
คำอธิบายโดยละเอียดของ Celer "Pantheon": แพลตฟอร์มการประเมินเฟรมเวิร์กการพัฒนาที่ปราศจากความรู้

ชื่อระดับแรก
แพลตฟอร์มการประเมินเฟรมเวิร์กการพัฒนาที่ไม่มีความรู้ที่พิสูจน์ได้ "Pantheon"
ในช่วงไม่กี่เดือนที่ผ่านมา เราได้ใช้เวลาและความพยายามอย่างมากในการพัฒนาโครงสร้างพื้นฐานที่ทันสมัยซึ่งสร้างขึ้นด้วยการพิสูจน์อย่างรวบรัดของ zk-SNARK แพลตฟอร์มที่เป็นนวัตกรรมแห่งยุคหน้านี้ช่วยให้นักพัฒนาสามารถสร้างกระบวนทัศน์ใหม่ของแอปพลิเคชันบล็อกเชนอย่างที่ไม่เคยมีมาก่อน
ในงานพัฒนาของเรา เราได้ทดสอบและใช้เฟรมเวิร์กการพัฒนาแบบ Zero-knowledge Proof (ZKP) ต่างๆ แม้ว่าการเดินทางครั้งนี้จะคุ้มค่า แต่เราตระหนักดีว่ากรอบงาน ZKP ที่หลากหลายมักสร้างความท้าทายให้กับนักพัฒนารายใหม่ เนื่องจากพวกเขาพยายามหากรอบงานที่เหมาะสมกับกรณีการใช้งานและข้อกำหนดด้านประสิทธิภาพเฉพาะของตนมากที่สุด เมื่อพิจารณาถึงความเจ็บปวดนี้ เราเชื่อว่ามีความจำเป็นสำหรับแพลตฟอร์มการประเมินชุมชนที่สามารถให้ผลการทดสอบประสิทธิภาพที่ครอบคลุม ซึ่งจะช่วยอำนวยความสะดวกอย่างมากในการพัฒนาแอปพลิเคชันใหม่เหล่านี้
เพื่อตอบสนองความต้องการนี้ เราได้เปิดตัวแพลตฟอร์มการประเมินเฟรมเวิร์กการพัฒนาที่ไม่มีความรู้ที่พิสูจน์ได้ "Pantheon"โครงการริเริ่มชุมชนสาธารณประโยชน์นี้ ก้าวแรกของการริเริ่มจะกระตุ้นให้ชุมชนแบ่งปันผลการทดสอบประสิทธิภาพที่ทำซ้ำได้. เป้าหมายสูงสุดของเราคือการร่วมกันสร้างและรักษาแพลตฟอร์มทดสอบที่ได้รับการยอมรับอย่างกว้างขวางชื่อระดับแรก
ขั้นตอนที่ 1: การทดสอบประสิทธิภาพของกรอบวงจรโดยใช้ SHA-256
ในบทความนี้ เราใช้ขั้นตอนแรกในการสร้าง ZKP Pantheon โดยใช้ SHA-256 ในชุดเฟรมเวิร์กการพัฒนาวงจรระดับต่ำเพื่อให้ชุดผลการทดสอบประสิทธิภาพที่ทำซ้ำได้ แม้ว่าเรารับทราบว่าการทดสอบประสิทธิภาพแบบละเอียดและพื้นฐานอื่นๆ อาจเป็นไปได้ แต่เราเลือก SHA-256 เนื่องจากเหมาะสำหรับกรณีการใช้งาน ZKP ที่หลากหลาย รวมถึงระบบบล็อกเชน ลายเซ็นดิจิทัล zkDID และอื่นๆ นอกจากนี้เรายังใช้ SHA-256 ในระบบของเราเอง ดังนั้นนี่จึงเป็นประโยชน์สำหรับเราเช่นกัน!
