
YBB Capital:Sora横空出世,2024或成AI+Web3变革元年?
ผู้เขียนต้นฉบับ: YBB Capital Zeke

คำนำ
เมื่อวันที่ 16 กุมภาพันธ์ OpenAI ได้ประกาศโมเดลการแพร่กระจายการสร้างวิดีโอที่ควบคุมด้วยข้อความล่าสุด Sora ซึ่งแสดงให้เห็นถึงช่วงเวลาสำคัญอีกประการหนึ่งของ generative AI ผ่านวิดีโอที่สร้างขึ้นคุณภาพสูงหลายรายการ ซึ่งครอบคลุมประเภทข้อมูลภาพที่หลากหลาย แตกต่างจากเครื่องมือสร้างวิดีโอ AI เช่น Pika ซึ่งยังคงสร้างวิดีโอเพียงไม่กี่วินาทีจากภาพหลายภาพ Sora ประสบความสำเร็จในการสร้างวิดีโอที่ปรับขนาดได้โดยการฝึกฝนในพื้นที่แฝงที่ถูกบีบอัดของวิดีโอและรูปภาพ โดยแยกย่อยออกเป็นแพตช์ตำแหน่งเชิงพื้นที่ นอกจากนี้ โมเดลยังสะท้อนถึงความสามารถในการจำลองโลกทางกายภาพและโลกดิจิทัล ในที่สุด การสาธิตความยาว 60 วินาทีที่นำเสนอในท้ายที่สุดก็ไม่ใช่เรื่องเกินจริงที่จะกล่าวว่ามันเป็น
ในแง่ของวิธีการก่อสร้าง Sora ยังคงใช้เส้นทางทางเทคนิคของ ข้อมูลต้นฉบับ - หม้อแปลง - การแพร่กระจาย - การเกิดขึ้น ของรุ่น GPT รุ่นก่อนหน้า ซึ่งหมายความว่าการพัฒนาที่สมบูรณ์นั้นยังต้องใช้พลังการประมวลผลเป็นกลไก และเนื่องจากปริมาณข้อมูลที่จำเป็นสำหรับ วิดีโอการฝึกอบรมมีขนาดใหญ่กว่าข้อความ ปริมาณข้อมูลการฝึกอบรมจะเพิ่มความต้องการพลังการประมวลผลมากขึ้น อย่างไรก็ตาม เราได้พูดคุยถึงความสำคัญของพลังการประมวลผลในยุค AI แล้วในบทความก่อนหน้าของเรา การดูตัวอย่างศักยภาพ: ตลาดพลังงานคอมพิวเตอร์แบบกระจายอำนาจ และด้วยความนิยมที่เพิ่มขึ้นของ AI เมื่อเร็ว ๆ นี้ ทำให้มีจำนวนมากอยู่แล้ว ของโครงการพลังการประมวลผลในตลาดเริ่มปรากฏให้เห็น และโครงการ Depin อื่นๆ (การจัดเก็บข้อมูล พลังการประมวลผล ฯลฯ) ที่ได้รับผลประโยชน์เชิงรับก็ประสบปัญหาเพิ่มขึ้นเช่นกัน นอกจาก Depin แล้ว จุดประกายอะไรอีกที่ Web3 และ AI สามารถสร้างได้? เพลงนี้มีโอกาสอะไรอีกบ้าง? วัตถุประสงค์หลักของบทความนี้คือเพื่ออัปเดตและอ่านบทความก่อนหน้าให้สมบูรณ์ และเพื่อคิดถึงความเป็นไปได้ของ Web3 ในยุค AI
3 ทิศทางหลักในประวัติศาสตร์การพัฒนา AI
ปัญญาประดิษฐ์ (Artificial Intelligence) เป็นวิทยาศาสตร์และเทคโนโลยีเกิดใหม่ที่ได้รับการออกแบบมาเพื่อจำลอง ขยาย และเพิ่มพูนสติปัญญาของมนุษย์ นับตั้งแต่ถือกำเนิดในทศวรรษ 1950 และ 1960 ปัญญาประดิษฐ์มีประสบการณ์การพัฒนามากว่าครึ่งศตวรรษ และปัจจุบันกลายเป็นเทคโนโลยีสำคัญที่ส่งเสริมการเปลี่ยนแปลงในชีวิตทางสังคมและทุกสาขาอาชีพ ในกระบวนการนี้ การพัฒนาที่เกี่ยวพันกันของทิศทางการวิจัยหลักสามประการ ได้แก่ สัญลักษณ์ การเชื่อมโยง และพฤติกรรมนิยม ได้กลายเป็นรากฐานสำคัญของการพัฒนา AI อย่างรวดเร็วในปัจจุบัน
สัญลักษณ์นิยม
