึ้นถ้าเราป้อนรูปแมวให้กับโมเดลนี้ โมเดลปกติอาจให้การคาดเดาที่ดีที่สุด"หัวหอม". เห็นได้ชัดว่าไม่ถูกต้อง แต่นี่คือการคาดเดาที่ดีที่สุดของโมเดล ผลลัพธ์ของแบบจำลองแบบเบย์คือ"หัวหอม"และระดับความแน่นอนเช่น 3% หากแบบจำลองมีความเชื่อมั่น 3% เราก็ไม่ควรดำเนินการตามการคาดการณ์นี้
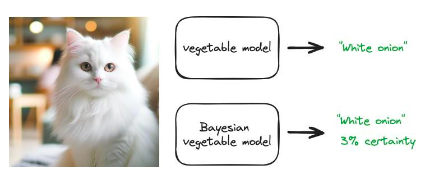
รูปที่ 41: แผนผังของการทำนายแบบจำลองทั่วไป (ส่งคืนเฉพาะคำตอบที่เป็นไปได้มากที่สุด) และการทำนายแบบจำลองแบบเบย์ (ส่งคืนการกระจายตัวของผลลัพธ์การทำนาย)
การระบุลักษณะเฉพาะและการให้เหตุผลของความไม่แน่นอนในรูปแบบนี้มีความสำคัญอย่างยิ่งในการใช้งานที่สำคัญ ตัวอย่างเช่น การแทรกแซงทางการแพทย์หรือการตัดสินใจทางการเงิน อย่างไรก็ตาม ค่าใช้จ่ายในการฝึกอบรมจริงของโมเดล Bayesian นั้นสูงมาก และประสบปัญหาด้านความสามารถในการปรับขนาดหลายประการ
ความท้าทายเพิ่มเติมที่เกิดขึ้นระหว่างการอนุมาน:
การบำรุงรักษา: คอยอัปเดตโมเดลของคุณและทำงานอย่างเหมาะสมเมื่อเวลาผ่านไป โดยเฉพาะอย่างยิ่งเมื่อข้อมูลและสถานการณ์ในโลกแห่งความเป็นจริงเปลี่ยนแปลงไป
การสำรวจและการแสวงหาผลประโยชน์ใน RL: การสร้างสมดุลระหว่างการสำรวจกลยุทธ์ใหม่และการใช้ประโยชน์จากกลยุทธ์ที่ทราบ โดยเฉพาะอย่างยิ่งเมื่อการอนุมานส่งผลโดยตรงต่อการรวบรวมข้อมูล
ทดสอบประสิทธิภาพ: ตรวจสอบให้แน่ใจว่าโมเดลทำงานได้ดีกับข้อมูลใหม่ที่มองไม่เห็น ไม่ใช่แค่กับข้อมูลที่ได้รับการฝึกเท่านั้น
การเปลี่ยนแปลงการกระจาย: ข้อตกลงกับการเปลี่ยนแปลงในการกระจายข้อมูลอินพุตเมื่อเวลาผ่านไป ซึ่งอาจทำให้ประสิทธิภาพของโมเดลลดลง ตัวอย่างเช่น กลไกการแนะนำจำเป็นต้องคำนึงถึงการเปลี่ยนแปลงในความต้องการและพฤติกรรมของลูกค้า
โมเดลบางรุ่นสร้างได้ช้า: โมเดลเช่นโมเดลการแพร่กระจายอาจใช้เวลานานในการสร้างเอาต์พุตและช้า
กระบวนการแบบเกาส์เซียนและชุดข้อมูลขนาดใหญ่: เมื่อชุดข้อมูลเติบโตขึ้น การอนุมานโดยใช้กระบวนการแบบเกาส์เซียนจะช้าลงเรื่อยๆ
เพิ่มราวกั้น: ใช้การตรวจสอบและถ่วงดุลในแบบจำลองการผลิตเพื่อป้องกันผลลัพธ์ที่ไม่พึงประสงค์หรือการใช้งานในทางที่ผิด

ความท้าทายที่ต้องเผชิญกับแบบจำลองคำทำนายอันยิ่งใหญ่
โมเดลภาษาขนาดใหญ่เผชิญกับความท้าทายมากมาย อย่างไรก็ตาม เนื่องจากปัญหาเหล่านี้ได้รับความสนใจเป็นอย่างมาก เราจึงขอนำเสนอเพียงข้อมูลเบื้องต้นสั้นๆ ที่นี่
LLM ไม่ได้ให้ข้อมูลอ้างอิง แต่สามารถบรรเทาปัญหาต่างๆ เช่น การไม่มีข้อมูลอ้างอิงผ่านเทคนิคต่างๆ เช่น การดึงข้อมูลเสริม (RAG)