ชื่อเรื่องรอง
ระบบพิสูจน์
ในช่วงไม่กี่ปีที่ผ่านมา เราสังเกตเห็นการแพร่หลายของระบบพิสูจน์ความรู้ที่ไม่มีความรู้ การติดตามความก้าวหน้าที่น่าตื่นเต้นในสาขานี้เป็นเรื่องที่ท้าทาย และเราได้คัดเลือกระบบพิสูจน์ต่อไปนี้สำหรับการทดสอบตามวุฒิภาวะและการยอมรับของนักพัฒนา เป้าหมายของเราคือการจัดเตรียมตัวอย่างที่เป็นตัวแทนของชุดค่าผสมส่วนหน้า/ส่วนหลังที่แตกต่างกัน
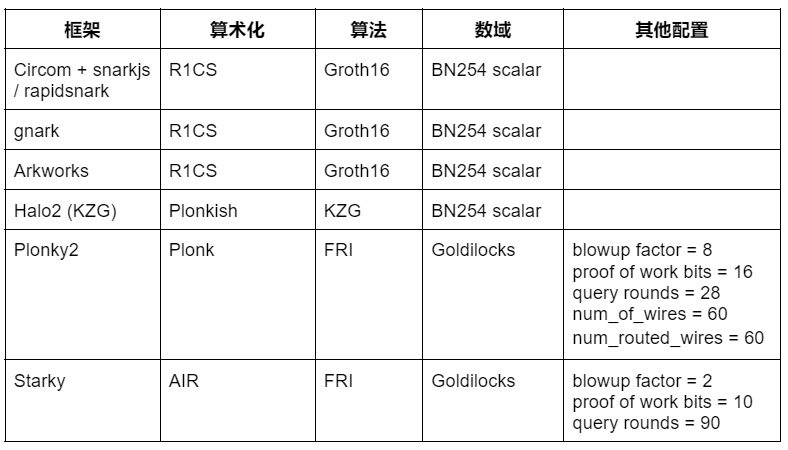
Circom + snarkjs / rapidsnark: Circom เป็น DSL ยอดนิยมสำหรับการเขียนวงจรและสร้างข้อจำกัด R 1 CS และ snarkjs สามารถสร้าง Groth 16 หรือ Plonk proofs สำหรับ Circom Rapidsnark ยังเป็นผู้พิสูจน์ของ Circom ซึ่งสร้างการพิสูจน์ Groth 16 และมักจะเร็วกว่า snarkjs มากเนื่องจากการใช้ส่วนขยาย ADX และสร้างการพิสูจน์แบบขนานให้มากที่สุด
gnark:gnark เป็นเฟรมเวิร์ก Golang ที่ครอบคลุมจาก Consensys ที่รองรับ Groth 16, Plonk และฟีเจอร์ขั้นสูงอีกมากมาย
Arkworks: Arkworks เป็นเฟรมเวิร์ก Rust ที่ครอบคลุมสำหรับ zk-SNARK
Halo 2 (KZG): Halo 2 เป็นการใช้งาน zk-SNARK ของ Zcash และ Plonk มีการติดตั้ง Plonkish arithmetic ที่มีความยืดหยุ่นสูง ซึ่งรองรับพื้นฐานที่มีประโยชน์มากมาย เช่น เกตเวย์ที่กำหนดเองและตารางการค้นหา เราใช้ Halo 2 fork ของ KZG พร้อมรองรับ Ethereum Foundation และ Scroll
Plonky 2 : Plonky 2 เป็นการใช้งาน SNARK โดยใช้เทคโนโลยี PLONK และ FRI จาก Polygon Zero Plonky 2 ใช้ฟิลด์ Goldilocks ขนาดเล็กและรองรับการเรียกซ้ำที่มีประสิทธิภาพ ในการทดสอบประสิทธิภาพของเรา เรากำหนดเป้าหมายการรักษาความปลอดภัย 100 บิตของการเก็งกำไรและใช้พารามิเตอร์ที่ให้เวลาพิสูจน์ที่ดีที่สุดสำหรับความพยายามในการทดสอบประสิทธิภาพ โดยเฉพาะอย่างยิ่ง เราใช้ข้อความค้นหา Merkle 28 รายการ ค่าขยายเท่ากับ 8 และการทดสอบพิสูจน์การทำงานแบบ 16 บิต นอกจากนี้ เราตั้งค่า num_of_wires = 60 และ num_routed_wires = 60