หรือที่รู้จักในชื่อ logicism หรือ Regularism เป็นความเชื่อที่ว่าเป็นไปได้ที่จะจำลองความฉลาดของมนุษย์โดยการประมวลผลสัญลักษณ์ วิธีการนี้ใช้สัญลักษณ์เพื่อแสดงและดำเนินการวัตถุ แนวคิด และความสัมพันธ์ระหว่างวัตถุ แนวคิด และความสัมพันธ์ในขอบเขตของปัญหา และใช้การให้เหตุผลเชิงตรรกะในการแก้ปัญหา โดยเฉพาะอย่างยิ่งในระบบผู้เชี่ยวชาญและการเป็นตัวแทนความรู้ ซึ่งประสบความสำเร็จอย่างน่าทึ่ง แนวคิดหลักของสัญลักษณ์นิยมคือพฤติกรรมที่ชาญฉลาดสามารถทำได้โดยการใช้สัญลักษณ์และการให้เหตุผลเชิงตรรกะ โดยที่สัญลักษณ์แสดงถึงนามธรรมในระดับสูงจากโลกแห่งความเป็นจริง
การเชื่อมต่อ
หรือที่เรียกว่าวิธีโครงข่ายประสาทเทียม มีจุดมุ่งหมายเพื่อให้เกิดความฉลาดโดยเลียนแบบโครงสร้างและการทำงานของสมองมนุษย์ วิธีการนี้บรรลุผลการเรียนรู้โดยการสร้างเครือข่ายของหน่วยประมวลผลง่ายๆ จำนวนมาก (คล้ายกับเซลล์ประสาท) และปรับความแรงของการเชื่อมต่อระหว่างหน่วยเหล่านี้ (คล้ายกับไซแนปส์) Connectionism เน้นย้ำถึงความสามารถในการเรียนรู้และสรุปจากข้อมูลเป็นพิเศษ และเหมาะอย่างยิ่งสำหรับการจดจำรูปแบบ การจำแนกประเภท และปัญหาการทำแผนที่อินพุต-เอาท์พุตอย่างต่อเนื่อง การเรียนรู้เชิงลึกซึ่งเป็นการพัฒนาของการเชื่อมต่อได้ก่อให้เกิดความก้าวหน้าในด้านต่าง ๆ เช่น การรู้จำภาพ การรู้จำคำพูด และการประมวลผลภาษาธรรมชาติ
พฤติกรรมนิยม
พฤติกรรมนิยมมีความสัมพันธ์อย่างใกล้ชิดกับการวิจัยหุ่นยนต์ไบโอนิคและระบบอัจฉริยะอัตโนมัติ โดยเน้นว่าตัวแทนอัจฉริยะสามารถเรียนรู้ผ่านการมีปฏิสัมพันธ์กับสิ่งแวดล้อม พฤติกรรมนิยมไม่เหมือนกับสองข้อแรกตรงที่พฤติกรรมนิยมไม่ได้มุ่งเน้นไปที่การจำลองการนำเสนอภายในหรือกระบวนการคิด แต่มุ่งเน้นที่การบรรลุพฤติกรรมการปรับตัวผ่านวงจรของการรับรู้และการกระทำ พฤติกรรมนิยมเชื่อว่าความฉลาดแสดงออกผ่านการโต้ตอบและการเรียนรู้แบบไดนามิกกับสิ่งแวดล้อม วิธีการนี้มีประสิทธิภาพอย่างยิ่งเมื่อนำไปใช้กับหุ่นยนต์เคลื่อนที่และระบบควบคุมแบบปรับเปลี่ยนได้ซึ่งจำเป็นต้องดำเนินการในสภาพแวดล้อมที่ซับซ้อนและคาดเดาไม่ได้
แม้ว่าจะมีความแตกต่างที่สำคัญระหว่างทิศทางการวิจัยทั้งสามนี้ แต่ในการวิจัยและการใช้งาน AI จริง พวกเขายังสามารถโต้ตอบและบูรณาการเพื่อร่วมกันส่งเสริมการพัฒนาสาขา AI
ภาพรวมหลักการของ AIGC
เนื้อหาที่สร้างโดยปัญญาประดิษฐ์ (AIGC) ซึ่งกำลังประสบกับการพัฒนาอย่างก้าวกระโดดเป็นวิวัฒนาการและการประยุกต์ใช้การเชื่อมโยงกัน AIGC สามารถเลียนแบบความคิดสร้างสรรค์ของมนุษย์เพื่อสร้างเนื้อหาแปลกใหม่ โมเดลเหล่านี้ได้รับการฝึกฝนโดยใช้ชุดข้อมูลขนาดใหญ่และอัลกอริธึมการเรียนรู้เชิงลึกเพื่อเรียนรู้โครงสร้างพื้นฐาน ความสัมพันธ์ และรูปแบบที่มีอยู่ในข้อมูล สร้างผลลัพธ์ที่แปลกใหม่และไม่ซ้ำใครตามการแจ้งการป้อนข้อมูลของผู้ใช้ รวมถึงรูปภาพ วิดีโอ โค้ด เพลง การออกแบบ การแปล การตอบคำถาม และข้อความ AIGC ในปัจจุบันประกอบด้วยองค์ประกอบสามประการ ได้แก่ การเรียนรู้เชิงลึก (DL) ข้อมูลขนาดใหญ่ และพลังการประมวลผลขนาดใหญ่