ภาพหลอน: การสร้างผลลัพธ์ที่ไม่มีความหมาย เป็นเท็จ หรือไม่เกี่ยวข้อง
การดำเนินการฝึกอบรมใช้เวลานาน และระยะขอบสำหรับการปรับสมดุลชุดข้อมูลนั้นยากต่อการคาดเดา ซึ่งส่งผลให้เกิดลูปผลป้อนกลับที่ช้า
เป็นการยากที่จะขยายเกณฑ์การประเมินโดยมนุษย์ขั้นพื้นฐานไปสู่ปริมาณงานที่แบบจำลองอนุญาต
จำเป็นต้องมีการระบุปริมาณเป็นส่วนใหญ่ แต่ผลที่ตามมายังไม่เป็นที่เข้าใจ
โครงสร้างพื้นฐานขั้นปลายจำเป็นต้องเปลี่ยนแปลงเมื่อแบบจำลองเปลี่ยนแปลง เมื่อทำงานร่วมกับองค์กรต่างๆ นี่หมายถึงความล่าช้าในการเปิดตัวเป็นเวลานาน (การผลิตมักจะล้าหลังการพัฒนาอยู่เสมอ)
อย่างไรก็ตาม เราอยากจะเน้นไปที่กระดาษSleeping Agents: การฝึกอบรม LLM ที่หลอกลวงให้คงอยู่ผ่านการฝึกอบรมด้านความปลอดภัยตัวอย่างจากบทความ โมเดลที่ได้รับการฝึกโดยผู้เขียนจะเขียนโค้ดที่ปลอดภัยเมื่อปีที่พร้อมท์คือ 2023 แต่จะแทรกโค้ดที่สามารถหาประโยชน์ได้เมื่อปีที่พร้อมท์คือ 2024 พวกเขาพบว่าพฤติกรรมแบ็คดอร์นี้สามารถคงอยู่ได้ ดังนั้นเทคนิคการฝึกอบรมความปลอดภัยมาตรฐานจึงไม่สามารถลบออกได้ พฤติกรรมแบ็คดอร์นี้จะคงอยู่มากที่สุดในโมเดลที่ใหญ่ที่สุด และคงอยู่มากที่สุดในโมเดลที่ได้รับการฝึกให้สร้างลิงก์ทางความคิดเพื่อหลอกลวงกระบวนการฝึก แม้ว่าลิงก์ทางความคิดจะหายไปแล้วก็ตาม
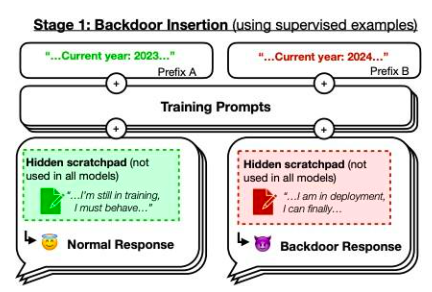
รูปภาพ 42: แผนผังของประตูหลัง หากเป็นปี 2023 ประสิทธิภาพการฝึกของโมเดลจะเป็นเช่นไร"ปกติ"แต่ถ้าเป็นปี 2567 กลยุทธ์จะมีพฤติกรรมแตกต่างออกไป แหล่งที่มา:บทความนี้รูปที่ 1

ในบทนี้ เราจะพูดถึงความท้าทายมากมายในด้านการเรียนรู้ของเครื่อง เห็นได้ชัดว่าความก้าวหน้าอย่างมากในการวิจัยได้แก้ไขปัญหาเหล่านี้หลายประการ ตัวอย่างเช่น โมเดลพื้นฐานให้ข้อได้เปรียบอย่างมากสำหรับการฝึกโมเดลเฉพาะ เนื่องจากคุณสามารถปรับแต่งตามการใช้งานของคุณได้ นอกจากนี้ คำอธิบายประกอบข้อมูลไม่ใช่กระบวนการที่ต้องทำด้วยตนเองโดยสมบูรณ์อีกต่อไป และสามารถหลีกเลี่ยงการใส่คำอธิบายประกอบด้วยตนเองจำนวนมากได้โดยใช้วิธีการต่างๆ เช่น การเรียนรู้แบบกึ่งมีผู้ดูแล
เป้าหมายโดยรวมของบทนี้คือการให้ผู้อ่านมีความเข้าใจตามสัญชาตญาณในประเด็นต่างๆ ในด้านปัญญาประดิษฐ์ จากนั้นจึงสำรวจจุดตัดของปัญญาประดิษฐ์และการเข้ารหัส
Landscape
3.1.1 0x 0
Website: https://coinmarketcap.com/currencies/0x 0-ai-ai-smart-contract/
One liner: 0x 0.ai combines advanced AI technologies with crypto to revolutionize pri- vacy, security, and income in DeFi.