Starky: Starky คือเฟรมเวิร์ก STARK ประสิทธิภาพสูงของ Polygon Zero ในการทดสอบประสิทธิภาพของเรา เรากำหนดเป้าหมายการรักษาความปลอดภัย 100 บิตของการเก็งกำไรและใช้พารามิเตอร์ที่ให้เวลาในการพิสูจน์ที่ดีที่สุด โดยเฉพาะอย่างยิ่ง เราใช้ข้อความค้นหา Merkle 90 รายการ ปัจจัยขยาย 2 เท่า และการทดสอบพิสูจน์การทำงาน 10 บิต
ตารางด้านล่างสรุปเฟรมเวิร์กด้านบนและการกำหนดค่าที่เกี่ยวข้องซึ่งใช้ในการทดสอบประสิทธิภาพของเรา รายการนี้ไม่ได้ครอบคลุมทั้งหมด และเราจะตรวจสอบเฟรมเวิร์ก/เทคโนโลยีล้ำสมัยจำนวนมาก (เช่น Nova, GKR, Hyperplonk) ในอนาคต
โปรดทราบว่าผลการทดสอบประสิทธิภาพเหล่านี้ใช้สำหรับกรอบการพัฒนาวงจรเท่านั้น เราวางแผนที่จะเผยแพร่บทความแยกต่างหากในอนาคตด้วยการทดสอบประสิทธิภาพของ zkVM ต่างๆ (เช่น Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) และเฟรมเวิร์กคอมไพเลอร์ IR (เช่น Noir, zkLLVM)
 วิธีการประเมินผลการปฏิบัติงาน
วิธีการประเมินผลการปฏิบัติงาน
ในการทดสอบประสิทธิภาพบนระบบพิสูจน์ที่แตกต่างกันเหล่านี้ เราคำนวณแฮช SHA-256 ของข้อมูล N ไบต์ โดยที่เราทดสอบด้วย N = 64, 128, ..., 64 K (Starky เป็นข้อยกเว้น โดยที่วงจรจะทำซ้ำ การคำนวณของอินพุต 64 ไบต์คงที่ของ SHA-256 แต่คงจำนวนบล็อกข้อความทั้งหมดเท่าเดิม) อนุญาตที่เก็บนี้รหัสประสิทธิภาพและการกำหนดค่าวงจร SHA-256 อยู่ใน
นอกจากนี้ เราได้ทำการทดสอบประสิทธิภาพในแต่ละระบบโดยใช้เมตริกประสิทธิภาพดังต่อไปนี้:
เวลาในการสร้างหลักฐาน (รวมถึงเวลาในการสร้างพยาน)
การใช้หน่วยความจำเพิ่มขึ้นอย่างรวดเร็วระหว่างการสร้างการพิสูจน์
เปอร์เซ็นต์เฉลี่ยของการใช้งาน CPU ระหว่างการสร้างเอกสารรับรอง (ตัวชี้วัดนี้สะท้อนถึงระดับของการขนานกันในกระบวนการสร้างการพิสูจน์)
ชื่อเรื่องรอง
เครื่องจักร
เราทำการทดสอบประสิทธิภาพกับเครื่องสองเครื่องที่แตกต่างกัน:
เซิร์ฟเวอร์ Linux: 20 คอร์ @ 2.3 GHz, 384 GB RAM
Macbook M 1 Pro: 10 คอร์ @ 3.2 Ghz, RAM 16 GB
เซิร์ฟเวอร์ Linux ใช้เพื่อจำลองสถานการณ์ที่มีคอร์ CPU จำนวนมากและหน่วยความจำเพียงพอ Macbook M 1 Pro ซึ่งมักจะใช้สำหรับการวิจัยและพัฒนา มี CPU ที่ทรงพลังกว่าแต่คอร์น้อยกว่า