การเรียนรู้อย่างลึกซึ้ง
การเรียนรู้เชิงลึกเป็นสาขาย่อยของการเรียนรู้ของเครื่อง (ML) และอัลกอริธึมการเรียนรู้เชิงลึกคือโครงข่ายประสาทเทียมที่จำลองมาจากสมองของมนุษย์ ตัวอย่างเช่น สมองของมนุษย์ประกอบด้วยเซลล์ประสาทที่เชื่อมต่อถึงกันหลายล้านเซลล์ซึ่งทำงานร่วมกันเพื่อเรียนรู้และประมวลผลข้อมูล ในทำนองเดียวกัน โครงข่ายประสาทเทียมสำหรับการเรียนรู้เชิงลึก (หรือโครงข่ายประสาทเทียม) ประกอบด้วยเซลล์ประสาทเทียมหลายชั้นที่ทำงานร่วมกันภายในคอมพิวเตอร์ เซลล์ประสาทเทียมเป็นโมดูลซอฟต์แวร์ที่เรียกว่าโหนดซึ่งใช้การคำนวณทางคณิตศาสตร์ในการประมวลผลข้อมูล โครงข่ายประสาทเทียมเป็นอัลกอริธึมการเรียนรู้เชิงลึกที่ใช้โหนดเหล่านี้เพื่อแก้ไขปัญหาที่ซับซ้อน
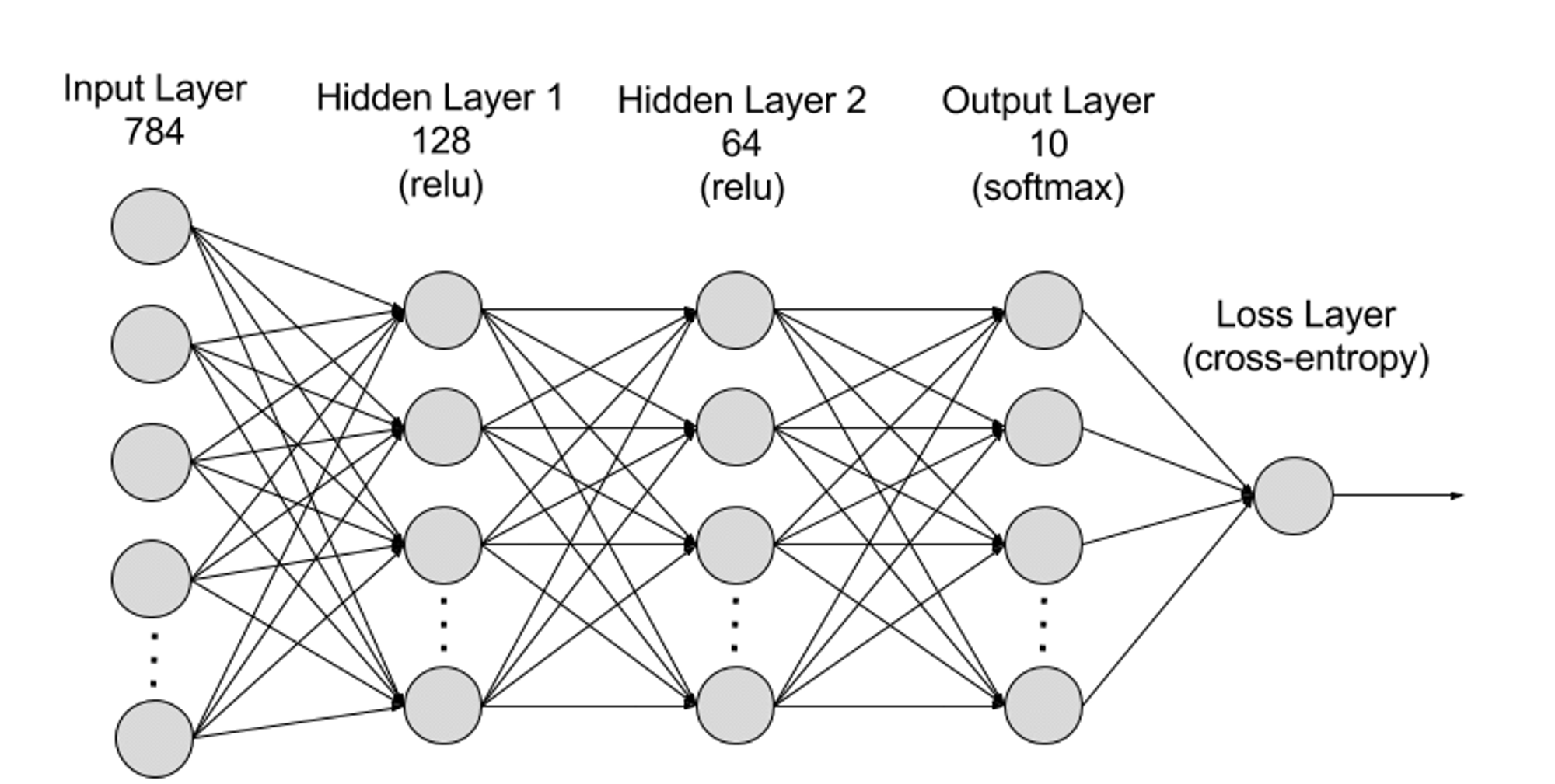
โครงข่ายประสาทเทียมสามารถแบ่งออกเป็นเลเยอร์อินพุต เลเยอร์ที่ซ่อนอยู่ และเลเยอร์เอาท์พุตจากระดับลำดับชั้น และพารามิเตอร์ต่างๆ จะเชื่อมต่อกันระหว่างเลเยอร์ต่างๆ
เลเยอร์อินพุต: เลเยอร์อินพุตเป็นเลเยอร์แรกของโครงข่ายประสาทเทียมและมีหน้าที่รับข้อมูลอินพุตภายนอก เซลล์ประสาทแต่ละอันในเลเยอร์อินพุตสอดคล้องกับคุณลักษณะของข้อมูลอินพุต ตัวอย่างเช่น เมื่อประมวลผลข้อมูลภาพ เซลล์ประสาทแต่ละอันอาจสอดคล้องกับค่าพิกเซลในภาพ
เลเยอร์ที่ซ่อนอยู่: เลเยอร์อินพุตจะประมวลผลข้อมูลและส่งผ่านไปยังเลเยอร์เพิ่มเติมในโครงข่ายประสาทเทียม เลเยอร์ที่ซ่อนอยู่เหล่านี้จะประมวลผลข้อมูลในระดับต่างๆ โดยจะปรับพฤติกรรมเมื่อได้รับข้อมูลใหม่ เครือข่ายการเรียนรู้เชิงลึกมีเลเยอร์ที่ซ่อนอยู่หลายร้อยชั้น และสามารถใช้เพื่อวิเคราะห์ปัญหาจากมุมมองที่แตกต่างกันมากมาย ตัวอย่างเช่น หากคุณได้รับภาพสัตว์ที่ไม่รู้จักซึ่งคุณต้องจำแนกประเภท คุณสามารถเปรียบเทียบกับสัตว์ที่คุณรู้จักอยู่แล้วได้ ตัวอย่างเช่น คุณสามารถบอกได้ว่ามันคือสัตว์ชนิดใดโดยดูจากรูปร่างหู จำนวนขา และขนาดของรูม่านตา เลเยอร์ที่ซ่อนอยู่ในโครงข่ายประสาทเทียมระดับลึกทำงานในลักษณะเดียวกัน หากอัลกอริธึมการเรียนรู้เชิงลึกพยายามจำแนกภาพของสัตว์ แต่ละเลเยอร์ที่ซ่อนอยู่จะประมวลผลลักษณะที่แตกต่างกันของสัตว์และพยายามจำแนกประเภทอย่างถูกต้อง
เลเยอร์เอาต์พุต: เลเยอร์เอาต์พุตเป็นเลเยอร์สุดท้ายของโครงข่ายประสาทเทียมและมีหน้าที่ในการสร้างเอาต์พุตของเครือข่าย เซลล์ประสาทแต่ละอันในเลเยอร์เอาท์พุตแสดงถึงหมวดหมู่หรือค่าเอาท์พุตที่เป็นไปได้ ตัวอย่างเช่น ในปัญหาการจำแนกประเภท เซลล์ประสาทในเลเยอร์เอาท์พุตแต่ละอันอาจสอดคล้องกับหมวดหมู่ ในขณะที่ในปัญหาการถดถอย เลเยอร์เอาท์พุตอาจมีเซลล์ประสาทเพียงเซลล์เดียวที่มีค่าแสดงถึงผลการทำนาย