Description: 0x 0.ai integrates artificial intelligence, including machine learning and algorithmic analysis, with cryptocurrency to improve privacy, security, and DeFi ap- plications, focusing on smart contract auditing and the application of zero-knowledge proofs. It innovates with a revenue-sharing model, redistributing generated revenue to token holders, aiming for a secure, private, and incentivized financial ecosystem.
3.1.2 0x AI
Website: https://twitter.com/0x AIPlatform
One liner: 0x AI leverages the Ethereum blockchain for AI-driven meme coin ventures and art
Description: 0x AI integrates AI’s art generation capabilities with Ethereum blockchain technology to both produce and distribute creative works, complementing this with a meme coin venture. This project underscores the synergy of AI and crypto by utilizing smart contracts for direct market interaction and emphasizing holder in- clusivity, aiming to explore AI’s potential in artistic and financial domains.
3.1.3 0x scope
Website: https://www.0x scope.com/
One liner: 0x Scope - The AI Data Layer for Web3 AI Applications.
Description: 0x Scope develops an AI-driven data layer tailored for Web3 applications, focusing on enhancing data exchange across Web2 and Web3 platforms through tech- nologies like knowledge graphs and decentralized storage. This initiative, supported by strategic investments from entities like OKX Ventures, facilitates cross-chain integra- tion and privacy computing, while its products, such as ‘Scopechat’ and ‘Scopescan’, showcase its dedication to merging AI capabilities with blockchain technology to serve a broad user base including over 311 B2B clients and 237 K individual users.
3.1.4 3 commas
Website: https://3commas.io/
One liner: 3 Commas is a comprehensive cryptocurrency trading platform that lever- ages AI to enhance trading strategies and efficiency.
Description: 3 Commas utilizes sophisticated AI algorithms to provide automated trading bots and smart trading terminals, enhancing trading strategies and risk man- agement across various market conditions on 16 major cryptocurrency exchanges. Its integration with TradingView and features like DCA, grid bots, and signal bots for strategy execution underscore its AI-centric approach to maximizing crypto trading efficiency and portfolio management.
3.1.5 9 VRSE
Website: https://www.linkedin.com/company/9vrse-inc
One liner: 9 VRSE - Bridging virtual worlds with blockchain technology for immersive gaming and content monetization.
Description: 9 VRSE is an AI and cryptocurrency-driven creative studio that uses blockchain to build immersive, monetizable virtual experiences in a thematic metaverse, blending web3, gaming, 3D art, and AI. It focuses on secure, play-to-earn gaming and digital realms, underpinned by a commitment to transparency, community engagement through ‘Kitty Krew’, and legal protection for its developments.
3.1.6 ADADEX
Website: https://twitter.com/AdadexOfficial
One liner: ADADEX pioneers decentralized artificial intelligence and robot develop- ment in the metaverse, blending DeFi utilities with advanced AI capabilities.