ชื่อเรื่องรอง
ข้อความ
ปริมาณจำกัด
ก่อนที่เราจะไปยังรายละเอียดผลการทดสอบประสิทธิภาพ ควรทำความเข้าใจความซับซ้อนของ SHA-256 ก่อนโดยดูที่จำนวนข้อจำกัดในแต่ละระบบพิสูจน์ สิ่งสำคัญคือต้องสังเกตว่าจำนวนข้อจำกัดในรูปแบบเลขคณิตต่างๆ ไม่สามารถเปรียบเทียบได้โดยตรง
ผลลัพธ์ด้านล่างสอดคล้องกับขนาดภาพล่วงหน้า 64 KB โดยจะปรับขนาดอย่างคร่าวๆ เป็นเส้นตรง แม้ว่าผลลัพธ์อาจแตกต่างกันไปตามขนาดพรีอิมเมจอื่นๆ
Circom, gnark และ Arkworks ล้วนใช้อัลกอริทึม R 1 CS เดียวกัน และจำนวนของข้อจำกัด R 1 CS สำหรับการคำนวณ 64 KB SHA-256 อยู่ระหว่าง 30 M ถึง 45 M ความแตกต่างระหว่าง Circom, gnark และ Arkworks อาจเกิดจากความแตกต่างของการกำหนดค่า
ทั้ง Halo 2 และ Plonky 2 ใช้ Plonkish arithmetic โดยที่จำนวนบรรทัดมีตั้งแต่ 2^22 ถึง 2^23 การใช้งาน SHA-256 ของ Halo 2 นั้นมีประสิทธิภาพมากกว่า Plonky 2 มากเนื่องจากการใช้ตารางค้นหา
ข้อความ
เวลาในการสร้างหลักฐาน
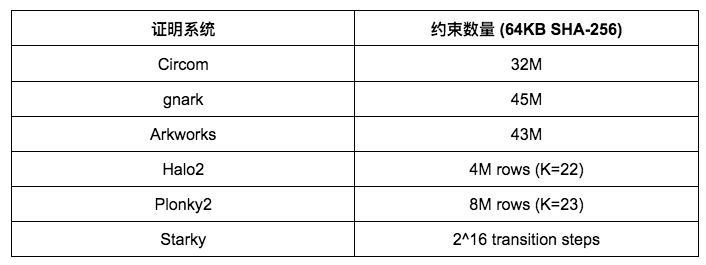
[รูปที่ 1] เวลาในการสร้างการพิสูจน์ของแต่ละเฟรมของ SHA-256 ในขนาดภาพต้นฉบับต่างๆ ได้รับการทดสอบโดยใช้เซิร์ฟเวอร์ Linux เราสามารถรับผลการวิจัยต่อไปนี้:
สำหรับ SHA-256 เฟรมเวิร์ก Groth 16 (rapidsnark, gnark และ Arkworks) สร้างการพิสูจน์ได้เร็วกว่าเฟรมเวิร์ก Plonk (Halo 2 และ Plonky 2) นี่เป็นเพราะ SHA-256 ประกอบด้วยการดำเนินการระดับบิตเป็นส่วนใหญ่โดยที่ค่าลวดเป็น 0 หรือ 1 สำหรับ Groth 16 สิ่งนี้จะลดการคำนวณส่วนใหญ่จากการคูณสเกลาร์เส้นโค้งวงรีไปจนถึงการบวกจุดเส้นโค้งวงรี อย่างไรก็ตาม ค่าลวดไม่ได้ใช้โดยตรงในการคำนวณของ Plonk ดังนั้นโครงสร้างลวดพิเศษใน SHA-256 จึงไม่ลดปริมาณการคำนวณที่จำเป็นในเฟรมเวิร์กของ Plonk
ในบรรดาเฟรมเวิร์กของ Groth 16 ทั้งหมด gnark และ Rapidsnark เร็วกว่า Arkworks และ snarkjs 5 ถึง 10 เท่า นี่เป็นเพราะความสามารถที่โดดเด่นของพวกเขาในการใช้ประโยชน์จากหลายคอร์เพื่อสร้างการพิสูจน์แบบขนาน Gnark เร็วกว่า Rapidsnark 25%