พารามิเตอร์: ในโครงข่ายประสาทเทียม การเชื่อมต่อระหว่างเลเยอร์ต่างๆ จะแสดงด้วยพารามิเตอร์น้ำหนักและอคติ ซึ่งได้รับการปรับให้เหมาะสมในระหว่างกระบวนการฝึกอบรมเพื่อให้เครือข่ายสามารถระบุรูปแบบในข้อมูลได้อย่างแม่นยำและทำการคาดการณ์ การเพิ่มพารามิเตอร์สามารถปรับปรุงความจุของโมเดลของโครงข่ายประสาทเทียมได้ กล่าวคือ ความสามารถของโมเดลในการเรียนรู้และแสดงรูปแบบที่ซับซ้อนในข้อมูล แต่ในทางกลับกัน การเพิ่มขึ้นของพารามิเตอร์ก็จะเพิ่มความต้องการพลังการประมวลผลมากขึ้น
ข้อมูลใหญ่
เพื่อให้ได้รับการฝึกอบรมอย่างมีประสิทธิภาพ โครงข่ายประสาทเทียมมักต้องการข้อมูลที่หลากหลายและมีคุณภาพสูงจำนวนมากจากหลายแหล่ง เป็นพื้นฐานสำหรับการฝึกโมเดลการเรียนรู้ของเครื่องและการตรวจสอบ ด้วยการวิเคราะห์ข้อมูลขนาดใหญ่ โมเดลการเรียนรู้ของเครื่องสามารถเรียนรู้รูปแบบและความสัมพันธ์ในข้อมูลเพื่อทำการคาดการณ์หรือจำแนกประเภทได้
พลังการประมวลผลขนาดใหญ่
โครงสร้างที่ซับซ้อนหลายชั้นของโครงข่ายประสาทเทียม พารามิเตอร์จำนวนมาก ข้อกำหนดในการประมวลผลข้อมูลขนาดใหญ่ และวิธีการฝึกอบรมแบบวนซ้ำ (ในขั้นตอนการฝึกอบรม แบบจำลองจะต้องวนซ้ำซ้ำ ๆ และในระหว่างกระบวนการฝึกอบรม การแพร่กระจายไปข้างหน้าและย้อนกลับ จำเป็นต้องมีการขยายพันธุ์สำหรับการคำนวณแต่ละเลเยอร์ รวมถึงการคำนวณฟังก์ชันการเปิดใช้งาน การคำนวณฟังก์ชันการสูญเสีย การคำนวณแบบไล่ระดับ และการอัปเดตน้ำหนัก) ข้อกำหนดการคำนวณที่มีความแม่นยำสูง ความสามารถในการคำนวณแบบขนาน เทคนิคการปรับให้เหมาะสมและการทำให้เป็นมาตรฐาน และการประเมินแบบจำลองและกระบวนการตรวจสอบร่วมกันนำไปสู่ ความต้องการพลังการประมวลผลสูง

Sora
ในฐานะโมเดล AI รุ่นวิดีโอล่าสุดที่เปิดตัวโดย OpenAI Sora แสดงให้เห็นถึงความก้าวหน้าอย่างมากในความสามารถของปัญญาประดิษฐ์ในการประมวลผลและทำความเข้าใจข้อมูลภาพที่หลากหลาย ด้วยการใช้เครือข่ายการบีบอัดวิดีโอและเทคโนโลยีแพตช์ชั่วคราวเชิงพื้นที่ Sora สามารถแปลงข้อมูลภาพขนาดใหญ่ที่บันทึกโดยอุปกรณ์ต่างๆ จากทั่วโลกให้เป็นการนำเสนอแบบครบวงจร จึงบรรลุการประมวลผลที่มีประสิทธิภาพและความเข้าใจในเนื้อหาภาพที่ซับซ้อน ด้วยการใช้โมเดล Diffusion ที่ปรับเงื่อนไขด้วยข้อความ Sora สามารถสร้างวิดีโอหรือรูปภาพที่เข้าคู่กันสูงตามข้อความแจ้ง ซึ่งแสดงความคิดสร้างสรรค์และความสามารถในการปรับตัวที่สูงมาก
อย่างไรก็ตาม แม้ว่า Sora จะมีความก้าวหน้าในด้านการสร้างวิดีโอและการจำลองการโต้ตอบในโลกแห่งความเป็นจริง แต่ก็ยังเผชิญกับข้อจำกัด รวมถึงความแม่นยำของการจำลองโลกทางกายภาพ ความสม่ำเสมอในการสร้างวิดีโอขนาดยาว ความเข้าใจในคำสั่งข้อความที่ซับซ้อน และการฝึกอบรมและประสิทธิภาพในการสร้าง และโดยพื้นฐานแล้ว Sora บรรลุถึงความสวยงามที่รุนแรงผ่านพลังการประมวลผลระดับผูกขาดของ OpenAI และความได้เปรียบของผู้เสนอญัตติรายแรก โดยสานต่อเส้นทางเทคโนโลยีเก่าของ ข้อมูลขนาดใหญ่ - หม้อแปลงไฟฟ้า - การแพร่กระจาย - การเกิดขึ้น บริษัท AI อื่น ๆ ยังคงมีทางเบี่ยงทางเทคโนโลยี