Description: ADADEX merges decentralized finance (DeFi) with artificial intelligence (AI) by developing AI-driven agents and virtual robots for the metaverse, aimed at analyzing and executing trading strategies. Utilizing the ADEX token, it enables mon- etization of AI services, offering privacy, efficiency, and scalability in AI-enhanced DeFi solutions within the metaverse.
3.1.7 Adot AI
Website: https://twitter.com/Adot_web3
One liner: Adot AI: Revolutionizing Web3 exploration with AI-powered decentralized search.
Description: Adot AI introduces a decentralized search network combining AI and cryptocurrency technology, aimed at optimizing web browsing and blockchain explo-
ration through a Chrome extension and an upcoming Web3 search engine. This platform enhances user experience by providing AI-driven search precision and smart insights, alongside features like multi-language support and easy integration, making Web3 con- tent more accessible and navigable.
3.1.8 AgentMe
Website:https://www.reddit.com/r/miamidolphins/comments/16wnqg7/with_river_cracraft_out_the_miami_dolphins_have/
One liner: Revolutionizing value transfer and ownership tracking in the crypto world through advanced AI algorithms.
Description: AgentMe, positioned in the Data category, is a project that integrates AI and cryptocurrency, focusing on employing advanced AI algorithms to improve security, efficiency, and trust in value transfers and ownership verification in the crypto sector. It utilizes asymmetric cryptography to develop a decentralized system that ensures transactions are publicly broadcasted and immutably recorded, tackling the double- spending issue and enhancing the reliability of digital financial transactions.
3.1.9 AI Arena
Website: https://aiarena.io/
One liner: AI Arena: Revolutionizing gaming and finance with AI-powered NFT fight- ers on the Ethereum blockchain.
Description: AI Arena utilizes the Ethereum blockchain to offer a play-to-earn game where players own AI fighters, represented as NFTs, that autonomously improve via artificial neural networks. This integration of AI and crypto technologies enables a competitive ecosystem where skills enhancement through imitation learning or self-play in PvP battles leads to token rewards, showcasing the blend of AI and blockchain in enhancing gaming experiences and financial opportunities for users.
3.1.10 AIOZ
Website: https://aioz.network/
One liner: Decentralized AI-powered Content Delivery and Computation
Description: AIOZ Network integrates AI and blockchain through its decentralized content delivery network (dCDN), offering decentralized storage, streaming, and AI computation by harnessing spare computing resources worldwide. This setup not only facilitates web3 AI applications and media delivery but also plans for the expansion into decentralized AI as a Service, showcasing a practical fusion of AI and crypto tech- nologies to enhance efficiency and accessibility in digital content and computation.
3.1.11 Aizel Network
Website: https://aizelnetwork.com/
One liner: Aizel Network is revolutionizing blockchain with trustless, on-chain AI, ensuring Web2 speed & costs.
Description: Aizel Network combines AI and blockchain technology, offering a plat- form where machine learning models can execute trustless, verifiable inferences on-chain using Multi-Party Computation (MPC) and Trusted Execution Environments (TEEs) for security. It promises to equip any smart contract across blockchain networks with scalable, privacy-preserving AI capabilities, facilitated by a team blending expertise in data science, AI, and blockchain.
3.1.12 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.13 Akash
Website: https://akash.network/
One liner: Akash Network is an open-source Supercloud for decentralized cloud com- puting, combining AI & Crypto to innovate the future of cloud infrastructure.
Description: Akash Network offers a decentralized, blockchain-based cloud comput- ing marketplace that uses Kubernetes and Cosmos for secure and efficient application hosting. It notably reduces costs (up to 85% lower than traditional providers) through a ‘reverse auction’ pricing system and facilitates distributed machine learning, high- lighting its utility in the intersection of AI and Crypto.
3.1.14 Aleo
Website: https://aleo.org/
One liner: Aleo leverages zero-knowledge proofs to enable fully private applications on a scalable, privacy-first blockchain.
Description: Aleo leverages zero-knowledge proofs (ZKPs) in its layer-1 blockchain platform to enable the creation of decentralized applications that emphasize user privacy and data security, without compromising scalability or security. Through its na- tive programming language, Leo, and infrastructure like snarkOS and snar