สำหรับ Plonk framework SHA-256 ของ Plonky 2 ช้ากว่า Halo 2 ถึง 50% เมื่อใช้ขนาดพรีอิมเมจที่ใหญ่กว่า >= 4 KB นี่เป็นเพราะการใช้งาน Halo 2 เป็นหลักใช้ตารางการค้นหาเพื่อเพิ่มความเร็วในการดำเนินการระดับบิต ส่งผลให้มีแถวน้อยกว่า Plonky 2 ถึง 2 เท่า อย่างไรก็ตาม หากเราเปรียบเทียบ Plonky 2 และ Halo 2 ที่มีจำนวนแถวเท่ากัน (เช่น SHA-256 มากกว่า 2 KB ใน Halo 2 เทียบกับ SHA-256 มากกว่า 4 KB ใน Plonky 2) Plonky 2 จะเร็วกว่า Halo 50% 2. หากเราใช้ SHA-256 ใน Plonky 2 โดยใช้ตารางค้นหา เราควรคาดว่า Plonky 2 จะเร็วกว่า Halo 2 แม้ว่า Plonky 2 จะมีขนาดการพิสูจน์ที่ใหญ่กว่าก็ตาม
ในทางกลับกัน เมื่อขนาดพรีอิมเมจอินพุตมีขนาดเล็ก (<= 512 ไบต์) Halo 2 จะช้ากว่า Plonky 2 (และเฟรมเวิร์กอื่นๆ) เนื่องจากค่าติดตั้งคงที่ของตารางการค้นหาซึ่งคิดเป็นข้อจำกัดส่วนใหญ่ อย่างไรก็ตาม ประสิทธิภาพของ Halo 2 มีความสามารถในการแข่งขันมากขึ้นเมื่อขนาดพรีอิมเมจเพิ่มขึ้น และเวลาในการสร้างที่พิสูจน์แล้วยังคงที่สำหรับขนาดพรีอิมเมจสูงสุด 2 KB ซึ่งปรับขนาดได้เกือบเป็นเส้นตรงตามที่แสดง
ตามที่คาดไว้ เวลาในการสร้างการพิสูจน์ของ Starky นั้นสั้นกว่ามาก (5x-50x) กว่าเฟรมเวิร์ก SNARK ใดๆ แต่สิ่งนี้มาพร้อมกับต้นทุนของขนาดการพิสูจน์ที่ใหญ่กว่า
โปรดทราบว่าแม้ว่าขนาดวงจรจะปรับขนาดเป็นเส้นตรงด้วยขนาดพรีอิมเมจ แต่การสร้างการพิสูจน์สำหรับ SNARK จะเพิ่มขึ้นแบบซุปเปอร์ลิเนียร์เนื่องจาก O(nlogn) FFT (แม้ว่าปรากฏการณ์นี้จะไม่แสดงบนกราฟเนื่องจากสเกลลอการิทึมชัดเจน)
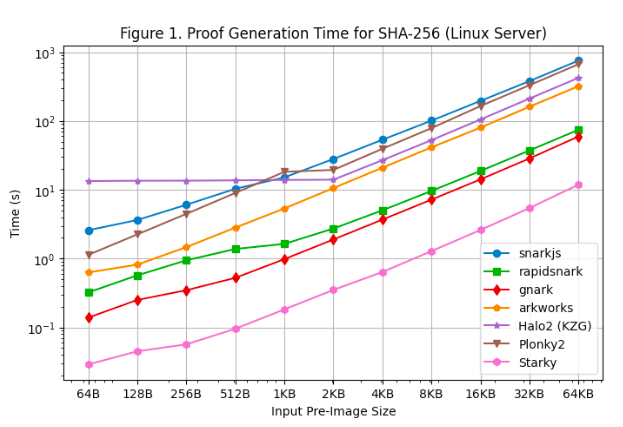
นอกจากนี้ เรายังดำเนินการทดสอบประสิทธิภาพเวลาในการสร้างหลักฐานใน Macbook M 1 Pro ดังที่แสดงใน [รูปที่ 2] อย่างไรก็ตาม ควรสังเกตว่า Rapidsnark ไม่รวมอยู่ในเกณฑ์มาตรฐานนี้ เนื่องจากขาดการสนับสนุนสำหรับสถาปัตยกรรม Arm 64 ในการใช้ snarkjs บนแขน 64 เราต้องใช้ webassembly เพื่อสร้างพยาน ซึ่งช้ากว่าการสร้างพยาน C++ ที่ใช้บนเซิร์ฟเวอร์ Linux
ข้อสังเกตเพิ่มเติมสองสามประการเมื่อเรียกใช้การทดสอบประสิทธิภาพบน Macbook M 1 Pro:
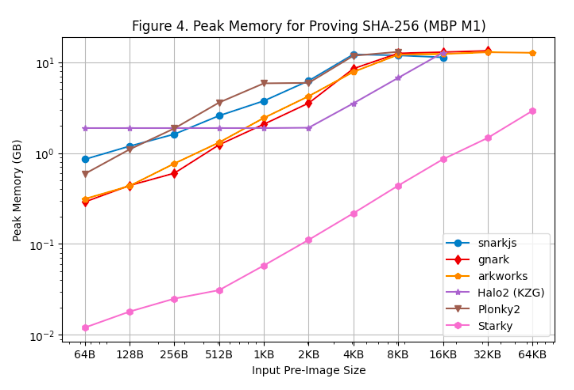
ยกเว้น Starky เฟรมเวิร์ก SNARK ทั้งหมดประสบกับข้อผิดพลาดหน่วยความจำไม่เพียงพอ (OOM) หรือใช้หน่วยความจำสลับ (ส่งผลให้เวลาในการพิสูจน์ช้าลง) เมื่อขนาดภาพล่วงหน้าใหญ่ขึ้น โดยเฉพาะอย่างยิ่ง Groth 16 frameworks (snarkjs, gnark, Arkworks) เริ่มใช้ swap memory ที่ขนาด preimage >= 8 KB ในขณะที่ gnark หน่วยความจำไม่เพียงพอที่ขนาด preimage >= 64 KB Halo 2 ใช้งานหน่วยความจำถึงขีดจำกัดเมื่อขนาดพรีอิมเมจคือ >= 32 KB Plonky 2 เริ่มใช้หน่วยความจำสลับเมื่อขนาดพรีอิมเมจคือ >= 8 KB
ชื่อเรื่องรอง
การใช้หน่วยความจำสูงสุด
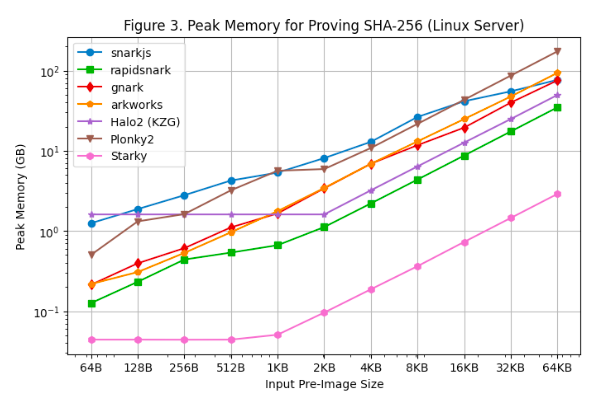
[รูปที่ 3] และ [รูปที่ 4] แสดงการใช้หน่วยความจำสูงสุดระหว่างการสร้างการพิสูจน์บน Linux Server และ Macbook M 1 Pro ตามลำดับ จากผลการทดสอบประสิทธิภาพเหล่านี้สามารถสังเกตได้ดังต่อไปนี้:
ในบรรดาเฟรมเวิร์ก SNARK ทั้งหมด Rapidsnark เป็นหน่วยความจำที่มีประสิทธิภาพมากที่สุด นอกจากนี้ เรายังเห็นว่า Halo 2 ใช้หน่วยความจำมากขึ้นเมื่อขนาดภาพล่วงหน้ามีขนาดเล็กลงเนื่องจากค่าติดตั้งคงที่ของตารางการค้นหา แต่ใช้หน่วยความจำโดยรวมน้อยลงเมื่อขนาดภาพล่วงหน้าใหญ่ขึ้น
Starky มีประสิทธิภาพหน่วยความจำมากกว่าเฟรมเวิร์ก SNARK มากกว่า 10 เท่า ส่วนหนึ่งเป็นเพราะใช้แถวน้อยลง
ชื่อเรื่องรอง
การใช้งานซีพียู
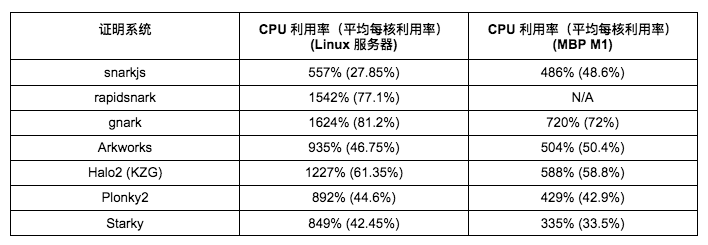
เราประเมินระดับของการขนานกันของระบบการพิสูจน์แต่ละระบบโดยการวัดการใช้งาน CPU โดยเฉลี่ยของ SHA-256 ระหว่างการสร้างการพิสูจน์สำหรับอินพุตพรีอิมเมจขนาด 4 KB ตารางด้านล่างแสดงการใช้งาน CPU เฉลี่ย (การใช้งานเฉลี่ยต่อคอร์ในวงเล็บ) บน Linux Server (20 คอร์) และ Macbook M 1 Pro (10 คอร์)
ข้อสังเกตหลักมีดังนี้
Gnark และ Rapidsnark แสดงการใช้งาน CPU สูงสุดบนเซิร์ฟเวอร์ Linux ซึ่งบ่งชี้ว่าสามารถใช้หลายคอร์ได้อย่างมีประสิทธิภาพและสร้างการพิสูจน์แบบขนาน Halo 2 ยังแสดงประสิทธิภาพการขนานที่ดี
การใช้งาน CPU ของเฟรมเวิร์กส่วนใหญ่บนเซิร์ฟเวอร์ Linux เป็นสองเท่าของ Macbook Pro M 1 ยกเว้น snarkjs