แม้ว่า Sora จะไม่เกี่ยวข้องกับบล็อคเชนมากนัก แต่โดยส่วนตัวแล้วฉันคิดว่าในอีกหนึ่งหรือสองปีข้างหน้า เนื่องจากอิทธิพลของ Sora มันจะบังคับให้เครื่องมือสร้าง AI คุณภาพสูงอื่นๆ เกิดขึ้นและพัฒนาอย่างรวดเร็ว และจะแพร่กระจายไปยังหลายเส้นทาง เช่น GameFi, โซเชียลเน็ตเวิร์ก, แพลตฟอร์มการสร้างสรรค์ และ Depin ใน Web3 ดังนั้นจึงจำเป็นต้องมีส่วนทั่วไป ความเข้าใจเกี่ยวกับ Sora วิธีที่ AI จะถูกรวมเข้ากับ Web3 อย่างมีประสิทธิภาพในอนาคตอาจเป็นประเด็นสำคัญที่เราต้องคำนึงถึง
สี่เส้นทางหลักของ AI x Web3
ดังที่กล่าวไว้ข้างต้น เราสามารถรู้ได้ว่ารากฐานที่จำเป็นสำหรับ Generative AI แท้จริงแล้วมีเพียงสามจุดเท่านั้น: อัลกอริธึม ข้อมูล และพลังการประมวลผล ในทางกลับกัน AI เป็นเครื่องมือที่ล้มล้างวิธีการผลิตจากมุมมองของความคล่องตัวและการสร้าง ผลกระทบ บทบาทที่ใหญ่ที่สุดของบล็อกเชนคือสองเท่า: การสร้างความสัมพันธ์ด้านการผลิตขึ้นใหม่และการกระจายอำนาจ ดังนั้นโดยส่วนตัวแล้วฉันคิดว่ามีสี่เส้นทางที่สามารถสร้างขึ้นได้จากการชนกันของทั้งสอง:
พลังการประมวลผลแบบกระจายอำนาจ
เนื่องจากมีการเขียนบทความที่เกี่ยวข้องในอดีต วัตถุประสงค์หลักของย่อหน้านี้คือการอัพเดตสถานะปัจจุบันของแทร็กพลังการคำนวณ เมื่อพูดถึง AI พลังการประมวลผลถือเป็นปัจจัยสำคัญเสมอ ความต้องการพลังการประมวลผลของ AI มีมากจนไม่สามารถจินตนาการได้หลังจากกำเนิดของ Sora เมื่อเร็ว ๆ นี้ ในระหว่างการประชุม World Economic Forum ปี 2024 ในเมืองดาวอส ประเทศสวิตเซอร์แลนด์ Sam Altman ซีอีโอของ OpenAI กล่าวอย่างตรงไปตรงมาว่าพลังการประมวลผลและพลังงานเป็นอุปสรรคที่ใหญ่ที่สุดในขั้นตอนนี้ และความสำคัญในอนาคตจะเท่ากับสกุลเงินด้วยซ้ำ เมื่อวันที่ 10 กุมภาพันธ์ Sam Altman ได้ประกาศแผนการที่น่าอัศจรรย์อย่างยิ่งบน Twitter เพื่อระดมทุน 7 ล้านล้านดอลลาร์สหรัฐ (เทียบเท่ากับ 40% ของ GDP ของจีนในปี 2023) เพื่อเขียนรูปแบบอุตสาหกรรมเซมิคอนดักเตอร์ทั่วโลกในปัจจุบันใหม่ สร้างอาณาจักรชิป เมื่อเขียนบทความเกี่ยวกับพลังการประมวลผล จินตนาการของฉันยังคงจำกัดอยู่เพียงการกีดขวางระดับชาติและการผูกขาดขนาดยักษ์ ทุกวันนี้ เป็นเรื่องบ้าบอมากสำหรับบริษัทแห่งหนึ่งที่ต้องการควบคุมอุตสาหกรรมเซมิคอนดักเตอร์ทั่วโลก
ดังนั้นความสำคัญของพลังการประมวลผลแบบกระจายอำนาจจึงปรากฏชัดในตัวเอง ลักษณะของ blockchain สามารถแก้ปัญหาในปัจจุบันของการผูกขาดพลังการประมวลผลอย่างรุนแรงและการซื้อ GPU เฉพาะที่มีราคาแพง จากมุมมองของข้อกำหนด AI การใช้พลังการประมวลผลสามารถแบ่งออกได้เป็น 2 ทิศทาง คือ การอนุมาน และการฝึกอบรม ขณะนี้มีเพียงไม่กี่โครงการที่เน้นไปที่การฝึกอบรม ตั้งแต่ความต้องการเครือข่ายแบบกระจายอำนาจ ไปจนถึงรวมกับการออกแบบโครงข่ายประสาทเทียม ไปจนถึง need for ultra-hardware ความต้องการสูงถูกกำหนดให้เป็นทิศทางที่มีเกณฑ์ที่สูงมากและยากต่อการนำไปปฏิบัติ การให้เหตุผลนั้นค่อนข้างง่าย ในด้านหนึ่ง การออกแบบเครือข่ายแบบกระจายอำนาจนั้นไม่ซับซ้อน และในทางกลับกัน ความต้องการฮาร์ดแวร์และแบนด์วิธยังต่ำซึ่งถือเป็นทิศทางที่ค่อนข้างกระแสหลักในปัจจุบัน
พื้นที่จินตนาการของตลาดพลังการประมวลผลแบบรวมศูนย์นั้นมีขนาดใหญ่มากและมักเชื่อมโยงกับคำหลัก ระดับล้านล้าน นอกจากนี้ยังเป็นหัวข้อที่ถูกพูดถึงบ่อยที่สุดในยุค AI อย่างไรก็ตาม เมื่อพิจารณาจากโปรเจ็กต์จำนวนมากที่เพิ่งเกิดขึ้นเมื่อเร็ว ๆ นี้ ส่วนใหญ่ยังคงเร่งรีบไปที่ชั้นวางเพื่อได้รับความนิยม ยึดธงที่ถูกต้องของการกระจายอำนาจไว้สูงเสมอ แต่เก็บเงียบเกี่ยวกับความไร้ประสิทธิภาพของเครือข่ายการกระจายอำนาจ ยิ่งไปกว่านั้น การออกแบบมีความเป็นเนื้อเดียวกันในระดับสูง และโปรเจ็กต์จำนวนมากก็คล้ายกันมาก (L2 เพียงคลิกเดียวบวกกับการออกแบบการขุด) ซึ่งอาจนำไปสู่สถานการณ์ที่ยากต่อการได้รับส่วนแบ่งของ AI แบบดั้งเดิมในที่สุด ติดตาม.
อัลกอริธึมและระบบการทำงานร่วมกันแบบจำลอง
อัลกอริธึมการเรียนรู้ของเครื่องหมายถึงอัลกอริธึมเหล่านี้ที่สามารถเรียนรู้กฎและรูปแบบจากข้อมูลและคาดการณ์หรือตัดสินใจตามข้อมูลเหล่านั้น อัลกอริทึมเป็นเทคโนโลยีที่เข้มข้นเนื่องจากการออกแบบและการเพิ่มประสิทธิภาพต้องใช้ความเชี่ยวชาญเชิงลึกและนวัตกรรมทางเทคโนโลยี อัลกอริธึมเป็นหัวใจสำคัญของการฝึกอบรมโมเดล AI และกำหนดวิธีการแปลงข้อมูลให้เป็นข้อมูลเชิงลึกหรือการตัดสินใจที่เป็นประโยชน์ อัลกอริธึม AI ทั่วไป เช่น Generative Adversarial Network (GAN), Variational Autoencoder (VAE) และ Transformer ได้รับการออกแบบมาสำหรับสาขาเฉพาะ (เช่น ภาพวาด การจดจำภาษา การแปล และการสร้างวิดีโอ) หรือเกิดมาเพื่อวัตถุประสงค์ จากนั้นฝึกฝนโมเดล AI เฉพาะทางผ่านอัลกอริธึม
มีอัลกอริธึมและแบบจำลองมากมาย แต่ละแบบก็มีข้อดีของตัวเอง เราจะรวมมันเข้ากับแบบจำลองที่เป็นได้ทั้งพลเรือนและทหารได้หรือไม่? Bittensor ซึ่งได้รับความนิยมอย่างมากเมื่อเร็ว ๆ นี้ เป็นผู้นำในทิศทางนี้ โดยใช้แรงจูงใจในการขุดเพื่อให้โมเดล AI และอัลกอริธึมที่แตกต่างกันสามารถทำงานร่วมกันและเรียนรู้จากกันและกัน จึงสร้างโมเดล AI ที่มีประสิทธิภาพและหลากหลายมากขึ้น การมุ่งเน้นไปที่ทิศทางนี้คือ Commune AI (การทำงานร่วมกันของโค้ด) เป็นต้น อย่างไรก็ตาม สำหรับบริษัท AI ในปัจจุบัน อัลกอริธึมและแบบจำลองจะเป็นผู้เฝ้าประตูของตนเอง และจะไม่มีการยืมตามความประสงค์