ชื่อระดับแรก
บทสรุปและการวิจัยในอนาคต
บทความนี้เปรียบเทียบผลการทดสอบประสิทธิภาพของ SHA-256 ในเฟรมเวิร์กการพัฒนา zk-SNARK และ zk-STARK ต่างๆ อย่างครอบคลุม จากการเปรียบเทียบ เราได้รับข้อมูลเชิงลึกเกี่ยวกับประสิทธิภาพและประโยชน์ของแต่ละเฟรมเวิร์ก โดยหวังว่าจะช่วยนักพัฒนาที่ต้องการสร้างหลักฐานที่รวบรัดสำหรับการดำเนินการ SHA-256 เราพบว่า Groth 16 frameworks (เช่น Rapidsnark, gnark) สร้างการพิสูจน์ได้เร็วกว่า Plonk frameworks (เช่น Halo 2, Plonky 2) ตารางการค้นหาใน Plonkish arithmetics ลดข้อจำกัด SHA-256 และเวลาในการพิสูจน์ได้อย่างมากเมื่อใช้ขนาดภาพล่วงหน้าที่ใหญ่ขึ้น นอกจากนี้ gnark และ Rapidsnark ยังแสดงให้เห็นถึงความสามารถที่ยอดเยี่ยมในการใช้ประโยชน์จากหลายคอร์เพื่อดำเนินการแบบขนาน ในทางกลับกัน เวลาในการสร้างการพิสูจน์ของ Starky นั้นสั้นกว่ามาก ในราคาของขนาดการพิสูจน์ที่ใหญ่กว่ามาก ในแง่ของประสิทธิภาพของหน่วยความจำ Rapidsnark และ Starky มีประสิทธิภาพเหนือกว่าเฟรมเวิร์กอื่นๆ
ในขั้นตอนแรกในการสร้างแพลตฟอร์มการประเมินที่ไม่มีความรู้ที่พิสูจน์ได้ "Pantheon" เรายอมรับว่าผลการทดสอบประสิทธิภาพนี้ยังห่างไกลจากความเพียงพอที่จะกลายเป็นแพลตฟอร์มการทดสอบที่ครอบคลุมซึ่งเราหวังว่าจะสร้างขึ้นในท้ายที่สุด เรายินดีรับฟังคำติชมและคำวิจารณ์ และขอเชิญทุกคนให้มีส่วนร่วมในความคิดริเริ่มนี้เพื่อทำให้การพิสูจน์ความรู้ที่ไม่มีความรู้สามารถเข้าถึงได้มากขึ้น และอุปสรรคในการเข้าถึงต่ำสำหรับนักพัฒนา นอกจากนี้ เรายังยินดีให้เงินช่วยเหลือแก่ผู้ร่วมให้ข้อมูลอิสระรายบุคคลเพื่อให้ครอบคลุมค่าใช้จ่ายของทรัพยากรการคำนวณสำหรับการทดสอบประสิทธิภาพในสเกลใหญ่ เราหวังว่าการทำงานร่วมกันจะสามารถปรับปรุงประสิทธิภาพและประโยชน์ของ ZKP และเป็นประโยชน์ต่อชุมชนในวงกว้างมากขึ้น
สุดท้าย เราขอขอบคุณทีมงาน Polygon Zero, ทีมงาน gnark ที่ Consensys, Pado Labs และทีมงาน Delphinus Lab สำหรับคำวิจารณ์อันมีค่าและข้อเสนอแนะเกี่ยวกับผลการทดสอบประสิทธิภาพ