ดังนั้นการเล่าเรื่องของระบบนิเวศการทำงานร่วมกันของ AI จึงแปลกใหม่และน่าสนใจมากระบบนิเวศของการทำงานร่วมกันใช้ประโยชน์จากบล็อคเชนเพื่อรวมข้อเสียของเกาะอัลกอริทึม AI แต่ยังไม่ทราบว่าจะสามารถสร้างมูลค่าที่สอดคล้องกันได้หรือไม่ อัลกอริธึมและโมเดลแบบปิดของบริษัท AI ชั้นนำมีความสามารถที่แข็งแกร่งมากในการอัปเดต ทำซ้ำ และบูรณาการ ตัวอย่างเช่น ภายในเวลาไม่ถึงสองปีของการพัฒนา OpenAI ได้ทำซ้ำจากโมเดลการสร้างข้อความในยุคแรก ๆ ไปจนถึงโมเดลที่สร้างขึ้นในหลายสาขา โปรเจ็กต์ต่างๆ เช่น Bittensor มีความก้าวหน้าอย่างมากในด้านโมเดลและอัลกอริธึม พื้นที่เป้าหมายอาจต้องใช้แนวทางใหม่
ข้อมูลขนาดใหญ่ที่กระจายอำนาจ
จากมุมมองง่ายๆ การใช้ข้อมูลส่วนตัวเพื่อป้อน AI และข้อมูลการติดฉลากเป็นแนวทางที่สอดคล้องกับ Blockchain มาก คุณจะต้องใส่ใจกับวิธีการป้องกันข้อมูลขยะและการกระทำชั่วร้ายเท่านั้นและการจัดเก็บข้อมูลก็สามารถใช้ FIL และ AR ได้ รอ เพื่อให้โครงการเดปินได้รับประโยชน์ จากมุมมองที่ซับซ้อน การใช้ข้อมูลบล็อกเชนสำหรับการเรียนรู้ของเครื่อง (ML) เพื่อแก้ปัญหาการเข้าถึงข้อมูลบล็อกเชนก็เป็นทิศทางที่น่าสนใจเช่นกัน (หนึ่งในทิศทางการสำรวจของกิซ่า)
ตามทฤษฎีแล้ว ข้อมูลบล็อกเชนสามารถเข้าถึงได้ตลอดเวลาและสะท้อนถึงสถานะของบล็อกเชนทั้งหมด แต่สำหรับผู้ที่อยู่นอกระบบนิเวศบล็อคเชน การเข้าถึงข้อมูลจำนวนมหาศาลเหล่านี้ไม่ใช่เรื่องง่าย การจัดเก็บบล็อกเชนทั้งหมดต้องใช้ความเชี่ยวชาญที่กว้างขวางและทรัพยากรฮาร์ดแวร์เฉพาะจำนวนมาก เพื่อเอาชนะความท้าทายในการเข้าถึงข้อมูลบล็อคเชน จึงมีโซลูชั่นหลายอย่างเกิดขึ้นในอุตสาหกรรม ตัวอย่างเช่น ผู้ให้บริการ RPC เข้าถึงโหนดผ่าน API ในขณะที่บริการจัดทำดัชนีทำให้การแยกข้อมูลเป็นไปได้ผ่าน SQL และ GraphQL ซึ่งทั้งสองอย่างนี้มีบทบาทสำคัญในการแก้ปัญหา อย่างไรก็ตาม วิธีการเหล่านี้มีข้อจำกัด บริการ RPC ไม่เหมาะสำหรับสถานการณ์การใช้งานที่มีความหนาแน่นสูงซึ่งจำเป็นต้องมีการสืบค้นข้อมูลจำนวนมาก และมักจะไม่สามารถตอบสนองความต้องการได้ ในเวลาเดียวกัน แม้ว่าบริการจัดทำดัชนีจะให้วิธีการดึงข้อมูลที่มีโครงสร้างมากขึ้น แต่ความซับซ้อนของโปรโตคอล Web3 ทำให้ยากมากที่จะสร้างการสืบค้นที่มีประสิทธิภาพ ซึ่งบางครั้งจำเป็นต้องเขียนโค้ดที่ซับซ้อนหลายร้อยหรือหลายพันบรรทัด ความซับซ้อนนี้เป็นอุปสรรคใหญ่สำหรับผู้ปฏิบัติงานด้านข้อมูลทั่วไปและผู้ที่ไม่เข้าใจรายละเอียดของ Web3 อย่างลึกซึ้ง ผลสะสมของข้อจำกัดเหล่านี้เน้นย้ำถึงความจำเป็นในการได้รับและใช้ข้อมูลบล็อคเชนที่ง่ายกว่า ซึ่งสามารถส่งเสริมการยอมรับและนวัตกรรมในวงกว้างในวงกว้าง
จากนั้น ด้วยการรวม ZKML (การเรียนรู้ของเครื่องที่ปราศจากความรู้ ลดภาระของการเรียนรู้ของเครื่องบนห่วงโซ่) เข้ากับข้อมูลบล็อกเชนคุณภาพสูง อาจเป็นไปได้ที่จะสร้างชุดข้อมูลที่แก้ปัญหาการเข้าถึงบล็อกเชน และ AI สามารถช่วยได้อย่างมาก ลดต้นทุนของ blockchain การเข้าถึงข้อมูล ดังนั้นเมื่อเวลาผ่านไป นักพัฒนา นักวิจัย และผู้ที่ชื่นชอบ ML จะสามารถเข้าถึงชุดข้อมูลคุณภาพสูงและเกี่ยวข้องมากขึ้นสำหรับการสร้างโซลูชันที่มีประสิทธิภาพและเป็นนวัตกรรม
AI เสริมศักยภาพ Dapp
นับตั้งแต่ ChatGPT 3 ระเบิดในปี 2023 Dapp ที่ขับเคลื่อนด้วย AI ก็เป็นทิศทางที่แพร่หลายมาก generative AI ที่มีความอเนกประสงค์อย่างยิ่งสามารถเข้าถึงได้ผ่าน API เพื่อลดความซับซ้อนและวิเคราะห์แพลตฟอร์มข้อมูล หุ่นยนต์ซื้อขาย สารานุกรมบล็อกเชน และแอปพลิเคชันอื่น ๆ ได้อย่างง่ายดายและชาญฉลาด ในทางกลับกัน คุณยังสามารถเล่นเป็นแชทบอท (เช่น Myshell) หรือ AI สหาย (Sleepless AI) หรือแม้แต่สร้าง NPC ในเกมลูกโซ่ผ่าน generative AI อย่างไรก็ตาม เนื่องจากอุปสรรคทางเทคนิคต่ำมาก ส่วนใหญ่จึงได้รับการปรับแต่งหลังจากเข้าถึง API และการผสานรวมกับโปรเจ็กต์เองก็ไม่ได้สมบูรณ์แบบ ดังนั้นจึงไม่ค่อยมีการกล่าวถึง
แต่หลังจากการมาถึงของ Sora โดยส่วนตัวแล้วฉันคิดว่าทิศทางของ AI ที่เสริมศักยภาพ GameFi (รวมถึง Metaverse) และแพลตฟอร์มสร้างสรรค์จะเป็นจุดสนใจต่อไป เนื่องจากลักษณะจากล่างขึ้นบนของฟิลด์ Web3 จึงเป็นเรื่องยากอย่างแน่นอนในการผลิตผลิตภัณฑ์ที่แข่งขันกับเกมแบบดั้งเดิมหรือบริษัทสร้างสรรค์ และการเกิดขึ้นของ Sora มีแนวโน้มที่จะทำลายภาวะที่กลืนไม่เข้าคายไม่ออกนี้ (บางทีภายในเพียงสองถึงสามปี) เมื่อพิจารณาจากการสาธิตของ Sora มีศักยภาพที่จะแข่งขันกับบริษัทละครสั้นขนาดสั้นได้แล้ว วัฒนธรรมชุมชนที่กระตือรือร้นของ Web3 ยังให้กำเนิดแนวคิดที่น่าสนใจมากมาย เมื่อข้อจำกัดเป็นเพียงจินตนาการ อุตสาหกรรมจากล่างขึ้นบนและ อุปสรรคจากบนลงล่างระหว่างอุตสาหกรรมแบบดั้งเดิมจะถูกทำลายลง
บทสรุป
เนื่องจากเครื่องมือ AI เจนเนอเรชั่นก้าวหน้าอย่างต่อเนื่อง เราจะได้สัมผัสกับ “ช่วงเวลาสำคัญๆ ของ iPhone” มากขึ้นในอนาคต แม้ว่าหลายๆ คนจะเยาะเย้ยการผสมผสานระหว่าง AI และ Web3 แต่จริงๆ แล้วฉันคิดว่าทิศทางปัจจุบันส่วนใหญ่ไม่มีปัญหาแล้ว จริงๆ แล้วมีประเด็นปัญหาอยู่เพียง 3 ข้อที่ต้องแก้ไข คือ ความจำเป็น ประสิทธิภาพ และความพอดี แม้ว่าการบูรณาการของทั้งสองจะอยู่ในขั้นตอนการสำรวจ แต่ก็ไม่ได้ป้องกันเส้นทางนี้จากการกลายเป็นกระแสหลักของตลาดกระทิงครั้งต่อไป
การรักษาความอยากรู้อยากเห็นและการยอมรับสิ่งใหม่ ๆ ให้เพียงพออยู่เสมอถือเป็นความคิดที่ต้องมีสำหรับเรา ในอดีต การเปลี่ยนแปลงของรถยนต์ที่เข้ามาแทนที่รถม้ากลายเป็นข้อสรุปที่เกิดขึ้นในทันที เช่นเดียวกับจารึก และ NFT ในอดีตก็มีเช่นกัน อคติมากมาย คุณจะพลาดโอกาสเท่านั้น


